Канал больших данных (4): Принцип высокой доступности канала и его установка
Принцип и установка Canal HA
1. Принцип работы канала HA
Canal обычно используется в сценариях синхронизации данных в реальном времени, поэтому высокая доступность особенно важна для сценариев реального времени. Canal поддерживает построение высокой доступности. Серверная и клиентская части Canal имеют соответствующие реализации высокой доступности. В больших данных данные синхронизации Canal обычно синхронизируются с Kafka. В данном случае Kafka эквивалентен Canal Client. Кластер Kafka имеет собственный атрибут HA, поэтому здесь мы ориентируемся только на HA Canal Server. Высокая доступность Canal Server предназначена главным образом для уменьшения количества запросов на дамп MySQL. Экземпляры на разных серверах (один и тот же экземпляр на разных серверах) требуют, чтобы одновременно работал только один, а остальные находились в состоянии ожидания (режим ожидания — это состояние экземпляра). ). Канал Принцип работы Сервера HA заключается в следующем:
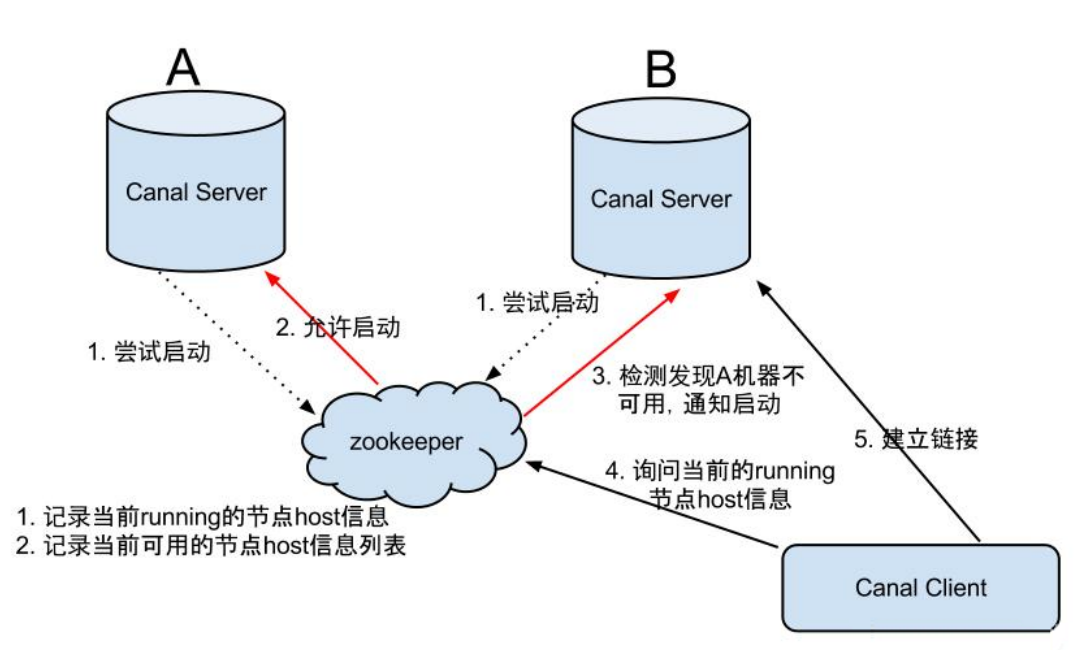
Гарантийные шаги Canal HA следующие:
- Когда сервер канала хочет запустить экземпляр канала, он сначала выносит решение о пробном запуске Zookeeper_.
- После успешного создания узла Zookeeper соответствующий сервер канала запускает соответствующий экземпляр канала. Если экземпляр канала не был успешно создан, он будет находиться в состоянии ожидания.
- Как только Zookeeper обнаруживает, что узел экземпляра, созданный сервером канала A, исчезает, он немедленно уведомляет другие серверы канала о необходимости повторного выполнения шага 1 и повторно выбирает сервер канала для запуска экземпляра.
- Каждый раз, когда клиент канала подключается, он сначала спрашивает Zookeeper, кто запустил экземпляр канала, а затем устанавливает с ним соединение. Как только ссылка становится недоступной, он пытается подключиться снова.
2. Строительство канала ГА
1. Подготовка машины
Машина работает на канале: node3, node4
Адрес смотрителя зоопарка: node3:2181,node4:2181,node5:2181
адрес MySQL: node2:3306
2. Разверните и настройте Canal отдельно на узлах node3 и node4.
Загрузите установочный пакет Canal на node3, node4 и разархивируйте его в каталог «/software/canal», измените файл canal.properties в разделе «/software/canal/conf» и добавьте конфигурацию Zookeeper.
#Указываем адрес кластера Zookeeper
canal.zkServers = node3:2181,node4:2181,node5:2181
#Настраиваем XML-файл конфигурации Spring
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
#canal записывает данные в Kafka, можно настроить с помощью: tcp, kafka, RocketMQ, TCP использует код канала для получения
canal.serverMode = kafka
#Настройте канал для записи адреса Kafka
canal.mq.servers = node1:9092,node2:9092,node3:9092Войдите в каталог «/software/canal/conf/example» и измените файл «instance.properties»:
#Измените другой компьютер на 123457, чтобы убедиться, что идентификатор подчиненного устройства не повторяется.
canal.instance.mysql.slaveId=123456
#Настраиваем MySQL master Узлы и порты
canal.instance.master.address=node2:3306
#Настройте имя пользователя и пароль для подключения к MySQL, которые являются именем пользователя и паролем для предыдущих разрешений на копирование.
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
#Настройте Canal для импорта данных в Kafka topic
canal.mq.topic=canal_topicПримечание. Имена каталогов экземпляров на двух компьютерах должны быть абсолютно одинаковыми. Режим высокой доступности зависит от имени экземпляра для управления. В то же время необходимо выбрать только конфигурацию default-instance.xml. информация о настройках Zookeeper.
3. Запустите Canal на обеих машинах.
#Запустить канал на узле3
[root@node3 ~]# cd /software/canal/bin
[root@node3 bin]# ./startup.sh
#Начать канал на узле 4
[root@node4 ~]# cd /software/canal/bin
[root@node4 bin]# ./startup.shПосле завершения запуска вы можете просмотреть соответствующую информацию о пути в Zookeeper:

3. Тест HA канала
После того как Canal HA будет построен по умолчанию, вы можете просмотреть узел активного канала, просмотрев «/otter/canal/destination/examples/running» в Zookeeper:

Проверьте Canal HA следующим образом:
1. Запишите данные в таблицу «testdb.person» в Mysql.
mysql> insert into person values (4,"s1",21),(5,"s2",22),(6,"s3",23);Можно заметить, что отслеживаемые данные в Kafka canal_topic выглядят следующим образом:
{"data":[{"id":"4","name":"s1","age":"21"},{"id":"5","name":"s2","age":"22"},{"id":"6","name":"s3","age":"23"}],"database":"testdb","es":1618849974000,"id":2,"isDdl":false,"mysqlType":{"id":"int","name":"varchar(255)","age":"int"},"old":null,"pkNames":null,"sql":"","sqlType":{"id":4,"name":12,"age":4},"table":"person","ts":1618849975203,"type":"INSERT"}2. Закройте активный узел Canal Server и продолжите запись данных в таблицу Mysql.
Завершите работу сервера канала node3:
[root@node3 ~]# cd /software/canal/bin
[root@node3 bin]# ./stop.shПросмотрите активный узел канала в пути Zookeeper «/otter/canal/destination/examples/running»:

Продолжайте записывать данные в таблицу «testdb.person» в MySQL:
mysql> insert into person values (7,"x1",24),(8,"x2",25),(9,"x3",26);Вы можете наблюдать данные, записанные в Kafka «canal_topic» следующим образом:
{"data":[{"id":"7","name":"x1","age":"24"},{"id":"8","name":"x2","age":"25"},{"id":"9","name":"x3","age":"26"}],"database":"testdb","es":1618850233000,"id":2,"isDdl":false,"mysqlType":{"id":"int","name":"varchar(255)","age":"int"},"old":null,"pkNames":null,"sql":"","sqlType":{"id":4,"name":12,"age":4},"table":"person","ts":1618850234136,"type":"INSERT"}После вышеуказанных испытаний Canal HA вступает в силу.
Примечание. После тестирования Canal HA использует Zookeeper для хранения позиции бинлога. Когда сервер Canal перезапускается и переключается на активный узел, последний фрагмент данных будет считываться повторно каждый раз. При использовании позиции бинлога локального хранилища, отличной от HA, такой проблемы не возникает.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
