KDD2025 | MM-Path: обучение мультимодальному и многограничному пространственно-временному представлению
Название статьи: MM-Path: Multi-modal, Multi-granularity Path Representation Learning
автор: Сюй Жунхуэй, Чэн Ханьинь, Го Чэньцзюань, Гао Хунфань, Ху Цзилинь, Ян Бинь, Ян Бинь
механизм: Восточно-Китайский педагогический университет, Чунцинский университет почты и телекоммуникаций
Ключевые слова: обучение представлению пути, мультимодальный, самостоятельное обучение
Бумажная ссылка: https://arxiv.org/abs/2411.18428
Ссылка на код: https://github.com/decisionintelligence/MM-Path
DI DaSE ECNU: KDD2025 | MM-Path: обучение мультимодальному пространственно-временному представлению

Нажмите в конце статьиПрочитайте оригинальную статьюПерейти к этой статьеarXivСвязь
краткое содержание: В различных областях интеллектуального транспорта разработка эффективных указателей пути становится все более важной. Хотя предварительно обученные пути обучения характеристике поверхности Модельповерхность показали хорошие результаты, они в основном фокусируются на на Унимодальныйданныетопология,например, дорожная сеть,Геометрические и контекстуальные особенности, связанные с изображением изображения пути (например, изображение изображения дистанционного зондирования), игнорируются. Интеграция информации из разных модальностей обеспечивает более полную картину,Повысьте точность определения характеристик и способность к обобщению поверхностей. Однако,Разница в детализации информации препятствует семантическому выравниванию путей на основе дорожной сети (дорожных путей) и путей на основе изображений (пути изображений картины).,В то же время неоднородность мультимодальной информации также дает большие преимущества для эффективной интеграции и использования. В этом документе предлагается новая мультимодальная структура обучения характеристик поверхности с многоуровневой структурой (MM-Path).,Общая функция пути изучается путем объединения двух модальностей: пути дороги и пути изображения. Улучшить согласованность мультимодальных данных,Мы предлагаем стратегию многоуровневого выравнивания,Систематически связывайте узлы, участки дорог и дорожные пути с соответствующими фрагментами изображений.,Обеспечьте синхронизацию подробной местной информации и более широкого глобального контекста. Чтобы эффективно решить проблему неоднородности мультимодальных данных,Мы предлагаем кросс-модальный компонент остаточного слияния на основе изображения.,Направлен на всестороннюю интеграцию информации различных модальностей и детализации. наконец,Обширные эксперименты проводятся на двух крупномасштабных наборах реальных данных в рамках двух последующих задач.,Эффективность MM-Path была проверена.
Нажмите в конце статьиПрочитайте оригинальную статьюПерейти к этой статьеarXivСвязь
мотивация
В таких областях, как интеллектуальная навигация, городское планирование и управление городскими чрезвычайными ситуациями, понимание путей и разработка эффективных представлений путей становится все более важным. Определение характеристик пути может широко использоваться для оценки времени в пути, рекомендаций по маршруту, а также анализа компоновки и оптимизации систем общественного транспорта. В последние годы многие исследовательские усилия были посвящены созданию предварительно обученных моделей обучения с представлением путей, которые демонстрируют отличные возможности обобщения. В реальном мире пути существуют в нескольких модальностях, которые предоставляют более богатую и разнообразную информацию. Например, пути, извлеченные из дорожной сети (называемые «дорожными путями»), раскрывают топологические отношения между сегментами дорог, тогда как пути на изображениях дистанционного зондирования (называемые «путями изображений») получены на основе геометрических особенностей и более широкого контекста окружающей среды; . Предоставляет новую перспективу (показано на рисунке 1). Интегрируя эту различную модальную информацию, мы можем обогатить представление путей с разных точек зрения, тем самым повышая точность и обобщение модели. Однако текущие модели обучения представлению путей в основном полагаются на одномодальные данные из дорожных сетей и еще не полностью охватывают глубокую и всеобъемлющую контекстную информацию, которая имеет решающее значение для всестороннего понимания путей. Поэтому особенно необходимо разработать предварительно обученную модель обучения представлению пути, которая может интегрировать мультимодальные данные.

Рисунок 1: Различные режимы пути
испытание
При построении такой предварительно обученной модели обучения функции поверхности мультимодального пути возникают две основные проблемы:
(1) Разница в детализации информации между дорожными путями и путями изображения серьезно затрудняет кросс-модальное семантическое выравнивание. Как показано на рисунке 1, дорожные пути обычно сосредоточены на подробной топологии и изображают дорожное сообщение, в то время как изображения путей обеспечивают более широкий глобальный контекст окружающей среды, который отражает функциональные атрибуты соответствующих областей. Следует отметить, что изображение может содержать большое количество областей, которые имеют низкую корреляцию с дорогами, как показано на рисунке 1(c). темные области в . Существующая мультимодальная модель «изображение-текст» обычно использует одно изображение изображения, согласованное с текстовой последовательностью.,Это единственное грубое выравнивание может привести к появлению шума.,Недостаточно для точного выравнивания знаков на поверхности дорожки.
(2) Присущая разнородность дорог и изображений создает огромную проблему для слияния объектов. дорожный путь икартинакартина路径在学习методогромная разница в,заставляя их сопоставляться с разными пространствами встраивания,Таким образом, измерения объектов со схожей семантикой содержат совершенно разную информацию. Простые стратегии объединения могут привести к потере информации или увеличению предвзятости.,И трудно уловить тонкую корреляцию между дорогой и траекторией изображения.
метод
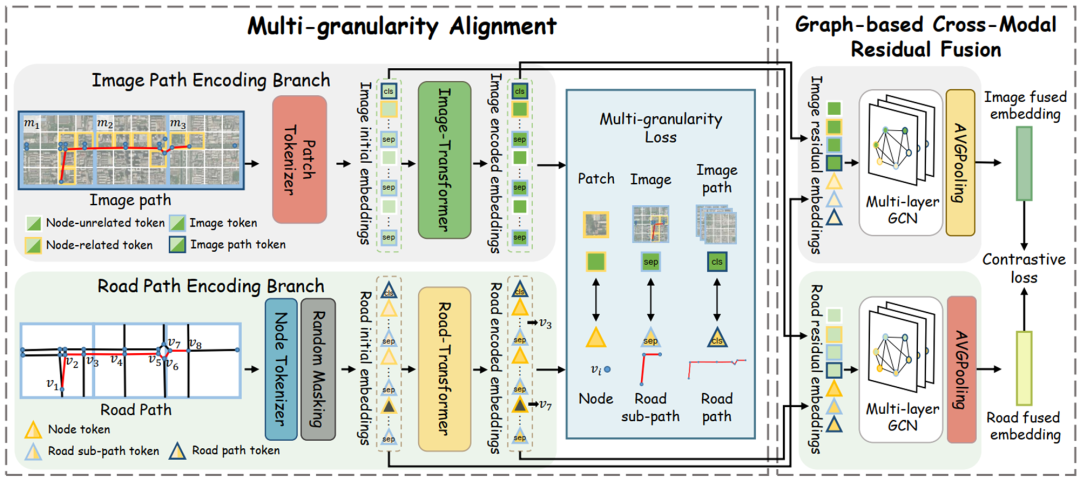
Рисунок 2: Общая структура MM-Path
Чтобы справиться с этими испытаниями,Мы предлагаем мультимодальный путь с разной степенью детализации, обучение функциям поверхности.,для изучения общих путейповерхностьвзимать。картина2 Показана общая структура MM-Path. MM-Path содержит два ключевых компонента: Многоуровневое выравнивание. Выравнивание) и кросс-модальное остаточное слияние на основе графика (на основе графика Cross-modal Residual Fusion) компонент.
Компоненты многоуровневого выравниваниясистематически соединять перекрестки、подпути и целые дорожные пути с соответствующими имкартинакартина信息关联起来,Точно фиксируйте детали с более тонкой детализацией,и поддерживать глобальную переписку с более грубой детализацией。 В частности, мы разделяем изображение всей интересующей области на небольшие изображения фиксированного размера, собираем небольшие изображения фиксированного размера вдоль каждого пути и упорядочиваем собранные изображения по пути изображения (т. е. последовательности изображений). Затем мы используем токенизаторы, специфичные для модальности, для создания начальных вложений для путей дорог и путей изображений соответственно. Эти первоначальные внедрения затем передаются в архитектуру Transformer, которая изучает сложные внедрения кодирования для каждой модальности с тремя уровнями детализации. Наконец, используется функция потери выравнивания с несколькими уровнями детализации, чтобы гарантировать встраивание выравнивания кодировок дорог и изображений с различной степенью детализации.
Кроссмодальный компонент остаточного слияния на основе изображения旨在在融合空间上下文信息的同时有效融合跨模态特взимать。Мы объединяем встраивание кодирования каждой модальности с начальным встраиванием другой модальности.,Создайте остаточные вложения изображения дороги и изображения отдельно.,для объединения кросс-модальных функций на разных этапах. Затем,Для каждого пути строится кросс-модальная матрица смежности на основе пространственного соответствия и контекстной информации. Эта матрица использует GCN для итеративного объединения двух остаточных вложений по отдельности.,Таким образом получаем вложения дороги и изображения, подобные слиянию. Наконец, применяется контрастная потеря, чтобы гарантировать согласованность двух модальных вложений слияния. наконец,Мы объединяем эти два объединенных вложения,Получите общий путь к знаку поверхности. Поскольку окончательный элемент поверхности эффективно объединяет межэтапные элементы и информацию о пространственном контексте двух модальностей.,Таким образом, этот компонент не только обеспечивает глубокое мультимодальное слияние,И это улучшает всестороннее использование информации.
Результаты эксперимента
общая производительность
В таблице 1 показана общая производительность по двум задачам: оценка времени в пути и ранжирование маршрута. Мы используем «» (чем больше, тем лучше) и «» (чем меньше, тем лучше), чтобы отметить достоинства числовых значений. В каждой задаче мы выделяем лучшие и вторые лучшие результаты, выделяя их жирным и подчеркиванием соответственно. Кроме того, две строки «Улучшение» и «Улучшение*» количественно определяют улучшение производительности модели MM-Path по сравнению с лучшими одномодальными и мультимодальными базовыми моделями соответственно. MM-Path превосходит все базовые показатели в обоих наборах данных, демонстрируя свое превосходство.
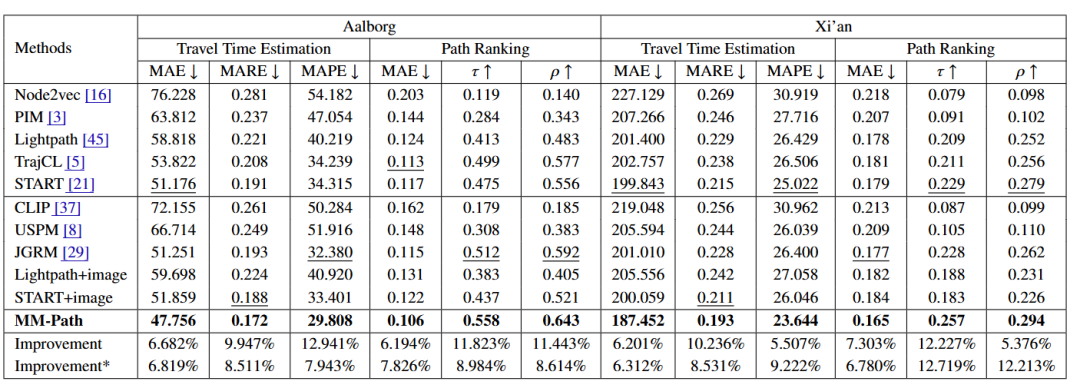
Таблица 1: Общая точность оценки времени в пути и ранжирования маршрутов
Пример анализа
Мы исследуем пару репрезентативных путей в Ольборге, чтобы продемонстрировать превосходство MM-Path. Путь дороги и путь изображения показаны на рисунке 3.
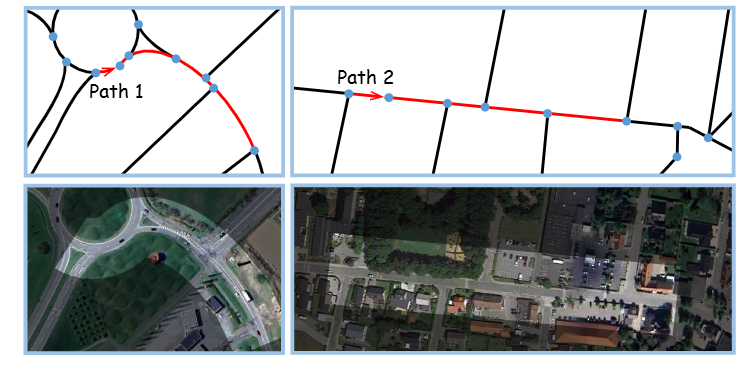
картина 3: Визуализация двух путей
Два маршрута на рисунке 3 демонстрируют схожие структуры поверхности дорожной сети.,Все они имеют последовательности степеней узлов. Эти данные одного режима могут означать, что время прохождения двух путей близко. Однако,Судя по информации об их изображении,Между ними есть существенные различия. Например,Путь 1 проходит через кольцевую развязку и следует по главной дороге.,Обычно такие пути позволяют двигаться с более высокой скоростью. Путь 2 — обычная дорога рядом с жилым районом.,Скорость движения обычно ниже.
поверхность 2 Приведено время в пути, оцененное с помощью различных моделей для этих двух маршрутов. модельTrajCL, START А START+image предсказывает, что время пути по пути 2 короче, чем по пути 1, что противоречит реальной ситуации. Эта поверхность показывает, что информация отдельных модальных данных может быть ограничена, и простое объединение мультимодальных данных, таких как START+модель изображения, не позволяет эффективно использовать информацию изображения изображения. Напротив, хотя мультимодальная модель JGRM Результаты согласуются с относительными различиями в фактическом времени в пути, но оценки по-прежнему значительно смещены. ММ-путь Модель показала лучшую производительность оценки времени в пути, показав, что она может эффективно интегрировать и использовать информацию об изображении для предоставления более точных прогнозов.
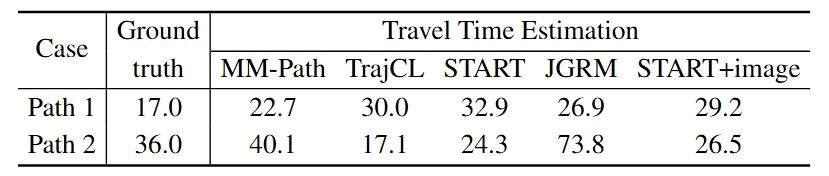
поверхность2: Результаты оценки времени перемещения для различных моделей
в заключение
В этой статье представлен мультимодальный путь с многоуровневой структурой для обучения характеристик поверхности кадраMM-Path. Это первая попытка интегрировать дорожные сети и данные изображений в общее обучение функциям поверхности пути. первый,Скомпонуйте модели дорожных дорожек и изображения дорожек отдельно,Внедрение стратегий многоуровневого выравнивания,Обеспечьте синхронизацию детализированной локальной информации с широким глобальным контекстом. также,Мы разработали кросс-модальный компонент остаточного слияния на основе изображения,Он может эффективно интегрировать информацию из обеих модальностей.,сохраняя при этом семантическую согласованность между модальностями. В тестах на последующих задачах на двух реальных наборах данных,MM-Path превосходит все базовые модели Модель,Показывая свою превосходную производительность.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
