[Камень с других гор] Действительно ли Мамба лучше Трансформера? Автор Мамбы: Гибридная архитектура — оптимальное решение!
Введение
Модель Mamba привлекла огромное внимание более чем за полгода с момента ее запуска благодаря своему огромному потенциалу, позволяющему конкурировать с Transformer. Однако в сценарии масштабного предварительного обучения эти две архитектуры еще не имели возможности «конкурировать». Недавно эмпирические исследовательские работы, совместно опубликованные NVIDIA, CMU, Принстоном и другими учреждениями, заполнили этот пробел.
декабрь прошлого года,CMU、Два китайских ученых в ПринстонеAlbert Гу и Три Dao одним махом запустил архитектуру Mamba,Бросить вызов многолетнему доминированию Transformer.

Адрес статьи: https://arxiv.org/abs/2312.00752.
Полный отказ от механизма внимания и модуля MLP, линейного масштабирования длины контекста и скорости вывода в 5 раз быстрее, чем у Transformer... Эти функции шокировали всех и похвалил Джима Фэна: «В восторге от исследования, способного свергнуть Transformer».
За шесть месяцев с момента публикации статьи оба автора обнаружили, что, хотя Мамба очень мощна, все по-прежнему уделяют больше внимания различным вариантам Трансформера.
Ведь над механизмами внимания уже много лет работает всё академическое сообщество, от моделей и стандартных библиотек до операторов и графических процессоров. В настоящее время полностью отказаться от предыдущих исследований и обратиться к SSM Мамбы, и это тоже заставляет. Архитектура Мамбы очень несовместима.
В результате мы видим, что бумага Мамба-2 объединяет ССМ и механизм внимания на более высоком уровне, при этом достигается увеличение скорости от 2 до 8 раз по сравнению с Мамбой-1.

Адрес статьи: https://arxiv.org/abs/2405.21060.
Как раз в тот момент, когда все с нетерпением ждут схватки Мамбы-2 и Трансформера в «Возвращении короля», авторы из NVIDIA, Университета Висконсин-Мэдисон, Принстона, CMU и других учреждений совместно опубликовали эмпирическую исследовательскую статью и обнаружили, что на основе Языковая модель архитектуры Mamba уступает Transformer в задачах с длинным контекстом.
Фактически, независимо от того, какой инновационный метод или модель появляется, статьи всегда неизбежно высказывают критику. Но более пристальный взгляд на эту статью показывает, что Три Дао и Альберт Гу, создатели Мамбы, также числятся в списке авторов.

Адрес статьи: https://arxiv.org/abs/2406.07887.
Я хотел бы поблагодарить этих двух ученых за их стремление искать истину на основе фактов.
Кроме того, в списке авторов можно найти еще одну изюминку — Альберта. Гу и Три У Дао новый титул.
Альберт Гу в настоящее время является соучредителем и главным научным сотрудником Cartesia AI. Их последний продукт — API голосового взаимодействия в реальном времени Cartesia Sonic.
https://cartesia.ai
Три Дао — учёный-основатель компании Together AI, которая в основном предоставляет облачные услуги, но также вносит свой вклад в передовые исследования с открытым исходным кодом.
https://www.together.ai
Далее давайте подробно рассмотрим конкретные сравнительные исследования возможностей Мамбы и Трансформера в этой статье.
Введение
Среди исследований на сегодняшний день (включая работы, предложившие Мамба Архитектура),SSMиTransformerсравнения проводились только в меньшем масштабе.(<3Bпараметр,<1T токен), справедливы ли эти выводы, когда бюджет на обучение больше?
Данный технический отчет призван ответить на этот вопрос. Автор отдельно обучил модели параметров 8B четырех архитектур: Mamba, Mamba-2, Mamba-2-Hybrid и Transformer, и сравнил производительность в 35 последующих задачах НЛП.

Данные обучения включают в себя два набора данных, 1.1T и 3.5T, оба из которых являются предшественниками набора данных, используемого NVIDIA для обучения Nemotron-4. Они состоят на 70% из английского, 15% неанглоязычного кода и 15% кода. .
в,Мамба-2-Гибрид — гибрид ССМ-Трансформера Архитектура Модель,Содержит 24 слоя Мамба-2.,А также 4 слоя самообслуживания и 28 слоев MLP, равномерно распределенных по Модели. общий,Этот сравнительный эксперимент устраняет распространенные трудности при сравнении различных LLM.,Включая данные обучения, сегментатор слов, конвейер «Оценивать» и т. д.,Обеспечить стандартность и повторяемость процесса Оценивать.
Чтобы облегчить воспроизведение и дальнейшие исследования, код, используемый для обучения Mamba, Mamba-2 и Mamba-2-Hybrid, был открыт с открытым исходным кодом, а исследовательская группа также опубликовала веса моделей Mamba-2 8B и Mamba-2-Hybrid. 8B на HuggingFace (как часть платформы и кодовой базы NVIDIA Megatron-LM).

https://huggingface.co/nvidia
Результаты экспериментов показывают, что, хотя «Мамба» и «Мамба-2» лучше моделируют язык, их производительность отстает от модели «Трансформер» в обучении контекста и вызове информации из контекста.
Особенно в тесте MMLU, даже если количество токенов в обучающих данных увеличится, модель на основе Mamba все еще сильно отстает от Transformer.
Mamba vs. Transformer
35 последующих задач «Оценивать» примерно делятся на 3 категории:
- Стандартные короткие контекстные задачи (12): HellaSwag, ARC-Easy, ARC-Challenge, MMLU, OpenBookQA, TruthfulQA и др.
- Естественные задачи с длинным контекстом (9): 6 задач в LongBench и 3 задачи в системе LM Evaluation Harness.
- Комплексные длинные контекстные задачи (14): 13 тестов с открытым исходным кодом в рамках RULER (включая 8 вариантов «найти иголку в стоге сена») и задача «Телефонная книга», предложенная только в этом году.,предназначен для измерения Модель Поиск по длинному вводному тексту、отслеживать、Умение агрегировать информацию.
В таблице 2 показаны частичные результаты оценки чистой SSM Архитектуры и Mamba-2 с моделью трансформатора после обучения данным 1.1T.

В обычных задачах производительность как Mamba, так и Mamba-2 может соответствовать или даже превосходить модель Transformer, но тест MMLU является исключением. При выполнении обучения с нулевой или малой выборкой Мамба-2 имеет разрыв в 10 и 17 баллов соответственно по сравнению с Трансформером.
Поскольку скорость обучения модели Mamba на наборе данных 1.1T уже почти в 3 раза медленнее, чем у Mamba-2 (размерность состояния модели больше), из соображений эффективности на наборе данных 3.5 была обучена только Mamba-2. Набор данных T 2 и модель трансформатора, некоторые результаты показаны в таблице 3.
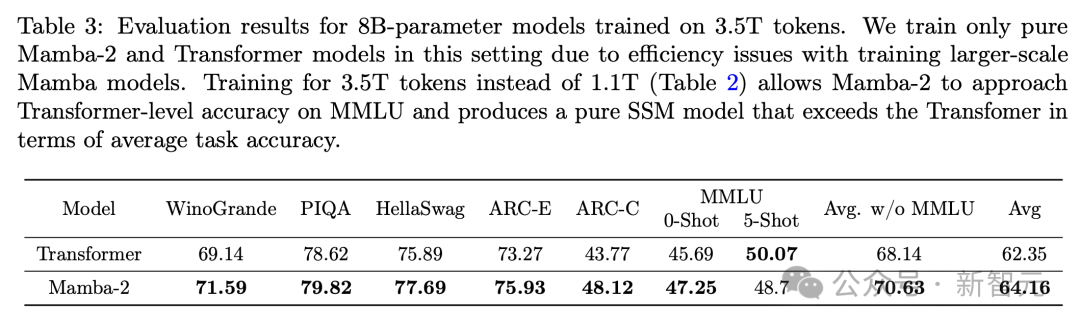
Как видно из таблицы 3, большее количество обучающих данных помогает «Мамбе-2» улучшить задачу MMLU. Разрыв в 5-ти выстрелах сокращается всего до 1,37 балла, а по остальным задачам он по-прежнему опережает «Трансформера».
Мамба не справляется с задачей MMLU и телефонной книги
Поскольку MMLU выглядит настолько аномальным в результатах многих последующих задач, в статье он разбирается и обсуждается более подробно.

Как показано на рисунке выше, задача MMLU аналогична вопросам с несколькими вариантами ответов на экзамене, но в закрытом формате альтернативные ответы также могут быть предоставлены модели в виде вопросов с заполнением пропусков. .
В таблице 4 представлены оценки каждой из трех моделей (обученных с помощью токена 1.1T) после разбивки MMLU по формату. В стандартном режиме и режиме множественного выбора архитектура Mamba проиграла Transformer, но в режиме «заполните пробелы» она фактически обогнала по баллам.

Объединив результаты таблицы 3, мы имеем основание сделать вывод, что содержание знаний, содержащееся в чистой модели SSM и модели Transformer, должно быть на одном уровне, но первая требует дополнительной подготовки для понимания первых двух форматов MMLU.
Автор приходит к выводу, что этот разрыв может быть обусловлен мощной способностью Transformer к контекстному обучению. Видно, что точность модели от 0 до 5 кадров очень очевидна.
Кроме того, модель SSM может быть не в состоянии напрямую направить знания, необходимые для ответа, в один токен ответа на выходе (т. е. в один из вариантов ABCD), в чем хорош уровень самообслуживания.
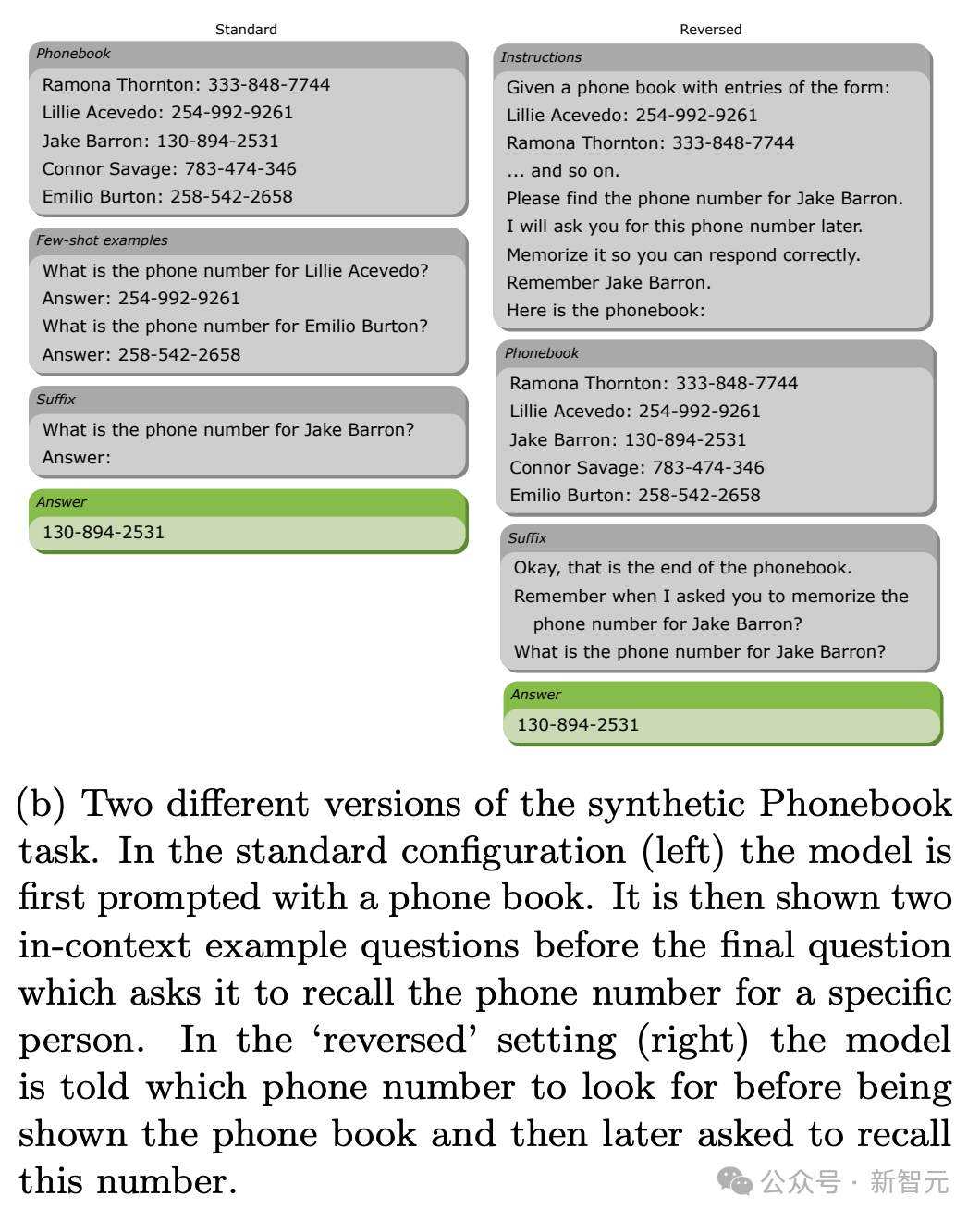
Кроме того, производительность моделей серии Mamba в «телефонной книге» не идеальна. Это задание предназначено для измерения способности модели изучать контекст с помощью нескольких примеров и копировать информацию из контекста.
На рисунке ниже показаны два варианта задачи. Стандартная версия сначала предоставляет всю телефонную книгу, а затем выдает целевой запрос; обратная версия сначала предоставляет запрос, а затем выдает телефонную книгу.
На рисунках 3а и в показана точность трех моделей для этих двух вариантов задачи соответственно.
Точность Transformer близка к 100%, когда длина телефонной книги не превышает длину предварительно обученного контекста (4096). Напротив, у Mamba и Mamba-2 наблюдается значительное снижение производительности, когда входная последовательность достигает 500 токенов.
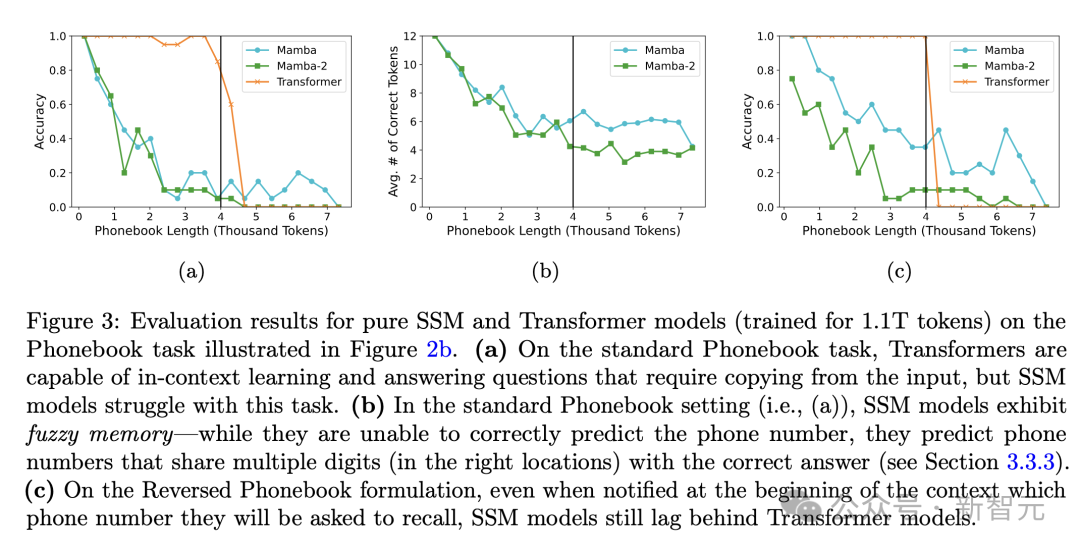
Если внимательно понаблюдать за выходными ответами серии Mamba (рис. 2b), то можно обнаружить, что модель архитектуры SSM не совсем неспособна запоминать контекстную информацию, но сохраняет некоторую нечеткую память, и несколько приведенных телефонных номеров обычно верны.
Основываясь на приведенных выше результатах, мы можем определить задачи MMLU и «телефонной книги» как сложные задачи для моделей чистой архитектуры SSM и предположить возможные причины: эти две задачи требуют изучения контекста, маршрутизации информации между токенами и возможности копирования из Они могут быть ахиллесовой пятой линейки моделей Mamba.
Гибридная архитектура SSM-Transformer
Поскольку я увидел недостатки архитектуры SSM в задачах MMLU и "Телефонная книга", автор задумался - может ли комбинация SSM и Transformer добиться эффекта дополнения сильных сторон друг друга?
Поэтому они добавили уровни самообслуживания и MLP в архитектуру Mamba, чтобы посмотреть, сможет ли модель преодолеть вышеуказанные проблемы.
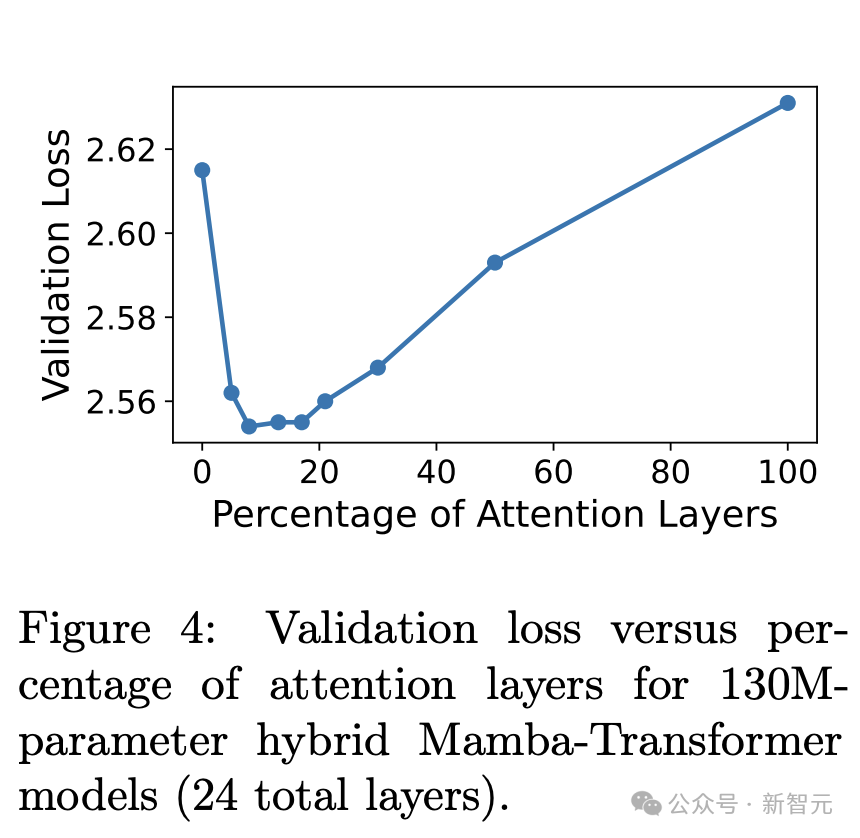
В статье сначала сообщаются результаты серии экспериментов по абляции. Путем сравнения производительности последующих задач исследуются конструкция архитектуры и параметры, позволяющие достичь наилучшей производительности (Таблица 6).

56-слойный «Мамба-2-Гибрид» включает в себя 4 (7,1%) слоя самообслуживания, 24 (42,9%) слоя «Мамба-2» и 28 (50%) слоев MLP, из которых слой «Мамба-2» использует модели «Мамба-2». имеют одинаковые параметры.
Выбор таких параметров, как самообслуживание, количество уровней MLP и коэффициент расширения уровня MLP, не является случайным, а представляет собой оптимизированную конструкцию, основанную на результатах значений потерь в проверочном наборе (рис. 4).
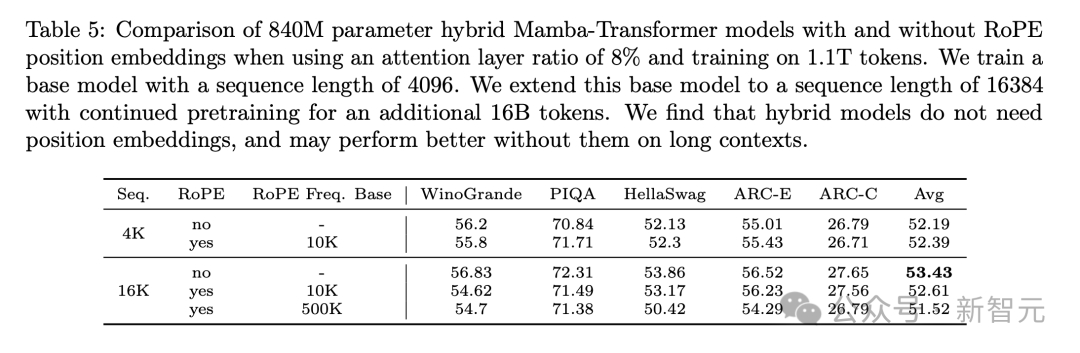
Результаты эксперимента по удалению также показывают, что отсутствие добавления кодирования положения вращения (RoPE) в гибридную модель может обеспечить лучшую производительность последующих задач (таблица 5), а также порядок слоев Mamba, уровня самообслуживания и уровня MLP. влияют на возможности модели.
Во-первых, слой Mamba должен появиться в начале архитектуры, чтобы модель естественным образом запоминала информацию о местоположении. По сравнению с использованием шаблонов повторяющихся блоков, это лучшая конфигурация для равномерного распределения внутреннего внимания и MLP по всей модели.
Более того, вычислив модель недоумения (недоумения) на проверочном наборе, мы можем знать, что по сравнению с многоголовым вниманием (MHA) использование уровня внимания группового запроса (GQA) может уменьшить объем вычислений вывода и памяти, но это Снижение качества вряд ли повлияет на модель.
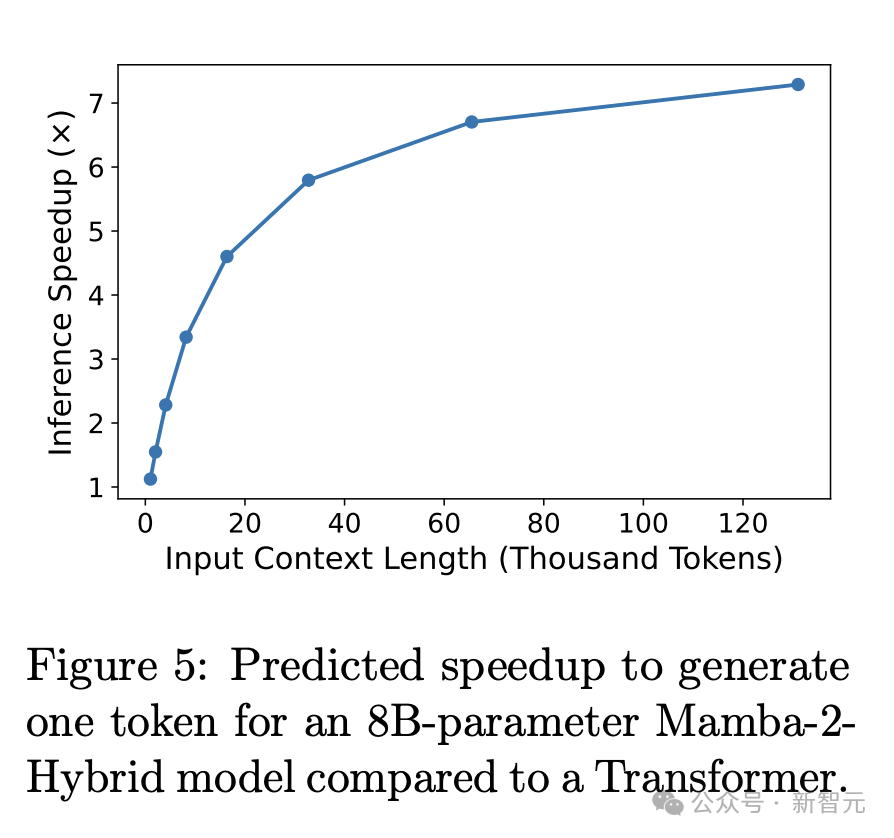
С точки зрения эффективности, Mamba-2-Hybrid достиг коэффициента использования FLOP (MFU) 29,9%, что в основном эквивалентно 30,7% Transfomer. Кроме того, первый имеет огромное преимущество в скорости вывода.
В сценарии с длинным контекстом, благодаря существованию нескольких уровней SSM, скорость генерации токенов Mamba-2-Hybrid почти в 8 раз выше, чем у Transformer (рис. 5).
Оценивать
Оценка показала, что эта гибридная архитектура действительно имела эффект «использования сильных сторон друг друга и компенсации слабых сторон». Гибридная архитектура превзошла как чисто трансформаторную архитектуру, так и архитектуру SSM в 5-этапной оценке MMLU, достигнув высочайшей точности (рис. 6). ).

В целом, судя по множеству тестов, представленных в таблице 7, Mamba-2-Hybrid более эффективен и превосходит модель Transformer.
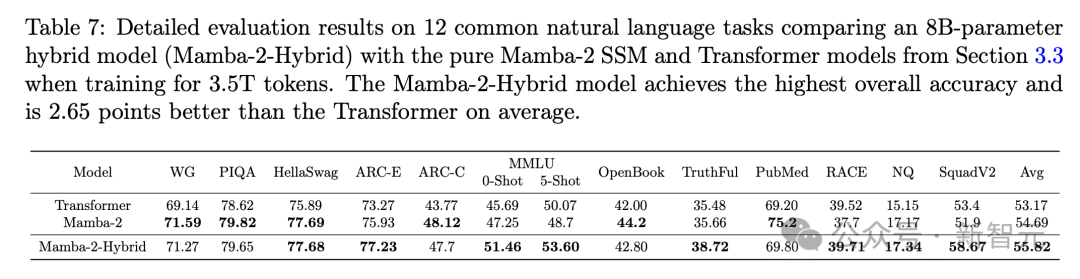
По сравнению с «Мамбой-2» возможности гибридной архитектуры с длинным контекстом также были значительно улучшены (табл. 10), а средняя производительность комплексных задач и задач «иголка в стоге сена» в бенчмарке RULER также превысила Transformer.
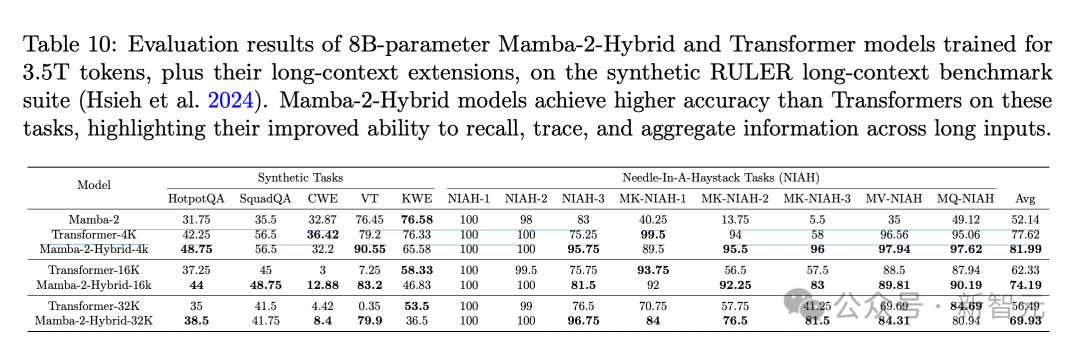
В задаче «телефонной книги», где серия Mamba работает плохо, Mamba-2-Hybrid может выполнить задачу телефонной книги с почти идеальной точностью в пределах длины контекста перед обучением (4 КБ), а также может обобщать немного больше этой длины. Достигните 100 % точности в телефонных книгах, используя до 5,5 000 токенов.
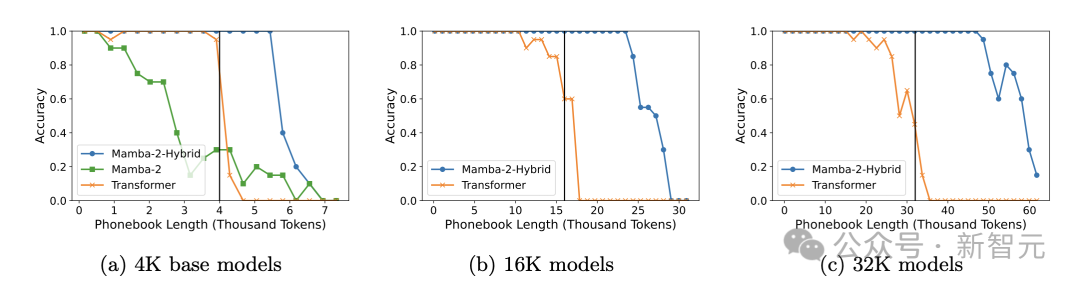
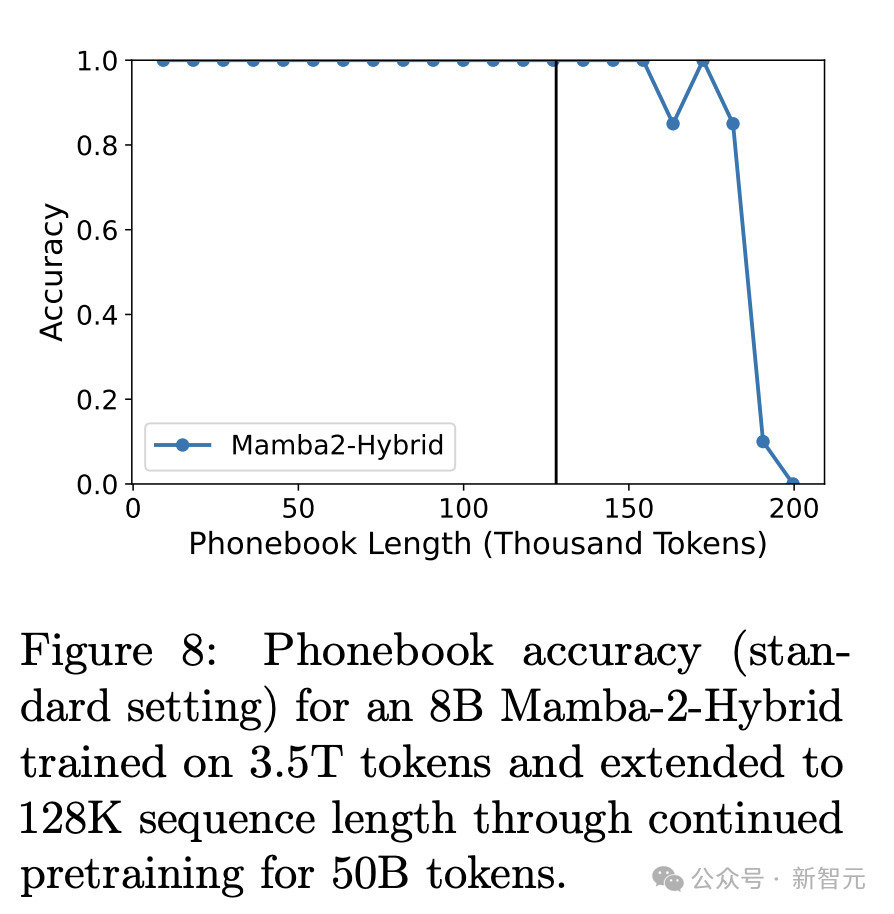
Даже потенциал Mamba-2-Hybrid на этом не заканчивается. Когда длина предварительного обучения увеличивается до 128 тыс. и используется глобальное внимание в 4 слоях самообслуживания, 100% точность задачи «телефонной книги» также распространяется на. почти 150 тысяч токенов.
в заключение
Результаты для Оценивать, начиная с бумаги, показывают, что,С большим бюджетом на обучение,Модель Pure SSM все еще может превзойти Transformer в последующих задачах.,Однако возможности контекстного обучения и поиска информации ограничены.
Исходя из этого, предложенная автором модель гибридной архитектуры Mamba-2-Hybrid может продолжать демонстрировать более высокую производительность, чем Transformer, при одновременном повышении эффективности и компенсировать соответствующие недостатки чистой SSM-архитектуры.
Комплексные результаты, показанные в этом исследовании, говорят нам, что две архитектуры Mamba и Transformer имеют свои сильные и слабые стороны, и, возможно, нет необходимости заменять одну другую. Объединение двух — это путь, который стоит изучить и имеет большой потенциал.
Целью этой статьи является академический обмен. Это не означает, что этот общедоступный аккаунт согласен с его взглядами или несет ответственность за подлинность его содержания. В случае каких-либо нарушений, пожалуйста, сообщите нам. удалите его.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
