Как devv.ai создает эффективную систему RAG

◆Part1
Полное название RAG: Retrival Augmented Generation (Поисковая дополненная генерация) Первоначально получено из статьи на Facebook в 2020 году: Retrival-Augmented Generation для наукоемких задач НЛП (Да, вы правильно прочитали, эта технология будет доступна в 2020 году). 2020).

Одна из проблем, которую хочет решить эта статья, очень проста: как генерировать языковые модели, используя внешние знания. Обычно знания модели перед обучением хранятся в параметрах, в результате чего модель не знает знаний за пределами обучающего набора (таких как данные поиска, отраслевые знания). Предыдущий подход заключался в повторной настройке модели перед обучением, когда были доступны новые знания. При таком подходе есть несколько проблем:
- Каждый раз, когда вы получаете новые знания, вам нужно их дорабатывать.
- Стоимость обучения Модельиз очень высока из-за
Итак, в этой статье предлагается метод RAG. Модель предварительного обучения может понимать новые знания, поэтому мы можем напрямую передать ей новые знания, которые мы хотим, чтобы модель поняла, с помощью подсказок.
Итак, минимальная система RAG состоит из 3 частей:
1. Языковая модель
2. Набор внешних знаний, необходимых модели (хранится в виде вектора)
3. Внешние знания, необходимые в текущем сценарии
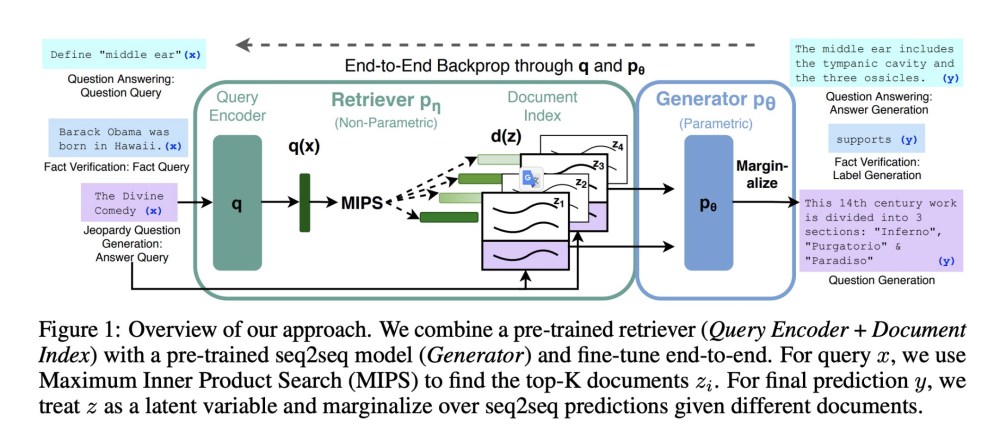
Langchain, lama-index — это по сути эта RAG-система (включая конечно же агент, построенный на RAG).
Если вы понимаете суть, то на самом деле нет необходимости добавлять дополнительный уровень абстракции. Вы можете просто построить эту систему в соответствии с вашей собственной бизнес-ситуацией. Например, чтобы поддерживать высокую производительность, мы приняли архитектуру Go + Rust, которая может поддерживать запросы RAG с высокой степенью параллелизма.
Чтобы упростить задачу, независимо от того, какой RAG построен, оптимизация системы означает оптимизацию этих трех модулей соответственно.
◆1) Языковая модель
Почему эта статья за 2020 год не вышла в свет до этого года?
Одна из основных причин заключается в том, что предыдущая базовая модель была недостаточно мощной. Если лежащая в основе модель глупа, даже если ей предоставлено множество внешних знаний, модель не может делать выводы на основе этих знаний.
Из некоторых тестов в статье также видно, что эффект улучшился, но это не особенно существенно.
1.1) Появление GPT-3 впервые делает RAG доступным.
Первая волна основана на RAG + GPT-3 компании получили очень высокие оценки & ARR (годовой регулярный доход):
- Copy AI
- Jasper
Оба эти продукта создают RAG в сфере маркетинга. Когда-то они стали звездными единорогами ИИ. Конечно, их стоимость также значительно упала после разочарования.
1.2)2023 С начала года большое количество open source & Базовые модели с закрытым исходным кодом могут быть построены поверх них. RAG система
Самый распространенный способ:
- GPT-3.5/4 + RAG (решение с закрытым исходным кодом)
- Лама 2/Мистраль + RAG (решение с открытым исходным кодом)
◆2) Набор внешних знаний, необходимых для модели.
Теперь каждый должен понимать модель внедрения, включая отзыв данных о внедрении.
Встраивание по существу преобразует данные в векторы, а затем использует косинусное сходство для поиска двух или более векторов, которые лучше всего совпадают.
knowledge -> chunks -> vector user query -> vector
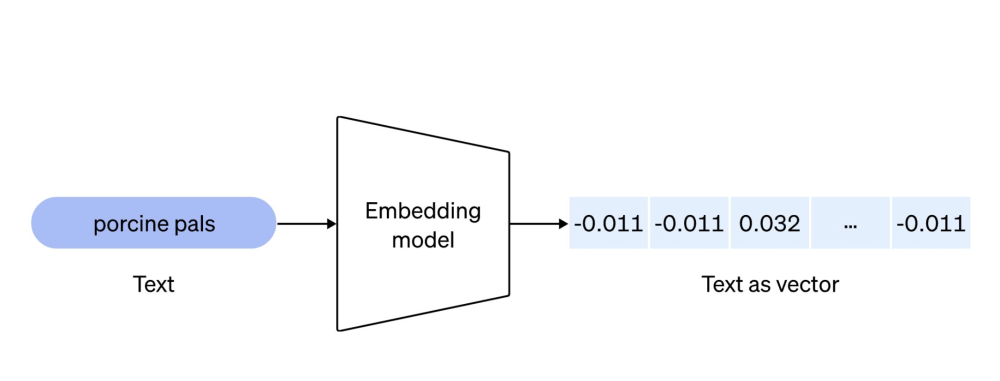
2.1) Этот модуль разделен на две части:
- embedding Модель
- хранилище embedding vector изданные Библиотека
Первый в основном использует модель внедрения OpenAI, а второй имеет множество вариантов, включая Pinecone, Zilliz отечественной команды, Chroma с открытым исходным кодом, pgvector, построенный на реляционной базе данных, и т. д.
2.2) Эти компании, занимающиеся внедрением баз данных, также получили очень высокие суммы финансирования и оценки на этой волне хайпа вокруг ИИ.
Но если исходить из основных принципов, то цель модуля 2 — хранить коллекции внешних знаний и вызывать их при необходимости.
Этот шаг не обязательно требует внедрения модели. Традиционное сопоставление поиска может работать лучше в некоторых сценариях (Elasticsearch).
2.3) http://devv.ai использует встраивание + традиционную базу данных отношений + Elasticsearch.
И в каждом сценарии было сделано множество оптимизаций. Одна из идей состоит в том, чтобы. encoding knowledge Чем больше работы вы делаете, когда retrieve может быть быстрее, когда & Более точная (сначала работа & Различия в окончательном исполнении).
2.4) Мы использовали Rust для создания полного набора индексов знаний.
включать:
- GitHub кодданные
- Разработка документацииданные
- Данные поисковой системы
◆3) Лучше вспомнить внешние знания, необходимые в текущем сценарии.
Согласно принципу приоритезации работы, при кодировании мы проделали большую обработку исходных данных знаний:
- Программный анализ кода
- Логически разделяйте документы разработки на части.
- Извлечение информации веб-страницы & page ranking оптимизация
3.1) После выполнения вышеуказанной работы гарантируется, что данные, которые мы получаем во время извлечения, сами по себе структурированы, не требуют слишком большой обработки и могут повысить точность вызова.
◆Сводка
Будь то универсальный RAG или фирменный RAG, это та область, где легко сделать так себе, но сложно сделать 90 пунктов.
Не существует рекомендаций для каждого шага, таких как встраивание размера фрагмента и необходимости подключения поисковых систем. Вам нужно попробовать больше, исходя из реального бизнес-сценария.
Есть много связанных статей, но не каждый метод, упомянутый в статье, полезен.
◆Part2
В этой серии тем мы поделимся опытом devv.ai в построении всей поисковой системы дополненной генерации, включая некоторые практики в производственной среде.
Это вторая статья из серии «Как оценить RAG система」。
То, о чем мы говорили в предыдущей статье, RAG система,И основные элементы, из которых состоят,Давайте еще раз рассмотрим это здесь.
самый простой RAG система состоит из 3 Он состоит из:
- Языковая модель
- сбор внешних знаний
- Внешние знания, необходимые в текущем сценарии
Если вы хотите оптимизировать всю систему, вы можете разбить задачу на оптимизацию этой системы по каждой части.
Но оптимизация на основе LLM Сложность в том, что эта система по сути является черным ящиком и не имеет эффективного метода оценки. Если даже самое элементарное benchmark Нет, как улучшить соответствующие показатели – это пустые разговоры.
Итак, первое, что нам нужно сделать, это настроить все RAG системаиз Система оценки。
Эта статья из Стэнфорда делает именно это, оценивая проверяемость генеративных поисковых систем.
Evaluating Verifiability in Generative Search Engines
arxiv.org/abs/2304.09848

Хотя эта статья используется для оценки Generative Search Engine (генеративная поисковая система), но методы также можно применять и к RAG по сути Generative Search Engine Вот и все RAG подмножество , а также данные, специфичные для предметной области RAG система。
В документе упоминается, что предпосылкой для заслуживающей доверия генеративной поисковой системы является: проверяемость.
Мы все знаем, что LLM часто говорит ерунду (галлюцинации) и генерирует контент, который кажется правильным, но на самом деле является неправильным. Одним из преимуществ RAG является то, что он предоставляет справочные материалы для модели, что позволяет модели снизить вероятность галлюцинаций.
Насколько уменьшилась эта иллюзия, можно оценить с помощью индикатора проверяемости.
идеальный RAG системадолжно быть:
- Высокая цитируемость, то есть весь сгенерированный контент полностью поддерживается цитированием (внешние знания).
- Высокая точность цитирования, т. е. действительно ли каждое цитирование соответствует сгенерированному контенту.
На самом деле эти два показателя не могут быть 100%. Согласно результатам экспериментов в статье, контент, генерируемый существующей генеративной поисковой системой, часто содержит необоснованные утверждения и неточные цитаты. Эти два показателя составляют 51,5% и 74,5% соответственно.
Проще говоря, сгенерированный контент не соответствует внешним знаниям.

В документе оцениваются 4 основные генеративные поисковые системы:
- Bing Chat
- NeevaAI (приобретена Snowflake)
- Perplexity
- YouChat
Вопросы для обзора касаются самых разных тем и областей.
Для оценки используются четыре показателя:
- беглость, является ли сгенерированный текст плавным и связным
- воспринимаемая полезность, практичность, полезен ли созданный контент
- отзыв цитирования, цитирование Отзывать, генерируемый контент полностью доступен для поддержки цитирования из соотношения
- точность цитирования, точность цитирования, доля цитирований, подтверждающих сгенерированный контент.

индекс 1 и 2 Обычно это общее условие. Если даже это не выполнено, то всё.
отличный RAG система должна быть в citation recall и citation precision Получите относительно высокие рейтинги.
Как реализуется конкретная система оценки? В этой части используются некоторые знания математики в средней школе. Для подробного описания процесса вы можете обратиться к исходному тексту статьи.
Метод оценки всего эксперимента заключается в использовании «искусственного» метода оценки.

1) Оцените беглость и практичность
Соответствуйте изreviewindex рецензенту, например. xxx Вот и всеfluentиз, используются вместе five-point Likert масштаб для расчета, начиная с Strongly Disagree приезжать Strongly Agree。
И пусть рецензенты оценят свое согласие с утверждением «Ответ — это полезный и информативный ответ на запрос».
2) Оценка отзыва цитат (Citation Recall)
цитирование Отзыватьотносится к:придетсяприезжатьцитированиеподдерживатьиз Генерировать контент / Сгенерированный контент, заслуживающий проверки
Таким образом, для расчета отзыва необходимо:
- Определите части сгенерированного контента, заслуживающие проверки.
- Оцените, поддерживается ли каждый контент, заслуживающий проверки, соответствующими цитатами.
Под «достойным проверки» можно понимать просто часть сгенерированного контента, содержащую информацию. На практике практически весь сгенерированный контент можно рассматривать как контент, заслуживающий проверки, поэтому скорость отзыва может быть примерно равна:
Напомним = сгенерированный контент, поддерживаемый цитированием / общее количество сгенерированного контента.
3) Измерение точности цитирования (Citation Precision)
Точность цитирования означает долю сгенерированных цитат, подтверждающих рассматриваемое утверждение. Если сгенерированный контент цитирует все веб-страницы в Интернете для каждого сгенерированного утверждения, то отзыв цитирования будет высоким, но точность цитирования будет низкой, поскольку многие статьи нерелевантны и не поддерживают сгенерированный контент.
Например, задавая вопросы на китайском языке, поисковые системы искусственного интеллекта, такие как Bing Chat, цитируют большое количество контента из CSDN, Zhihu и Baidu Zhizhi. Уровень цитирования очень высок, и иногда даже каждое предложение генерируется. Контент имеет соответствующее значение. цитаты, но точность цитат очень низкая. Большинство цитат не соответствуют сгенерированному контенту или имеют низкое качество.
devv.ai провел множество оптимизаций точности цитирования, особенно для многоязычных сценариев. Если предположить, что вопросы задаются на китайском языке, точность значительно выше, чем у таких продуктов, как Perplexity, Bing Chat и Phind.
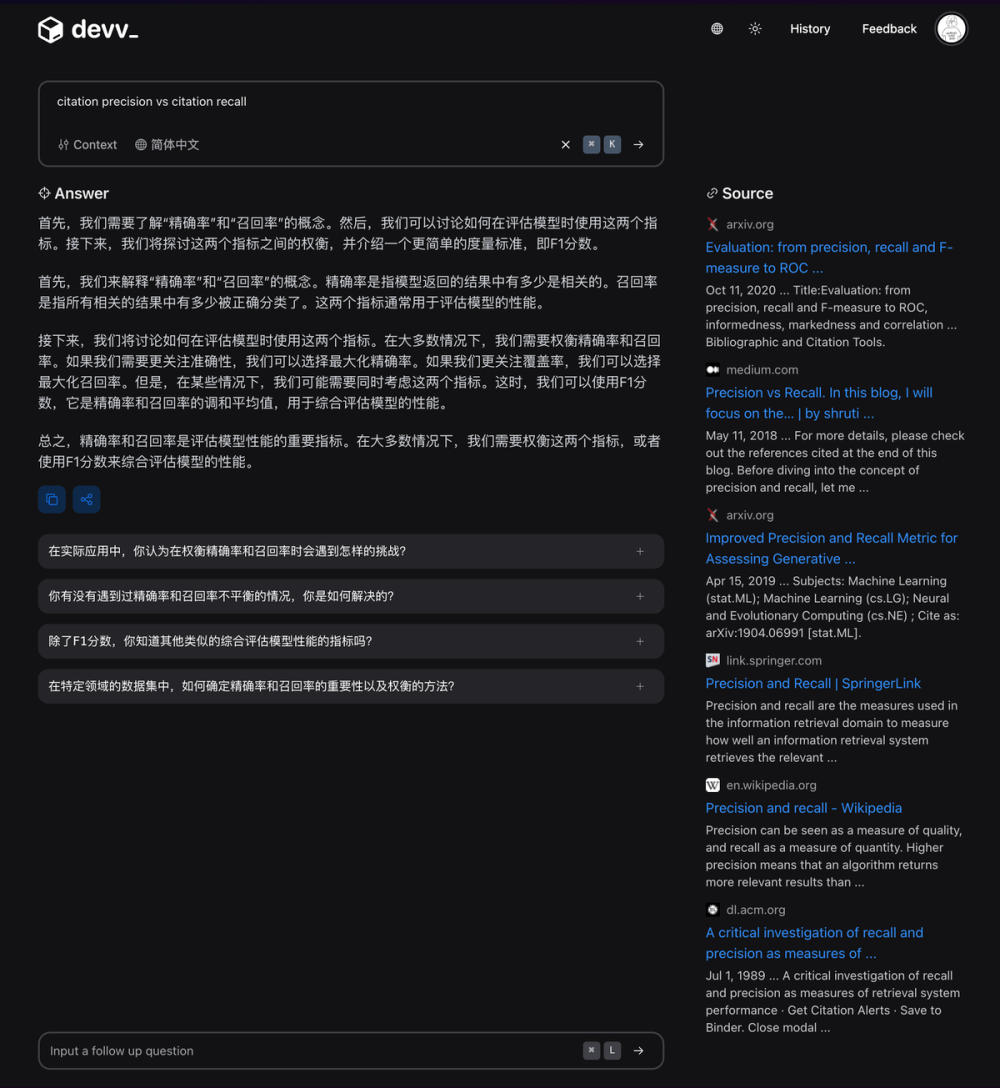
Конкретный метод расчета точности цитирования здесь описываться не будет. Его описание можно найти в статье.
Благодаря точности цитирования «Отзывать», мы можем вычислить итоговое значение Citation F (среднее тональное значение).
Чтобы добиться высокого F, вся система должна иметь высокую точность цитирования и высокую цитируемость Отзывать.

о Среднее гармоническое
devv.ai/en/search?threadId=d6xolrry09vk
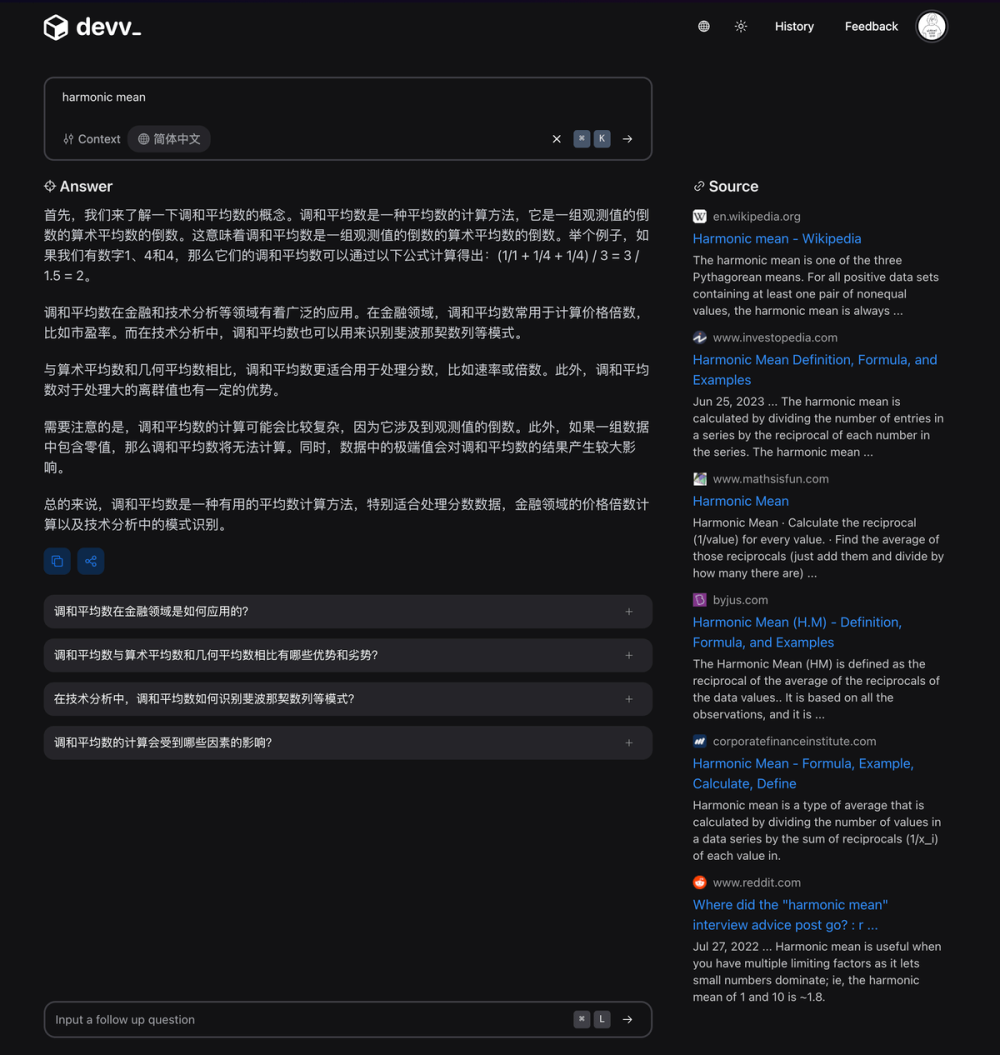
Выше представлен полный набор пар. RAG системапроверяемостьиз Метод оценки。
Благодаря этой системе отзывов каждый раз RAG оптимизации, вы можете снова запустить набор оценок, чтобы определить соответствующие изменения и оценить весь процесс с макроэкономической точки зрения. RAG Система становится лучше или хуже?
Также поделитесь devv.ai Некоторые приемы использования данного набора системы:
1) Оценочный набор
Выбор набора оценок должен соответствовать RAG в соответствии с соответствующей сценой, например devv.ai. Все выбранные обзоры связаны с программированием, и было добавлено множество наборов обзоров на нескольких языках.
2) Автоматизированная система оценки
Метод, используемый в статье, по-прежнему представляет собой человеческую оценку. Например, в статье для участия в оценке было задействовано 34 оценщика.
Недостатки:
- Рабочая сила и затраты времени
- Размер выборки небольшой, и существует определенная погрешность.
Поэтому для сценариев промышленного уровня мы создаем автоматизированную систему оценки (Evaluation Framework).
Основная идея заключается в следующем:
- на основе llama 2 train обзор Модель (проверить Отзывать точность цитирования)
- Создавайте большое количество наборов оценок и автоматически генерируйте наборы оценок на основе заданных строк.
- RAG После замены основного модуля произойдет CI Автоматически запускать всю систему оценки и генерировать скрытые данные и отчеты.
используйте этот метод,Можно очень эффективно тестировать и улучшать,Например для prompt изменения, вы можете быстро открыть один a/b эксперимент,Затем разные экспериментальные группы запустили систему оценки.,Получите окончательные результаты.
Эта структура все еще строится внутри компании. & В рамках эксперимента в будущем может быть рассмотрен открытый исходный код, соответствующий оценочному коду модели. (Я чувствую, что одна только эта система оценки может открыть новую startup )
Наконец, давайте представим devv.ai. devv.ai — это новое поколение поисковой системы искусственного интеллекта, специально предназначенное для разработчиков. Она призвана заменить ежедневное использование разработчиками Google/StackOverflow/документов и помочь разработчикам повысить эффективность и создать ценность.
Продукт выпускается уже больше месяца, а devv.ai уже используют сотни тысяч разработчиков.
кроме того,Если у вас есть какие-либо отзывы или предложения, вы можете опубликовать их в этом репо.,Вы можете напрямую пересылать прибытия на другие платформы.,Просто обратите внимание на источник.
Источник: https://twitter.com/Tisoga/status/1731478506465636749
https://typefully.com/Tisoga/PBB58Vu
Источник: https://www.toutiao.com/article/7319073154234958372/?log_from=6c1d282a778aa_1704166461102.
«IT Big Guys Say» приветствует заявки от технического персонала по электронной почте: aliang@itdks.com.
Ты сейчас здесь, иди куда хочешь, просто оставь сообщение~
ИТ-гуру говорят | о Авторское право
Оригинальная статья "ИТ-гуру Говорят (ID: itdakashuo)",При перепечатке указывайте автора, источник и официальный аккаунт WeChat. Пожалуйста, добавьте WeChat, чтобы отправлять, запрашивать и перепечатывать статьи (примечание: отправка),Мисс Жасмин свяжется с вами вовремя!
Благодарим за интерес к ИТ-гуру Говорятиз с энтузиазмом поддерживает!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
