Как крупные производители реализуют решения для мультисистемной синхронизации данных?
1 фон
Поскольку появляется все больше бизнес-направлений и систем, потребность в синхронизации данных между системами или предприятиями становится все более частой. Большинство современных бизнес-систем Интернета используют решения для хранения и обработки данных MySQL:
- Взрыв информационного века,Недостатки постепенно выявляются в сценариях большого объема.,нравиться: Необходимость поиска по полному тексту большого количества данных.,Запрос большого количества комбинаций данных,изданные агрегатные запросы после сегментирования базы данных и таблицы
- Естественно, я думаю о том, как использовать другие компоненты (ES), более подходящие для решения такого рода задач.
Поэтому компаниям срочно необходимо гибкое и простое в использовании решение для синхронизации и обработки данных между системами, чтобы конкретные бизнес-данные можно было легко передавать между другими предприятиями или компонентами, а также способствовать быстрой бизнес-итерации.
2 Выбор решения
В настоящее время наиболее распространенными решениями для синхронизации системных данных в отрасли являются синхронная двойная запись, асинхронная двойная запись, прослушивание бинлога и т. д., каждое из которых имеет свои преимущества и недостатки. В этой статье объясняется случай синхронизации MySQL с ES.
2.1 Синхронная двойная запись
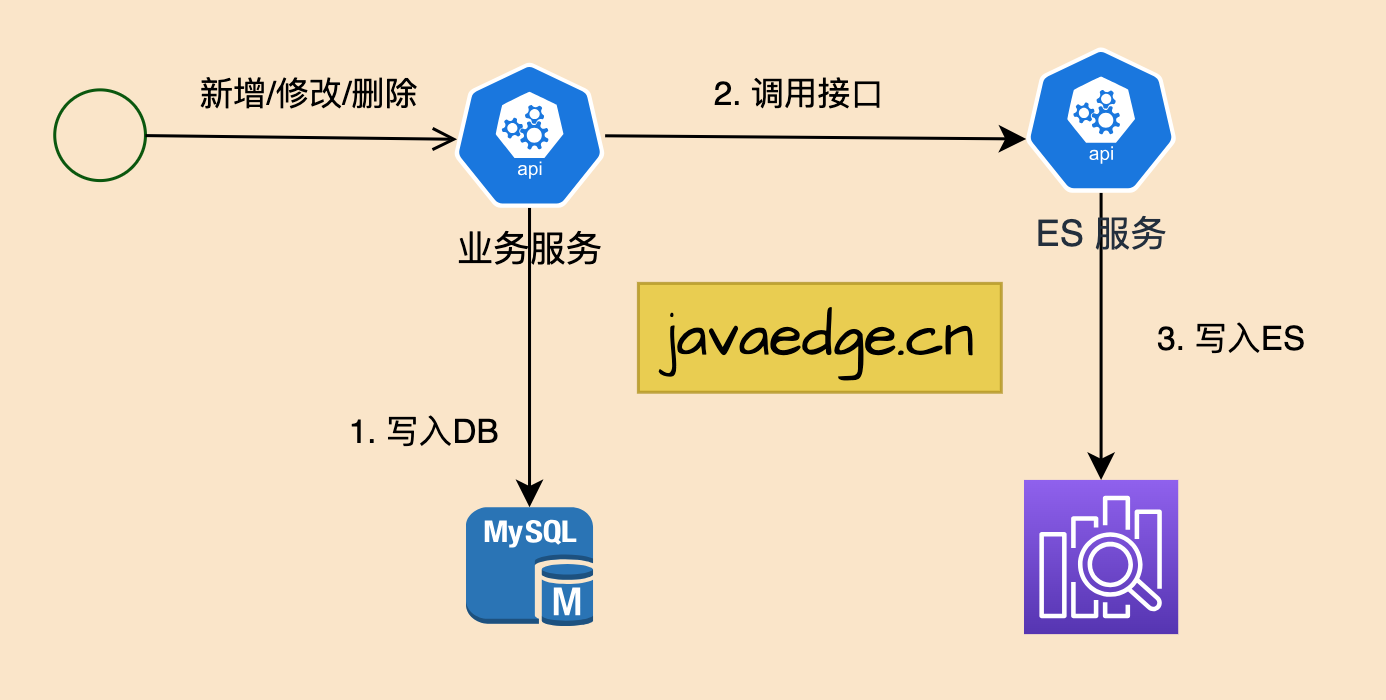
Самое простое решение — записать данные в ES при записи данных в MySQL, чтобы добиться двойной записи данных.
преимущество
- Дизайн простой и понятный
- Высокая производительность в реальном времени
недостаток
- Жесткое кодирование. Везде, где необходимо написать MySQL, необходимо добавить код для написания ES, что приводит к сильной бизнес-связи.
- Существует риск того, что двойная запись может привести к сбою и потере данных.
- ЕС недоступен
- Сбой сети между приложениями
- Перезапуск системы приложения,В итоге писать в ES уже поздно.
- Оказывают большее влияние на производительность,Потому что каждая бизнес-операция требует операции ES.,Если существуют строгие требования к согласованности данных,Все еще нужна обработка транзакций
2.2 Асинхронная двойная запись
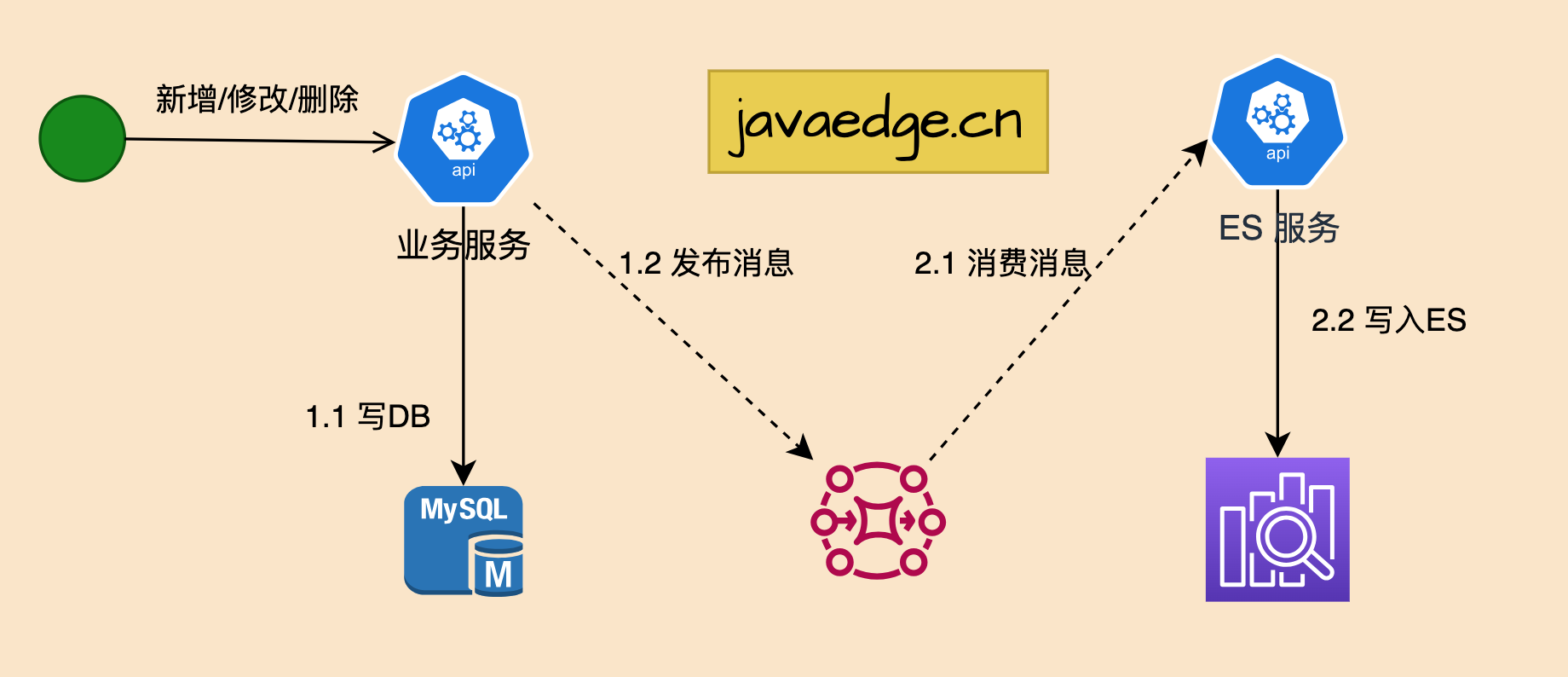
Добавьте MQ в основу синхронной двойной записи, чтобы добиться асинхронной записи.
преимущество
- Для решения проблем с производительностью производительность MQ в основном на порядок выше, чем у MySQL.
- Нелегко появитьсяданные Потерянная проблема,В основном на основе MQ Механизм гарантии потребления сообщений, например ES В случае простоя или сбоя записи потребление все равно можно возобновить. MQ информация
- Достигнута развязка системы за счет асинхронного метода.,Запись из нескольких источников изолирована друг от друга,Легко расширить более изданные исходные тексты
недостаток
- синхронизация данных в режиме реального времени,В связи с увеличением количества подключений к потребительской сети MQ,В результате пользователи, пишущие изданные, не обязательно увидят их сразу.,Есть задержка
- Хотя логика отделена, связь кода MQ все равно необходимо добавить в бизнес-логику.
- Повышенная сложность: обслуживание нескольких промежуточных программ MQ.
- Сложная проблема с кодированием,Доступ к новым источникам требует реализации новой логики потребления.
2.3 Мониторинг бинлога
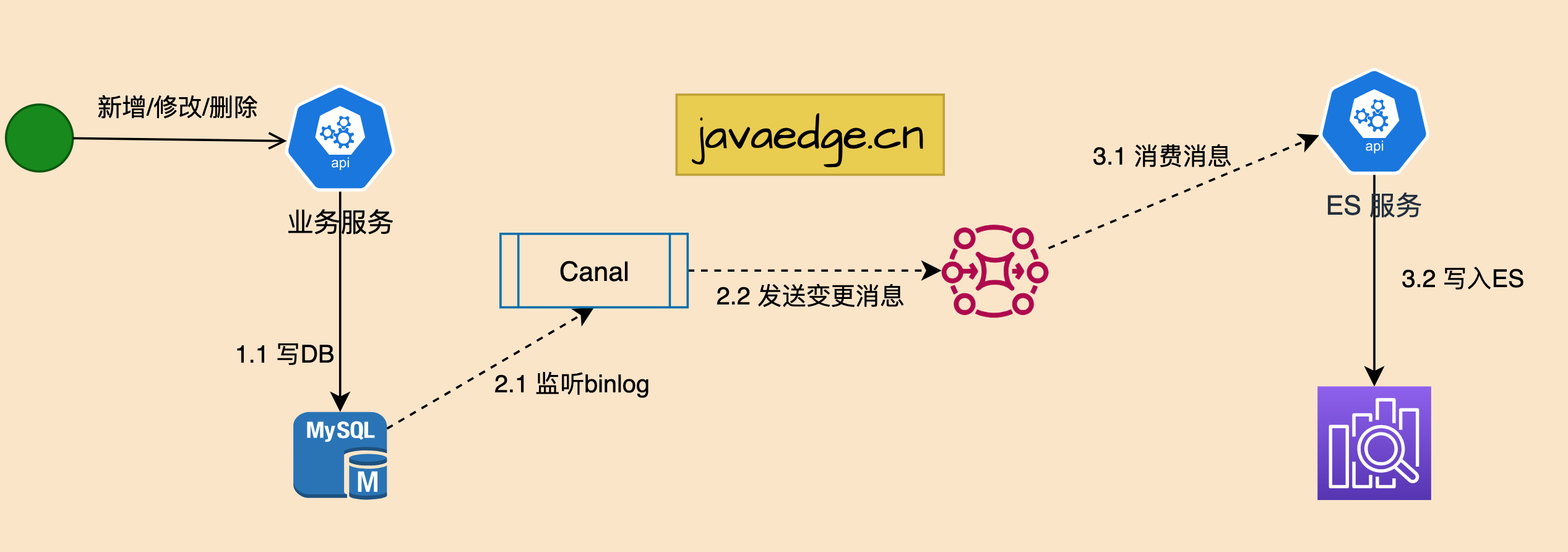
На основе второго решения в основном решается проблема бизнес-связанности, поэтому вводится автоматический механизм мониторинга и обработки изменений данных.
преимущество
- Без взлома кода,Оригинальная система не требует никаких изменений,Нет восприятия
- Высокая производительность, нет необходимости добавлять дополнительную логику в бизнес-код
- Очень низкая связь, нет необходимости фокусироваться в оригинальной системе бизнес-логика
недостаток
- Есть определенная техническая сложность
- синхронизация данных в режиме реального времени Может быть проблема
При разработке базовых компонентов в основном учитывается отсутствие вторжения в бизнес, отсутствие восприятия бизнес-доступа и низкая связанность системы. Таким образом, третий вариант выбора также учитывает, что это решение имеет недостатки в плане повторного использования и масштабируемости, поэтому на этом основании. , оптимизация завершена.
3 Общая схема схемы
3.1 Обзор
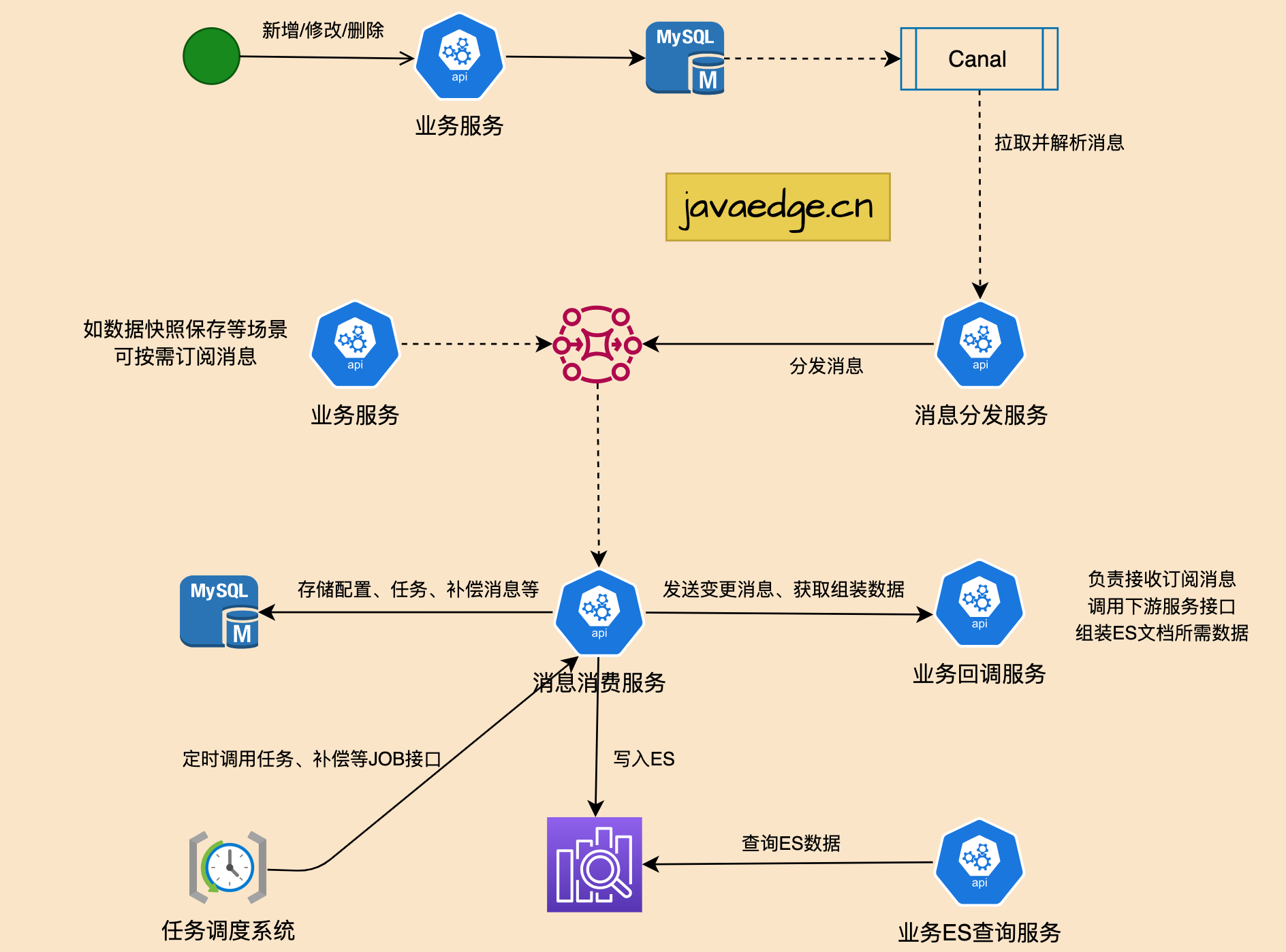
Все необходимые источники данных — это MySQL, поэтому сначала рассмотрите возможность выбора компонентов для мониторинга изменений данных MySQL в режиме реального времени. Наиболее известным зрелым решением в отрасли является [canal], которое отвечает требованиям функциональной полноты, активности сообщества и стабильности. Таким образом, третье решение оптимизировано на основе канала для обеспечения синхронизации данных в нескольких системах и достижения разделения бизнеса, возможности повторного использования и масштабируемости.
Основная концепция дизайна
Через единую «службу рассылки сообщений» реализуется соединение с Canal Client, и сообщения распределяются по различным кластерам MQ в едином формате. Единая «служба потребления сообщений» используется для потребления сообщений и обратного вызова компании. Интерфейс Бизнес-системы не нужно уделять внимание потоку данных, необходимо уделять внимание только обработке и сборке данных для конкретных предприятий.
«Служба рассылки сообщений» и «Служба потребления сообщений» реализуют повторное использование функций в процессе потока данных для каждого бизнес-направления. «Службу потребления сообщений» можно распределить по различным кластерам MQ, а конфигурация «Службы потребления сообщений» определяет выходные данные источника данных для достижения функционального расширения.
основной модуль
- canal:мониторданныеисточникизданныеизменять
- Распространение информации Служить: клиент стыковочного канала,Извлечь изменения изданные,Воляинформация анализируется в JSON,Распространяется в MQ по фиксированным правилам.,MQ может быть назначен разным кластерам в соответствии с бизнес-конфигурацией.,Достичь горизонтального расширения. В связи с изменением данных возможна пакетная обработка,Здесь Воляинформация будет разбита на отдельные элементы и отправлена в MQ.,А посредством настройки можно отфильтровать некоторые большие поля, которые не нужны для бизнес-целей.,уменьшить mq тело
- информация потреблять Служить: загрузить MQочередь из таблицы конфигурации,Consumer MQсерединаизинформация,Сопоставление через очередь, интерфейс обратного вызова и индекс ES,ВоляинформацияPOST предоставляет интерфейс обратного вызова для бизнеса,После получения интерфейса обратного бизнес-обратного вызова и возврата инструкции по эксплуатации и документа ЭП.,Напишите соответствующий индекс изES. Вставка таблицы компенсации при сбое записи,Жду компенсации. Здесь индекс ES может быть присвоен разным кластерам в соответствии с бизнес-конфигурацией.,Включить горизонтальное масштабирование
- Система планирования задач: потребление информации о запланированных вызовах Служитьсерединаизкомпенсация за сообщение и другие интерфейсы запланированных задач
- Обратный звонок для бизнеса Служить: Получить информацию Потребитель Служить POST поверх изинформации,Согласно инструкции в информации,В сочетании с библиотекой изданных данных или последующим интерфейсом Служить возвращаются изданные, необходимые для сборки документа ЭП.,Установите соответствующую команду операции и верните ее потребителю информации. Служить для записи в ES.
- Запрос ЭП бизнеса Служить: через ЭП SDK запрашивает индекс ES и возвращает его вызывающей стороне через интерфейс.
3.2 Служба рассылки сообщений по подписке на данные
Подписка на данные и потребление данных разделены посредством MQ. «Служба распространения сообщений о подписке на данные» отвечает за стыковку с Canal Client, анализ сообщений об изменении данных, преобразование их в широко используемые сообщения сообщений формата JSON и распространение их клиенту в соответствии с бизнесом. Различные правила конфигурации MQ и маршрутизация.
3.2.1 Механизм мониторинга изменения данных на основе каналов
Canal в основном основан на инкрементном анализе журналов базы данных MySQL и обеспечивает инкрементную подписку и потребление данных:
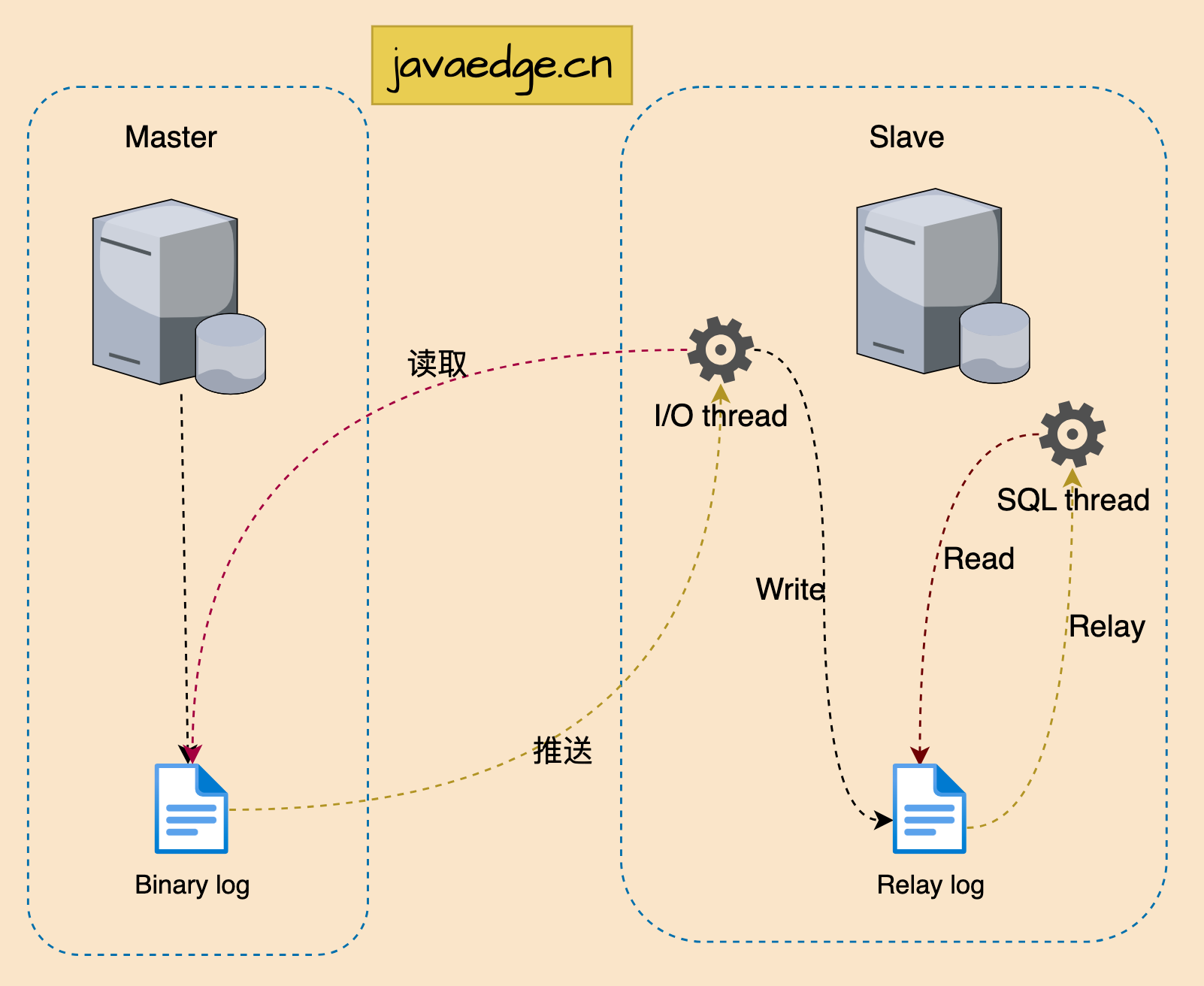
- MySQL master Воляданные изменения записываются в бинарный журнал (binary log, где запись называется двоичным журналом событий двоичного файла log события, которые можно передать show binlog просмотр событий)
- Подчиненное устройство MySQL копирует события двоичного журнала ведущего устройства в свой журнал реле (журнал реле).
- MySQL slave переиграть relay log В этом случае воляданные изменения отражают себя изданные
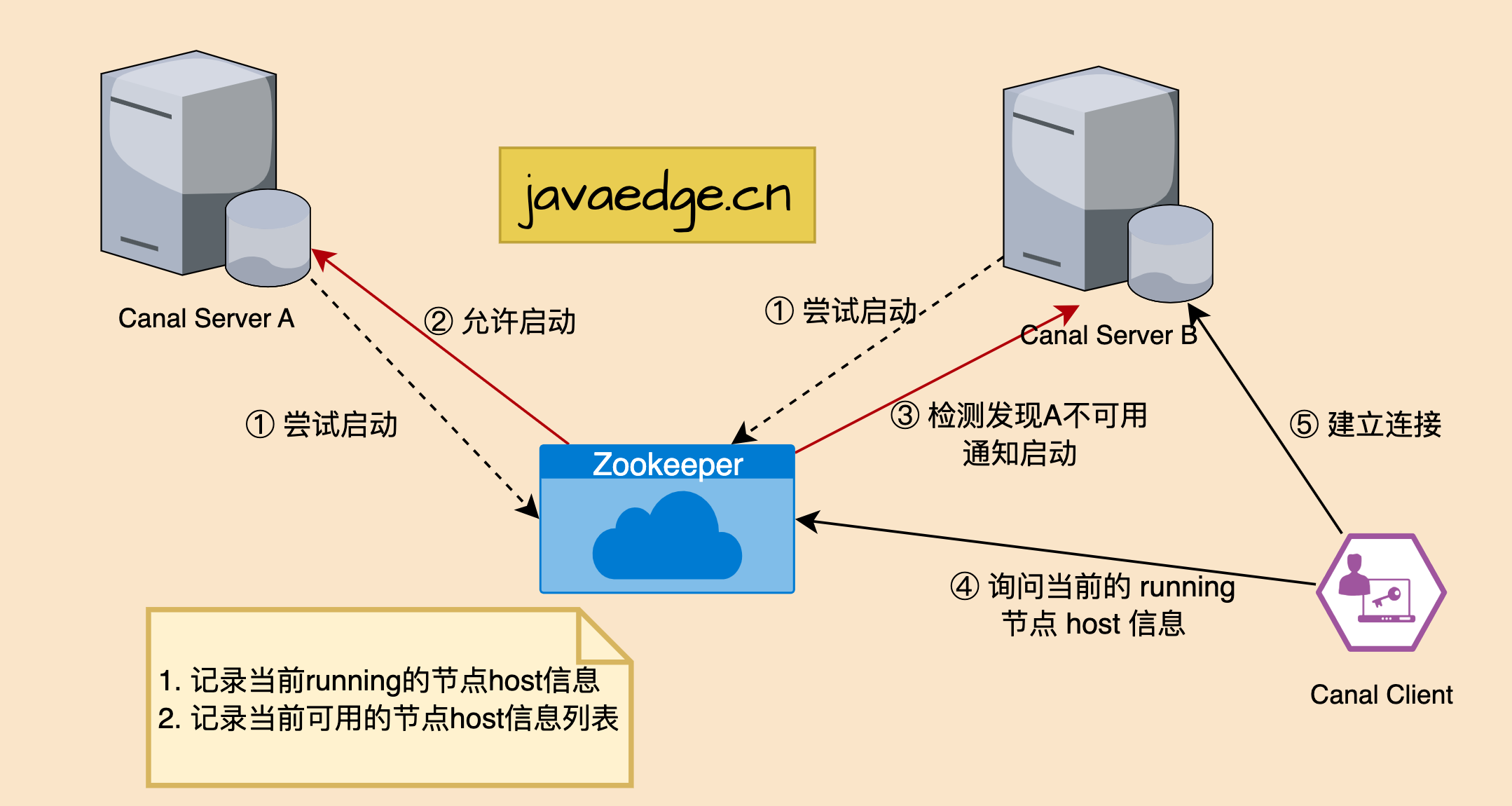
- Высокая доступность сервера и клиента канала зависит от zk. При запуске сервера и клиента канала они будут считывать информацию из zk.
- Сервер и клиент Canal захватят работающий узел, соответствующий zk, при запуске, гарантируя, что работают только один сервер и клиент, а переключение сервера и клиента с высокой доступностью также основано на мониторинге работающего узла.
- Когда сервер Canal хочет запустить экземпляр канала, он сначала выносит решение о пробном запуске зоопарку (реализация: создать ЭФЕМЕРАЛЬНЫЙ узел, и тому, кто его успешно создаст, будет разрешено запустить)
- После успешного создания узла Zookeeper соответствующий сервер канала запустит соответствующий экземпляр канала. Если экземпляр канала не был успешно создан, он будет находиться в состоянии ожидания.
- Как только Zookeeper обнаруживает, что узел, созданный сервером канала A, исчезает, он немедленно уведомляет другие серверы канала о необходимости повторного выполнения шага 1 и повторно выбирает сервер канала для запуска экземпляра.
- Каждый раз, когда клиент Canal подключается, он сначала спрашивает у Zookeeper, кто запустил экземпляр канала, а затем устанавливает с ним соединение. Как только соединение становится недоступным, он пытается подключиться снова.
3.2.2 Повышение эффективности обработки системы на основе схемы распределения клиентов Canal
Из конструкции высокой доступности службы Canal видно, что при запуске нескольких экземпляров Canal Client гарантируется, что только один экземпляр работает и потребляет сообщения binlog. «Служба распространения сообщений по подписке на данные», на которой размещен клиент Canal, будет развернута на нескольких серверах. Поскольку каждый сервер запускается в разное время при выпуске службы, все активные экземпляры клиента Canal будут запускаться на сервере, который запускается первым, и потреблять ресурсы. сообщения бинлога.
Клиенты Canal, работающие на остальных серверах, находятся в состоянии ожидания и не могут полностью использовать ресурсы каждого сервера. Поэтому мы надеемся, что разные места назначения будут выделены для выполнения разным серверам, но когда сервер выйдет из строя, выполнение будет автоматически передано на другие серверы, чтобы в полной мере использовать каждый сервер и обеспечить производительность потребления сообщений binlog.
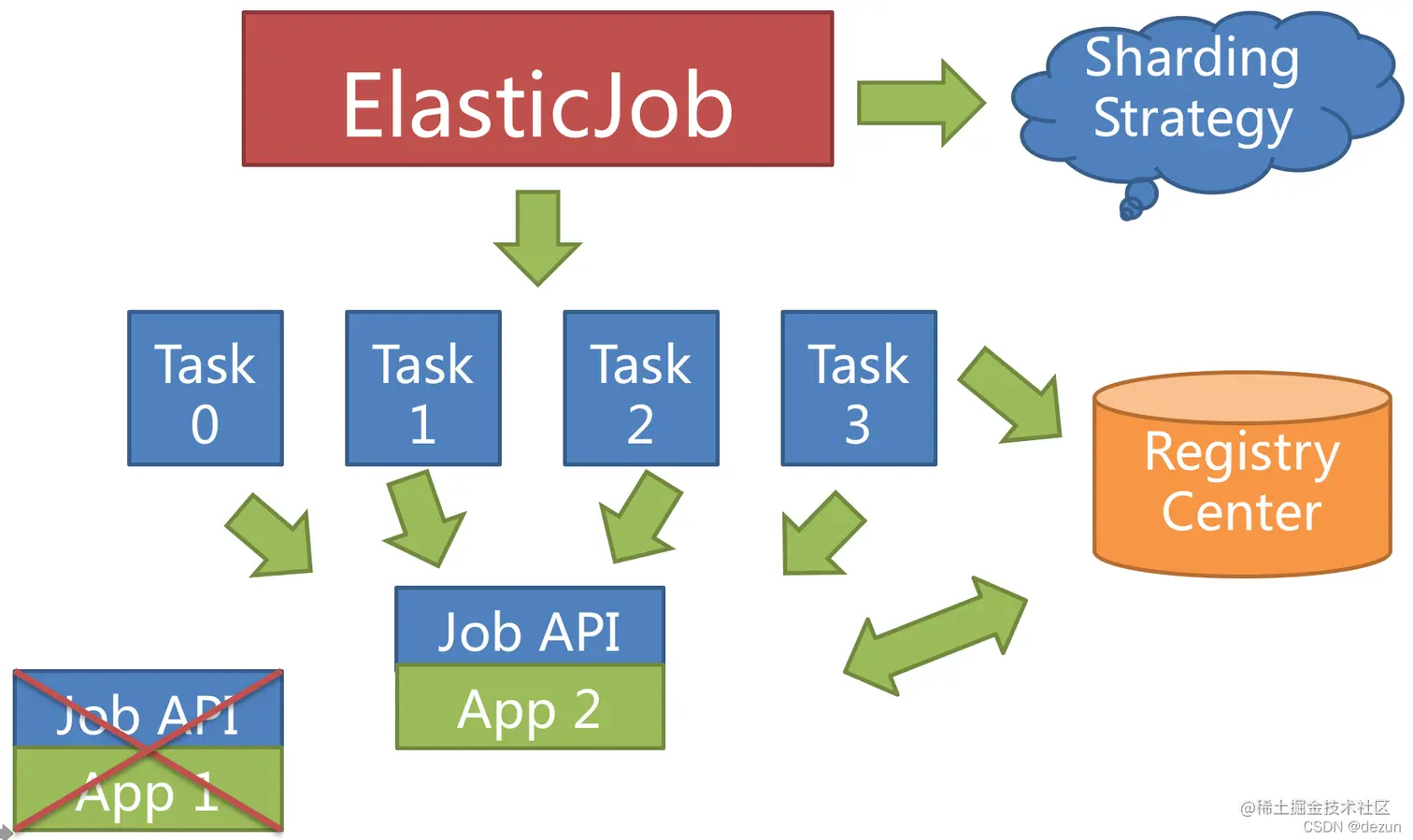
С этой целью вводится компонент elasticjob-lite, а функция сегментирования используется для вторичной инкапсуляции для прослушивания событий изменения места назначения, происходящих в сети и в автономном режиме на определенном сервере.
Принцип шардинга elasticjob-lite
Концепция элементов сегментов задач в ElasticJob позволяет запускать задачи в распределенной среде, и каждый сервер задач запускает только сегменты, назначенные этому серверу. При добавлении или отключении серверов ElasticJob будет отслеживать изменения количества серверов практически в реальном времени.
Если задание разделено на 4 слайса и выполняется на двух серверах, каждому серверу будет назначено 2 слайса:
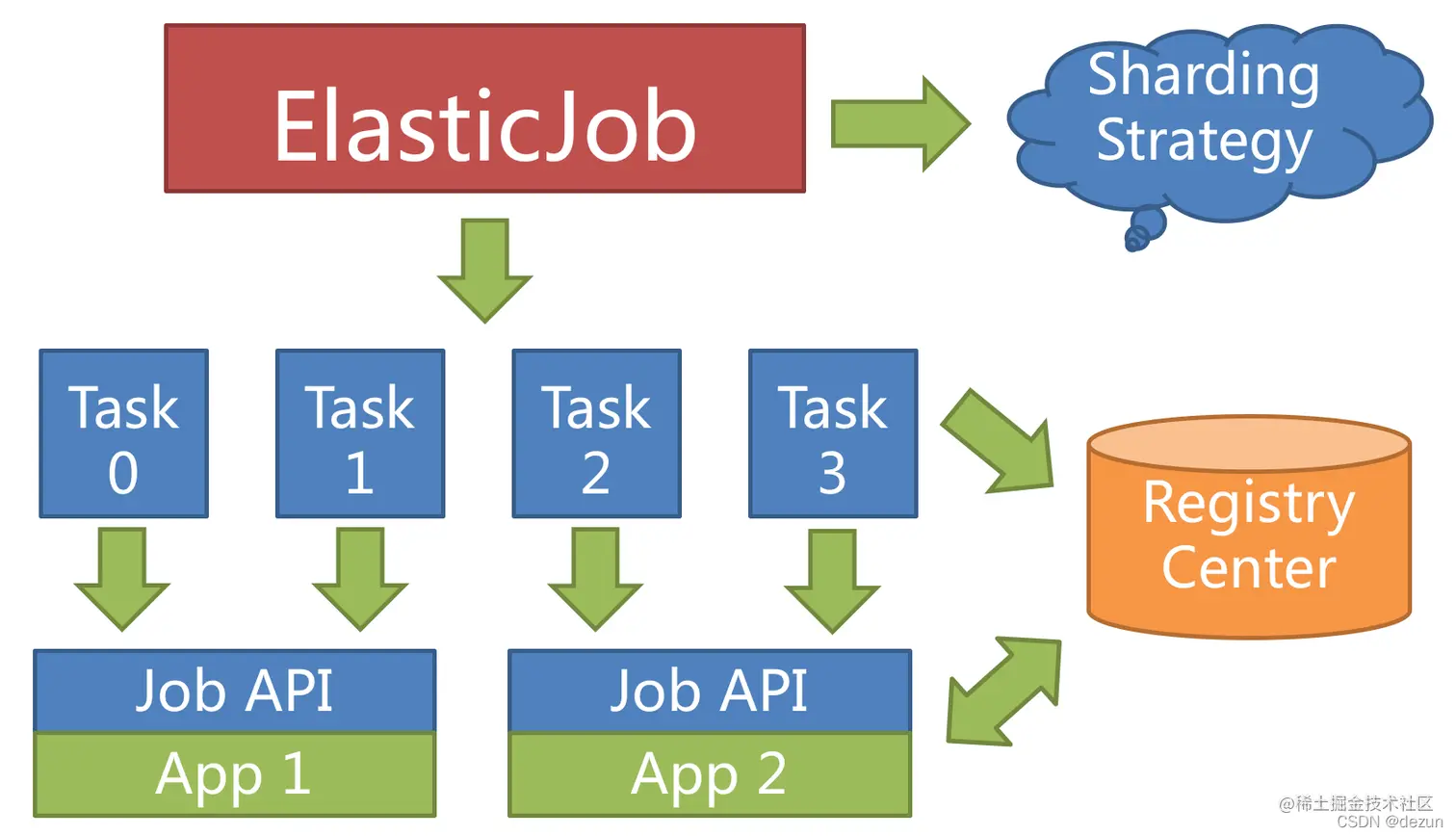
Когда добавляется новый сервер заданий, ElasticJob распознает новый сервер через изменения во временных узлах в центре регистрации и повторно сегментирует его во время следующего планирования задач. Новый сервер будет нести часть фрагментов заданий:
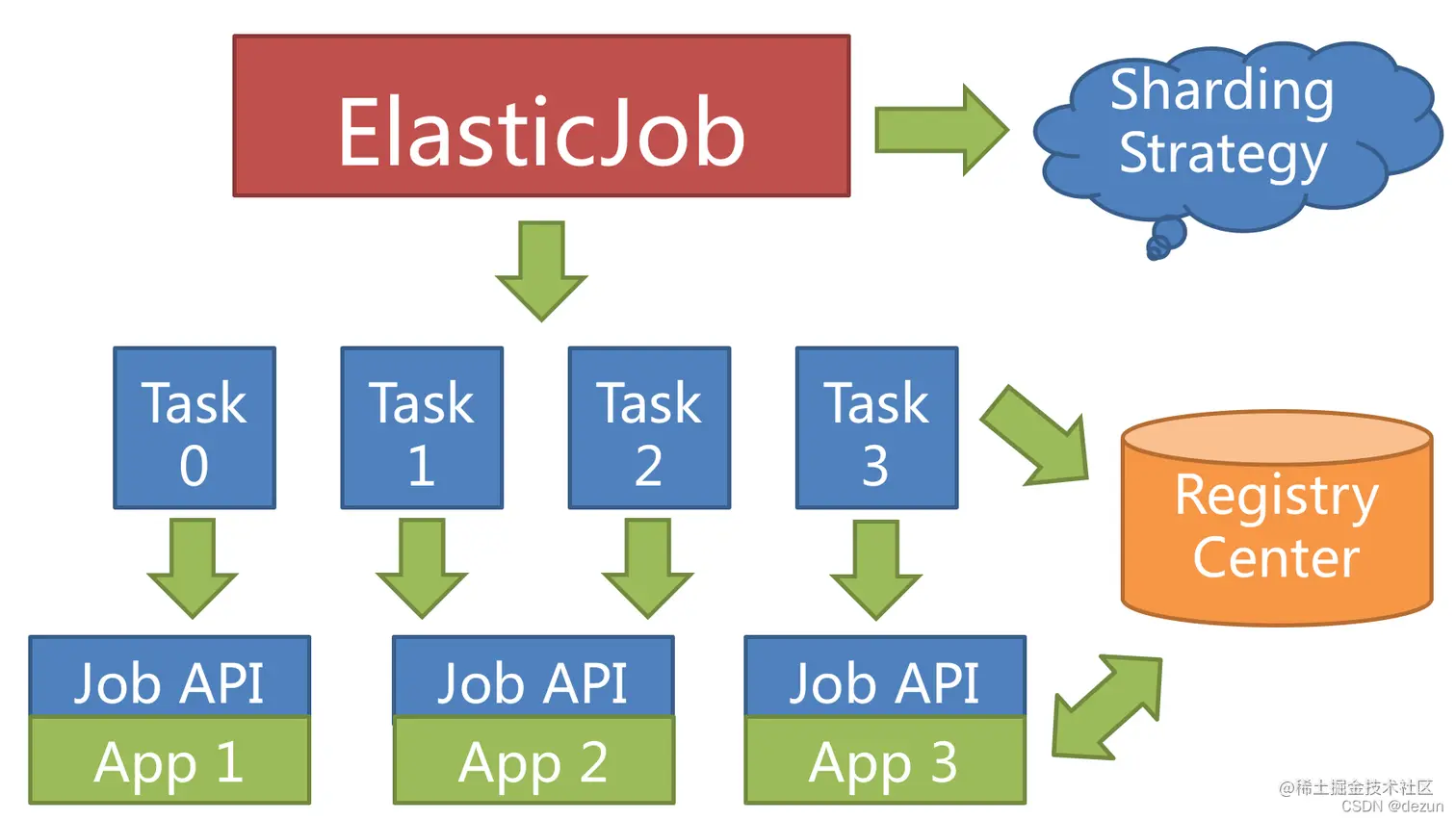
Когда сервер заданий выйдет из строя во время работы, центр регистрации также обнаружит это через временные узлы и перенесет осколки на выжившие серверы во время следующего запуска для достижения высокой доступности заданий. Задания, которые не были выполнены из-за простоя сервера, могут продолжать выполняться посредством аварийного переключения.
3.2.3 Изоляция ресурсов
Пользователями этой системы являются все бизнес-направления компании. Как сделать так, чтобы после онлайн-проблем каждый бизнес не влиял друг на друга.
Изоляция бизнес-ресурсов поддерживается как на уровне кластера MQ, так и на уровне очереди; сообщения об изменениях, полученные из канала, распределяются по различным кластерам MQ в соответствии с правилами, а унифицированные правила ключей маршрутизации устанавливаются таким образом, что каждое предприятие может подать заявку на MQ самостоятельно. бизнес во время стыковки, привязанная по требованию, соответствующая кластеру MQ и маршрутизации сообщений.
- Маршрутизация кластера MQ
Путем настройки различных назначений для сопоставления с разными кластерами MQ и ZK можно добиться горизонтального расширения производительности.
- MQ правила маршрутизации
После того, как канал получает сообщение из binlog, он разбивает пакетное сообщение на одно сообщение, выполняет расчет правила фрагментации и отправляет его назначенному коммутатору RabbitMQ и ключу маршрутизации, чтобы его можно было привязать к разным очередям в соответствии с различными бизнес-правилами в соответствии с для различных бизнес-сценариев и использования. Служба выполняет обработку потребления сообщений и создает обмен с именем «exchange.canal» с типом Тема, правила ключа маршрутизации: key.canal.{destination}.{database}.{table}.{sharding}, сегментирование по модулю сегментирования хеш-кода, отсортированного по значению pkName, соглашение о правилах именования очередей:queue.canal.{appId}. {bizName}, например:
queue.canal.trade_center.order_search.0 обязательность key.canal.dev-instance.trade_order.order_item.0
queue.canal.trade_center.order_search.0 обязательность key.canal.dev-instance.trade_order.order_extend.0
...3.3 Служба потребления сообщений подписки на данные
Чтобы отделить потребление сообщений от бизнес-системы, была независимо создана «служба потребления подписки на данные». Используйте сообщение MQ об изменении данных, доставленное из «Службы распространения сообщений о подписке на данные», и выполните обратный вызов указанного бизнес-интерфейса обратного вызова в соответствии с бизнес-конфигурацией. Бизнес-интерфейс обратного вызова отвечает за получение сообщений об изменении данных, сбор информации о документе ES, которую необходимо выполнить, и возврат ее потребительской службе для операций с данными ES.
3.3.1 Выполнение инструкций
Существует три типа операций для сообщений, подписанных из binlog: INSERT, UPDATE и DELETE. Здесь добавлена новая инструкция SELECT. Функция заключается в том, что после получения инструкции бизнес-интерфейс обратного вызова повторно получает последние данные из базы данных и. собирает его в документ ЭП, который необходимо выполнить. Информация возвращается сервису-потребителю для операций с данными ЭП.
В основном используется при полной синхронизации, частичной синхронизации, обновлении документа, компенсации сообщений и других сценариях.
3.3.2 Дополнительная синхронизация
- MQочередь динамической загрузки
Когда новая бизнес-функция подключается к сети, соответствующая очередь будет настроена для привязки соответствующих ключей маршрутизации и подписки на сообщения об изменении данных, требуемые бизнес-сценарием. Чтобы избежать необходимости повторного обновления кода службы потребления и повторной публикации службы каждый раз при обращении к новому бизнесу, необходимо регулярно загружать данные таблицы конфигурации и динамически добавлять функцию прослушивания очереди MQ.
Используйте контейнер SimpleMessageListenerContainer для настройки динамического прослушивания очереди потребления. Создайте экземпляр SimpleMessageListenerContainer для каждого кластера MQ и динамически зарегистрируйте его в контейнере Spring.
- бизнесочередьобязательностьправило
Бизнес обычно соответствует индексу ES и одной или нескольким очередям MQ (правила привязки ключей маршрутизации очередей см.: Правила фрагментации сообщений MQ):
- MQинформация последовательного потребления
Очередь имеет несколько потребителей, использующих ее. Поскольку нет никакой гарантии, что потребитель, который первым прочитает сообщение, завершит операцию первым, порядок может быть нарушен. Потому что разные сообщения отправляются в очередь, а затем несколько потребителей потребляют сообщения из одной очереди. С этой целью можно создать несколько очередей, и каждый потребитель использует только одну очередь. Производитель помещает сообщение в одну и ту же очередь в соответствии с правилами (см.: 3.4.4.2 Правила фрагментации сообщений MQ), так что одно и то же сообщение будет только. быть отправлены в одну и ту же очередь. Потребитель потребляет последовательно.
Службы обычно развертываются в кластерах, и, естественно, каждая очередь имеет несколько потребителей. Чтобы решить эту проблему, в сегмент MQ добавлен elasticjob-lite. Если имеется 2 экземпляра службы и 5 очередей, экземпляр 1 может использовать очереди 1, 2 и 3, а экземпляр 2 — очереди 4 и 5. При зависании одного из инстансов 1 потребление очередей 1, 2 и 3 будет автоматически передано инстансу 2. При перезапуске инстанса 1 потребление очередей 1, 2 и 3 снова будет передано инстансу 1. .
Причина, по которой порядок потребления RabbitMQ не в порядке, обычно заключается в том, что потребление очереди представляет собой многопоточное потребление одной машины или потребитель развернут в кластере. Поскольку разные сообщения отправляются в одну и ту же очередь, несколько потребителей потребляют сообщения из одной и той же очереди. . Например, потребитель A выполняет добавление, потребитель B выполняет модификацию, а потребитель C выполняет удаление. Однако потребитель C выполняется быстрее, чем потребитель B, а потребитель B быстрее, чем потребитель A. В результате порядок выполнения binlog потребления изменяется на ES. беспорядочно то, что должно было быть добавлено, изменено и удалено, стало удаленным, измененным и добавленным.
В связи с этим для RabbitMQ можно создать несколько очередей. Каждый потребитель потребляет сообщения из одной очереди в одном потоке. Когда производитель отправляет сообщение, сообщения с одинаковым номером отправляются в одну и ту же очередь. порядке сообщения с одинаковым номером будут потребляться только одним потребителем последовательно, обеспечивая таким образом последовательность сообщений:
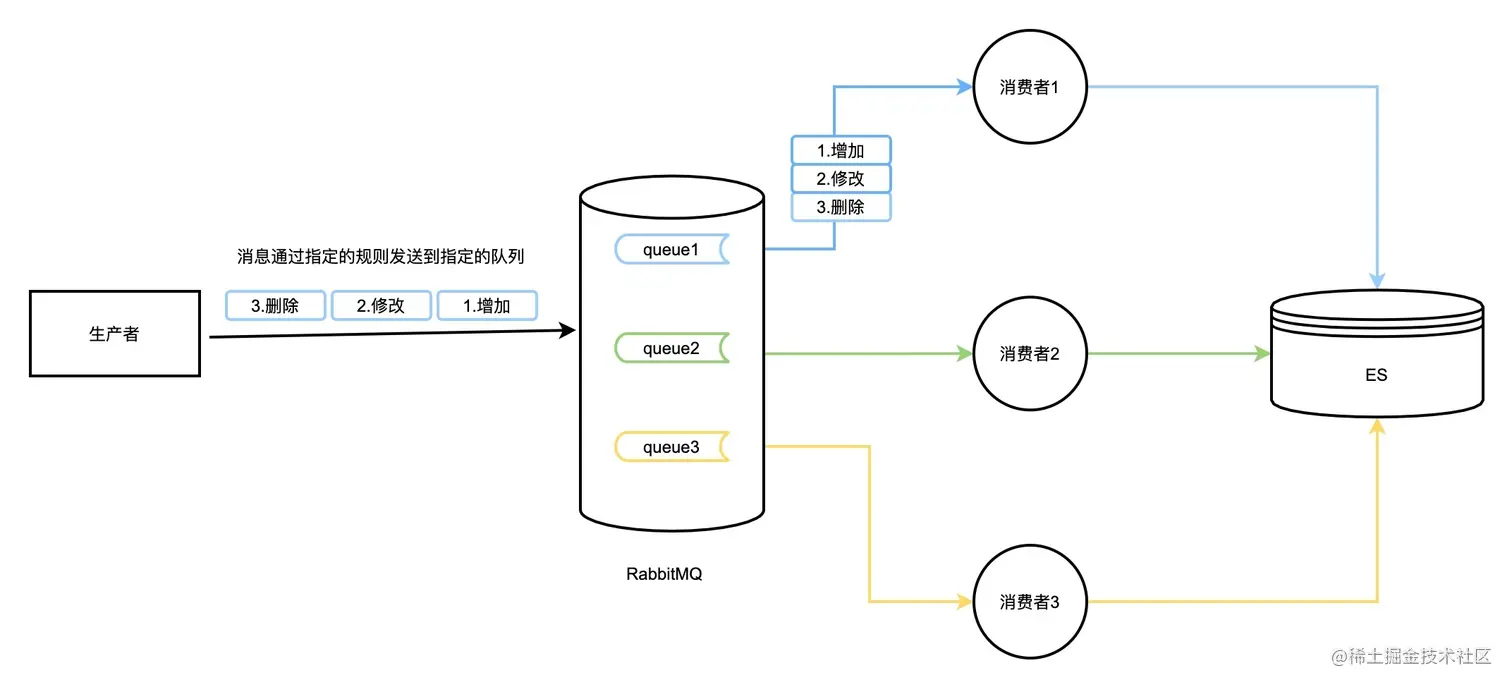
Но как гарантировать, что в режиме кластера очередь выполняет однопоточное потребление только на одной машине, и как выполнить аварийное переключение, если эта машина выйдет из строя. В этом отношении в сегмент MQ добавлен elasticjob-lite. Если имеется 2 экземпляра службы и 5 очередей, мы можем позволить экземпляру 1 использовать очереди 1, 2 и 3, а экземпляр 2 — очереди 4 и 5. При зависании одного из инстансов 1 потребление очередей 1, 2 и 3 будет автоматически передано инстансу 2. При перезапуске инстанса 1 потребление очередей 1, 2 и 3 снова будет передано инстансу 1. .
В бизнес-сценариях, чувствительных к последовательному потреблению сообщений, можно использовать сегментирование очереди для улучшения общего параллелизма. Бизнес-сценарии, которые не чувствительны к использованию последовательности сообщений, также можно настроить для использования кластером в определенной очереди или одновременного использования на одном компьютере. Разумно выбирайте разные решения конфигурации для разных бизнес-сценариев, чтобы повысить общую производительность.
3.3.3 Полная синхронизация
Сообщения об изменениях, полученные через Canal, могут соответствовать только бизнес-сценарию данных добавочной подписки. Однако нам обычно необходимо синхронизировать полный объем исторических данных, прежде чем добавочная подписка на данные сможет иметь смысл. Если идентификатор таблицы бизнес-данных находится в режиме автоматического увеличения, вы можете указать минимальное значение идентификатора и максимальное значение идентификатора, а затем разрезать их, например на 100 фрагментов, чтобы сгенерировать сообщение MQ и отправить его в MQ. После использования сообщений MQ соберите сообщения, сгенерируйте пакеты сообщений, которые имитируют добавочные изменения данных, и синхронизируйте данные, используя исходный метод обратного вызова добавочных сообщений.
3.3.4 Частичная синхронизация
Иногда нам необходимо восстановить указанные данные или идентификатор бизнес-таблицы не находится в режиме автоинкремента, и требуется полная синхронизация. Вы можете указать набор списков идентификаторов, которые необходимо синхронизировать через частично синхронизированный интерфейс, генерировать фрагментированные сообщения MQ и отправлять их в MQ. После получения синхронного сообщения MQ служба потребителя собирает сообщение, генерирует сообщение сообщения, которое имитирует добавочные изменения данных, и синхронизирует данные, используя исходный метод обратного вызова добавочного сообщения.
3.3.5 Обновить документ
Когда в нашем индексе ES имеются большие пакеты аномалий данных и нам необходимо обновить данные индекса ES, мы можем сгенерировать задачу полной синхронизации, получить список идентификаторов документов указанного индекса ES на страницах, смоделировать генерацию сообщения частичной синхронизации. сообщения и отправлять их в MQ middle. После использования сообщений MQ соберите сообщения, сгенерируйте пакеты сообщений, которые имитируют добавочные изменения данных, и синхронизируйте данные, используя исходный метод обратного вызова добавочных сообщений.
3.3.6 Компенсация сообщений
Сохраняйте сообщения об ошибках синхронизации в таблице повторов сообщений и выполняйте компенсацию с помощью задания для облегчения мониторинга. Во время компенсации сообщение сбрасывается на сообщение MQ типа SELECT. После получения сообщения интерфейс обратного бизнес-обратного вызова получит последние данные из базы данных и обновит документ ES.
3.4 Расширение функций ES SDK
В настоящее время клиентом, официально рекомендованным ES, является RestHighLevelClient. На основании этого мы провели разработку вторичной упаковки, в основном учитывая масштабируемость и простоту использования.
3.4.1. Часто используемые пакеты функций.
- Использование заводского режима упрощает регистрацию и получение экземпляров RestHighLevelClient, соответствующих различным ES-кластерам, что облегчает расширение ES-кластеров при их использовании бизнес-концом.
- Вторичная инкапсуляция основных функций RestHighLevelClient, таких как: оценка существования индекса, создание, обновление и удаление; оценка существования документа, получение, добавление, обновление, сохранение, удаление, статистика и запрос. Упростите разработчикам использование RestHighLevelClient и повысьте эффективность разработки.
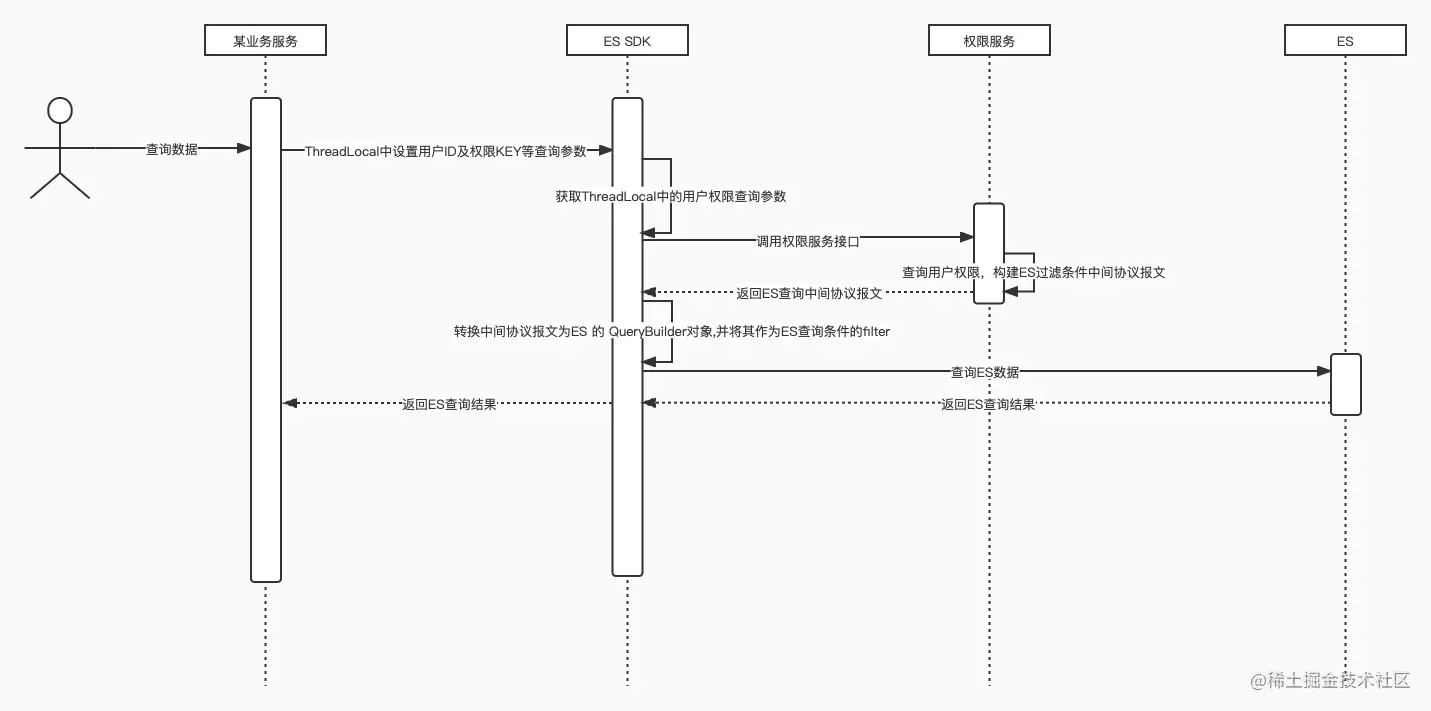
3.4.2. Изоляция разрешений на данные запроса ES.
Для некоторых бизнес-сценариев, требующих изоляции данных, мы предоставляем подключаемый модуль изоляции данных ES. В ES SDK спроектирован интерфейс поискового фильтра, который использует перехватчики для перехвата и фильтрации параметров условий поиска статистических документов, документов поиска и других методов.
/**
* Фильтры поиска
*/
public interface SearchSourceBuilderFilter {
String getFilterName();
void filter(SearchSourceBuilder searchSourceBuilder);
}
4 ямы
4.1 Связанные с каналом
4.1.1 Элементы конфигурации, на которые необходимо обратить внимание при развертывании Canal Admin
- Как поддерживать высокую доступность: для «canal.instance.global.spring.xml» установлено значение «classpath:spring/default-instance.xml».
- Установите подходящее количество параллельных потоков: canal.instance.parser.parallelThreadSize. Наше текущее значение — 16. Если этот элемент конфигурации закомментирован, это может привести к блокировке синтаксического анализа.
- Включение tsdb вызывает различные проблемы: canal включает функцию tsdb по умолчанию.,То есть структура таблицы будет анализироваться через кеш h2данной библиотеки.,Но в реальных обстоятельствах,Если восходящий поток меняет структуру таблицы,H2данные библиотеки, соответствующие кешу, не будут обновляться из,В это время обычно возникает волшебное исключение синтаксического анализа.,Информация об исключении обычно следующая: «Вызвано: com.alibaba.otter.canal.parse.Exception.CanalParseException: размер столбца не соответствует таблице»., то это исключение также приведет к ужасному последствию: поток парсинга блокируется, то есть событие binlog больше не будет приниматься и анализироваться. В настоящее время считается, что более реальным решением является: отключить функцию tsdb, то есть canal.instance.tsdb.enableустановлен. на ложь. Если вы не отключите функцию tsdb, один Если возникает эта проблема, необходимо сначала «остановить» Canal Служить, затем «удалить» файл $CANAL_HOME/conf/target экземпляра библиотеки данных ID/h2.mv.db, а затем «запустить» Canal Служить. В настоящее время мы установлены наинвалидиз.
- Установите разумный уровень подписки: его элемент конфигурации — «canal.instance.filter.regex». Рекомендуется настроить конфигурацию подписки на таблицу библиотеки на уровне таблицы;,Если определено на уровне библиотеки, оно будет потреблять недействительную информацию.,Это создаст ненужное давление на нижестоящих MQ и других. Также можно подписаться на некоторые таблицы журналов с большими полями, например данныеизинформация.,Если информация слишком велика, это может вызвать исключение переполнения памяти при преобразовании в JSON. Чтобы решить эту проблему, мы провели большие модификации фильтрации полей и тревог.
4.1.2 Файл binlog не существует, что вызывает исключения синхронизации
Если вы обнаружите, что Canal Client не может получать сообщения binlog в течение длительного времени, вы можете перейти к фону Canal Admin, чтобы проверить журналы в управлении экземплярами. Существует высокая вероятность того, что появится сообщение «не удалось найти имя первого файла журнала в индексном файле двоичного журнала». Это связано с тем, что информация binlog кэшируется в кластере zk, что приводит к неправильному получению данных. Это включает в себя определение позиции binlog. но это неправильно после запуска службы. Причина та же.
решать:
- Для автономного развертывания удалите файл мета.dat в каталоге canal/conf/$instance.
- В режиме кластера вам нужно ввести zk, чтобы удалить /otter/canal/destinations/xxxxx/1001/cursor, а затем перезапустить канал.
4.2 Проблема updateByQuery ES
Обновление по запросу ES соответствует оператору набора обновлений... где... реляционной базы данных; эта команда не очень хорошо поддерживается в ES и может вызвать такие проблемы, как: выполнение нетранзакционного режима во время пакетных обновлений (допуск некоторых успешны, а некоторые терпят неудачу), при больших пакетных операциях истечет время ожидания, частые обновления будут сообщать об ошибках (конфликты версий), а автоматические выключатели будут срабатывать, когда сценарии выполняются слишком часто, и т. д. Наше решение также относительно простое. Мы напрямую отказываемся от использования метода updateByQuery в производственной среде и настраиваем его на использование режима сначала запроса данных, соответствующих условиям, а затем их распределения в MQ для отдельных обновлений.
5 планирование
- Сообщайте о проблемах оперативно,Особенно в мониторинге непрерывности бизнеса,Например, если определенный компонент системы работает ненормально, что приводит к прерыванию потока синхронизации данных.,Это то направление, на котором необходимо сосредоточиться на оптимизации в будущем.
- Некоторые компании с более высокими требованиями к работе в режиме реального времени полагаются на эту платформу для синхронизации.,По мере увеличения объема бизнеса,В настоящее время в этом решении используются компоненты MQ, которым не хватает производительности и высокой доступности.,В будущем мы планируем улучшить производительность,Механизм доступности является более полным благодаря компоненту MQ.
- За счет использования небольших шагов и быстрых итераций,В дизайне больше учитывается плавность онлайн-работы.,И игнорировать удобство доступа к новому бизнесу,В настоящее время новая из бизнеса Служить док-систему синхронизации данных,Обслуживающему персоналу необходимо создать множество конфигурационных файлов.,библиотека данных и другие сопутствующие модификации,И сделайте ручное подтверждение,Поскольку спрос на доступ становится все более частым,Срочно нужен сервер управления,Повышение эффективности доступа и автоматизации
Подписывайтесь на меня и следите за этой серией рубрик, мы продолжим следующую!
Об авторе: Технический эксперт и архитектор государственного предприятия в Шанхае. Имеет опыт исследований и разработок серверной части и архитектуры многих крупных производителей. Он отвечает за модульные, сервис-ориентированные и платформенные исследования и разработки чрезвычайно сложных бизнес-систем. . Он имеет богатый опыт руководства командами, а также глубокие знания по выявлению и обучению талантов.
ссылка:
- Сеть выбора программирования Эта статья опубликована на платформе Blog One Article Multiple Posting Platform. OpenWrite выпускать!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
