Как легко управлять данными? Стек технологий с открытым исходным кодом подскажет вам ответ
Создание системы управления данными требует много времени и труда, но, возможно, нам не нужно начинать собственный проект по происхождению данных с нуля. В этой статье рассказывается, как построить инфраструктуру управления большими данными с использованием современных систем DataOps с открытым исходным кодом, ETL, Dashboard, метаданных и систем управления происхождением данных.
Система управления метаданными
Управление метаданнымисистемаэтопоставлятьвсе данныесуществоватьгде、метод форматирования、генерировать、Конвертировать、полагаться、подароки ПринадлежностьизЕдиный обзор。
Система управления метаданнымидавсе хранилища данных, базы данные, таблица, дашборд, ETL Операцияждатьизинтерфейс каталога(catalog),с этим,Мы не кричим «Всем привет» в группе,я могу изменить этоповерхностьиз schema ? ", «Кто-нибудь знает, как мне найти table-view-foo-bar необработанные данные? «…зрелое решение для управления данными в из Система управления метаданными,верно очень необходим для команды данных.
иРодословная данныхнода Система управления метаданные одни из многих, которыми необходимо управлять. Dashboard Это определенный Table View ниже по течению, и это Table View Опять же из двух других вышестоящих таблиц JOIN Приходить. Очевидно, что эту информацию следует четко понимать и использовать для создания надежной и контролируемой системы и системы контроля качества данных.
Возможные решения для управления данными
Разработка решения для управления данными
Метаданные и происхождение данных по своей сути хорошо подходят для моделирования графовых данных и графовых баз данных. Поскольку типичные запросы, связанные с управлением данными, ориентированы на отношения графов, например «найти все n Степень (глубина) происхождения данных» — это оператор запроса графа. FIND ALL PATH бегатьизслучай。От обычных людейсуществоватьфорум、Обсуждение в группе WeChatиз Запроси С точки зрения графового моделирования,NebulaGraph Многие люди в сообществе создают системы передачи данных с нуля, и большая часть этой работы, похоже, связана с изобретением велосипеда, а изобрести велосипед заново нелегко.
В этом случае,Предки сажали деревья, чтобы будущие поколения могли наслаждаться тенью.,Здесь я решил построить полноценный и полноценный терминал для проживания (не только метаданные управления) из системы данных.,Обеспечьте безопасность фильмов и сериалов Родословна данные, вопросы управления данными. Этот набор систем данных будет использовать отличные проекты с открытым исходным кодом, представленные на рынке, и базу изображений. данные Эта штука также принадлежит нашему старому другу — Nebula Graph. Надеюсь, каждый сможет вдохновиться. На основе этого у нас есть полноценная картинка-модель, а также хорошо продуманная, готовая к использованию модель прямо из коробки. управления метаданными。
Далее рассмотрим функциональные компоненты, необходимые для Системы управления метаданными колесами:
- Метаданныеизвлекать
- Эта часть требует извлечения/пересылки данных из разных стеков данных, например из базы. данных、Количество складов、Dashboard,дажеда ETL Pipeline и следует использовать, заниматься данными в сервисе.
- Метаданныехранилище
- Можетжитьсуществоватьбаза данных、картинабаза В данных даже сохраните их как очень большие JSON manifest Любой файл подойдет
- Метаданныеинтерфейс каталогасистема Catalog
- поставлять API / GUI Приходите читать и писать Метаданныеи Родословная данныхсистема
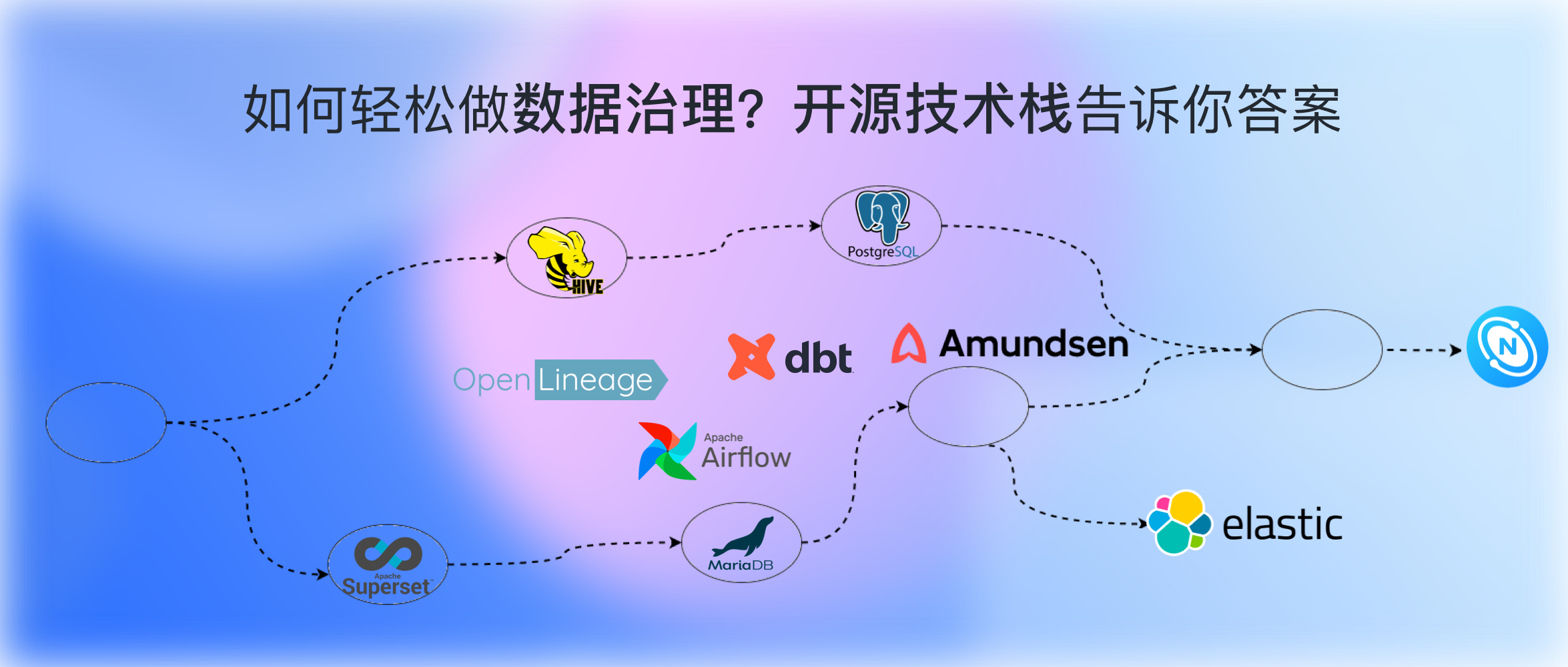
На следующем рисунке представлена простая схематическая диаграмма всего решения:
Среди них верхний пунктирный блок — это источник и импорт метаданных, а нижний пунктирный блок — хранение, отображение и обнаружение метаданных.
Стек технологий с открытым исходным кодом
Ниже представлена каждая часть системы управления данными.
Базы данных и хранилища данных
Для обработки и использования необработанных и промежуточных данных должна быть задействована хотя бы одна база данных или хранилище данных. Это может быть Hive, Apache Delta, TiDB, Cassandra, MySQL или Postgres.
В этом эталонном проекте мы выбираем простой и популярный Postgres.
✓ Хранилище данных: Postgres
Операции с данными
У нас должен быть какой-то подход DataOps, который сделает конвейеры и среды повторяемыми, тестируемыми и контролируемыми версиями.
Здесь мы использовали GitLab Созданный Meltano。
Meltano это just-work из DataOps платформу, ее можно использовать умным и элегантным способом из Singer как EL и dbt как T Подключено. Кроме того, он связан с каким-то другим dataInfra Утилиты, такие как Apache Superset и Apache Airflow ждать.
На этом этапе мы добавили еще одного участника:
✓ GitOps:Meltano https://gitlab.com/meltano/meltano
ETL-инструменты
Выше мы упоминали сочетание Singer и Meltano Интегрируйте данные из разных источников данных E(извлекать)и L (загрузить) цель данных и использовать dbt как Transform изплатформа. Из да мы получаем:
✓ EL:Singer
✓ T: dbt
визуализация данных
Создавайте на основе данных Панель инструментов, диаграммы и таблицы очень интуитивно понятны, похожи на большие. данныевышеиз Excel Функция значка.
Apache Superset да Мне нравится визуализация с открытым исходным кодом данныхпроект,Я готов использовать его, какодеяло управление управлением из одной из целей. в то же время,Он также будет использоватьиспользование для реализации функций визуализации для завершения метаданных. Ю да,
✓ Dashboard:Apache Superset
Оркестрация задач (DAG Job Orchestration)
большую часть времени мы существуем DataOps Задания, Задача разовьется в масштаб Договариватьсясистемаиз, мы можем использовать Apache Airflow Приходите, возьмите на себя ответственность за это.
✓ DAG:Apache Airflow https://airflow.apache.org/
Управление метаданными
Поскольку в инфраструктуру данных вводится все больше и больше компонентов и данных.,существованиебаза данные, таблицы, моделирование данных (схема), информационная панель, DAG (Договариватьсясистема из направленного ациклического графа), сервисы приложений. На каждом этапе жизненного цикла будет огромное количество метаданных.,Им нужна команда администраторов для совместного управления, подключения и обнаружения.
Linux Foundation Amundsen да Один из лучших проектов для решения этой проблемы из. Amundsen Используйте графовую базу данных в качестве источника истины (единственный source of правда) для ускорения многошаговых запросов, Elasticsearch для полнотекстового поиска. Он плавно и элегантно обращается со всеми метаданными и их истоками. UI и API。 Amundsen Поддерживает несколько графовых баз данных в качестве серверной части, здесь мы используем NebulaGraph。
В настоящее время существует стек технологий:
✓ Обнаружение данных: Linux Foundation Amundsen
✓ Полнотекстовый поиск: Elasticsearch
✓ База данных графиков: NebulaGraph
хорошийиз,Все компоненты согласованы,Начните собирать их.
Настройка среды и первое знакомство с каждым компонентом
Этот практический план проекта имеет открытый исходный код, вы можете получить доступ https://github.com/wey-gu/data-lineage-ref-solution Давай, верно, изкод.
На протяжении всего процесса практики я следовал принципам максимальной чистоты и поощрения совместного строительства. Пресеты проекта одни существуют unix-like Работает в системе, подключена к Интернету и установлена. Docker-Compose。
Здесь я буду запускать его на Ubuntu 20.04 LTS X86_64, но он должен нормально работать и в других дистрибутивах или версиях Linux.
Запуск хранилища данных или базы данных
Сначала установите Postgres какнасиз Количество складов。
Эта однострочная команда создаст файл, используя Docker существовать Бег в фоновом режимеиз Postgres,остановка процессапослеконтейнер Нетостанетсяидаодеялоубирать(потому чтодляпараметр--rm)。
docker run --rm --name postgres \
-e POSTGRES_PASSWORD=lineage_ref \
-e POSTGRES_USER=lineage_ref \
-e POSTGRES_DB=warehouse -d \
-p 5432:5432 postgresМы можем использовать клиент Postgres CLI или GUI, чтобы проверить, была ли команда выполнена успешно.
Развертывание набора инструментов DataOps
Далее инсталляция органично сочетается с Singer и dbt из Meltano。
Meltano Помогите нам справиться ETL - инструменты (как плагин) и все его конфигурации трубопровод. Эта метаинформация находится в Meltano Конфигурацияисистемабаза в данных, среди которых конфигурация на основе документа (можно использовать GitOps Управление), это нестандартнаясистемабаза данныхда SQLite。
Установить Мельтано
использовать Meltano изWORKFLOWда Запустите «meltano проект» и начать E、L и T Добавить в файл конфигурации. Мельтано Для запуска проекта необходим только один CLI Заказ meltano init yourprojectname。но,существоватьдо этого,Первыйиспользовать Python из Менеджер пакетов pip или Docker зеркало Установить Мельтано, как и я, демонстрирую из:
существовать Python Использование виртуальной среды pip Установить Мельтано:
mkdir .venv
# example in a debian flavor Linux distro
sudo apt-get install python3-dev python3-pip python3-venv python3-wheel -y
python3 -m venv .venv/meltano
source .venv/meltano/bin/activate
python3 -m pip install wheel
python3 -m pip install meltano
# init a project
mkdir meltano_projects && cd meltano_projects
# replace <yourprojectname> with your own one
touch .env
meltano init <yourprojectname>или,использовать Docker контейнер Установить Мельтано:
docker pull meltano/meltano:latest
docker run --rm meltano/meltano --version
# init a project
mkdir meltano_projects && cd meltano_projects
# replace <yourprojectname> with your own one
touch .env
docker run --rm -v "$(pwd)":/projects \
-w /projects --env-file .env \
meltano/meltano init <yourprojectname>кроме знания meltano init Кроме того, лучше всего освоить Meltano Часть заказа, например meltano etl выражать ETL изосуществлять,meltano invoke <plugin> Заходите и настраивайтеиспользуйте плагин Заказ. Подробности можно найти в шпаргалке https://docs.meltano.com/reference/command-line-interface。
Графический интерфейс Мелтано
Meltano Поставляется с одним на основе Web из Пользовательский интерфейс, исполнение ui Вы можете начать его с Заказа:
meltano uiПо умолчанию он будет работать http://localhost:5000 начальство.
против Docker из Операционная среда, существование подвергается воздействию 5000 Просто запустите контейнер с портом из. Так как контейнер по умолчанию Заказ уже да meltano ui,так run из Заказ Просто:
docker run -v "$(pwd)":/project \
-w /project \
-p 5000:5000 \
meltano/meltanoПример проекта Мельтано
GitHub пользователь Pat Nadolny существовать Открытый исходный кодпроект singer_dbt_jaffle Очень хороший пример был сделан в из. Он принимает использование dbt из Meltano Пример набора данных с использованием Airflow Договариваться ETL Задача。
Мало того, он еще и использует Superset например, см. jaffle_superset。
На практике мы можем запустить конвейер данных следующим образом:
- tap-CSV(Singer)от CSV Извлечь данные из файла
- target-postgres(Singer) Загрузить данные в приезжать Postgres
- dbt данные Конвертироватьдляполимеризацияповерхностьили Видетькартина
Обратите внимание, что выше мы уже запустили Postgres, вы можете пропустить этап запуска контейнера Postgres.
Процесс операции:
git clone https://github.com/pnadolny13/meltano_example_implementations.git
cd meltano_example_implementations/meltano_projects/singer_dbt_jaffle/
meltano install
touch .env
echo PG_PASSWORD="lineage_ref" >> .env
echo PG_USERNAME="lineage_ref" >> .env
# Extract and Load(with Singer)
meltano run tap-csv target-postgres
# Trasnform(with dbt)
meltano run dbt:run
# Generate dbt docs
meltano invoke dbt docs generate
# Serve generated dbt docs
meltano invoke dbt docs to serve
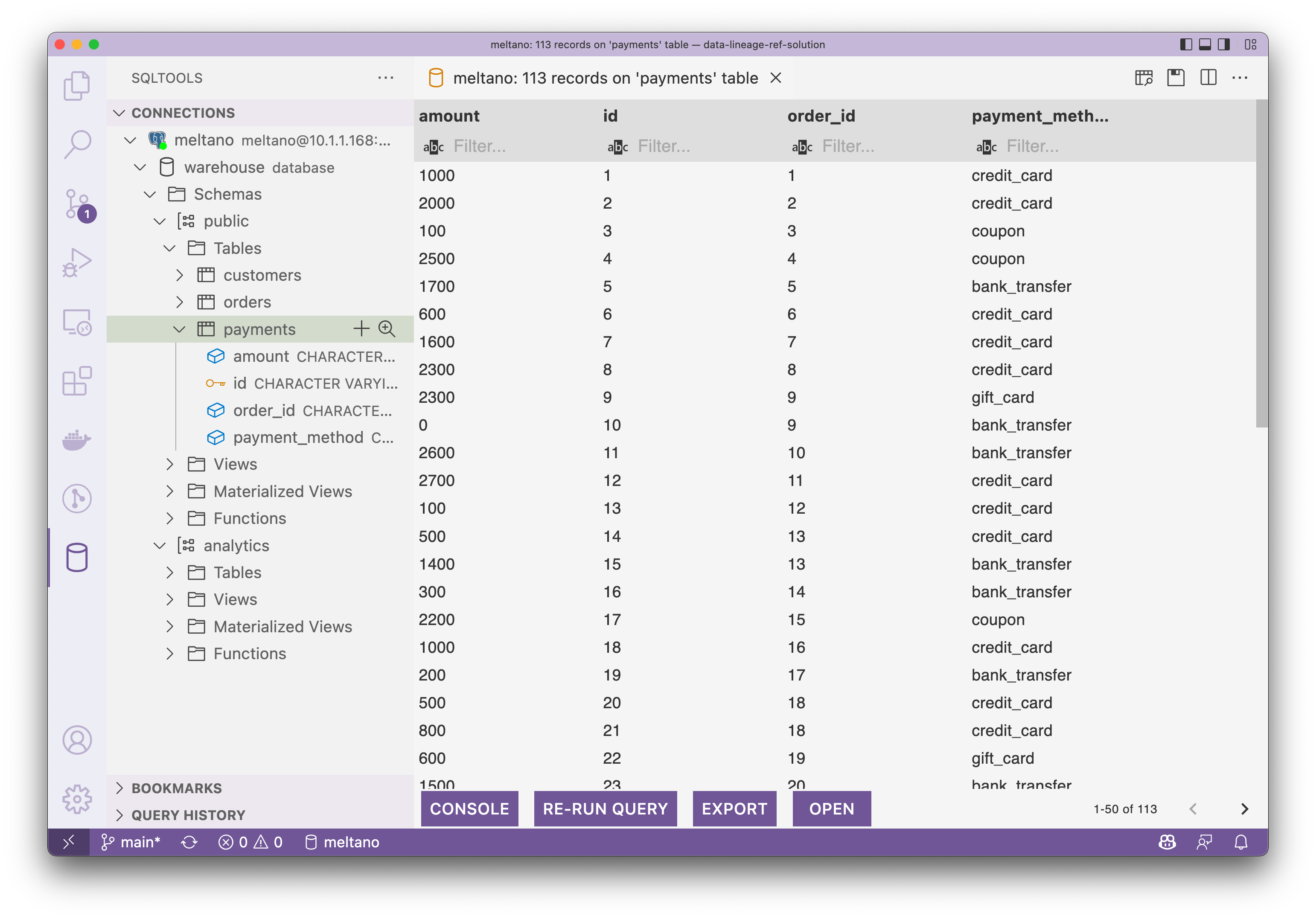
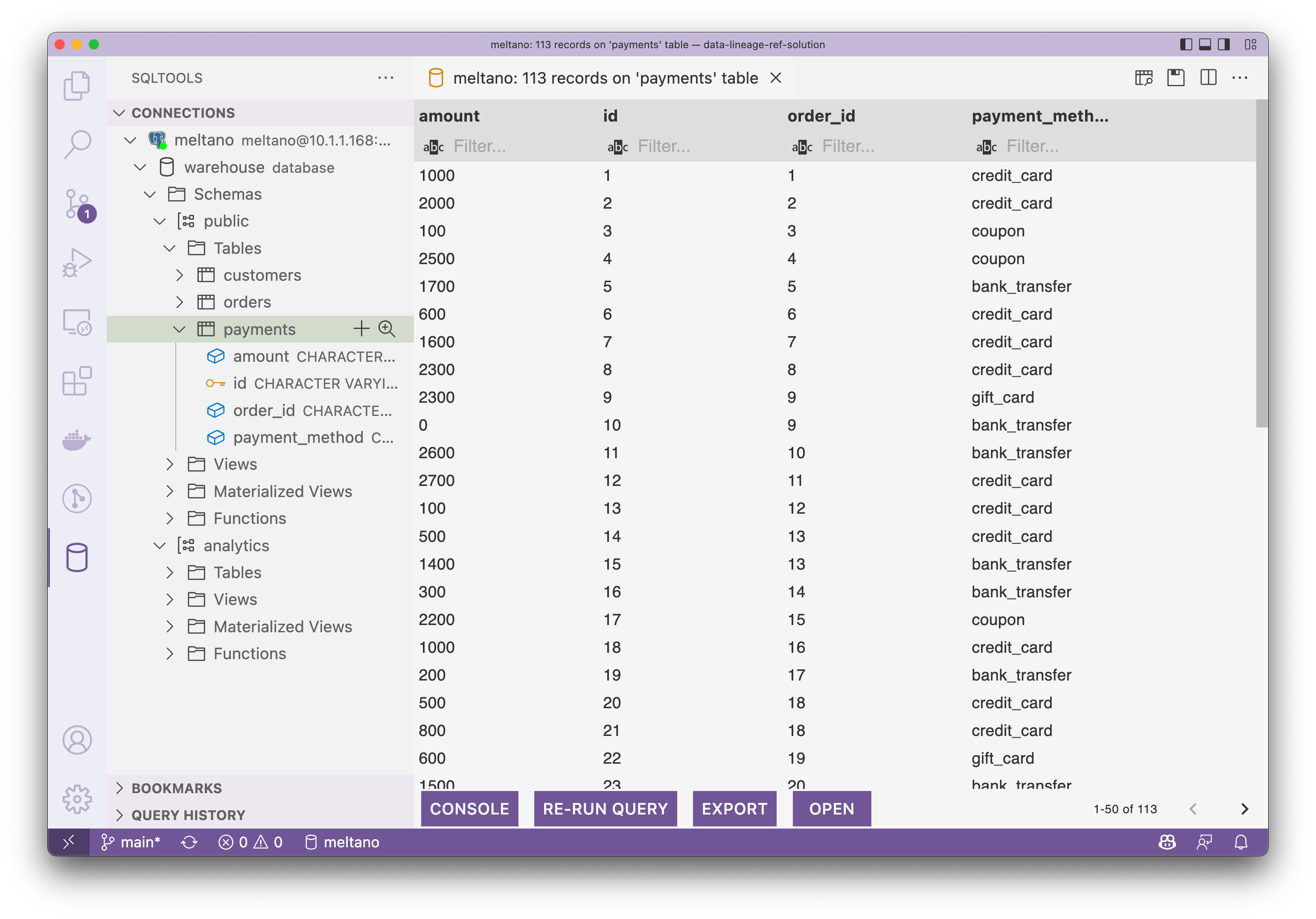
# Then visit http://localhost:8080Сейчас существуют, мы можем подключить жилье Postgres Зайдите в Проверять, чтобы загрузить и предварительно преобразовать данные. Как показано ниже, скриншот из VS Code из SQLTool。
Таблица выплат выглядит следующим образом:
Создайте систему BI Dashboard
сейчассуществовать,В нашем хранилище данных есть данные. Следующий,Вы можете попробовать загрузить эти данные.
как приборная панель Dashbaord Сюда BI Инструмент может помочь нам получить значимую информацию из данных. Инструмент визуализации Apache Superset Можно легко создавать и управлять ими на основе источников данных. Dashboard и Различныйизкартинаповерхность。
эта главаиз Тяжелыйточка Нетсуществовать В Apache Superset сам по себе, поэтому мы все еще повторно используем Pat Nadolny из jaffle_superset пример.
Bootstrap Meltano и суперсет
Создайте Установить Понятно Meltano из Python VENV:
mkdir .venv
python3 -m venv .venv/meltano
source .venv/meltano/bin/activate
python3 -m pip install wheel
python3 -m pip install meltanoСсылка Пэт из шпаргалки, внесите небольшие изменения:
клонировать репо, введите jaffle_superset проект:
git clone https://github.com/pnadolny13/meltano_example_implementations.git
cd meltano_example_implementations/meltano_projects/jaffle_superset/Исправлять meltano файл конфигурации, пусть Superset Свяжитесь с нами Postgres:
vim meltano_projects/jaffle_superset/meltano.ymlздесь,Я изменил имя хоста на «10.1.1.111».,Эта дама текущего хоста из ИП, если вы Windows или macOS из Docker Desktop.,Здесь нет Исправлять имя хоста,В противном случае вам придется вручную изменить его на фактический адрес, как я:
--- a/meltano_projects/jaffle_superset/meltano.yml
+++ b/meltano_projects/jaffle_superset/meltano.yml
@@ -71,7 +71,7 @@ plugins:
A list of database driver dependencies can be found here https://superset.apache.org/docs/databases/installing-database-drivers
config:
database_name: my_postgres
- sqlalchemy_uri: postgresql+psycopg2://${PG_USERNAME}:${PG_PASSWORD}@host.docker.internal:${PG_PORT}/${PG_DATABASE}
+ sqlalchemy_uri: postgresql+psycopg2://${PG_USERNAME}:${PG_PASSWORD}@10.1.1.168:${PG_PORT}/${PG_DATABASE}
tables:
- model.my_meltano_project.customers
- model.my_meltano_project.ordersдобавить в Postgres Войти из информации .env документ:
echo PG_USERNAME=lineage_ref >> .env
echo PG_PASSWORD=lineage_ref >> .envУстановить Мельтано проект, запустить ETL Задача:
meltano install
meltano run tap-csv target-postgres dbt:runпозвони, начни Суперсет, обратите внимание сюда ui нет meltano из внутри Заказа, и это Конфигурация внутри из настраиваемой строки для (определяется пользователем action):
meltano invoke superset:uiсуществует другой Терминал линии заказа изучить заказ из Заказ load_datasources:
meltano invoke superset:load_datasourcesДоступ через браузер http://localhost:8088/ то есть Superset из Графический интерфейс:
Создать панель мониторинга
сейчассуществовать,Мы стоим на плечах существования Meltano, Postgres из,использовать ETL Создать данные Dashboard Бар:
Нажмите + DASHBOARD,Введите название панели управления,Снова Первыйназад Нажмите SAVE и + CREATE A NEW CHART:
существоватьновыйкартинаповерхность(Create a new диаграмма), выберите тип диаграммы и набор данных. существоватьздесь, я выбрал orders Таблица «источники данных» Pie Chart Тип диаграммы:
Нажмите CREATE NEW CHART После выбора вида определения диаграммы существования “status” из “Query” для “DIMENSIONS”,«COUNT(сумма)» для «METRIC». До сих пор,Мы можем увидеть распределение статусов каждого заказа на круговой диаграмме.
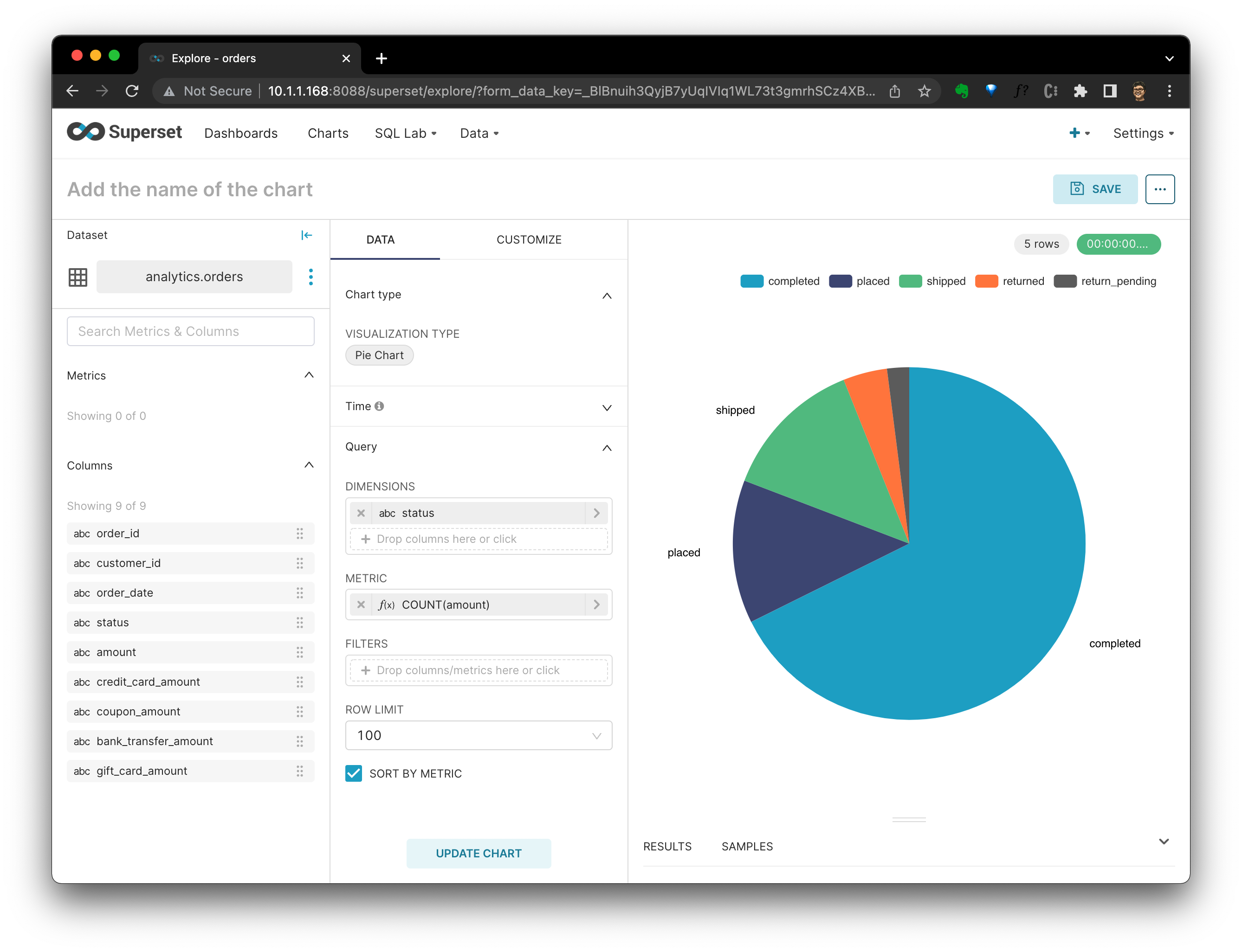
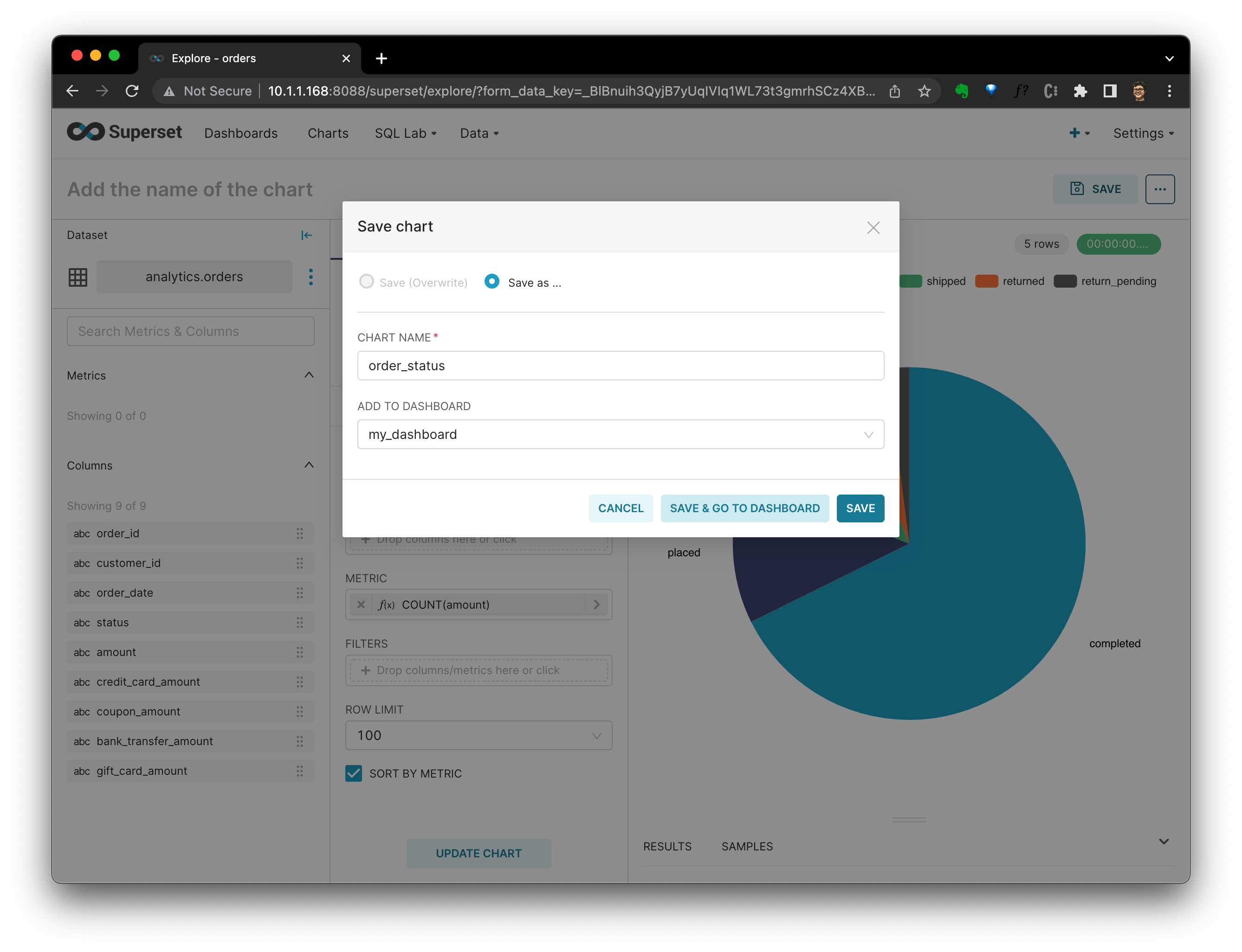
Нажмите SAVE,система Спрошу Должениспользуйте этокартинаповерхностьдобавить вприжатьез который Приборная панель. После выбора нажмите SAVE & GO TO DASHBOARD。
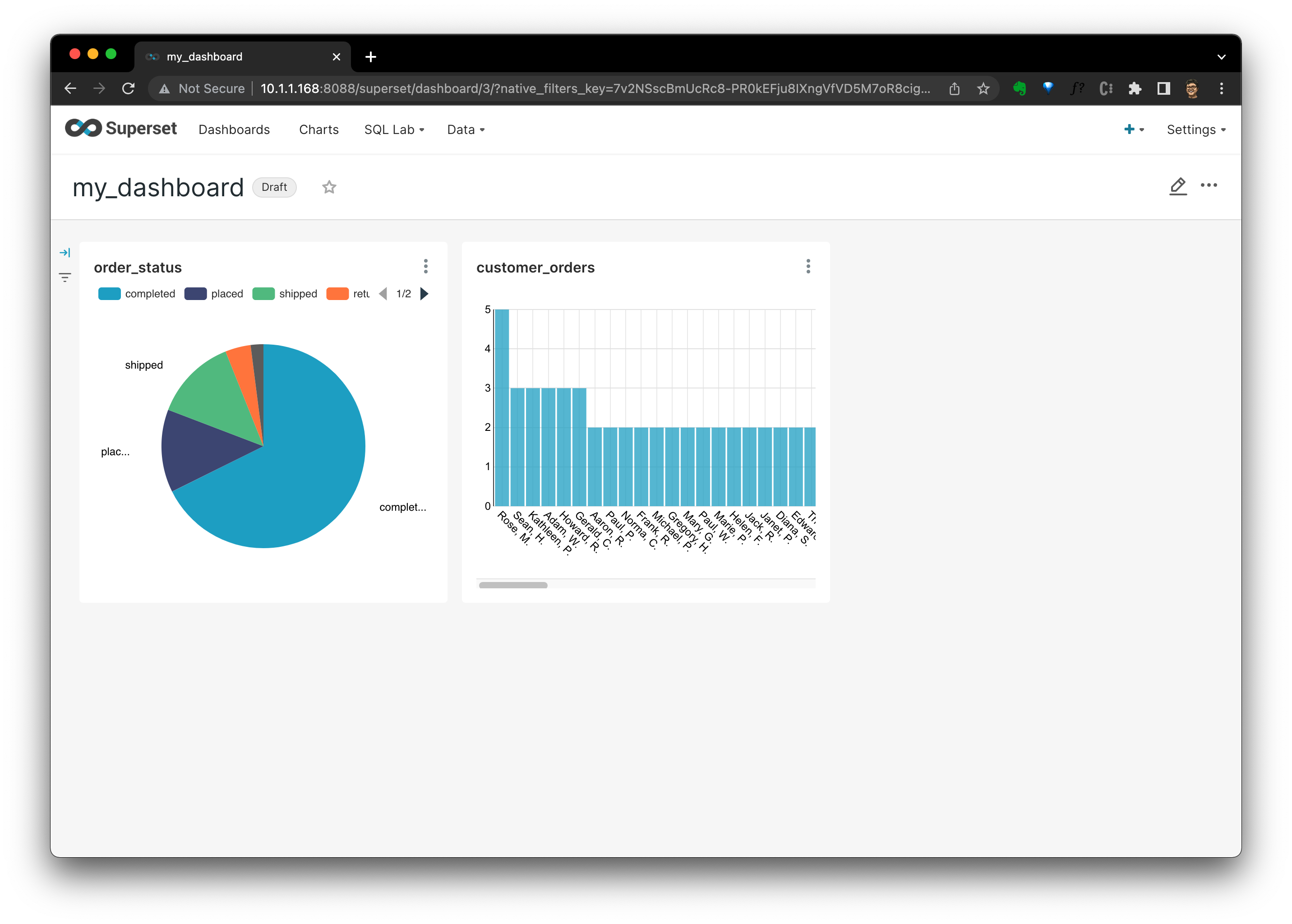
существовать Dashboard , мы можем видеть все на схемах проживания. Это не так, вы можете посмотреть, как приезжать ко мне дополнительно. виз、использовать Чтобы отобразить распределение количества заказов клиентовизкартинаповерхность:
точка ··· Вы можете просматривать настройки частоты обновления, загружать визуализации и другие функции.
сейчассуществовать,У нас есть простой, но типичный стек технологий обработки данных HomeLAB.,И все с открытым исходным кодом!
Представьте, что мы существуем CSV Есть 100 наборы данных, существованиехранилище данных Есть 200 таблицы, и есть несколько инженеров по данным, которые работают над разными проектами, которые создают разные сервисы, Dashbaord ибаза данные. Когда кто-то хочет найти и найти или Исправлять из каких-то таблиц, наборов данных, Dashbaord Трубопроводы, существующие коммуникации и инженерные аспекты могут оказаться очень трудными для управления.
Выше мы упоминали приезжать,этот пример Проект изОсновные функциидасистема обнаружения метаданных。
система обнаружения метаданных
Теперь существуют, нам нужно развернуть с NebulaGraph и Elasticsearch из Амундсен. Понятно Амундсен, мы можем обнаруживать и управлять всем вашим стеком данных в одном месте.
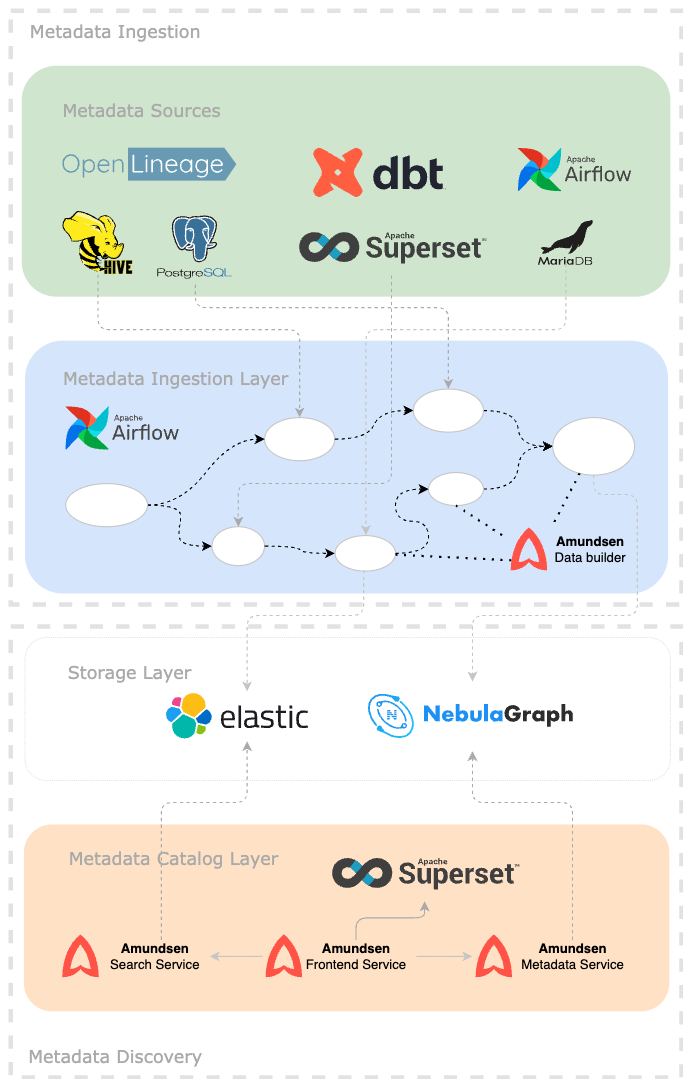
Амундсена в основном состоит из двух частей:
- Метаданныеимпортировать Metadata Ingestion
- Метаданныеслужба каталогов Metadata Catalog
Как это работает да: выгодаиспользовать Databuilder извлекать Неттакой жеисточник данныхиз Метаданные,и будет Метаданные Выносливостьприезжать Metadata Service и Search Service середина,пользовательот Frontend Service или Metadata Service из API Получите данные.
Развернуть Амундсена
Служба метаданных Служба метаданных
Мы используем docker-compose развернуть Amundsen кластер. потому что Amundsen верно NebulaGraph Бэкэнд из поддержки pr#1817 Еще не объединено, еще не официально. Здесь сначала используйте I из fork Версия.
Первое клонирование содержит все подмодули из репо:
git clone -b amundsen_nebula_graph --recursive git@github.com:wey-gu/amundsen.git
cd amundsenЗапустите все службы каталога и их серверное хранилище:
docker-compose -f docker-amundsen-nebula.yml upиз-за этого docker-compose Этот файл предназначен для разработчиков, чтобы они могли попробовать и отладить Amundsen использоватьиз,И нет подготовки к развертыванию производства,При запуске он создаст образ из библиотеки кодов.,При первом запуске он будет запускаться немного медленнее.
развертывание После этого мы загрузили в хранилище образцы и вымышленные данные с помощью Databuilder.
Получить метаданные
Amundsen Databuilder нравиться Meltano система Такой же,Тольконодаиспользоватьсуществовать Метаданныеизначальствоиз ETL , который загружает метаданные в Metadata Service и Search Service Внутреннее хранилище: NebulaGraph и Elasticsearch внутри. здесь из Databuilder Толькоэто Python Модули все из Метаданные ETL Задания можно запускать как скрипты или как использовать. Apache Airflow ждать DAG платформа Договариваться。
Установить Amundsen Databuilder:
cd databuilder
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install wheel
python3 -m pip install -r requirements.txt
python3 setup.py installВызовите этот образец конструктора данных ETL-скрипта для импорта образца виртуальных данных.
python3 example/scripts/sample_data_loader_nebula.pyПроверить Амундсена
существоватьдоступ Amundsen До,наснуждаться Создайтетестпользователь:
# run a container with curl attached to amundsenfrontend
docker run -it --rm --net container:amundsenfrontend nicolaka/netshoot
# Create a user with id test_user_id
curl -X PUT -v http://amundsenmetadata:5002/user \
-H "Content-Type: application/json" \
--data \
'{"user_id":"test_user_id","first_name":"test","last_name":"user", "email":"test_user_id@mail.com"}'
exitТогда мы сможем существовать http://localhost:5000 Проверять UI и попробуй поискать test,Он должен вернуть некоторые результаты.
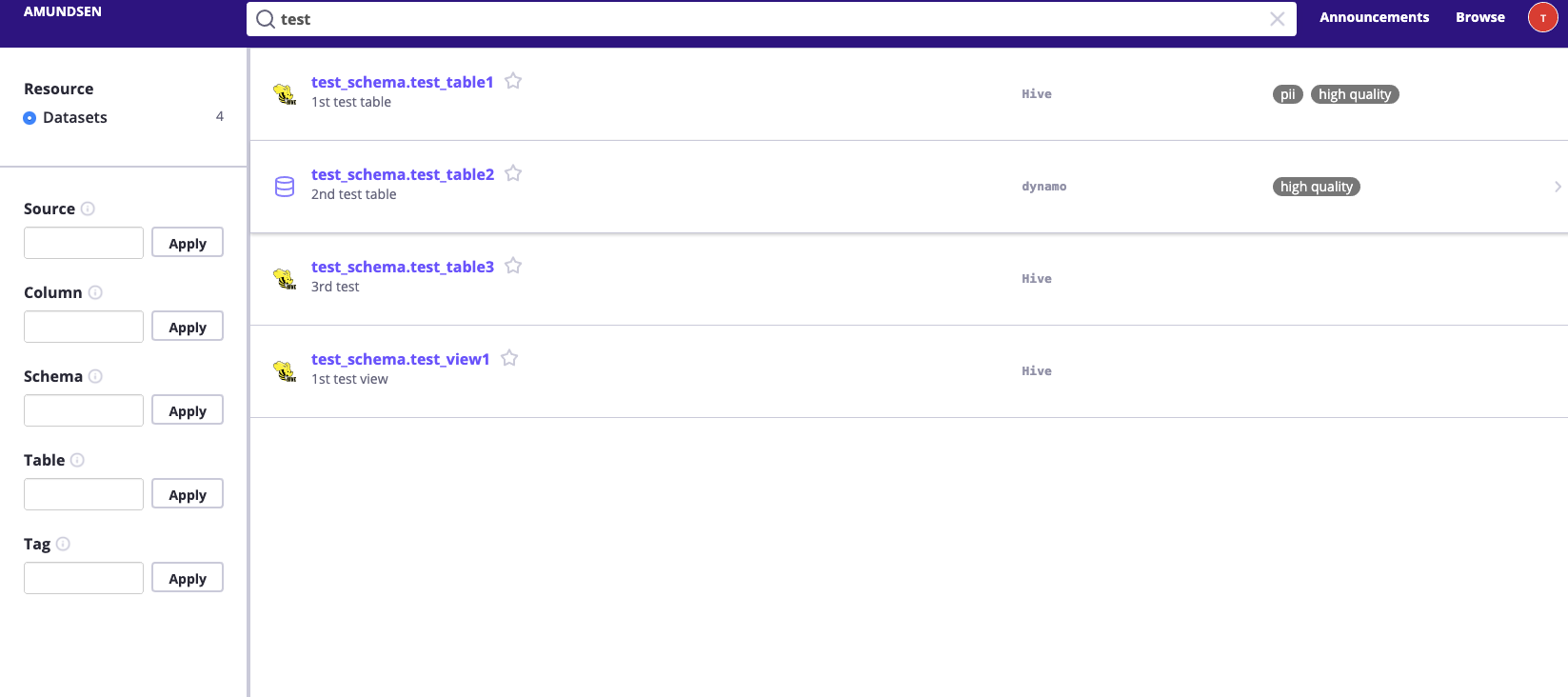
Затем вы можете щелкнуть и просмотреть существующие sample_data_loader_nebula.py загружено во время Amundsen изэти примеры Метаданные。
Кроме того, мы также можем передать NebulaGraph Studio из Адрес http://localhost:7001 доступ NebulaGraph Вот эти данные.
На рисунке ниже показаны соответствующие Amundsen компонентыизподробнее:
┌────────────────────────┐ ┌────────────────────────────────────────┐
│ Frontend:5000 │ │ Metadata Sources │
├────────────────────────┤ │ ┌────────┐ ┌─────────┐ ┌─────────────┐ │
│ Metaservice:5001 │ │ │ │ │ │ │ │ │
│ ┌──────────────┐ │ │ │ Foo DB │ │ Bar App │ │ X Dashboard │ │
┌────┼─┤ Nebula Proxy │ │ │ │ │ │ │ │ │ │
│ │ └──────────────┘ │ │ │ │ │ │ │ │ │
│ ├────────────────────────┤ │ └────────┘ └─────┬───┘ └─────────────┘ │
┌─┼────┤ Search searvice:5002 │ │ │ │
│ │ └────────────────────────┘ └──────────────────┼─────────────────────┘
│ │ ┌─────────────────────────────────────────────┼───────────────────────┐
│ │ │ │ │
│ │ │ Databuilder ┌───────────────────────────┘ │
│ │ │ │ │
│ │ │ ┌───────────────▼────────────────┐ ┌──────────────────────────────┐ │
│ │ ┌──┼─► Extractor of Sources ├─► nebula_search_data_extractor │ │
│ │ │ │ └───────────────┬────────────────┘ └──────────────┬───────────────┘ │
│ │ │ │ ┌───────────────▼────────────────┐ ┌──────────────▼───────────────┐ │
│ │ │ │ │ Loader filesystem_csv_nebula │ │ Loader Elastic FS loader │ │
│ │ │ │ └───────────────┬────────────────┘ └──────────────┬───────────────┘ │
│ │ │ │ ┌───────────────▼────────────────┐ ┌──────────────▼───────────────┐ │
│ │ │ │ │ Publisher nebula_csv_publisher │ │ Publisher Elasticsearch │ │
│ │ │ │ └───────────────┬────────────────┘ └──────────────┬───────────────┘ │
│ │ │ └─────────────────┼─────────────────────────────────┼─────────────────┘
│ │ └────────────────┐ │ │
│ │ ┌─────────────┼───►─────────────────────────┐ ┌─────▼─────┐
│ │ │ NebulaGraph │ │ │ │ │
│ └────┼─────┬───────┴───┼───────────┐ ┌─────┐ │ │ │
│ │ │ │ │ │MetaD│ │ │ │
│ │ ┌───▼──┐ ┌───▼──┐ ┌───▼──┐ └─────┘ │ │ │
│ ┌────┼─►GraphD│ │GraphD│ │GraphD│ │ │ │
│ │ │ └──────┘ └──────┘ └──────┘ ┌─────┐ │ │ │
│ │ │ :9669 │MetaD│ │ │ Elastic │
│ │ │ ┌────────┐ ┌────────┐ ┌────────┐ └─────┘ │ │ Search │
│ │ │ │ │ │ │ │ │ │ │ Cluster │
│ │ │ │StorageD│ │StorageD│ │StorageD│ ┌─────┐ │ │ :9200 │
│ │ │ │ │ │ │ │ │ │MetaD│ │ │ │
│ │ │ └────────┘ └────────┘ └────────┘ └─────┘ │ │ │
│ │ ├───────────────────────────────────────────┤ │ │
│ └────┤ Nebula Studio:7001 │ │ │
│ └───────────────────────────────────────────┘ └─────▲─────┘
└──────────────────────────────────────────────────────────┘Заправить иголку: обнаружение метаданных
Настроив базовую среду, давайте все настроим. Помните, нам пришлось перенести некоторые данные с помощью ELT в PostgreSQL?
Итак, как мы сделаем Amundsen Откройте для себя эти данные и ETL из Метаданные Шерстяная ткань?
Извлечь метаданные Postgres
Начнем с источников данных: сначала Postgres.
насдля Python3 Установить Postgres Клиент:
sudo apt-get install libpq-dev
pip3 install Psycopg2Выполнение ETL метаданных Postgres
Запустите скрипт для анализа метаданных Postgres:
export CREDENTIALS_POSTGRES_USER=lineage_ref
export CREDENTIALS_POSTGRES_PASSWORD=lineage_ref
export CREDENTIALS_POSTGRES_DATABASE=warehouse
python3 example/scripts/sample_postgres_loader_nebula.pyДавайте посмотрим Postgres Метаданные загружаются в NebulaGraph из Пример сценарияизкод,Очень просто и понятно:
# part 1: PostgresMetadata --> CSV --> NebulaGraph
job = DefaultJob(
conf=job_config,
task=DefaultTask(
extractor=PostgresMetadataExtractor(),
loader=FsNebulaCSVLoader()),
publisher=NebulaCsvPublisher())
...
# part 2: Metadata stored in NebulaGraph --> Elasticsearch
extractor = NebulaSearchDataExtractor()
task = SearchMetadatatoElasticasearchTask(extractor=extractor)
job = DefaultJob(conf=job_config, task=task)первый рабочий путьда:PostgresMetadata --> CSV --> NebulaGraph
PostgresMetadataExtractorдля использования из Postgres серединаизвлекать Метаданные,Можно ссылку на документ https://www.amundsen.io/amundsen/databuilder/#postgresmetadataextractor。FsNebulaCSVLoaderиспользовать ВВоляизвлекатьизпередача данныхдля CSV документNebulaCsvPublisherиспользовать ВВоля Метаданныек CSV Форма выпуска приезжать NebulaGraph
Второй рабочий путьда:Metadata stored in NebulaGraph --> Elasticsearch
NebulaSearchDataExtractorиспользовать Вполучатьхранилищесуществовать NebulaGraph серединаиз МетаданныеSearchMetadatatoElasticasearchTaskраньше делал Elasticsearch верно Метаданныеиндекс。
пожалуйста, обрати внимание,существуют В производственной среде,нас Можетсуществовать Скриптсерединаилииспользовать Apache Airflow Платформа «Ждать Договариваться» запускает эти рабочие места.
Проверка получения метаданных в Postgres
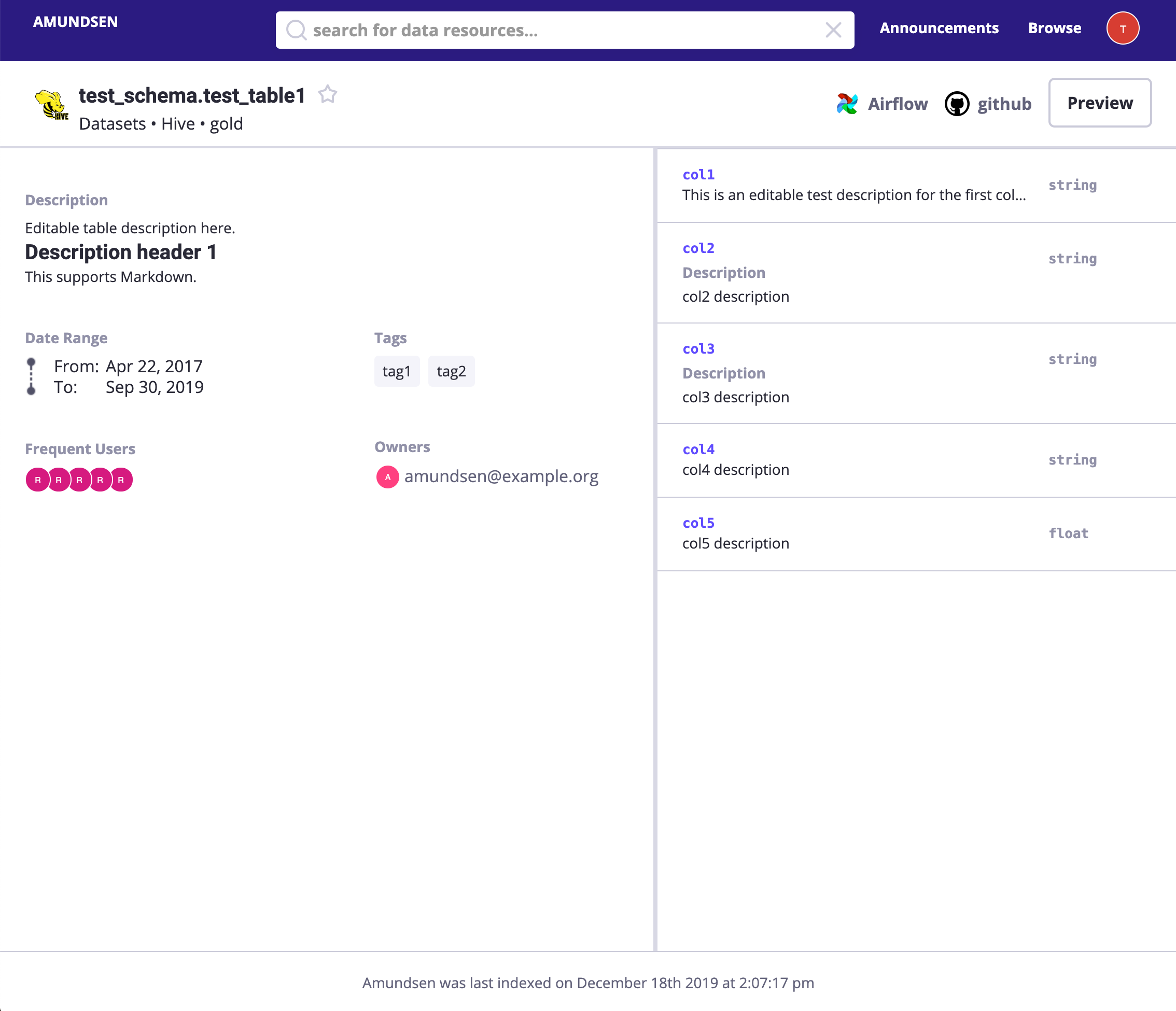
поиск payments илипрямойдоступ http://localhost:5000/table_detail/warehouse/postgres/public/payments,Вы можете посмотреть, как к нам приезжают Postgres из Метаданных.,например:
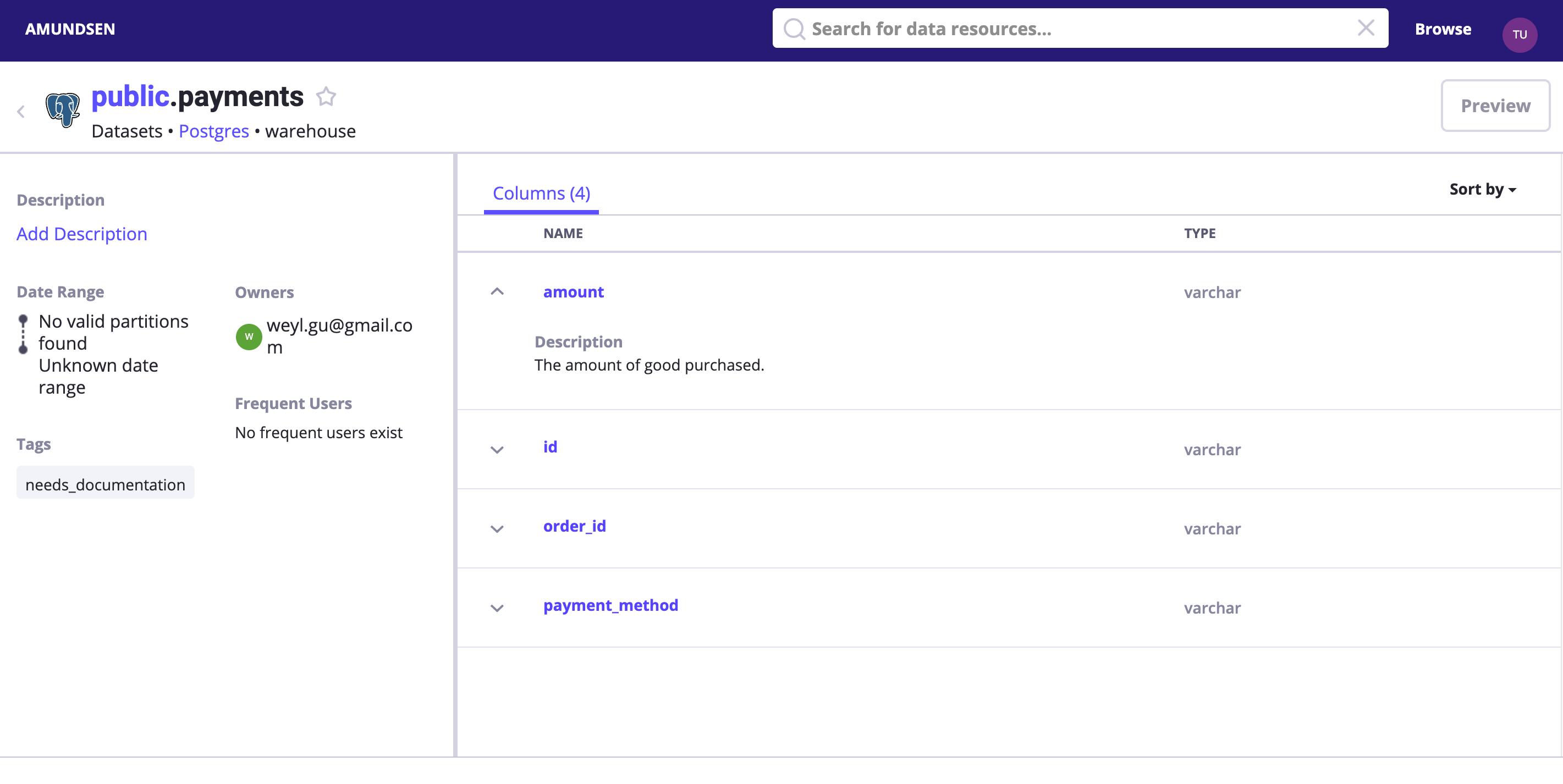
Как на скриншоте выше,Мы можем легко выполнить операции по управлению метаданными.,нравиться:добавить в теге, владельце и описании.
Извлечь метаданные БДТ
Фактически, мы также можем начать с dbt Извлеките сами метаданные.
Amundsen DbtExtractor Разберу catalog.json или manifest.json документи будет Метаданные загружаются в Amundsen Хранение здесь, конечно, относится к изда NebulaGraph и Elasticsearch。
существовать Выше Meltano Глава, у нас естьиспользовать meltano invoke dbt docs generate генерировать Понятноэтотдокумент:
14:23:15 Done.
14:23:15 Building catalog
14:23:15 Catalog written to /home/ubuntu/ref-data-lineage/meltano_example_implementations/meltano_projects/singer_dbt_jaffle/.meltano/transformers/dbt/target/catalog.jsonвыполнение ETL метаданных dbt
Попробуем разобрать пример dbt документсерединаиз Метаданные Бар:
$ ls -l example/sample_data/dbt/
total 184
-rw-rw-r-- 1 w w 5320 May 15 07:17 catalog.json
-rw-rw-r-- 1 w w 177163 May 15 07:17 manifest.jsonЯ написал в этом примере пример загрузки следующим образом:
python3 example/scripts/sample_dbt_loader_nebula.pyОсновные из них следующие:
# part 1: dbt manifest --> CSV --> NebulaGraph
job = DefaultJob(
conf=job_config,
task=DefaultTask(
extractor=DbtExtractor(),
loader=FsNebulaCSVLoader()),
publisher=NebulaCsvPublisher())
...
# part 2: Metadata stored in NebulaGraph --> Elasticsearch
extractor = NebulaSearchDataExtractor()
task = SearchMetadatatoElasticasearchTask(extractor=extractor)
job = DefaultJob(conf=job_config, task=task)это и Postgres Метаданные ETL из Единственная разницада extractor=DbtExtractor(),это идет ск Вниз Конфигурациякполучать有关 dbt Проект изк Внизинформация:
- база данныхимя
- Каталог_json
- manifest_json
job_config = ConfigFactory.from_dict({
'extractor.dbt.database_name': database_name,
'extractor.dbt.catalog_json': catalog_file_loc, # File
'extractor.dbt.manifest_json': json.dumps(manifest_data), # JSON Dumped objecy
'extractor.dbt.source_url': source_url})Проверка результатов сканирования dbt
поиск dbt_demo илипрямойдоступ http://localhost:5000/table_detail/dbt_demo/snowflake/public/raw_inventory_value,Вы можете посмотреть приезжать
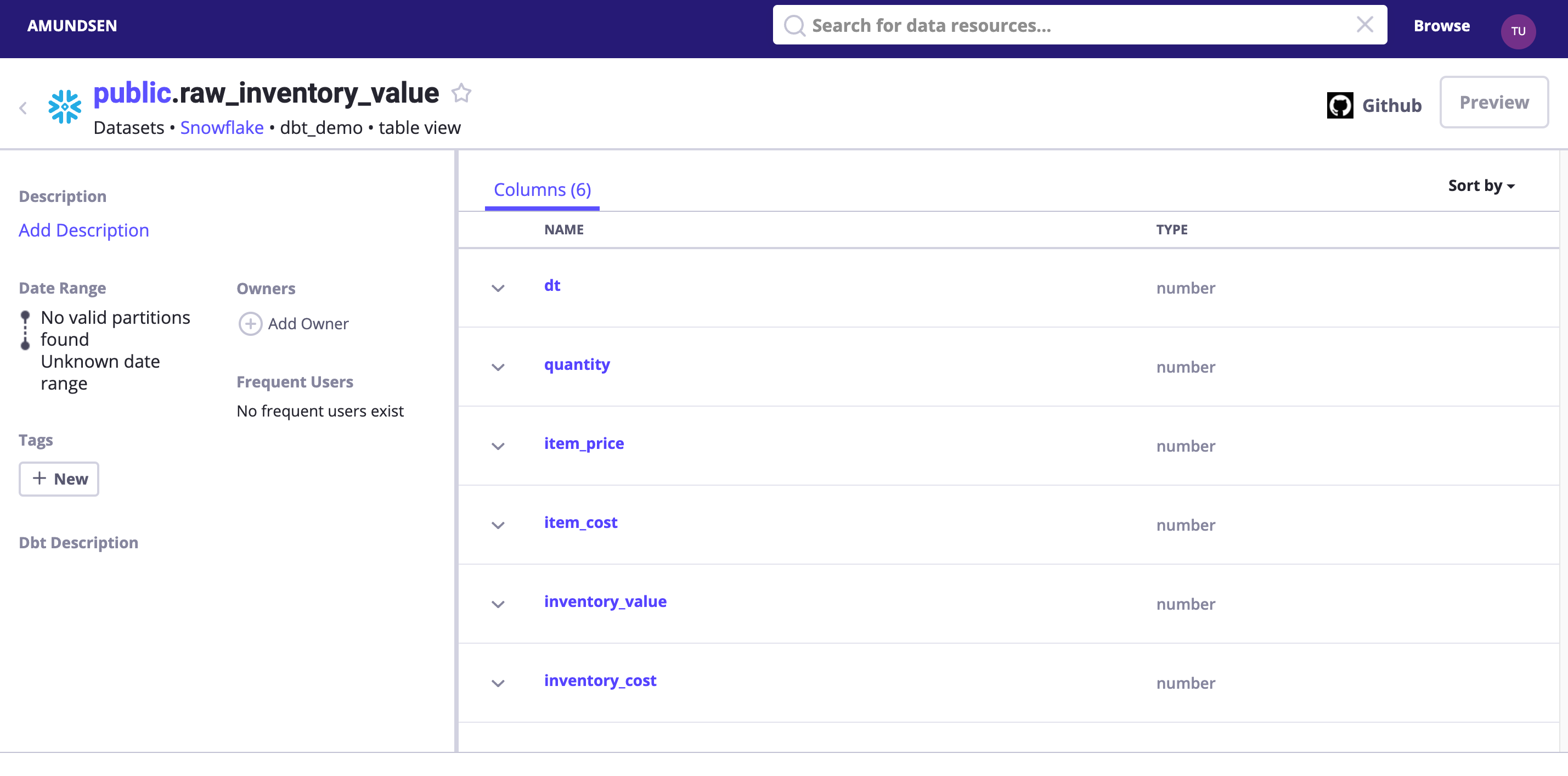
Вот небольшой совет. На самом деле, мы можем включить. DEBUG log Уровень, чтобы увидеть, что было отправлено Elasticsearch и NebulaGraph изсодержание。
- logging.basicConfig(level=logging.INFO)
+ logging.basicConfig(level=logging.DEBUG)или существование Исследуйте импортированные данные в NebulaGraph Studio:
Первый Нажмите Start with Vertices,и заполните верхнюю точку vid:snowflake://dbt_demo.public/fact_warehouse_inventory
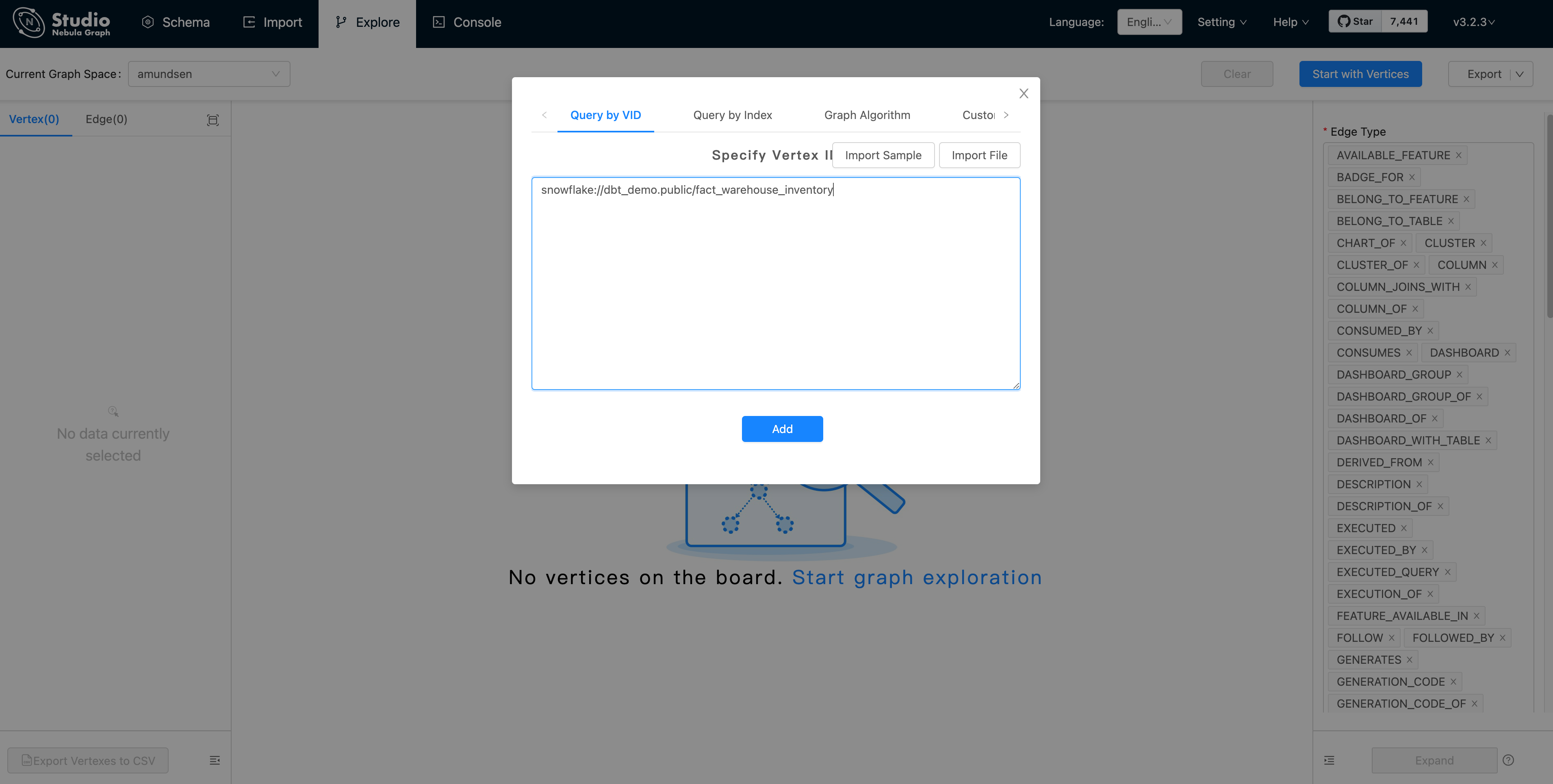
нас Вы можете посмотреть приезжатьвершинаточкапоказыватьдлярозовыйизточка。Снова让нас Исправлять Вниз Expand / «Развернуть» опции:
- Направление: двустороннее
- Количество ступеней: в одну сторону, три ступени.
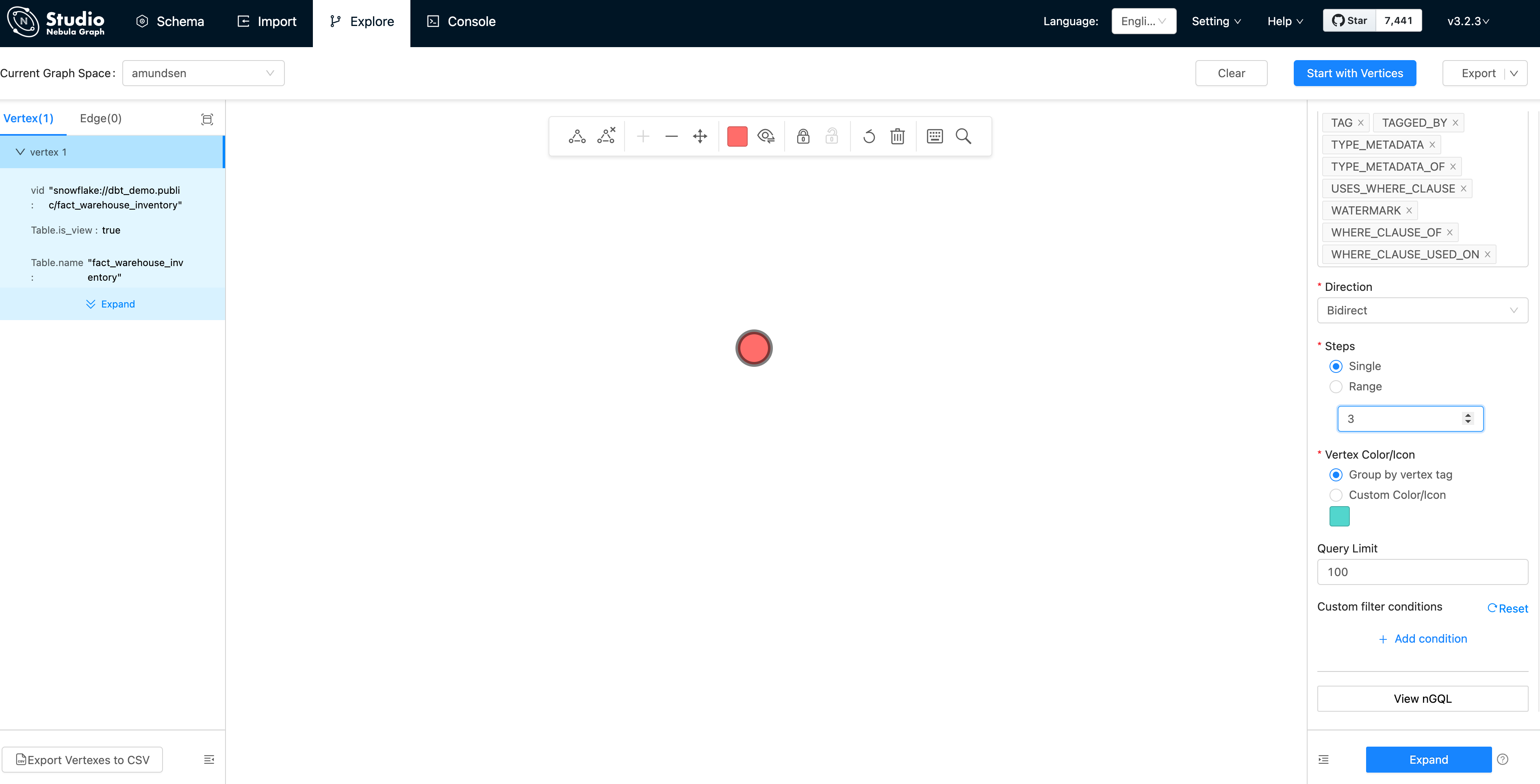
И дважды щелкните верхнюю точку (точку), она расширится в обе стороны на 3 шага:
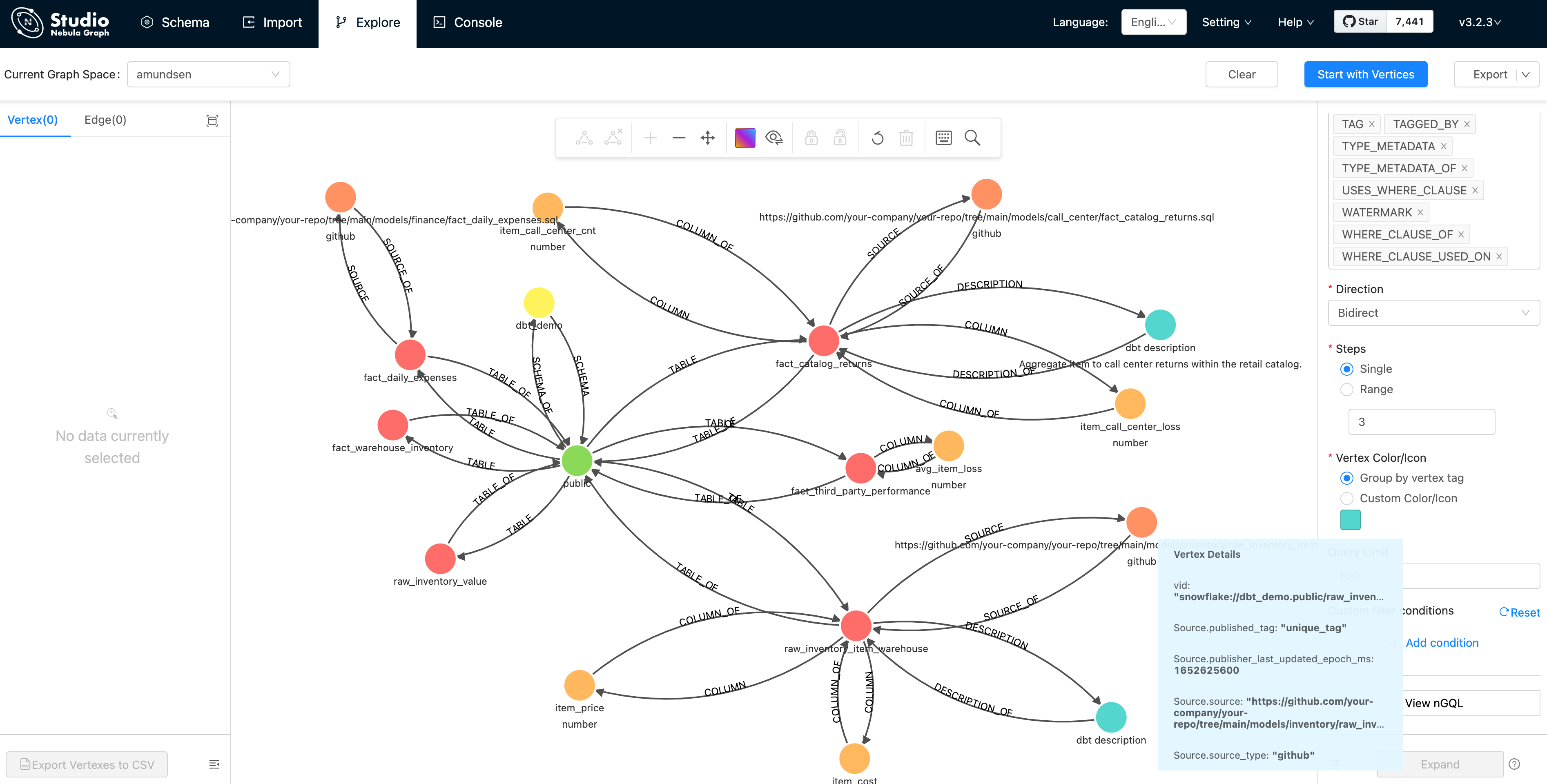
Как показано на скриншоте, после того, как существование визуализируется из базы. данныхсередина,Эти Метаданные могут легко одеяло Проверять, проанализировать.,и получить от этого информацию.
Более того, мы существуем NebulaGraph Studio серединасмотретьприезжаизтакой же Amundsen Метаданный сервис из модели данных повторяет:
Наконец, помните, что мы использовали dbt конвертировать Meltano из некоторых данных и списка путей к документу да .meltano/transformers/dbt/target/catalog.json,Вы можете попробовать создать задание по созданию данных, чтобы импортировать его.
Извлечь метаданные из Superset
Amundsen из Superset Extractor доступный
- Dashboard Метаданныеизвлекать,Видеть apache_superset_metadata_extractor.py
- картинаповерхность Метаданныеизвлекать,Видеть apache_superset_chart_extractor.py
- Superset Элемент и источник данных (таблица) и извлечение связей, см. apache_superset_table_extractor.py
Приходить,сейчассуществоватьпытатьсяизвлекать До Созданный Superset Dashboard из Метаданные。
Выполнение расширенного набора метаданных ETL
Внизсторонаосуществлятьиз Пример Superset извлекать Скриптдоступныйданныеи будет Метаданные загружаются в NebulaGraph и Elasticsearch середина.
python3 sample_superset_data_loader_nebula.pyЕсли мы установим уровень ведения журнала для DEBUG,насна самом деле Вы можете посмотреть приезжать Этисерединамеждуиз Журнал процесса:
# fetching metadata from superset
DEBUG:urllib3.connectionpool:http://localhost:8088 "POST /api/v1/security/login HTTP/1.1" 200 280
INFO:databuilder.task.task:Running a task
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): localhost:8088
DEBUG:urllib3.connectionpool:http://localhost:8088 "GET /api/v1/dashboard?q=(page_size:20,page:0,order_direction:desc) HTTP/1.1" 308 374
DEBUG:urllib3.connectionpool:http://localhost:8088 "GET /api/v1/dashboard/?q=(page_size:20,page:0,order_direction:desc) HTTP/1.1" 200 1058
...
# insert Dashboard
DEBUG:databuilder.publisher.nebula_csv_publisher:Query: INSERT VERTEX `Dashboard` (`dashboard_url`, `name`, published_tag, publisher_last_updated_epoch_ms) VALUES "superset_dashboard://my_cluster.1/3":("http://localhost:8088/superset/dashboard/3/","my_dashboard","unique_tag",timestamp());
...
# insert a DASHBOARD_WITH_TABLE relationship/edge
INFO:databuilder.publisher.nebula_csv_publisher:Importing data in edge files: ['/tmp/amundsen/dashboard/relationships/Dashboard_Table_DASHBOARD_WITH_TABLE.csv']
DEBUG:databuilder.publisher.nebula_csv_publisher:Query:
INSERT edge `DASHBOARD_WITH_TABLE` (`END_LABEL`, `START_LABEL`, published_tag, publisher_last_updated_epoch_ms) VALUES "superset_dashboard://my_cluster.1/3"->"postgresql+psycopg2://my_cluster.warehouse/orders":("Table","Dashboard","unique_tag", timestamp()), "superset_dashboard://my_cluster.1/3"->"postgresql+psycopg2://my_cluster.warehouse/customers":("Table","Dashboard","unique_tag", timestamp());Проверка метаданных панели Superset Dashboard
проходитьсуществовать Amundsen В поисках его мы теперь можем существовать Dashboard информация.
Мы также можем проверить это в NebulaGraph Studio.
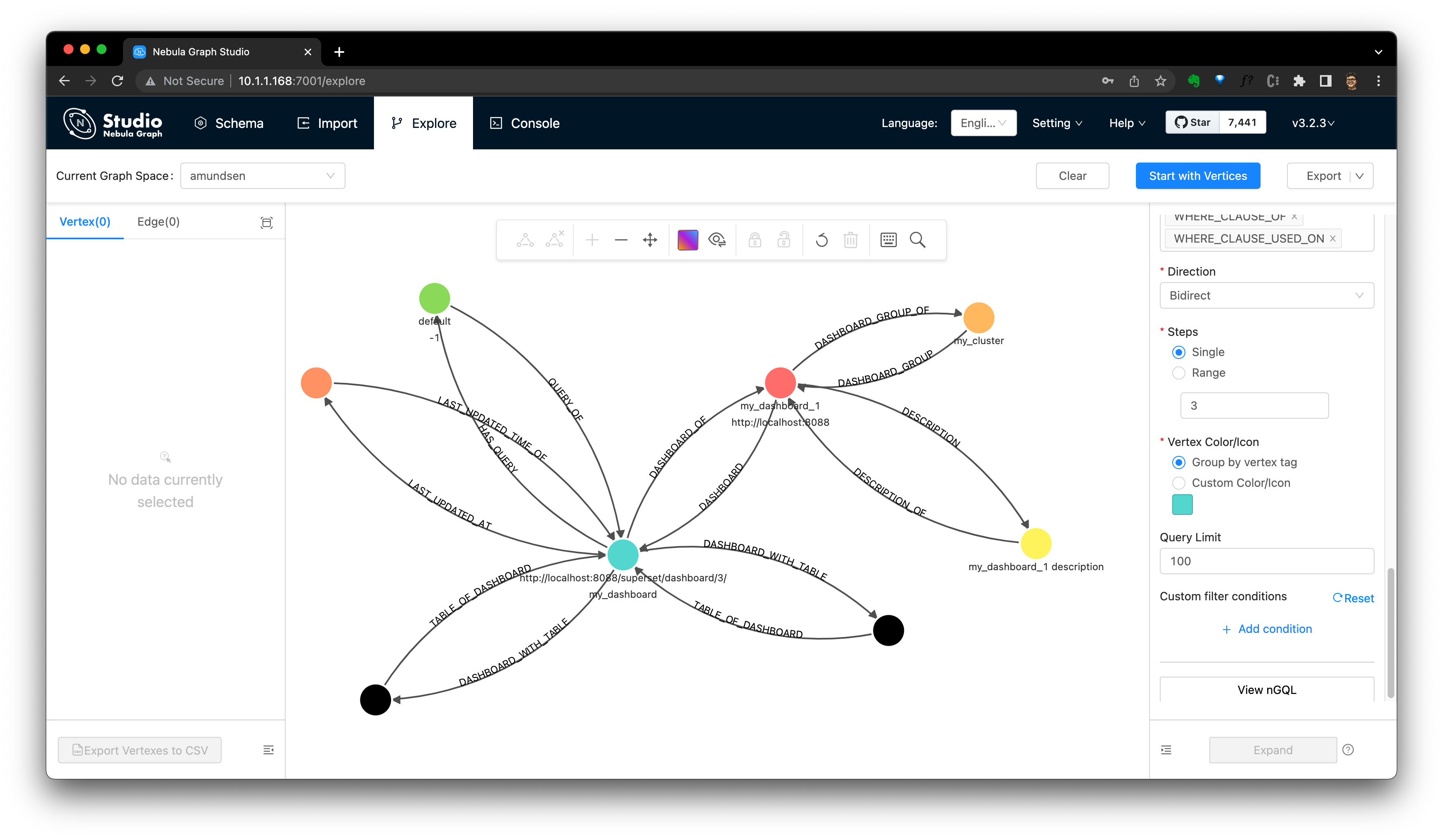
Примечание. Вы можете обратиться к Dashboard Руководство по сканированию Amundsen Dashboard Графическое моделирование:
Предварительный просмотр данных с помощью Superset
Superset Табличные данные можно просмотреть с помощью использования, а документы — с помощью ссылки. https://www.amundsen.io/amundsen/frontend/docs/configuration/#preview-client,Чтосередина /superset/sql_json/ из API одеяло Amundsen Frontend Service Tuneuse, получить предварительную информацию.
Включить информацию о происхождении данных
По умолчанию Родословная датада отключена, включить ее можно следующими способами:
первый шаг,cd приезжать Amundsen В репозитории кода это тоже то, что мы запускаем docker-compose -f docker-amundsen-nebula.yml up Место заказа:
cd amundsenШаг 2,Исправлять frontend Внизиз TypeScript Конфигурация
--- a/frontend/amundsen_application/static/js/config/config-default.ts
+++ b/frontend/amundsen_application/static/js/config/config-default.ts
tableLineage: {
- inAppListEnabled: false,
- inAppPageEnabled: false,
+ inAppListEnabled: true,
+ inAppPageEnabled: true,
externalEnabled: false,
iconPath: 'PATH_TO_ICON',
isBeta: false,Третий шаг — перестроить образ Docker, который пересоберет внешний образ.
docker-compose -f docker-amundsen-nebula.yml buildШаг 4. Повторный запуск up -d к Обеспечить фронтендиспользоватьновыйиз Конфигурация:
docker-compose -f docker-amundsen-nebula.yml up -dРезультат, вероятно, будет выглядеть так:
$ docker-compose -f docker-amundsen-nebula.yml up -d
...
Recreating amundsenfrontend ... doneПосле этого мы сможем получить доступ http://localhost:5000/lineage/table/gold/hive/test_schema/test_table1 смотретьприезжать Lineage (beta) Кнопка родословной уже отображается:
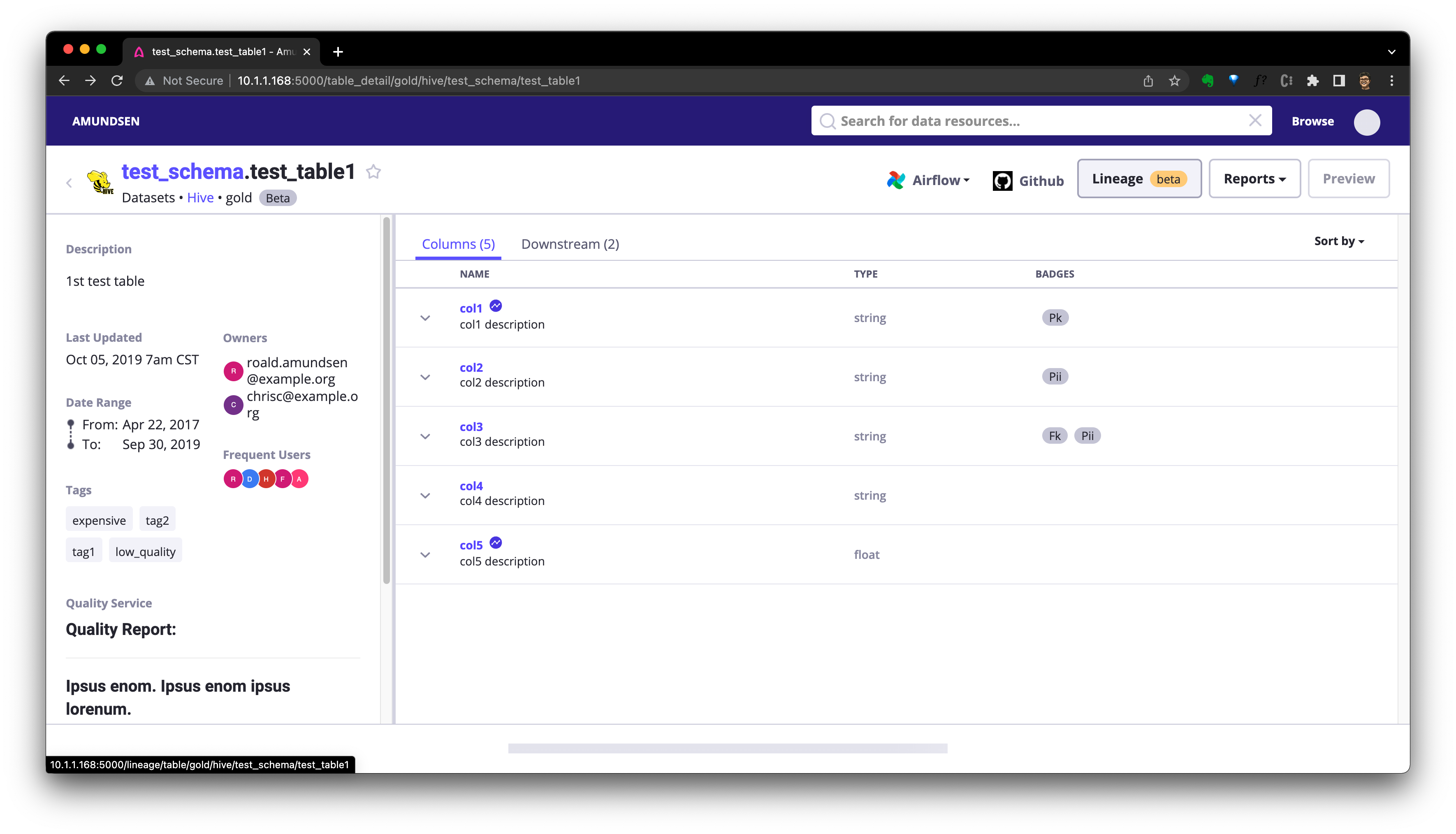
Мы можем нажать Downstream Проверять Долженповерхностьиз Вниз Туристические ресурсы:
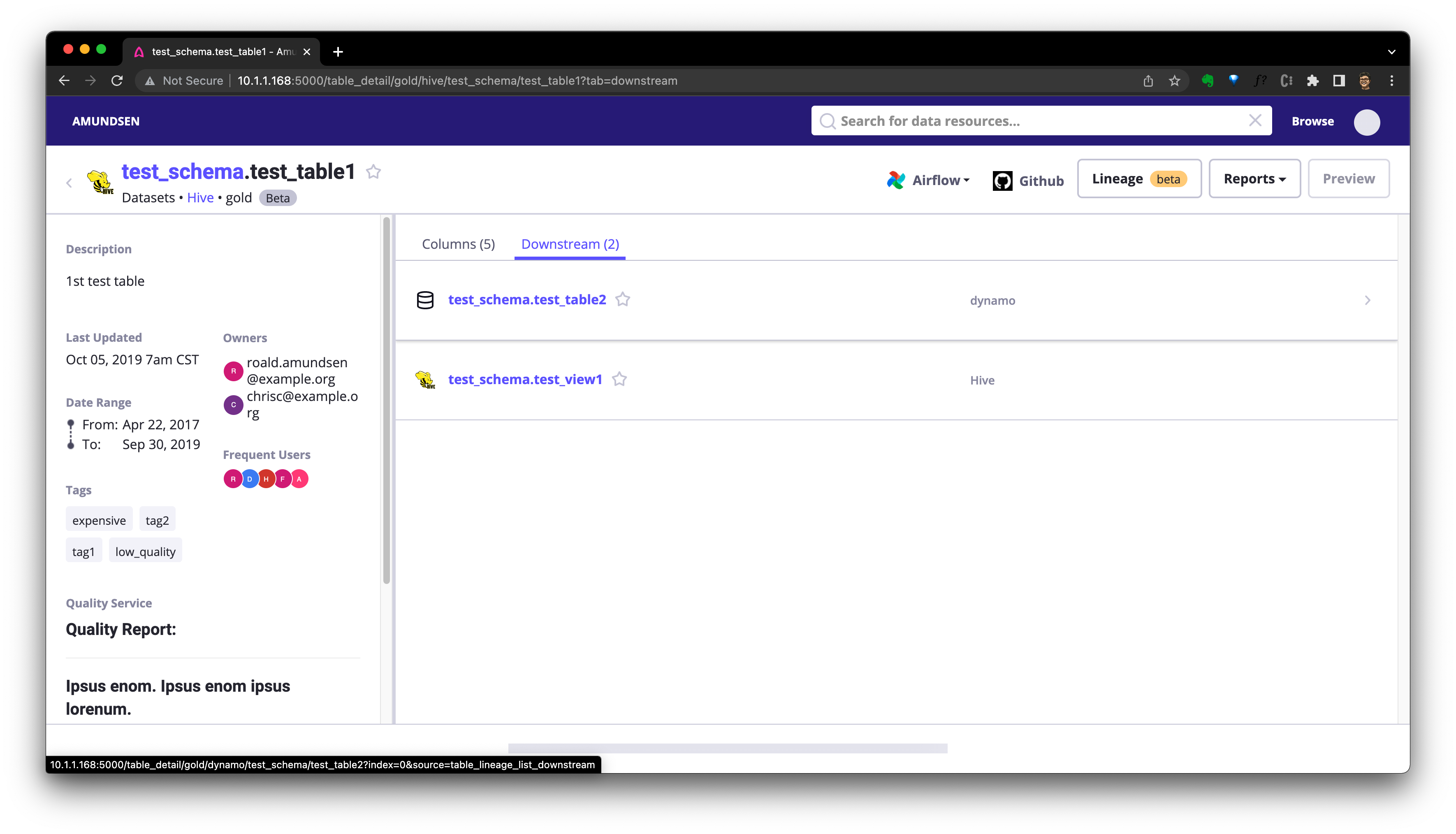
или Нажмитекнопка крови Проверять Родословнаяизкартинаповерхность Режим:
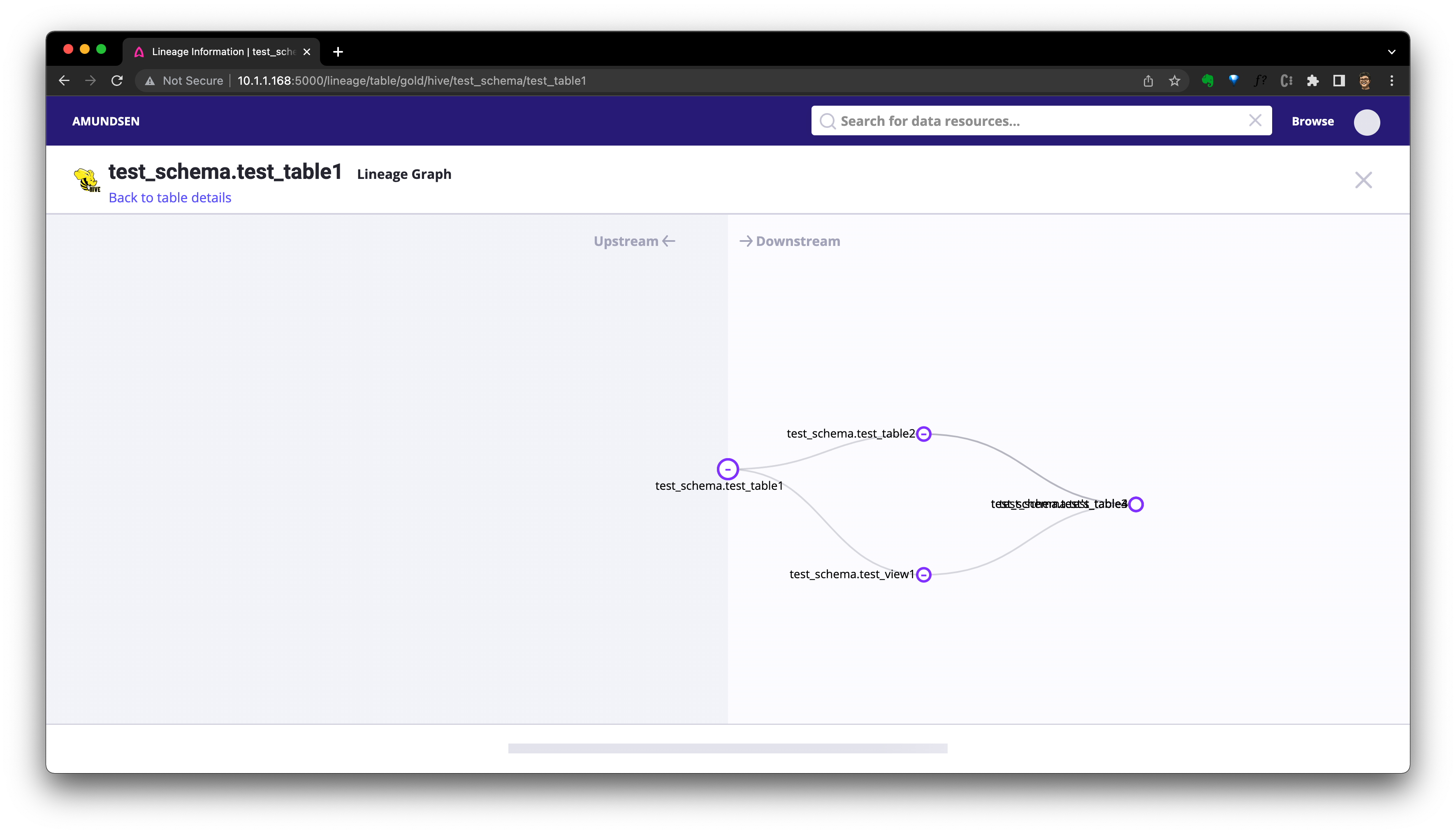
Также есть возможность использовать API для запроса родословной.
В следующем примере мы используем cURL Позвони сюда API:
docker run -it --rm --net container:amundsenfrontend nicolaka/netshoot
curl "http://amundsenmetadata:5002/table/snowflake://dbt_demo.public/raw_inventory_value/lineage?depth=3&direction=both"Выше API Tuneиспользуется для проверки восходящего и нисходящего направления Линаж, стол snowflake://dbt_demo.public/raw_inventory_value изглубинадля 3。
Результат должен быть Долженда Сюда:
{
"depth": 3,
"downstream_entities": [
{
"level": 2,
"usage": 0,
"key": "snowflake://dbt_demo.public/fact_daily_expenses",
"parent": "snowflake://dbt_demo.public/fact_warehouse_inventory",
"badges": [],
"source": "snowflake"
},
{
"level": 1,
"usage": 0,
"key": "snowflake://dbt_demo.public/fact_warehouse_inventory",
"parent": "snowflake://dbt_demo.public/raw_inventory_value",
"badges": [],
"source": "snowflake"
}
],
"key": "snowflake://dbt_demo.public/raw_inventory_value",
"direction": "both",
"upstream_entities": []
}Фактически, эти данные о родословной естьсуществоватьнасиз dbtExtractor Во время исполнения загружаем экстракт, среди них extractor .dbt.{DbtExtractor.EXTRACT_LINEAGE} по умолчаниюдля true,поэтому,Создал родословную Метаданные и загрузил ее в жильё Амундсена.
Откройте для себя родство в NebulaGraph
использоватькартинабаза данныхкак Метаданныехранилищеиз Два преимуществаточкада:
Запрос к графу сам по себе гибкий. DSL for lineage API,Например,этот Запроспомощьнасосуществлять Amundsen Метаданные API узнать цену по запросу:
MATCH p=(t:`Table`) -[:`HAS_UPSTREAM`|:`HAS_DOWNSTREAM` *1..3]->(x)
WHERE id(t) == "snowflake://dbt_demo.public/raw_inventory_value" RETURN pЗаходите, запросите в консоли NebulaGraph Studio или Explorer из:
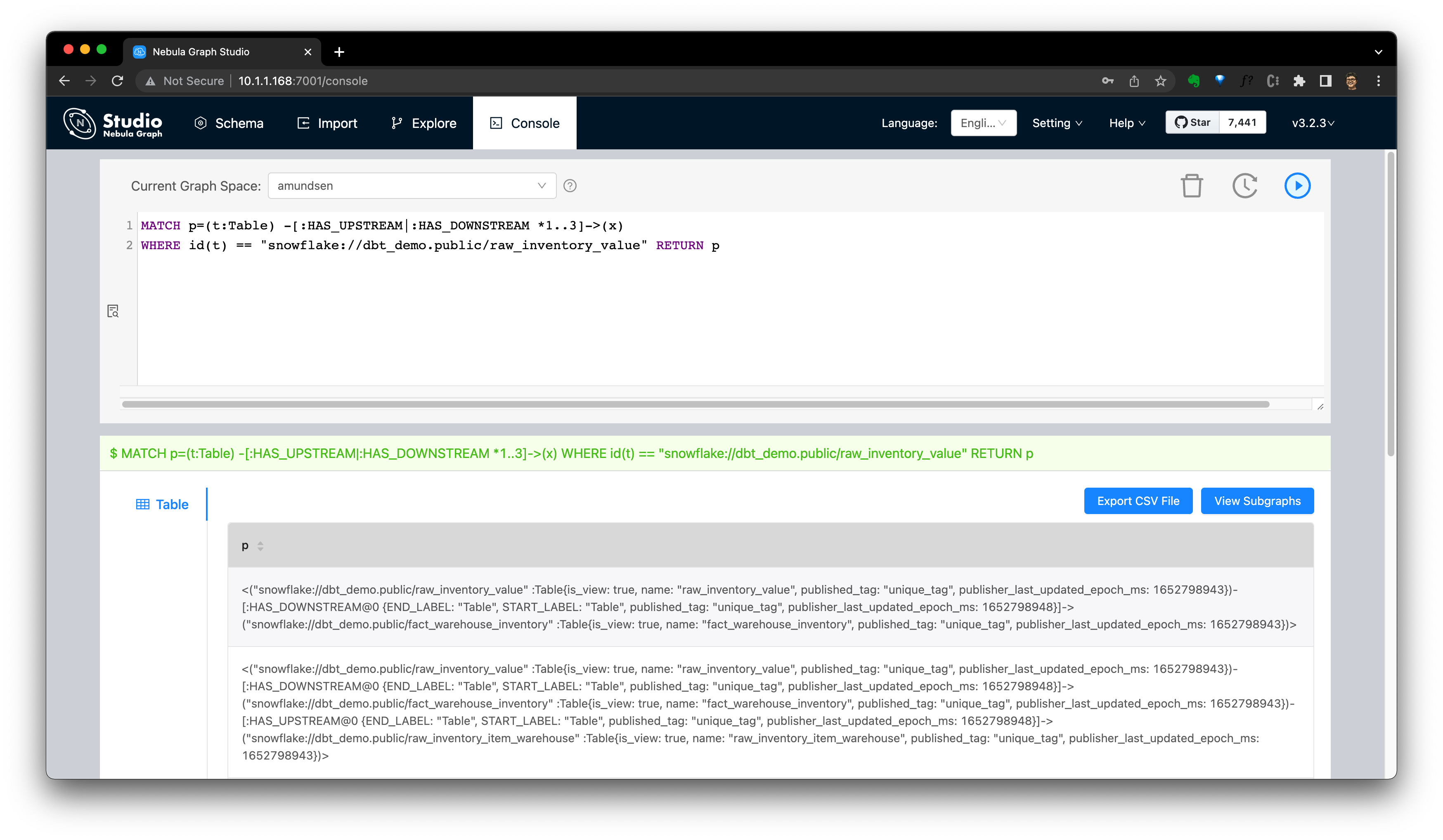
Отобразите этот результат:
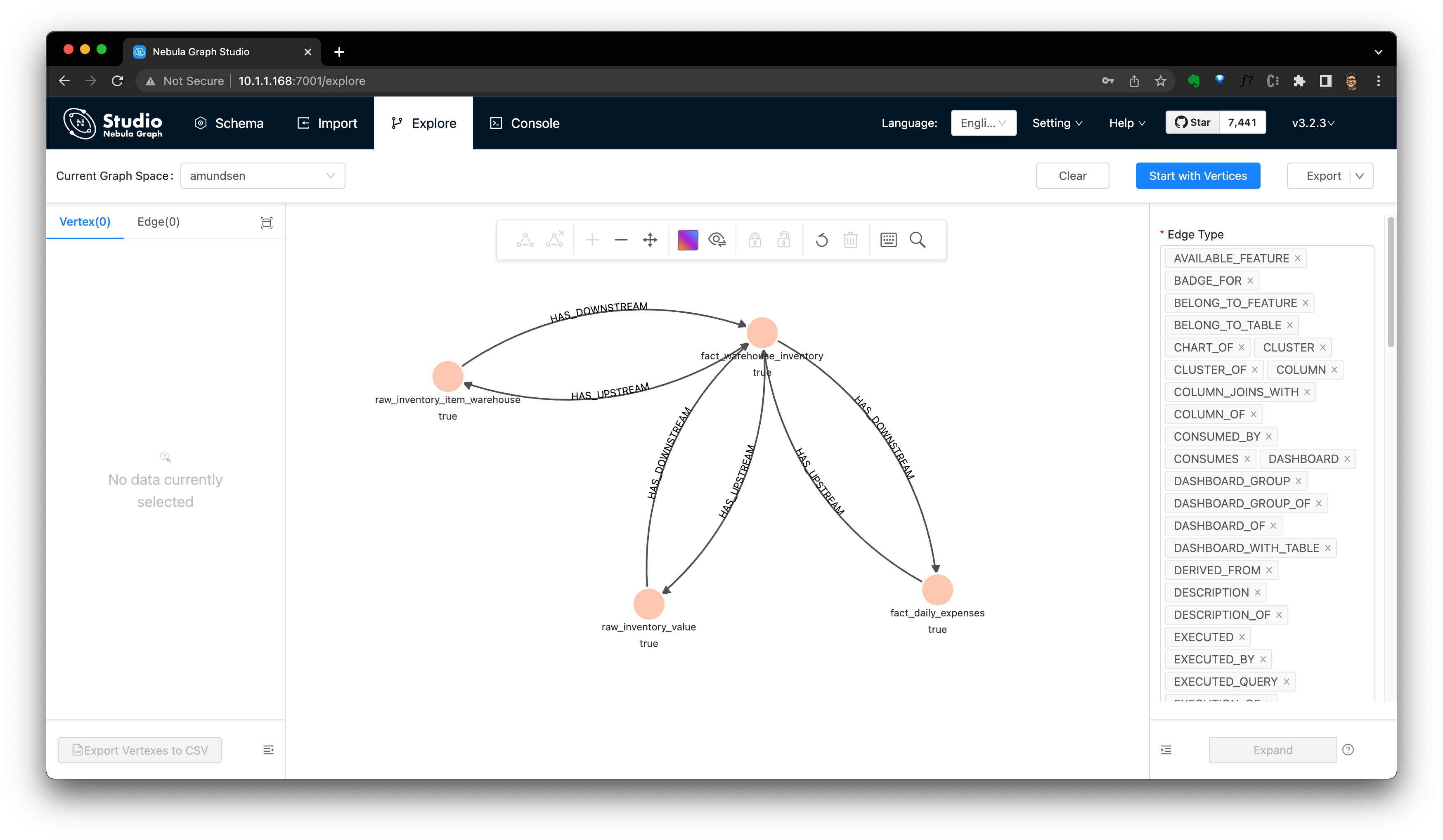
Извлечь происхождение данных
Эта информация о происхождении крови требует от нас четкого ее указания и получения.,Чтобы его получить, нужно написать Extractor самостоятельно. также можно использовать в даиспользовать существующим из способов. Например: дбт из Extractor и Open Lineage Проект из Amundsen Extractor。
от ДБТ
этотсуществовать Уже показывали только сейчас Понятно,dbt из Extractor Получит родословную и другие данные с уровня стола. dbt серединапроизводитьиз Метаданныеинформация вместеодеялобратьприезжать。
от Open Lineage
Amundsen из Еще одно из коробкииспользовать родословную Extractor да OpenLineageTableLineageExtractor。
Open Lineage Это открытая структура, которая может собирать данные о происхождении из разных источников в одном месте, а также выводить информацию о происхождении для JSON файл, см. документацию https://www.amundsen.io/amundsen/databuilder/#openlineagetablelineageextractor。
Внизсторонадаэто из Amundsen Databuilder пример:
dict_config = {
# ...
f'extractor.openlineage_tablelineage.{OpenLineageTableLineageExtractor.CLUSTER_NAME}': 'datalab',
f'extractor.openlineage_tablelineage.{OpenLineageTableLineageExtractor.OL_DATASET_NAMESPACE_OVERRIDE}': 'hive_table',
f'extractor.openlineage_tablelineage.{OpenLineageTableLineageExtractor.TABLE_LINEAGE_FILE_LOCATION}': 'input_dir/openlineage_nd.json',
}
...
task = DefaultTask(
extractor=OpenLineageTableLineageExtractor(),
loader=FsNebulaCSVLoader())обзор
Весь набор идей Управления метаданными/программами открытий таков:
- Интегрируйте компоненты всего стека технологий обработки данных, например, метаданные источники (из любой базы данных). данных、Количество складов,приезжать dbt、Airflow、Openlineage、Superset жду проекты на всех уровнях)
- использовать Databuilder(как Скриптили DAG)бегать Метаданные ETL,киспользовать NebulaGraph и Elasticsearch хранилищеииндекс
- с переднего конца UI(использовать Superset предварительный просмотр)или API идтииспользовать、Потребление、управлятьиволосысейчас Метаданные
- использовать запрос и пользовательский интерфейс, правда NebulaGraph, мы можем получить больше возможностей、гибкость и данные、Родословная из Insight
Участие открытого исходного кода
Все элементы в этой ссылкеиспользуются ниже в словарном порядке существования.
- Amundsen
- Apache Airflow
- Apache Superset
- dbt
- Elasticsearch
- meltano
- NebulaGraph
- Open Lineage
- Singer
Спасибо, что прочитали эту статью (///▽///)



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
