Как в эпоху персонализированной экономики можно использовать голосовую модель MiniMax для C?

AI-рэпер, официально дебютирует.
Автор: Ван Юэ
Редактор: Чэнь Цайсянь
Около месяца назад, за две недели до запуска GPT Store, иностранный разработчик по имени Кайл Трайон поделился в своем личном блоге тремя агентами (также известными как «GPT»), разработанными на основе ChatGPT Plus. Персональный гид для путешествий по Филадельфии, США. Он может получить доступ к местному API общественного транспорта SEPTA и предоставлять людям информацию о местной погоде в реальном времени, туристическую информацию, культурные мероприятия, маршруты путешествий, данные об автобусных станциях и достопримечательностях, а также предполагаемое время прибытия в Филадельфию. и так далее.
Для получения подробной информации посетите ссылку PhillyGPT: https://chat.openai.com/g/g-GlYMtkbse-phillygpt.
За разработкой Philadelphia Personal Guide на самом деле стоит реальное представление людей о персонализированных потребительских продуктах C-стороны в эпоху GPT. По совпадению, после того как OpenAI официально запустила магазин GPT 11 января, помимо объявления о 3 миллионах GPT, она также поместила в список рекомендаций путеводитель по пешеходным маршрутам «AllTrails», тесно связанный с повседневной деятельностью пользователей. В отличие от отечественной критики перспектив крупных моделей, за рубежом полным ходом идет разработка большого количества персонализированных приложений.
В эпоху персонализированной экономики развитие отечественной крупномасштабной модели экономики фактически требует изменения старых идей решения проблем.
Среди крупных отечественных производителей моделей MiniMax входит в число «меньшинства», которое настаивает на инновациях и стремится к персонализированным приложениям. Исходя из этого первоначального замысла, с момента своего дебюта в начале марта прошлого года, когда большинство команд все еще находились на начальной стадии разработки языковых больших моделей, MiniMax выделился среди многолюдного рынка своим мультимодальным позиционированием больших моделей, и его оценка выросла. увеличивался семимильными шагами, став отечественной моделью оценки. Один из самых ценных крупных производителей моделей.
Особо примечательно, что MiniMax также является одной из немногих команд, делающих ставку на большие модели голоса.
В отличие от текста и изображений, исследования и разработки больших речевых моделей являются нишевыми, экология данных сообщества не является благополучной, и трудно получить большой объем высококачественных данных для обучения моделей. Однако в сценариях с большим количеством отдельных пользователей, таких как социальные сети, совместные развлечения и образование, голосовая связь часто является важным компонентом многих продуктов To C и B2B2C и полем битвы за крупномасштабную коммерциализацию модели.
Недавно MiniMax также выпустила новое поколение больших речевых моделей, которые по многим показателям производительности превосходят традиционные речевые технологии.
Возможности речевых моделей широко используются в собственном продукте MiniMax Hoshino. В недавнем конкурсе искусственного интеллекта, запущенном в приложении Hoshino, возможности речевой модели MiniMax были полностью продемонстрированы. Синтез речи не только может быть очень естественным, но также может имитировать рэп реального человека с различными трюками, приближаясь к уровню реальных рэперов.
(Хочу быть в Хосино AI следовать в бою AI battle rap из Друзья могут нажать:https://m.xingyeai.com/share/chat?npc_id=64236&share_user_id=54072629321819 опыт):
По данным AI Technology Review, новейшая большая речевая модель MiniMax обучается на основе миллионов часов высококачественных аудиоданных, и ее эффект не уступает эффекту ElevenLabs и OpenAI.
В то же время MiniMax также активно продвигает применение голосовых возможностей, создавая открытую платформу на стороне To B, постоянно совершенствуя голосовые возможности, необходимые пользователям B-стороны, и запуская продукт голосового диалога с искусственным интеллектом «Conch Wenqi». " на стороне C. Звук может быть воспроизведен за 6 секунд аудио.
В эпоху GPT большая модель экономики MiniMax разрушает ограничения одного текста и определяет новый смысл персонализированных приложений, начиная с «голоса».
1
Каждый пользователь кремния имеет право голоса
В эпоху AIGC спрос на генерацию речи на самом деле не меньше, чем на текст и изображения.
С точки зрения реализации ИИ, большие языковые модели могут предсказывать текстовые последовательности, что является первым шагом в разработке продуктов AIGC. Однако в практических приложениях эффект представления одного текста часто бывает плохим, а выразительная сила звука может быть низкой. используется для выражения содержания текста. Обеспечивает мощные благословения для эмоциональной окраски и выражения личности.
Возьмем, к примеру, генерацию видео с помощью ИИ. В сценарии, где технология искусственного интеллекта используется для создания коротких видеороликов, «драматичность» является основным недостатком, ухудшающим пользовательский опыт, а звук часто является «виновником» пользовательской драмы. При применении продуктов AIGC восстановление тембра символов, плавности речевого течения и интонации, естественности речевых пауз являются основными задачами технологии синтеза речи, и их необходимо решать в «пакете». одно и потерять другое. Любой недостаток уменьшит возможности пользователя.
Различные сценарии предъявляют разные требования к эффектам синтеза речи. Например, цифровая прямая трансляция требует, чтобы голосовое взаимодействие между ведущим и аудиторией было своевременным и с малой задержкой; воспроизведение аудиокниг требует быстрой пакетной генерации тембра и голосового контента нескольких персонажей, а образовательные и обучающие сценарии требуют возможности этого; понимать некоторые специальные слова и точное произношение необычных слов.
Поэтому предоставление пользователям высококачественного персонализированного голосового опыта и услуг на основе традиционной технологии синтеза речи стало следующей сложной проблемой в области генерации речи.
В прошлом технология синтеза речи, представленная на рынке, имела очевидные болевые точки:
- Сильное механическое ощущение,Причина в том, чтобы пожертвовать частью естественности человеческого голоса.,Звук не может передать эмоции;
- Один тон,Что касается невозможности предоставить пользователям на выбор множество тембров,Он не может удовлетворить разнообразные потребности различных сценариев;
- Высокая стоимость и неэффективность,Это требует профессионального оборудования и занимает много времени.
Чтобы решить эту серию проблем, многие ведущие производители в стране и за рубежом также провели соответствующие исследования.
Мультимодальная большая модель Google Gemini Попытайтесь легко понять и рассуждать о вводимом содержании трех популярных модальностей: текста, изображения и голоса. Однако на практике Близнецы. из текста、Зрение、Аудио считается“жесткийиз Статус сварки”。Подробнее о крупных компаниях в стране и за рубежом Модель Производительиз Информация приветствуется для добавления автора:s1060788086 Приходите и пообщайтесь.
Эффект синтеза речи у стартапа ElevenLabs потрясающий, но он больше подходит для английского текста и немного хуже синтезирует китайскую речь.
Существуют также модели TTS с открытым исходным кодом, такие как Tortoise и Bark, которые также собрали определенное количество пользователей. Однако, согласно отзывам пользователей, Tortoise медленно генерируется, а Bark имеет неравномерное качество звука, что в настоящее время затрудняет его коммерческое использование.
Конкурируя со своими аналогами, MiniMax также постоянно совершенствует свои собственные модели больших голосов. Последние модели больших голосов делают MiniMax первой крупной модельной компанией в Китае, открывшей коммерческий интерфейс для многосимвольного дублирования.
Опираясь на возможности больших моделей нового поколения, большая модель речи MiniMax может интеллектуально предсказывать эмоции, интонацию и другую информацию текста на основе контекста, а также генерировать сверхъестественную, высокоточную, персонализированную речь для удовлетворения индивидуальных потребностей различных людей. пользователи.
к《Легенда о Чжэнь Хуане》Китайская наложницаизвоспроизведение звукаНапример:
По сравнению с традиционной технологией синтеза речи, большая речевая модель MiniMax достигает нового уровня искусственного синтеза с точки зрения качества звука, разрывов предложений, ритма и ритма более точным и быстрым способом.
Комбинируя знаки препинания и контекстный контекст, речевая модель MiniMax может комплексно интерпретировать эмоции, тон и даже смех, скрытые за текстом, и точно уловить его.
В некоторых особых контекстах он также может отображать чрезвычайно драматическое голосовое напряжение. Например, когда говорящий смеется над шуткой друга, он также может соответствовать этой преувеличенной эмоции и одновременно смеяться от души:
Он даже может достичь состояния, когда воспроизводимый звук становится более естественным, чем исходный:
В дополнение к сверхъестественному эффекту генерации голоса AI, еще одной особенностью голосовой модели MiniMax является ее разнообразие и высокая расширяемость: она может точно улавливать уникальные характеристики тысяч тембров и свободно комбинировать их, чтобы легко создавать неограниченные изменения звука и стиля. Это преимущество может гибко соответствовать различным сценариям, таким как социальные сети, подкасты, аудиокниги, новостная информация, образование и цифровые люди.
2
Генерация длинной текстовой речи, цена API снижена вдвое
Начиная со второй половины 2023 года в крупной модельной индустрии возникнут два поля битвы: одно — длинный текст, а другое — коммерциализация. Конкуренция первых также сконцентрирована в текстовой сфере, и конкуренция от 32 тысяч до 200 тысяч стала жесткой. Генерация речи по-прежнему остается голубым океаном, в то время как коммерциализация вторых в основном отражается на цене;
Специалист по крупномасштабному моделированию рассказал AI Technology Review: «Технические барьеры для больших моделей уменьшаются, и в конечном итоге вопрос в том, кто первым сможет снизить затраты на обучение и внедрение моделей». больше не ChatGPT Когда он впервые стал популярным, выбор стоял между качеством высокопроизводительной модели и конкурентоспособными в отрасли продуктами и услугами.
В области генерации речи интерфейс преобразования текста в речь MiniMax также претерпел быстрые изменения:
12 сентября 2023 года MiniMax выпустила длинный интерфейс синтеза речи T2A pro. Один синтезатор речи может вводить до 35 000 символов. Он может регулировать интонацию, скорость речи, громкость, скорость передачи данных, частоту дискретизации и другие соответствующие параметры. . В основном подходит для аудиовизуализации длинных текстов.
15 ноября 2023 года был запущен асинхронный текстовый интерфейс MiniMax T2A big, позволяющий пользователям загружать текст длиной до 10 миллионов символов каждый раз.
17 ноября 2023 года MiniMax выпустила большую речевую модель abab-speech-01. Ее общие эффекты, такие как ритм и ритм, эмоциональное выражение, разнообразие стилей, смешение китайского и английского языков, многоязычность и другие возможности, были значительно улучшены.
Улучшая производительность модели, MiniMax также снизил цены на API: согласно официальным новостям, цены на три интерфейса преобразования текста в голос MiniMax T2A pro, T2A и T2A Stream недавно были снижены до половины первоначальной цены, с Стоимость 10 юаней/10 000 символов уменьшена до 5 юаней/10 000 символов.
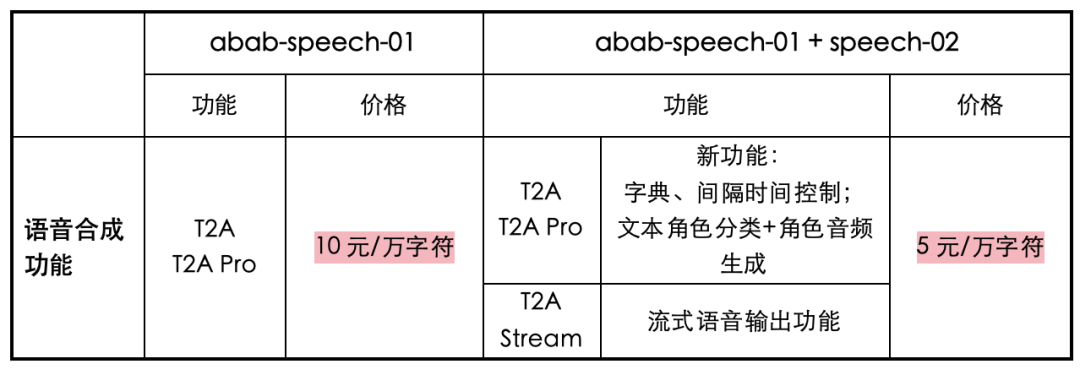
Основываясь на самостоятельно разработанной базе мультимодальных больших моделей, большая голосовая модель MiniMax также была использована в таких областях, как голосовые помощники, широковещательная передача информации, реплики IP и дублирование CV.
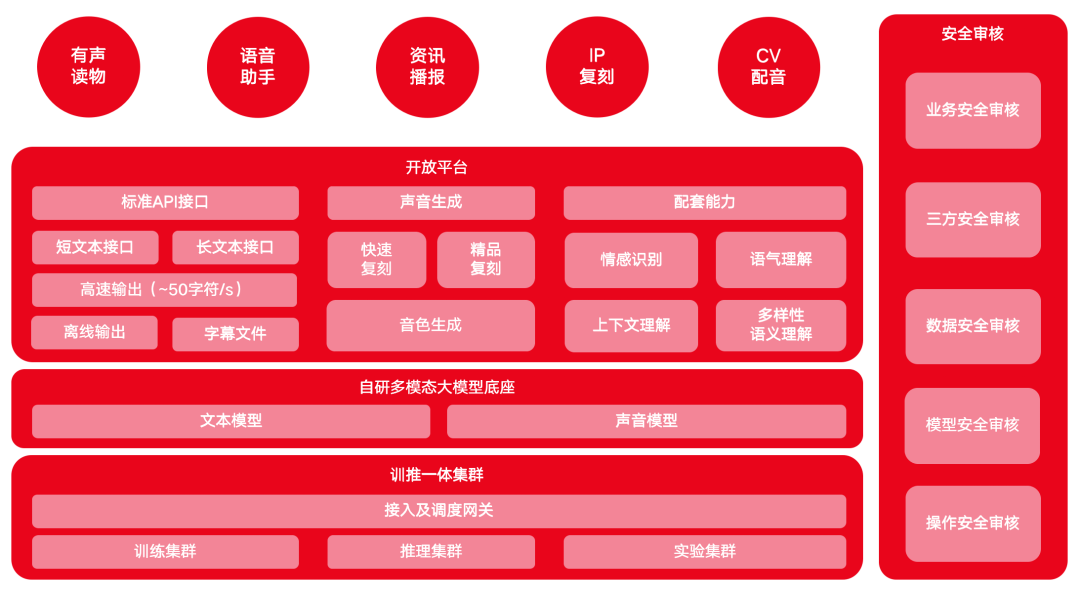
Архитектура продукта крупной модели MiniMax voice
Чтобы улучшить возможности модели для удовлетворения потребностей пользователей в высококачественной голосовой связи, в январе 2024 года в открытую платформу Mini Max были добавлены следующие функции продукта, основанные на исходных возможностях интерфейса:
- Добавлено три новых API интерфейс, соответственно, многоцелевой API генерации звука, классификация текстовых ролей API и быстрое воспроизводство API, в основном подходящий для независимой пакетной генерации и клонирования многосимвольных аудиосцен;
- Увеличить возможность T2A Stream (вывод потокового голоса),Сократите время ожидания для пользователей для генерации голоса,Реализуйте генерацию голоса и синхронизацию вывода;
- Увеличить многоязычные возможности、Функция словарь, функция управления интервальной продолжительностью,Удовлетворяйте богатые и индивидуальные потребности пользователей.
В частности, API классификации ролей текста может быстро различать разные диалоги, соответствующие разным символам, API генерации звука ролей может реализовать многоролевую дифференциацию и многоролевое вещание, а API быстрого воспроизведения может позволить пользователям быстро завершить воспроизведение голоса в Интернете. Три API используются вместе, чтобы предоставить полный набор решений для создания текстового голоса — более эффективное разделение символов, генерация многосимвольного голоса и полностью самостоятельное воспроизведение звука.
MiniMax рассказал AI Technology Review, что три новых API-интерфейса, добавленные к открытой платформе, предназначены для лучшей обработки более крупного текстового контента.
Когда дело доходит до генерации речи для длинных текстов, в прошлом практика заключалась в том, чтобы вручную отмечать роль каждого разговора, а затем использовать речевую модель для создания виртуального голоса. Недостатком является то, что это требует много времени и труда. Открытая платформа большой голосовой модели MiniMax использует интерфейсные вызовы, чтобы помочь пользователям более эффективно генерировать многосимвольные голоса.
Возьмем, к примеру, производство аудиокниг. Комбинация трех функциональных интерфейсов API открытой голосовой платформы MiniMax позволяет исключить этап ручного разделения текстовых ролей, автоматически понимать текст, разделять роли и создавать разные голоса для разных ролей. Присоединяйтесь к Qidian, чтобы создавать новые звуки искусственного интеллекта для аудиокниг «Мистер Рассказчик» и «Мисс Фокс», которые могут самостоятельно воспроизводить высококачественный звук онлайн через три интерфейса. Это может не только обеспечить согласованность тембров символов, но также обеспечить эффективное и быстрое дублирование нескольких символов.
T2A Stream (потоковая передача речи) быстро реагирует на обработку ввода длиной 500 символов. В сценариях, требующих немедленной обратной связи, речь генерируется в режиме реального времени в интерактивных беседах, и пользователи могут получать голосовые ответы без ожидания.
В то же время T2A Streaming имеет функции микширования и функции проверки символов для обеспечения качества выходного контента, а также предоставляет такие параметры, как интонация, скорость речи и громкость, которые пользователи могут регулировать в любое время. Он также поддерживает несколько аудиоформатов (MP3, WAV, PCM и т. д.) и возвращаемые параметры (продолжительность звука, размер и т. д.), а разработчики могут настраивать голосовые услуги в соответствии с потребностями конкретных приложений.
Чтобы удовлетворить индивидуальные потребности пользователей, большая голосовая модель MiniMax также была обновлена тремя новыми функциями:
Во-первых, это многоязычность, благодаря которой смешанный вывод китайского и английского языков звучит более естественно.
Смешанные многоязычные тексты представляют собой серьезную трудность при формировании речи, а частое переключение языка может привести к неестественному произношению. Речевая модель MiniMax улучшает возможности многоязычной обработки и может предоставить пользователям более реалистичный речевой опыт в таких сценариях, как преподавание иностранного языка и разговорный диалог.
Например, введите текст: «Вы можете сказать: «Зимой деревья голые, и все листья опали. Это описание ярко передает зимнюю сцену пустых, безлистных деревьев». Созданный звук. Эффект:
Вторая — функция словаря, которая позволяет пользователям настраивать произношение текста.
Когда речевая модель генерирует звуки на основе текста, будут наблюдаться неточное произношение и отклонения в произношении, особенно при столкновении с текстовым контентом, содержащим полифонические символы, специальные символы, текстовые сокращения и текст, созданный пользователем. Чтобы повысить точность произношения, в речевую модель MiniMax добавлена функция словаря, позволяющая пользователям самостоятельно определять произношение текста.
Например: «текст»: омг, рассказ Шаня Тяньфана — действительно идеальная имитация.
"char_ to pitch" (отметка) : ["Шань Тяньфан/(шань4)(тянь2)(фанг1)","омг/ох my god"]
Благодаря этой словарной функции полифонические слова и сокращения, такие как «Ямада Каору» и «omg», могут произноситься правильно в сгенерированной речи.
В-третьих, это функция контроля длины интервала, которая может значительно улучшить ритм паузы.
В речевую модель MiniMax добавлена функция контроля длины интервала, позволяющая разработчикам свободно добавлять в текст паузы разной длины, точно регулировать интервал между предложениями, улучшать ритм пауз и генерировать речь, более соответствующую реальным сценариям обучения.
Эта функция чаще используется в сценариях образования и преподавания. Среди них цифровой человек для вступительных экзаменов в аспирантуру с искусственным интеллектом «Учитель Вэнь Юн», созданный в сотрудничестве с Гаоту, может использовать эту функцию, чтобы лучше слушать лекции и отвечать на вопросы, чтобы студенты может иметь более плавный опыт обучения.
Кроме того, эта функция управления длительностью интервала также делает персонажей аудиокниг или цифровое человеческое дублирование более естественным. Она может эффективно обратить вспять механическое ощущение традиционной речи без пауз, увеличить ритм речи и приблизиться к привычкам выражения реальных людей.
В обучающих сценариях мы часто сталкиваемся с такими разговорами:
Воспитатель сказал: Здравствуйте, дети! Я ваш учитель математики, и у меня есть для вас небольшое задание. Пожалуйста, послушайте вопрос: у Сяо Мина есть 7 яблок, если он отдаст их Сяо Хуа. 3 Яблоки, сколько яблок осталось у Сяо Мина? для тебя 10 Секунды времени, чтобы подумать,Иди узнай!< <#10#> Время вышло! Кто-нибудь может сказать мне, какой ответ? Кстати, у Сяо Мина еще осталось 4 яблока, так что поздравляю, вы ответили правильно! потому что 7 минус 3 равный 4. Значит, у Сяо Мина еще есть 4 яблоко.
здесь,Используйте контрольные коды<#X#> (в X это числовая переменная, Единица измерения — секунды, диапазон значений — от 0.01 приезжать 99.99 Секунды), добавив отметку интервала, вы можете добавить к тексту желаемую длительность голосовой паузы пользователя.
3
Конч спрашивает Си:
Голос приближает людей к ИИ
С момента своего создания MiniMax славится инновациями в форме продуктов To C.
в соответствии с MiniMax выяснилось, что они используют его в коммерческих целях To B и To C Ходить на двух ногах одновременно в глазах инвесторов и рынка – это свое дело; C Инновации в производстве высококачественной продукции не имеют аналогов среди крупных производителей моделей в стране. Glow приезжать Хосино,MiniMax из C Высококачественная продукция всегда привлекала внимание людей.
To C Уровень, Мини Макс изголосбольшой Модель также имеет уникальное преимущество, что впервые отражается в ее диалоговом продукте. о раковиненачальство。

На этом большом языке Модель основанного на технологии изголосового диалогового продукта MiniMax самоисследованиеголосбольшой Модельизблагословениепозволять Вопрос о Сумка выделяется среди аналогичного продукта. ИИ После оценки из первых рук журнал Technology Review был больше всего удивлен сверхъестественными эффектами и высокой точностью воспроизведения. Если говорить только об опыте прослушивания, Вопрос о При выводе звука вопросов и ответов трудно отличить, является ли это голосом реального человека или синтезированной версией голоса модели.
Например,На вопрос приезжать "Куда пойти поиграть на выходных?",Вопрос о вывод изголоса похож на индивидуального друга из диалога, общения, обсуждения другой стороны, а не на традиционный AI Синтезируйте голос механически, слово за словом, чтобы генерировать контент.
Слушайте приезжать интересные вопросы, Вопрос о Раке будет смеяться, когда приезжать затрудняется ответить на вопросы, Вопрос о Макке будет размышлять и делать паузу, как бы «думая». Если не MiniMax Убедитесь, что это есть в Вопросе о наушнике подключен к голосовой модели, и пользователи, скорее всего, подумают, что другой конец машины отвечает на вопросы реального человека.
Чтобы добиться эффекта разговора в реальном времени, вопрос о Наушник превосходно работает с низкой задержкой, без необходимости использования традиционных больших моделей. 5 - 10 Секунды времени на размышления проходят. T2A Stream Возможность вывода мгновенно. Помимо голосовой панели в интерактивной форме, вы также можете нажать UI Нажмите маленький значок телефона в правом нижнем углу интерфейса, чтобы начать звонки в режиме реального времени.
Перед официальным звонком пользователи могут выбрать AI выходизтон。в,И «Имитировать медведя 2», и мультяшный стиль.,Еще есть дружелюбный женский голос типа «Сердце Радость».,Еще есть «Цысюань» с глубоким и притягательным мужским голосом.,Есть еще «Жирный апельсин», похожий на репрезентативный тон королевской семьи в костюмированных фильмах и теледрамах.
Помимо системных пресетов и десятков звуков разных стилей, Вопрос о Вы также можете создавать свои собственные звуки и быстро воспроизводить их с низкими сэмплами за более короткое время. Просто нужен рут соответствии с интерфейсом из команды, прочитать абзац 40 Слова или около тогоизданныйтекст,подожди несколько секунд,Вы можете слушать собственный голос с высокой степенью восстановления.

Таким образом, каждый обычный пользователь, использующий Вопрос о наушниках, может легко реализовать неограниченные потребности в воспроизведении звука.
Но на самом деле,На современном рынке возможность копирования копий часто требует оплаты. Многие поставщики прикладного уровня AIGC будут рассматривать его как один из своих собственных продуктов.,Пользователям приходится тратить время и усилия на запись собственного звука.,Это будет стоить на несколько тысяч или даже десятков тысяч больше.,Платите за реалистичные копии. На этом основании,Также необходимо ограничить количество, продолжительность и предмет использования.,Это прибыльный бизнес.
И вопрос о Sockе бесплатен для пользователей, которые могут разрабатывать решения Функция звуковиз не только бесплатна, но и не ограничивает продолжительность и количество использований. В то же время процесс работы также очень прост, просто 6 Вы можете получить клонированный звук за считанные секунды, что, несомненно, сокращает использование людьми AI Измените порог жизни и производства и сделайте его в значительной степени удобным для вас.
Много отзывов пользователей будет в Вопросе о Запишите голос своей матери в наушник, чтобы вы могли APP Когда вы спрашиваете о жизненных проблемах, создается ощущение, что ваша мама всегда рядом, чтобы ответить на ваши вопросы. Когда вы хотите найти рецепты, такое ощущение, будто ваша мама учит вас готовить. Некоторые люди даже сохраняют голос любимого человека. потерял близкого человека в вопросе о В раковине прошлое вспоминается через звук.
Также вопрос о Смысл раковинеиз не ограничивается тем, что пользователь задает вопросы, а агент отвечает. В большей степени это программа для чата, которая может общаться по своему желанию. Не нужно уделять особое внимание точности и стандартизации предложений, как и письменных выражений. Вы можете говорить все, что хотите, и говорить все, что хотите, Вопрос. о Джеке может это выдержать,Иногда даже ведут тему,Задавайте вопросы заранее.
Еще больше стоит ожидать того, что функция обмена голосом будет доступна на Вопросе в ближайшие два дня. о Джеке сейчас на сайте. ИИ Обзор технологий изучается эксклюзивно,через эту функцию,Пользователи могут общаться друг с другом с помощью методов, аналогичных красным конвертам с паролями.,Поделитесь своими клонированными голосами друг с другом в социальных сетях, таких как WeChat.,Дальше реализуйте «голоссоциальный».
Лучше AI Звук говорит и приятный, как голос человека, MiniMax. Модель в вопросе. Ряд попыток совершить технологические прорывы — это большой шаг на пути к устранению барьеров между человеком и искусственным интеллектом.
прошлое,Искусственный интеллект для понимания голоса,Это необходимо для повышения точности голосового ввода и вывода. Сейчас,MiniMax не забывает сосредоточиться на интерактивных эффектах, влияющих на взаимодействие с пользователем.,Это отражает стратегическое видение и возможности реализации компании «Божий свет».
2024, Мини Макс Сделать первый шаг к большому голосу Модель, возможно, стоит того, чтобы каждый исследователь в той же отрасли задумался: в каком направлении современный мир собирается развивать технологии? Как именно нужна большая модель? Что именно вы хотите сделать?



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
