Как эффективно управлять сервером региона в HBase
В системах больших данных количество и конфигурация региональных серверов оказывают решающее влияние на общую производительность. Если сервер региона не управляется должным образом, это может вызвать следующие проблемы:
- Дисбаланс нагрузки:частьRegion Сервер перегружен, что приводит к снижению производительности.
- узкое место в хранилище:частьRegionСлишком много данных хранится,Это приводит к увеличению времени ответа на запрос.
- Пустая трата ресурсов:Неразумное распределение ресурсов,Это приводит к пустой трате аппаратных ресурсов, таких как память и процессор.
Поэтому в этой статье будет подробно рассмотрено, как улучшить общую производительность HBase и снизить затраты на эксплуатацию и обслуживание за счет разумной настройки и управления региональным сервером. В этой статье объединены реальные случаи, чтобы подробно представить, как оптимизировать управление сервером региона с разных точек зрения, таких как распределение регионов, автоматическая балансировка нагрузки и сжатие данных.
Обзор архитектуры сервера региона HBase
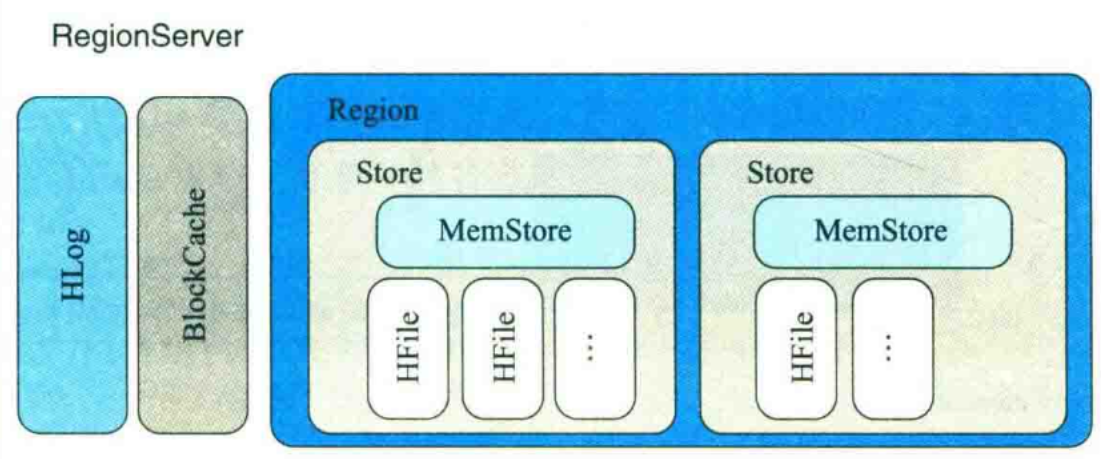
В HBase таблица разделена на несколько регионов для хранения в соответствии с диапазоном значений ключа строки. Сервер регионов отвечает за управление операциями распространения, хранения, чтения и записи этих регионов. На каждом сервере региона может размещаться несколько регионов. Обычно на каждом сервере региона имеется Wal (журнал упреждающей записи), чтобы обеспечить надежность записи данных.
Ниже приведен основной принцип работы сервера региона HBase:
Функция | иллюстрировать |
|---|---|
Разделение регионов | Когда размер региона превышает настроенный порог, он автоматически разделяется на два меньших региона. Разделенный регион может быть перенесен на другой региональный сервер. |
Объединение регионов | Когда данные удаляются или сжимаются, некоторые регионы могут стать маленькими, и HBase автоматически объединит их для экономии ресурсов. |
балансировка нагрузки | HBase автоматически распределяет нагрузку на сервер региона между несколькими компьютерами через балансировщик нагрузки, чтобы избежать перегрузки одного сервера региона. |
Стратегии эффективного управления региональным сервером
Для эффективного управления сервером региона необходимо объединить несколько факторов, таких как размер данных, нагрузка на чтение и запись, а также аппаратные ресурсы. Вот несколько распространенных стратегий оптимизации:
1 Грамотно планируйте количество Регионов
В HBase количество регионов напрямую влияет на общую производительность. Слишком большое количество регионов может привести к чрезмерному потреблению системных ресурсов, а слишком малое количество регионов может привести к перегрузке одного сервера региона. Поэтому разумное планирование размера и количества каждого региона является первым шагом в управлении сервером региона.
- Настроить размер региона:существоватьHBaseв файле конфигурации,Можно установить
hbase.hregion.max.filesizeограничить каждогоRegionМаксимальный размер файла。Например,Установите размер каждого региона на 5 ГБ:
<property>
<name>hbase.hregion.max.filesize</name>
<value>5368709120</value> <!-- 5GB -->
</property>- Автоматически разделить регион:когдаRegionКогда размер файла достигает порога,HBaseАвтоматически разделится。может пройти
hbase.hregion.precreate.flushthresholdНастройте стратегию разделения。
2 Включить регион Балансировка нагрузки сервера
В крупномасштабных кластерах нагрузка на один региональный сервер может быть слишком высокой, что приводит к возникновению узких мест. Благодаря механизму балансировки нагрузки HBase регионы можно автоматически переносить на серверы регионов с меньшими нагрузками.
Балансировку нагрузки можно включить следующей командой:
hbase balance_switch true- Оптимизация параметров балансировки нагрузки:балансировка Интервал работы сервера, порог нагрузки и другие параметры можно настроить через файл конфигурации. Ниже приведены некоторые общие элементы конфигурации:
<property>
<name>hbase.balancer.period</name>
<value>300000</value> <!-- Проверяйте балансировку каждые 5 минут. нагрузки -->
</property>
<property>
<name>hbase.balancer.maxoverloaded</name>
<value>5</value> <!-- Один регион Максимальное количество регионов, разрешенное для перегрузки сервером -->
</property>3 Предварительное разбиение и разбиение вручную
Предварительное разделение позволяет избежать концентрации всех данных в нескольких регионах на ранних этапах записи данных. На сервере,Это приводит к снижению производительности системы. при создании таблицы,Можно использоватьSPLITSПараметр для указания количества предварительных разделов,Например:
create 'my_table', 'cf', { SPLITS => ['A', 'B', 'C'] }Таким образом, данные будут распределяться по разным регионам в соответствии с диапазоном значений ключей, что снизит нагрузку на один регион.
Пример развертывания кода
Чтобы лучше проиллюстрировать, как управлять сервером региона HBase в реальных сценариях, ниже приведен пример использования кода Java для автоматического управления операциями сервера региона, включая балансировку нагрузки, миграцию региона и сжатие данных.
1 Структура проекта
В этой статье мы будем использовать код Java для управления региональным сервером. Базовая структура каталогов проекта выглядит следующим образом:
HBaseRegionManagement/
│
├── src/
│ └── main/
│ ├── java/
│ │ └── com/
│ │ └── example/
│ │ ├── HBaseRegionBalance.java
│ │ └── HBaseRegionCompression.java
│ └── resources/
│ └── hbase-site.xml
└── pom.xml2 Балансировка нагрузки и миграция регионов
Создайте класс Java, чтобы включить балансировщик нагрузки в HBase и вручную перенести определенные регионы на другие серверы регионов.
пакет com.example;
импортировать org.apache.hadoop.conf.Configuration;
импортировать org.apache.hadoop.hbase.HBaseConfiguration;
импортировать org.apache.hadoop.hbase.client.Admin;
импортировать org.apache.hadoop.hbase.client.Connection;
импортировать org.apache.hadoop.hbase.client.ConnectionFactory;
импортировать org.apache.hadoop.hbase.client.RegionInfo;
импортировать org.apache.hadoop.hbase.util.Bytes;
импортировать java.util.List;
общественный класс HBaseRegionBalance {
public static void main(String[] args) выдает исключение {
Конфигурация конфигурации = HBaseConfiguration.create();
попробуйте (Соединение Connection = ConnectionFactory.createConnection(config)) {
Администратор admin = Connection.getAdmin();
// балансировка нагрузки
admin.setBalancerRunning(true, true);
System.out.println("балансировка нагрузка включена");
// Получить список регионов таблицы
List<RegionInfo> regions = admin.getRegions(Bytes.toBytes("my_table"));
for (RegionInfo region : regions) {
System.out.println("Region: " + region.getRegionNameAsString());
}
// Перенос регионов вручную
if (!regions.isEmpty()) {
RegionInfo regionToMove = regions.get(0);
admin.move(regionToMove.getEncodedNameAsBytes(), Bytes.toBytes("server_name"));
System.out.println("Region " + regionToMove.getRegionNameAsString() + " Перенесён в новый регион Server");
}
// тесная связь
admin.close();
}
}
}- проходить
ConnectionFactory.createConnection()Получить сHBaseсвязь。 admin.setBalancerRunning(true, true)давать возможностьбалансировка нагрузкиустройство。admin.getRegions()Получить указанную таблицуRegionсписок,И выведите информацию о регионе.admin.move()Используется для ручного измененияRegionМигрировать в указанныйRegion Server。
3 Включить сжатие данных
HBase поддерживает несколько алгоритмов сжатия, таких как Gzip, Snappy, LZO и т. д. Мы можем динамически настраивать сжатие таблиц с помощью кода, чтобы уменьшить использование пространства хранения и повысить производительность чтения.
package com.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.io.compress.Compression;
public class HBaseRegionCompression {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config)) {
Admin admin = connection.getAdmin();
// Получить дескриптор таблицы
TableDescriptor tableDescriptor = admin.getDescriptor(Bytes.toBytes("my_table"));
// Изменение метода сжатия семейства столбцов
TableDescriptorBuilder.ModifyableTableDescriptor newDescriptor =
new TableDescriptorBuilder.ModifyableTableDescriptor(tableDescriptor);
ColumnFamilyDescriptorBuilder.ModifyableColumnFamilyDescriptor cfDescriptor =
new ColumnFamilyDescriptorBuilder.ModifyableColumnFamilyDescriptor(
tableDescriptor.getColumnFamily(Bytes.toBytes("cf")));
cfDescriptor.setCompressionType(Compression.Alg
orithm.SNAPPY); // Использовать алгоритм сжатия Snappy
new
// Установить новый дескриптор семейства столбцов
newDescriptor.modifyColumnFamily(cfDescriptor);
// Обновить дескриптор таблицы
admin.modifyTable(newDescriptor);
System.out.println("Метод сжатия таблицы для семейства столбцов изменен на Snappy");
// тесная связь
admin.close();
}
}
}проходитьadmin.getDescriptor()Получить указанную таблицудескриптор。
ColumnFamilyDescriptorBuilder.ModifyableColumnFamilyDescriptorИспользуется для изменения конфигурации семейства колонн.,где мы устанавливаем алгоритм сжатияCompression.Algorithm.SNAPPY。- вызов
admin.modifyTable()обновить дескриптор таблицы,и примените новую конфигурацию сжатия.
Таким образом, метод сжатия таблицы HBase может быть динамически изменен. Правильное использование алгоритмов сжатия может значительно сократить использование дискового пространства и сыграть положительную роль в повышении производительности чтения.
Решения и предложения по оптимизации
В крупномасштабном кластере HBase разумное управление сервером региона является ключом к обеспечению эффективной работы системы. Ниже приведены некоторые практические примеры и предложения по оптимизации:
- Правильно настройте аппаратные ресурсы сервера региона.
- Сервер региона обычно предъявляет высокие требования к памяти, процессору и дисковому вводу-выводу. Вы можете выбрать подходящую конфигурацию оборудования в зависимости от размера кластера и нагрузки на чтение и запись данных, чтобы избежать нехватки или растраты ресурсов.
- Постарайтесь выбрать устройства хранения данных с более высокой пропускной способностью, например твердотельные накопители, которые могут значительно повысить производительность чтения.
- Оптимизируйте распределение данных с помощью стратегий предварительного разделения
- При первом импорте данных можно разработать стратегию предварительного разделения на основе потребностей бизнеса, чтобы избежать централизованной записи данных в определенные регионы. Server,привести к Дисбаланс нагрузки。
- Регулярно контролируйте и настраивайте вручную
- Хотя HBase поставляется с механизмом балансировки нагрузки, администраторам все равно приходится вручную переносить некоторые регионы в особых сценариях (например, в периоды пиковой нагрузки).
- Регулярно отслеживайте загрузку каждого Сервера региона с помощью инструментов управления HBase или пользовательских скриптов и корректируйте стратегию распределения регионов в соответствии с потребностями.
- Оптимизация сжатия и хранения
- Правильное использование алгоритмов сжатия, таких как Snappy и Gzip, может эффективно сократить использование диска с данными и повысить производительность чтения.
- Для бизнес-сценариев с большим объемом исторических данных операции слияния и сжатия могут выполняться регулярно, чтобы обеспечить эффективность чтения и записи в системе.
- Рекомендации по улучшению производительности записи
- может пройти Отрегулируйте размер кэша записи(
hbase.regionserver.global.memstore.size)и записать кешflushчастота(hbase.hstore.flusher.count)для оптимизации производительности записи。 - Настройте соответствующую стратегию записи Wal, чтобы сбалансировать надежность данных и производительность записи.
Разработка управления сервером региона HBase
Поскольку размер данных продолжает расти, растет и применение HBase в крупномасштабных наборах данных. В будущем управление кластером HBase станет более интеллектуальным и автоматизированным, что в основном отразится на следующих аспектах:
тенденция | иллюстрировать |
|---|---|
Интеллектуальное планирование и автоматизированный мониторинг | Опираясь на интеллектуальные алгоритмы планирования, он автоматически определяет условия нагрузки и вносит коррективы в режиме реального времени, чтобы обеспечить эффективное управление региональным сервером. |
Динамическое расширение и гибкое развертывание | Кластер HBase будет иметь возможности эластичного расширения и сможет динамически регулировать масштаб в соответствии с потребностями бизнеса, сокращая потери ресурсов и улучшая адаптивность системы. |
Интеллектуальная оптимизация распределения данных | На основе моделей доступа к историческим данным и потребностей бизнеса автоматически оптимизируйте стратегии распределения по регионам, чтобы улучшить производительность хранения и чтения данных. |
В сценариях крупномасштабной обработки данных Region Управление сервером имеет решающее значение для общей производительности и стабильности кластера HBase. В этой статье подробно рассматривается «Как» с разных точек зрения. эффективно управлять сервером региона в HBase,включать Правильно настройте регионколичество、давать возможностьбалансировка стратегии, такие как нагрузка, оптимизация распределения данных и использование алгоритмов сжатия, а также приведены соответствующие примеры развертывания кода, основанные на реальных случаях. Через разумный регион Управление серверами позволяет значительно повысить производительность кластеров HBase, сократить потери ресурсов и обеспечить высокую доступность и стабильность системы.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
