Kafka быстрый запуск (производитель) синхронная и асинхронная отправка, секционирование, отправка сообщения ровно один раз, идемпотентность, транзакции
Kafka продюсер
1. Процесс отправки сообщения производителю
1.1 Принцип отправки
В процессе отправки сообщения задействованы два потока – основной Темы и Sender нить。существовать main нитьсерединасоздавать Понятнодек RecordAccumulator。main Поток отправляет сообщение RecordAccumulator,Sender Ветка продолжает идти от RecordAccumulator Извлекайте сообщения и отправляйте их Kafka Broker。
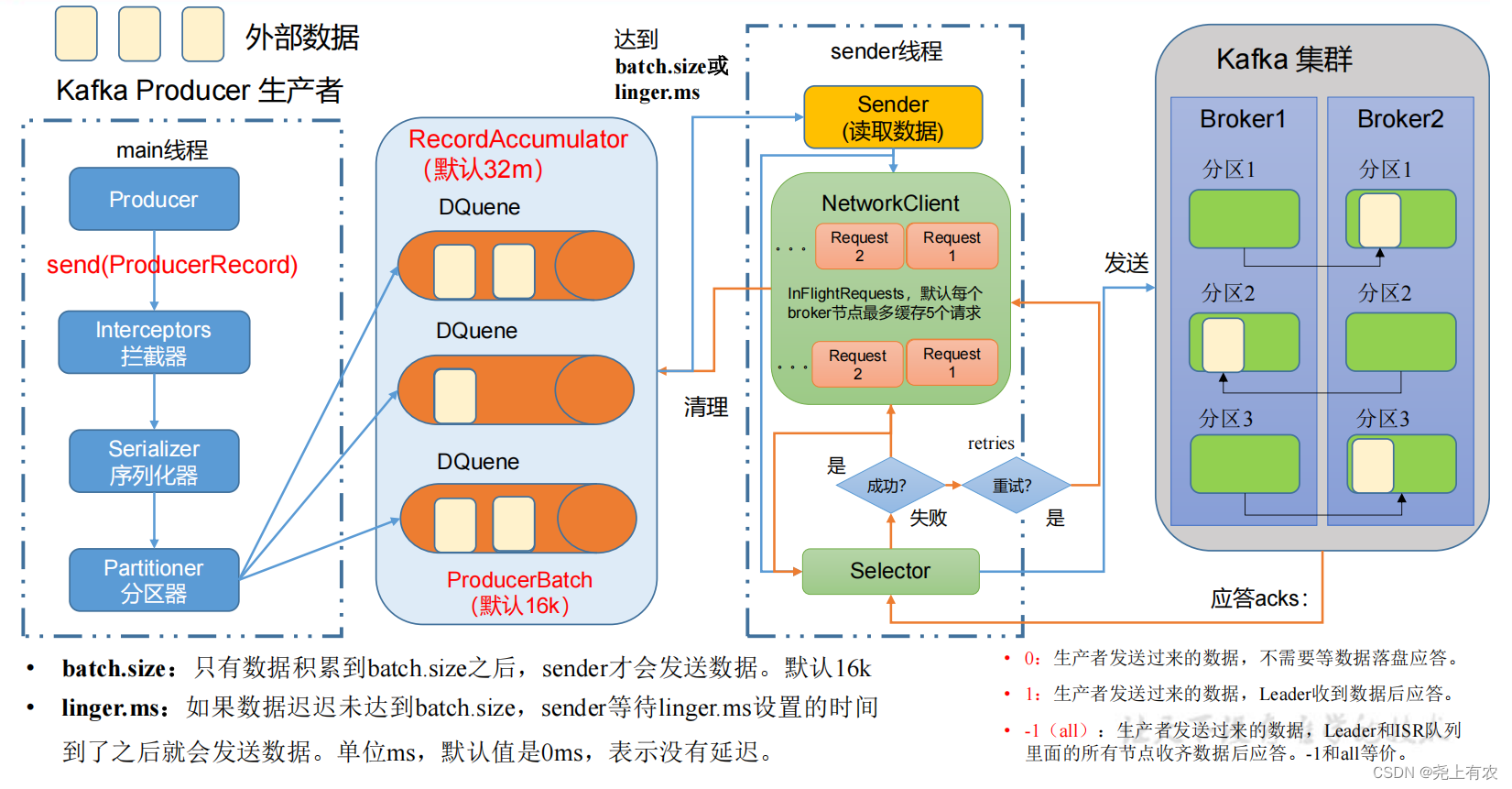
1.2 Перечень важных параметров для производителей
-Имя параметра | -описывать |
|---|---|
bootstrap.servers | Список адресов брокеров, необходимых производителям для подключения к кластеру. Например, Hadoop102:9092, Hadoop103:9092, Hadoop104:9092 можно задать один или несколько, разделив их запятыми. Обратите внимание здесь и |
key.serializer ? value.serializer | Указывает тип сериализации ключа и значение отправленного сообщения. Обязательно напишите полное имя класса. |
buffer.memory | Общий размер буфера RecordAccumulator, по умолчанию 32 м. |
batch.size | Максимальный размер пакета данных в буфере, по умолчанию 16 КБ. Соответствующее увеличение этого значения может улучшить пропускную способность, но если это значение установлено слишком большим, задержка передачи данных увеличится. |
linger.ms | Если данные не достигают размера пакета, отправитель ожидает linger.time перед отправкой данных. Единица измерения — мс. Значение по умолчанию — 0 мс, что означает отсутствие задержки. Для производственных сред рекомендуется, чтобы это значение составляло от 5 до 100 мс. |
acks | 0: данным, отправленным производителем, не нужно ждать отправки данных на диск для ответа. 1: Данные отправлены производителем, лидер отвечает после получения данных. -1 (все): данные, отправленные производителем, Leader+ и всеми узлами в очереди isr, отвечают после получения данных. Значение по умолчанию — -1, -1, и все они эквивалентны. |
max.in.flight.requests.per.connection | Максимальное количество раз, когда подтверждение не возвращается. Значение по умолчанию — 5. Чтобы включить идемпотентность, убедитесь, что значение представляет собой число от 1 до 5. |
retries | В случае ошибки при отправке сообщения система отправит сообщение повторно. retries представляет количество повторных попыток. По умолчанию используется максимальное значение int: 2147483647. Если установлена повторная попытка и вы хотите обеспечить порядок сообщений, вам необходимо установить MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1. В противном случае при повторной попытке этого неудачного сообщения другие сообщения могут быть отправлены успешно. |
retry.backoff.ms | Интервал времени между двумя повторными попытками, по умолчанию — 100 мс. |
enable.idempotence | Включить ли идемпотентность, по умолчанию — true, идемпотентность включена. |
compression.type | Метод сжатия всех данных, отправленных производителем. По умолчанию установлено значение none, что означает отсутствие сжатия. Поддерживаемые типы сжатия: нет, gzip, snappy, lz4 и zstd. |
2.Отправить асинхронно API
2.1 Обычная асинхронная отправка
1) Требования: Создать продюсер Кафки, отправлено асинхронно в Kafka Broker
Асинхронный процесс отправки
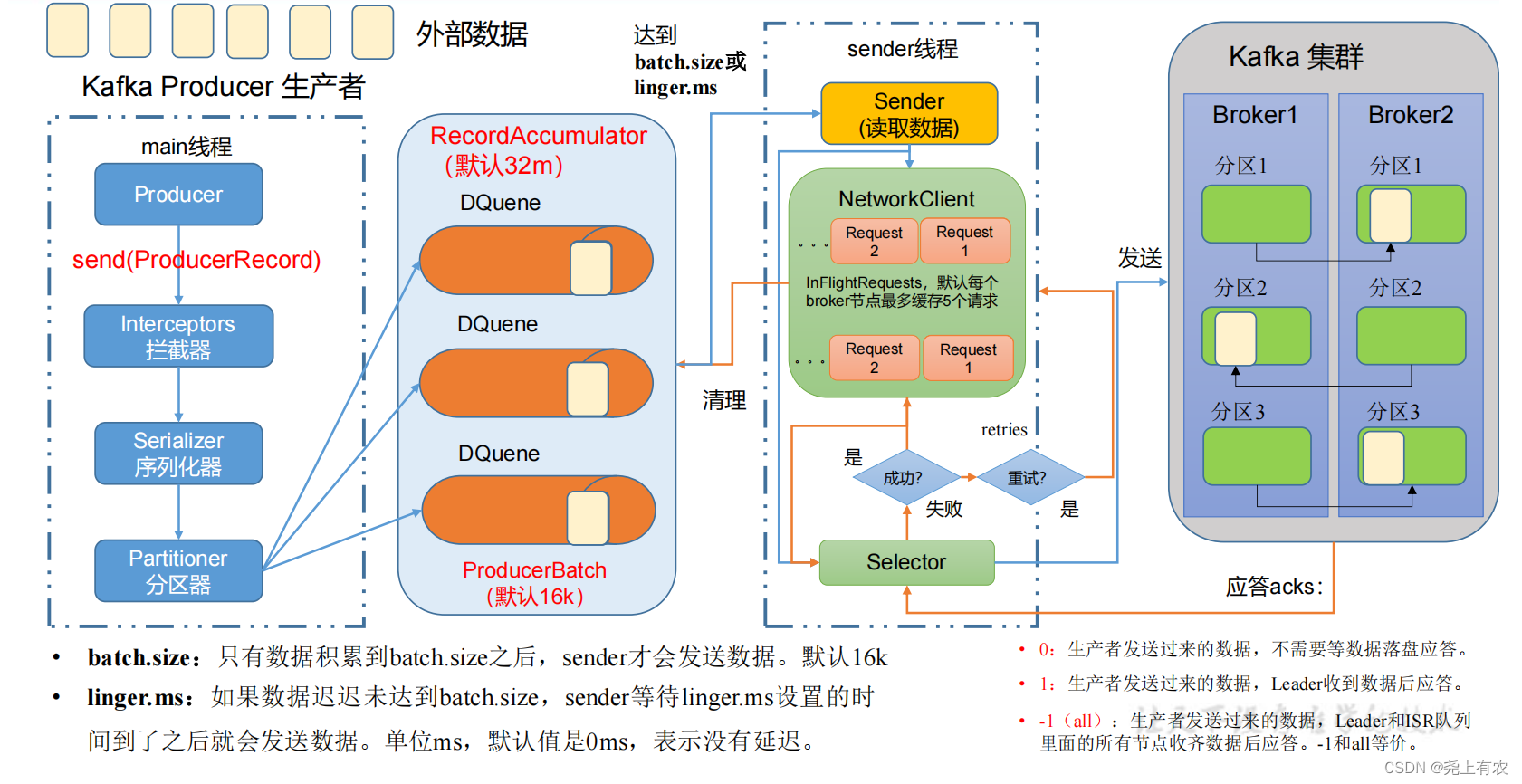
2) Написание кода
(1) Создать проект Кафка
(2) Зависимости импорта
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>(3) Создайте имя пакета: com.atguigu.kafka.producer.
(4) Напишите код API без функции обратного вызова.
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducer {
public static void main(String[] args) throws
InterruptedException {
// 1. создавать kafka Объект конфигурации производителя
Properties properties = new Properties();
// 2. Давать kafka Добавьте информацию о конфигурации в объект конфигурации: bootstrap.servers.
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// key,value Сериализация (обязательно): key.serializer, value.serializer.
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 3. создавать kafka продюсерский объект
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. вызов send метод, отправить сообщение
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new
ProducerRecord<>("first","yy " + i));
}
// 5. закрыть ресурс
kafkaProducer.close();
}
}тест:
①Откройте потребителя Kafka на Hadoop102.
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first②Выполните код в IDEA и посмотрите, поступают ли сообщения в консоль Hadoop102.
2.2 Асинхронная отправка с функцией обратного вызова
Функция обратного вызова будет вызвана, когда производитель получит подтверждение. Это асинхронный вызов. Этот метод имеет два параметра: информацию о метаданных (RecordMetadata) и информацию об исключении (Exception). Если значение Exception равно нулю, это означает, что сообщение отправлено успешно. Если Exception не имеет значения. Если оно равно нулю, это означает, что отправка сообщения не удалась.
Примечание. Если сообщение не удалось отправить, оно будет повторено автоматически. Нам не нужно вручную повторять попытку в функции обратного вызова.
// 1. создавать kafka Объект конфигурации производителя
Properties properties = new Properties();
// 2. Давать kafka Объект конфигурации добавляет информацию о конфигурации.
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value Сериализация (обязательно): key.serializer, value.serializer.
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 3. создавать kafka продюсерский объект
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. вызов send метод, отправить сообщение
for (int i = 0; i < 5; i++) {
// Добавить обратный вызов
kafkaProducer.send(new ProducerRecord<>("first", "atguigu " + i), new Callback() {
// Методсуществовать Producer получать ack часвызов,дляасинхронныйвызов
@Override
public void onCompletion(RecordMetadata metadata,
Exception exception) {
if (exception == null) {
// Без исключений, выводить информацию в консоль
System.out.println(" тема: " +
metadata.topic() + "->" + "Раздел:" + metadata.partition());
} else {
// Происходит печать исключений
exception.printStackTrace();
}
}
});
// После задержки вы увидите, что данные отправляются в разные разделы.
Thread.sleep(2);
}
// 5. закрыть ресурс
kafkaProducer.close();3. Отправить синхронноAPI
Просто вызовите метод get() на основе асинхронной отправки.
// Отправить синхронно
kafkaProducer.send(new ProducerRecord<>("first","kafka" + i)).get();4. раздел производителя
4.1 Преимущества разделения
(1)Содействовать рациональному использованию ресурсов хранения.,КаждыйиндивидуальныйPartitionсуществоватьодининдивидуальныйBrokerхранение на,Огромные объемы данных можно разделить на разделы
Часть данных хранится на нескольких брокерах. Разумный контроль над задачами разделов может обеспечить эффект балансировки нагрузки.
(2)Улучшение параллелизма,производитель может отправлять данные в разделе для единиц; потребители могут использовать данные в разделе для единиц;
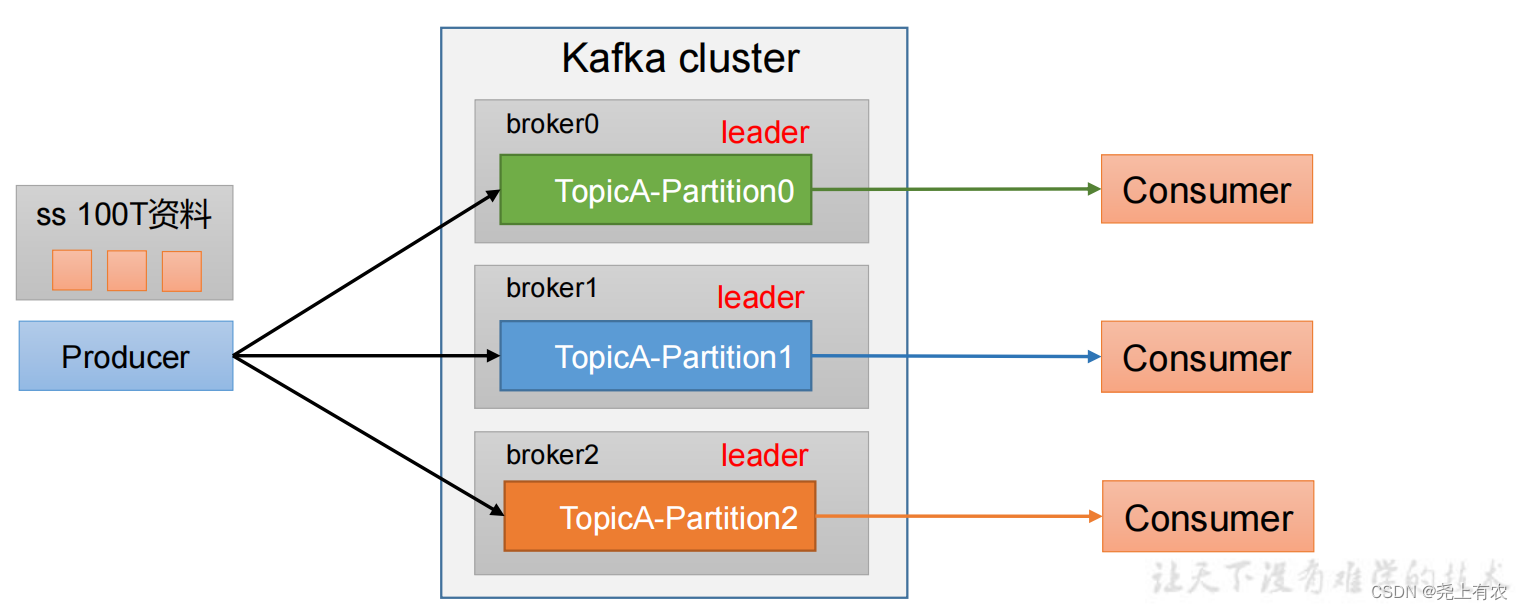
4.2 Стратегия разделения производителей для отправки сообщений
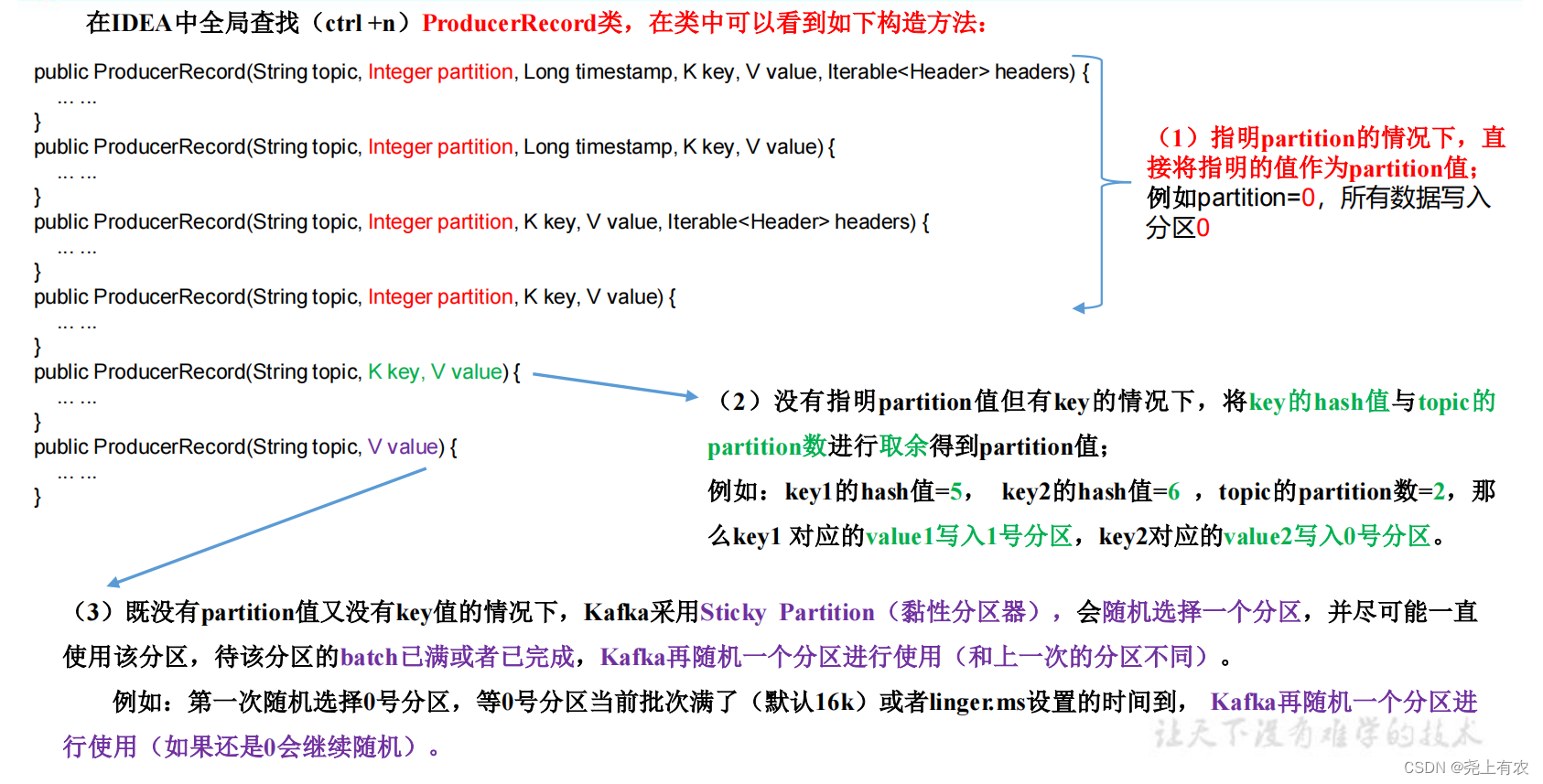
1)Разделитель по умолчанию DefaultPartitioner
В IDEA нажмите ctrl +n и выполните глобальный поиск DefaultPartitioner.
4.3 Пользовательский разделитель
1)нуждаться
Например, если мы реализуем реализацию секционирования, и если отправленные данные содержат xxx, они будут отправлены в раздел 0.
Если он не содержит xxx, он будет отправлен в раздел №1.
2)выполнитьшаг
(1) Определите класс для реализации интерфейса Partitioner.
(2) Перепишите метод раздела().
/**
* 1. реализовать интерфейс Partitioner
* 2. выполнить 3 индивидуальныйметод:partition,close,configure
* 3. писать partition Метод, возвращает номер раздела
*/
public class MyPartitioner implements Partitioner {
/**
* Вернуть раздел, соответствующий информации
* @param topic тема
* @param key новости key
* @param keyBytes новости key Сериализованный массив байтов
* @param value новости value
* @param valueBytes новости value Сериализованный массив байтов
* @param cluster Метаданные кластера могут просматривать информацию о разделах.
* @return
*/
@Override
public int partition(String topic, Object key, byte[]
keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// Получить новости
String msgValue = value.toString();
// создавать partition
int partition;
// Определите, содержит ли сообщение atguigu
if (msgValue.contains("xxx")){
partition = 0;
}else {
partition = 1;
}
// Вернуть номер раздела
return partition;
}
// закрыть ресурс
@Override
public void close() {
}
// Метод настройки
@Override
public void configure(Map<String, ?> configs) {
}
}(3) Используйте метод секционирования и добавьте параметры секционирования в конфигурацию производителя.
// добавить в Пользовательский разделитель
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.yy.kafka.producer.MyPartitioner");5. Как производители могут повысить производительность
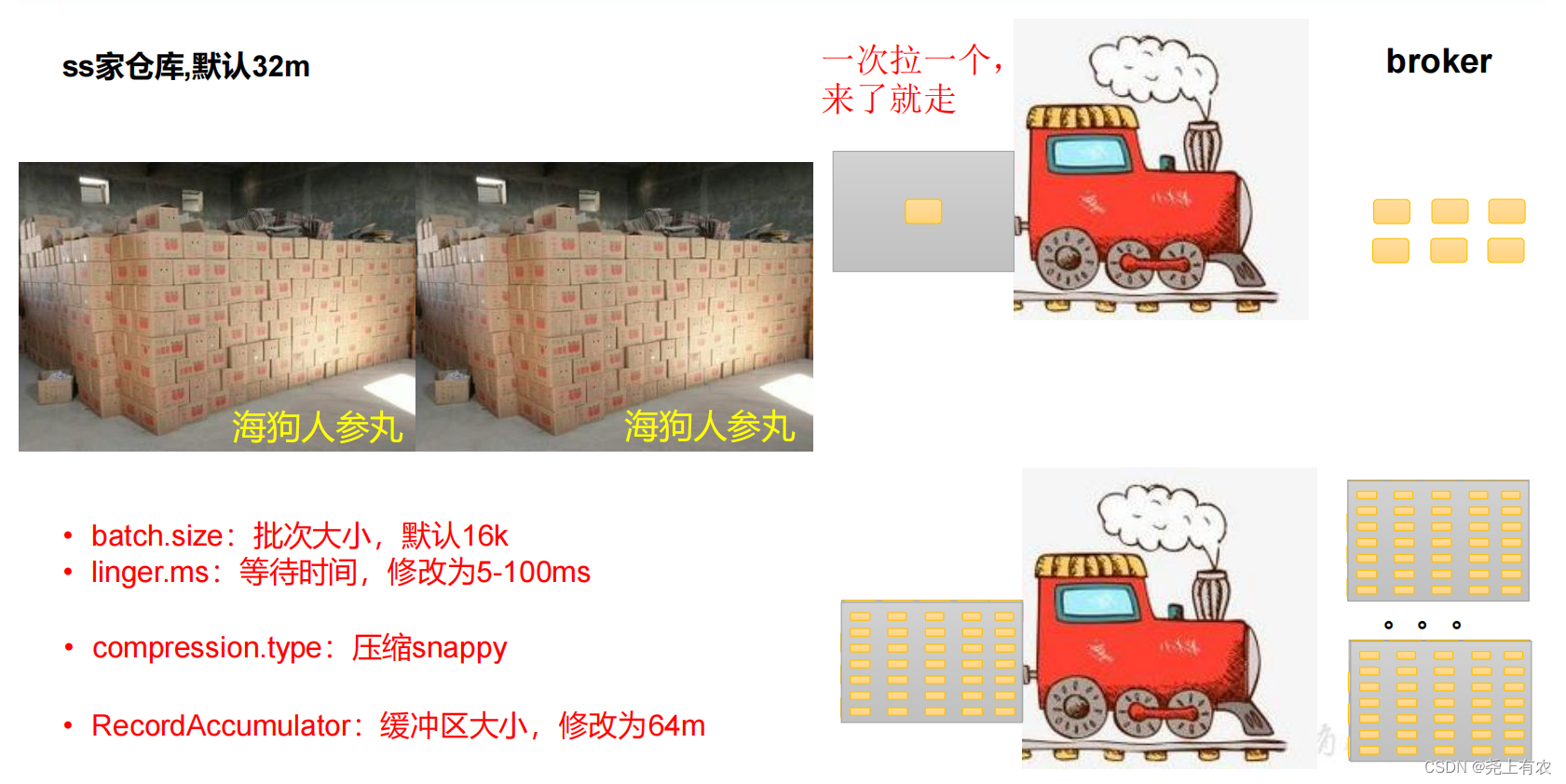
// пакет.размер: размер пакета, по умолчанию 16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// linger.ms: время ожидания, по умолчанию 0
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// RecordAccumulator: размер буфера, по умолчанию. 32M:buffer.memory
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
// compress.type: сжатие, по умолчанию нет, настраиваемое значение gzip、snappy、lz4 и zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");6. Надежность данных
1)ack Принцип реагирования
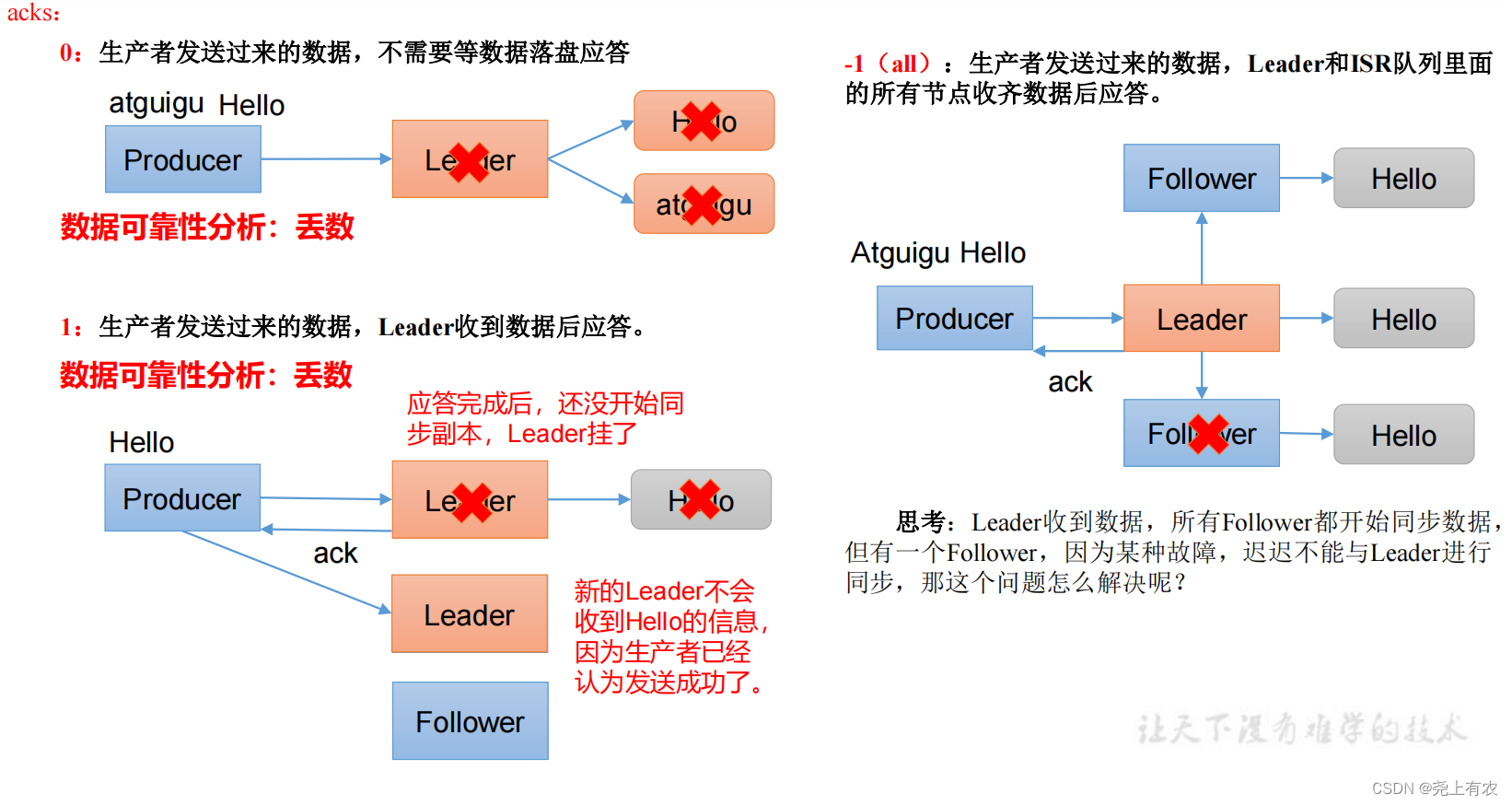
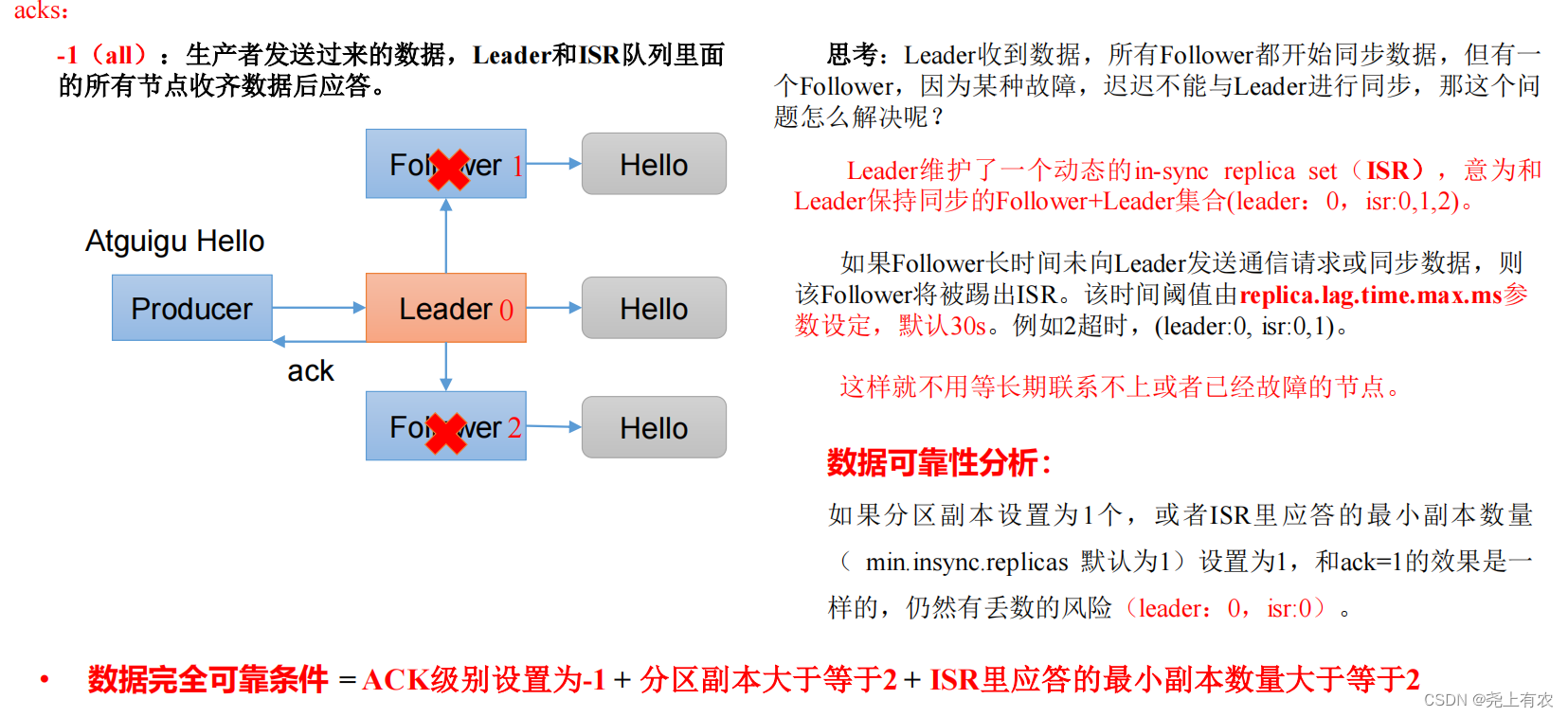
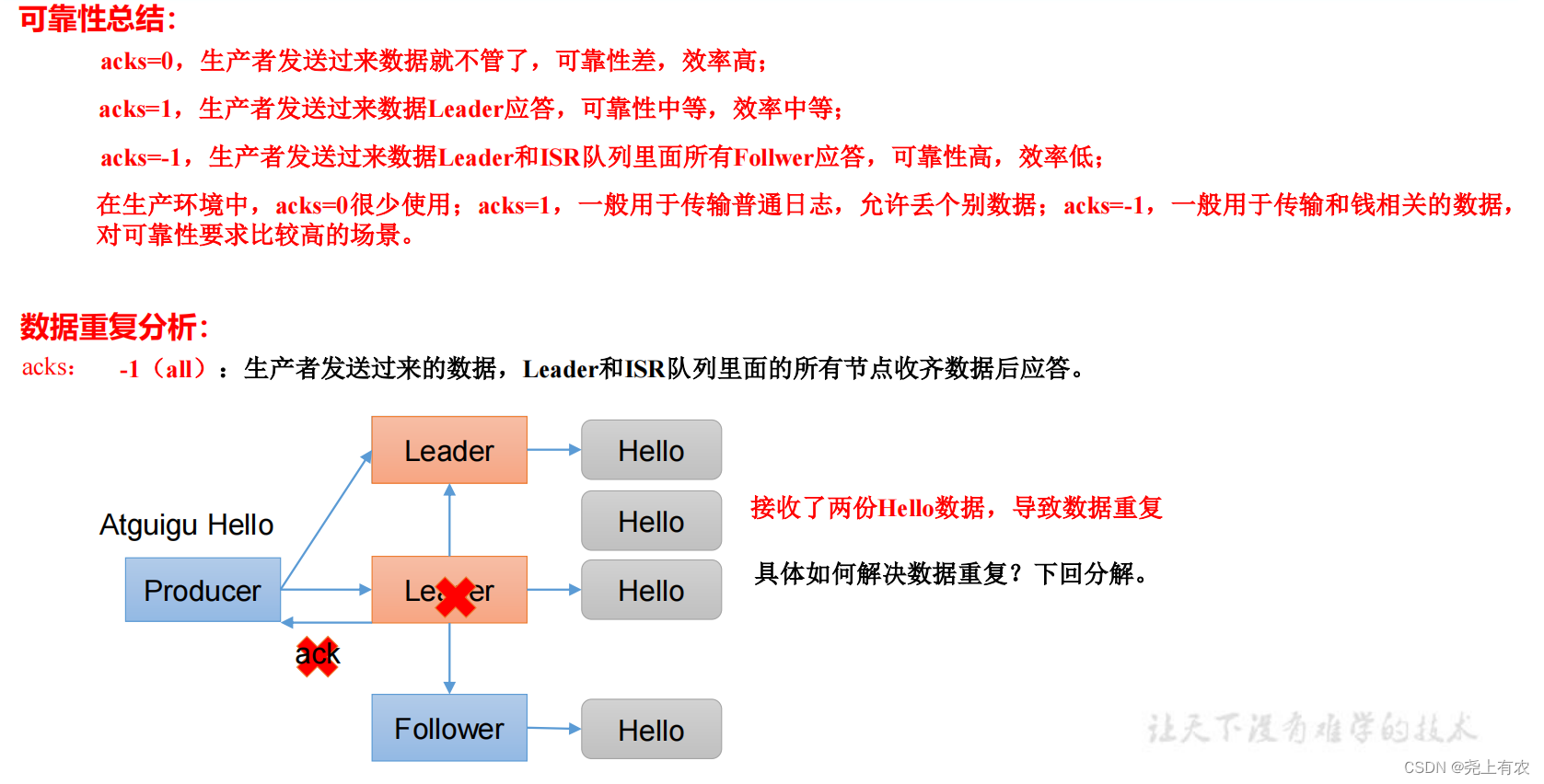
// настраивать acks
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// Количество повторов повторные попытки, значение по умолчанию int Максимальное значение, 2147483647
properties.put(ProducerConfig.RETRIES_CONFIG, 3);7. Дедупликация данных
7.1 Семантика передачи данных

7.2 Идемпотентность
1)принцип идемпотентности
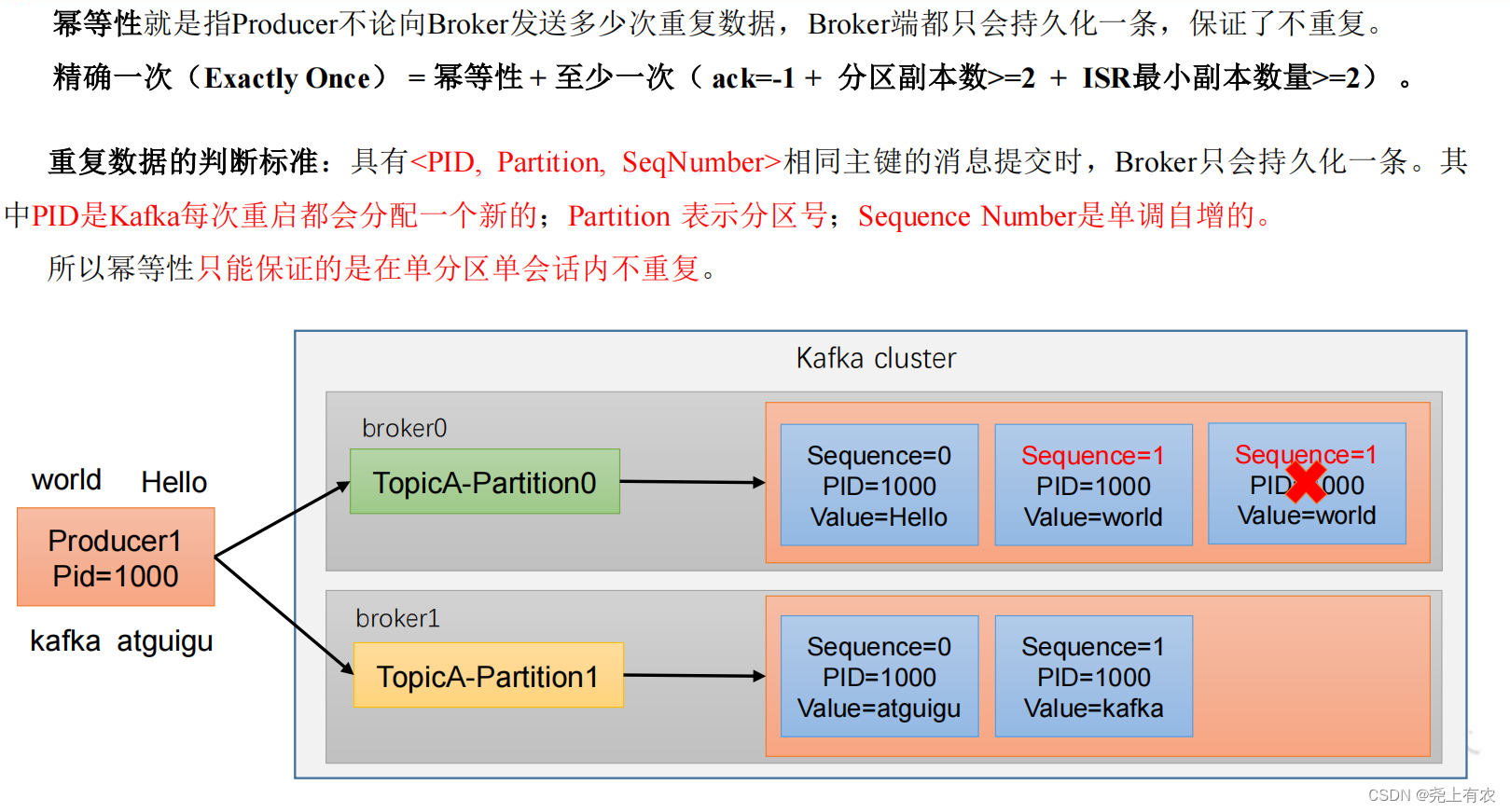
2)Как использовать идемпотентность
Открытые параметры enable.idempotence По умолчанию true,false закрытие.
7.3 транзакция производителя
1) Принцип транзакции Кафки

2) Транзакции Kafka имеют в общей сложности следующие 5 API.
// 1 Инициализировать транзакцию
void initTransactions();
// 2 Открыть транзакцию
void beginTransaction() throws ProducerFencedException;
// 3 существовать Зафиксировать потребленное возмещение в рамках транзакции (в основном используется для потребителей)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws ProducerFencedException;
// 4 совершить транзакцию
void commitTransaction() throws ProducerFencedException;
// 5 Отменить транзакцию (операция, аналогичная откату транзакции)
void abortTransaction() throws ProducerFencedException;3) Один производитель использует транзакции, чтобы гарантировать, что сообщения отправляются только один раз.
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerTransactions {
public static void main(String[] args) throws InterruptedException {
// 1. создавать kafka Объект конфигурации производителя
Properties properties = new Properties();
// 2. Давать kafka Объект конфигурации добавляет информацию о конфигурации.
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value сериализация
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// настраиватьдела идентификатор (обязательно), транзакция id Назовите все, что вам нравится
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction_id_0");
// 3. создавать kafka продюсерский объект
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// Инициализировать транзакцию
kafkaProducer.initTransactions();
// Открыть транзакцию
kafkaProducer.beginTransaction();
try {
// 4. вызов send метод, отправить сообщение
for (int i = 0; i < 5; i++) {
// отправить сообщение
kafkaProducer.send(new ProducerRecord<>("first","atguigu " + i));
}
// int i = 1 / 0;
// совершить транзакцию
kafkaProducer.commitTransaction();
} catch (Exception e) {
// Завершить транзакцию
kafkaProducer.abortTransaction();
} finally {
// 5. закрыть ресурс
kafkaProducer.close();
}
}
}8. Данные в порядке
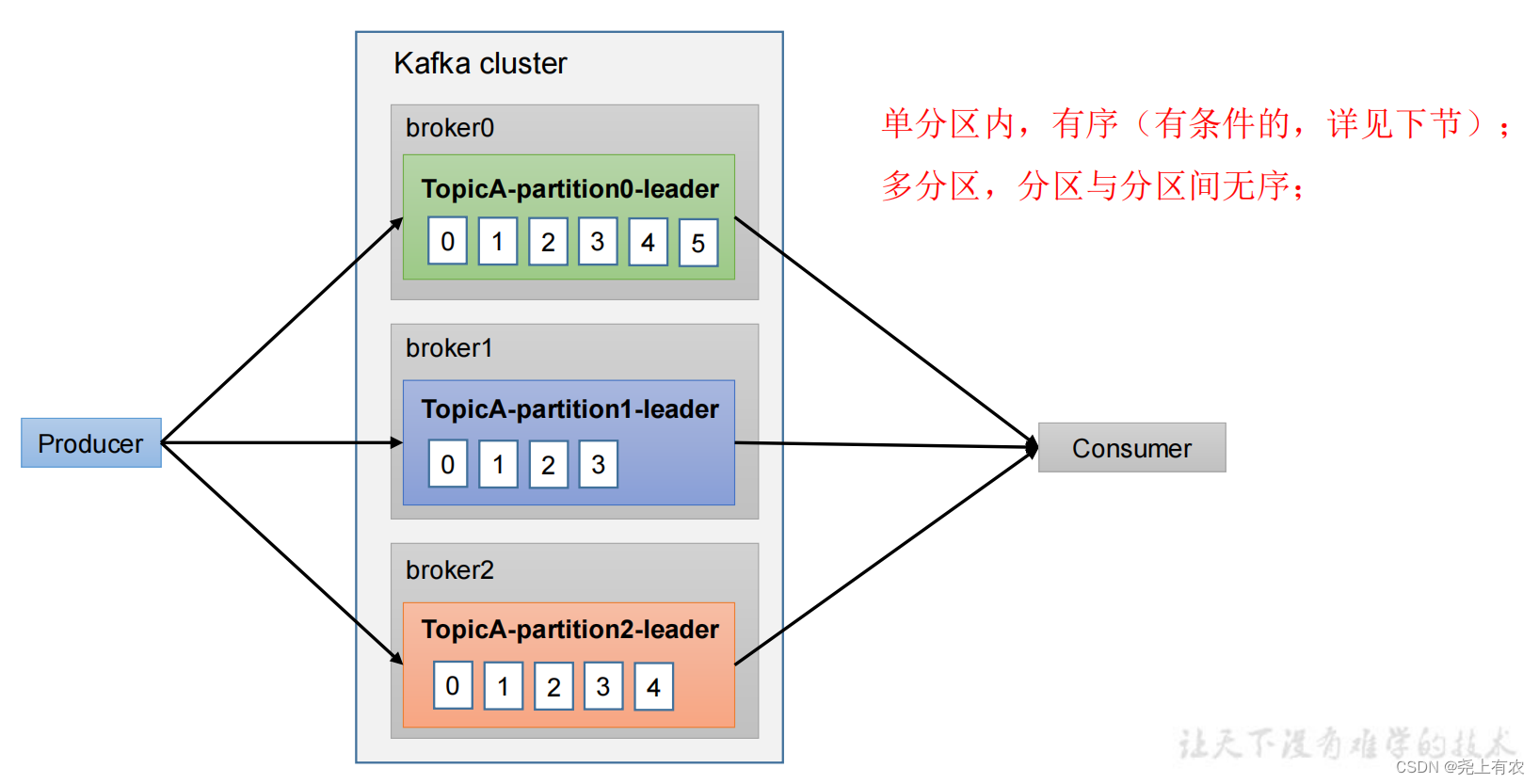
9. Данные не в порядке
1) Kafka гарантирует, что данные в одном разделе упорядочиваются до версии 1.x. Условия следующие:
max.in.flight.requests.per.connection=1(Не нужно думать, стоит ли его включать Идемпотентность)。
2) Kafka обеспечивает порядок данных в отдельных разделах в версиях 1.x и более поздних. Условия следующие:
(1) Идемпотентность не включена
max.in.flight.requests.per.connectionнуждатьсянастраиватьдля1。
(2) Включить идемпотентность
max.in.flight.requests.per.connectionнуждатьсянастраиватьменьше или равно5。
Объяснение причины: поскольку после kafka1.x после включения идемпотентности сервер Kafka будет кэшировать метаданные последних 5 запросов, отправленных производителем.
Поэтому, несмотря ни на что, мы можем гарантировать, что данные последних пяти запросов в порядке.
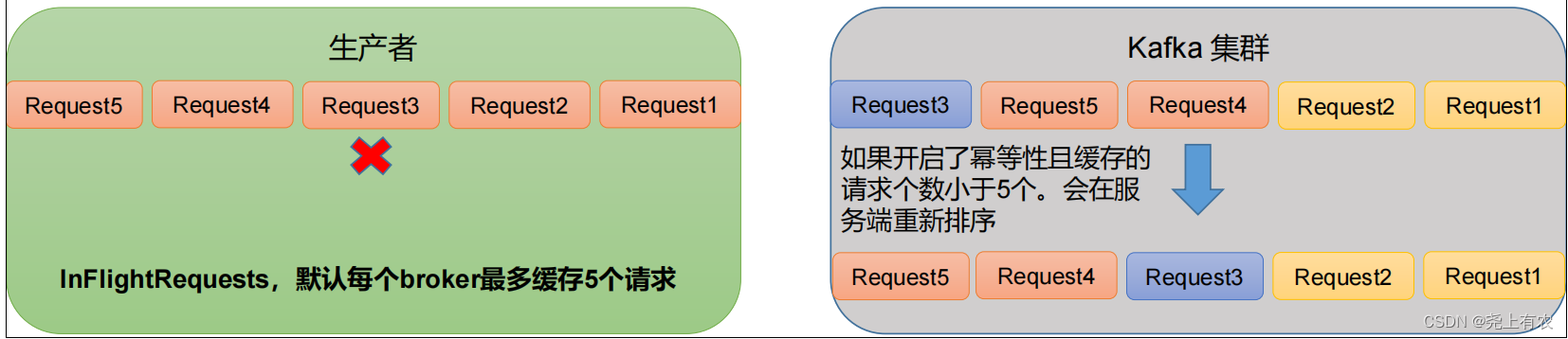



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
