Как обрабатывать 15 миллиардов логов в день и обрабатывать большие запросы в течение 1 секунды
Этот вариант использования хранилища данных предполагает масштабирование. Пользователем является компания China Unicom, один из крупнейших в мире поставщиков телекоммуникационных услуг. Развернул несколько кластеров размером в петабайты на десятках компьютеров с использованием Apache Doris для поддержки 15 миллиардов журналов, добавляемых ежедневно более чем 30 направлениями бизнеса. Такая большая система анализа журналов является частью управления сетевой безопасностью. Из-за необходимости мониторинга в реальном времени, отслеживания угроз и оповещения пользователям нужна система анализа журналов, которая может автоматически собирать, хранить, анализировать и визуализировать журналы и записи событий.
С точки зрения архитектуры система должна иметь возможность выполнять анализ журналов в различных форматах в режиме реального времени и, конечно же, быть масштабируемой для поддержки больших и постоянно растущих масштабов данных. В этой статье рассказывается о том, как выглядит архитектура обработки журналов пользователя и как добиться стабильного приема данных, недорогого хранения и быстрого выполнения запросов.
Архитектура системы
Это конвейер данных пользователя. Журналы собираются в хранилище данных и обрабатываются на нескольких уровнях.
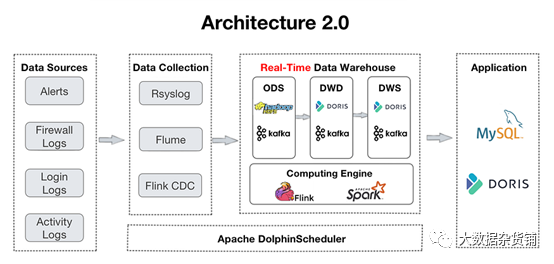
- ODS: собираются необработанные бревнои оповещения из всех источников. Apache Kafka середина. При этом их копии будут находиться в HDFS для проверки или воспроизведения.
- DWD: Здесь находится таблица фактов. Апач Flink Очистите, стандартизируйте, заполните заново, деидентифицируйте данные и запишите их обратно. Кафка. Эти таблицы фактов также будут помещены в Apache Doris так что Doris Отслеживайте проект или используйте его для информационных панелей и отчетов. Поскольку Бревно не возражает против дублирования, таблица фактов будет следовать Apache. Doris Дублировать Key Модель по договоренности.
- DWS: этот уровень агрегирует информацию из DWD и закладывает основу для запросов и анализа.
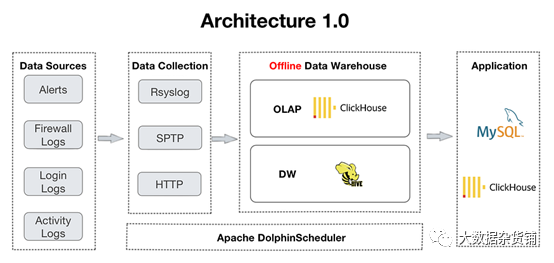
- ADS: на этом уровне Apache Doris использовать его Aggregate Key Модель автоматически агрегирует данные и использует уникальные Key Модель Номер автоматического обновления Архитектура 2.0 из Архитектура 1.0 разработан из ClickHouse и Apache Hive поддерживать. Этот сдвиг обусловлен потребностями пользователей в обработке запросов на объединение нескольких таблиц в реальном времени. По использованию ClickHouse По опыту пользователи обнаружили недостаточную поддержку параллелизма и многотабличных соединений, что проявляется в частых тайм-аутах информационной панели и OOM в распределенных соединениях. ошибка.
Теперь давайте посмотрим на практику пользователей по приему, хранению и запросу данных с использованием Архитектуры 2.0.
Упражнения на реальных кейсах
Стабильная обработка 15 миллиардов журналов каждый день.
Бизнес пользователя генерирует 15 миллиардов журналов каждый день. Быстро и стабильно обрабатывать такой большой объем данных — настоящая проблема. Для Apache Doris рекомендуемый подход — использовать Flink-Doris-Connector. Он разработан сообществом Apache Doris для крупномасштабной записи данных. Этот компонент требует простой настройки. Реализация потоковой загрузки позволяет достичь скорости записи 200 000–300 000 журналов в секунду без прерывания рабочей нагрузки по анализу данных.
Полученный опыт показывает, что при использовании Flink для высокочастотной записи вам необходимо найти подходящую конфигурацию параметров в соответствии с вашей собственной ситуацией, чтобы избежать накопления версий данных. В ответ на эту ситуацию пользователь произвел следующие оптимизации:
- Flink Контрольная точка: измените интервал контрольной точки с 15 секунды увеличились до 60 секунды для уменьшения частоты записи и единицы времени Doris Количество обработанных транзакций. Это может облегчить нагрузку на запись данных и избежать создания слишком большого количества версий данных.
- предварительная агрегация данных: для данных с одинаковым идентификатором, но из разных таблиц,Flink предварительно агрегирует и создаст плоскую таблицу на основе идентификатора первичного ключа.,Во избежание чрезмерного потребления ресурсов, вызванного записью данных из нескольких источников.
- Doris Сжатие: советы здесь включают в себя поиск правильных параметров серверной части Doris (BE) для выделения соответствующего объема ресурсов ЦП для сжатия данных, настройку соответствующего количества разделов данных, сегментов и реплик (слишком много фрагментов данных приведет к огромным накладным расходам) и набор max_tablet_version_num Чтобы избежать накопления версий.
В совокупности эти меры обеспечивают стабильность ежедневного приема данных. В ходе процесса пользователи стали свидетелями стабильной производительности и низкого показателя сжатия серверной части Doris. Кроме того, предварительная обработка данных в Flink сочетается с моделью уникального ключа в Doris, что обеспечивает более быстрое обновление данных.
Стратегия хранения снижает затраты на 50 %
Размер и скорость создания журналов также оказывают давление на хранилище. Лишь часть массивных данных журнала имеет высокую информационную ценность, поэтому ее следует хранить дифференцированно. Пользователи применяют три стратегии хранения для снижения затрат.
- Алгоритм сжатия ZSTD (ZStandard): для таблиц размером более 1 ТБ при создании таблицы укажите метод сжатия «ZSTD», что обеспечит степень сжатия 10:1.
- Хранилище горячего и холодного многоуровневого хранения данных: это поддерживается новой функцией Doris. Пользовательские настройки 7 данные период «остывания». Это означает, что данные (т. е. «горячие» данные) за последние 7 дней будут находиться на SSD. Со временем тепловые данные «остывают» (более 7 небо),Он автоматически перейдет на более дешевый жесткий диск. Поскольку данные становятся более «холодными»,Он будет перенесен в хранилище объектов.,Чтобы значительно снизить стоимость хранилища. кроме того,в хранилище объектов,данные будут обслуживать только одну порцию вместо трех. Это еще больше снижает затраты и административные накладные расходы, связанные с резервированием.
- Разные номера копий для разных разделов данных: пользователи разделяют данные по временному диапазону. Принцип состоит в том, чтобы предоставить больше реплик для новых разделов данных.,Предоставляйте меньше копий для старых разделов данных. в своих приложениях,прошлое 3 месяцы данных часто посещаются, поэтому для этого раздела у них есть 2 копии. Есть две копии данных от 3 до 6 месяцев назад и одна копия данных от 6 месяцев назад.
Благодаря этим трем стратегиям затраты пользователей на хранение данных сокращаются на 50%.
Дифференцированные стратегии запросов в зависимости от размера данных
Некоторые журналы необходимо отслеживать и обнаруживать немедленно, например журналы аномальных событий или сбоев. Чтобы обеспечить ответ на эти запросы в режиме реального времени, пользователи используют разные стратегии запросов для разных размеров данных:
- Менее 100 ГБ: используйте функцию динамического разделения Doris. Небольшая таблица будет разделена по дате.,Большая таблица будет разделена по часам. Это позволяет избежать искажения данных. Для дальнейшего обеспечения баланса данных внутри раздела,Используйте идентификатор снежинки в качестве поля группировки. Также устанавливает начальное смещение в 20 дней.,Это означает, что будут сохранены данные за последние 20 дней. таким образом,Найдите баланс между резервом данных и потребностями анализа.
- 100G~1T: Эти таблицы имеют материализованные представления.,Является ли хранилище предварительно вычисленным набором результатов в Doris. поэтому,Запросы к этим таблицам выполняются быстрее и потребляют меньше ресурсов. Синтаксис DDL материализованных представлений в Doris такой же, как в PostgreSQL и Oracle.
- Более 100T: эти таблицы помещаются в Apache. Агрегат от Дорис Ключевая модель и предварительно полимеризованная. Таким образом, 20 Миллиардов можно пройти за 1-2 секунды. запрос записи журналов.
Эти стратегии сокращают время ответа на запросы. Например, запросы к конкретным элементам данных, которые раньше занимали минуты, теперь могут быть выполнены за миллисекунды. Для больших таблиц с десятками миллиардов данных запросы в разных измерениях могут быть выполнены за несколько секунд.
Текущие планы
Пользователь тестирует новый инвертированный индекс в Apache Doris. Предназначен для ускорения полнотекстового поиска строк, а также запросов на равенство и диапазон чисел и даты и времени. Пользователи также предоставили ценные отзывы о логике автоматического распределения сегментов в Doris: в настоящее время Doris определяет количество сегментов для раздела на основе размера данных предыдущего раздела. Проблема в том, что пользователи вводят большую часть новых данных днем и очень мало — ночью. В результате Дорис создает слишком много сегментов для ночных данных и слишком мало для дневных, что прямо противоположно тому, чего хотят пользователи. Пользователь хочет добавить новую логику автоматического распределения по сегментам, чтобы определять количество сегментов на основе размера и распределения данных предыдущего дня. Мы работаем над этой оптимизацией.
Автор оригинала: Апач Дорис



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
