Как различать сценарии больших данных в автономном режиме и в режиме реального времени
Существенная разница между автономной пакетной обработкой и потоковой обработкой в реальном времени.
Разница между оффлайн и реальным временем не в скорости.
Сценарии применения больших данных обычно делятся на сценарии автономной обработки и сценарии обработки в реальном времени. Это справедливо и для традиционного развития, то же самое.
Есть ли у вас какие-либо идеи относительно сценариев вычислений в автономном режиме и в реальном времени?
Ваше первое впечатление может заключаться в том, что обработка сцен в автономном режиме происходит медленнее, тогда как обработка сцен в реальном времени происходит относительно быстрее, и вы можете получить результат обработки более своевременно.
Но по сути это не то, как отличить оффлайн от реального времени. Фактически, когда объем данных невелик, автономная обработка может быть очень быстрой; когда объем данных велик, обработка в реальном времени также может быть очень медленной.
Существенная разница между автономным режимом и режимом реального времени заключается в том, являются ли обрабатываемые данные ограниченными или неограниченными.
Что такое сценарий автономной обработки?
В качестве примера возьмем сценарий автономной обработки. После того, как данные сгенерированы из источника данных, мы сначала сохраняем их. Где бы вы его ни сохранили, если предположить, что сохраненные данные составляют 10 ГБ, эти 10 ГБ данных не будут увеличиваться или уменьшаться при последующих операциях. Он установлен на уровне 10 ГБ.
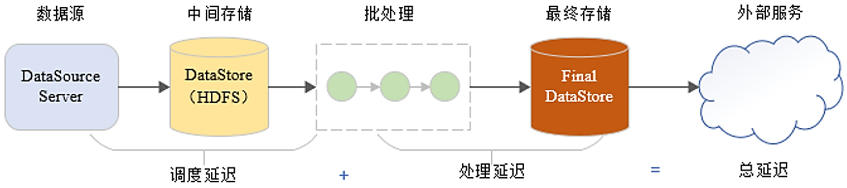
Мы выполняем операции на основе этих 10 ГБ данных. Операции, завершенные в это время, являются оффлайн-операциями. Автономные операции наиболее подходят для пакетной обработки. После обработки выведите окончательный результат и сохраните его.
С точки зрения программы пакетной обработки данные, которые мы обрабатываем, представляют собой сохраненный набор данных, который представляет собой ограниченные данные. При хранении он равен 10 Г, а при обработке также равен 10 Г. Он не увеличивается и не уменьшается.
Конечно, офлайн имеет и другое значение: вы можете напрямую отключиться от Интернета после сохранения данных. Эта часть данных может быть обработана, даже если сеть прервана.
Что такое сценарий обработки в реальном времени?
Сценарий обработки в реальном времени отличается. После того, как данные сгенерированы из источника данных, они немедленно передаются на обработку задаче потоковой обработки. Вычислительные задачи могут быть написаны на Java или Python. Независимо от того, какая это вычислительная задача потоковой обработки, она должна работать круглосуточно и без перерывов, чтобы обеспечить своевременную обработку данных.
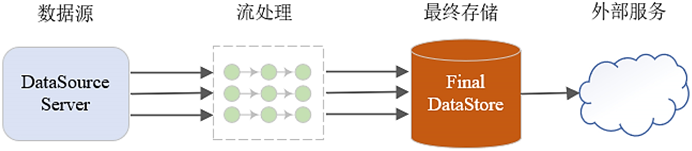
Результаты обработки могут сохраняться и обновляться в режиме реального времени, что позволяет вызывать и отображать внешние службы в режиме реального времени.
Поскольку данные из источника данных генерируются в реальном времени, с точки зрения задачи потоковой обработки, являются ли эти данные ограниченными или неограниченными? Оно не должно иметь границ. Это происходит в реальном времени, как будто не имеет границ и всегда течет.
Обработка такого рода неограниченных данных называется обработкой в реальном времени.
Два способа обработки данных: пакетная обработка и потоковая обработка.
При обработке такого рода данных в реальном времени мы обычно используем потоковую обработку. Поэтому иногда, когда упоминаются автономная пакетная обработка и потоковая обработка в реальном времени, они упоминаются вместе. Автономные сценарии подходят для операций пакетной обработки, а сценарии реального времени подходят для операций потоковой обработки.
В операции пакетной обработки после получения данных сначала все данные проходят через первый этап обработки, а затем отправляются окончательный результат на следующий этап для обработки.
Это означает, что при пакетной обработке при наблюдении в любой момент времени можно обнаружить, что все данные должны находиться на определенном этапе одновременно.
Существуют различные методы обработки потока. Каков метод обработки потока?
Потоковая обработка работает так же, как рабочие на сборочной линии: первый рабочий отвечает за первый этап, второй — за второй этап и так далее.
Они ждут передачи данных. После поступления данных приступают к обработке. После завершения обработки результаты обработки сразу передаются на следующий этап. Затем продолжайте ждать поступления новых данных.
Как только данные доступны, они обрабатываются и после обработки передаются на следующий этап. Каждый этап такой.
При потоковой обработке, когда вы наблюдаете за ней в любой момент, вы можете обнаружить, что данные существуют в несколько этапов. Вот в этом они и различаются.
Краткое описание: Разница между автономной пакетной обработкой и потоковой обработкой в реальном времени.
Автономная пакетная обработка и потоковая обработка в реальном времени — эту концепцию каждый должен четко различать. Автономная обработка и обработка в реальном времени в основном сосредоточены на том, ограничены ли данные или нет. Ограниченный означает обработку в автономном режиме, а неограниченный означает обработку в реальном времени.
Автономные данные подходят для пакетной обработки. Данные в реальном времени подходят для потоковой обработки.
Типичные сценарии пакетной обработки в автономном режиме включают хранилище данных, поиск и извлечение, графические вычисления и анализ данных, которые являются автономными сценариями.
Для сценариев обработки в реальном времени существуют хранилища данных в реальном времени, анализ данных в реальном времени, машинное обучение в режиме реального времени и т. д. Все задачи, требующие обработки в реальном времени, относятся к этому сценарию.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
