Kafka-4.1-Обзор принципов работы

1 Подробное объяснение принципа работы Kafka
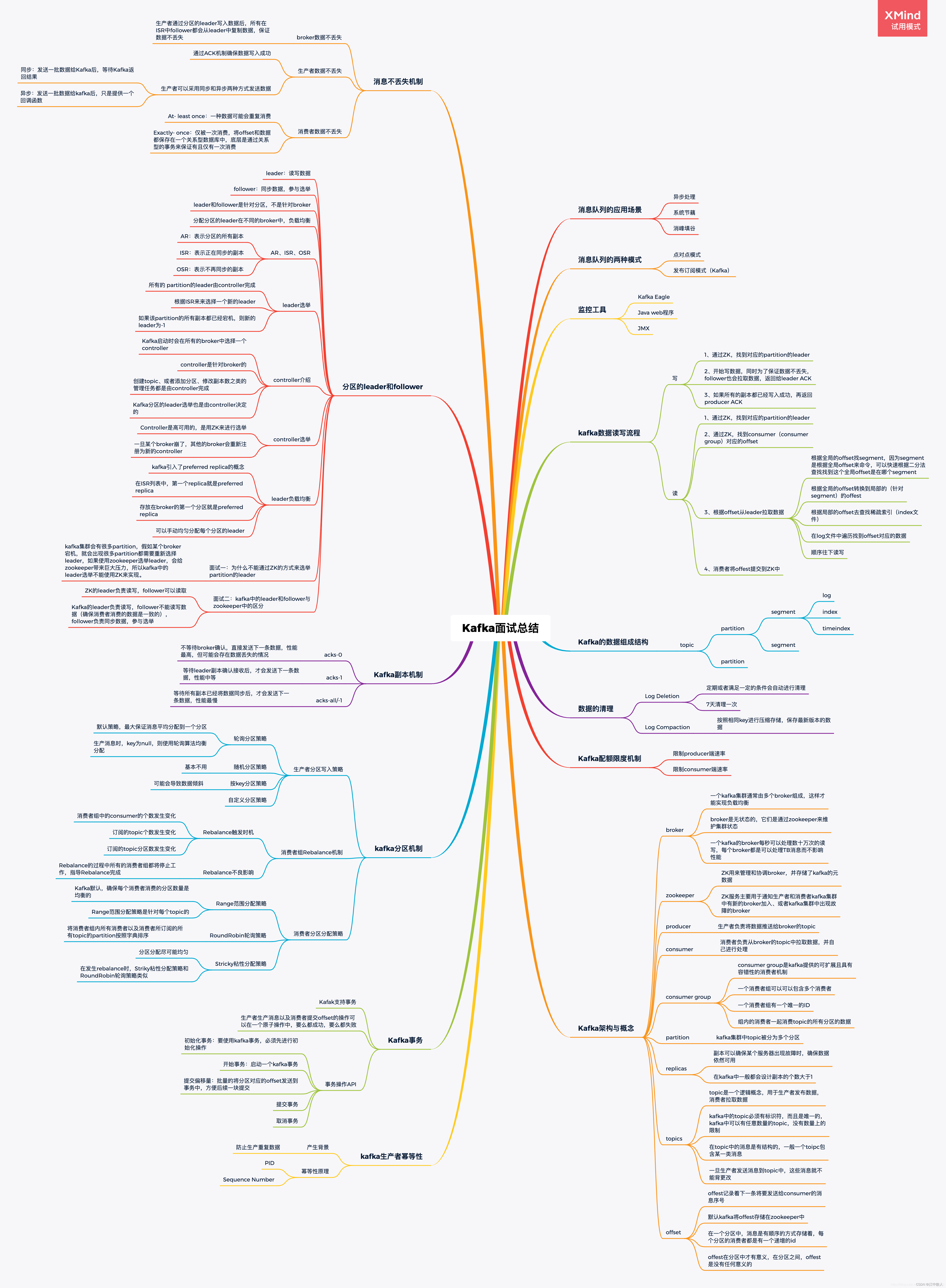
1.1 Рабочий процесс
Кластер Kafka хранит поток записей в классе Topic. Каждая запись состоит из ключа, значения и метки времени.
Сообщения в Kafka классифицируются по темам. Производители создают сообщения, а потребители потребляют сообщения, ориентированные на одну и ту же тему. Тема — это логическая концепция, а раздел — это физическая концепция. Каждый раздел соответствует файлу журнала, и в файле журнала хранятся данные, сгенерированные производителем. Данные, сгенерированные производителем, будут постоянно добавляться в конец файла журнала, и каждая часть данных имеет свое собственное смещение. Каждый потребитель в группе потребителей будет в режиме реального времени записывать, какое возмещение он израсходовал, чтобы при устранении ошибки потребление могло продолжиться с последней позиции.
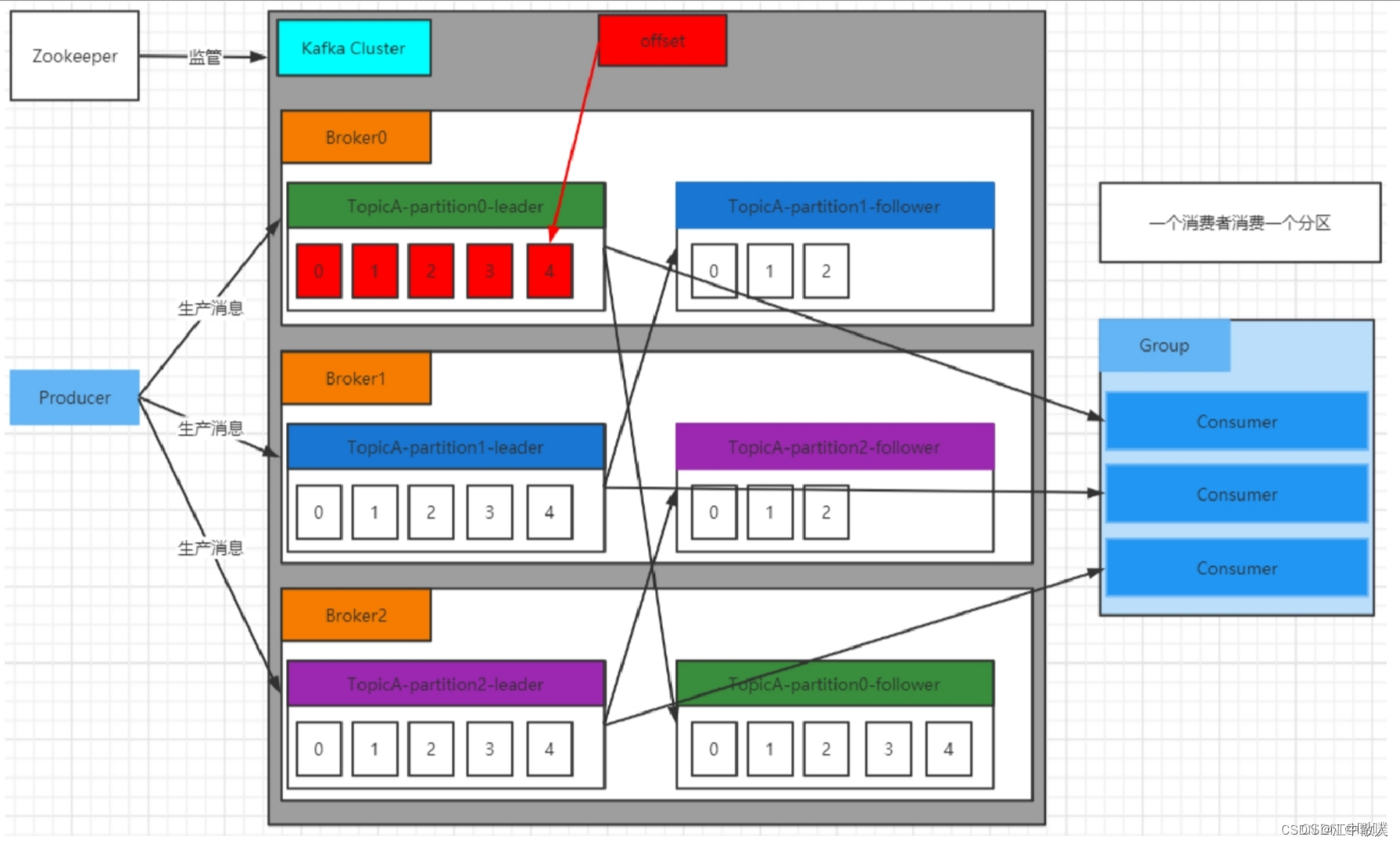
1.2 Механизм хранения
Поскольку сообщения, сгенерированные производителем, по-прежнему будут добавляться в конец файла журнала, чтобы файл журнала не был слишком большим и не приводил к неэффективности позиционирования данных, Kafka использует механизм фрагментации и индексирования. Он делит каждый раздел на несколько сегментов, и каждый сегмент соответствует двум файлам: индексному файлу «.index» и файлу данных «.log». Эту идею индексации стоит изучить и применять в повседневной разработке.
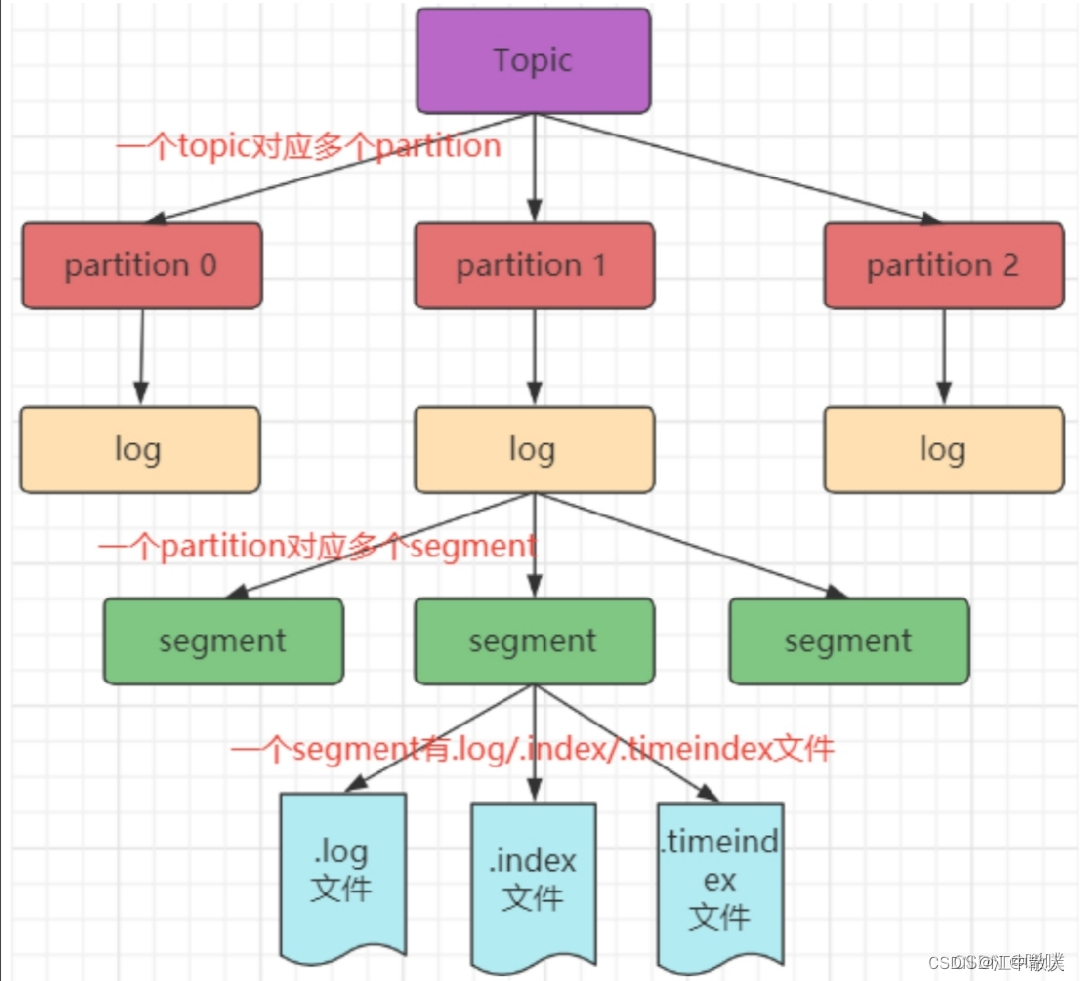
Эти файлы расположены в одном файле, а правило именования папки такое: имя темы-номер раздела. Например, если тематический тест имеет три раздела, соответствующие папки — test-0, test-1 и test-2.
$ ls /tmp/kafka-logs/test-1
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
leader-epoch-checkpointФайлы индекса и журнала называются по смещению первого сообщения текущего сегмента. На следующем рисунке показана структурная диаграмма индексного файла и файла журнала.
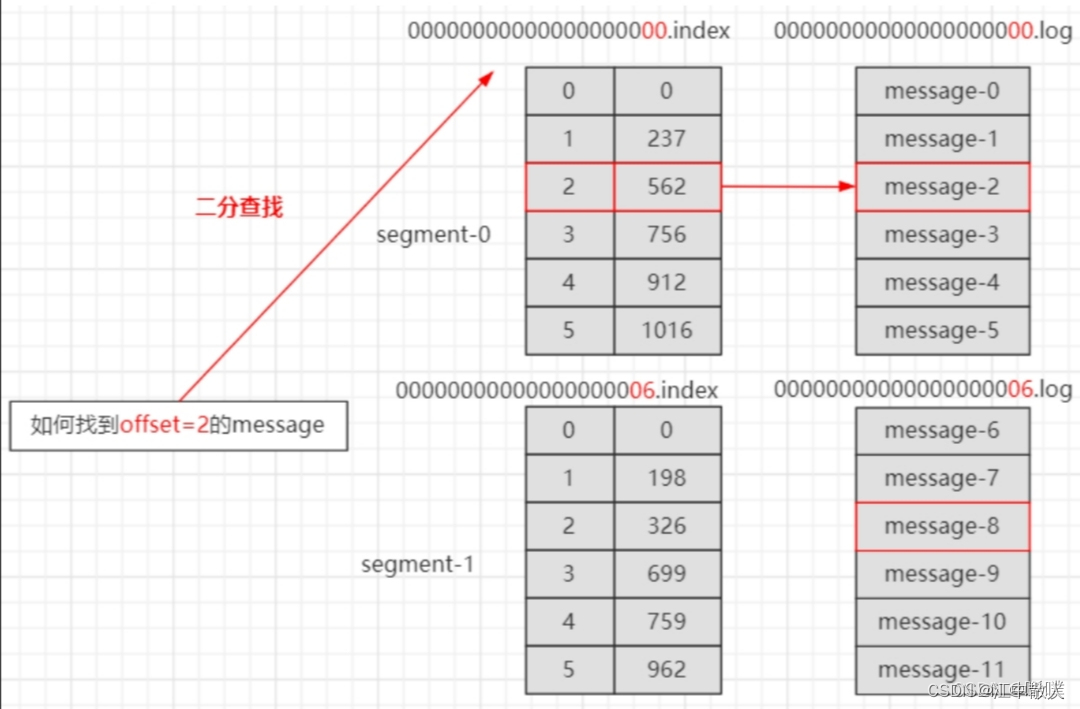
Файлы «.index» хранят большой объем индексной информации, а файлы «.log» хранят большой объем данных. Метаданные в индексном файле указывают на физическое смещение сообщения в соответствующем файле данных.
Используйте команду оболочки для просмотра индекса:
./kafka-dump-log.sh --files /tmp/kafka-logs/test-1/00000000000000000000.index1.3 Механизм разделения
Причина разделения:
- Чтобы облегчить расширение кластера, каждый раздел можно настроить в соответствии с машиной, на которой он расположен, а тема может состоять из нескольких разделов, поэтому ее можно читать и записывать в единицах разделов.
- Это может улучшить параллелизм и избежать конкуренции за ресурсы при сохранении двух разделов.
- Проблема с резервным копированием. Предотвратите проблему потери данных после выхода из строя машины.
Принцип секционирования: нам необходимо инкапсулировать данные, отправленные производителем, в объект ProducerRecord. Этот объект должен указать некоторые параметры:
- тема: строковый тип NotNull.
- раздел: тип int, необязательно.
- временная метка: длинный тип, необязательно.
- ключ: тип строки, необязательно.
- значение: тип строки, необязательно.
- заголовки: тип массива, Nullable.
Если указан раздел, данное значение напрямую используется в качестве значения раздела; если раздел не указан, но есть ключ, значение раздела получается путем взятия остатка хэш-значения ключа и количества имеющихся разделов; ни раздел, ни ключ В случае часто упоминаемого алгоритма опроса Round-Robin.
1.4 Продюсеры
Производитель — это точка входа данных. Производитель всегда ищет лидера при записи данных и не записывает данные напрямую ведомому. Диаграмма ниже очень хорошо иллюстрирует рабочий процесс продюсера. Полученная здесь информация о разделах получена от Zookeeper. Производитель не будет вызывать send() один раз для каждого сообщения, что слишком неэффективно. По умолчанию он будет вызывать send() один раз, когда данные сохраняются до 16 КБ или по истечении времени ожидания (например, 10 мс). Обратите внимание, что отправка сообщений здесь является асинхронной операцией.
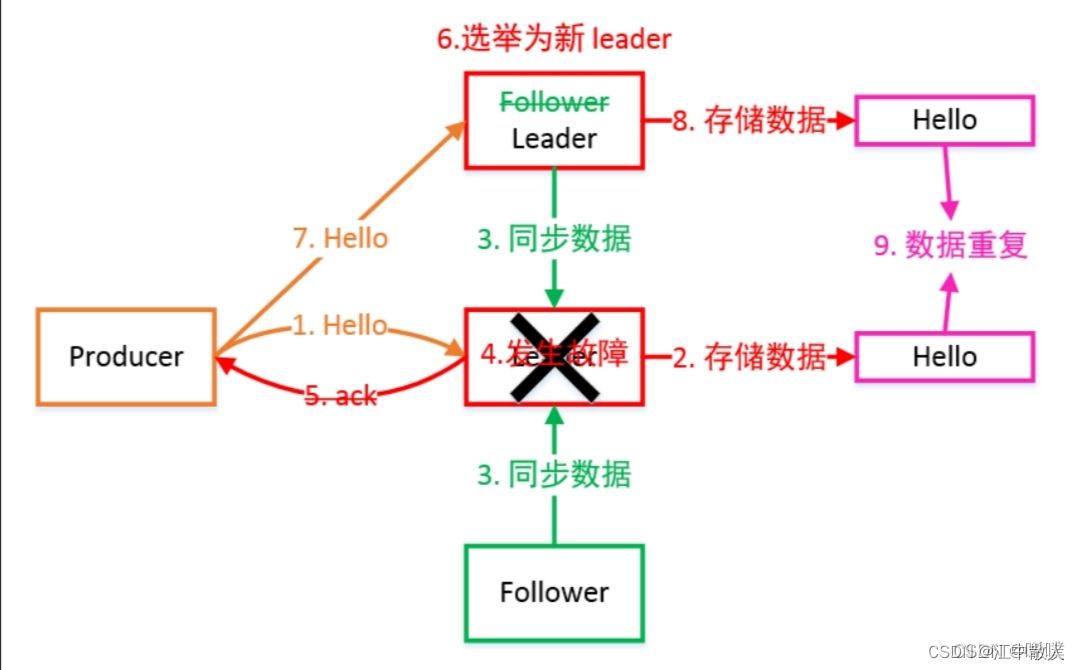
1,5 акк механизм
Производитель устанавливает request.required.acks=0; пока запрос отправлен, он считается отправленным, и его не волнует, была ли запись успешной или нет. Производительность очень хорошая. Если вы анализируете некоторые журналы, вы можете выдержать потерю данных. Используя этот параметр, производительность будет очень хорошей.
- request.required.acks=1; отправить сообщение в качестве лидера раздел записан успешно. Однако этот метод также имеет возможность потери данных.
- request.required.acks=-1; это сообщение нельзя считать успешно написанным, пока не будут записаны все копии в списке ISR.
Разработайте решение без потери данных: Решение без потери данных: 1) Копирование раздела. >=2 2)acks = -1 3)min.insync.replicas >=2。
Ниже представлена ситуация, когда в это время выходит из строя лидер. Видно, что данные в это время могут дублироваться.
... Объясните несколько существительных, которые встречаются выше. Лидер поддерживает динамический набор синхронизированных реплик (ISR): набор последователей, который синхронизируется с лидером. Когда ведомый элемент в наборе ISR завершит синхронизацию данных, ведущий отправит ACK ведомому. Если Фолловер не синхронизирует данные с Лидером в течение длительного времени, Фолловер будет исключен из набора ISR. Порог времени задается параметром Replica.lag.time.max.ms. После провала Лидера из ISR будет избран новый Лидер.
min.insync.replicas на сервере Kafka. Если мы его не установим, значение по умолчанию равно 1. Ведущий раздел будет поддерживать список ISR. Это значение ограничивает, по крайней мере, количество копий, которое должно быть в списке ISR. Например, если это значение равно 2, то при наличии только одной копии в списке ISR возникнет ошибка. сообщается при вставке данных в этот раздел.

1.6 Потребители
Потребитель использует режим Pull для чтения данных от брокера. Режим Pull может потреблять сообщения с соответствующей скоростью в зависимости от возможностей потребления Потребителя. Недостаток режима Pull заключается в том, что если у Kafka нет данных, потребитель может застрять в цикле и продолжать возвращать пустые данные. Поскольку потребитель активно получает данные от брокера, ему необходимо поддерживать длительный опрос. По этой причине потребители Kafka будут передавать тайм-аут параметра продолжительности при получении данных. Если в настоящее время нет доступных данных для потребления, Потребитель будет ждать некоторое время, прежде чем вернуться. Этот период времени является тайм-аутом.
1.6.1 Стратегия распределения разделов
В группе потребителей имеется несколько потребителей, а в теме имеется несколько разделов. Потребители в разных группах независимы друг от друга, и сотрудничать будут только потребители в одной группе. Это неизбежно потребует выделения разделов, то есть определения того, какой раздел каким потребителем потребляется.
У Кафки есть три стратегии распределения:
- RoundRobin
- Диапазон, по умолчанию — Диапазон.
- Sticky
Когда потребители в группе потребителей меняются, будет активирована стратегия распределения разделов (перераспределение методов). Прежде чем распределение будет завершено, Kafka приостановит внешние службы. Обратите внимание: чтобы обеспечить максимально упорядоченное выполнение сообщений, один раздел может соответствовать только одному потребителю, что также означает, что количество потребителей не может превышать количество разделов.
1.6.1.1 режим дальности
Метод Range разделен по темам и не вызовет проблемы путаницы при использовании метода опроса, но у него также есть недостатки.
Обратите внимание, что картинка и текст не совпадают. Рисунок является примером. Для понимания к тексту приведён ещё один пример. Предположим, у нас есть 10 разделов и 3 потребителя. Отсортированные разделы будут 0,1,2,3,4,5,6,7,8,9; отсортированный потребительский поток будет C1 -0,C2-0,C3-. 0. Затем разделите количество разделов на общее количество потоков-потребителей, чтобы определить, сколько разделов использует каждый поток-потребитель. Если его невозможно разделить, первые несколько потребительских потоков займут еще один раздел.
В нашем примере у нас есть 10 разделов и 3 потребительских потока, 10/3 = 3, и его нельзя разделить, тогда потребительский поток C1-0 будет потреблять еще один раздел: C1-0 будет потреблять разделы 0, 1, 2, 3; C2-0 будет использовать разделы 4,5,6; C3-0 будет использовать разделы 7,8,9.
... Предположим, у нас 11 разделов, тогда окончательный результат распределения разделов будет выглядеть так:
- C1-0 будет использовать разделы 0,1,2,3;
- C2-0 будет использовать разделы 4,5,6,7;
- C3-0 будет использовать разделы 8, 9 и 10.
Предположим, у нас есть 2 темы (T1 и T2), каждая по 10 разделов, тогда окончательный результат выделения разделов будет выглядеть так:
- C1-0 будет использовать разделы 0, 1, 2, 3 темы T1 и разделы 0, 1, 2, 3 темы T2.
- C2-0 будет использовать разделы 4,5,6 темы T1 и разделы 4,5,6 темы T2.
- C3-0 будет использовать разделы 7,8,9 темы T1 и разделы 7,8,9 темы T2.
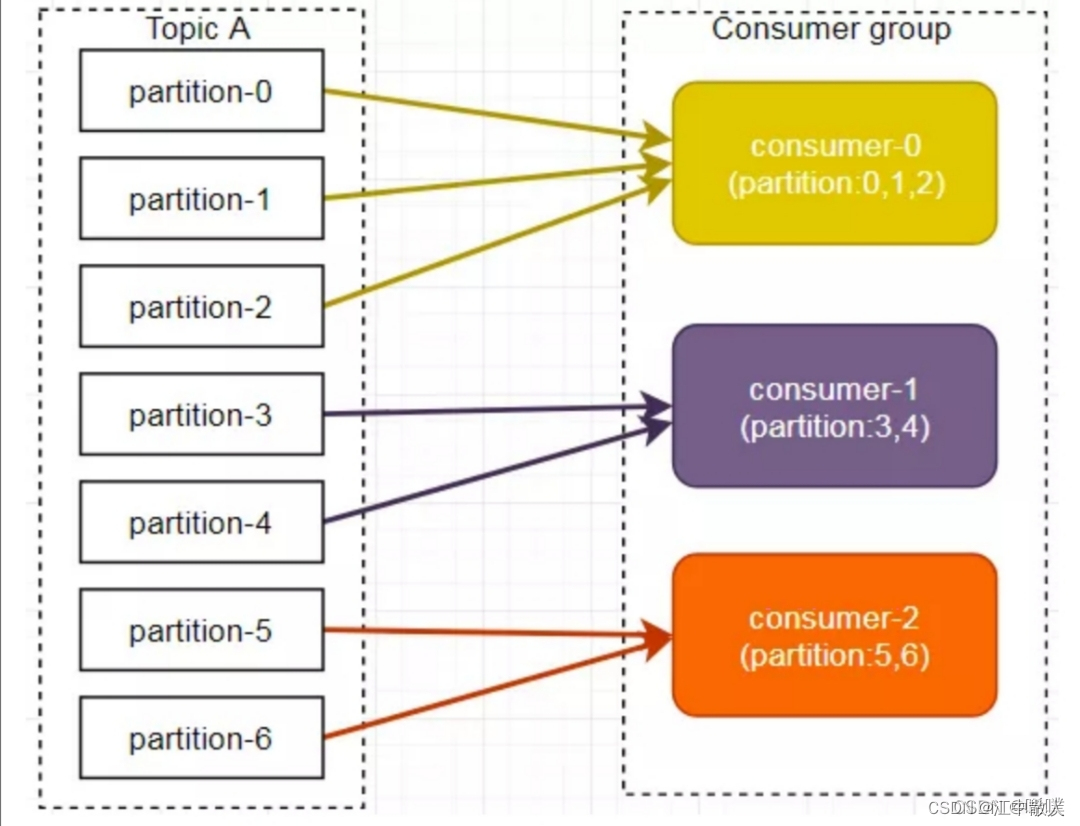
Видно, что потребительский поток C1-0 использует на 2 раздела больше, чем другие потребительские потоки. Это очевидный недостаток стратегии Range. Как показано на рисунке ниже, Consumer0 и Consumer1 одновременно подписываются на темы A и B, что может привести к неравномерному распределению сообщений. Если в группе потребителей подписано больше тем, распределение разделов может быть более несбалансированным.
1.6.1.2 RoundRobin
Метод опроса RoundRobin выполняет хэш-сортировку по всем разделам в целом. Максимальная разница в количестве разделов, выделенных внутри группы потребителей, равна 1. Она разделена по группам, что может решить проблему несбалансированных данных потребления нескольких потребителей.
Стратегия разделения по опросу состоит в том, чтобы составить список всех разделов и всех потребительских потоков, а затем отсортировать их по хеш-коду. Наконец, раздел выделяется потоку-потребителю посредством алгоритма опроса. Если подписки всех экземпляров-потребителей одинаковы, разделы будут распределены равномерно.
В приведенном выше примере, если согласно Группы тем-разделов, отсортированные по хэш-коду: T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9. потребительские потоки сортируются как C1-0, C1-1, C2-0, C2-1, а окончательный результат выделения раздела:
- C1-0 будет использовать разделы T1-5, T1-2 и T1-6;
- C1-1 будет использовать разделы T1-3, T1-1, T1-9;
- C2-0 будет использовать разделы T1-0 и T1-4;
- C2-1 будет использовать разделы T1-8, T1-7.
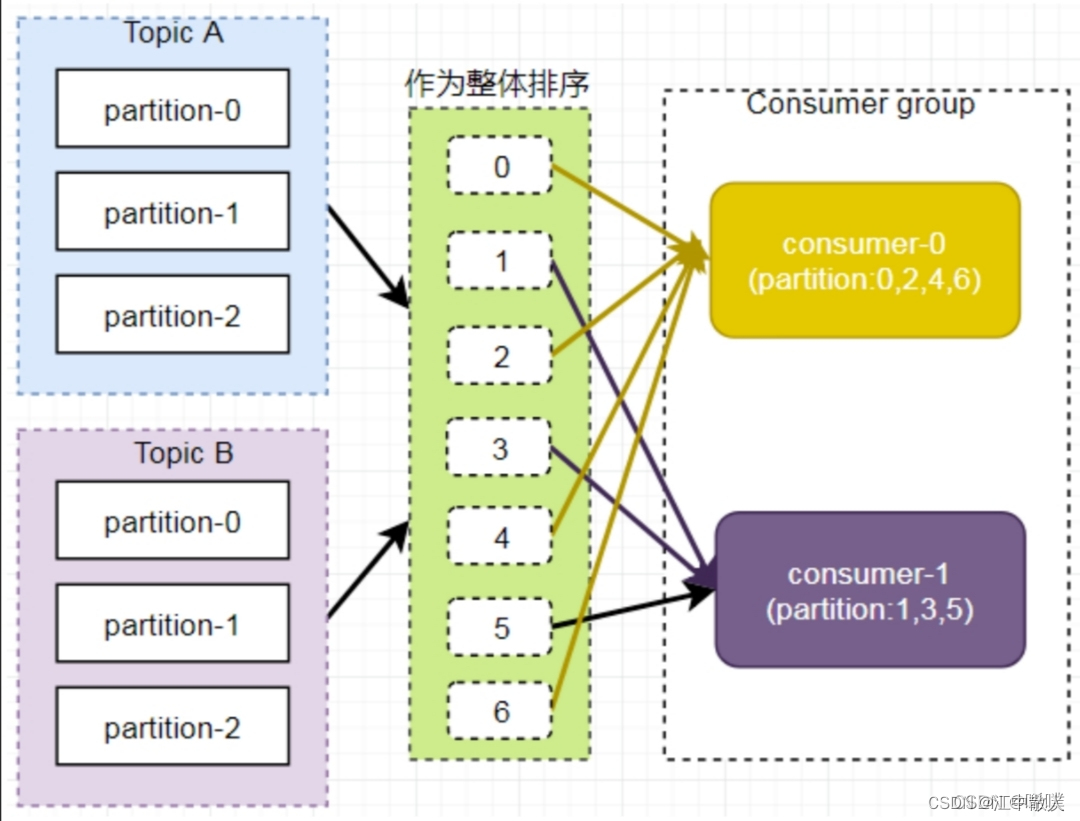
Картинка и текст не совпадают.
Однако, когда группа потребителей подписывается на разные темы, это может вызвать путаницу в потреблении. Как показано на рисунке ниже, Consumer0 подписывается на тему A, а Consumer1 подписывается на тему B.
Отсортируйте разделы тем A и B и назначьте их группам потребителей. Данные в разделе TopicB могут быть назначены Consumer0.
Таким образом, для использования стратегии разделения по опросу должны быть выполнены два условия:
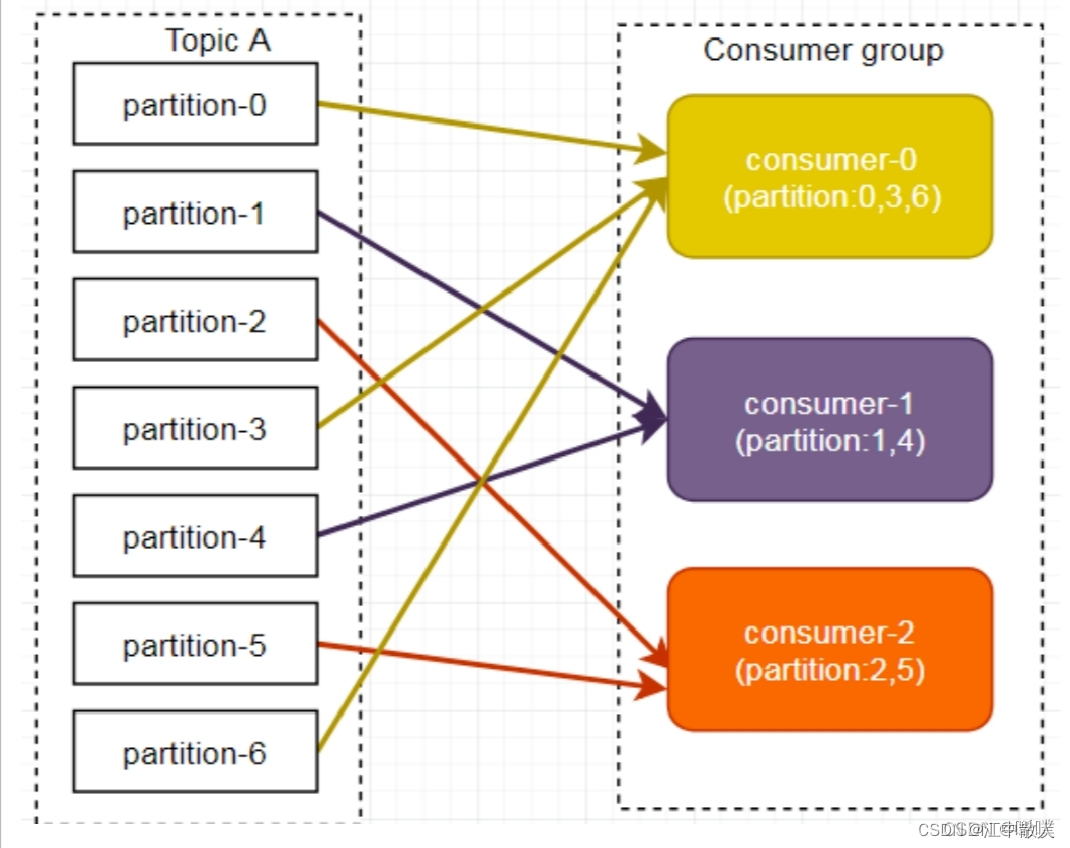
- Потребительские экземпляры каждой темы имеют одинаковое количество потоков;
- Каждый потребитель должен подписаться на одну и ту же тему.
Обратите внимание, что на самом деле для производителей вы можете настроить PUSH, но какие разделы также можно использовать.
1.6.1.3 Sticky
Первые два метода ребалансировки требуют переназначения, что является дорогостоящим, тем более что служба будет приостановлена на период ребалансировки, что требует, чтобы процесс был как можно более коротким. Sticky использует опрос, когда нет перебалансировки. Когда происходит перебалансировка, он пытается сохранить исходные отношения сопоставления, изменяет только сопоставление, связанное с простоем, и по-прежнему использует опрос.
1.6.2 Гарантия надежности
После того, как подтверждающее сообщение о гарантии достигает брокера, потребитель также должен иметь определенные гарантии, поскольку у потребителя также могут возникнуть некоторые проблемы, из-за которых сообщение не будет использовано.
Вот введение в офсет. Структура данных в памяти каждого потребителя хранит смещение потребления для каждого раздела каждой темы. После версии 0.9 отправленное смещение отправляется в дополнительную тему, созданную внутри Kafka: __consumer_offsets. Ключ — это group.id+topic+номер раздела, а значение — это значение текущего смещения. Время от времени Kafka сжимает (объединяет) эту тему внутри, то есть каждый group.id+topic+partition. номер сохранит последние данные.
Здесь представлен параметр Enable.auto.commit, значение по умолчанию — true, что означает автоматическую отправку смещений, которая выполняется пакетами и имеет временной интервал. Этот метод может вызвать проблемы с повторной отправкой или потерей сообщений. Поэтому необходимо отправлять данные вручную. использоваться для программ с высокими требованиями к надежности. Для приложений с высокими требованиями к надежности лучше использовать повторно, чем терять сообщения из-за ненормального потребления. Конечно, мы также можем использовать стратегии, позволяющие избежать повторного потребления и потери сообщений, например, используя транзакции для помещения смещения и выполнения сообщения в одну и ту же базу данных.
Наконец, давайте кратко представим приложение. Kafka можно использовать в распределенных очередях с задержкой. Создайте дополнительную тему и запланированный процесс, чтобы определить, истек ли срок действия каких-либо сообщений в этой теме. По истечении срока действия они будут помещены в обычную очередь сообщений. Потребитель будет получать сообщения из этой обычной очереди для использования.
1.7 Механизм ограничения квот Kafka (Квоты)
скорость Производство/потребление большого количества данных или запрос на высокой скорости,Таким образом занимая все ресурсы брокера,Вызвать перенасыщение сети ввода-вывода. Квоты позволяют избежать этих проблем. Kafka поддерживает управление квотами,Чтобы вы моглиProducerиConsumerизproduce&fetchДействуйте ограничения трафика,Не допускайте перегрузки сервера отдельными службами.
- Ограничение скорости по квоте
- Может ограничить скорость производителя и потребителя
- Не позволяйте Kafka работать слишком быстро и занимать все ресурсы ввода-вывода всего сервера (брокера)
1.7.1 Ограничение ставки на стороне производителя
Установите значения по умолчанию для всех идентификаторов клиентов. Следующее — установите TPS всех программ-производителей не выше 1 МБ/с, то есть 1048576/с. Команда выглядит следующим образом:
bin/kafka-configs.sh
--zookeeper bigdata-pro-m07:2181
--alter
--add-config 'producer_byte_rate=1048576'
--entity-type clients
--entity-defaultЗапустите тест и понаблюдайте за скоростью выдачи сообщений
bin/kafka-producer-perf-test.sh
--topic test
--num-records 500000
--throughput -1
--record-size 1000
--producer-props bootstrap.servers=bigdata-pro-m07:9092,bigdata-pro-m08:9092,bigdata-pro-m09:9092 acks=1результат:
50000 records sent, 1108.156028 records/sec (1.06 MB/sec)1.7.2 Ограничение ставки со стороны потребителя
Ограничение скорости для потребителей аналогично ограничениям для производителей, за исключением того, что имена параметров отличаются.
Для указанного ограничения скорости TOPIC для всех потребительских программ установлена скорость TOPIC всех потребительских программ, равная 1048576/с. Команда выглядит следующим образом:
bin/kafka-configs.sh
--zookeeper bigdata-pro-m07:2181
--alter
--add-config 'consumer_byte_rate=1048576'
--entity-type clients
--entity-defaultЗапустите тест:
bin/kafka-consumer-perf-test.sh
--broker-list bigdata-pro-m07:9092,bigdata-pro-m08:9092,bigdata-pro-m09:9092
--topic test
--fetch-size 1048576
--messages 500000Результат:
MB.sec:1.07431.7.3 Отмена конфигурации квоты Kafka
Используйте следующую команду, чтобы удалить конфигурацию квоты Kafka
bin/kafka-configs.sh
--zookeeper bigdata-pro-m07:2181
--alter
--delete-config 'producer_byte_rate'
--entity-type clients
--entity-default bin/kafka-configs.sh
--zookeeper bigdata-pro-m07:2181
--alter
--delete-config 'consumer_byte_rate'
--entity-type clients
--entity-defaultСправочная ссылка
KafkaСупер подробная лекция(один)_kafkaТонкий анализ_<один Жизнь в тумане и дожде>изблог-CSDNблог
Суперполная лекция Kafka (2)_Библиотека функций Kafka — блог CSDN
[Выбрано] Подробное объяснение основных принципов Kafka_Epiphyllum Блог Чжуюэ-CSDN Блог
Это самое подробное руководство по приложению Kafka — Nuggets
Kafka: вводное руководство по Kafka и использование клиента JAVA — блог CSDN
Простое руководство | Kafka от создания до использования — Чжиху
[Выбрано] Знакомство с блогом kafka_Xi Pu — блог CSDN
Краткий анализ архитектуры Kafka и основных принципов
Подробное объяснение кафки (1). Что такое кафка и как ее использовать.
Еще через полчаса вы поймете, как работает Кафка.
Подробное объяснение дизайна и принципов Kafka.
Кафка [Начало работы] Вот оно! - Чжиху
Введение в kafka_kafka_叏嗗-Альянс разработчиков облачных технологий Huawei
Изучение Kafka, очень подробное классическое руководство — блог CSDN



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
