Как Mini Program создает систему анализа портретов пользователей на уровне десятков миллиардов?

Введение | We Анализ — это платформа анализа данных, официально запущенная WeChat Mini Program для поставщиков услуг мини-программ, в которой портретное понимание является очень важным функциональным модулем. Инженер-разработчик WeChat Чжун Вэньбо расскажет We Проанализировать, как устроен каждый модуль системы визуализации, представить существующий Базовый модуль После этикеток сосредоточьтесь на Модуль. группы Разработано пользователями. Надежда, связанная с Технической идеи реализации могут вас вдохновить.
Оглавление
1 Общие сведения
1.1 Краткое описание системы визуализации
1.2 Цели проектирования системы изображений
2 Общий обзор системы визуализации
3 Базовый модуль этикеток
3.1 Описание функции
3.2 Техническая реализация
4 Модуль группы пользователей
4.1 Описание функции
4.2 Прогноз толпы в реальном времени
4.3 создание толпы
4.4 приложение для отслеживания толпы
5 Резюме
01
Предыстория
1.1 Краткое описание системы визуализации
We Analysis — это платформа анализа данных, официально запущенная Mini Programs для поставщиков услуг мини-программ, в которой портретное понимание является важным функциональным модулем. Эта функция предоставит пользователям базовые возможности анализа портретных тегов и предоставит настраиваемые функции группировки пользователей для удовлетворения более персонализированных потребностей анализа и поддержки большего количества портретных сценариев приложений.
До этого исходный портретный анализ MP включал только базовые портреты, что было эквивалентно анализу только основных атрибутов рынка мини-программ за фиксированный период, но не мог анализировать и применять его к конкретным группам людей или индивидуальным группам. Пользователи, находящиеся на вершине платформы, надеются, что платформа предоставит полные возможности анализа изображений. В дополнение к самым базовым атрибутам портрета он также предоставляет пользователям более богатые теги и более гибкие возможности приложений для групп пользователей. Поэтому мы анализируем планы по оптимизации соответствующих возможностей.
1.2 Цели проектирования системы изображений
- Простота использования:Простота Использование в основном означает, что когда пользователи уже используют функцию портретного анализа, они могут начать использовать ее напрямую, без затрат на обучение. Пользователи могут решать задачи на основе собственных бизнес-сценариев и использовать их «из коробки». 0 порог.
- стабильность:стабильность Относится к стабильности системы, надежности и хорошему опыту.。Например, данные портретной этикетки.、Крауд-пакеты производятся стабильно и вовремя,существуют Высокая скорость запросов во время интерактивного использования,Достигните ощущения гладкости и шелковистости.
- Полнота:Относится к богатству данных、Гибкие правила、Полные функции поддерживают богатые данные выбора толпы и предустановленные метки;、тег толпы、поведение платформы、Настройте поведение отчетов и т. д. Платформа будет в основном предоставлять данные, которые нужны пользователям, без нарушения конфиденциальности.
общий,Платформа поддерживает гибкие теги и методы создания толпы.,Пользователи могут произвольно выбирать нужную группу людей по собственным представлениям.,Выбирайте крауд-пакеты вручную или автоматически в зависимости от разных периодов. Кроме того, он также поддерживает анализ отслеживания толпы.,Crowd существует, имеет множество сценариев применения и многое другое.
02
Общий обзор системы визуализации
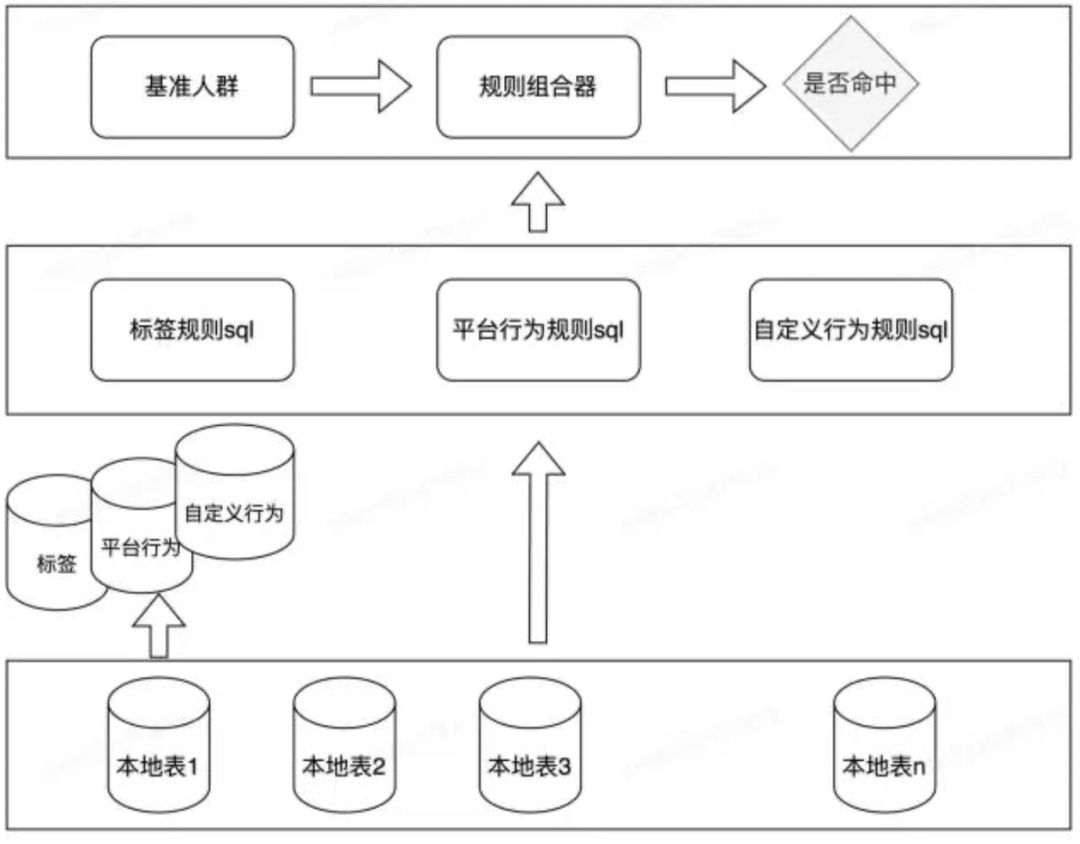
система изФорма продуктаиз Начиная с перспективы,существовать Следующее подразделяется на2модули для объяснения——Они естьБазовый модуль этикетоки Модуль группы пользователей。
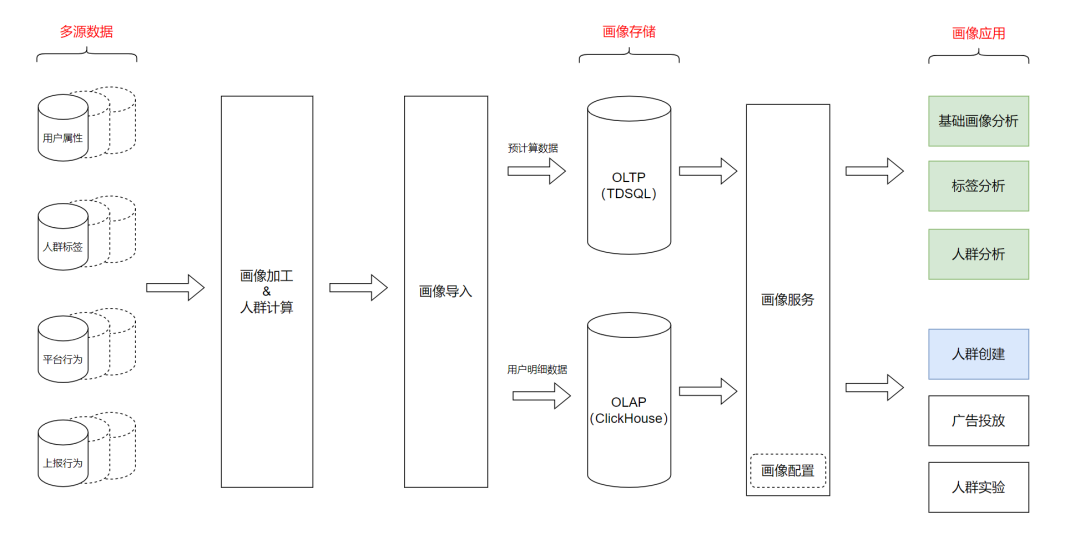
- Данные из нескольких источников:Источник данных включает свойства пользователя.、тег толпы、поведение платформыданные、Настройте данные отчетов.
- Обработка изображения:В основном для пользовательских атрибутов、тег толпы、поведение платформы,Провести соответствующие ETL(Extract Transform Load , извлечение нагрузки преобразования) и предварительные вычисления.
- Расчет толпы:По определению пользователяиз Правила группировки пользователей,Соответствующие популяции рассчитываются на основе данных из нескольких источников.
- Ввод изображения:изображениеитолпаданныесуществовать TWD После обработки из TWD распределенный HDFS Импортируйте кластер онлайн TDSQL 、 ClickHouse Среди них предварительно рассчитанные данные импортируются онлайн; TDSQL хранилище, поведение пользователей и другие подробные данные импортируются онлайн. ClickHouse в кластере.
- Портретная услуга:поставлятьсуществовать Проволокаиз Интерфейс сервиса изображений。В управлении тегами используется универсальная система конфигурации.,Служба данных использует разработку инфраструктуры RPC,существовать Верхний уровень — платформа.изданные中间件。Управление потоком здесь также унифицировано、асинхронный вызов、Мониторинг звонков、и проверка безопасности параметров.
- Портретное приложение:поставлять基础анализ тегови针对特定толпаизанализ тегов,Кроме того, он также предоставляет анализ отслеживания выбора толпы и онлайн-приложения.
03
Базовый модуль этикеток
3.1 Описание функции
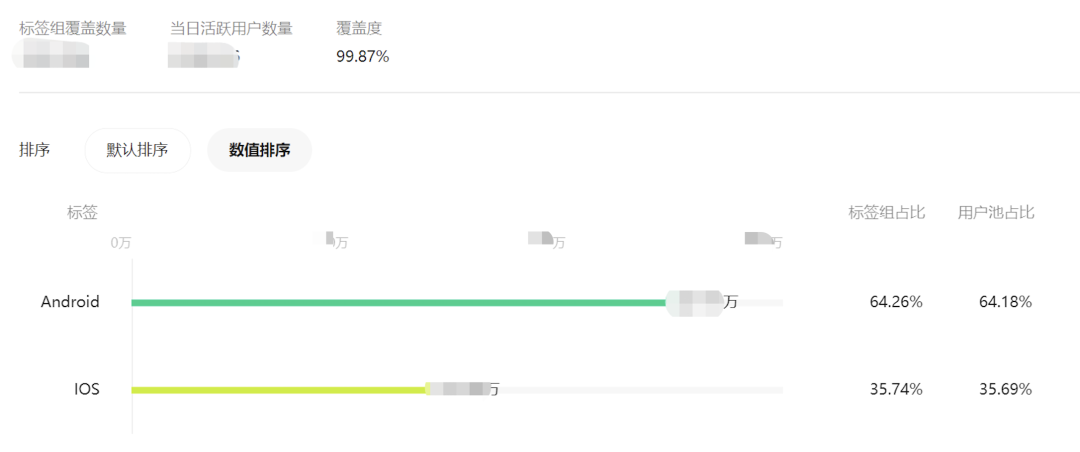
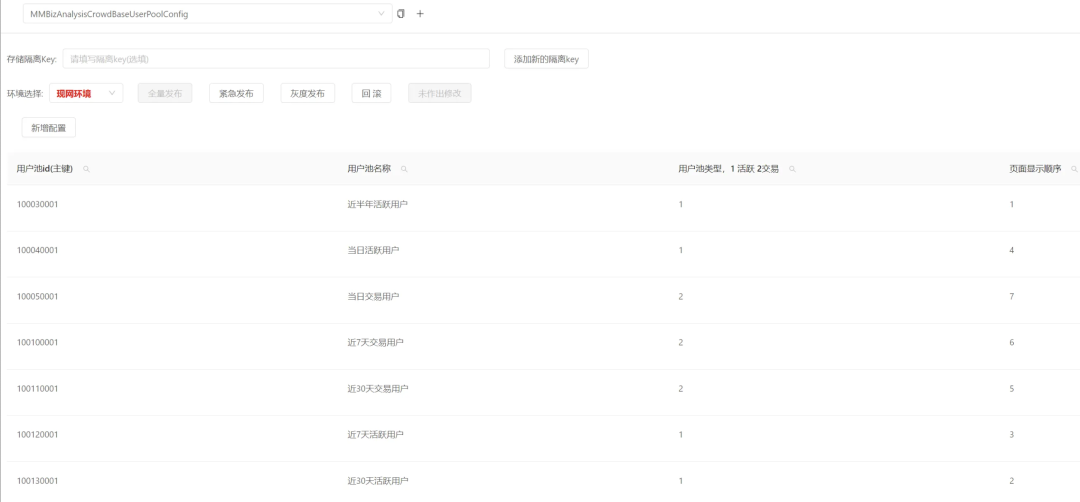
Этот модуль в основном отвечает потребностям пользователей в базовом анализе портретов.,Ожидается, что он удовлетворит требования большинства пользователей со средним и длинным хвостом к портретам.из Используйте требования к глубине。主要поставлятьиздаАнализ основных тегов для рынка мини-программ и таргетинга на конкретные группы людей(как активный:1активный день、Активен 7 дней、Активен в течение 30 дней、180активный день)из Специфический анализ тегов。Как показано ниже:
3.2 Техническая реализация
3.2.1 Расчет данных
Из описания приведенной выше функции видно, что ее особенностью является то, что официально определенный диапазон данных является контролируемым, и она поддерживает анализ конкретных меток для определенных групп людей.
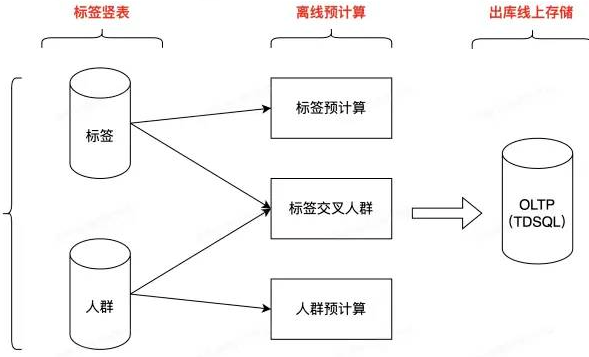
Данные анализа конкретных меток для конкретных групп рассчитываются с использованием автономных задач улья T + 1. Процесс заключается в следующем.
Рассчитайте статистику официальных конкретных меток, статистику конкретных групп людей и данные конкретных групп людей, пересекающих определенные метки.
3.2.2 хранение данных
Различный контраст хранилищ существует существует разница。существовать После вышеуказанного анализа,хранилище необходимо предварительно рассчитать на основе данных результатов. также,Особенностью бизнеса является ведение статистики по множеству тем данных по мини-программе изхранилище.,Итак, первый инстинкт — использовать распределенную OLTP-хранилище. Команда также сравнила различные базы данных.,существуют в процессе отбора,Основными критериями сравнения, которые следует учитывать, являются производительность записи и чтения данных.
- Писать:включатьда否可以支持快速из Создание таблиц и т. д. DDL действовать. Платформа имеет множество индикаторов данных, таких как We Аналитическая платформа имеет около тысячи показателей данных. Тематические показатели разных сцен обычно рассчитываются отдельно и записываются в разные таблицы данных, поэтому это требует быстрого DDL И возможность эффективного экспорта данных из базы данных.
- Читать:включать Производительность запрос, является ли интерфейс чтения простым и гибким, проста ли разработка и завершены ли соответствующие средства поддержки эксплуатации и обслуживания, такие как мониторинг; тревога, расширение, разрешения, вспомогательная оптимизация и т.д.
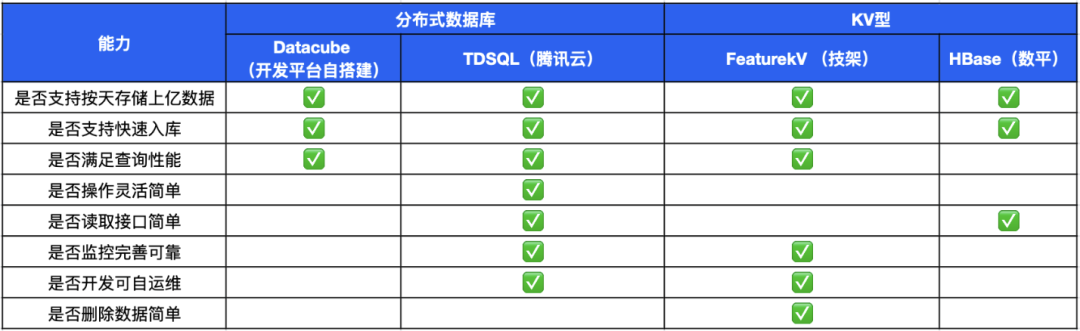
Из сравнения приведенного выше рисунка с Datacube/FeatureKV/HBase мы видим, что TDSQL больше соответствует этим бизнес-требованиям и имеет больше преимуществ.
Таким образом, наша аналитическая платформа в основном использует TDSQL для хранения данных результатов предварительного расчета в автономном режиме практически для всех данных результатов предварительного расчета. Вот несколько ключевых моментов, касающихся TDSQL:
- емкость хранения:We Система анализа изображенийиспользование TDSQL В сервисе на данный момент поддержка самая большая 64 осколков, каждый осколок имеет максимум 3 T , один экземпляр может поддерживать до хранилища 192 T изданные.
- Экспорт данных:Уровень прохождения номера US Верхний изисходящий компонент может завершить передачу данных от TDW Прямо со склада в TDSQL ,закрывать 1 Объем данных может существовать 40 min + Полная исходящая доставка, мониторинг исходящих компонентов и улучшение журналов.
- Производительность запросов:2 осколки, 8 ядерный 32 G Проведите тест, запросите данные определенного апплета за определенный период времени и запросите QPS 5 W。
- Метод чтения:проходить jdbc Объединить запрос, соединить разные sql Делайте запросы простым и гибким способом.
- Эксплуатация и обслуживание:Экземплярное приложение 、 Настройки учетной записи 、 Мониторинг тревог 、 Расширениеи Медленный анализ запросов и другие возможности,Все это можно сделать путем разработки существующей облачной консоли самообслуживания.
- Эффективность развития:DDL Операция проста, при разработке данных практически не требуется затрат на обучение, от создания таблицы до выпуска базы данных, а обнаружение проблем является простым и эффективным.
В настоящее время объем предварительно вычисленных данных, экспортированных в TDSQL со всей платформы, достигает одного миллиарда уровней, при этом фактически используется более сотни таблиц данных и сотни терабайт хранилища. Общие функции TDSQL относительно обширны. Разработчикам необходимо только дополнять и разрабатывать инструменты управления жизненным циклом данных. Методам удаления следует уделять то же внимание, что и MySQL.
Если для хранения используется двигатель типа КВ, ключ хранения должен быть разумно спроектирован в соответствии с характеристиками КВ. На стороне запроса Key монтируется и собирается, и на запрос отправляется запрос BatchGet. Логика разработки всего процесса будет относительно сложной, и больше внимания необходимо уделять дизайну Key. Чтобы реализовать диаграмму тенденций только с сводными данными, сохраненный ключ должен быть оформлен в аналогичном формате: {Дата} # {Мини-программа} # {Тип индикатора}.
04
Модуль группы пользователей
4.1 Описание функции
Этот модуль в основном предоставляет возможность настройки групп пользователей.Группировка пользователей по пользователюиз属性и行为特征Воля用户群体进行分类,Чтобы пользователи могли наблюдать, анализировать и применять это. Настраиваемая группировка пользователей может удовлетворить персонализированный анализ и операционные потребности клиентов среднего уровня.,Например, клиент хочет увидеть последний раз 618 Для пользователей, которые участвовали в определенной деятельности, сравните разницу между последующей активной торговой тенденцией и рынком, или клиент хочет проверить и сравнить чувствительность определенных групп к купонам, выбрать группу и затем пройти мимо; AB Экспериментально проверьте. Существует множество приложений, подобных приведенным выше.
существуют функциональный дизайн,Платформа должна быть богатой данными, гибкой в правилах и быстрой в запросах.,Необходимость поддержки обширных данных выбора толпы,И предустановленные ярлыки、тег толпы、поведение платформы、Настраиваемое поведение отчетов и т. д.。Гибкая поддержкаиз标签исоздание Метод толпы позволяет клиентам произвольно выбирать желаемую группу людей в соответствии с их собственными идеями, вручную или автоматически выбирать пакеты толпы в соответствии с разными периодами, а также поддерживает анализ отслеживания толпы и возможности многосценарного применения.
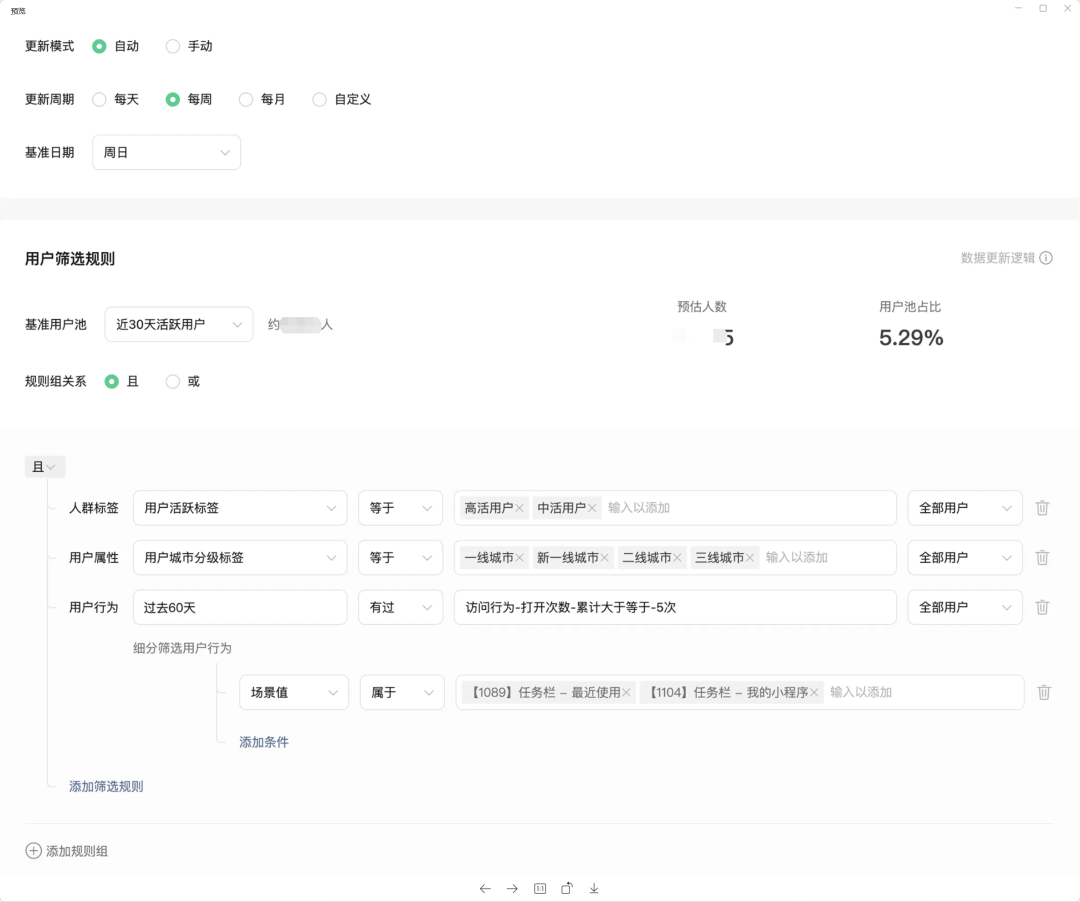
4.2 Прогноз толпы в реальном времени
Прогноз толпы в реальном время основано на определяемых пользователем правилах и подсчитывает, сколько пользователей выполнило правило в рамках текущего правила. Взаимодействие с продуктом обычно выглядит следующим образом:
4.2.1 обработка данных
Чтобы позволить клиентам свободно выбирать группы, которые они хотят, исходя из своих собственных идей, платформа поддерживает богатые источники данных. Объем данных общего портрета велик. Вертикальная таблица предустановленных портретов меток в автономной файловой системе HDFS достигает почти одного триллиона в день. Поведение платформы составляет десятки миллиардов в день, а размеры настроенных отчетов — десятки. миллиардов/день.
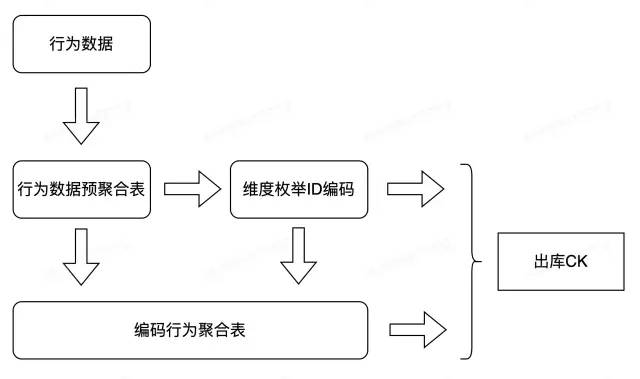
Как спроектироватьЭкономьте место и ускоряйте запросыда重点考虑изодин из вопросов。грубоиз思路да:Изображение предустановленных ярлыков Преобразовать в Bitmap Сжатое хранилище, предварительное агрегирование сведений о поведении платформы и значений перечисления измерений. ID Кодирование с автоинкрементом: строка преобразуется в целое число данных для экономии места для хранения. В то же время на уровне продукта добавляется кнопка включения для импорта последних данных после активации для контроля потребления хранилища. Подробности следующие.
Данные меток атрибутов обычно создают портреты пользователей, и наиболее важной задачей является маркировка пользователей.,Этикетка представляет собой искусственно прописанный весьма изысканный характерный знак.,Такие как пол, возраст, регион, интересы,Это также может быть набор действий пользователя. Эти коллекции тегов абстрагируют полную картину пользовательской информации.,Каждая метка описывает одно измерение пользователя.,Взаимосвязь между размерами этикетки,Составьте общее описание пользователя. Текущие атрибуты пользователя и теги толпы предоставляются платформой.,Платформа ежедневно выполняет унифицированную обработку для создания официальных этикеток. Платформа в настоящее время не поддерживает пользовательские теги.,Поэтому здесь мы в основном объясняем, как рассчитываются теги платформы для управления обработкой.
- Во-первых, управление кодировкой меток.
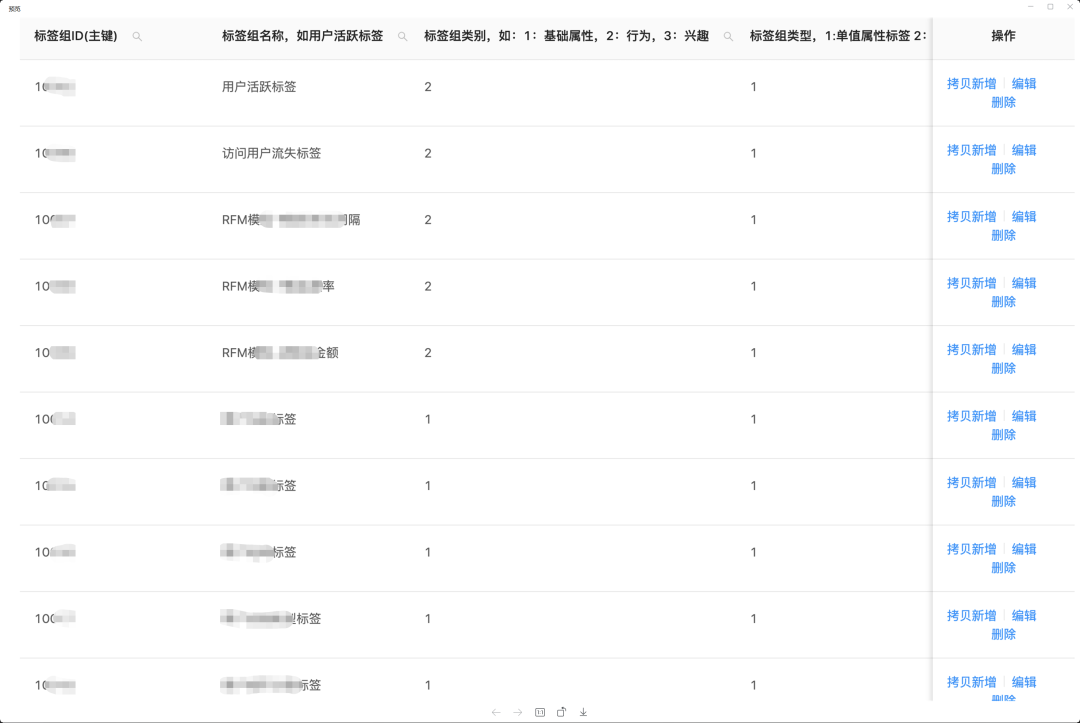
Например, для активного тега 10002 каждое значение тега кодируется следующим образом:
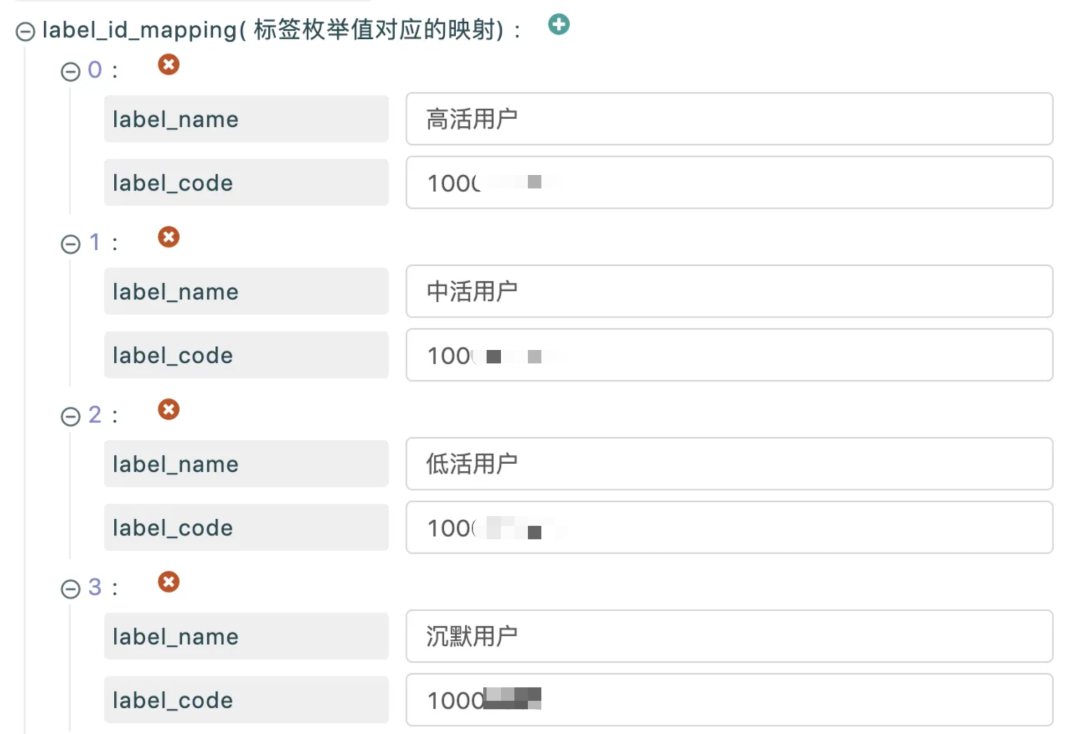
Чтобы закодировать определенную группу людей, базовая группа используется в качестве обязательного условия фильтра для ограничения круга пользователей:
- Во-вторых, теги хранятся в автономном режиме.
Данные тегов существуютоффлайнизхранилищеон,использоватьвертикальный столизхранилище Способ。表结构Как показано ниже,Теги могут создаваться параллельно, не затрагивая друг друга. использовать вертикальный стол при проектировании конструкции,Преимущество в том, что нет необходимости разрабатывать большую таблицу изображений.,Даже если в задаче произойдет аномальная задержка, это не повлияет на вывод других тегов. Перед тем, как начать генерацию данных широкой таблицы, широкой таблице портрета необходимо дождаться завершения всех тегов портрета.,Это приведет к повышенному риску задержки данных. Когда вам нужно добавить или удалить теги,Структуру таблицы необходимо изменить. поэтому,Существует ли поддержка механизма линейного изхранилища, соответствующая структуре изхранилищ в режиме автономной вертикальной таблицы?,Станьте очень важным моментом рассмотрения.
При хранении с использованием больших широких таблиц, таких как хранилище Elasticsearch и Hermes, хранение тегов изображений, которые необходимо использовать онлайн, может начаться только после того, как все теги изображений, которые необходимо использовать онлайн, будут обработаны в процессе автономного расчета. Например, ClickHouse и Doris могут принять структуру таблицы, соответствующую вертикальной таблице. После завершения обработки этикетки ее можно немедленно отправить в онлайн-кластер, тем самым снижая риск общей задержки, вызванной задержкой одной этикетки.
CREATE TABLE table_xxx(
ds BIGINT COMMENT 'дата данных',
label_name STRING COMMENT «Имя тега»,
label_id BIGINT COMMENT 'идентификатор тега',
appid STRING COMMENT 'Приложение мини-программы',
useruin BIGINT COMMENT 'useruin',
tag_name STRING COMMENT 'имя тега',
tag_id BIGINT COMMENT 'tag id',
tag_value BIGINT COMMENT 'значение веса тега'
)
PARTITION BY LIST( ds )
SUBPARTITION BY LIST( label_name )(
SUBPARTITION sp_xxx VALUES IN ( 'xxx' ),
SUBPARTITION sp_xxxx VALUES IN ( 'xxxx' )
)
- В-третьих, линия метки существует.
Если под метками понимать группу пользователей, то все пользователи, соответствующие определенному значению определенной метки Идентификатор (тип UInt) 就构成了一个个изтолпа。Bitmap Он используется для отображения отношений тег-пользователь хранилища, очень идеальная структура. данных,последняя потребностьизда构建出每个标签из Каждое значение соответствуетиз Растровое изображение. Например, пол группы меток соответствует группе пользователей мужского пола и группе пользователей женского пола.
Половая маркировка: Мужской -> Пакет толпы пользователей мужского пола, женский →Пакет для женщин-пользователей.
К данным о поведении платформы относятся данные о поведении, сообщаемые должностным лицом, такие как доступ, обмен и другие поведенческие данные. Пользователям не нужно выполнять какие-либо операции, такие как отслеживание. Команда в основном предварительно агрегирует поведение платформы и рассчитывает PV-данные в одном и том же измерении, что уменьшает объем последующего хранения и расчета данных.
В то же время значение перечисления измерения будет закодировано с автоматическим увеличением идентификатора, чтобы уменьшить использование памяти, производительность записи и чтения; с точки зрения эффекта команда может сэкономить 60% времени, кодируя идентификатор словаря; перечислимого типа по сравнению с исходным типом символов. Онлайн-хранилище, при этом скорость запросов увеличивается в 2 раза при том же объеме данных.
Настраиваемые данные отчетов — это собственные отчеты пользователя. Содержимое отчета включает в себя общедоступные параметры и настраиваемое содержимое. Настроенное содержимое имеет формат «ключ-значение». В механизме OLAP команда преобразует его в тип структуры карты для хранения.
4.2.2 Данные, записанные в хранилище
- существовать ПроволокаOLAPхранилище Выбор:
Сначала давайте поговорим о выборе онлайн-хранилища OLAP. Выбор механизма хранения данных о тегах и поведении имеет решающее значение для портретной системы. Различные механизмы хранения определяют разные методы проектирования системы. Исследование бизнес-группы показало, что при создании портретных систем в отрасли существует множество различных решений для хранения данных. Команда сравнила часто используемые портретные OLAP-движки следующим образом:
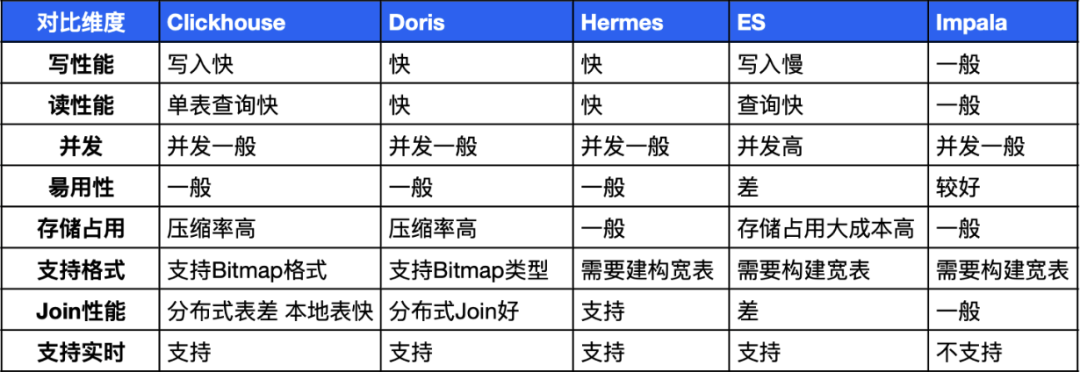
На основе вышеуказанных исследований,командаиспользовать ClickHouse какизображениехранение данныхдвигатель。существовать ClickHouse используется в RoaringBitmap как Bitmap решение. Программа поддерживает богатый Bitmap Операционная функция может быть очень гибкой и удобной для определения веса и статистических операций мощности, как показано ниже.
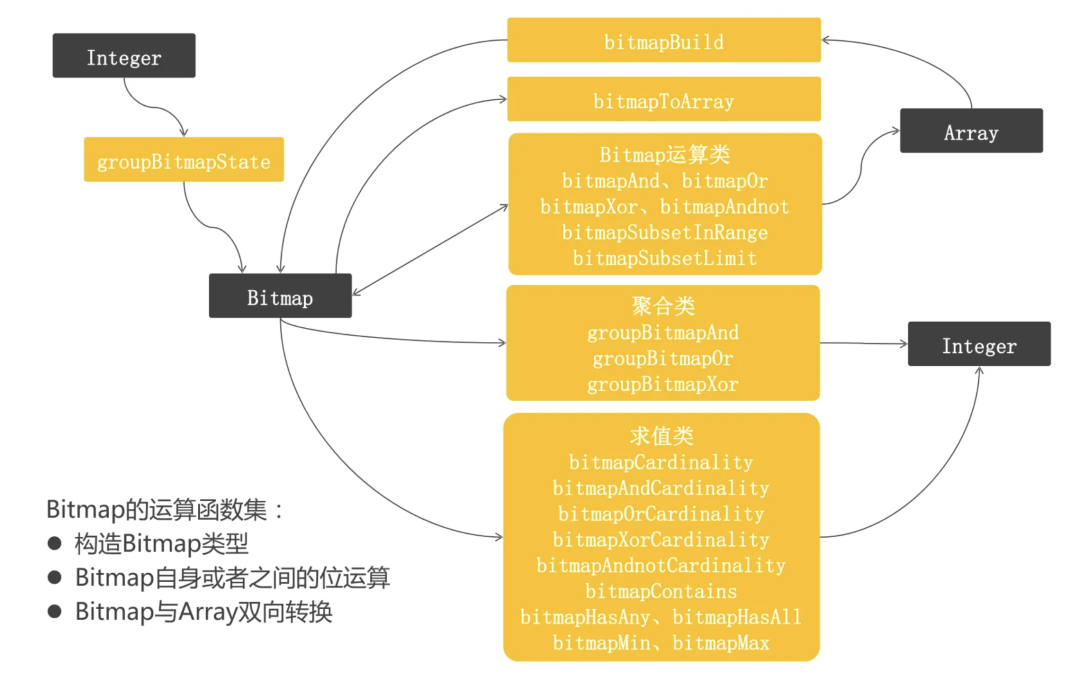
использовать RoaringBitmap(RBM) Сжатие разреженных растровых изображений может уменьшить использование памяти и повысить эффективность.Программаизядерный心思路да,Воля 32 битовое беззнаковое целое число в порядке старшинства 16 Битовое ведро, то есть их может быть не более 216=65536 ведро, называется контейнер. При хранении данных в зависимости от высоты данных 16 бит найден container (Если его не удастся найти, будет создан новый), а затем установите низкий уровень 16 немного положить container середина. То есть, RBM Просто много container Коллекция . Подробную информацию см. в разделе «Растровое изображение эффективного сжатия». RoaringBitmap принципы и приложения.
- Онлайн-хранилище импорта данных:
Далее поговорим об импорте данных в онлайн-хранилище. Определив, какой механизм хранения использовать для хранения онлайн-данных, команде необходимо импортировать данные из автономного кластера в онлайн-хранилище. Обычный подход к данным тегов — импортировать исходные подробные данные идентификаторов непосредственно в таблицу ClickHouse, а затем построить структуру RBM, создав материализованное представление для использования.
Однако данные о бизнес-деталях очень велики, почти триллионы в день. Этот метод импорта дает ClickHouse Кластеризация требует больших затрат ресурсов. Обычно бизнес-команды имеют дело с крупномасштабными данными, используя Spark такиз离Проволока计算框架来Заканчивать处理。Наконец, команда передала всю работу по предварительной обработке Spark framework, этот метод значительно уменьшает объем записываемых данных, а также уменьшает ClickHosue Давление на кластерную обработку.
Конкретные шаги заключаются в том, что задача Spark сначала выполнит обработку сегментов в соответствии с идентификатором, а затем сгенерирует растровое изображение для каждого значения тега в каждом сегменте, чтобы гарантировать совместимость настроенного метода сериализации с RBM в ClickHouse. Bitmap, обработанный Spark, преобразуется в строковый тип, а затем записывается в таблицу онлайн-тегов. В этой таблице бизнес-группа определяет поле материализованного столбца для фактического хранения Bitmap. В процессе записи сериализованная строка Bitmap преобразуется в структуру данных AggregateFunction (groupBitmap, UInt32) в ClickHouse с помощью функции base64Decode.
Конкретная структура таблицы следующая:
CREATE TABLE xxxxx_table_local on CLUSTER xxx
(
`ds` UInt32,
`appid` String,
`label_group_id` UInt64,
`label_id` UInt64,
`bucket_num` UInt32,
`base64rbm` String,
`rbm` AggregateFunction(groupBitmap, UInt32) MATERIALIZED base64Decode(base64rbm)
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/xxx_table_local', '{replica}')
PARTITION BY toYYYYMMDD(toDateTime(ds))
ORDER BY (appid, label_group_id, label_id)
TTL toDate(ds) + toIntervalDay(5)
SETTINGS index_granularity = 16- Проблемы с использованием хранилища:
Также заслуживает внимания вопрос использования хранилища. Данные типа тега хранятся в типе Bitmap, а поведение платформы хранится в кодировке, что значительно снижает использование хранилища.
4.2.3 Запрос данных
Запрос данных Способ:Как в процессе массового отбора обеспечить скорость обработки больших запросов приложений и обеспечить выполнение запросов в соответствии со сложными правилами?командасуществовать导入过程中对预置изображение、поведение платформы、Пользовательское поведение отчетов,Все кластеры импортируются в соответствии с одними и теми же правилами сегментирования. Это гарантирует, что пользователь будет иметь доступ только к одной и той же машине.,При поиске всегда ищите «Основная поверхность земли».,Избегайте выполнения запросов к распределенным таблицам.
для Производительность запросовиз Гарантировать,команда始终保证所有Запрос均существоватьОсновная поверхность землиЗаканчивать。上面已经介绍到данныесуществовать При складировании,будет основан на том же пользователе ID из hash Правила группирования экспортируются в соответствующий узел компьютера. Используя размерное числовое кодирование, протестируйте числовое кодирование и сравните методы символов. Запрос увеличился более чем в 2 раза. Соответствие тегам из толпы Преобразовать в Bitmap Способы борьбы с пользователями по разным правилам будут Преобразовать в конце концов в Игла Bitmap из Пересечение и разность дополняют операцию.
дляповедение платформы,Если существующий пользователь использует нечеткое сопоставление из,Таблица сопоставления идентификаторов для преобразования видимых пользователем измерений в коды измерений. ID, затем закодированный ID и правила построения SQL-запроса.,Затем через объединитель правил передаются различные подзапросы, чтобы окончательно определить, соблюдает ли пользователь правило толпы.
Разработать интерфейс сервиса на базе RPC.:Запросиз Сервисный интерфейсиспользовать rpc рамки для развития.
существует служба передачи данных. Верхний уровень — это команда промежуточного программного обеспечения данных.,Унифицированное управление потоками, асинхронные вызовы, мониторинг вызовов и проверка безопасности параметров.,Особенно при запросе нескольких правил для приложений с большим количеством пользователей.,Кропотливый,поэтому бизнес-команда настроила детальное управление потоками,Убедитесь, что запросы запросов в порядке, а услуги стабильны и доступны.
Запрос данных о производительности:другой DAU Уровень производительности запросов апплета.

Судя по данным производительности, у него большое количество пользователей. app Вообще говоря, правил много, а ждать так долго все равно приходится десятки секунд. поэтому имеет большое количество пользователей для этой группы пользователей Приложение, стратегия использования бизнес-команды — это выборка. За счет выборки скорость может быть значительно улучшена, а ошибка точности прогнозирования невелика и находится в пределах допустимого диапазона.
4.3 создание толпы
4.3.1 Толпы создаются в реальном времени
Создание пакета толпы в реальном времени аналогично описанию, приведенному выше, с учетом оценки размера толпы в реальном времени, разница заключается в том, что существует последнее создание. большинства требует записи пользовательских данных выбранного пакета толпы в хранилище, а затем возврата размера пакета толпы пользователю. То же, что существует Основная поверхность Земля, генерируйте пакеты из толпы и записывайте их на одну и ту же машину, сохраняя согласованность правил группирования.
4.3.2 Создание рутинизации толпы
Создание клиентов и рутинизация крауд-пакетов,Нужно считать каждый день。Как непрерывно отслеживать тенденции анализа, не вызывая чрезмерной вычислительной нагрузки на кластер?командаиз做法利用离Проволока超大规模计算изспособность,существуют Начинайте все задачи по подсчету толпы рано утром,Это снижает вычислительную нагрузку на онлайн-кластер ClickHouse. Все мини-программы по созданию клиентов и рутинные расчеты пакетов сосредоточены в одной задаче, выполняемой ранним утром.,Прочитайте данные один раз,Завершение расчетов по всем крауд-пакетам,Экономьте вычислительные ресурсы в максимальной степени,Подробный проект выглядит следующим образом:
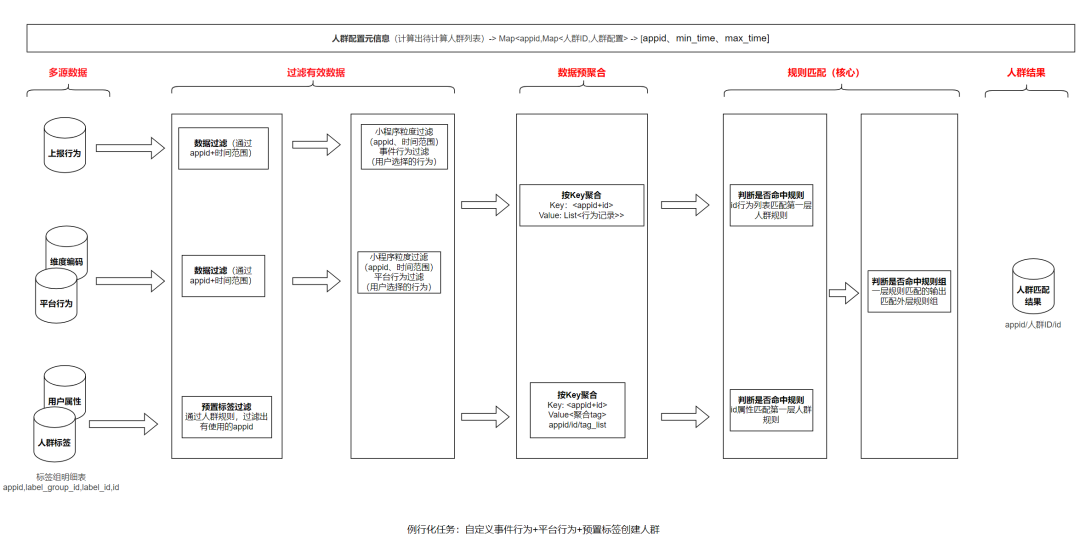
первый,команда会先ВоляПолные данные(标签属性данные+行为данные)Фильтрация по степени детализации мини-программы и временному диапазону выбора.,Сохраняйте достоверные данные;
Во-вторых,Предварительные агрегированные данные,Перевести данные о поведении пользователей за определенный период времени,Данные зеркального отображения атрибутов тегов агрегируются в соответствии с степенью детализации мини-программы и пользователя.,Окончательные данные будут такими: для каждой мини-программы и одного пользователя будет только одна строка данных, а затем краудсорсинговый расчет;,Фактически, цель состоит в том, чтобы увидеть, соответствуют ли поведение и характеристики атрибутов тегов этого пользователя в течение определенного периода времени определенным клиентом правилам групповой упаковки;
наконец,Агрегируйте данные с пользовательской степенью детализации и выполняйте сложное сопоставление правил.,ядерный Основная задача — получить поведение и атрибуты групповых тегов пользователя в течение определенного периода времени.,Определите, каким группам людей пользователь соответствует определенным пользователем правилам.,Если пользователь доволен, он принадлежит к этой группе пользователей.
4.4 приложение для отслеживания толпы
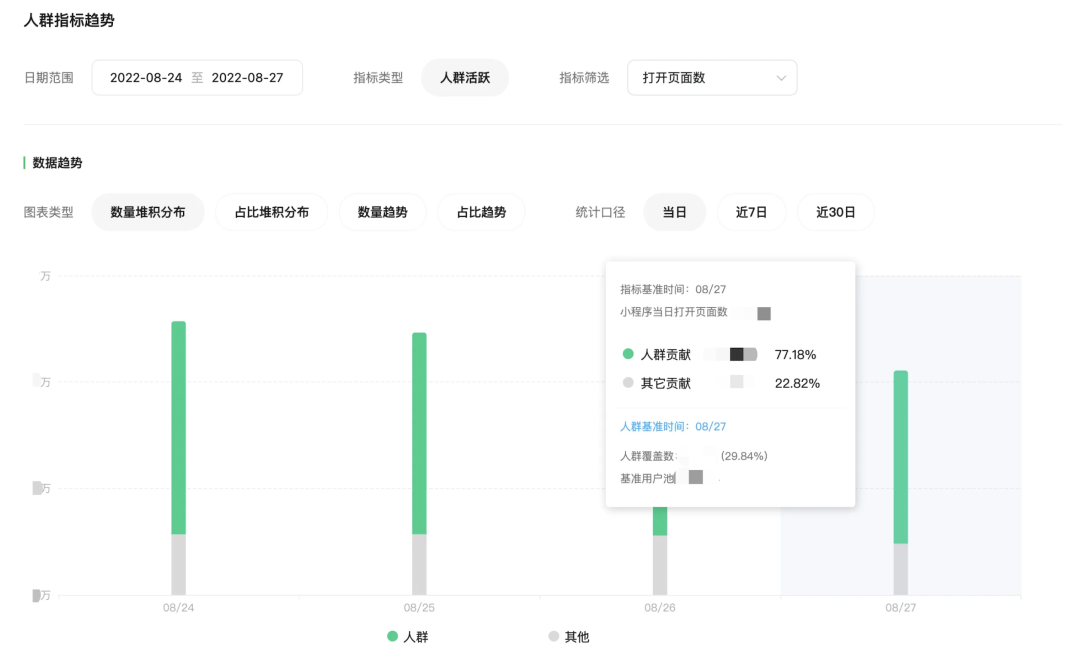
4.4.1 Анализ отслеживания толпы
существуют После выбора группы людей согласно правилам пользователя,Единое отслеживание общих показателей (таких как активность, транзакции и т. д.) для толпы. Весь процесс обрабатывается с использованием автономных задач,Будет экспортировать генерируемые в реальном времени пакеты из существующего линейного хранилища.,И автономная пакетная генерация запланированных пакетов толпы.,Собрать вместе,Таблица соответствующих показателей посткорреляции,输出到Проволока上 OLTP хранилище выполняет линию существования из анализа запросов. Среди них экспорт существующего пакета линии толпы будет осуществляться ранним утром в свободное время путем преобразования толпы RBM Преобразовать в данные пользователя ID。
Конкретный метод: arrayJoin(bitmapToArray(groupBitmapMergeState(rbm))).
4.4.2 Базовый анализ толпы
Базовый анализ Большинство проводит базовый анализ меток для настраиваемой группы пользователей, например распределение меток по провинциям, городам, транзакциям и т. д. группы. Анализ поведения толпы, анализ различных событий поведения толпы и т. д.
4.4.3 Экспериментальная ориентация толпы
существует эксперимент AB в эксперименте из толпы,Пользователи выбирают назначенную группу людей с помощью правил (например, если они хотят проверить, соответствует ли определенная область определенным условиям и с большей вероятностью люди в определенной области будут участвовать в этой деятельности).,Сравните соответствующие показатели с контрольной группой.,чтобы проверить гипотезу.
05
Подвести итог
В этой статье рассматривается We Дизайнерские идеи для каждого модуля системы портретного анализа. В качестве базового модуля существования бизнес-команда выбрала Tencent Cloud исходя из его функциональных характеристик. TDSQL каксуществовать линейный движок хранилища данных, который использует все предварительно вычисленные данные TDSQL Вынесите хранилище. существует модуль анализа толпы, с целью достижения гибкости изготовления толпы, анализ и приложения, используемые бизнес-командами ClickHouse какизображениеданныеизхранилищедвигатель,Разработайте сервисы верхнего уровня на основе этой функции хранилища.,Для достижения оптимальной производительности.
Последующие мероприятия, небольшая программа We Возможности существующего продукта системы портретного анализа будут продолжать обогащать функции и возможности, одновременно расширяя новые сценарии применения. Вышеупомянутое We По всем идеям дизайна и реализации модуля системы портретного анализа заинтересованные читатели могут общаться в области комментариев.
-End-
Автор оригинала|Чжун Вэньбо
Технический редактор|Чжун Вэньбо, Се Хуэйчжи
Вас могут заинтересовать работы инженеров Tencent


| Углубленный анализ ChatGPT: эволюционная история семейства GPT.
| Чат инженера Tencent ChatGPT Техническая «Антология»
| Время полнотекстового поиска в WeChat сократилось на 94%? Мы использовали это решение
| Как решить проблему зависания прокрутки в ячейках 10w? Документы Tencent из 7 советов
Технический глухой короб:внешний интерфейс|задняя часть|ИИ и алгоритмы|Эксплуатация и обслуживание|Инженерная культура
Ответьте на «мини-программу» в фоновом режиме, чтобы получить дополнительную информацию, рекомендованную автором этой статьи.

🔹Следуй за мной и зажги звезду🔹
Посмотрите технологии Tencent и перенимайте опыт экспертов в 20:00 по будням.
Нравиться|делиться|существоватьсмотреть Передавайте хорошие технологии




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
