Ключевые проблемы и исследование применения двустороннего движения между графом знаний и большой моделью
Введение
Графы знаний и большие языковые модели являются одновременно средством представления и обработки знаний. Большие модели дополняют способность понимать язык, а графы знаний обогащают способы выражения знаний. Углубленное сочетание этих двух факторов, несомненно, предоставит искусственному интеллекту более полный, надежный и контролируемый метод обработки знаний. В этом контексте OpenKG организует серию новых перспективных статей KG - «Большой альбом моделей» и время от времени приглашает экспертов отрасли для проведения углубленных дискуссий по интеграции графов знаний и больших моделей. В этом выпуске Лян Лэй, руководитель отдела знаний Ant Group, был приглашен поделиться «Ключевыми вопросами и исследованием применения двунаправленного вождения SPG и LLM». Эта статья составлена на основе рассказа учителя Лян Лея в CNCC Knowledge Graph. Форум пройдет в Шэньяне 26 октября 2023 года.
01 Введение
Интеграция массивов данных на уровне предприятия все чаще становится консенсусом в отрасли. Благодаря интеграции массивов данных на основе знаний можно ускорить стандартизацию данных, устранение/уменьшение двусмысленности и объединение «островков» данных. Как форма моделирования данных с более сильными выразительными возможностями, графы знаний также требуют постоянного технологического обновления, чтобы идти в ногу со временем. Programmable Graph)Группа муравьев иOpenKGСовместно выпущено новое поколение семантической структуры знаний промышленного уровня.,Это краткое изложение опыта Ant в различных сценариях приложений корпоративного уровня. В то время, когда предприятия переходят на цифровую модернизацию, а технологии искусственного интеллекта расширяют возможности тысяч отраслей,,Ожидайте прохожденияOpenSPGСоздавайте и ускоряйте интеграцию корпоративных массивов данных,Символизация знаний эффективно связывает представление знаний и структуру механизма спектра изображений систем искусственного интеллекта.,В целях содействия внедрению в бизнесе управляемых технологий искусственного интеллекта.
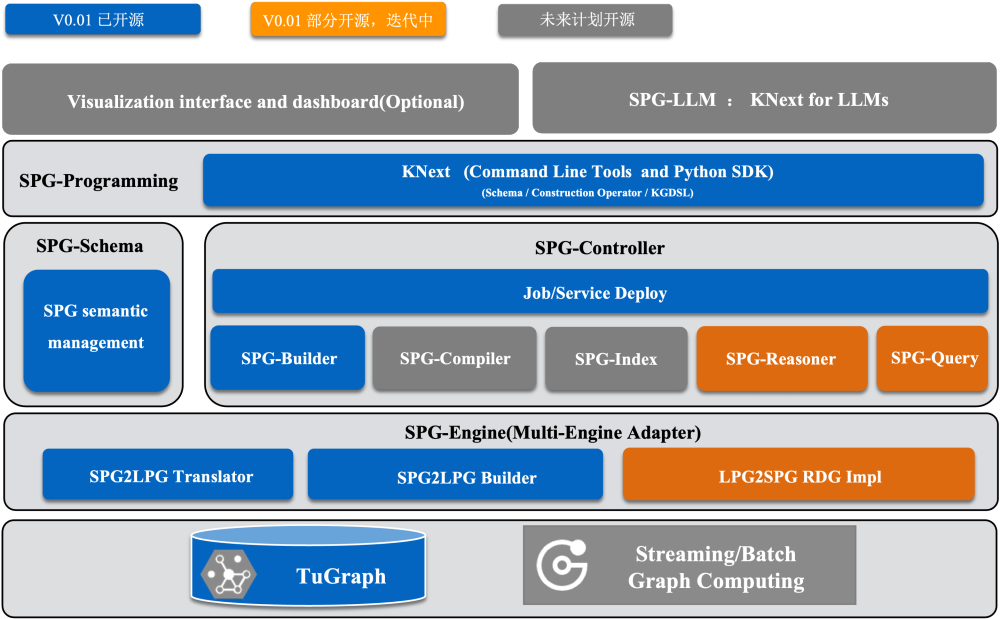
Рисунок 1. Общая архитектура OpenSPG.
02 График знаний идет в ногу со временем
Граф знаний сам по себе представляет собой комплекс междисциплинарных технологий, и о нем часто шутят: «только граф знаний может четко описать техническую систему графа знаний». Он по своей сути связан с технологией больших данных, технологией НЛП, графовыми вычислениями, графовым обучением и т. д. и технологии искусственного интеллекта. Системы и другие системы интегрированы и совместимы, и благодаря этому граф знаний может легче поглощать и интегрировать преимущества других технологий. То же самое справедливо и в эпоху больших моделей. Мощные языковые возможности больших моделей компенсируют недостаточную эффективность извлечения/конструирования знаний, а технология графов знаний является проактивной и предполагает открытость.
Внутри, благодаря семантической структуре SPG и графовой технологии, система семантического представления была модернизирована с двоичной статической до многомерной динамической, чтобы лучше реализовать восприятие фактов, индукцию и осаждение знаний здравого смысла, а также глубокие контекстуальные ассоциации и т. д. и понимать и использовать знания через систему Карты избегают понимания концепций многочисленных карт извне, картографическая технология активно использует новое поколение технологических систем искусственного интеллекта, таких как модель большого языка; LLM), реализует двойное улучшение обоих, определяет техническую парадигму и ключевые вопросы интеграции и взаимодействия, а также использует мощную способность понимания языка LLM для повышения эффективности построения графов на основе не-/полуструктурированных данных. В то же время в вопросах и ответах пользователя понимание элементов и семантических структур также будет более точным.

Рисунок 2. Общая семантическая структура SPG
На рисунке 2 показана общая семантическая структура, опубликованная в официальном документе SPG. В данной статье анализируются ключевые проблемы, которые необходимо решить с точки зрения графа знаний на основе представления знаний SPG. Благодаря постоянным технологическим прорывам мы надеемся значительно снизить стоимость построения графов знаний и продолжить снижение порога применения графов предметной области. В то же время, в сочетании с типичными сценариями реализации крупных моделей в полевых условиях, мы стремимся построить парадигму отраслевой реализации с двойным управлением SPG + LLM для улучшения управляемости и надежности приложений предметной области.
Кроме того, решение проблемы иллюзии LLM на основе графа знаний — это длительная и сложная работа. Для этого необходимо построить графы предметных областей, охватывающие различные отрасли, и добиться семантической связи и миграции между ними. В этом процессе остается еще много сложных проблем, которые необходимо решить. В настоящее время исследования SPG в основном начинаются с вертикальных полей и направлены на освоение ключевых технологий взаимного улучшения SPG и LLM, а также накопление карт знаний предметной области для улучшения управляемости и надежности приложений предметной области.
03 Улучшение двойного привода SPG и LLM
Во-первых, давайте посмотрим на круг проблем, которые SPG и LLM могут решить индивидуально и с помощью двунаправленных драйверов, взяв в качестве примера сценарии применения торговых операций и управления рисками на предприятиях, как показано в Таблице 1, алгоритмические задачи LLM и SPG. приложения можно условно разделить на три категории:
- Только LLM: из-за профессиональных и фактических требований в этой области LLM еще не реализовала четко сценарии в области торговых операций и контроля рисков;
- Двойной драйвер LLM + SPG: в основном отражается в сценариях взаимодействия с пользователем, таких как вопросы и ответы о знаниях и создание отчетов, таких как телефонный звонок AI, чтобы разбудить жертву, и генерация интеллектуальных пробных сообщений по борьбе с отмыванием денег, упомянутых выше. Кроме того, существуют сценарии построения знаний, такие как извлечение элементов знаний и связывание сущностей. Двойной фактор LLM и SPG подробно описан в литературе, включая три аспекта: LLM с усилением KG, SPG с усилением LLM и синергия структуры LLM+SPG;
- Только SPG: в сценариях принятия решений/извлечения знаний, которые не требуют сложного языкового взаимодействия и понимания намерений, таких как рассуждения и принятие решений, аналитические запросы и интеллектуальный анализ знаний, прямое обучение графическому представлению, обоснование правил, запрос знаний и т. д. на основе на графоструктурированных знаниях. Благодаря сотрудничеству структуры LLM и SPG имеют двойное управление, поддерживая кросс-модальное согласование знаний, логическое обоснование знаний, запросы на знание естественного языка и т. д. Это выдвигает более высокие требования к унифицированному представлению семантики знаний SPG и межсценарной миграции структуры механизма.
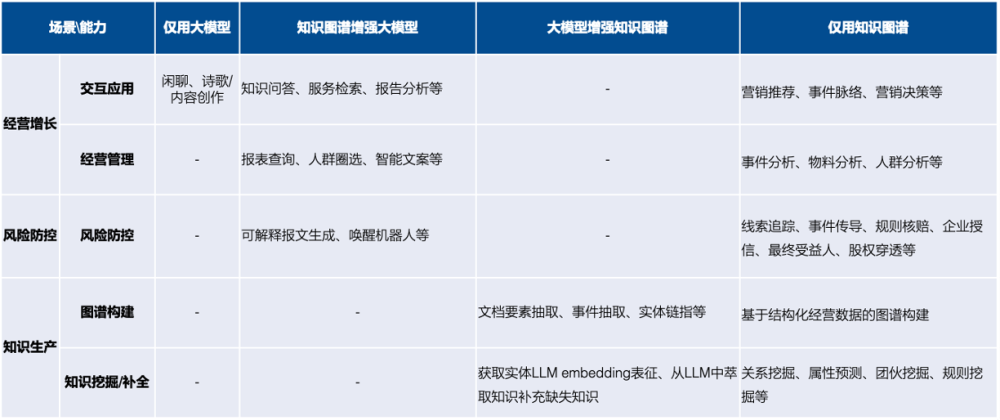
Таблица 1. Анализ сценариев применения графов знаний и больших моделей на предприятиях
Мы планируем объединить практику Ant Knowledge Graph и планирование с открытым исходным кодом OpenSPG, чтобы создать структуру двусторонней интеграции SPG и LLM для достижения связи производства знаний и рассуждения/запроса знаний. С точки зрения общего определения возможностей ядро состоит из трех частей: 1) LLM улучшает построение карты домена SPG. С помощью мощных возможностей LLM по пониманию языка можно построить многократно используемый процесс производства знаний для поддержки построения карт на уровне атомарных элементов и подграфов. 2) SPG расширяет возможности запроса вывода LLM. Обеспечьте необходимые возможности запросов и рассуждений для приложений LLM с помощью рассуждений по правилам KGDSL или рассуждений по обучению графов AGL. 3) Согласование знаний LLM и SPG. Мы планируем построить архитектуру иерархического согласования (Alignment) для достижения согласования LLM и предметных знаний.
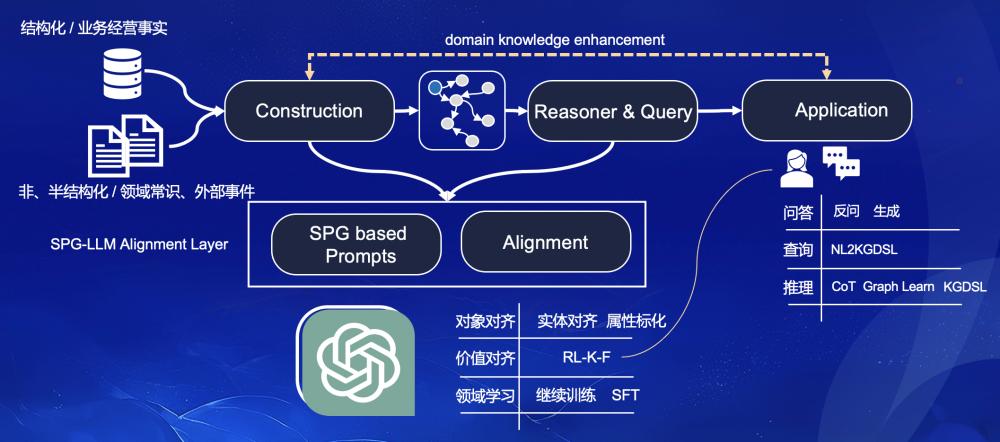
Рисунок 3. Общая связь двойного привода SPG и LLM
Далее в этой статье мы подробно представим модель возможностей построения знаний и запроса на обоснование графа. Здесь мы кратко представим модель возможностей части согласования LLM и SPG. Мы надеемся способствовать наращиванию возможностей уровня согласования SPG и LLM. из четырех уровней:
Согласование знаний предметной области. Благодаря непрерывному предварительному обучению и возможностям SFT, контролируемая точная настройка реализуется на основе базовой модели, чтобы помочь большим моделям быстро понять знания предметной области, профессиональный словарь, логические структуры и т. д., а также автоматически генерирует предварительное обучение на основе базы знаний предметной области и SPG. отображать экземпляры данных команд, тем самым интегрируя знания и логические ограничения в процесс предварительного обучения.
Выравнивание ценностного поведения. Включая обратную связь о поведении пользователя во время нескольких раундов диалога и запроса знаний, а также обратную связь о согласованности, основанную на тройках базы знаний. Мы также пытаемся построить модель вознаграждения на основе графических знаний и генерировать правильные и неправильные ответы на основе фактов и здравого смысла в SPG. на базе САУ реализована РЛ-К-Ф.
Выравнивание твердого объекта. Выравнивание сущностей — это очень важная базовая возможность двухдисковой структуры SPG+LLM. Цель состоит в том, чтобы получить представления LLM и SPG одного и того же объекта и добиться их выравнивания посредством векторного расчета, чтобы его можно было выполнить. Точно получаемые, когда пользователь задает вопросы или генерируются ответы. Для знаний, хранящихся в SPG, основная проблема, которую необходимо решить, - это согласование естественного языка и структурных знаний, а также интеграция словарного запаса, распознаваемого NER, в пользователе. вопрос (запрос) и исходный документ (документ) с выравниванием сущностей, концепций и структурированных объектов событий.
Выравнивание контекста ICL. Автоматически создавайте подсказки на основе знаний, хранящихся в SPG, полностью активируйте глубокую контекстную информацию в SPG и сокращайте стоимость создания подсказок для пользователей. Среди них 1/3/4 находятся в центре нашего текущего строительства, а 2 все еще находятся в стадии изучения. Мы поделимся этой информацией после того, как в будущем будет достигнут поэтапный прогресс в наращивании соответствующего потенциала.
04 LLM расширяет знания о SPG
Отсутствие возможности переносимости алгоритмов извлечения знаний в графы знаний было проблемой в течение многих лет, и мощные возможности LLM по пониманию языка могут лучше компенсировать отсутствие переносимости алгоритмов извлечения. Ожидается, что LLM справится с моделью возможностей SPG. обеспечить САУ конструктивными возможностями, как показано на рисунке 4.
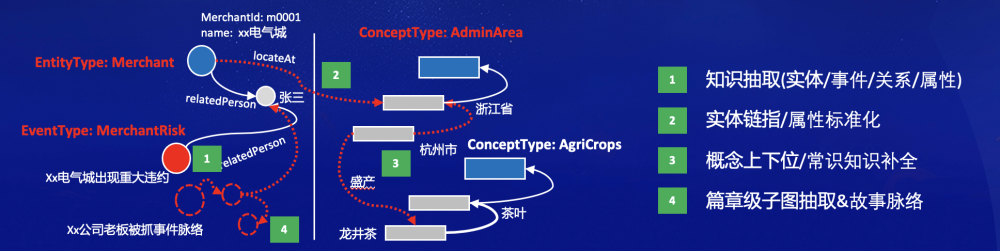
Рисунок 4. LLM расширяет модель возможностей создания знаний SPG
1) Извлечение элементов знаний. Этот тип полностью активирует способность LLM понимать язык. Этап SFT позволяет LLM полностью понять знания предметной области и определить структуру ввода и вывода инструкций посредством точной настройки инструкций. Этап ICL определяет извлеченный шаблон подсказок на основе SPG и создает подсказки. на основе экземпляров графа для повышения точности извлечения знаний можно определять шаблоны строго в соответствии с семантической структурой в SPG и заполнять подсказки на основе экземпляров графа. К общим задачам извлечения элементов относятся: сущности, понятия, атрибуты, события и т. д. Типичная структура запроса на извлечение взаимосвязей, автоматически создаваемая путем объединения схемы и экземпляров, показана в псевдокоде ниже.
Известные связи СПО включают: болезнь-симптомы заболевания (указывающие симптомы, вызванные болезнью)-симптомы (например, головные боли, боли в шее и т. д.), болезнь-группы высокого риска-популяции (такие как пожилые люди, молодые люди, дети, и т.д.), болезненные отделения -кафедры (такие как общая хирургия, эндокринология и т.д.). Извлеките эти отношения, определенные из следующих предложений. Окончательный результат извлечения выводится в формате json. Если в выводе несколько значений, разделите их запятыми. Не выводите какую-либо информацию за пределами указанного формата. вводные данные: Узелком щитовидной железы называют образование в щитовидной железе, которое может перемещаться вверх и вниз вместе с щитовидной железой во время глотания. Это распространенное клиническое заболевание, вызываемое множеством причин...
Выходной формат:
{"spo":[{"subject":,"predicate":,"object":},]}
output:
{"spo":[{"subject":"Узел щитовидной железы","predicate":"Симптомы заболевания","object":"Боль в шее, ощущение инородного тела в горле, давление"}, ....]}2) Стандартизация атрибутов и связывание сущностей. Стандартизация и создание цепочек являются одними из основных применений возможностей выравнивания объектов. Основываясь на определениях возможностей SPG Evolving и SPG DC, эта часть больше посвящена построению представления знаний, которое соответствует семантическим ограничениям SPG. Слоган графа знаний — «Вещи». , а не строки". Цель SPG состоит в том, чтобы каждый атрибут и связь имели четкую модель предметной области. Типичными примерами определения схемы SPG являются:
Компания: EntityType
properties:
hasPhone(номер телефона): STD.ChinaMobile
RegisterPlace (место регистрации): AdminArea
IND#tax0fCompany (принадлежит): Tax0fCompany
relations:
hasCert (имеет сертификат): Cert
HoldПоделиться: КомпанияСоздавайте векторные представления текста и структурированных элементов с помощью LLM, используйте векторные вычисления базы данных для достижения эффективного выравнивания объектов и индексируйте/стандартизируйте извлеченные текстовые ссылки на концепции и экземпляры сущностей целевого типа. Таким образом, это может ускорить стандартизацию. знания для достижения объяснимого уплотнения редких связей. Этот параграф также более подробно представлен в официальном документе SPG.
3) Завершение концептуального превосходства/знания здравого смысла. Основной принцип LLM заключается в том, чтобы учиться на массивном корпусе и суммировать вероятность совместного появления слов и предложений, чтобы предсказать следующее слово, а определения понятий и здравого смысла также суммируются людьми на основе различных фактов и имеют внутрипредприятие или взаимодействие; отраслевой консенсус. Существует большое сходство между картами здравого смысла и большими моделями, которые представляют собой обобщение фактов. Разница в том, что большие модели обладают сильными возможностями обучения и индукции, основанными на массивном корпусе. LLM получает последовательность троек (h, r, t)любые два из,И выведите концепции головы и хвоста или промежуточные предикаты. Например,<Провинция Чжэцзян, столица провинции, ?> Его можно завершить как город Ханчжоу. Заполнение знаний здравого смысла может широко использоваться в таких сценариях, как прогнозирование восходящей и последующей производственной цепочки, завершение синонимов/антонимов слов сущности и прогнозирование концепций классификации. Это также основная зависимость в операторе стандартизации понятий при извлечении концептуальных знаний. .
4)уровень главыкартинаизвлекать&сюжетная линия。Знаниеизвлекатьконечная цель,Надеюсь, у него есть возможность извлекать профессиональную литературу и читать,Введите документ или книгу,Ядро знаний Графика извлекается посредством повторяющихся раундов извлечения. и реализовать классификацию и стратификацию знаний на основе SPG. Реализация возможностей извлечения на уровне главы включает в себя Атомарное извлечение элементов знаний, автоматическое моделирование знаний и объединение подграфов графов основаны на атомарных базовых возможностях. Атомное извлечение элементов знаний обеспечивает точность и охват извлечения после определения целей задачи, таких как извлечение основных имен, таких как имена людей и атрибутов. отношения человек-человек, отношения человек-место рождения-регион и т. д. Автоматическое моделирование знаний предназначено для обнаружения новых сущностей/концепций/типов событий (классов), имен атрибутов, имен отношений и т. д. на основе текущей структуры документа и базовой схемы. И реализовать полуавтоматическое моделирование на основе ручной проверки, Слияние подграфов графов заключается в объединении извлеченной новой структуры подграфа с существующим базовым графом.
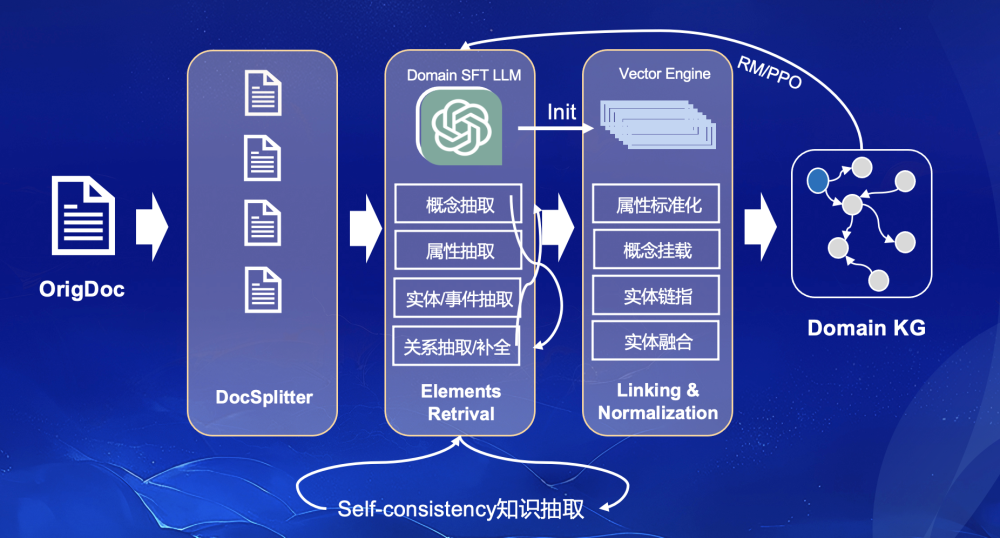
Рисунок 5. Конвейер построения знаний улучшенной SPG LLM
Чтобы реализовать многократно используемый процесс производства знаний в сочетании с программируемой моделью оператора (оператора) SPG, мы создали компонентную и основанную на процессах абстракцию процесса производства знаний, как показано на рисунке 5, который обычно включает в себя четыре части: Сегментация документа. , извлечение элементов, стандартизация знаний и оценка знаний. Среди них сегментация документов (Document Splitter) предоставляет оператор, необходимый для сегментации входного документа на главы и абзацы, а также строит структуру абзацев документа для достижения попунктного извлечения. Извлечение элементов Извлечение) и стандартизация знаний (связывание) & Нормализация), которая была введена ранее и больше не будет описываться. Оценка знаний (Знания В настоящее время платформа графа знаний в основном полагается на ручную оценку для полной проверки правильности знаний с помощью платформ аннотаций. Мы также изучаем некоторые методы автоматической оценки для повышения точности извлечения знаний.
Ниже мы приводим простой пример повышения точности извлечения знаний на основе большой самосогласованности модели. Как мы все знаем, медицинская помощь представляет собой типичный сценарий применения наукоемких технологий. Как точно извлекать и понимать медицинские знания, также является ключевой проблемой, с которой мы сталкиваемся.

Рисунок 6. Пример извлечения на основе самосогласованности
Как показано на рисунке 6, взяв в качестве примера выделение «гиперплазии предстательной железы» на основе ChatGPT, LLM может определить ее как заболевание, симптом или тип местоположения в нескольких ответах, что приводит к некоторым несоответствиям в результатах. Однако хороших результатов можно также достичь, позволив крупным моделям генерировать разные точки зрения и самим дискутировать. Чтобы повысить точность извлечения медицинских объектов, можно создать различные шаблоны точек зрения для обсуждения, чтобы определить различные способы мышления и генерации для LLM. Путем создания возможных аргументов на основе различных подсказок и классификационных меток, а также позволяя LLM оценивать и оценивать все мнения, можно сделать возможные выводы. Этот метод также может значительно повысить точность извлечения медицинских объектов.
Помимо извлечения текстовых знаний, таких как сущности предметной области и концепции на основе LLM, экспертные правила также очень важны в сценариях применения в вертикальных областях предприятия. В отрасли также ведется много исследований и дискуссий о том, как эффективно накапливать домены и управлять ими. экспертный опыт. SPG предлагает основанное на правилах решение для достижения органической интеграции экспертных правил и фактических знаний, а также построения логических зависимостей между элементами знаний для формирования цепочки правил. На рисунке 7 представлен простой пример знания правил. Благодаря знаниям правил можно построить определение и повторное использование экспертного опыта на разных уровнях, таких как отделы, бизнес-направления, компании, отрасли и т. д.
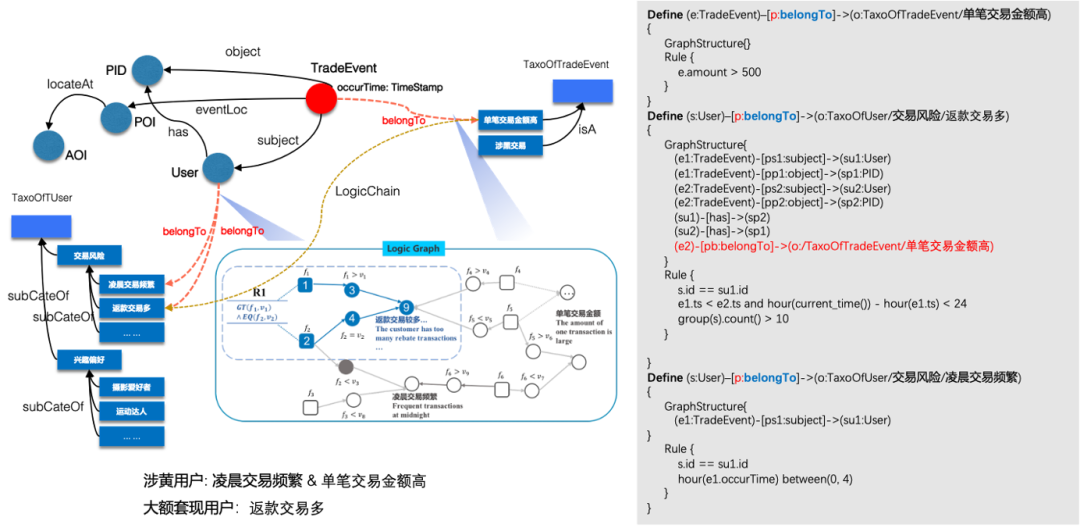
Рисунок 7. Схематическая диаграмма цепочки правил SPG.
Чтобы экспертные правила не были слишком сложными, мы можем разделить правила на атомарную степень детализации. На рисунке 7, основанном на ежедневном процессе суждения экспертов о «серых» и «черных» продуктах и мошенничестве в азартных играх, показаны типичные параметры суждений пользователей, подозреваемых в рискованных действиях. транзакции включают сумму одной транзакции, частые ли транзакции ранним утром, частые операции по скидкам и т. д., частые ли транзакции с несколькими картами, частые ли транзакции за рубежом и т. д. Мы можем определить эти явные процессы экспертного суждения как знание правил. Эксперты могут напрямую судить и подтверждать факты на основе текстовых меток. Текстовые метки будут обратно связывать структуры суждений и возможные подсказки, а обратное похищение может повысить эффективность экспертных суждений. интерпретируемость результатов.
05 Усовершенствованная САУ, управляемая LLM, вопросы и ответы
Поскольку применение LLM продолжает расти, такие проблемы, как иллюзия LLM, недостаточная сложность рассуждений и плохая своевременность обновления знаний, также значительно ограничивают промышленное внедрение LLM. Чтобы облегчить вышеупомянутые проблемы, отрасль также провела дополнительные исследования. такие как улучшение поиска (RAG), плагины / обучение плагинов, улучшение данных, улучшение карт и другие методы, которые появляются бесконечно. Мы пытаемся разобрать несколько ключевых проблем, которые необходимо решить с точки зрения SPG.

Рисунок 8. Принципиальная схема расширенного приложения LLM SPG.
Основной процесс вопросов и ответов на знание — это вопрос и ответ. Опрос — это процесс, в котором пользователь не вводит информацию, а ответ — это процесс, который объединяет диапазон ответов на основе ввода пользователя и дает пользователю надежный и удовлетворительный ответ. . Расширенный LLM SPG можно разделить на три части с точки зрения возможностей: получение фактических знаний, символическое рассуждение знаний и интегрированное рассуждение LLM и SPG. Объединив эти три категории, в вертикальной области уровня предприятия типичными категориями, которые может предоставить SPG, являются: следующее:
- Класс запроса структуры подграфа. Также известный как NL2GQL или NL2KGDSL, он переводит естественный язык в язык графовых запросов, типичный для многомерного анализа данных, маркетинговых кругов и т. д. Он генерирует определенные выражения запроса правил на основе определяемых пользователем логических структур для повышения эффективности операций и анализа данных. .
- Класс сведений о подграфе сущности. Этот тип приложения является типичным применением глубокого контекста SPG. Простого использования текста в индуктивном смысле портретных меток недостаточно для полного описания информации о глубине целевого объекта. Другими словами, этот тип применения требует как индуктивных выводов, так и подтверждающих аргументов. Они должны уметь рассуждать вперед и назад и предоставлять интерпретируемые подсказки, необходимые для выводов.
- Класс символической логики рассуждений. Символическое рассуждение имеет преимущества, не имеющие себе равных с LLM, с точки зрения точности рассуждений, сложности задач и вычислительных затрат. Оно преобразует вопросы пользователя в символические представления и реализует связь между пользовательским контекстом и данными графика для завершения окончательного рассуждения. Вы можете использовать символическое рассуждение по прямому правилу или использовать методы обучения графов для прогнозирования отношений или классификации атрибутов. Этот тип задач похож на NL2KGDSL и требует использования LLM для точного понимания структуры проблемы и ключевых параметров для достижения эффективного сотрудничества между нейронной сетью LLM и символическим представлением SPG. Такие проблемы распространяются на многоэтапные решения сложных проблем, таких как CoT/ToT/GoT. В будущем мы также надеемся интегрировать многоэтапный вывод цепочки правил и цепочки мышления SPG, чтобы LLM мог понять этапы рассуждения и. получить параметры для достижения многоэтапного связанного рассуждения.
- Многоходовой диалог больше связан с применением трех вышеупомянутых основных способностей, определением намерений, получением знаний, интерактивной обратной связью и генерацией ответов. Он больше полагается на запись истории пользователей для достижения долговременной исторической памяти. Сохранение информации о взаимодействии с пользователем в виде исходного текста сложно эффективно архивировать, и масштаб исторических разговоров будет огромен. привести к катастрофическому забвению или повторению одной и той же проблемы. В случае запроса мы также изучаем возможность создания временного графика путем извлечения функций для хранения истории пользователя в частном пространстве имен пользователя. Кроме того, популярный в последнее время метод улучшения поиска (RAG) является продолжением приложений поисковых систем. Это относительно эффективный метод, позволяющий в краткосрочной перспективе облегчить иллюзию больших моделей LLM. В долгосрочной перспективе присущие поисковым системам проблемы. такие как фактология и объединение нескольких источников. Если проблема все еще не решена, возникнут новые проблемы, которые пользователям будет трудно отследить.
В сочетании с разделением вышеупомянутых типов приложений, с точки зрения SPG, возникают новые основные проблемы, которые необходимо решить:
- Контекстная память пользователя. Вы можете создать память истории пользователей на основе графов, извлечь пользовательские запросы и расширения запросов в структурированные представления подграфов и интегрировать новые подграфы с Memory KG. В то же время записывается индексная связь между ключевыми объектами, концептуальными узлами и исходной записью диалога, чтобы облегчить создание полных и эффективных подсказок в новом раунде диалога. Во время нескольких раундов диалога можно извлечь историческую память, а также удобно создавать контекст пользовательских событий на основе памяти, например, прошлую историю болезни пользователя и опыт лечения в медицинских сценариях. Кроме того, с помощью семантической стандартизации SPG можно реализовать и нематериализованное автоматическое соединение Memory KG и Base KG.
- Запросы на естественном языке. Изучив схему графа, примеры и логическую структуру DSL, можно реализовать задачу NL2KGDSL для автоматического создания подграфов запросов. В настоящее время в отрасли проводится множество исследований ответов на вопросы на естественном языке на основе крупных моделей. По сравнению с традиционным методом ответов на вопросы базы знаний (KBQA), использование LLM может значительно снизить затраты на извлечение элементов сущности и логических структур. Благодаря точной настройке инструкций LLM изучает структуру схемы SPG, семантические ограничения и различные синтаксические структуры KGDSL, чтобы понимать проблемы пользователей и генерировать целевые запросы KGDSL. После исправления можно выполнить операцию запроса.
- Возможности выравнивания объектов. Выравнивание объектов было представлено ранее и не будет описываться снова. Стоит отметить, что благодаря связи с процессом производства знаний предметной области ответы на вопросы могут повторно использовать набор SFT LLM предметной области с извлечением знаний, повторно используя унифицированные возможности извлечения элементов знаний и одну и ту же структуру выравнивания объектов.
- В процессе запроса знаний мы часто сталкиваемся с ситуациями, требующими логического расчета или интерпретации меток знаний. Путем определения логических меток с помощью логических правил SPG вопросы пользователя можно преобразовать в логические вычисления, а при вынесении выводов можно вывести обратные подсказки, подтверждающие выводы.
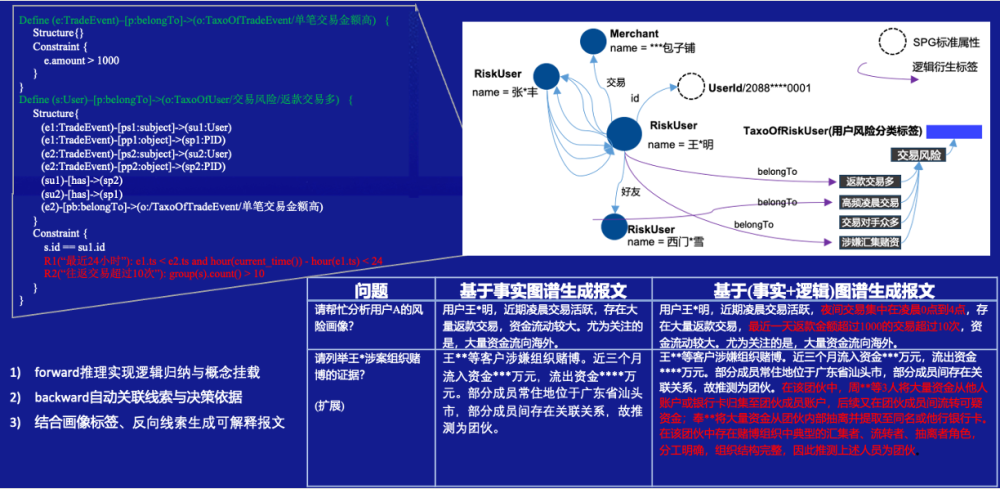
Рисунок 9. Пример глубокого контекста SPG
Как показано на рисунке 9, путем обратного запроса связанной структуры графа и портретной информации с помощью сущностей и концепций можно эффективно заполнить фактическую информацию в отчете об исследовании или процессе создания профиля риска. Что касается логических отношений и логических атрибутов, используемых в элементах сообщения, SPG может получить подсказки и доказательства для поддержки вывода посредством обратного рассуждения, обеспечивая тем самым более конкретные описания копий и улучшая интерпретируемость вывода.
06 Связь сообщества SPG и OpenKG
Этот обмен познакомит вас с общей идеей SPG и ключевыми вопросами двойного применения SPG и LLM. Основная цель SPG — создание семантической структуры и механизма знаний нового поколения, объединяющего большие данные и искусственный интеллект. Есть надежда, что в эпоху искусственного интеллекта ускоряется усвоение данных и эффективно интегрируются огромные объемы корпоративных данных, а также улучшается связь с технологической системой искусственного интеллекта посредством символизации знаний. На этот раз основными возможностями OpenSPG с открытым исходным кодом являются базовая семантическая структура SPG, возможности запросов и среда Python SDK. Мы также продолжим итерацию и оптимизацию.
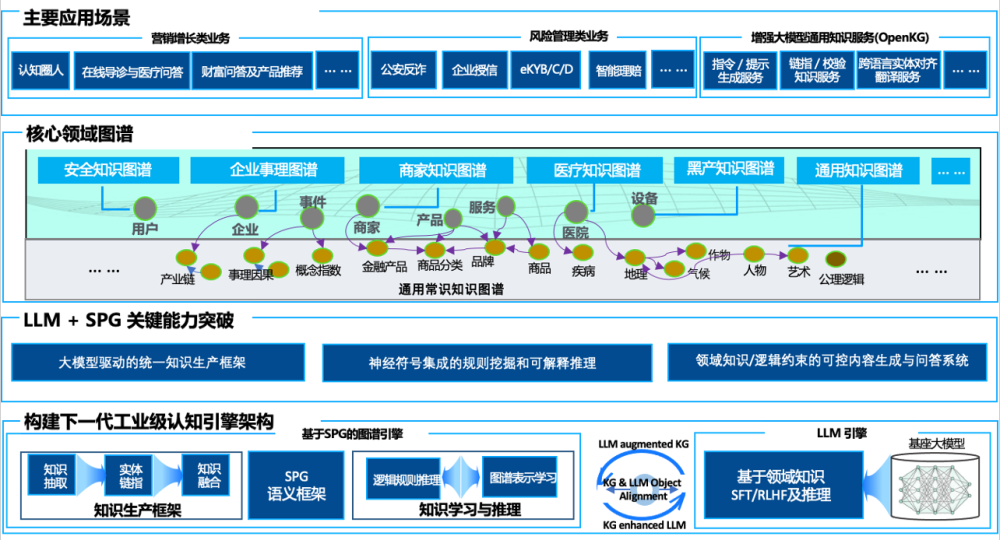
Рисунок 10. Общая техническая схема двойного привода SPG + LLM
В будущем мы рассчитываем на углубленное сотрудничество с OpenKG на основе OpenSPG в сочетании с отраслевыми приложениями для постоянного улучшения накопления знаний OpenSPG и возможностей системного ядра:
Связан с OpenKG для накопления общих знаний в этой области. Как представлено в официальном документе SPG, семантическая структура SPG может автоматически отделять общий здравый смысл предметной области от фактических бизнес-знаний, моделируется с использованием концептуальной системы для построения между ними причинных, вышестоящих, ипостасных и семантических систем. Этот тип знаний имеет сильную отраслевую универсальность. Его можно использовать внутри компании и между отраслями. Мы также будем выпускать больше карт знаний и услуг, основанных на здравом смысле, через OpenKG.
Создайте связанную технологическую парадигму LLM на основе OpenSPG. В этом обмене основное внимание уделяется техническим проблемам, которые необходимо решить в рамках парадигмы двойного привода SPG и LLM. В будущем мы продолжим преодолевать трудности и совершенствовать построение знаний SPG, улучшенных SPG. Мы продолжим решать трудности, связанные с SPG. Символический движок и нейронная сеть, представленные LLM, интегрированы в технологическую систему OpenSPG для постоянного содействия обновлению соответствующих технических возможностей и внедрению бизнес-приложений.
Службы знаний OpenKG, расширение домена и приложения. В будущем мы надеемся постоянно совершенствовать возможности семантического выражения SPG посредством всестороннего применения в различных отраслях, расширять семантические модели в GeoSPG, ScienceSPG, MedicalSPG и других областях, а также продолжать способствовать совершенствованию языковой парадигмы SPG. Создавайте с помощью OpenKG расширенные службы знаний больших моделей, такие как согласование знаний, генерация инструкций, проверка знаний и другие уникальные возможности знаний.
OpenSPG в настоящее время является открытым исходным кодом, и более заинтересованные коллеги из отрасли могут обсуждать и работать вместе, чтобы способствовать зрелости технологии графов знаний и построить новое поколение парадигмы управляемой технологии искусственного интеллекта.
Гость: Лян Лэй, руководитель службы знаний Ant Group, эксперт OpenKG TOC и профессиональный член CCF. Мои основные направления исследований включают графы знаний, графические механизмы обучения и рассуждения, инженерию искусственного интеллекта, поисковые системы и т. д.
Примечание организации | Дэн Хунцзе (OpenKG)
Утверждение содержания | Чэнь Хуацзюнь



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
