Как использовать граф знаний и Llama-Index для реализации RAG?
Галлюцинации — распространенная проблема при работе с большими языковыми моделями (LLM). LLM способен создавать гладкий и связный текст, но часто выдает неточную или противоречивую информацию. Один из способов избежать галлюцинаций в LLM — использовать внешние источники знаний, такие как базы данных или графики знаний, для предоставления фактической информации.
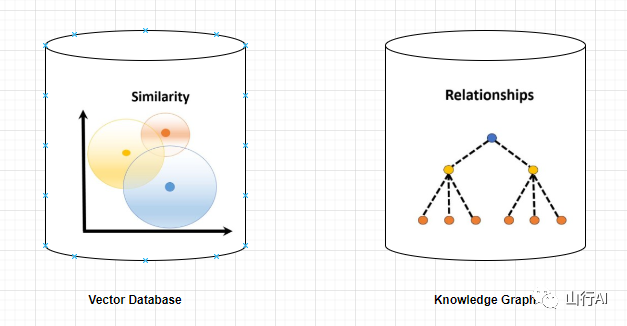
Что такое векторная база данных?
База данных векторов — это набор многомерных векторов, которые представляют объекты или понятия, такие как слова, фразы или документы. На основе векторного представления векторные базы данных можно использовать для измерения сходства или корреляции между различными объектами или концепциями.
Например, база данных векторов может сказать вам, что «Париж» и «Франция» более тесно связаны друг с другом, чем «Париж» и «Германия», благодаря своим векторным расстояниям.
Что такое граф знаний?
Граф знаний — это совокупность узлов и ребер, которые представляют сущности или понятия, а также связи между ними (например, факты, атрибуты или категории).
Графы знаний можно использовать для запроса или вывода фактической информации о различных объектах или концепциях на основе атрибутов узлов и ребер.
Например, граф знаний может сказать вам, что «Париж» — столица «Франции», основываясь на метках на краях. Запрос к базе данных графов включает в себя просмотр структуры графа и извлечение узлов, связей или шаблонов на основе определенных критериев. Вот простой пример, показывающий, как выполнить запрос к графовой базе данных:
Предположим, у вас есть графовая база данных, представляющая социальную сеть, где пользователи являются узлами, а их отношения (например, дружба) представлены ребрами, соединяющими узлы. Вы хотите найти друзей друзей данного пользователя (взаимные контакты).
1. Начните с эталонного пользователя: определите узел в графовой базе данных, который представляет эталонного пользователя. Этого можно добиться, запросив конкретный идентификатор пользователя или другие соответствующие критерии. 2. Обходим граф:
Перейдите по графу, начиная с эталонного пользовательского узла, используя язык запросов графа, такой как Cypher или Gremlin, используемый в Neo4j. Напишите запрос, указывающий шаблон или взаимосвязь, которую вы хотите изучить. В этом случае вы хотите найти друзей друзей. Например, запрос Cypher:
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User)
RETURN fofЭтот запрос начинается со ссылки на пользователя, за ним следует отношение ДРУГ к другому узлу (друг), а затем следует другое отношение ДРУГ, чтобы найти друзей друзей (fof).
3. Результаты поиска:
Выполните запрос к базе данных графов и получите результирующие узлы (друзья друзей) на основе шаблона запроса. При необходимости вы можете получить конкретные свойства или другую информацию о полученном узле.
4. Представление результатов. Отображение полученных данных о друзьях друзей пользователю или дальнейшая обработка данных по мере необходимости. Эта информация может быть использована для рекомендаций, веб-анализа или других подобных целей.
Базы данных графов предоставляют более расширенные возможности запросов, включая фильтрацию, агрегирование и сопоставление сложных шаблонов. Конкретный язык и синтаксис запросов могут различаться, но общий процесс включает в себя обход структуры графа для извлечения узлов и связей, соответствующих требуемым критериям. Запрос к базе данных векторов обычно включает поиск похожих векторов или извлечение векторов на основе определенных критериев. Вот простой пример, показывающий, как выполнить запрос к базе данных векторов:
Предположим, у вас есть векторная база данных, содержащая профили клиентов, представленные в виде многомерных векторов, и вы хотите найти других клиентов, похожих на данного эталонного клиента.
1. Определим эталонный вектор клиентов:
Сначала определите векторное представление эталонного клиента. Это можно сделать путем извлечения соответствующих объектов или атрибутов и преобразования их в векторный формат.
2. Выполните поиск по сходству:
Выполните поиск по сходству в базе данных векторов, используя соответствующий алгоритм, такой как k-ближайший сосед (k-NN) или косинусное сходство. Алгоритм определит соседей, наиболее похожих на эталонный вектор клиентов, на основе показателя сходства.
3. Найдите похожих клиентов:
Получите профиль клиента, соответствующий вектору ближайшего соседа, определенному на предыдущем шаге. Эти профили будут представлять клиентов, похожих на эталонного клиента, на основе определенной меры сходства.
4. Представьте результаты. Наконец, предоставьте пользователю полученный профиль клиента или соответствующую информацию, например имя, демографическую информацию или историю покупок. Эта информация может использоваться для рекомендаций, целевых маркетинговых кампаний или для персонализации вашего опыта.
Основные компоненты графа знаний
Графы знаний обычно состоят из двух основных компонентов:
1. Вершины/узлы:
Представляет сущность или объект в области знаний. Каждый узел соответствует уникальному объекту и идентифицируется уникальным идентификатором. Например, в графе знаний о команде «Ченнаи Кингз» значениями узлов могут быть «Филадельфия Филлис» и «Высшая лига крикета» и т. д.
2. Сторона:
Представляет связь между двумя узлами. Например, ребро «Соревнование» может соединить узел «Ченнаи Кингз» с узлом «Высшая лига крикета».
Тройки в графах знаний
Триплеты — это основные единицы данных в графиках. Он состоит из трёх частей:
1.предмет: Узел, на который указывает тройка。2.объект: Узел, на который указывает отношение。3.предикат: Отношения между субъектом и объектом.
В приведенном ниже примере тройки «Ченнаи Кингз» является подлежащим, «соревноваться» — сказуемым, а «Высшая лига крикета» — объектом.
(Chennai Kings) — [compete in]->(Major League Cricket)Базы данных графов знаний могут эффективно хранить и запрашивать сложные графовые данные, сохраняя тройки.
Каковы преимущества графов знаний по сравнению с векторными базами данных с точки зрения иллюзии LLM?
•Графики знаний предоставляют более точную и конкретную информацию, чем векторные базы данных.。векторбаза данные указывают на сходство или родство между двумя объектами или концепциями, а График знания позволяют лучше понять взаимосвязь между ними. Например, График Знания могут сказать вам, что «Эйфелева башня» является достопримечательностью «Парижа», а векторная база данныхможет лишь указать, насколько схожи эти два понятия.。это может помочьLLMгенерировать более точные и Связанныйтекст。•Графы знаний поддерживают более разнообразные и сложные запросы, чем векторные базы данных.。векторбаза данные могут в основном отвечать на запросы, основанные на векторном расстоянии, сходстве или ближайшем соседе, которые ограничены прямыми мерами сходства. Напротив, График знаний может обрабатывать запросы, основанные на логических операторах.,Например“Иметь атрибутыZКаковы все сущности?”или“WиVКакие общие категории?”это может помочьLLMСоздание обновлений Разнообразныйизменятьиинтересныйтекст。•Графы знаний позволяют делать больше рассуждений и выводов, чем векторные базы данных.。векторбаза данныхмогу только предоставитьхранилищесуществоватьбаза Прямые сообщения в данных. Напротив, График Знания могут предоставить косвенную информацию, полученную из отношений между сущностями или концепциями. Например, График знания могут сделать вывод, что «Эйфелева башня расположена в Европе», основываясь на фактах «Париж — столица Франции» и «Франция расположена в Европе». Это может помочь LLM генерировать более логичный и последовательный текст. Короче говоря, с векторной базой данныхпо сравнению с,График знания — лучшее решение проблемы галлюцинаций в LLM. График Знания предоставляют LLM более точную, актуальную, разнообразную, интересную, логичную и последовательную информацию. Использовать график Знания могут уменьшить галлюцинации в LLM, что делает его более надежным в создании точных и основанных на фактах текстов. Но главное – в документе должна быть четко отражена взаимосвязь, иначе График знания не смогут его поймать.
Разница между векторизованной базой данных и графом знаний
Различные способы хранения и представления данных
1. Векторизованная база данных и граф знаний используют два разных метода хранения и представления данных. 2. Методы векторизации баз данных используют числовые векторы для представления данных и в основном используются для поиска по сходству.
•Каждый объект представлен в виде многомерного вектора, а сходство между объектами рассчитывается на основе векторного расстояния. • Векторизованные базы данных хорошо подходят для операций, основанных на сходстве, но могут иметь трудности с представлением сложных отношений и семантических значений между объектами. Напротив, графы знаний призваны фиксировать и представлять отношения между объектами. • Граф знаний фиксирует сложные отношения и зависимости между объектами и обеспечивает возможности семантического анализа и рассуждения. • Графы знаний могут отвечать на сложные запросы с помощью логических операторов, а также выполнять расширенные рассуждения и поиск знаний.
3. Графовые базы данных в основном ориентированы на отношения «один к одному» между объектами, тогда как векторные базы данных фокусируются на сходстве векторов.
Хранение данных отличается
1. Графовая база данных
• Базы данных графов, в которых для представления связей используются узлы и ребра. • Базы данных графов идеально подходят для анализа связей между объектами и сложными сетями.
2. База данных векторов
•Векторные базы данных используют числовые массивы. •Векторные базы данных идеально подходят для поиска сходства и поиска наилучшего соответствия.
Как выбрать?
Вопрос о том, какой метод использовать, зависит от нескольких важных факторов, таких как характер данных и их взаимосвязей, требования к запросам и анализу, а также эффективность поиска сходства или исследования взаимосвязей. Оба подхода имеют свои преимущества и недостатки, и конкретный вариант использования определяет, какой подход является наиболее подходящим. Ключевые факторы сравнения:
• Структура данных: хранилище данных совершенно другое. Граф (база данных графов) используется для хранения узлов и ребер. Он очень хорошо отображает отношения и рассматривает отношения как первоклассных элементов. VectorDB хранит данные в виде числовых массивов. •Поиск и анализ данных: граф (база данных графов) используется для анализа связей между объектами, а векторные базы данных хороши для анализа закономерностей. • Запрос: Граф (база данных графов) запрашивает связи и сложные сети между объектами. А VectorDB (база данных векторов) очень хороша для поиска по сходству или поиска наилучшего соответствия. •Производительность. В зависимости от направленности запроса GraphDB/Knowledge Graph превосходно справляется с запросами, включающими связи, а VectorDB обеспечивает быстрый поиск по сходству.
При сравнении графовых баз данных с векторными базами данных следует учитывать несколько важных вопросов. Вот несколько ключевых вопросов для изучения:
• Какова природа данных и их взаимосвязей? •Являются ли данные в первую очередь структурированной или неструктурированной информацией? •Существуют ли сложные отношения и зависимости между объектами? • Каковы конкретные требования к запросам и анализу? •Нужен эффективный поиск сходства и рекомендации? • Требуются ли сложные обходы графов и исследование взаимосвязей? •Являются ли навыки семантического анализа и рассуждения критически важными? • Критична ли низкая задержка для приложений реального времени? • Существует ли несколько типов отношений и атрибутов, которые необходимо зафиксировать? •Какие языки запросов, API и интеграции экосистем доступны? Подводя итог, можно сказать, что векторные базы данных и графы знаний используют разные методы хранения и представления данных. В то время как векторные базы данных подходят для операций, основанных на сходстве, графы знаний предназначены для сбора и анализа сложных отношений и зависимостей. Выбор подходящего метода зависит от конкретных потребностей и целей вашего проекта.
Реализация кода
Используемый стек технологий
1.LlamaIndex: LlamaIndexэто структура оркестровки,Для упрощения интеграции частных данных с общедоступными данными,для создания приложений, использующих большие языковые модели (LLM). Он предоставляет инструменты приема, индексирования и запроса данных.,Делаем его универсальным решением для нужд генеративного искусственного интеллекта.。2.встроенная модель:встроенная Модель используется для преобразования текста в числовое представление для выражения предоставленной текстовой информации. Такое представление отражает семантическое значение встроенного контента, что делает его пригодным для многих отраслевых приложений. Здесь мы использовали "thenlper/gte-large" Модель.3.LLM:Большие языковые модели используются на основе предоставленных вопросов.и Ответ на создание контекста。существоватьздесь,Мы использовали бета-модель Zephyr 7B.
постепенно Реализация кода
этот Реализация код проведет вас через Ламу Индекс создает граф знаний.
1. Здесь мы прочитаем файл .pdf и преобразуем его в структурированный граф знаний. 2. Сохраните внедрение в хранилище данных графа. 3. Получите соответствующий контекст, соответствующий запросу пользователя. 4. Предоставьте ответы LLM для получения ответов.
Этапы реализации
Установите необходимые зависимости
%%capture
pip install llama_index pyvis Ipython langchain pypdfВключить ведение журнала диагностики
• Ведение журнала может предоставить ценную информацию о выполнении кода. • Здесь для уровня журнала установлено значение «ИНФО», что поможет отслеживать сообщения потока операций приложения.
import logging
import sys
#
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))Импортируйте необходимые зависимости
from llama_index import (SimpleDirectoryReader,
LLMPredictor,
ServiceContext,
KnowledgeGraphIndex)
#
from llama_index.graph_stores import SimpleGraphStore
from llama_index.storage.storage_context import StorageContext
from llama_index.llms import HuggingFaceInferenceAPI
from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings
from llama_index.embeddings import LangchainEmbedding
from pyvis.network import NetworkКраткий обзор используемых пакетов
•SimpleDirectoryReader: используется для чтения неструктурированных данных. •LLMPredictor: для создания прогнозов с использованием больших языковых моделей (LLM). •ServiceContext: предоставляет необходимые контекстные данные для организации различных сервисов. •KnowledgeGraphIndex: необходим для построения и работы с графиками знаний. •SimpleGraphStore: простой репозиторий для хранения данных графиков. • HuggingFaceInferenceAPI: модуль для использования LLM с открытым исходным кодом.
Настроить LLM
Здесь мы использовали конечную точку API вывода HuggingFace.
HF_TOKEN = "Your Huggaingface api key "
llm = HuggingFaceInferenceAPI(
model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN
)Настройка модели внедрения
embed_model = LangchainEmbedding(
HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large")
)Загрузить данные
documents = SimpleDirectoryReader("/content/Documents").load_data()
print(len(documents))выход
44Построить индекс графа знаний
Создание графов знаний часто включает в себя специализированные и сложные задачи. Однако, используя Llama Index (LLM), KnowledgeGraphIndex и GraphStore, мы можем легко создать относительно эффективный граф знаний из любого источника данных, поддерживаемого Llama Hub.
Установить контекст службы
service_context = ServiceContext.from_defaults(
chunk_size=256,
llm=llm,
embed_model=embed_model
)Установить контекст хранения
#setup the service context
service_context = ServiceContext.from_defaults(
chunk_size=256,
llm=llm,
embed_model=embed_model
)
#setup the storage context
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
#Construct the Knowlege Graph Undex
index = KnowledgeGraphIndex.from_documents( documents=documents,
max_triplets_per_chunk=3,
service_context=service_context,
storage_context=storage_context,
include_embeddings=True)•max_triplets_per_chunk: определяет количество реляционных триплетов, обрабатываемых на каждый фрагмент данных. •include_embeddings: используется для включения включения векторных внедрений в индекс для расширенного анализа.
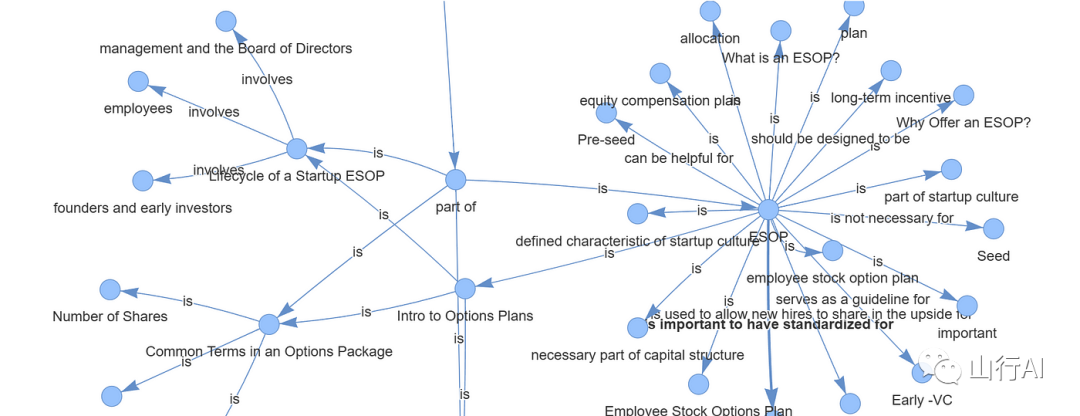
Граф знаний, созданный на основе документов
Text: page_label: 2
file_path: /content/Documents/Employee-Stock-Option-Plans-ESOP-Best-Practices-2.pdf
What is an ESOP?
Triplets:
(page_label, is, 2)
(ESOP, is, What is an ESOP?)
---------------------
Text: page_label: 3
file_path: /content/Documents/Employee-Stock-Option-Plans-ESOP-Best-Practices-2.pdf
Why Offer an ESOP?
Triplets:
(page_label, is, 3)
(ESOP, is, Why Offer an ESOP?)
---------------------
Text: page_label: 4
file_path: /content/Documents/Employee-Stock-Option-Plans-ESOP-Best-P
(page_label, is, part of)
(page_label, is, Table of Contents)
(file_path, is, path of)
(file_path, is, /content/Documents/Employee-Stock-Option-Plans-ESOP-Best-Practices-2.pdf)
(ESOP, is, part of)
(ESOP, is, Intro to Options Plans)
...Часть контента опущена. Если вам интересно, вы можете просмотреть исходный текст напрямую: https://medium.aiplanet.com/implement-rag-with-knowledge-graph-and-llama-index-6a3370e93cdd.Запросите граф знаний, создав механизм запросов.
query = "What is ESOP?"
query_engine = index.as_query_engine(include_text=True,
response_mode ="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,)
#
message_template =f"""<|system|>Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer.</s>
<|user|>
Question: {query}
Helpful Answer:
</s>"""
#
response = query_engine.query(message_template)
#
print(response.response.split("<|assistant|>")[-1].strip())
#####OUTPUT #####################
ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.query ="Who is Atul?"
message_template =f"""<|system|>Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer.</s>
<|user|>
Question: {query}
Helpful Answer:
</s>"""
#
response = query_engine.query(message_template)
#
print(response.response.split("<|assistant|>")[-1].strip())
################OUTPUT#####################
I do not have prior knowledge or context about who atul is. Please provide more information or context so I can assist you better. Without any further context, I do not know the answer to your question.графическая визуализация
• Библиотека pyvis используется для графического представления графиков знаний. • Notebook=True гарантирует, что график совместим с Jupyter Notebooks. • cdn_resources=”in_line” указывает встроенное расположение ресурсов. • Directed=True определяет график как направленный ввод.
from pyvis.network import Network
from IPython.display import display
g = index.get_networkx_graph()
net = Network(notebook=True,cdn_resources="in_line",directed=True)
net.from_nx(g)
net.show("graph.html")
net.save_graph("Knowledge_graph.html")
#
import IPython
IPython.display.HTML(filename="/content/Knowledge_graph.html")
Сохранение данных
Сохранение данных играет решающую роль в процессе построения графов знаний и связанных с ними индексов, особенно когда они очень сложны или требуют больших вычислительных усилий. Сохраняя данные, мы можем легко получить данные, необходимые для будущего анализа, без необходимости полной перестройки.
storage_context.persist()Папка, содержащая следующую информацию:

в заключение
Подводя итог, можно сказать, что разница между векторными базами данных и графами знаний заключается в том, как они хранят и представляют данные. Векторные базы данных специализируются на операциях, основанных на сходстве, полагаясь на числовые векторы для измерения расстояний между объектами. С другой стороны, графы знаний предназначены для отражения сложных отношений и зависимостей через узлы и ребра, чтобы облегчить семантический анализ и расширенные рассуждения. Для решения проблемы галлюцинаций языковых моделей (LLM) графы знаний оказываются лучше векторных баз данных. Графики знаний предоставляют более точную, разнообразную, интересную, логичную и последовательную информацию, снижая вероятность галлюцинаций в LLM. Это преимущество связано с его способностью предоставлять точные сведения об отношениях между объектами, а не просто указывать на сходство, поддерживая более сложные запросы и логические рассуждения. Эффективность каждого метода зависит от конкретного характера данных, сложности взаимосвязей и желаемых результатов. В качестве поддержки графов знаний графовые базы данных хороши для анализа отношений и сложных сетей. Векторные базы данных превосходно подходят для поиска по сходству и сценариев наилучшего сопоставления с помощью своих числовых массивов. В конечном счете, какой метод выбрать, зависит от потребностей проекта, включая характер данных, необходимость исследования взаимосвязей и типы ожидаемых запросов. Ключевые факторы, которые следует учитывать при выборе этого варианта, включают характер данных и их взаимосвязей, наличие сложных зависимостей, потребности в запросах и анализе, необходимость эффективного поиска по сходству и особенности применения в реальном времени. Кроме того, следует учитывать наличие языков запросов, API и интеграции экосистемы. Таким образом, как векторизованные базы данных, так и графы знаний имеют свои преимущества и недостатки, и лучший выбор зависит от конкретного варианта использования. Понимание характера данных и требований проекта имеет решающее значение при определении того, следует ли использовать векторизованную базу данных или граф знаний для хранения и представления соответствующей информации.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
