Как гарантировать, что сообщение не потеряется в случае потери сообщения RabbitMQ? (Подробное объяснение, разберёмся в одной статье)
1. Концепции, связанные с RabbitMQ
Выпущенная в 2007 году, это корпоративная система обмена сообщениями многократного использования, основанная на AMQP (расширенный протокол очереди сообщений). В настоящее время это одно из наиболее распространенных промежуточных программ для обмена сообщениями.
RabbitMQ — это реализация AMQP (Advanced Message Queue Advanced Message Queuing Protocol) с открытым исходным кодом, разработанная erlang. Благодаря высоким характеристикам параллелизма язык erlang имеет хорошую производительность. По сути, это очередь FIFO. , а содержимое, хранящееся в нем, является сообщением.
RabbitMQ — это промежуточное программное обеспечение для сообщений: оно получает сообщения и пересылает их, как курьерская станция. Продавец доставляет нам экспресс через экспресс-станцию. То же самое относится и к MQ, который получает и сохраняет сообщения, а затем пересылает их.
2. Три ситуации, в которых теряются сообщения RabbitMQ
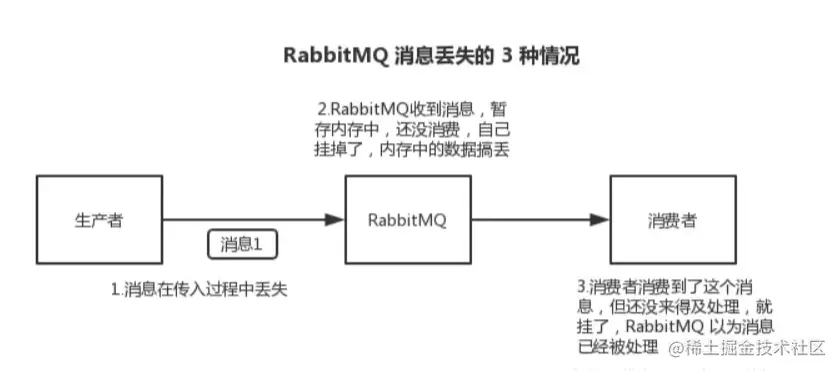
Первый тип:Продюсер проиграл.данные。Производители будутданныеотправить в RabbitMQ Иногда данные могут быть потеряны на полпути из-за проблем с сетью или других проблем.
Второй вид:RabbitMQ Потерял данные. MQ еще не сохранился и умер сам по себе.
Третий вид:Потребительская часть потеряла данные. Только что потратил,Еще не обработано,В результате процесс зависает,Например, перезапуск.
3. Решение проблемы потери сообщений RabbitMQ
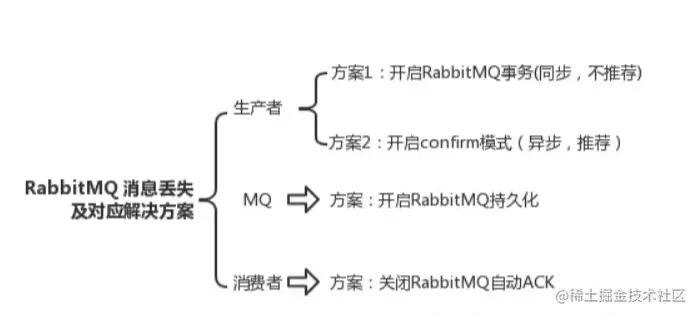
1. Для производителей
Вариант 1 : Запустить транзакцию RabbitMQ. Вы можете использовать RabbitMQ Предоставленная функция транзакции активируется до того, как производитель отправит данные. RabbitMQ Channel.txВыберите транзакцию, а затем отправьте сообщение, если сообщение не было успешно отправлено. RabbitMQ В случае получения производитель получит сообщение об ошибке исключения. В это время транзакцию Channel.txRollback можно откатить и отправить сообщение повторно; если сообщение получено, транзакция Channel.txCommit может быть отправлена.
// Включи дела
channel.txSelect
try {
// Отправить сообщение сюда
} catch (Exception e) {
channel.txRollback
// Повторно опубликовать это сообщение здесь
}
// Отправить дела
канал.txCommitнедостаток: RabbitMQ Механизм транзакций является синхронным. После того, как вы отправите транзакцию, она будет заблокирована. Таким образом, пропускная способность в основном снизится, поскольку она потребляет слишком много производительности.
Вариант 2. Использовать механизм подтверждения.
Самая большая разница между механизмом транзакции и механизмом подтверждения заключается в том, что механизм транзакции является синхронным. После отправки транзакции она будет заблокирована, но механизм подтверждения является асинхронным.
После того, как производитель включит режим подтверждения, каждому написанному сообщению будет присвоен уникальный идентификатор. Затем, если оно записано в RabbitMQ, RabbitMQ отправит вам ответное сообщение, сообщающее, что сообщение отправлено ОК, если RabbitMQ Если сообщение не удалось; для обработки, вам перезвонит интерфейс nack и сообщит, что сообщение не удалось отправить, и вы можете повторить попытку. И вы можете объединить этот механизм, чтобы знать, что вы сохраняете идентификатор каждого сообщения в памяти. Если вы не получили обратный вызов для этого сообщения по истечении определенного периода времени, вы можете отправить его повторно.
//Открываем подтверждение
channel.confirm();
//Отправляем успешный обратный вызов
public void ack(String messageId){
}
// Отправить обратный вызов при ошибке
public void nack(String messageId){
//Повторно отправить сообщение
}2. Для RabbitMQ
Давайте поговорим о трёх моментах:
(1) Чтобы гарантировать, что RabbitMQ не теряет сообщения, вам необходимо включить механизм сохранения RabbitMQ, то есть сохранять сообщения на жестком диске, чтобы даже если RabbitMQ зависает, он все равно мог читать сообщения с жесткого диска после перезапуск;
(2) Что делать, если в RabbitMQ есть одна точка отказа. Эта ситуация не приведет к потере сообщений. Здесь мы упомянем три режима установки RabbitMQ: автономный режим, режим обычного кластера и режим зеркального кластера. необходимо обеспечить высокую производительность RabbitMQ. Если доступно, вы должны сотрудничать с HAPROXY для создания режима зеркального кластера.
(3) Как гарантировать, что сообщения не потеряются, если жесткий диск сломан?
(1) Сохранение сообщений
Сообщения RabbitMQ по умолчанию хранятся в памяти. Если не указаны специальные настройки, сообщения не будут сохраняться на жестком диске. Если узел перезапускается или случайно выходит из строя, сообщения будут потеряны.
Поэтому необходимо сохранить сообщение. Как сохраниться, подробно описано ниже:
Чтобы добиться устойчивости сообщения, должны быть выполнены следующие три условия, каждое из которых является обязательным.
1) Сохранение настроек обмена
2) Постоянство наборов очередей
3) Постоянная отправка сообщения. Чтобы отправить сообщение, установите режим доставки DeliveryMode=2, который представляет собой постоянное сообщение.
(2) Установите режим зеркалирования кластера.
Давайте сначала представим три режима развертывания RabbitMQ:
1)Режим одного узла:простейший случай,некластеризованный режим,Узел не работает,Сообщение больше не доступно. Бизнес может быть парализован,Все, что мы можем сделать, это ждать.
2)Обычный режим:Сообщение будет существовать только в текущем узле.,Он не будет синхронен с другими узлами.,Текущий узел не работает,Влиятельный бизнес будет парализован,Вы можете только дождаться восстановления и перезапуска узла (если сообщения должны сохраняться).
3)Зеркальный режим:пресс-конференциясинхронныйк другим узлам,Вы можете установить количество узлов для синхронного,Но пропускная способность упадет. Решение высокой доступности, принадлежащее RabbitMQ
Зачем настраивать кластер с зеркальным режимом, потому что содержимое очереди существует только на определенном узле и не существует на всех узлах. Все узлы хранят только структуры сообщений и метаданные. Ниже я нарисовал картинку, чтобы представить ситуацию потери сообщений в обычных кластерах:
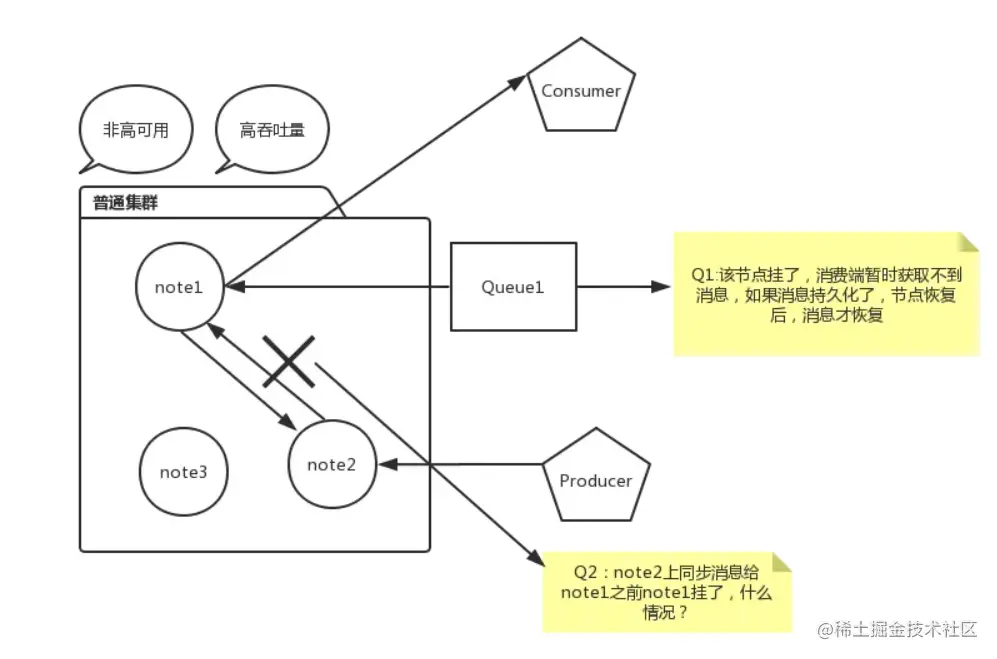
Если вы хотите решить вышеуказанные проблемы и гарантировать, что сообщения не будут потеряны, вам необходимо использовать очередь режима зеркалирования HA.
Давайте представим это нижеТри режима стратегии высокой доступности:
1) Синхронизировать со всеми
2) Синхронизировать до N машин
3) Синхронизировать только с узлами, соответствующими указанному имени.
Шаблон политики высокой доступности обработки команд: Rabbitmqctl set_policy [-p Vhost] Определение шаблона имени [Приоритет]
1) Установите зеркало всех узлов для каждой очереди, начиная с "rock.wechat", и установите для него режим автоматической синхронизации Rabbitmqctl set_policy ha-all "^rock.wechat" '{"ha-mode":"all", " ha-sync-mode":"automatic"}' Rabbitmqctl set_policy -p rock ha-all "^rock.wechat" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
2) Установите два зеркала узла для каждой очереди, начиная с «rock.wechat», и установите режим автоматической синхронизации Rabbitmqctl set_policy -p rock ha-exacly «^rock.wechat». '{"ha-mode":"точно","ha-params":2,"ha-sync-mode":"automatic"}'
3) Назначьте указанный узел каждой очереди, начиная с «узла», для зеркалирования Rabbitmqctl set_policy ha-nodes «^nodes». '{"ha-mode":"nodes","ha-params":["rabbit@nodeA", "rabbit@nodeB"]}'
Однако у зеркальной очереди высокой доступности есть большой недостаток: снизится пропускная способность системы.
(3) Механизм компенсации сообщений
Зачем нам нужен механизм компенсации сообщений? Будут ли сообщения по-прежнему теряться? Да, система находится в сложной среде. Не думайте слишком просто. Хотя приведенные выше три решения в принципе могут обеспечить высокую доступность сообщений и предотвратить их потерю.
Но как начинающий программист я обязательно должен обеспечить стабильность своей системы и иметь ощущение кризиса.
Например: В процессе сохранения постоянных сообщений на жёсткий диск текущий узел очереди зависает, жёсткий диск узла хранения выходит из строя и сообщение теряется. Что делать?
1) Производственная сторона сначала сохраняет бизнес-данные и данные сообщения в базе данных. Это должно быть в одной транзакции. Если данные сообщения не могут быть сохранены в базе данных, вся транзакция будет отменена.
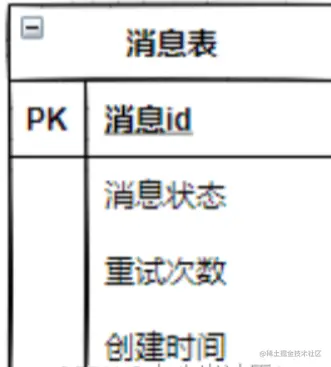
2) В соответствии со статусом сообщения в таблице сообщений, в случае сбоя будут приняты меры по компенсации сообщения и сообщение будет отправлено повторно.
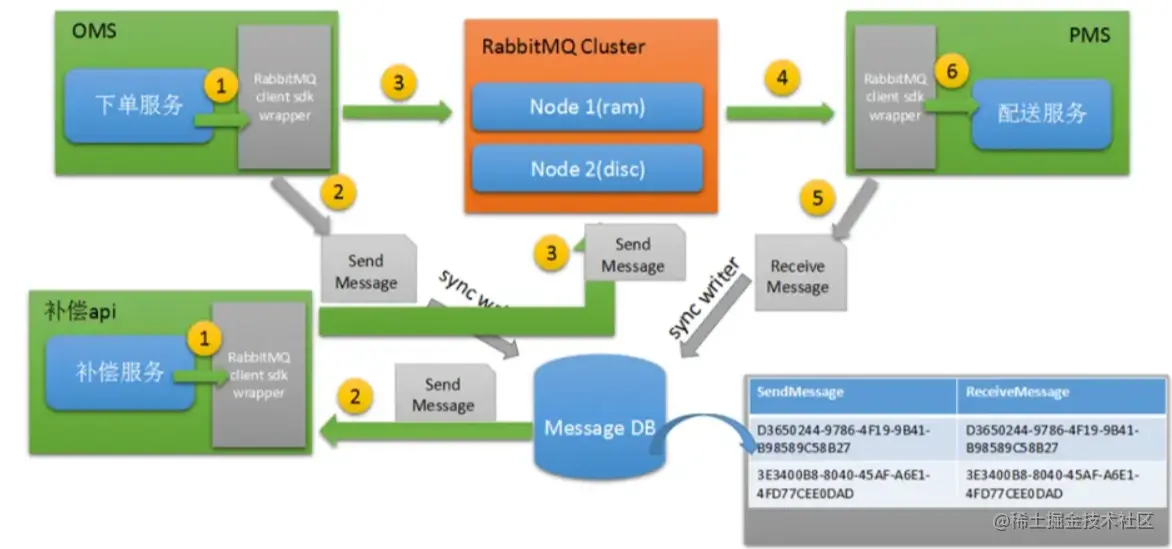
3. Целевые потребители
Вариант 1: механизм подтверждения ACK
Несколько потребителей получают сообщения одновременно. Например, при получении сообщения на полпути потребитель умирает (слишком сложная логика, истекает время, или потребление прекращается, или сеть отключается). не потеряно?
Используя механизм подтверждения, предоставляемый RabbitMQ, сервер сначала отключает автоматическое подтверждение RabbitMQ, а затем вручную вызывает ACK в коде каждый раз после проверки того, что сообщение обработано. Это позволит избежать подтверждения до обработки сообщения. После этого сообщение удаляется из памяти.
Это решает проблему. Даже если у потребителя возникнет проблема, сообщение не будет синхронизировано с сервером, и его будут использовать другие потребители, гарантируя, что сообщение не будет потеряно.
4. Резюме
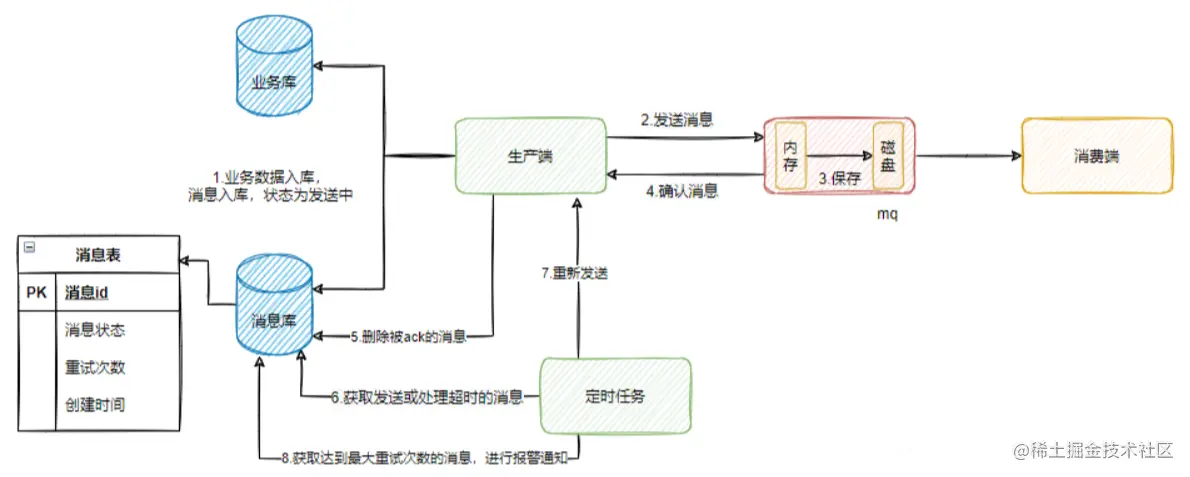
Если необходимо обеспечить, чтобы сообщения не терялись по всей ссылке, то производственная сторона, сам mq и потребительская сторона должны работать вместе, чтобы обеспечить это.
Производственная сторона:Маркировка статуса создаваемых сообщений,Включите механизм подтверждения,Обновить статус сообщения на основе ответа mq,Используйте запланированные задачи для повторной доставки сообщений об истечении времени ожидания.,Предупреждайте, если произойдет несколько сбоев доставки.
сам mq:Включить сохранение,И затем подтверждение после размещения заказа. Если это режим развертывания зеркала,Прежде чем активировать, необходимо получить несколько копий.
Потребительская сторона:Включить вручнуюackмодель,Выполните подтверждение после завершения бизнес-обработки.,И его идемпотентность должна быть гарантирована.
Благодаря вышеуказанной обработке теоретически потери сообщений не происходит, но снижается пропускная способность и производительность системы.
В реальной разработке необходимо учитывать влияние потери сообщений, чтобы найти компромисс между надежностью и производительностью.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
