KDD'24 | MMBee: Применение мультимодального слияния и расширения поведенческого интереса в рекомендации подарков в прямом эфире Kuaishou
1. Введение
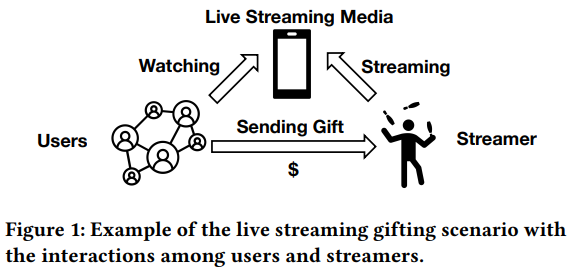
В этой статье в основном предлагаются решения проблем моделирования поведения пользователей (комментариев, подарков и т. д.) в прямых трансляциях. Предыдущие исследования по прогнозированию подарков в прямом эфире рассматривают эту задачу как традиционную рекомендательную задачу и используют категориальные данные и наблюдаемые исторические модели поведения пользователей. Однако, поскольку поведение пользователей редкое, особенно платное поведение, такое как отправка подарков, трудно уловить предпочтения и намерения пользователей. В этой статье предлагается метод MMBee, основанный на мультимодальном слиянии в реальном времени и поведенческом расширении.
- Впервые предложил мультимодальный модуль слияния (MFQ) с обучаемыми запросами.,Динамический контент для просмотра стоковых мультимедийных клипов,и обрабатывать сложные мультимодальные взаимодействия,Включает изображения, текстовые комментарии и голос.
- Чтобы смягчить проблему редкости поведения дарителей, предлагается новое графическое расширение Метод интересов (GIE), который изучает пользователей и акции на крупномасштабном графике подарков с мультимодальными атрибутами. мультимедийная характеристика. В основном он состоит из двух частей: предварительное обучение представления узла графа и расширение поведения на основе метапути.,Помогает модели исследовать не только конкретные исторические модели поведения в сфере дарения.,Богатое поведенческое представление.
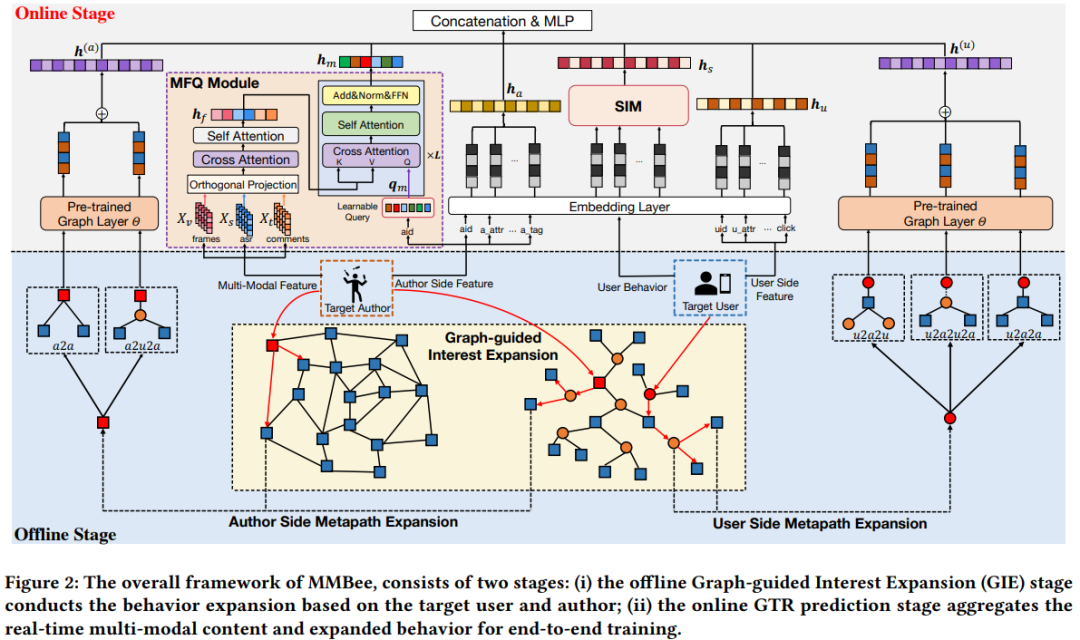
2. Метод
alt text
2.1 Мультимодальный термоядерный модуль
Для каждого сегмента прямой трансляции из каждого сегмента равномерно выбираются три кадра, а собранные данные ASR (автоматическое распознавание речи) и текст комментариев фильтруются. Затем внутренняя предварительно обученная мультимодальная модель 8B Kuaishou K7-8B используется для извлечения мультимодальных характеристик исходных данных, включая кортежи мультимодальных последовательностей изображения, голоса и комментариев соответственно.
Получив репрезентации разных модальностей, используйте ненужные части, чтобы дополнить репрезентации. Например, используя визуальную модальность в качестве целевой модальности, рассчитайте показатель корреляции между визуальной модальностью и двумя другими модальностями.
Особенностью слияния визуальной модальности является следующая формула, которая заключается в дополнении ее частями, не имеющими отношения к текущему распознаваемому представлению, поскольку соответствующие части эквивалентны избыточной информации.
Затем исходное представление и представление, дополненное op, используются для реализации механизма внимания (перекрестного attn),Объедините соответствующие результаты и введите их в слой самообслуживания.,Вот к этомуСлияние разных представлений
Однако функции слияния могут отражать только представления на уровне содержания и не иметь связи с характеристиками разных типов авторов (якорей). Чтобы решить эту проблему, вводится несколько обучаемых токенов запроса для извлечения шаблонов контента с поддержкой потоковой передачи. Каждый автор сохраняет случайно инициализированный набор обучаемых запросов emb. N представляет количество токенов запроса для каждого автора. Обучаемый запрос сначала взаимодействует с объединенными мультимодальными функциями посредством перекрестного внимания, а затем подается на уровень собственного внимания.
2.2 Расширение интересов с помощью графиков
2.2.1 график «пользователь-автор» и график «автор-автор»
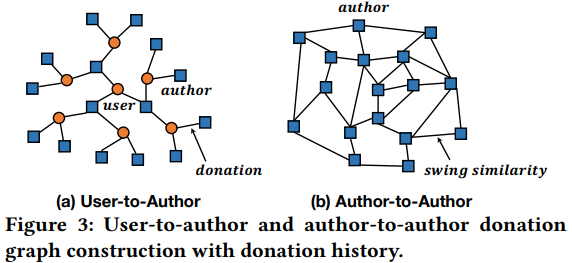
На основе истории чаевых пользователей строится график «пользователь-автор» (U2A), отражающий корреляцию между пользователями и авторами. V — соответствующий набор пользователей и авторов, а E — соотношение чаевых. Вес ребра — это сумма вознаграждения, а узел автора имеет атрибут агрегирования мультимодальных признаков.
Граф «автор-автор» (A2A) строится для представления взаимозависимостей между авторами, а ребра представляют отношения сходства Swing между авторами. Метод расчета сходства колебаний следующий: U — это совокупность пользователей, которые дали чаевые автору, поэтому знаменатель здесь рассчитывается как общее количество авторов, получивших чаевые от пользователей, которые дали чаевые обоим авторам i и j одновременно. В то же время, чем более однородны авторы, давшие чаевые (Низкое разнообразие), тем ниже сходство, используемое для предотвращения деления на 0.
Графики A2U формируются посредством отношений чаевых между пользователями и авторами, но есть также некоторые новые или начинающие авторы, которым чаевые практически никогда не получали. Однако вы можете использовать карту A2A, чтобы найти похожих пользователей для этих пользователей с небольшими чаевыми, чтобы облегчить проблему холодного запуска. После построения графов U2A и A2A метод обучения представлению узлов графа сначала используется для обучения уровня внедрения графа. Затем разреженная последовательность поведения пополняется с использованием метода расширения поведения на основе метапутей. Сначала поймите некоторые определения метапутей,
- Определение 1. Метапуть — это последовательность отношений, используемая для фиксации определенных структурных отношений между объектами. На диаграммах A2U и A2A автор определяет пять метапутей: три метапути, начинающиеся от целевого пользователя, и два, начинающиеся от автора.
- Определение 2: Соседние узлы, управляемые метапутями,Учитывая узел o в графе и метапуть, начинающийся с o,Представляет сбор соседнего узла i-го шага (порядка), посещенного по метапути, начиная с o.
2.2.2 Использование Graphcl для предварительного обучения представлению узла
Чтобы использовать информацию о связности всего графа,Примените платформу Graph Contrastive Learning (GraphCL) для обучения слоя внедрения графа. Чтобы сгруппировать похожие узлы вместе,Отталкивайте разнородные узлы одновременно,Перебрать все узлы графа G1.,Соседи, руководствующиеся метапутами, получают узлы положительной выборки,Узлы отрицательной выборки выбираются случайным образом.。Обучение с функцией потери кросс-энтропии и infoNCE,infoNCE легче понять,Часто используемая функция контрастной потери обучения,Но я не понимаю упомянутой здесь роли потери перекрестной энтропии.,Разве это не должно быть самообучение?(Кто знает больше, может прокомментировать,Мне кажется, что CE здесь должно быть следующее Расширение интересы в прогнозировании того, является ли задача классификации проигрышной)

alt text
2.2.3 Расширение интересов
Чаевые пользователи, как правило, относительно немногочисленны, поэтому интересы пользователей здесь расширяются. Учитывая вычислительные затраты, авторы выполняют до 3 прыжков на графах U2A и A2A для получения соседей. Были перечислены все возможные метапути и наконец выбраны пять наиболее важных наборов.
- , представляет пользователей, похожих на текущего пользователя, которым нравится один и тот же автор (привязка)
- Есть и другие, и я не буду приводить их здесь по отдельности. Ведь пути, встречающиеся в разных бизнес-сценариях, могут быть разными. Кому интересно, можно прочитать оригинальную статью.
На основе этого поведение пользователя обогащается. На этапе автономного расширения интересов совокупная совокупность расширенных соседей сохраняется в базе данных и используется на этапе онлайн-обучения. Чтобы устранить разрыв между представлением предварительно обученного узла и моделью онлайн-рекомендаций, модель сквозных обученных рекомендаций оптимизируется с помощью задачи двоичной классификации, позволяющей прогнозировать, будет ли предоставлено вознаграждение. Расширенная пользовательская эмблема и эмблема автора выражаются следующим образом и представляют соответственно слой эмблемы узла графа (для пользователей) и мультимодальные атрибуты (для авторов).
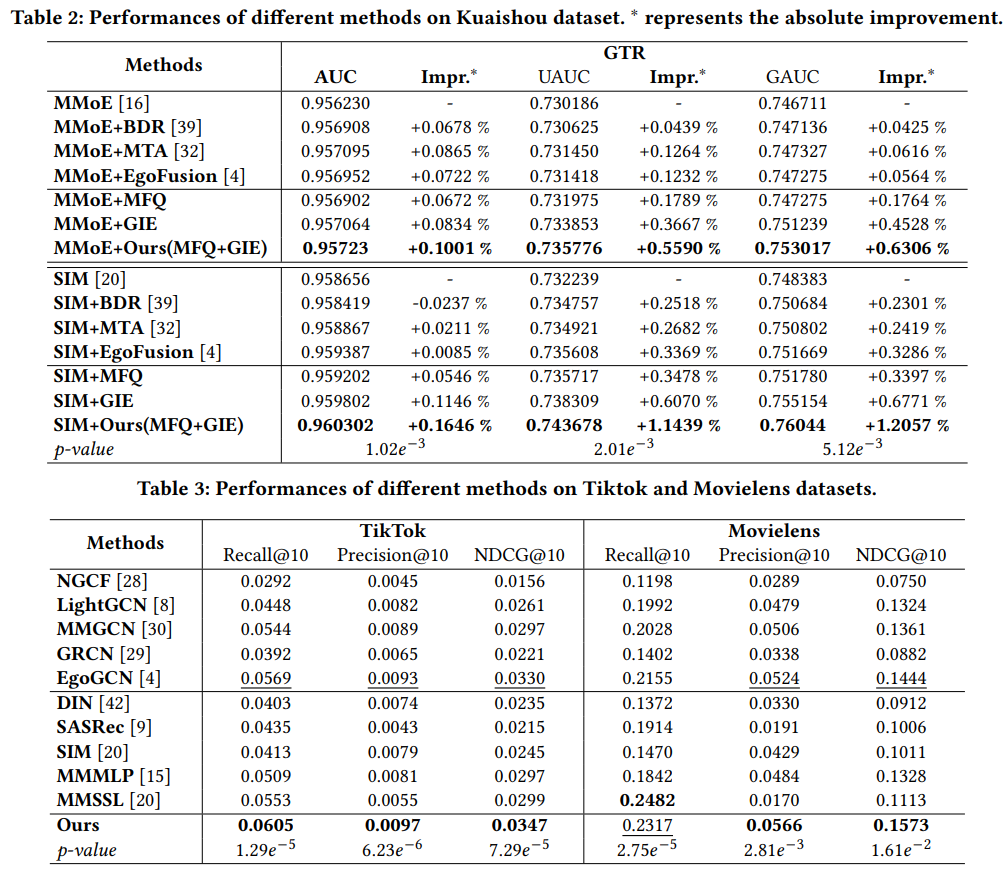
3 эксперимента
alt text



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
