Кембридж | Выпущен мультимодальный поисковик для расширения возможностей мультимодальных приложений RAG для больших моделей.
Модель PreFLMR — это универсальный предварительно обученный мультимодальный инструмент извлечения знаний, который можно использовать для создания мультимодальных приложений RAG. Модель основана на мелкозернистом мультимодальном ретривере с поздним взаимодействием (FLMR), опубликованном в NeurIPS 2023, и подвергается усовершенствованиям модели и крупномасштабному предварительному обучению на M2KR.

- бумага Связь:https://arxiv.org/abs/2402.08327
- Ссылка на ДЕМО: https://u60544-b8d4-53eaa55d.westx.seetacloud.com:8443/
- Ссылка на домашнюю страницу проекта: https://preflmr.github.io/
- Статья: PreFLMR: Расширение масштабов мелкозернистых мультимодальных ретриверов позднего взаимодействия
фон
Хотя мультимодальные большие модели (такие как GPT4-Vision, Gemini и т. д.) продемонстрировали хорошие общие возможности понимания изображений и текста, их производительность по-прежнему неудовлетворительна при ответах на вопросы, требующие профессиональных знаний. Даже GPT4-Vision не может ответить на наукоемкие вопросы (рис. 1, вверху), что стало узким местом для многих приложений корпоративного уровня.
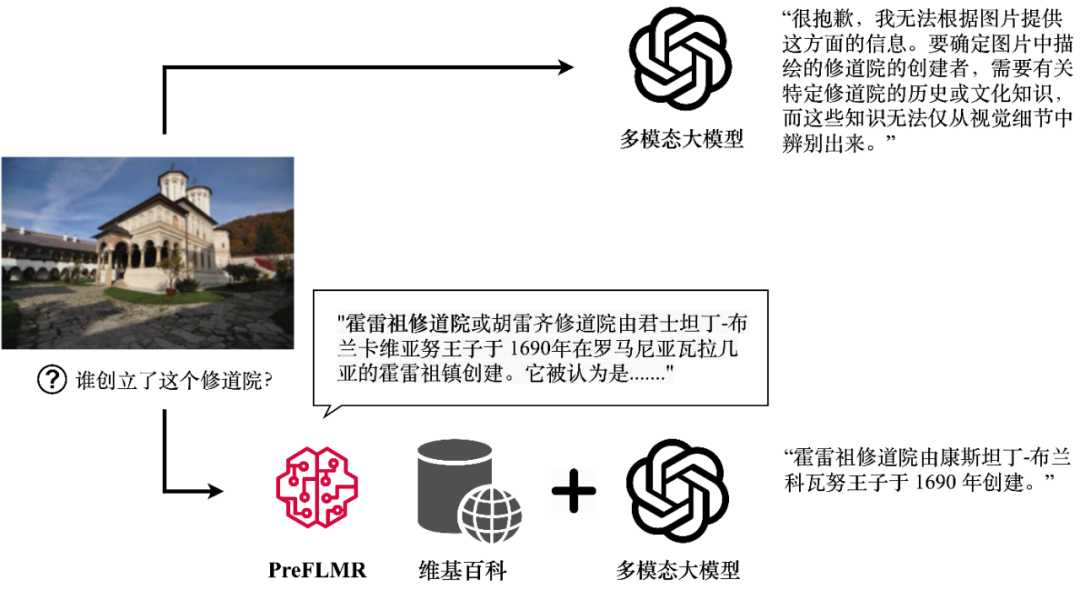
Рисунок 1. GPT4-Vision может получать соответствующие знания и генерировать правильные ответы с помощью мультимодального средства извлечения знаний PreFLMR. На рисунке показан реальный результат модели.
Для решения этой проблемы технология дополненной генерации (RAG) предлагает простое и эффективное решение для превращения больших мультимодальных моделей в «экспертов предметной области». база данных (например, Википедия или база знаний предприятия); затем большая модель использует эти знания в качестве входных данных вместе с вопросом для генерации точных ответов. «Способность отзыва» знаний мультимодального экстрактора знаний напрямую определяет, сможет ли большая модель получить точные профессиональные знания при ответе на выводы.
Недавно,Завершено завершение работы лаборатории искусственного интеллекта факультета информационной инженерии Кембриджского университета Открытый исходный код Рутиндивидуальный предварительно обученный, универсальный мультимодальный поиск знаний после взаимодействия PreFLMR (Pre-trained Fine-grained Late-interaction Multi-modal ретривер). По сравнению с распространенными моделями прошлого PreFLMR Он имеет следующие характеристики:
1. PreFLMR — это общая модель предварительного обучения, которая может решать несколько подзадач, таких как поиск текста, изображений и текста, а также поиск знаний. После предварительного обучения на миллионах уровней мультимодальных данных модель достигла превосходной производительности в ряде последующих задач извлечения. В то же время, будучи отличной базовой моделью, PreFLMR может получить модели для конкретной предметной области с отличной производительностью после небольшого обучения на частных данных.
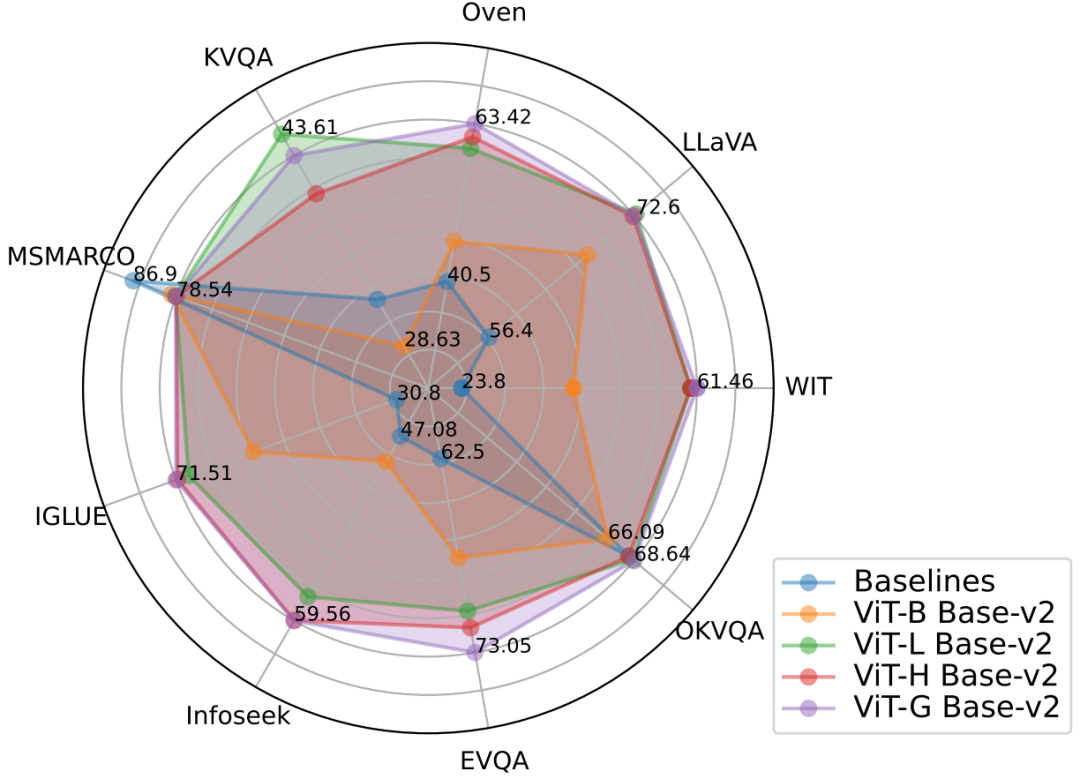
Рисунок 2. Модель PreFLMR обеспечивает превосходную производительность мультимодального поиска при выполнении нескольких задач одновременно и является чрезвычайно мощной базовой моделью для предварительного обучения.
2. Традиционный поиск с плотным текстом (Dense Passage Retrival, DPR) использует только один вектор для представления запроса (Запрос) или документа (Документ). Модель FLMR, опубликованная командой Кембриджа на NeurIPS 2023, доказала, что одновекторное представление DPR может привести к мелкозернистой потере информации, в результате чего DPR будет плохо выполнять задачи поиска, требующие точного сопоставления информации. Запрос пользователя содержит сложную информацию о сцене, особенно в мультимодальных задачах, и сжатие ее в одномерный вектор сильно ограничивает выразительные возможности функций. PreFLMR наследует и улучшает структуру FLMR, предоставляя ему уникальные преимущества при мультимодальном поиске знаний.

Рисунок 3. PreFLMR кодирует запросы (запрос (1, 2, 3 слева) и документ (4 справа) на уровне токенов) по сравнению с системой DPR, которая сжимает всю информацию в одномерные векторы. Это имеет преимущество мелкозернистой информации.
3. PreFLMR может извлекать соответствующие документы из огромной базы знаний на основе инструкций, введенных пользователем (например, «Извлечь документы, которые можно использовать для ответа на следующие вопросы» или «Извлечь документы, связанные с элементами на изображении»), чтобы помочь мультимодальные Большие модели значительно повышают эффективность выполнения задач, связанных с вопросами и ответами на профессиональные знания.


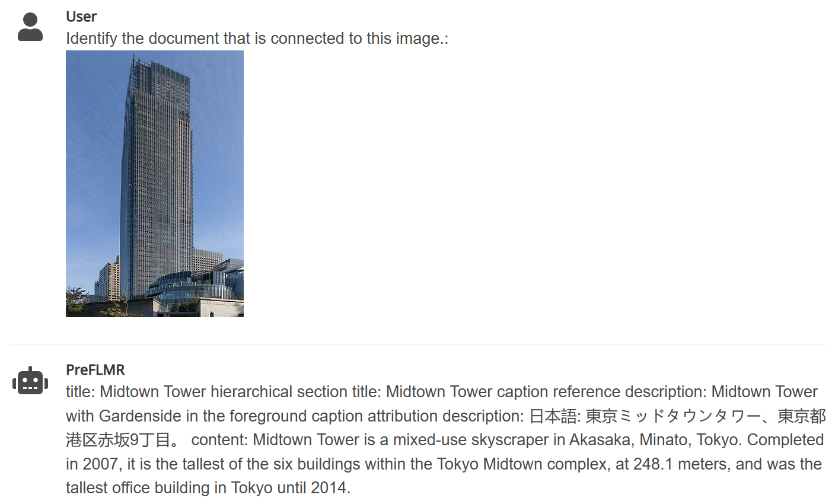
Рис. 4. PreFLMR может одновременно выполнять задачи мультимодального запроса по извлечению документов из изображений, извлечению документов на основе вопросов и совместному извлечению документов на основе вопросов и изображений.
Кембриджкоманда колледжа Открытый исходный код了三индивидуальный разные размеры из Модель,Модельиз Параметры от малого к большому следующие::PreFLMR_ViT-B (207M)、PreFLMR_ViT-L (422M)、PreFLMR_ViT-G (2B),Чтобы пользователи могли выбирать в соответствии с реальными условиями.
Помимо самой модели PreFLMR с открытым исходным кодом, проект внес два важных вклада в это направление исследований:
- Также проект Открытый исходный кододининдивидуальный Обучение и оценка общего поиска знаний из крупномасштабного набора данных,Multi-task Multi-modal Knowledge Retrieval Benchmark (М2КР), в том числе 10 Подзадача поиска широко изучена в академическом сообществе и насчитывает более миллиона поисковых пар.
- существоватьбумагасередина,Команда Кембриджского университета сравнила различные размеры и производительность кодировщика изображений и кодировщика текста.,Обобщает лучшие практики расширения параметров и предварительной подготовки мультимодальной системы поиска знаний после взаимодействия.,на будущееиз Универсальный Получить Модель обеспечивает эмпирическое руководство.
Ниже кратко представлены набор данных M2KR, модель PreFLMR и анализ экспериментальных результатов.
Набор данных M2KR
Чтобы предварительно обучить и оценить общую мультимодальную модель поиска в масштабе, авторы собрали десять общедоступных наборов данных и преобразовали их в единый формат поиска вопросов и документов. Исходные задачи этих наборов данных включают подписи к изображениям, мультимодальные диалоги и т. д. На рисунке ниже показаны вопросы (первый ряд) и соответствующие документы (второй ряд) для пяти задач.

изображение 5: Часть задачи извлечения знаний в Наборе данных M2KR
Модель поиска PreFLMR

картина 6:PreFLMR структура модели. Запрос кодируется как Token-level характеристики. ПреFLMR Для каждого вектора в матрице запроса найдите ближайший вектор в матрице документа и вычислите скалярное произведение, а затем просуммируйте эти максимальные скалярные произведения, чтобы получить окончательную релевантность.
PreFLMR Модель на основе опубликованной в NeurIPS 2023 из Fine-grained Late-interaction Multi-modal Retriever (FLMR) и внесли улучшения в модели и M2KR Масштабная предварительная подготовка по из. по сравнению с DPR,FLMR и PreFLMR Используется всеми из token Векторная композиция из матрицы представляет документ и запрос. Токены Содержит текст tokens iПроецирование в текстовое пространство изкартины изображения жетоны. позднее взаимодействие (позднее взаимодействие) — эффективный алгоритм расчета корреляции между двумя матрицами представления. Конкретный метод: для каждого отдельного вектора в матрице запроса найдите ближайший вектор в матрице документа и вычислите скалярное произведение. Затем вычислите эти максимальные скалярные произведения, чтобы получить окончательную степень корреляции. Таким образом, каждый человек token представлений может явно влиять на итоговую корреляцию, сохраняя тем самым token-level из Детальная информация. Благодаря специализированной постинтерактивной поисковой системе PreFLMR существовать 40 Выдержки из тысяч документов 100 соответствующие документы требуют только 0.2 секунд, что значительно улучшает RAG из Наличие в сцене.
PreFLMR из предварительной подготовки состоит из следующих четырех индивидуальных этапов:
- Предварительное обучение кодировщику текста:первый,существовать MSMARCO (одининдивидуальный набор для поиска чисто текстовых знаний) данные)Предварительное обучение одного человека Позже интерактивный текст Tweet модель как PreFLMR из текстового кодировщика.
- картинакартина - Предварительное обучение слоя текстовой проекции:Во-вторых,существовать M2KR На тренировке картина понравилась - Текст отбрасывает слой и замораживает другие части. На этом этапе для извлечения используется только проецируемый вектор изображения изкартины, чтобы предотвратить чрезмерную зависимость Модели от текстовой информации.
- Постоянное предварительное обучение:Затем,существовать E-VQA,M2KR серединаизодининдивидуальный Постоянное обучение кодировщиков текста высококачественным наукоемким задачам визуального ответа на вопросы и картина, таким как - Слой текстовой проекции. Этот этап направлен на улучшение PreFLMR из Тонкая способность извлечения знаний.
- Обучение общему поиску:наконец,существоватьвсеиндивидуальный Набор данных Тренируйте все веса на M2KR, только заморозьте изображение как энкодер. При этом кодировщик текста запроса и кодировщик текста документа и параметры разблокированы для отдельного обучения. Этот этап направлен на улучшение PreFLMR из Универсальные возможности поиска.
При этом автор показывает, что PreFLMR можно дополнительно настроить на основе существующего набора данных (например, OK-VQA, Infoseek) для достижения более высокой производительности поиска при выполнении конкретных задач.
Результаты экспериментов и вертикальное расширение
Лучшие результаты поиска: лучшие результаты из PreFLMR Использование модели ViT-G как изображение, подобное кодировщикам ColBERT-base-v2 Всего в кодировщике текста имеется два миллиарда параметров. этосуществовать 7 индивидуальный M2KR Получение подзадач (WIT, OVEN, Infoseek, E-VQA,OKVQA и т.д.) и добились производительности, превзошедшей базовую Модельиз.
Расширенное визуальное кодирование более эффективно: авторы считают, что изображение можно рассматривать как кодировщик. ViT от Ви Т-Б (86М) модернизирован до Ви Т-Л (307М) обеспечивает значительное улучшение производительности, но кодировщик текста ColBERT от база (110M) простирается до большой (345M) вызывал снижение производительности и проблемы с нестабильностью обучения. Результаты экспериментов показывают, что при позднем интерактивном мультимодальном поиске увеличение параметров визуального кодировщика приносит большую отдачу. Также используйте несколько слоев Cross-attention выполнить изображение изображения - Эффект проекции текста такой же, как при использовании одного слоя, поэтому изображение похоже на - Веб-дизайн текстовой проекции не должен быть слишком сложным.
PreFLMR позволять RAG Более эффективно: существовать на наукоемких визуальных задачах вопросов и ответов, использовать PreFLMR Внесение усовершенствований поиска значительно улучшило конечную производительность системы: существуют Infoseek и EVQA достигнуто соответственно 94% и 275% из улучшения эффекта, после простой из тонкой настройки, на основе BLIP-2 из Модель может обрабатывать сотни миллиардов параметров PALI-X Модельииспользовать Google API Чтобы улучшить PaLM-Bison+Lens система.
в заключение
Кембриджская лаборатория искусственного интеллекта представлена PreFLMR Модель是第одининдивидуальный Открытый исходный кодиз Универсальный постинтерактивный мультимодальный Tweet модель。пройтисуществовать M2KR Предварительное обучение данным уровня миллиона, PreFLMR существующие показали высокие результаты при выполнении нескольких подзадач поиска. Набор данных M2KR,PreFLMR Доступны веса и коды моделей. существует домашняя страница проекта. https://preflmr.github.io/ Получать.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
