Язык разработки больших данных Scala: зародился на Java, неявное преобразование мгновенно убивает Java
Предисловие
За многие годы обучения я также освоил несколько распространенных языков, таких как Java, Python и языки, входящие во фронтенд-экосистему Vue. Часто фреймворки со схожими функциями на разных языках сравниваются вместе, чтобы оценить достоинства самого языка.
В моем реальном учебном приложении я обнаружил, что у каждого языка есть свои подходящие поля. Например, Java имеет огромную и богатую серверную экосистему, поэтому ее часто используют для создания серверных служб. Python легок и прост в использовании и часто используется в таких сценариях, как анализ данных, поисковые роботы и машинное обучение. Кроме того, есть несколько нишевых языков, которые также блестят в своих областях.
До того, как я начал заниматься разработкой больших данных, я никогда не слышал о языке Scala. Позже, в области разработки в реальном времени Spark и Flink, среди официально предоставляемых Java, Python и scala особая симпатия у меня возникла к scala, как будто scala родилась для потоковой обработки данных.
Поэтому эта статья начнется с уникальных характеристик Scala в сочетании с некоторыми советами по разработке и объяснит, почему неизвестная Scala может конкурировать с Java в потоковой обработке.
неявное преобразование
Когда я впервые столкнулся с неявным преобразованием: «Что такое неявное преобразование?» Позже, изучив это, я понял: «Скрытое преобразование типов», поэтому начал с преобразования типов.
1. Неявное преобразование переменных
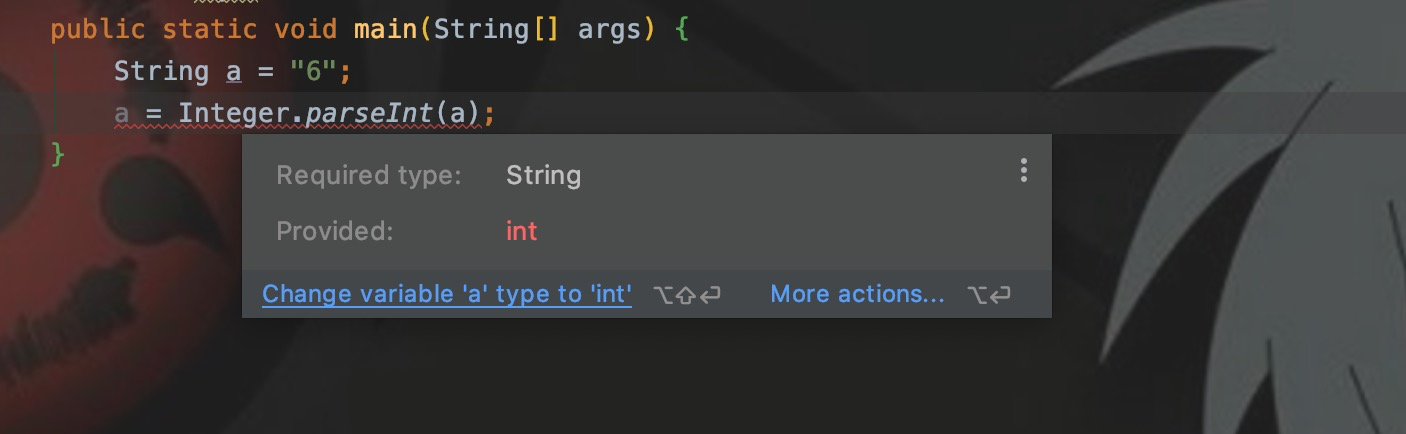
Предположим, я определяю строковую переменную a. Если a преобразуется в тип int, ее необходимо присвоить переменной. В Java мне нужно:
String a = "6";
int a_ = Integer.parseInt(a)В питоне мне нужно:
a = '6'
a = int(a)В двух вышеупомянутых языках есть что-то общее от строки до целого числа.,Это означает, что вам нужно вызывать методыпреобразование типов,А еще в Java нужно заново создать переменную типа int,чтобы получить конвертированную стоимость。
потому чтоPythonэтодинамически типизированный язык,Итак, в Python вы можете напрямую использовать переменную a,чтобы получить конвертированную стоимость,И вJavaдастатически типизированный язык,существовать Определить переменныечас,Тип переменной уже объявлен. Если вы напрямую присваиваете int переменной типа String,Во время проверки типа будет сообщено об ошибке.
scalaтакжеэтостатически типизированный язык,существоватьscalaХотяиспользоватьvalилиvarПриходить Определить переменные,Но на самом деле только тогда, когда переменная определена,Тип данных можно опустить,Затем компилятор Scala автоматически объявляет его. Итак, в приведенном выше примере,Ситуация аналогична для Scala и Java. Если вам нужно реализовать переменную, например Python,Два типа эффектов динамического типа,Затем посмотрите вниз:
var a: Int = "6"
a += 1
print(a)В приведенном выше коде я напрямую присваиваю значение типа String переменной типа int? ? ? Это более динамично, чем Python. Более того, scala наконец конвертируется в Java для запуска. Можно ли это сделать без ошибок?
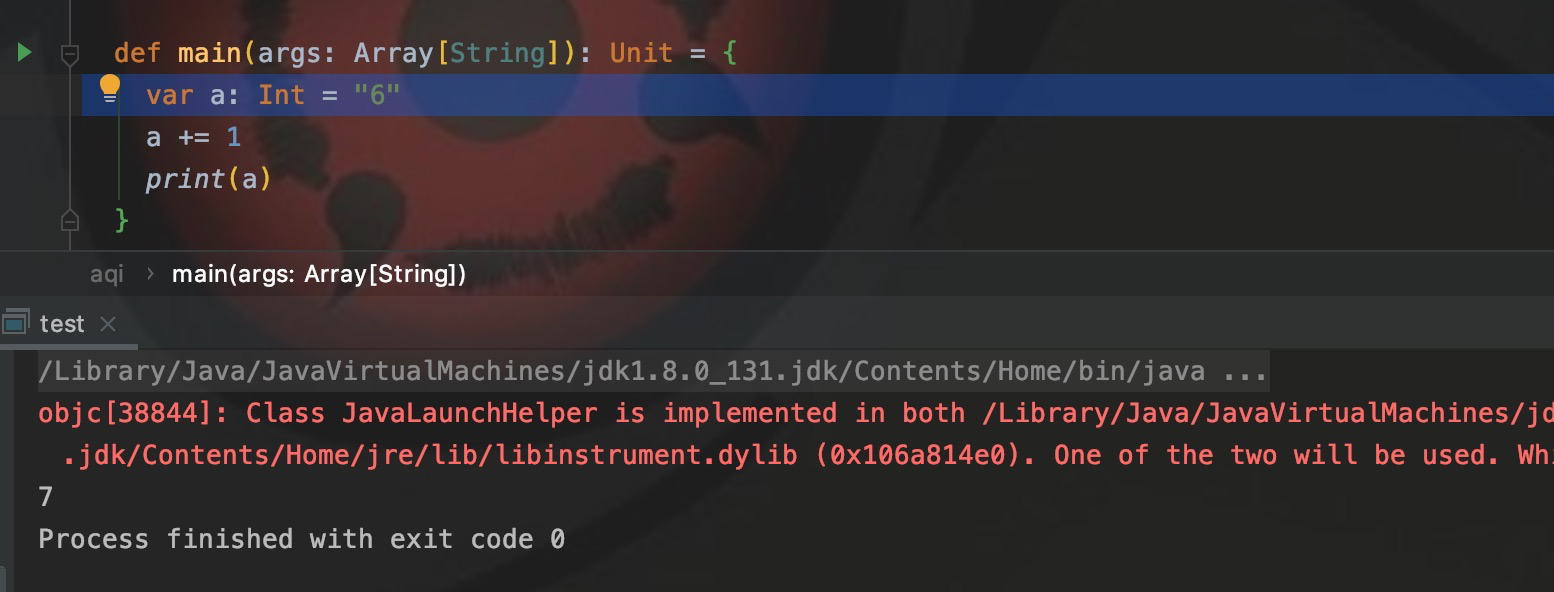
Никаких проблем при компиляции и никаких ошибок в работе нет.,Строковый тип 6 также стал типом int.,Конечный результат — 7. В обычных обстоятельствах,Он начинает сообщать об ошибках на этапе присвоения значений.,нода Понятноscalaизнеявное преобразование,Компилятор Scala автоматически преобразует его. В приведенном выше коде,Я определил неявный метод преобразования:
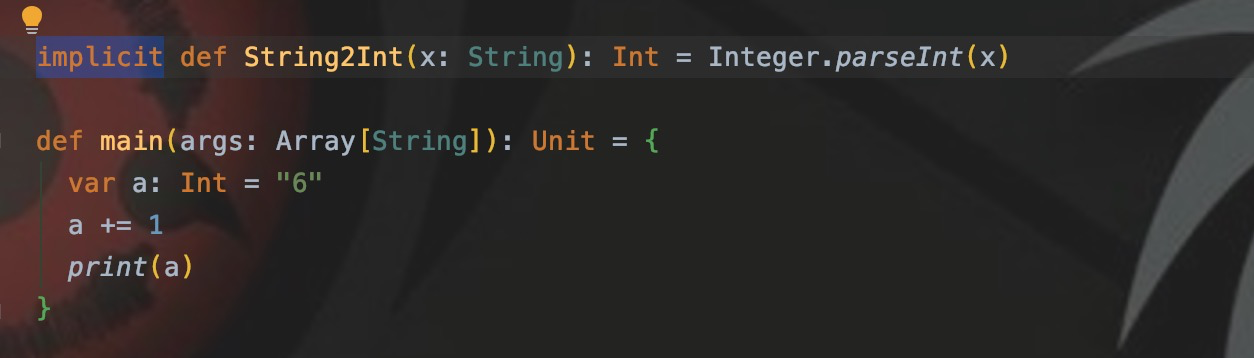
Используйте неявный тип для определения метода. Тип параметра метода — это тип данных, который нужно преобразовать, а возвращаемое значение метода — это тип целевой переменной, которую нужно назначить. Когда обнаруживается, что тип String должен быть присвоен переменной типа Int, будет вызвана эта неявная функция преобразования для преобразования типа String в int.
Если вы удалите этот метод неявного преобразования, будет сообщено об ошибке, как и в Java.
2. Неявные параметры метода
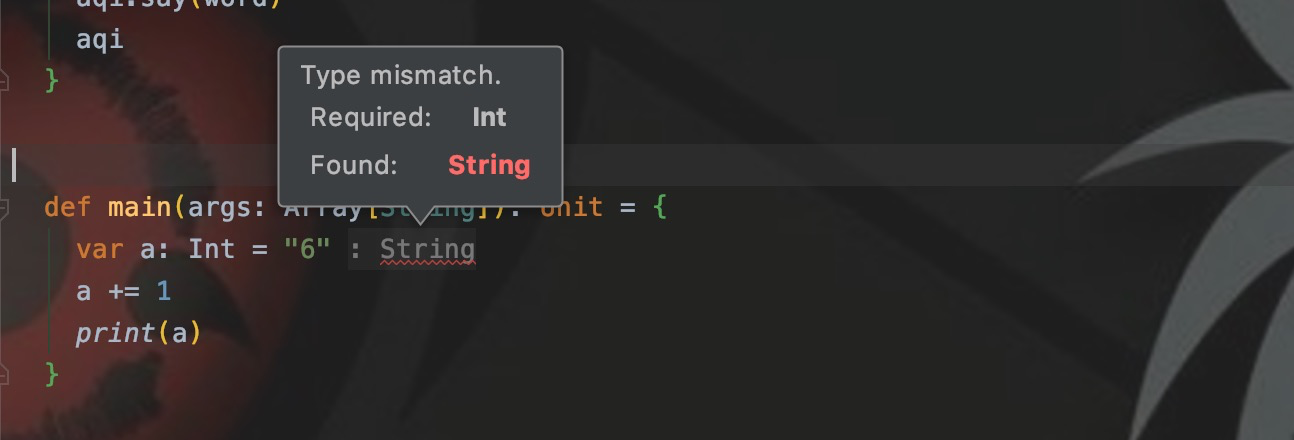
Неявные параметры используются при определении параметров метода.,используйте неявную модификацию перед формальным именем параметра. Затем при вызове этого метода,Если вы передадите параметры,Это обычный вызов метода. Если никакие параметры не передаются,автоматически найдетрядом、тот же тип、неявно измененныйпеременная,Он автоматически передается как параметр метода.
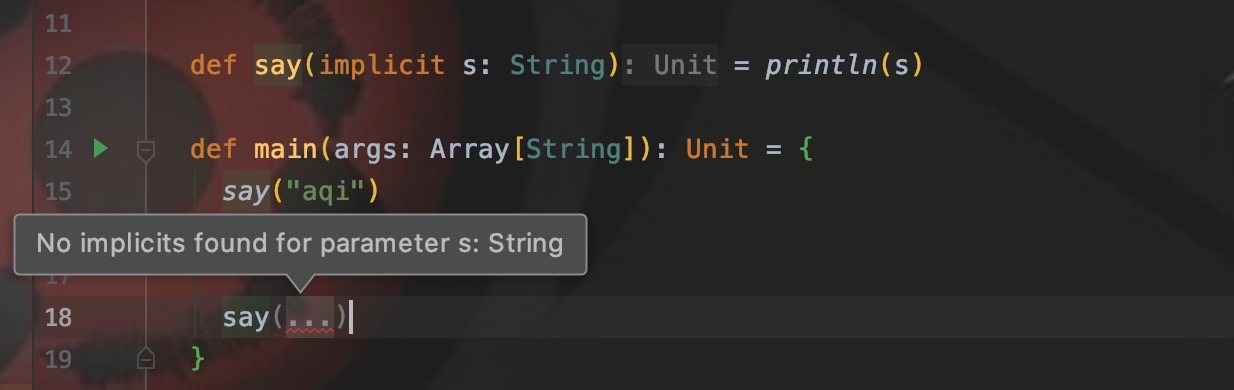
Как показано на рисунке: я определил метод Say с параметром типа String, который изменяется неявно. При вызове метода с использованиемsay("aqi") он выполняется нормально. Если я напишу Say напрямую, не добавляя круглые скобки и не передавая параметры, будет сообщено об ошибке.
Сообщение об ошибке означает: неявный параметр типа String не найден. Мы определяем неявную переменную как параметр непосредственно перед вызовом сказать.
def say(implicit s: String) = println(s)
implicit val a = "aqi aqi"
sayИспользуйте неявное использование для изменения переменной типа String a, напрямую используйте, скажем, для вызова метода, a будет автоматически передано в качестве параметра и, наконец, выведено нормально.
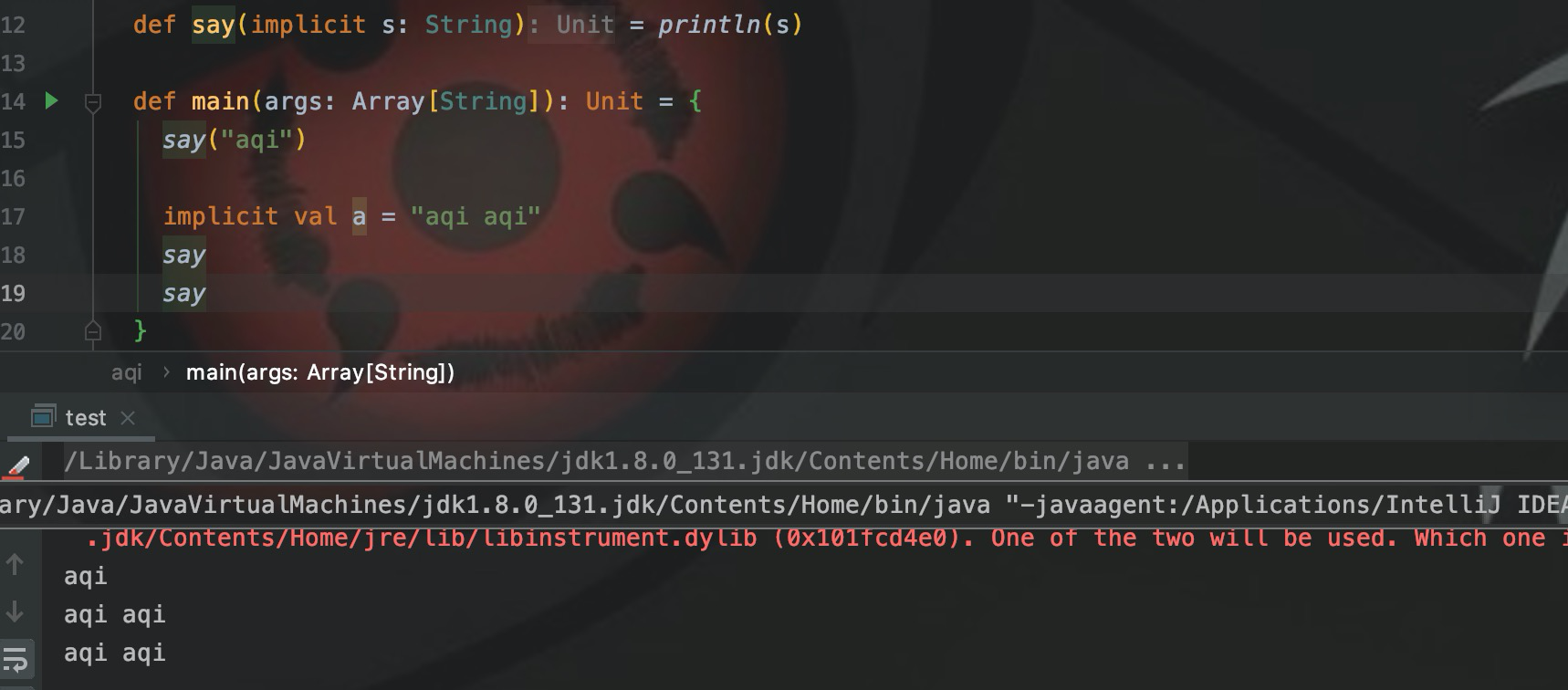
Как показано на рисунке, последний формальный параметр Say автоматически привязывается к неявно измененной переменной a и передается в функцию Say() для вывода результата.
scala
Теперь, когда закуска закончена, давайте начнем с простейшего синтаксиса Scala.
Определить переменные
Хотя Scala зависит от JDK,и может ссылаться на классы Java,Но помимо использования двойных кавычек для строк,Я считаю, что между Scala и Java не так уж много общего. Вот пример из scala Определить переменные:
var a = 1
val b = new util.HashMap[String, Int]val определяет константу, varОпределить переменные。aдаодинIntтип,b — это Java HashMap,Друзья, знакомые с Java, могут заметить: «После HashMap не хватает одной скобки!». В Скала,Если сипользовать конструктор без аргументов,Круглые скобки можно опустить.
определить функцию
scalaЗаброшенныйJavaЭтот видpublic static voidопределить функцию Способ,идаиPythonТакой жеиспользовать Ключевые словаdef。существовать На этой основе существует дальнейшееизоптимизация,Сразуда Возвращаемое значение не используетсяreturn。
val a = 1
def aqi() = {
a
}
print(aqi)Выходной результат равен 1, где a — возвращаемое значение функции aqi.
несколько параметров
Мало того, при определении функции я также могу помещать разные параметры в разные скобки:
def add(x:Int)(y: Int): Int = x + y
add(1)(2)Конечный результат вывода — 3. На этом этапе у вас могут возникнуть вопросы: какая польза от этих наворотов? Его чудесное применение будет обсуждаться позже в «Расширенном использовании».
Возьмите функцию в качестве параметра
В определениях методов в Scala помимо использования общих типов данных в качестве параметров вы также можете использовать функции в качестве параметров. Например, я определяю метод:
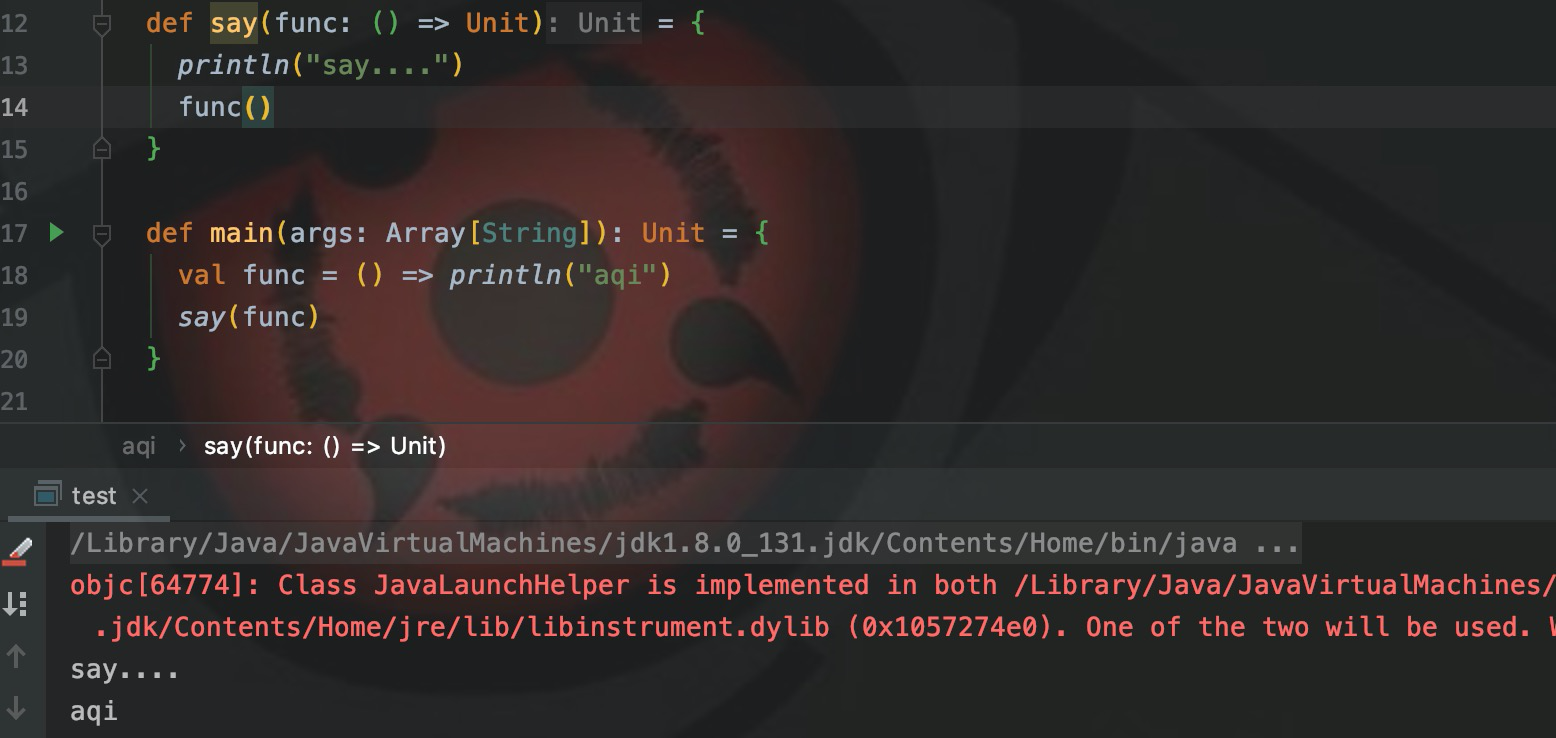
def say(func: () => Unit) = {
println("say....")
func()
}Определяя функциюsay(), определите формальный параметр func как функцию. Поэтому при вызове необходимо передать функцию. ,
val func = () => println("aqi")
say(func)Определите переменную функции func и передайте ее при вызове Say(). Результат работы:
Определить класс
В Scala существует три способа определения класса, а именно: класс, объект, регистр. Класс, класс и объект обычно определяются в исходном файле и имеют одно и то же имя. класс – Виды-компаньоны объекта, объект – Сопутствующий класса объект。эти концепциииз Вещи трудно произнести,Я также потратил много времени на понимание этой части. Не беспокойтесь об этом здесь,Запомните эти понятия непосредственно из их использования.
Виды-компаньоны
Определите класс:
class aqi {
def say(word: String) ={
print(word)
}
}Согласно использованию Java, если мы хотим вызвать функциюsay(), нам нужно сначала создать объект с помощью new aqi(), а затем вызвать метод с помощью .say(xxx).
val aqi = new aqi()
aqi.say("hello aqi")Наконец выведите hello aqi. Но извините, хотя вы и можете использовать его таким образом в Scala, не рекомендуется использовать его таким образом. Обычно объект используется для создания классов.
Сопутствующий объект
Мы создаем еще один объект с тем же именем в приведенном выше файле класса.
// Сопутствующий объект
object aqi {
def apply(word: String): aqi = {
val aqi_ = new aqi
aqi_.say(word)
aqi_
}
}существовать Сопутствующий объект Есть один вapplyфункция,это синтаксический сахар в Scala,Создать объект через объект,Фактически, apply() вызывается напрямую.
В качестве примера возьмем следующий код:
val aqi_ = aqi("hello aqi")Здесь нет нового перед аки,Таким образом, ссылка — это объект, а не класс.,Поскольку для применения требуется параметр String,Итак, передайте строку. Затем примените inusenew,Чтобы создать объект класса aqi из aqi,позвони, скажи(),и вернуть аки。
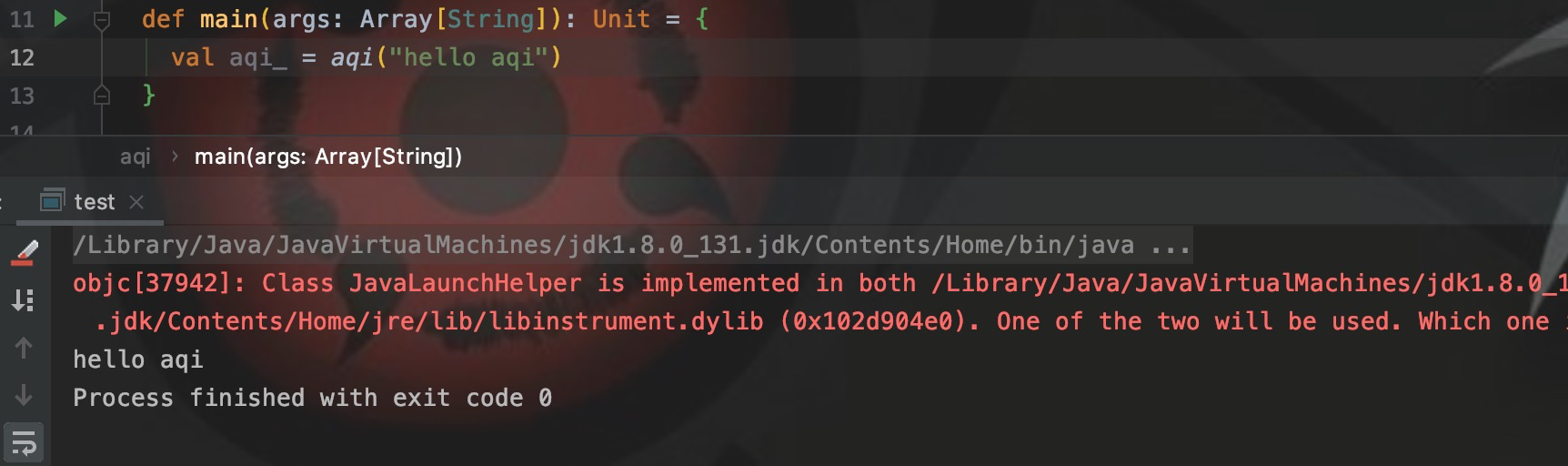
Как видно из приведенного выше примера,класс и объект взаимозависимы,Применение объекта должно возвращать объект,И класс используется приложением для создания объектов.,Эти два связаны,Также переводится по названию,такclassдаВиды-компаньоны,objectдаСопутствующий объект。
Кроме того, объект обеспечивает применение для создания объектов и отмену применения к объектам структуры. В то же время объект является синглтоном, и только объект имеет функцию main() для запуска приложения.
case class
И дело класс автоматически сгенерирует Сопутствующий объект, и понял.
case class Person(name:String, age:Int)После компиляции проверьте файл класса и Сопутствующий будет сгенерирован автоматически. объектMODULE$,И реализовали методы Apply, Unapply, Equals, Hashcode.,И реализовать интерфейс Serializable Java и интерфейс Product scala.
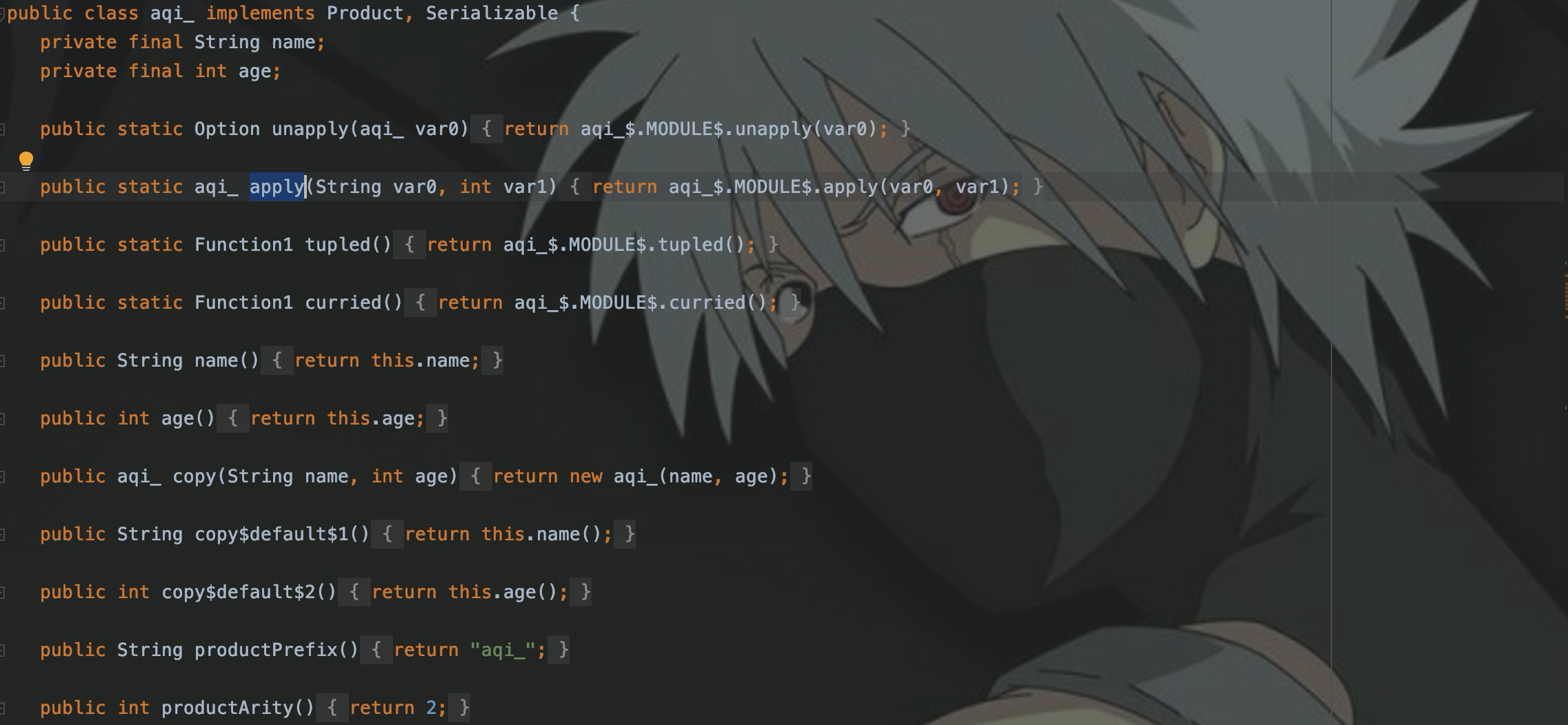
Класс Case обычно используется для определения классов сущностей при разработке Spark.
Расширенное использование
При чтении исходного кода Spark,Обнаружил много интересных применений Scala.,这里Сразу拿出其中具有代表性из Два варианта использования:Модели карринга и кредитования。
карри
Каррирование — это преобразование функции, которая изначально принимает два параметра, в,Процесс становления новой функции, принимающей один параметр. Как упоминалось в определении функции выше,Несколько формальных параметров функции,можно поместить в две скобки。
Давайте сначала разберемся в этой концепции на примере кода каррирования. Таким образом, процесс каррирования заключается в преобразовании
def func1(x: Int)(y: Int) = x + y
val func2 = func1(1)_Определите func1() с двумя списками параметров x и y, которые можно вызывать через func1(1)(2), и возвращаемым значением будет 3. Каррирование означает, что я сначала жестко закодирую один параметр func1, а затем использую заполнитель _ для представления другого параметра, что означает, что второй параметр не передается первым, а возвращаемое значение является значением функции, а затем присваивается func2, func2. Это становится функцией, которой нужно передать только один параметр.
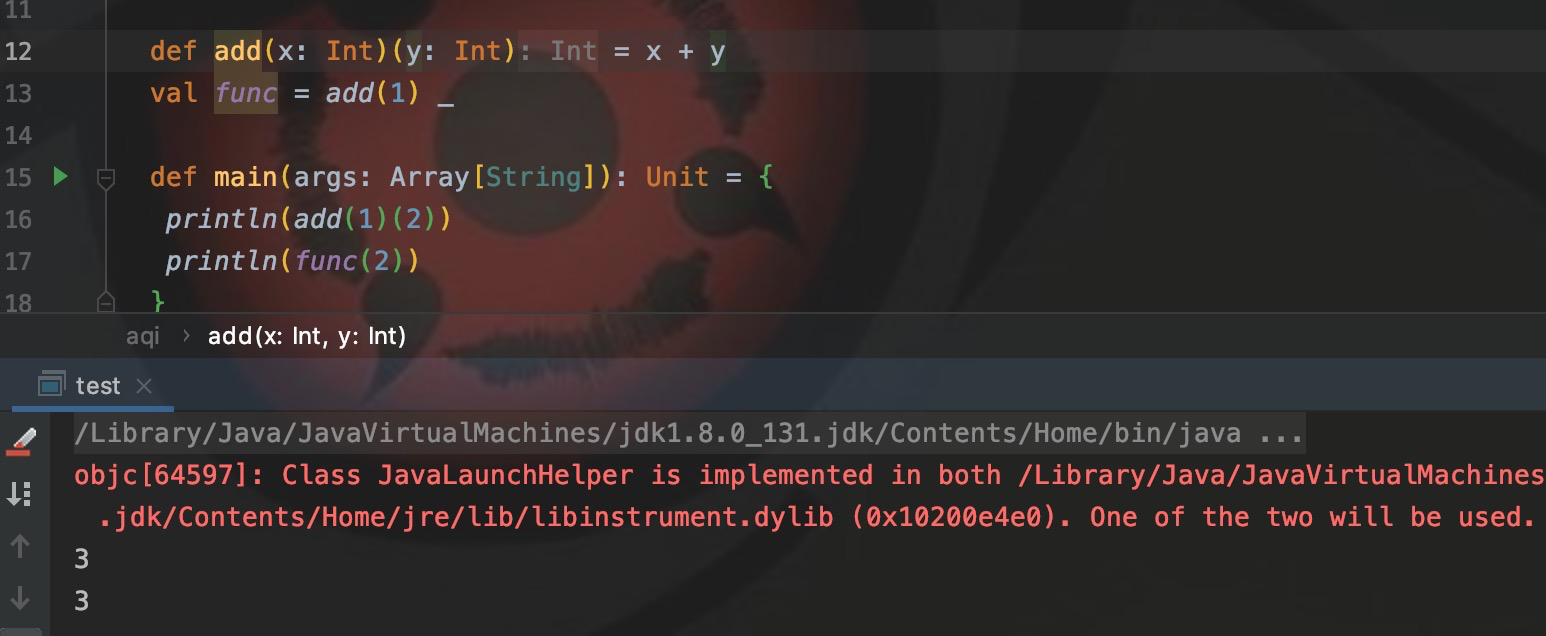
Как показано на рисунке, это результат выполнения приведенного выше каррированного кода.
схема кредита
Модель кредитования в основном предполагает приобретение, использование и высвобождение ресурсов и обычно применяется к процессу управления такими ресурсами, как файлы и соединения с базами данных. Мы определяем получение и закрытие соединения в методе. Формальный параметр в этом методе является функцией. В методе мы «одалживаем» полученное соединение и другие ресурсы функции формального параметра, а затем вызываем этот метод. . При передаче функции используйте для работы соединение непосредственно в теле функции.
Инициализация и закрытие соединения выполняются в методе достижения контроля над ресурсом. Если не поняли, посмотрите код:
def withFileReader[T](fileName: String)(func: BufferedReader => T): T = {
val fileReader = new BufferedReader(new FileReader(fileName))
try {
// Передача объекта Reader параметру func
func(fileReader)
} finally {
fileReader.close()
}
}
// Вызовите withFileReader, используйте режим кредита для чтения файла.
val result = withFileReader("aqi.txt") { reader =>
reader.readLine()
}Таким образом, в теле функции формального параметра, передаваемого при вызове withFileReader, мы можем использовать объект Reader, переданный в withFileReader, для чтения файла.
Путь разработки Scala
Как упоминалось в начале, Spark/Flink предоставляет три языка разработки: Java, Python и scala. В принципе, вы можете разрабатывать на любом языке, который вы знаете. Когда я только начал изучать Spark-разработку, я уже освоил Java и Python, но еще изучал Scala. Есть две причины:
- исходный код искры реализован в Scala
- scala соответствует конструкции потоковой обработки
Ниже приведены три фрагмента кода, предоставленные официальной документацией Spark. Эти три фрагмента кода выполняют одно и то же. Это коды для реализации вычислений SparkSQL из RDD в DataFrame. Нам не нужно понимать логику кода, а только сложность разработки и читаемость каждого кода.
Java-версия
Использование Java для разработки потоковой обработки требует большого количества кода, и каждая переменная должна четко объявлять свой тип данных.
/** Java Bean class for converting RDD to DataFrame */
public class JavaRow implements java.io.Serializable {
private String word;
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
}
...
/** DataFrame operations inside your streaming program */
JavaDStream<String> words = ...
words.foreachRDD((rdd, time) -> {
// Get the singleton instance of SparkSession
SparkSession spark = SparkSession.builder().config(rdd.sparkContext().getConf()).getOrCreate();
// Convert RDD[String] to RDD[case class] to DataFrame
JavaRDD<JavaRow> rowRDD = rdd.map(word -> {
JavaRow record = new JavaRow();
record.setWord(word);
return record;
});
DataFrame wordsDataFrame = spark.createDataFrame(rowRDD, JavaRow.class);
// Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words");
// Do word count on table using SQL and print it
DataFrame wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word");
wordCountsDataFrame.show();
});При преобразовании RDD в DataFrame Java также необходимо определить класс сущности.
Python
Python — это тип потоковой разработки, который я не рекомендую использовать без необходимости. Код Python в конечном итоге преобразуется в Java для запуска.
# Lazily instantiated global instance of SparkSession
def getSparkSessionInstance(sparkConf):
if ("sparkSessionSingletonInstance" not in globals()):
globals()["sparkSessionSingletonInstance"] = SparkSession \
.builder \
.config(conf=sparkConf) \
.getOrCreate()
return globals()["sparkSessionSingletonInstance"]
...
# DataFrame operations inside your streaming program
words = ... # DStream of strings
def process(time, rdd):
print("========= %s =========" % str(time))
try:
# Get the singleton instance of SparkSession
spark = getSparkSessionInstance(rdd.context.getConf())
# Convert RDD[String] to RDD[Row] to DataFrame
rowRdd = rdd.map(lambda w: Row(word=w))
wordsDataFrame = spark.createDataFrame(rowRdd)
# Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words")
# Do word count on table using SQL and print it
wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
except:
pass
words.foreachRDD(process)Объем кода гораздо меньше, но читаемость немного хуже.
scala
Последний — scala, я вам не скажу, вы сами видите!
/** DataFrame operations inside your streaming program */
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SparkSession
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}Общий код от простоты и читабельности,Гораздо больше, чем Java и Python. Хотя это статически типизированный язык, такой как Java.,Но при преобразовании RDD в DataFrame,Нет необходимости определять классы сущностей,ПрямойtoDFЗаканчивать。
Заключение
Это некоторые советы по разработке и интересные варианты использования, которые я лично суммировал при использовании Scala. В целом, Scala определенно превосходит Java и Python в области разработки обработки больших потоков данных. И хотя Scala опирается на Java, ее гибкость разработки и простота кода превосходят Java.
Поэтому scala действительно стоит изучения.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
