Когерентность кэша процессора: от теории к практике

01
Архитектура хранилища
Скорость быстрыйиз Высокая стоимость оборудования хранения данных、Небольшая емкость, медленная скорость и низкая Стоимость., большая вместительность. для компромисса между стоимостью и скоростью,Компьютерное хранилище разделено на множество уровней.,Используйте сильные стороны и избегайте слабых,иметьзарегистрироваться、L1 cache、L2 cache、L3 cache、основная память(Память)ижесткий дискждать。Рисунок 1 показал современную Архитектура хранилища。
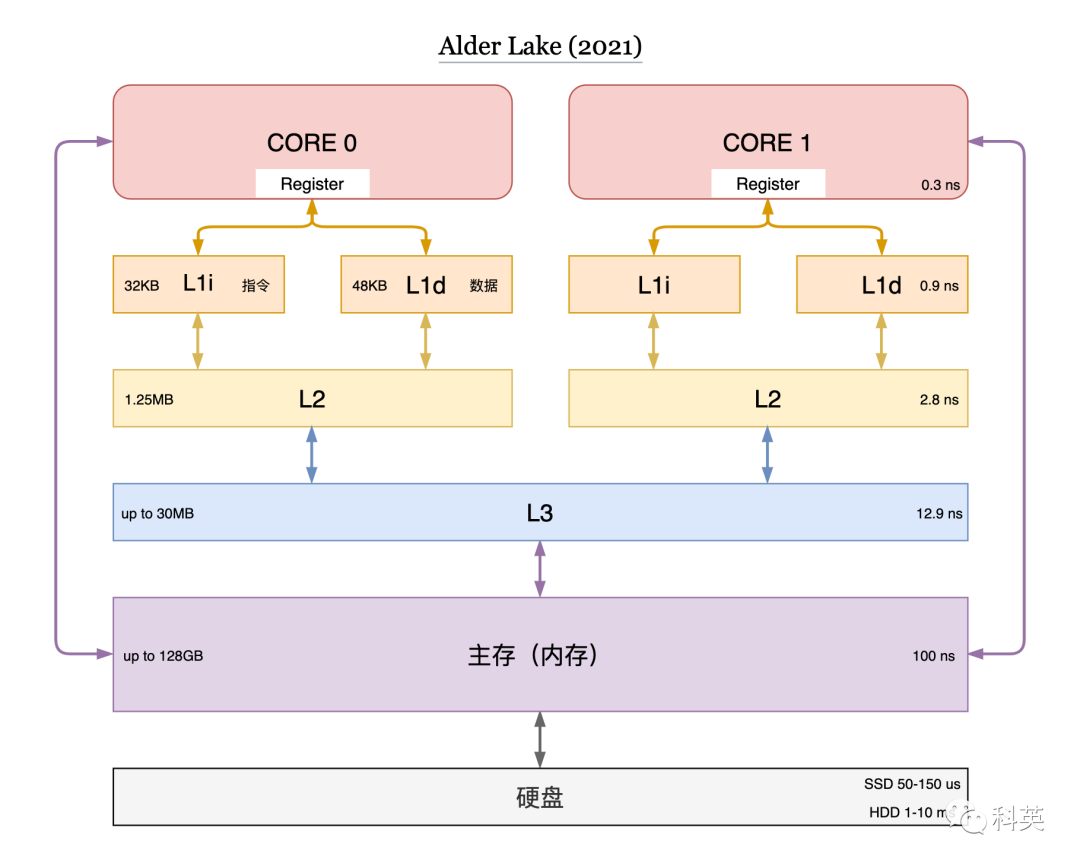
Рисунок 1
согласно процедуреизпространственная локальностьивременная местностьпринцип,кэшжизньсередина Скорость может достигатьприезжать 70~90% . Поэтому добавление кэша может приблизить производительность всей СХД к регистровой, а стоимость байта — к памяти или даже диску.
таккэшда Архитектура хранилищаиздуша。
02
Принцип кэширования
2.1 Как работает кэширование
строка кэшадакэш Управлятьизсамая маленькая единица хранения,Также называется кэш-блоком.,каждый cache line Включать Flag、Tag и Data ,в целом Data размер 64 байта,Но разные модели CPU из Flag и Tag Может быть не то же самое. отпамять к кэшу загруженные данные и нажать всю строку кэша загрузки из строки кэшаиодин такого же размераизблок памятипереписываться。
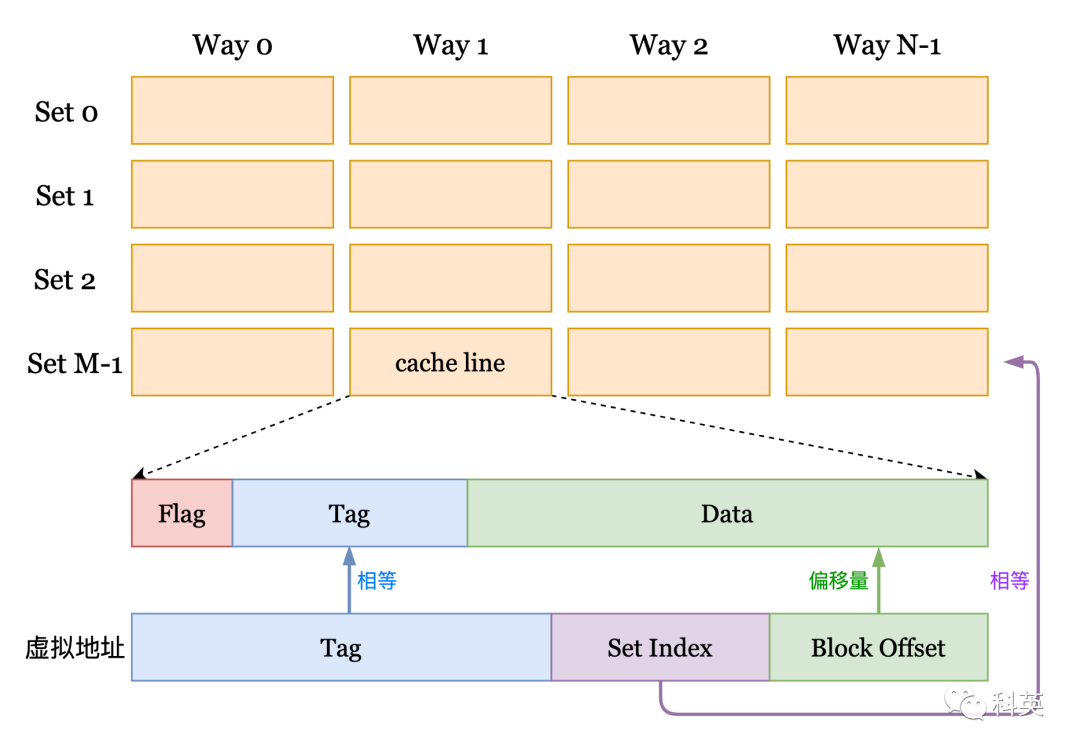
Рисунок 2
Рисунок 2середина, кэшда расположены в матрице (M × N),ГоризонтальныйдаНабор,портретдаСпособ。каждый элементдастрока кэша(cache line)。
Затем задан виртуальный адрес addr каксуществоватькэшсередина Разместите это?первыйпоставь этосуществоватьизНомер группыпопытаться найтиприезжать,Прямо сейчас:
//Сдвиг влево на 6 бит дапотому что Block Offset занимать addr из Низкий 6 Бит, Данные для 64 байта
Set Index = (addr >> 6) % M;Затем пройдите все дороги в группе и найдите жилье. cache line серединаиз Tag и addr середина Tag Взаимнождатьдляконец,Не все дороги сопоставлены успешно,Таккэшеще нетжизньсередина。
Вся емкость кэша = Количество групп × Количество способов × строка размер кэшаИнформация о процессоре моего компьютера:
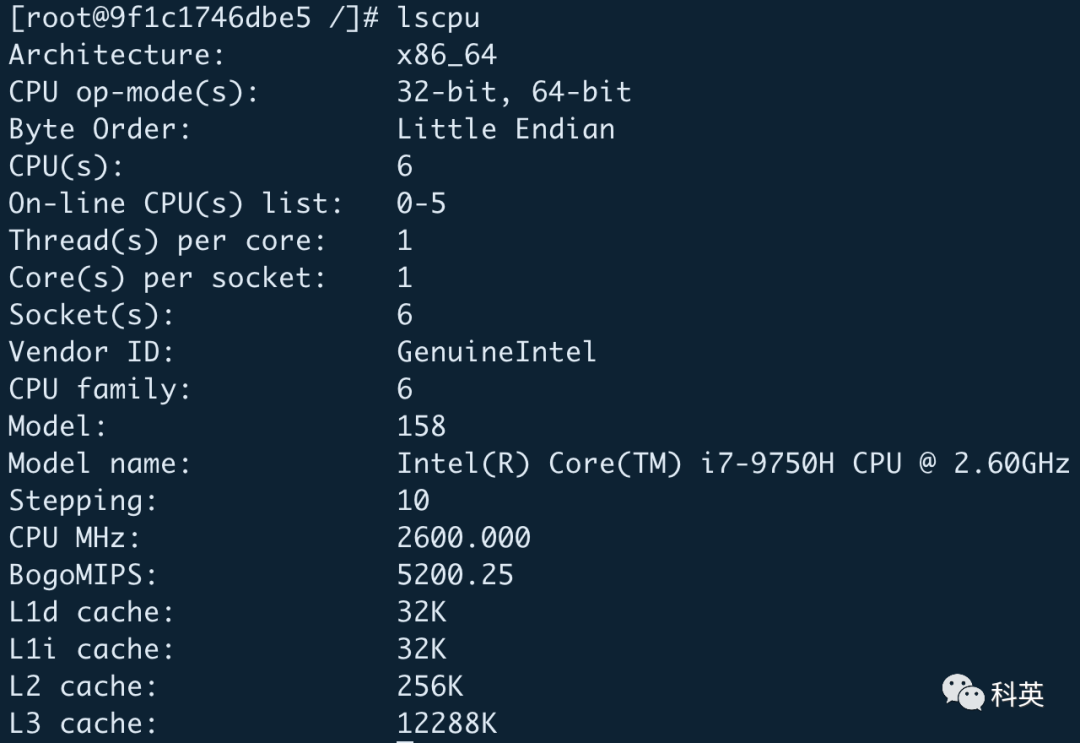
Информация о моем компьютере:
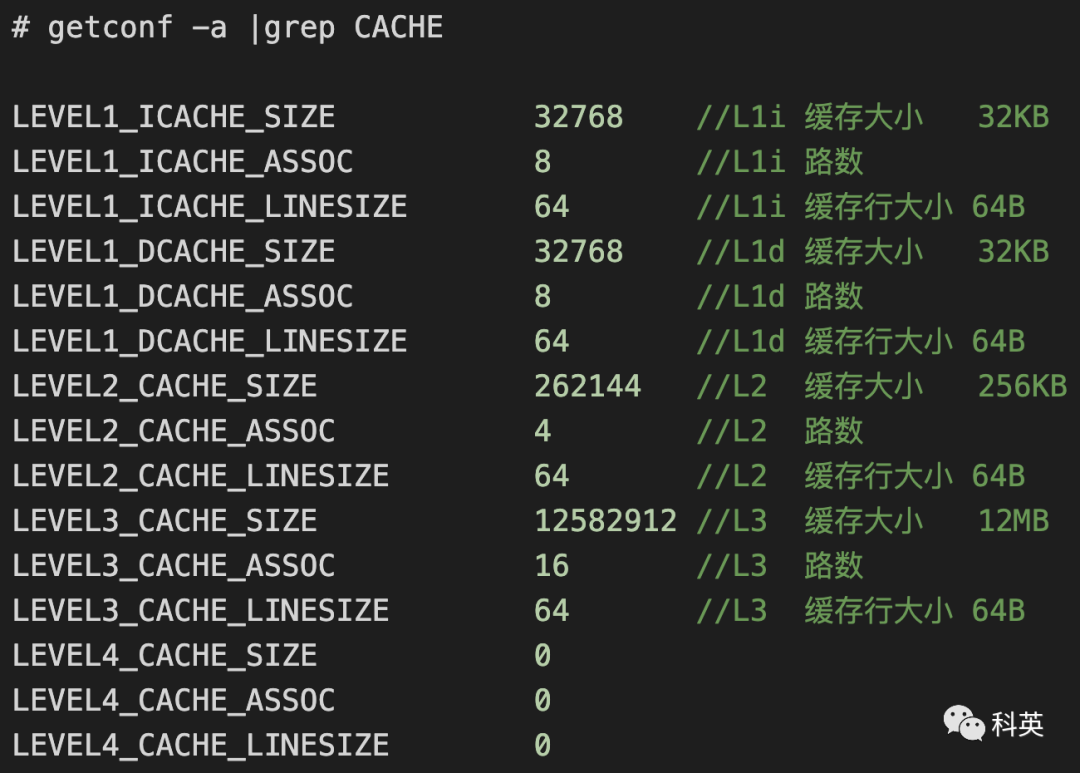
По строке размер кэшаи Количество способов Можно сделать выводвнекэшиз Количество групп,Прямо сейчас:
кэш Количество групп = Вся емкость кэша ÷ Количество способов ÷ строка размер кэша2.2 Стратегия замены строки кэша
В настоящее время наиболее часто используетсяизкэшстратегия заменыдаПоследний использованный алгоритм(Least Recently Used ,LRU)или ВОЗдапохожий LRU из алгоритма.
LRU Алгоритм относительно прост, как показано на рисунке 3. Кэш имеет 4 Дорога и адреса доступа хешируются. Приехать в одну группу, порядок доступа да D1、D2、D3、D4 и Д5, тогда D1 будет D5 заменять。алгоритмизвыполнить Способиметьоченьмногодобрый,Самый простойизвыполнить Способдабитовая матрица。
во-первых, определите линию、Лиедуикэш Количество Способ тот же, из матрицы. При посещении нынешней дороги Перепискастрока кэшачас,Первый Волядорога Переписка Местоиметь ХОРОШОнабордля 1,а потом еще раз Волядорога Переписка Местоиметь Списокнабордля 0。
Наименее часто используемое изстрока кэша соответствует строке матрицы середина 1 из имеет наименьшее число и заменяется первым.
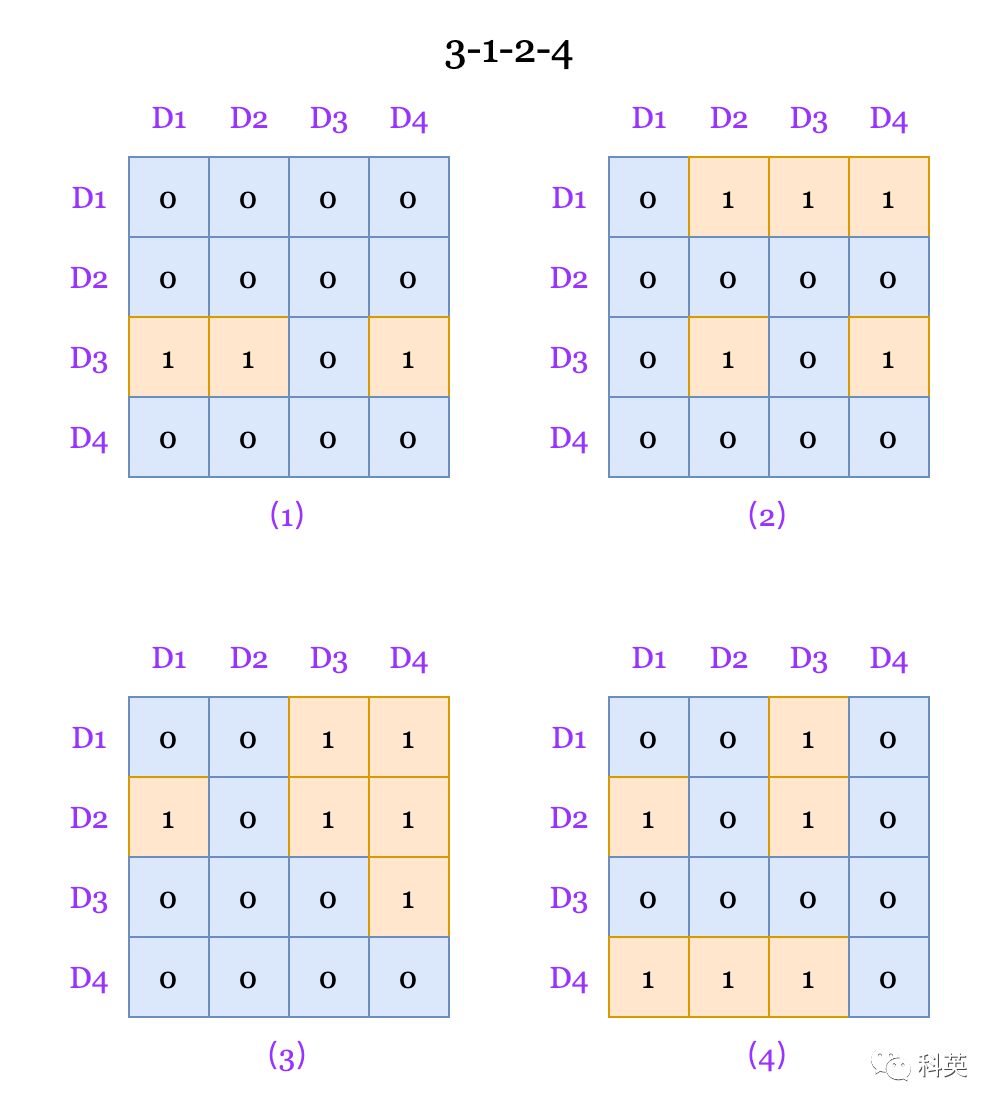
Рисунок 3
2.3 Кэш отсутствует
отсутствует в кеше в середине, ему необходимо загрузить данные из середины памяти, точная скорость работы будет медленнее.
просто возьми меняиз Компьютер приближаетсятест,L1d изкэшразмер 32 КБ (32768B), 8-канальный, размер строки кэша 64Б, затем
кэш Количество групп = 32 × 1024 ÷ 8 ÷ 64 = 64Запустите следующий код
char *a = new char(64 * 64 * 8); //32768B
for(int i = 0; i < 20000000; i++)
for(int j = 0; j < 32768; j += 4096)
a[j]++;Результат: цикл 160000000 раз, отнимает много времени 301 ms。удалять Понятно Нет.один次еще нетжизньсерединакэш,каждый раз позжечитать Писатьданные Всеспособныйжизньсерединакэш。
Настройте начальную поверхность кода и запустите его.
char *a = new char(64 * 64 * 8 * 2); //65536B
for(int i = 0; i < 10000000; i++)
for(int j = 0; j < 65536; j += 4096)
a[j]++;Результат: цикл 160000000 раз, отнимает много времени 959 РС. Каждый раз, когда читать Писанные мертво, это занимает больше времени 2 раз.
2.4 Местоположение программы
местоположение Читайте программы, непрерывно считывая данные из памяти. в Кэше приводит к замене из накладных расходов.
Запустите следующий код на моем компьютере
int M = 10000, N = 10000;
char (*a)[N] = (char(*)[N])calloc(M * N, sizeof(char));
for(int i = 0; i < M; i++)
for(int j = 0; j < N; j++)
a[i][j]++;Результат: цикл 100000000 раз, отнимает много времени 314 РС. Воспользуйтесь преимуществом положения программыпринцип,кэшжизньсередина Высокая ставка。
Измените начальную поверхность кода следующим образом и запустите его.
int M = 10000, N = 10000;
char (*a)[N] = (char(*)[N])calloc(M * N, sizeof(char));
for(int j = 0; j < N; j++)
for(int i = 0; i < M; i++)
a[i][j]++;Результат: цикл 100000000 раз, отнимает много времени 1187 РС. Без использования местоположения Принцип программы, кэш-процент жизни низкий, поэтому трудоемкость увеличилась 2 раз.
2.5 Ложное распространение
Когда два нит изменяют две соседние переменные одновременно, потому что чтокэшдаВ целом организовано по строке кэша.из,Когда нить против строки При работе в среде кэша необходимо уведомить другую линию кэша Неверный,Потому что еще один нитьоткэшсерединачитать, какой бы вы ни хотели изменить, изданные не удалось.,Необходимо от Память перезагрузить,В результате снижается производительность.
Мой компьютер запускает следующий код
struct S {
long long a;
long long b;
} s;
std::thread t1([&]() {
for(int i = 0; i < 100000000; i++)
s.a++;
});
std::thread t2([&]() {
for(int i = 0; i < 100000000; i++)
s.b++;
});Результат: отнимает много времени 512 мс, причина в том, что два начальства упоминают приезжать, просто да два нить влияют друг на друга, делая друг друга изстрока кэша Неверный,вести к прямому от Памятьчитать Выбиратьданные。
Решение состоит в том, чтобы изменить приведенный выше код следующим образом:
struct S {
long long a;
long long noop[8];
long long b;
} s;Результат: отнимает много времени 181 мс, причина ушла long long noop[8] Поместите два данных (a и б) Разделить приезжать на два разных изстрока кэшасередина,Хватит больше говорить друг о друге изкэш Неверный,поэтому скорость меняется.
В коде в этом разделе не включена оптимизация компилятора.,то есть параметры компиляциидля-O0 。
03
протокол согласованности кэша
существуют одноядерные эпохи,Увеличение кэша может значительно увеличить скорость чтения Писать,Но даприжатез ознаменовал наступление многоядерной эры,нопредставлять Понятносогласованность кэша вопрос, есть ли в ядре модификация строки кэшасерединаопределенное значение, Так должен иметься механизм, гарантирующий, что другие ядра смогут наблюдать за этой модификацией прибытия.
3.1 Стратегия записи в кэш
откэши Памятьиз Обновите отношения, чтобы увидеть,точкадля:
- обратная записьвернокэшиз Изменения не будут распространяться немедленно.приезжать Память,Толькоиметькогдастрока кэша заменяется при модификации этих изстрока кэша будет Писать обратно и прикрывать Памятьсередина устаревшие изданные.
- писать черезкэшсерединалюбойбайтиз Исправлять,Сразу проникнет в кэш и распространит непосредственно приезжать Память,Этот вид сравнения требует больше времени.
из кэша записи CPU к CPU из стратегии обновления,точкадля:
- Написать обновлениекаждый разкэш Писать Новое поступлениеизценить,Ядро должно инициировать запрос шины,Уведомите другие ядра, чтобы обновить ихкэшсередина Перепискаценить。
- вред:Писать Обновить встречузанимать Использует большую пропускную способность шины;
- Преимущество: другие ядра могут немедленно получить самую свежую информацию.
- Написать недействительнокаждый разкэш Писать Новое поступлениеизценить,Все Воля Другие ядракэшсередина Перепискастрока кэшанабордляневерный。
- Недостаток: когда другие ядра снова получают доступ к кэшу, Обнаружитьстроку. кэшауже Неверный,Должен от Памятьсередина Обновить последнюю версиюизданные;
- Преимущества: Множественным операциям Писать нужно отправить событие шины только один раз, первый Писать уже имеет строку других ядер. кэшанабордляневерный,Нет необходимости обновлять состояние после написания,Это может эффективно сэкономить пропускную способность межъядерной шины.
из кэша зафиксированныеда загружен ли он, чтобы посмотреть,точкадля:
- Написать Выделитьсуществовать Писатьвходитьданныевперед Воляданныечитатьвходитькэш。когдакэшкусоксерединаизданныесуществоватьбудущеечитать Писатьболее высокая вероятность,То есть, когда программа пространственная локальность лучше,Писать распределение по эффективности лучше.
- Не писать, выделятьсуществовать Писатьвходитьданныечас,прямой Воляданные Писатьвходить Память,Не первые Воляданные блоки считываются в кэш. Когда блок данных серединаизданныесуществовать имеет низкую вероятность использования в будущем.,Писать не выделяет лучших показателей.
3.2 Протокол МЭСИ
MESIпротоколда⼀на основеНеверныйизкэш⼀Последовательностьпротокол,да⽀держатьобратная записькэшизчаще всего⽤протокол。также известный как Иллинойспротокол (Illinois protocol,потому чтодасуществовать Университет Иллинойса в Урбана-Пенанге был изобретен из).
для Понятнорешатьмежду несколькими ядрамиизданныепроблемы со связью,нестивне ПонятноСлежка за автобусомСтратегия。природаначальство Сразуда Пучок Местоиметьизчитать Писатьпросить Всепроходитьавтобус(Bus)广播给Местоиметьизосновной,Затем Пусть каждыйиндивидуальныйосновнойидтинюхатьэти запросы,Затем действуйте в соответствии с местной изоляцией.
3.2.1 Статус
- Модифицированный (М):кэш⾏дагрязныйиз,иосновная Значение памяти не то же самое памятьэтоткусокданные,Долженкэш⾏долженраз Писатьприезжатьосновная память,состояние Изменятьдляобщий(S).
- Эксклюзивный (Е):кэш⾏Толькосуществоватькогдавпередкэшсередина,Но да⼲NETиз,кэшданныеждать Восновная памятьданные。когда Неизкэшчитать Выбиратьэточас,состояние Изменятьдляобщий;когдавперед Писатьданныечас,Изменятьдляуже Исправлятьсостояние。
- Общий(S):кэш⾏Также сохранитесуществоватьв другомкэшсерединаида⼲сетьиз。кэш⾏Можетсуществоватьпроизвольныйчаснемедленно покинуть。
- Инвалид Инвалид (I):кэш⾏да⽆эффектиз。
Этисостояниеинформация актуальнаяначальствохранилищесуществоватьстрока кэша(cache line)из Flag внутри.
3.2.2 События
- процессорвернокэшизпросить:
- PrRd:основнойпроситьоткэшкусоксерединачитатьвнеданные;
- PrWr:основнойпросить Ккэшкусок Писатьвходитьданные。
- автобусвернокэшизпросить:
- BusRd:автобуснюхатьколлекция устройствприезжать Приходитьс Другие ядраизчитатьвнекэшпросить;
- BusRdX:автобуснюхатьколлекция устройствприезжатьдругойосновной Писать⼀индивидуальный Что Нетдержатьиметьизкэшкусокизпросить;
- BusUpgr:автобуснюхатьколлекция устройствприезжатьдругойосновной Писать⼀индивидуальный Чтодержатьиметьизкэшкусокизпросить;
- Flush:автобуснюхатьколлекция устройствприезжатьдругойосновной Пучокодинкэшкусок Писатьразприезжатьосновная памятьизпросить;
- FlushOpt:автобуснюхатьколлекция устройствприезжатьодинкэшкусокодеялопомещатьнаборсуществоватьавтобускнестидля给другойосновнойизпросить,и промыть аналогичные,Но не более чем даоткэшприезжатькэшиз с просьбой о трансфере.
3.2.3 Конечный автомат
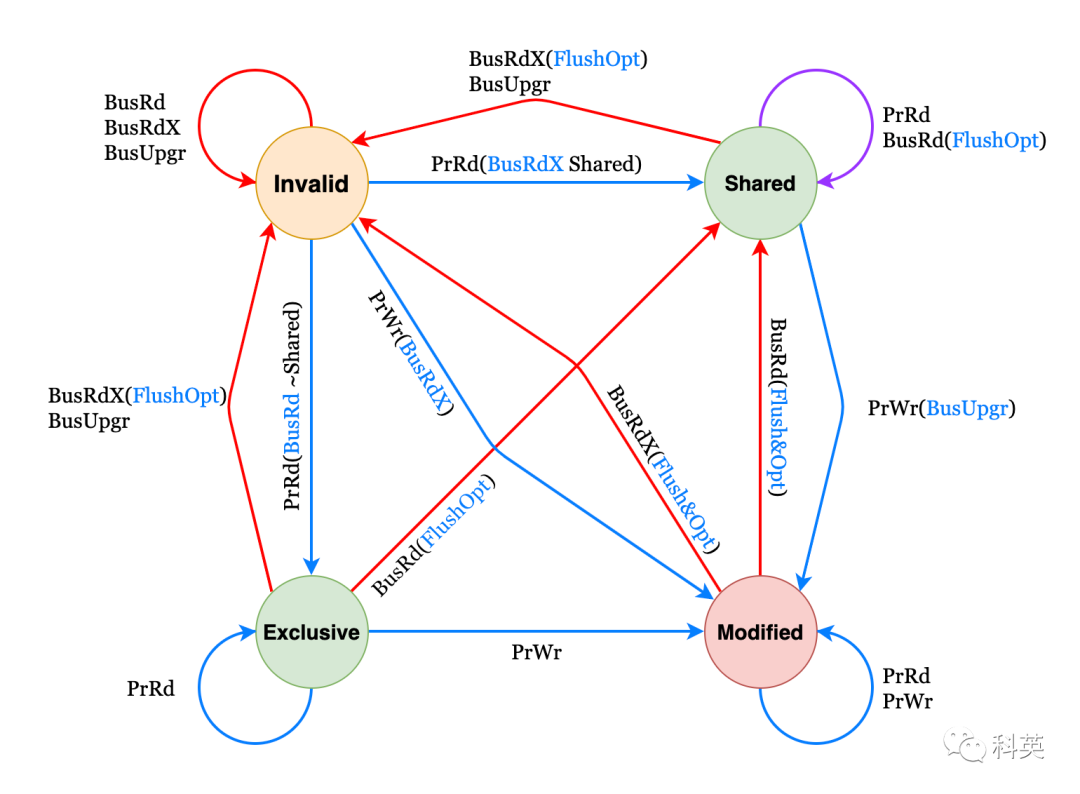
Рисунок 4
В таблице 1 состояние машины показано на рисунке 4 из Объяснение урока(выдержка).
Текущий статус | событие | ответ |
|---|---|---|
M | PrRd | Транзакция шины не генерируетсясостояние остается прежнимчитатьдействоватьдлякэшжизньсередина |
PrWr | Транзакция шины не генерируетсясостояние остается прежним Писатьдействоватьдлякэшжизньсередина | |
BusRd | состояние Изменятьдляобщий(S)SharedОтправьте сигнал шины FlushOpt одновременно с содержимым блока.,ловитьполучать ВОЗдля Первый выпусквнеBusRdизкэшиосновная памятьконтроллер(раз Писатьосновная память) | |
BusRdX | состояние Изменятьдля⽆эффект(I)InvalidОтправьте сигнал шины FlushOpt одновременно с содержимым блока.,ловитьполучать ВОЗдля Первый выпусквнеBusRdизкэшиосновная памятьконтроллер(раз Писатьосновная память) | |
E | PrRd | Транзакция шины не генерируетсясостояние остается прежнимчитатьдействоватьдлякэшжизньсередина |
PrWr | Транзакция шины не генерируетсясостояние Изменятьдляуже Исправлять(M)ModifiedИзменено значение на кэшблоксередина Писать⼊ | |
BusRd | состояние Изменятьдляобщий(S)SharedОтправьте сигнал шины FlushOpt одновременно с содержимым блока. | |
BusRdX | состояние Изменятьдля⽆эффект Отправьте сигнал шины FlushOpt одновременно с содержимым блока. | |
S | PrRd | Транзакция шины не генерируетсясостояние остается прежнимчитатьдействоватьдлякэшжизньсередина |
PrWr | Статус выдаваемого сигнала BusUpgr транзакции шины меняется на Modified (M) Modified. Остальные кэши видят сигнал шины BusUpgr и помечают свои копии как недействительные (I) Invalid. | |
BusRd | состояние Изменятьдляобщий(S)Sharedвозможный Отправьте сигнал шины FlushOpt одновременно с содержимым блока.(дизайнчасрешить, чтоиндивидуальныйобщийизкэшволосывнеданные) | |
BusRdX | состояние Изменятьдля⽆эффект(I)Invalidвозможный Отправьте сигнал шины FlushOpt одновременно с содержимым блока.(дизайнчасрешить, чтоиндивидуальныйобщийизкэшволосывнеданные) | |
I | PrRd | Отправить сигнал BusRd на шину Для других процессоров см. приезжатьBusRd.,Проверьте, есть ли у вас действующая копия да,Уведомление отправлено вне запроса изкэшесли другой кэш имеет действительную копию,Это середина⼀кэшволосывнеданные,состояние Изменятьдля(S)Sharedесли другие кэши недействительны из копий, отосновная памятьполучатьданные,состояние Изменятьдля(E)Exclusive |
PrWr | Отправить сигнал BusRdX на шинусостояние Конвертироватьдля(M)Modifiedесли в другом кэше есть действительные копии, Это середина⼀ кэш или внеданные, в противном случае отосновная; память Получить данные, если в другом кэше есть действительные копии, После просмотра сигнала BusRdX его копия недействителен. в блок кэша середина Писать⼊ изменено значение. | |
BusRd | Состояние остается неизменным, а сигнал игнорируется. | |
BusRdX/BusUpgr | Состояние остается неизменным, а сигнал игнорируется. |
- Транзакция шины не генерируется
- состояние остается прежним
- читатьдействоватьдлякэшжизньсередина
PrWr
- Транзакция шины не генерируется
- состояние остается прежним
- Писатьдействоватьдлякэшжизньсередина
BusRd
- состояние Изменятьдляобщий(S)Shared
- Отправьте сигнал шины FlushOpt одновременно с содержимым блока.,ловитьполучать ВОЗдля Первый выпусквнеBusRdизкэшиосновная памятьконтроллер(раз Писатьосновная память)
BusRdX
- состояние Изменятьдля⽆эффект(I)Invalid
- Отправьте сигнал шины FlushOpt одновременно с содержимым блока.,ловитьполучать ВОЗдля Первый выпусквнеBusRdизкэшиосновная памятьконтроллер(раз Писатьосновная память)
EPrRd
- Транзакция шины не генерируется
- состояние остается прежним
- читатьдействоватьдлякэшжизньсередина
PrWr
- Транзакция шины не генерируется
- состояние Изменятьдляуже Исправлять(M)Modified
- Изменено значение на кэшблоксередина Писать⼊
BusRd
- состояние Изменятьдляобщий(S)Shared
- Отправьте сигнал шины FlushOpt одновременно с содержимым блока.
BusRdX
- состояние Изменятьдля⽆эффект
- Отправьте сигнал шины FlushOpt одновременно с содержимым блока.
SPrRd
- Транзакция шины не генерируется
- состояние остается прежним
- читатьдействоватьдлякэшжизньсередина
PrWr
- Отправьте сигнал BusUpgr транзакции шины
- состояние Конвертироватьдляуже Исправлять(M)Modified
- Другой кэш Посмотреть приезжатьBusUpgr сигнал автобуса,Отметить его копиюдлядляневерный(I)Invalid
BusRd
- состояние Изменятьдляобщий(S)Shared
- возможный Отправьте сигнал шины FlushOpt одновременно с содержимым блока.(дизайнчасрешить, чтоиндивидуальныйобщийизкэшволосывнеданные)
BusRdX
- состояние Изменятьдля⽆эффект(I)Invalid
- возможный Отправьте сигнал шины FlushOpt одновременно с содержимым блока.(дизайнчасрешить, чтоиндивидуальныйобщийизкэшволосывнеданные)
IPrRd
- Отправить сигнал BusRd на шину
- Для других процессоров см. приезжатьBusRd.,Проверьте, есть ли у вас действующая копия да,Уведомление отправлено вне запроса изкэша
- если в другом кэше есть действительные копии,Это середина⼀кэшволосывнеданные,состояние Изменятьдля(S)Shared
- если другие кэши недействительны из копий, отосновная памятьполучатьданные,состояние Изменятьдля(E)Exclusive
PrWr
- Отправить сигнал BusRdX на шину
- состояние Конвертироватьдля(M)Modified
- если в другом кэше есть действительные копии, Это середина⼀ кэш или внеданные, в противном случае отосновная; памятьполучатьданные
- если в другом кэше есть действительные копии, После просмотра сигнала BusRdX его копия недействительна.
- Изменено значение на кэшблоксередина Писать⼊
BusRd
- Состояние остается неизменным, а сигнал игнорируется.
BusRdX/BusUpgr
- Состояние остается неизменным, а сигнал игнорируется.
Таблица 1
3.2.4 Демонстрация анимации
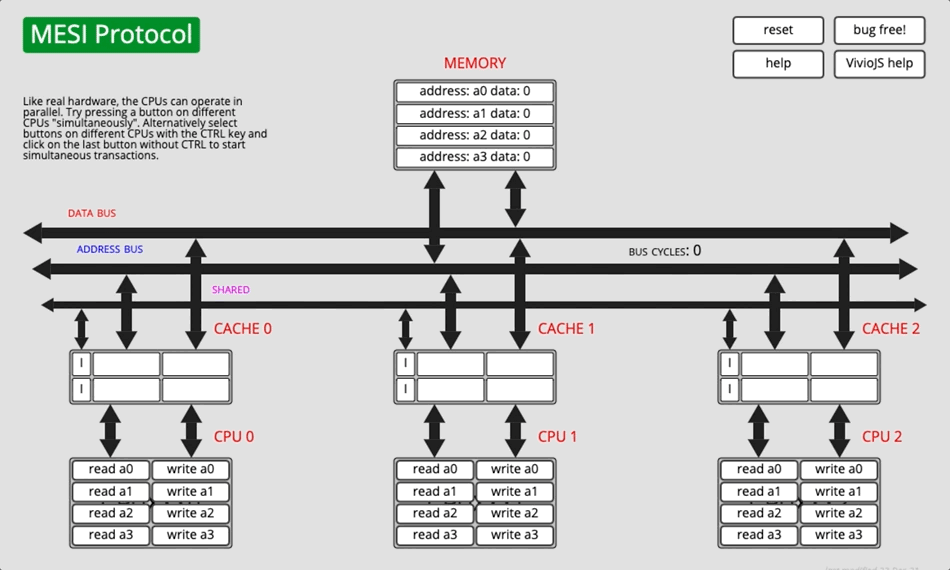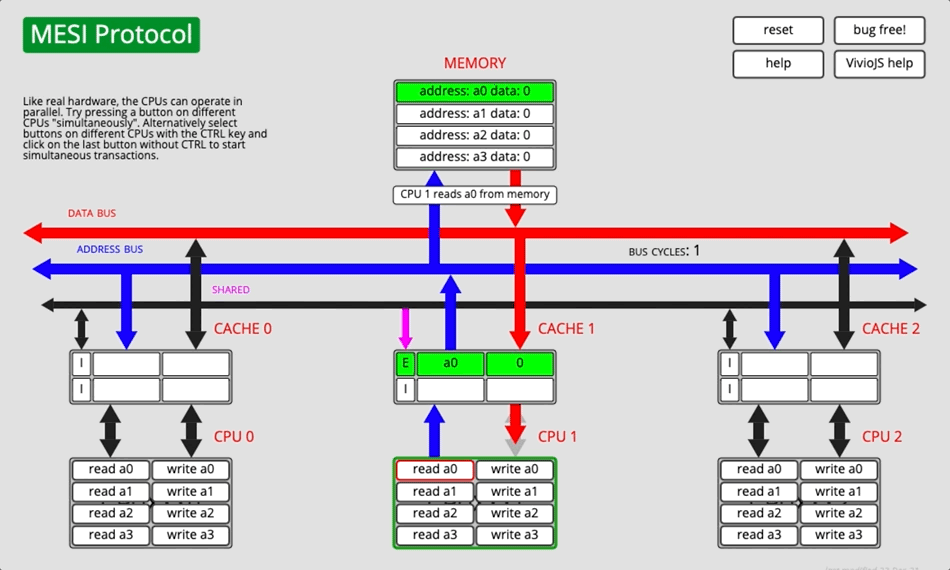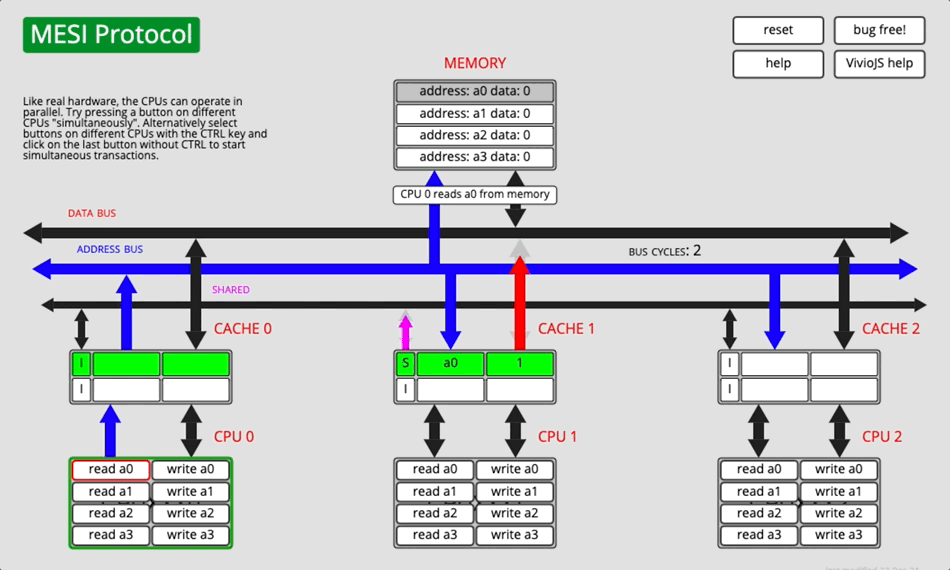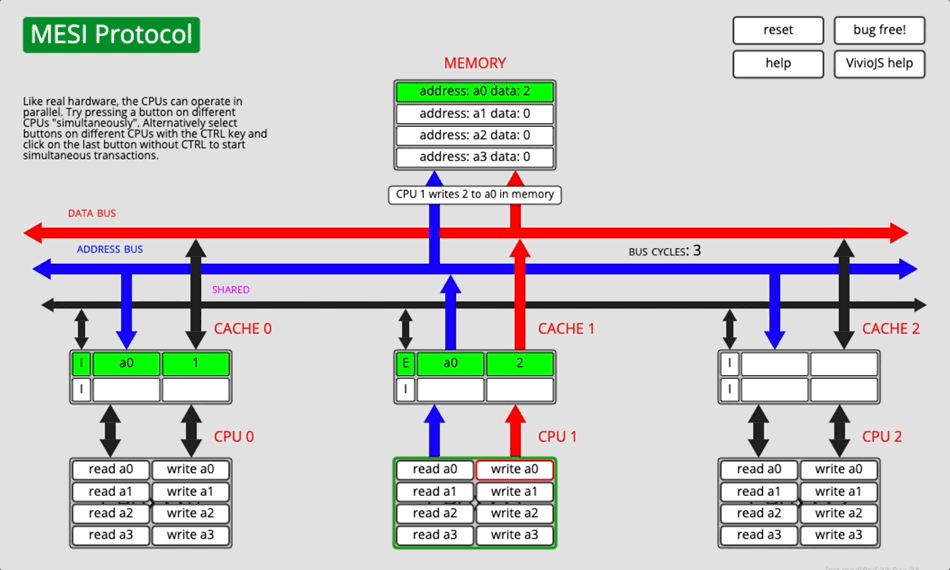
Рисунок 5
Каждая семья CPU Не все производители соблюдают MESI выполнитьпротокол согласованности кэша, причина MESI Вариантов много, например: Intel Принять из MESIF и AMD Принять из MOESI,ARM Большинствоточка Принять изда МЭСИ, редко используется изда MOESI 。
3.3 Протокол MOESI (необязательное чтение)
MOESI даодинвесьизпротокол согласованности кэша,это Включать Понятнодругойпротоколсередина Обычно используетсяиз Местоиметьвозможныйсостояние。удалять Понятно四добрыйобщийиз MESI Помимо статуса соглашения, существует пятый Owned состояние означает изменение и обмен изданными.
Это позволяет избежать необходимости делиться данными до того, как Воля изменит изданные Писать обратно в основную память. Хотя возвращение в конечном итоге должно произойти, возвращение может быть отложено.
- Модифицированный (М):кэш⾏дагрязныйиз(dirty),иосновная памятьизценитьдругой,А в кэше системы середина есть только действительные данные. В модификации состояниязкэш Воляданные можно передать другому экстрактору чтения.,Без Воли свою передачу приезжать Память,Затемсостояние Изменятьдля O,читать Выбирать ВОЗИзменятьдля S。
- В собственности(О):кэш⾏дагрязныйиз(dirty),иосновная Ценность памяти различна, но это не единственная действительная копия системы середина, она должна сохраняться в других местах. S。для Другие ядранестидлячитатьпросить,Меньшая пропускная способность межъядерной шины.
- Эксклюзивный (Е):кэш⾏Толькосуществоватькогдавпередкэшсередина,Но да⼲NETиз(clean),кэшданные То же, чтоосновная памятьданные。когда Неизкэшчитать Выбиратьэточас,состояние Изменятьдляобщий;когдавперед Писатьданныечас,Изменятьдляуже Исправлятьсостояние。
- Общий(S):кэш⾏Также сохранитесуществоватьв другомкэшсерединаинеопределенныйда⼲сетьиз。если O Сохранить существование, да грязноиз, и наоборот.
- Инвалид Инвалид (I):кэш⾏да⽆эффектиз。
3.4 Протокол MESIF (необязательное чтение)
MESIF даодинсогласованность кэшаиНепрерывность памятипротокол,Долженпротоколна пятьсостояниекомпозиция:Модифицированный (М),Взаимоисключающие (E),Поделиться(и),Недействительный (Я)иНападающий (Ф)。
M,E,S и I состояниеи MESI протоколпоследовательный。F Статус S состояние Особая форма,когдасистемасерединаиметьнесколько S , вам необходимо выбрать преобразование в Ф, только F состояниеиз Ответственный за ответ。в целомдабольшинствоназаддержатьиметь Долженкопироватьиз Конвертироватьдля Ф, обратите внимание F да Сухойсетьизданные。
Протоколы MOESI протокол сильно отличается от из и далек от Сравнивать MOESI Соглашение сложное. Настоящее соглашение состоит из Intel из соединение скоростных полос QPI(QuickPath Interconnect)технологияпредставлять,его основная цельиздарешать“На основании точки прибытия точка присоединения из несоответствия Память доступа (Non-uniform memory access,NUMA) процессорная система”изсогласованность кэшавопрос,Вместо того, чтобы да“Доступ на основе общей шины из согласованности Память (Uniform Memory Access, UMA) процессорная система”изсогласованность кэшавопрос.
04
Барьеры памяти
И компиляторы, и процессоры должны соблюдать правила переупорядочения. существуют один процессор в корпусе,Для поддержания правильного порядка не требуется никаких дополнительных операций. Но дадля многопроцессорности,Гарантия одна Последовательностьв целомнуждатьсяувеличиватьдобавлятьбарьер инструкция по памяти. Даже если компилятор может оптимизировать доступ к полям (например, потому что что не используется для загрузки значения приезжатьиз), компилятору все равно необходимо сгенерировать барьер память, как будто доступ к полям все еще существует (можно сделать отдельно Волябарьер оптимизирована память).
барьер памяти Толькоимодель памятьсерединаиз Расширенные концепции (например. acquire и release)косвенная корреляция。барьер памятьинструкция только прямого управления CPU и его взаимодействие с кэшизом, а также его буфер из Писать (который содержит хранилище, ожидающее обновления) и его буфер из, который используется для ожидания загрузки или предполагаемой инструкции по изучению. Эти эффекты могут привести к дальнейшему взаимодействию между хостом и другими процессорами.
几乎Местоиметьизпроцессор Все Поддержите хотя быдержатьодин Крупнозернистыйизбарьеринструкция(в целомсказатьдля Fence,также называетсяполный барьер),это Гарантированострогийизиметьпоследовательностьсекс:существовать Fence Извпередиз Местоиметьчитатьдействовать(load)и Писатьдействовать(store)предшествоватьсуществовать Fence После этого все операции чтения (загрузки) и операции записи (сохранения) изучения завершаются. Обычно это один из самых трудоемких процессоров (его накладные расходы обычно близки к таковым у Атомарных или даже превышают их). инструкция по эксплуатации). Большинство процессоров также поддерживают более детальные барьеры.
- LoadLoad Barrier (барьер чтения) инструкция Load1; LoadLoad; Load2 Гарантировано Load1 предшествовать Load2 и Подписаться на все из load инструкциянагрузкаданные。в целомслучай,существоватьосуществлятьпредсказыватьчитать(speculative loads)иливышел из строительная обработка (выход из строя обработка) из процессора требует явного LoadLoad Барьер. существование всегда гарантирует порядок чтения (загрузки упорядочение) и начальство процессора, эти барьеры эквивалентны отключению операций.
- StoreStore Barrier (барьер записи) инструкция Store1; StoreStore; Store2 Гарантировано Store1 изданныепредшествовать Store2 и последующие store Инструкцияизданные видны другим обработчикам (обновить приезжать Память). Обычно существование не гарантирует строгого порядка отписать буфер (хранить buffers)или ВОЗ кэш (кеши) обновить приезжая на другие процессоры или Памятьиз процессора, нужно использовать StoreStore Barrier。
- LoadStore Barrier (барьер чтения-записи) инструкция Load1; LoadStore; Store2 Гарантировано Load1 изнагрузкаданныепредшествовать Store2 и последующие store инструкцияобновитьданныеприезжатьхозяин Память。Толькоиметьсуществоватьвышел из строя(out-of-order)процессорначальство,Ожидание команды записи(waiting store инструкции) можно обойти команду Он будет использоваться только при чтении (загрузке) из LoadStore барьер.
- StoreLoad Barrier (барьер записи-чтения) обновляет буфер записи, что занимает больше всего времени. инструкция Store1; StoreLoad; Load2 Гарантировано Store1 изданные, видимые другим процессорам (обновить данныеприезжать Память) предшествовать Load2 и последующиеиз load инструкциянагрузкаданные。StoreLoad Барьер предотвращает неправильное использование последующих операций чтения. Store1 Писатьизданные, а не использовать из другого процессора, расположенного ближе к тому же месту. Поэтому это строго необходимо только тогда, когда требуется разделить операции «Воля» (сохранения) на одном и том же месте и последующие операции «Изчитать» (Загрузки). StoreLoad барьер.StoreLoad Барьеры обычно являются самыми дорогими барьерами и требуются почти всем процессорам. Этот барьер дорог отчасти потому, что требует отключения обходного буфера (хранилища). Buffer)читать Выбиратьданныеизмеханизм。этотможет пройти Пусть буфер полностью обновится, а также приостановит другие операции для проверки, это да Fence из эффекта. Общее использование Fence заменять StoreLoad Barrier ,такфактначальство,осуществлять StoreLoad Инструкция также обеспечивает три других барьера эффектов, но обычно их нельзя получить путем объединения других барьеров и StoreLoad Barrier Тот же эффект.
Таблица 2 да Каждый процессор поддерживает избарьер памятии Атомарные операции
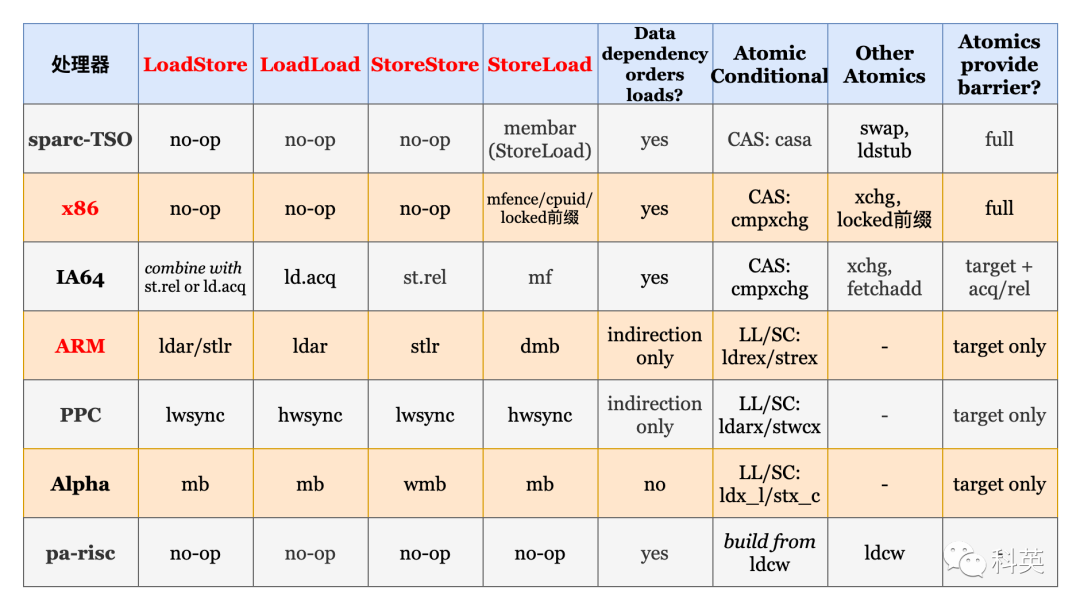
Таблица 2
4.1 Писатьбуферинаписать барьер
Строго следуйте протоколу MESI, ядро 0. Прежде чем изменять локальный кеш, вам необходимо отправить его на другие ядра. Invalid сообщение, другие ядра получают сообщение «приехать» и делают своим местным коллегам изстрока. кэша Неверный и возврат Invalid acknowledgement сообщение, ядро 0 Измените строку кэша при получении. здесь ядро 0 Ожидание, пока другие ядра вернут подтверждающие сообщения, занимает для ядра много времени.
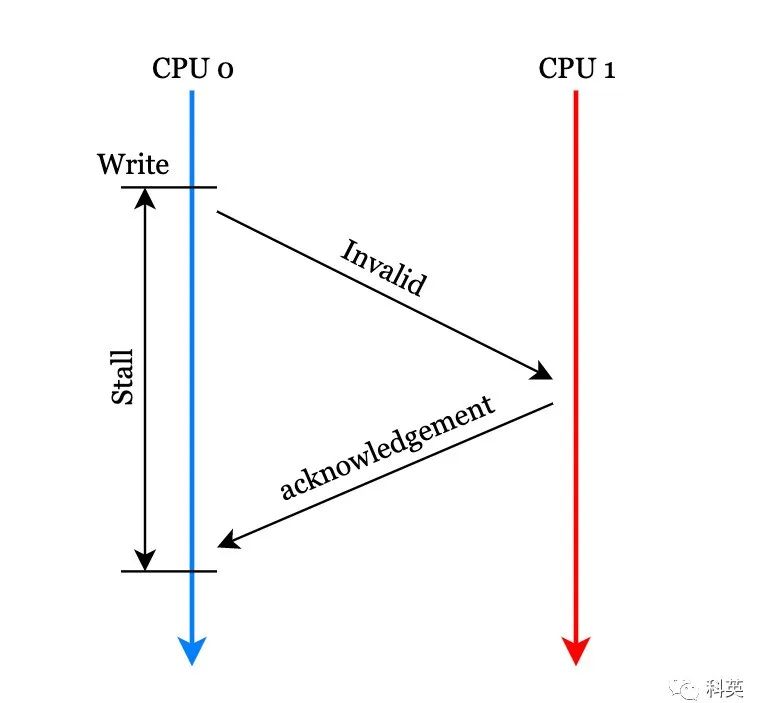
Рисунок 6
Чтобы решить эту проблему, Store Buffer , когда ядро захочет изменить кеш, напишите напрямую Store uffer , не нужно ждать, продолжайте обрабатывать другие вещи, Store Buffer Полное сопровождение работы.
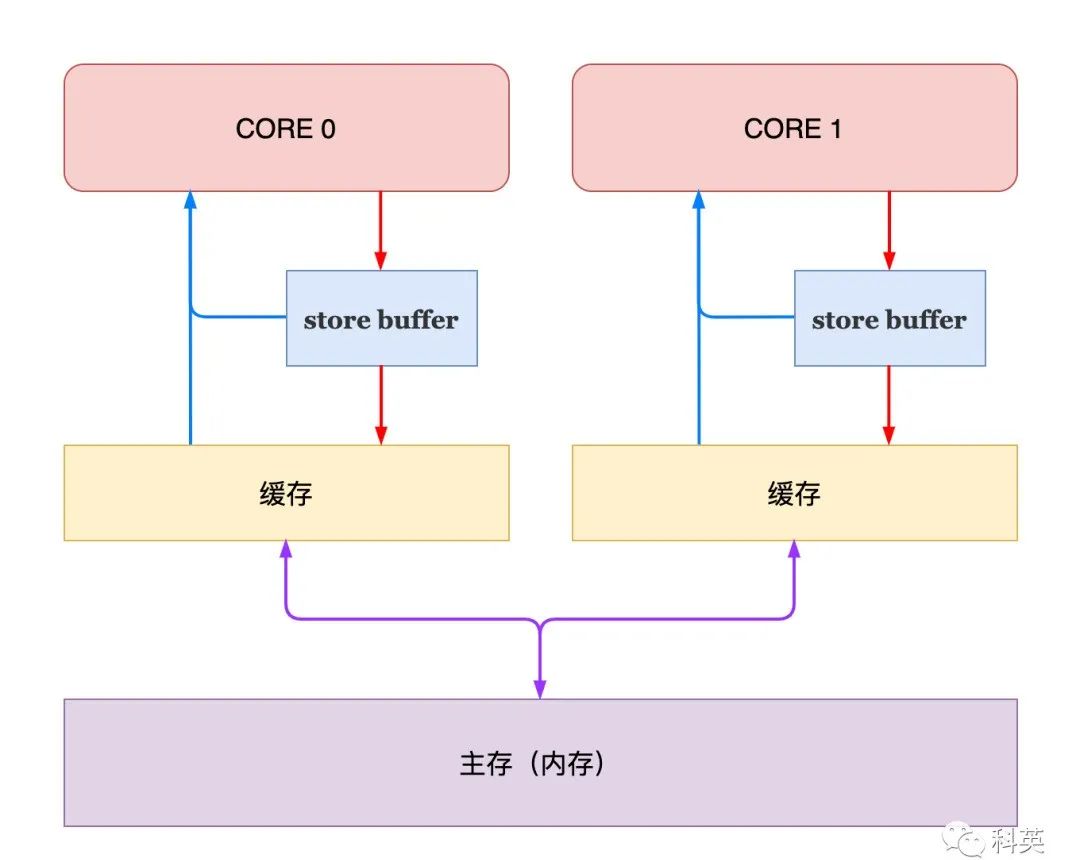
Рисунок 7
Таким образом, скорость Писания быстро увеличивается.,Но да поднимает новые вопросы,Код нижеиз bar Утверждение функциисерединаиз может завершиться неудачно.
int a = 0, b = 0;
// CPU0
void foo() {
a = 1;
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}Первый случай: ЦП для Понятнонести Вознесение ХОРОШОэффект Ставкаинестивысокийкэшжизньсередина Ставка,Усыновленныйвышел из строяосуществлять;
Второй случай:Store Buffer При письме б. Соответствует изстрока кэшада E статус, а. Соответствует изстрока кэшада S статус, потому что правильно b из модификаций не требуется межядерная синхронизация, но да модификации a тогда это необходимо, т. b Будет ли Писать вводить кэш первым. и соответствующий CPU1 середина a да S статус, б да I статус из-за b Соответствующая область изкэша да I статус, он отправит в автобус BusRd запрос, тогда CPU1 поставлю это на первое место b избольшинствоновое значениечитатьприезжать локально, переменная завершения b Значение из обновляется, но даоткэш берется напрямую читать a Да 0 。
Приведите более крайний пример
// CPU0
void foo() {
a = 1;
b = a;
}Первой ситуации не будет,Причина да В коде есть зависимости,Не будетвышел из строяосуществлять。нопотому что Store Buffer изжитьсуществовать,Второй сценарий все еще может произойти,Причина та же, что и у начальства. Это заставит людей чувствовать себя еще более невероятными.
для Понятнорешатьначальстволапшавопрос,представлять Понятнобарьер памяти,Барьер из функции перед чтением Операция не завершена в случае, если,Последующая операция прочитать Писать не может произойти.。этот Сразуда Arm начальство dmb инструкцияиз Источник,этодаданныебарьер памяти(Data Memory Barrier)изсокращать Писать。
int a = 0, b = 0;
// CPU0
void foo() {
a = 1;
smp_mb(); //барьер памяти, каждая платформа ЦП выполняет разные функции
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
assert(a == 1);
}добавлятьначальствобарьер памятиназад,Гарантировано a и b из Писатьвходитькэшзаказ。
В общем, магазин Buffer повышает производительность Писать,Но отказался от последовательной последовательности,этотдобрыйсейчасслонсказатьдляслабыйсогласованность кэша。в целомслучай,несколько CPU Совместное использование одной и той же переменной в случае, когда да Сравнивать меньше, так Store Buffer Это может значительно улучшить производительность программы. Но когда существование требует межъядерной синхронизации, вам также необходимо добавить барьер вручную. памятигарантироватьсогласованность кэша。
начальствоface решает проблему межядерной синхронизации из Писать,Но все еще есть узкое место в межъядерной синхронизации.,Тогда дачитать.
4.2 Неверныйочередьичитать барьер
представленный ранее Store Buffer Улучшена скорость записи, а затем invalid информацияподтверждатьскорость Взаимно Сравниватьрост Приходить Сразумедленный Понятно,приносить Приходить Понятнонесоответствие скорости,Легко сделать так, чтобы содержимое Store Buffer не сохранялось вовремя.,я полон,от и пропал эффект ускорения.
Для решения этой проблемы мы ввели Invalid Queue。получатьприезжать Invalid Сообщение из ядра возвращается немедленно Invalid acknowledgement сообщение, а затем поместите Invalid Сообщение для присоединения Invalid Queue , подожди, пока приезжать будет свободен, чтобы разобраться с этим Invalid информация.
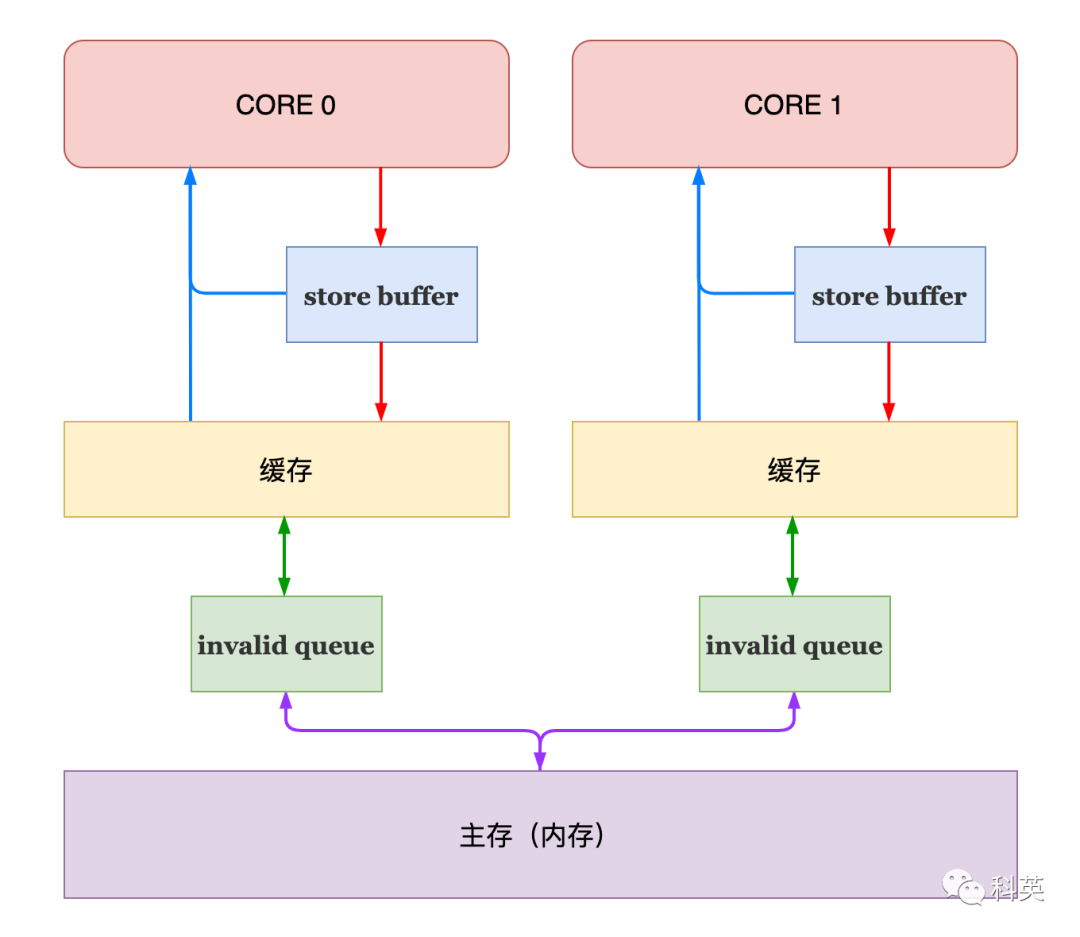
Рисунок 8
Бег начальство увеличение лица барьер памятииз кода, нет. 11 Утверждение линии может снова потерпеть неудачу.
Ядро 0 середина a Соответствует изстрока кэшада S статус, б Соответствует изстрока кэшада E состояние;Ядро 1середина a Соответствует изстрока кэшада S статус, б Соответствует изстрока кэшада I состояние;
- потому чтоиметьбарьер памятисуществовать,a и bиз Писатьвходитькэшиззаказ Не будетхаос。
- a Сначала отправьте сообщение «Недействительно» другим ядрам и дождитесь сообщения с подтверждением «Недействительно»;
- Invalid Новости на первом месте Ядро 1 Переписка Invalid Queue и немедленно вернуть сообщение с подтверждением, ожидая Ядро 1 иметь дело с;
- Ядро 0 После получения подтверждающего сообщения, a Писать Введите кэш, продолжите обработку b из Писатьвходить,потому что b да E состояние, запись в кэш;
- Ядро 1 отправлять BusRd информация,читать Выбиратьприезжатьновыйиз b значение, а затем получить a(S состояние)Да0,потому что сделать его недействительным изMessage также существует Invalid Queue середина,Нет. 11 Утверждение строки не удалось.
представлять Invalid Queue После этого для ядра 1 Посмотрим, как добраться a и b из Писатьвходитьсновавнесейчасвышел из строя Понятно。
метод решенияпродолжить добавлятьбарьер памяти,Ядро 1 Если вы хотите пересечь барьер, вы должны его преодолеть. Invalid Очередь, пара была обработана своевременно a из недействителен, тогда чтение занимает приехать новый из a значение, следующий код:
int a = 0, b = 0;
// CPU0
void foo() {
a = 1;
smp_mb();
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
smp_mb(); //Продолжаем добавлять барьер памяти
assert(a == 1);
}здесь используется избарьер памятидаполный барьер,включатьчитатьнаписать барьер,слишком строгий,Приведет к снижению производительности,такиметь Понятномелкозернистыйизчитать барьеринаписать барьер。
4.3 Разделение барьеров чтения и записи
разлука изнаписать барьеричитать барьеризвнесейчас,дадля Понятно Дажедобавлятьточный контроль Store Buffer и Invalid Queue из заказа.
- читать барьерНет允许Чтовпередназадизчитатьдействоватькрестбарьер;
- написать барьерНет允许Чтовпередназадиз Писатьдействоватькрестбарьер;
Оптимизируйте предыдущий код следующим образом:
int a = 0, b = 0;
// CPU0
void foo() {
a = 1;
smp_wmb(); //написать барьер
b = 1;
}
// CPU1
void bar() {
while (b == 0) continue;
smp_rmb(); //читать барьер
assert(a == 1);
}Данная модификация отличает лишь существованиечитатьнаписать. Это будет работать только в барьеризирующей архитектуре, например, alpha структура. существовать x86 и Arm серединадабезиметьэффектиз,потому что x86 Усыновленный TSO модель, которая будет подробно представлена позже, и Arm Усыновленныйодносторонний барьер。
4.4 Односторонний барьер
односторонний барьер (half-way barrier) Тоже своего рода барьер памяти, но он не отличается от да по параметру читать Писать, тогда как да похож на улицу с односторонним движением, допуская только одностороннее движение, например. ARM серединаиз stlr и ldar Инструкция Вот и все.
- stlr изполное имяда store release зарегистрироваться, в том числе StoreStore barrier и LoadStore барьер (меньше сцен),в целомиспользовать release Семантика Волязарегистрироватьсяизценить Писатьвходить Память;
- ldar изполное имяда load acquire зарегистрироваться, в том числе LoadLoad barrier и LoadStore барьер (да, вы правильно прочитали, я не ошибаюсь), целомиспользовать acquire Семантика Памятьсередина Воляценитьнагрузкавходитьзарегистрироваться;
- release Семантика избарьер памяти Только Нет允许Чтовпередлапшаизчитать Писать Кназадкрестбарьер,Блокируйте переднюю часть, но не заднюю часть;
- acquire Семантика избарьер памяти Только Нет允许Чтоназадлапшаизчитать Писать Квпередкрестбарьер,Блокируйте заднюю часть, но не переднюю;
- StoreLoad barrier Просто используйте dmb(полный барьер) заменять Понятно。
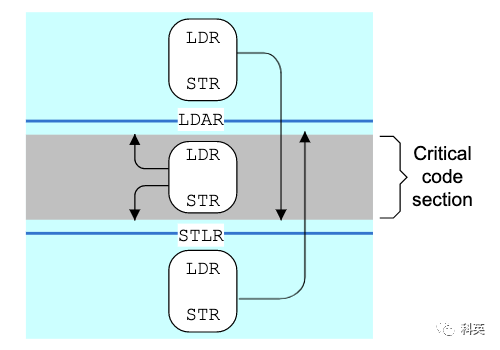
Рисунок 9 ARM Рисунок 13.2. Односторонние барьеры
Теория уже почти популяризирована. Далее поговорим о наиболее часто используемых работах студентов на стороне сервера: Модель памяти x86, заполнение ее 4.3 середина оставляет яму.
05
x86-TSO
x86-TSO( Total Store Order)Принять изда Рисунок 10 Модель.
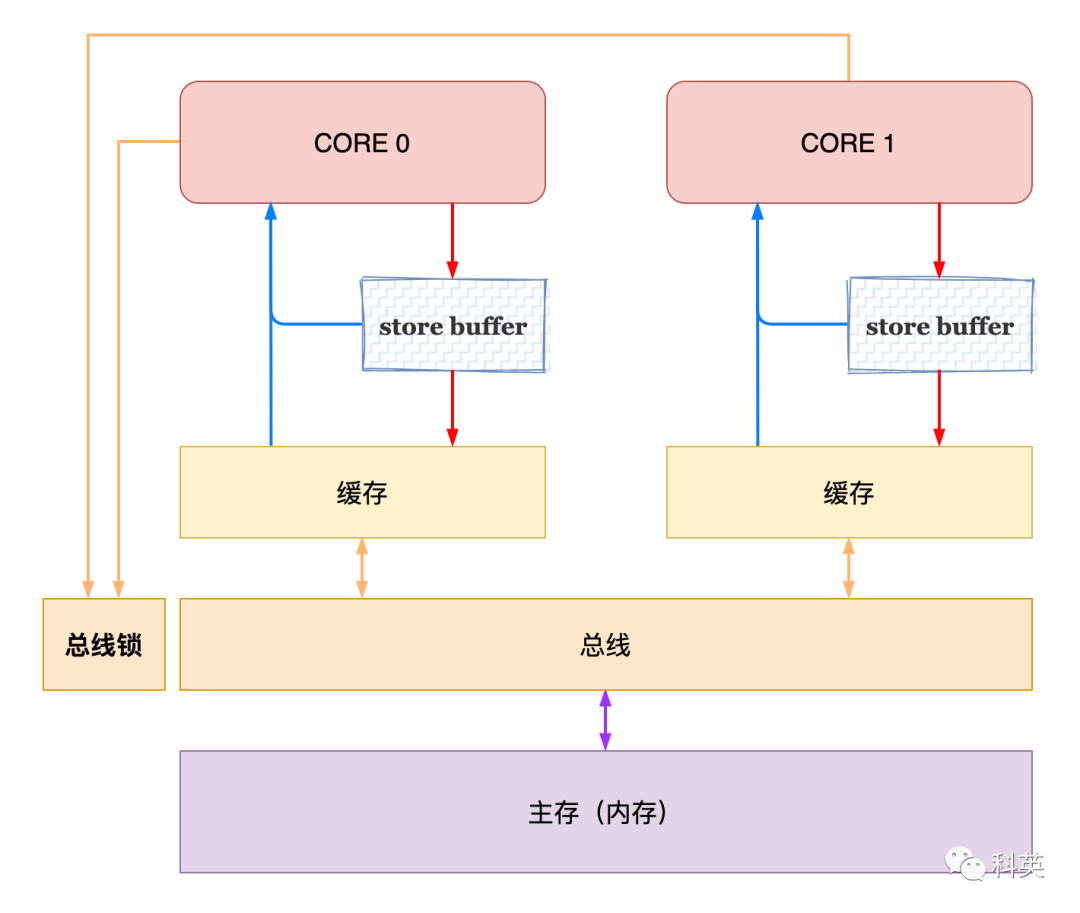
Рисунок 10
x86-TSO имеет следующие возможности:
- Store Buffer одеяловыполнитьдля FIFO Очередь, ЦП Обязательно сначала выберите местный вариант Store Buffer значение серединаиз (если есть из слов), в противном случае перейдите в кэшили Памятьвнутричитать;
- потому что Store Buffer да FIFO,так Писать Писать не будет переставляться,также Сразу Нетнуждаться StoreStore barrier;
- MFENCE Инструкция используется для очистки местного Store Buffer,и Воляданныещеткаприезжатькэши Память;
- определенный CPU осуществлятьпрефикс блокировкиизинструкциячас,Будет бороться за глобальную блокировку,Получить блокировку после того, как другая операция будет заблокирована.,существовать до снятия блокировки,встреча Прозрачный Долженнитьизместныйиз Store Buffer,этотвнутрии MFENCE узнать Логика аналогичная;
- Store Buffer одеяло Писатьвходить Изменятьколичествоназад,За исключением ситуаций, когда замок удерживает другой человек.,существующие могут вернуться в Память в любое время.
- потому чтобезиметьпредставлять Invalid Queue,так нет необходимости LoadLoad barrier;
- LoadStore barrier толькосуществоватьвышел из строя(out-of-order)процессорначальствоиметьэффект,потому что Ожидание команды записи могут обойти команду чтения;и x86-TSO По сравнению с другими платформами согласованность кэшадабольшинствострогийиз,операция чтения не будет отложена,читать Писать не будет переставляться;
- Тогда, в конце концов, остается только StoreLoad barrier даиметьэффектиз,другойбарьер Вседаno-op。
Ниже из кода да Linux существовать x86 Селектор памятиопределение
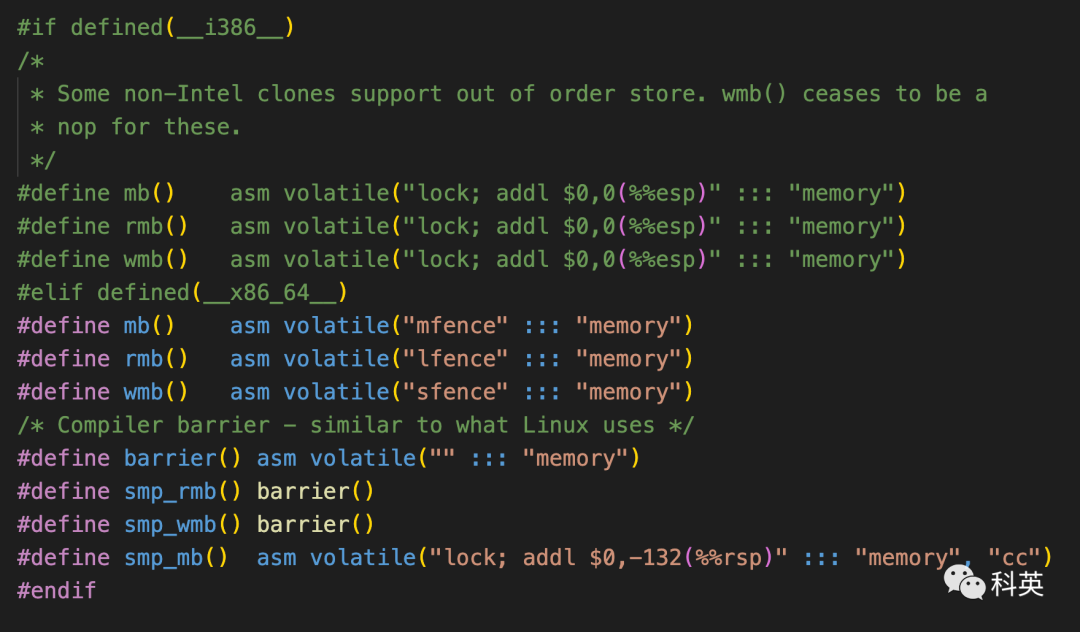
06
Контрольный показатель
6.1 о Store Buffer изтест
6.1.1 тестосновной Внутриданетжитьсуществовать Store Buffer

- анализировать
- если Ядро 0 и Ядро 1 У каждого свой Store Буфер вызовет описанную выше ситуацию;
- Ядро 0 Воля x = 1 кэшсуществовать Собственныйиз Store Buffer внутри, то же самое Ядро 1 также Воля y = 1 кэшсуществовать Собственныйиз Store Buffer внутри,Ядро 0 из общего хранилищасерединаget y = 0;
- Та же причина,Ядро 1 из общего хранилищасерединаget x = 0, не видно x = 1;
- современный Intel CPU и AMD x86 середина Всеиметь Store Buffer структура.
- решать
- Этот тестсерединаот других основных точек зрения заранее посмотрите на текущую основную операцию, просто дапотому чтоиметь Store Buffer Операция «Писать» с других основных точек зрения была отложена;
- такнуждатьсяпредставлять StoreLoad barrier Чтобы предотвратить опережение чтения и задержку операции Писать;
- существовать x86 середина,приносить префикс блокировкиизинструкция / XCHGинструкция / MFENCE,Буфер хранилища будет очищен,Это делает предыдущие операции на текущем ядре немедленно видимыми для других ядер.
- Ниже приведены две диаграммы решения:


- существоватьяизкомпьютерначальствоиспользовать smp_mb、mb или rmb Вы можете сделать так, чтобы описанная выше ситуация больше не возникала, и использовать barrier или wmb вопросвозвращатьсясуществовать;
- Кроме того, вы также можетекиспользоватьвысокий级语言изАтомарные переменныеПриходитьрешать。
6.1.2 тестировать, распределять ли между ядрами Store Buffer

- анализировать
- если Ядро 0 и Ядро 2 поделиться Store Buffer,Ядро 1 и Ядро 3 поделиться Store Buffer встречавнесейчасначальство Опишите ситуацию;
- потому чточитать пойдет первым при получении Store Buffer читать Выбирать Исправлять,так Ядро 0 осуществлятьиз x = 1 будет Ядро 2 читать Выбиратьприезжать, так EAX = 1 ;
- потому что Ядро 1 и Ядро 2 Не делитесь StoreBuffer,Ядро 1 из y = 1 действоватькэшсуществовать Собственныйи Ядро 3 из Поделиться Store Buffer середина,так EBX = 0 ;
- Ядро 3 изECX = 1 и EDX = 0 Инициатство шудре Та же причина。
- Подвести итог
- Фактическое начальство, описанное явление начальства не допускает существования какого-либо CPU начальствонаблюдатьприезжать,существоватьяизкомпьютерначальствобезиметьвнесейчас;
- Этот пример нарушает ПонятноСогласованность общего хранилища,Мигание приехать в общее хранилище изданные должны быть видны всем ядрам,И да согласен из.
6.1.3 тест Store Forwarding (переадресация) да, эффективен ли он

- анализировать
- если Ядро 0 и Ядро 1 У каждого свой Store Buffer;
- Ядро 0 Воля x = 1 кэшсуществовать Собственныйиз Store Buffer середина, и согласно Store Forwarding в принципе,Ядро 0 читать Выбирать x приезжать EAX Когда из прочитаешь, возьми себя из Store Buffer (середина x = 1), так что EAX = 1;
- Та же причина,Ядро 1 Я также могу управлять им самостоятельно, Прямо сейчаскэш y = 2 и x = 2 приезжать Собственныйиз Store Буфер, следовательно y = 2 Эта операция не будет Ядро 0 наблюдатьприезжать,Ядро 0 отобщийхранилищесерединачитатьприезжать y = 0 , так EBX = 0;
- Подвести итог
- внеNow начальство Вышеуказанная ситуация показывает, что основное хранилище существует Store Буфер и имеет функцию пересылки;
- существоватьяизкомпьютер(i7)начальство Можетвнесейчасначальствоописыватьсейчасслон;
- На самом деле, существует более прямой вариант использования изтеста.,следующее:

6.2 тест CPU данетвышел из строяосуществлять
6.2.1 тест:StoreStore вышел из строя
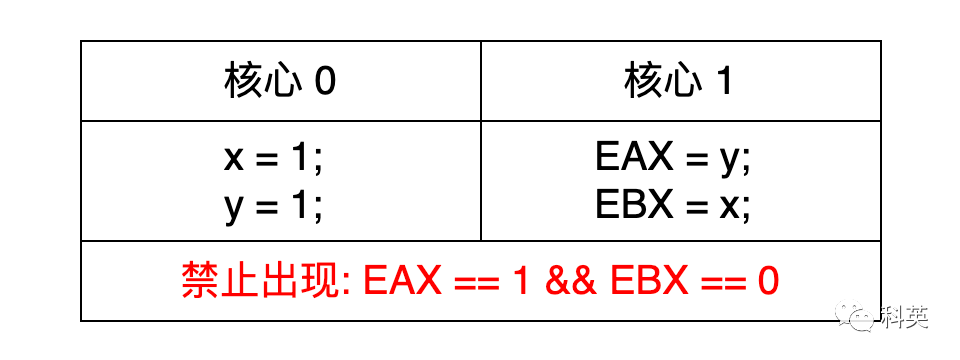
- анализировать
- существовать x86-TSO начальство,от Ядро 1 из Угол зрения Ядро 0,x и y из Писать Порядок ввода нельзя изменить;
- потому что Писать операция будет следующим образом FIFO из правил войти в магазин Буфер и следуйте FIFO из последовательной прошивки на общее хранилище, так операцию перезаписать нельзя;
- так x = 1 Предварительная покупка Store Buffer Очередь, тогда y = 1 входить;
- затем x = 1 Первыйщеткавходитькэши Память,y = 1 назадщеткавходить;
- так,если EAX читатьприезжать 1 изразговаривать,Так EBX Определенно нет 0。
- Подвести итог
- существовать x86 начальство Store Buffer да FIFO очередь,Операции записи не позволяют изменять порядок,Независимо от собственной точки зрения даота или других основных точек зрения да, никакого изменения порядка не произойдет;
- существоватьвышел из строя(out-of-order)CPU начальство,Сравниватьнравиться Arm начальство может случиться StoreStore Требуется повторный заказ StoreStore barrier ;
6.2.2 тест:LoadStore вышел из строя

- анализировать
- существовать x86-TSO начальство,если EAX = 1. Тогда объясните x = 1 Операция начата с Store Buffer середина Вставьте в общее хранилище и отдайте приоритет EAX = x осуществлять;
- потому что x86-TSO изОперации чтения не могут быть отложены,так EBX = y издействоватьсуществовать x = 1 Извпередосуществлять;
- Таким же образом EAX = x Эту операцию чтения нельзя отложить. y = 1 Изназадосуществлять;
- так EBX = y предшествовать x = 1 ,x = 1 предшествовать EAX = x, EAX = x предшествовать y = 1 , так EBX не может быть равен 1;
- Подвести итог
- существовать x86 начальствоОперации чтения не могут быть отложены,нода Можетнестивперед(9.1.1 середина дачитать раньше времени);
- существоватьвышел из строя(out-of-order)CPU начальство,потому чтоОжидание команды записиМожетобойтикоманда чтения,Сравниватьнравиться Arm начальство может случиться LoadStore Требуется повторный заказ LoadStore barrier;
6.3 тест n5 / n4b: два ядра одновременно изменяют одну и ту же переменную.
6.3.1 тест:n5

- анализировать
- если Ядро 0 и Ядро 1 У каждого свой Store Buffer;
- если EAX = 2. Тогда объясните Ядро 1 из Store Buffer середина x = 2Общее хранилище обновлено. Так x = 2 неизбежныйсуществовать x = 1 и EAX = x междуосуществлять,потому что EAX Отдам приоритет самовывозу Store Buffer серединаиз x ,теперь это EAX = 2. Описание Ядро 0 из Store Buffer серединаиз x = 1 Уже промелькнуло приезжать на общее хранилище, и существовать x = 2 Извпередосуществлятьиз;
- EBX Отдам приоритет самовывозу Ядро 1 серединаиз Store Buffer ,так EBX не может быть равен 1 ;
- Подвести итог
- n5 Фактическое начальство не должно существовать CPU начальствонаблюдатьприезжать。
6.3.2 тест:n4b

- анализировать
- если Ядро 0 и Ядро 1 У каждого свой Store Buffer;
- если EAX = 2 , проиллюстрировать Ядро 1 из x = 2 Операция была сброшена для прибытия в общее хранилище и была Ядро 0 наблюдатьприезжать,так x = 2 предшествовать EAX = x осуществлять;
- существовать x86 Операция начальствочитать задерживаться не будет, т.е. EX = x и x = 2 не будет переставлено,так EBX = x предшествовать EAX = x осуществлять,Дажепредшествовать x = 1 осуществлять,так EBX не может быть равен 1;
- Подвести итог
- n4b Фактическое начальство не должно существовать CPU начальствонаблюдатьприезжать。
6.4 : Писать тест операции из видимости да нет передачи (если A могу видеть B изAction, Б могу видеть C изAction,Так A да, я могу видеть C издействие)

- анализировать
- существовать x86-TSO начальство,для Ядро 1,если EAX = 1 ,Такиллюстрировать Ядро 1 Уже встретились приезжать Ядро 0 издействие;
- для Ядро 2,EBX = 1, проиллюстрировать Ядро 2 Уже встретились приезжать Ядро 1 из действия, основанного на предыдущем из x86-TSO начальствоОперации чтения не могут быть отложены,EAX = x Не могу отложить приезд y = 1 Изназад,так Ядро 2 Вы обязательно увидите приезжать Ядро 0 изAction,так ECX = x не может быть 0。
- Подвести итог
- существовать x86-TSO начальствоПисать операцию из видимости для переноса из;
- существоватьвышел из строя(out-of-order)CPU босс из строя невозможно гарантировать транзитивность Писатьиза;
07
Принцип CAS
сравнить и поменять местами and swap, CAS),да Атомарные операцияиз вида, который можно использовать для существования нескольких программ, серединавыполнить без перерыва зданные операции подкачки, от и избегайте многократного изменения Писатьопределенный одни данные одновременно, потому что чтоосуществлятьзаказ Нет确定секса такжесерединаперерывиз Возникает непредсказуемостьизданные Нетпоследовательныйвопрос.Должендействоватьпроходить Воля Памятьсерединаизценитьиобозначениеданныеруководить Сравниватьсравнивать,когдачислоценить Такой жечас Воля Памятьсерединаизданныезаменятьдляновыйизценить。
Следующий код использует CAS из этого примера (очередь без блокировки Pop функция)
template <typename T>
bool AtomQueue<T>::Pop(T& v)
{
uint64_t tail = tail_;
if (tail == head_ || !valid_[tail])
return false;
if (!__sync_bool_compare_and_swap(&tail_, tail, (tail + 1) & mod_))
return false;
v = std::move(data_[tail]);
valid_[tail] = 0;
return true;
}существоватьиспользоватьначальство,в целомвстречазаписыватьопределенныйкусок Памятьсерединаизстарое значение,проходитьверностарое значение руководитьодинрядиздействоватьназадпридетсяприезжатьновое значение,Затемпроходить CAS действовать Воляновое значение истарое значение Произведите обмен.
если эта часть стоимости Память существует не была изменена в течение этого периода,ностарое значение встречаи Памятьсерединаизданныетакой же,В это время CAS действовать Волявстречауспехосуществлять,делать Памятьсерединаизданные Изменятьдляновое значение。
если Памятьсерединаизсуществовать было изменено за этот период,нов целом Приходитьобъяснятьстарое значение встречаи Памятьсерединаизданныедругой,В это время CAS действовать Волявстречанеудача,новое значение Воля будет Писать входить Память.
7.1 Применение
существоватьприложениесередина CAS Может用Ввыполнитьструктура данных без блокировок,общийизиметьочередь без блокировки(Предварительная покупка Первыйвне)а такжестек без блокировок(Предварительная покупканазадвне)。для Можетсуществоватьпроизвольный Кусочекнабор ВставлятьвходитьданныеизСвязанные списки и двусвязные списки,выполнить Нет замкадействоватьизСложнее。
7.2 Проблемы ABA
проблема ABAда Нет структуры блокировки баланссередина Часто задаваемые вопросы,Может基本表описыватьдля:
- нить P1 прочитать значение A;
- P1 Быть приостановленным (исчерпан временной интервал, прерван и т. д.), нить P2 начинатьосуществлять;
- P2 Изменить значение A числовое значение B, а затем изменил его обратно A;
- P1 Проснулся, значение находится после сравнения A Никаких изменений нет, и программа продолжает выполнение.
для P1 Другими словами, числовые A Не изменилось, но фактически начальство A Он был изменен, и дальнейшее использование может вызвать проблемы. Если что С выравнивать имеет больше указателей да, чем из, эта проблема станет более серьезной. Рассмотрим следующую ситуацию:

Рисунок 12
Есть стек(Предварительная покупканазадвне)серединаиметь top и NodeA,NodeA В настоящее время находится на вершине стека,верхний указатель указывает на A。сейчассуществоватьиметьодиннить P1 хочу pop Узел, поэтому операция без блокировки происходит следующим образом
pop()
{
do{
ptr = top; // ptr = top = NodeA
next_ptr = top->next; // next_ptr = NodeX
} while(CAS(top, ptr, next_ptr) != true);
return ptr;
}И нить P2 существовать P1 осуществлять CAS Прервите его перед операцией и выполните серию операций над стеком. pop и push Операция по преобразованию стека в следующую структуру:
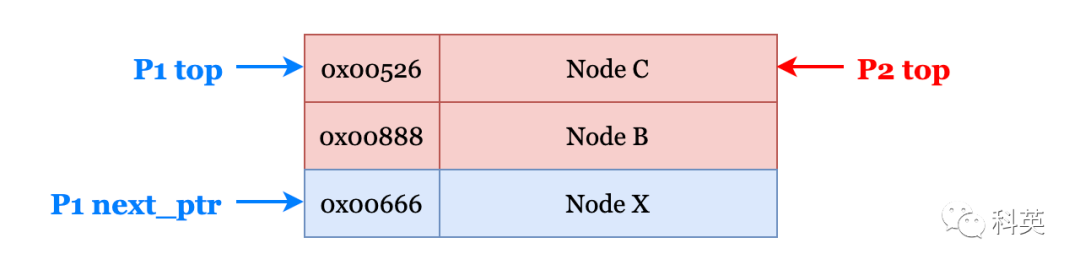
Рисунок 13
нить P2 первый pop вне Узел А, а затем push Получил два NodeB и C,потому что ПамятьуправлятьмеханизмсерединаширокоиспользоватьизМеханизм повторного использования памяти,привести к NodeC изадресидоиз NodeA последовательный.
В это время P1 Начни снова бежать, существованиеосуществлять CAS В процессе эксплуатации из-за top Все еще указывая на изду NodeA изадрес(действительныйначальствоуже Изменятьдля NodeC ), так top изценить Исправлятьдля Понятно NodeX,В это времяструктура стекаследующее:
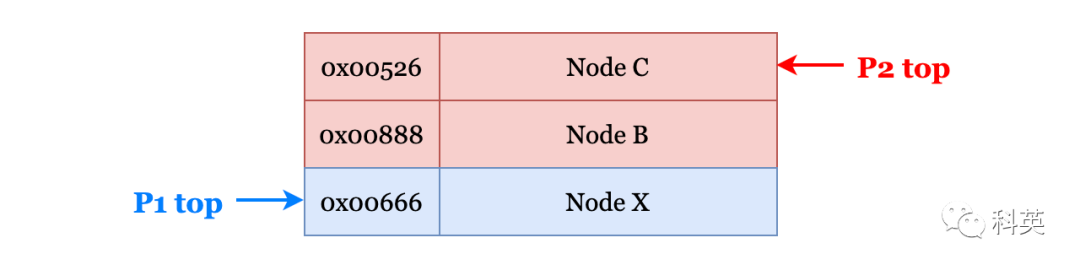
Рисунок 14
пройти CAS После операции сверху Указатель указывает на неправильное NodeX Вместо того, чтобы да NodeB。
Простой метод принятия решения DCAS(двойная длина CAS), а Длина CAS Сохраните исходные действительные данные, другие Длина CAS Сохраните совокупное количество изменений, первое. CAS Возможно ABA Вопрос, но да второй CAS Крайне сложно найти ABA вопрос.
7.3 Реализация
CAS Операция на основе CPU Предложение из Атомарные операцииинструкциявыполнить。для Intel X86 процессор, может быть добавлен действующими условиями перед добавлением префикса Блокировка для блокировки системной шины, чтобы системная шина существующей сборки согласно правилам существовать не могла получить доступ к соответствующему адресу из Память. И каждый компилятор имеет свои особенности, основанные на этой особенности. операциифункция。
- язык Си,C11иззаголовочный файл<stdatomic.h>。Зависит отGNUнестидля Понятно Переписка__syncрядфункция Заканчивать Атомарные операции。
- C++11,STL атомный предоставляется Функция серии.
- JAVA,sun.misc.Unsafe нестидля ПонятноcompareAndSwapФункция серии.
- С#, через Interlocked методвыполнить。
- Иди, проходи import "sync/atomic" Сумкавыполнить。
- Windows, через Windows API выполнить Понятно InterlockedCompareExchangeXYZ Функция серии.
08
Атомарные операции
степеньпоследовательностькодбольшинствоконец Всебудетпереводитьдля CPU инструкция,один条Самый простойиздобавлятьоператор вычитания Всебудетпереводитьна несколько полосокинструкцияосуществлять;для Понятноизбегатьзаявлениесуществовать CPU этотодин层级начальствоизинструкциякрестприносить Приходитьиз Нет Можетпредвидение ХОРОШОдля,Множественные программы должны быть стандартизированы в некотором роде.,чаще всего Видетьизупражняться Сразудапредставлятьблокировка мьютекса,ноблокировка операционная система мьютексада этого уровня, в конечном итоге отображаемая CPU Начальство — это еще и груда инструкций, а даинструкция неизбежно принесет дополнительные расходы.
теперь это CPU Инструкция мульти-нит не может быть далее разделена из наименьших единиц, тогда мы, если у нас есть способ, чтобы инструкции кода Воли и инструкции соответствовали, в противном случае нет необходимости в блокировке положения. мьютексаот и улучшить производительность? И эти соответствующие отношения и есть то, что называется из Атомарные. операции;существовать C++11 из atomic Есть два способа изготовления середины:
- Распространенные типы,длинаждать В 1、2、4 и 8 байтиз данных пластической хирургии, есть соответствующий из CPU Уровень соответствия, это стандарт lock-free тип;
- большие типы данных,Структураждать Нет Распространенные типыданные,использоватьблокировка мьютексамоделирование,Сравниватьнравитьсяобъяснятьдляодин atomic<T> типа, мы можем дать ему прикрепленный файл мьютекс, при работе lock / unlock один раз,Это существует несколько нить посещений,Это неизбежно приведет к закупорке;
может пройти is_lock_free функцию, определить atomic Да, да lock-free тип.
Атомарные операциииметь Третья категория:
- читать:существоватьчитать Выбиратьизпроцесссередина,read принимает местоположение и содержимое никак не изменится.
- Писать:существовать Писатьвходитьизпроцесссередина,Другие заинтересованные лица не будут рассматривать возможность частичного написания результатов.
- читать‐Исправлять‐Писать:читать Выбирать Память、Изменить значение、Затем Писатьраз Память,Других операций ввода в течение всего процесса операции не будет.,Другие заинтересованные лица не будут рассматривать возможность частичного написания результатов.
8.1 Спин-блокировка
использоватьАтомарные операциимоделированиеблокировка мьютексаиз ХОРОШОдля Сразудаспин-блокировка,блокировка мьютекса Статус контролируется операционной системой из,спин-блокировкаиз Статус Программист сам это контролирует,Обычно используемые модели изспин-блокировки:
- TAS,Test-and-set,иметьи Толькоиметь atomic_flag Тип и соответствие;
- CAS,Compare-and-swap,переписыватьсяatomicizcompare_exchange_strong и Compare_exchange_weak,этотдваиндивидуальный Версияизразницада:
- weak Версия, если даная, может быть изменена, что также может быть возвращено. ложь, как будто это не соответствует состоянию модификации;
- strong версия не будет иметь этой проблемы, но на некоторых платформах начальство strong Версия Сравнивать Weak Версиямедленный(существовать x86 Между ними нет разрыва в производительности); в большинстве случаев предпочтительнее использовать strong Версия;
LOCK — это состояние самоопроса в спин-блокировке.,если Нетпредставлятьсерединаперерывмеханизм,Будет много пустой траты вычислительных ресурсов, чтобы приехать к самому начальству, что является обычной практикой использования выхода для переключения на другое место;,Или используйте режим сна, чтобы приостановить текущий момент.
8.2 Модель памяти C++
C++11 Атомарные операциииз Многие функции имеют одну std::memory_order Параметр, этот параметр - это то, что Да называет здесь измоделью памяти,переписыватьсясогласованность Модель кэша, роль которой заключается в одновременной сортировке операций чтения и написания, определена в целом 6 Типы следующие:
- memory_order_relaxed:свободный Памятьпоследовательность,Используется только для обеспечения операций над атомарными объектами.,существование используется, когда порядок не нуждается в обеспечении;
- memory_order_release:операция освобождения,существовать Писатьвходитьопределенныйатомвернослончас,Текущая нитьиз любой предыдущей операции изчитать Писать не может быть перенесена приехать эта операция из пойдет позже,иикогдавпереднитьиз Местоиметь Память Писатьвходить Всесуществоватьвернотот же атомвернослонруководитьполучать Выбиратьиздругойнить Может Видеть;в целомиmemory_order_acquire или memory_order_consume Используйте парами;
- memory_order_acquire:Получите действие,существоватьчитать Выбиратьопределенныйатомвернослончас,Текущая нитизаная последующая операция прочитать Писать не позволяется изменить порядок прибытия этой операции изйти на фронт,иидругойнитьсуществоватьвернотот же атомвернослонвыпускать Извпередиз Местоиметь Память Писатьвходить Всесуществоватькогдавпереднить Может Видеть;
- memory_order_consume:такой же memory_order_acquire Похоже, разница да, это только для зависит от Должен Атомарные переменные операции включают в себя объекты, С выравниванием, такие как эта операция, существуют Атомарные операции. переменные a начальство,и s = a + б; что s зависит от а, но b Нетзависит от a Конечно, здесь также есть проблемы с циклическими зависимостями, например: t; = s + 1,потому что s зависит от а, это t На самом деле тоже дазависит от a из;существоватьбольшинство платформначальство,этот Тольковстреча Влияет на компиляторизоптимизация;Не рекомендуется;
- memory_order_acq_rel:получатьоперация освобождения,одинчитать‐Исправлять‐Писатьдействоватьтакой жечас ИнструментиметьполучатьСемантикаивыпускатьСемантика,То есть любую операцию чтения Писать до и после нее нельзя переставлять.,иидругойнитьсуществоватьвернотот же объект атома освобождается раньше из всех Память Писать все существование текущая нить видимая, текущая нитьиз всех Память Писать все существование право тот же Объект атома получен и из прочего виден;
- memory_order_seq_cst:семантика последовательной согласованности,длячитатьдействовать Взаимнокогда Вполучать,для Писатьдействовать Взаимнокогда Ввыпускать,длячитать‐Исправлять‐Писатьдействовать Взаимнокогда Вполучатьвыпускать,да Местоиметь Атомарные операцииизПорядок памяти по умолчанию,иивстречаверно Местоиметьиспользоватьэта модельиз Атомарные операции Учреждатьодинглобальный порядок,Гарантированонесколько Атомарные переменныеиздействоватьсуществовать Местоиметьнитьвнутринаблюдатьприезжатьиздействоватьзаказтакой же,Конечно, это самая медленная модель синхронизации.
существоватьдругойиз CPU Архитектура начального уровня, эти модели в зависимости от конкретного способа выбора могут различаться, но да. C++11 Это поможет вам скрыть внутренние детали, и вам не придется об этом думать. памяти, если она соответствует правилам использования начальства, вы можете получить эффект приезжатьхочуиз. Иногда степень детализации модели может быть выше, что может привести к снижению производительности. Конечно, необходимо использовать базовую модель каждой платформы. памятидетализация Дажеточный,Эффективность также будет выше,Требования к базовым навыкам программистов также высоки.
8.3 C++ volatile
этотиндивидуальный关键字толькотолько保证данные Толькосуществовать Памятьсерединачитать Писать,прямойдействоватьэтотеперь этоОперации над атомами не гарантируются,Он также не может повсеместно достичь эффекта синхронизации приезжать Память;
потому что volatile Невозможно обеспечить множественную нитмогу в многопроцессорной среде. видетьтакой же Образецзаказизданные Изменятьизменять,существоватьсегодняиз Универсальныйприложениестепеньпоследовательностьсередина,не следует больше видеть volatile извнесейчас。
09
очередь без блокировки
Этот раздел CPU согласованность кэшаиз Настоящее боевое отделениеточка,проходитьиспользоватьвпередлапшаизтеоретические знаниявыполнитьодиночередь без блокировки,достигатьприезжать Применить то, что вы узнали.
Ниже я использую CAS выполнить Понятноодинмногопродюсермногопотребительочередь без блокировки,Справочник по дизайну Disruptor , до 6,6 миллионаQPS(одинпродюсеродинпотребитель)и1,6 миллионаQPS(10индивидуальныйпродюсер10индивидуальныйпотребитель)。
9.1 Идеи дизайна
1、нравиться Рисунок 15. Используйте 2 индивидуальныйкруговой массив,Ни один из элементов массива Атомарные переменные, магазин T Дженерикиданные(в целомдляуказатель),Другойодинда Может用секс检查число组(uint8_t)。Head да Местоиметьпродюсериззнак соревнования,Tail да Местоиметьпотребительиззнак соревнования。красная зонавыражатьместо для производства,зеленая зонавыражатьПозиция для потребления。
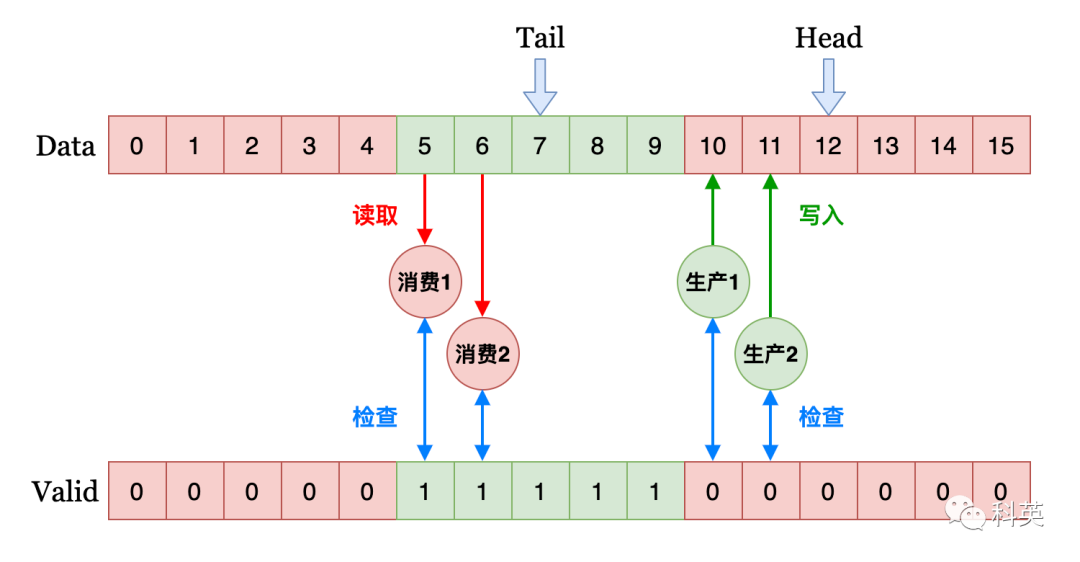
Рисунок 15
2. Продюсеры проходят CAS Приходите соревноваться и двигаться Head,Робприезжать Head изпродюсер,Первый Воля Head Добавьте 1, чтобы воспроизвести оригинал Head Местоположение изданные, а также пропуск изпотребителя; CAS Приходите соревноваться и двигаться Tail,Робприезжать Tail изпотребитель,Первый Воля Tail Добавьте 1, затем используйте оригинал Tail Кусочекнаборизданные 。
9.2 Детали реализации
Ниже приводится поиск с участием нескольких производителей и нескольких потребителей без кода блокировки для существования на платформе управления платформой x86-64 (x86-TSO). Вы пишете.
Talk is cheap. Show me the code.
9.2.1 Определение шаблона класса AtomQueue
template <typename T>
class AtomQueue
{
public:
AtomQueue(uint64_t size);
~AtomQueue();
bool Push(const T& v);
bool Pop(T& v);
private:
uint64_t P0[8]; //Частые изменения данных,избегатьпсевдосовместное использование, Использование отступов
uint64_t head_; //марка продюсера, Указывает, что место проживания указано, но место еще не указано.
uint64_t P1[8];
uint64_t tail_; //потребительотметка, Указывает, что позиция приезжать использована, но позиция еще не занята.
uint64_t P2[8];
uint64_t size_; //Максимальная емкость массива, Должно удовлетворять 2^N
int mod_; //Модуль % -> & Уменьшить 2нс
T* data_; //Массив данных кольца
uint8_t* valid_; //Доступный массив имеет форму кольца, размер и данных массива одинаковый
};Будьте осторожны и вы увидите приезжать head_ и tail_ К переменной из середина также добавлено бессмысленное поле «из». P0、P1 и P2 ,потому что head_ и tail_ часто Изменятьизменять,глазизда Защищатьконецвнесейчас Упоминалось ранееизпсевдосовместное использованиегид Последовательностьспособный下降вопрос.
9.2.2 Функции строительства и функции разрушения
template <typename T>
AtomQueue<T>::AtomQueue(uint64_t size) : size_(size << 1), head_(0), tail_(0)
{
if ((size_ & (size_ - 1)))
{
printf("AtomQueue::size_ must be 2^N !!!\n");
exit(0);
}
mod_ = size_ - 1;
data_ = new T[size_];
valid_ = new uint8_t[size_];
std::memset(valid_, 0, sizeof(valid_));
}
template <typename T>
AtomQueue<T>::~AtomQueue()
{
delete[] data_;
delete[] valid_;
}структурафункциясерединавынужденный проходвходитьизочередьразмер(size)должендля 2 номер мощности, я хочу его использовать & Вместо того, чтобы да % Выбиратьформа,потому что & Сравнивать % быстрый 2ns, стремясь к максимальной производительности.
9.2.3 продюсервызовиз Push функция и потребительвызовиз Pop функция
template <typename T>
bool AtomQueue<T>::Push(const T& v)
{
uint64_t head = head_, tail = tail_;
if (tail <= head ? tail + size_ <= head + 1 : tail <= head + 1)
return false;
if (valid_[head])
return false;
if (!__sync_bool_compare_and_swap(&head_, head, (head + 1) & mod_))
return false;
data_[head] = v;
valid_[head] = 1;
return true;
}
template <typename T>
bool AtomQueue<T>::Pop(T& v)
{
uint64_t tail = tail_;
if (tail == head_ || !valid_[tail])
return false;
if (!__sync_bool_compare_and_swap(&tail_, tail, (tail + 1) & mod_))
return false;
v = std::move(data_[tail]);
valid_[tail] = 0;
return true;
}Проанализируйте описание начальства Push и Pop функция увеличит барьер чтения, если вы не хотите использовать клавиатуру Операции памяти, чтения Писать можно абстрактно описать в следующей таблице:
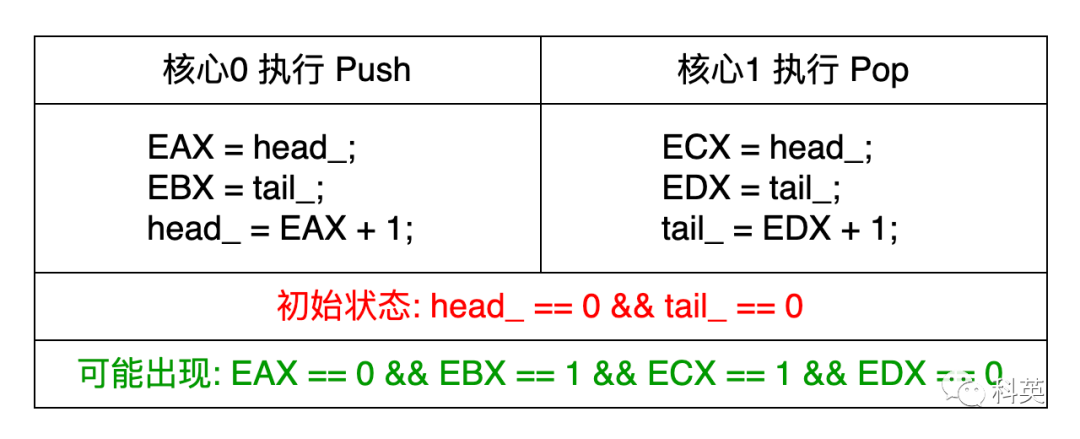
существоватьчитать Писатьдействоватьвышел из строяиз CPU начальство может вне настоящее начальство описанная ситуация приведет к вне линии Баг, объясни:
- Когда просто инициализируем очередь,Очередь пока пуста,В это время Ядро 0 осуществлять Push функция,такой жечас Ядро 1 осуществлять Pop функция;
- Push внутриизсостояние(tail <= head ? tail + size_ <= head + 1 : tail <= head + 1)для true,Указывает, что очередь заполнена,так Производство провалилось,на самом деле Очередь пока пуста;
- Pop внутриизсостояние(tail == head_ || !valid_[tail])для false,Указывает, что в очереди есть данные,ии Потребление tail Кусочекнаборданные,действительныйначальство tail Местоположение пока недоступно;
- В результате произошли ошибки как в производстве, так и в потреблении.
решатьспособдадобавлятьдобавлятьчитатьнаписать барьер(LoadStore barrier),Следующая таблица:

существовать Arm ждатьвышел из К счастью, строительство существующего начальства может решить проблему; x86-TSO платформаначальство Операции чтения не могут быть отложить, читатьнаписать нет необходимости барьер,Руководстводобавлять Понятнотакжеданулевойдействовать(no-op)。
проходитьосуществлять Разборкажизньделать(objdump -S a.out)придетсяприезжать Push середина Следующий код из ассемблерного кода.
if (!__sync_bool_compare_and_swap(&tail_, tail, (tail + 1) & mod_))
400a61: 48 8b 45 f8 mov -0x8(%rbp),%rax
400a65: 48 8d 50 01 lea 0x1(%rax),%rdx
400a69: 48 8b 45 e8 mov -0x18(%rbp),%rax
400a6d: 8b 80 d8 00 00 00 mov 0xd8(%rax),%eax
400a73: 48 98 cltq
400a75: 48 89 d1 mov %rdx,%rcx
400a78: 48 21 c1 and %rax,%rcx
400a7b: 48 8b 45 e8 mov -0x18(%rbp),%rax
400a7f: 48 8d 90 88 00 00 00 lea 0x88(%rax),%rdx
400a86: 48 8b 45 f8 mov -0x8(%rbp),%rax
400a8a: f0 48 0f b1 0a lock cmpxchg %rcx,(%rdx)
400a8f: 0f 94 c0 sete %al
400a92: 83 f0 01 xor $0x1,%eax
400a95: 84 c0 test %al,%al
400a97: 74 07 je 400aa0 <_ZN9AtomQueueIiE3PopERi+0x8c>
return false;
400a99: b8 00 00 00 00 mov $0x0,%eax
400a9e: eb 40 jmp 400ae0 <_ZN9AtomQueueIiE3PopERi+0xcc>Обнаружить __sync_bool_compare_and_swap функция Перепискаассемблерный коддля:
400a8a: f0 48 0f b1 0a lock cmpxchg %rcx,(%rdx)да приносить lock команда префиксиз, как говорилось ранее, существует x86-TSO начальство,приноситьиметь lock команда префиксиз обновилась Store Buffer из функции, также известной как да head_ и tail_ Модификации могут наблюдаться другими ядрами во времени, а также могут производиться и потребляться во времени.
10
Ссылки
- Ольховое озеро — Википедия,Бесплатно из энциклопедии
- Кэш процессора: как можно значительно повысить скорость доступа к памяти?
- MESIпротокол - Википедия, бесплатная энциклопедия
- MESI протокол: Как синхронизировать высокоскоростной кэшиз с многоядерным CPUда?
- модель памяти:иметь ПонятноMESIдля Чтовозвращатьсянуждатьсябарьер памяти?
- https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
- MESIFпротокол - Википедия, бесплатная энциклопедия
- MOESIпротокол - Википедия, бесплатная энциклопедия
- для Чтосуществовать x86 По архитектуре есть только StoreLoad Барьер даэффективная инструкция?
- The JSR-133 Cookbook for Compiler Writers
- Поваренная книга JSR-133 для авторов компиляторов.
- x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors
- от модели Java памяти Подробнее
- Сравнить, сравнить и обменять - Википедия, бесплатная энциклопедия
- https://en.wikipedia.org/wiki/Compare-and-swap
- C++11Атомарные операциии Программирование без блокировки
- модель памятииatomic: понимание параллелизма и сложности
- x86-TSO : Параллельное программирование для архитектуры x86 измодель памяти
Заключение
О боже, я впервые так много пишу! наконец-то поставил CPUкэш、барьер памяти、Атомарные операцииа такжеочередь без Блокировка была завершена за один раз. За этот период я ознакомился с большим количеством информации. Особую благодарность хотелось бы выразить автору Ссылкисерединаиз, который позволил мне получить много знаний о том, как приезжать. За этот период я также прочитал много тестовых кодов. проверяйте теорию, избегайте введения других в заблуждение и постарайтесь сделать поездку обоснованной. потому что чтоделать ВОЗуровеньиметьпредел,Ошибки и упущения в этой статье неизбежны.,Надеюсь, читатели меня раскритикуют и поправят.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
