Я сказал интервьюеру, что объем данных одной таблицы MySQL не должен превышать 20 миллионов, но интервьюер этому не поверил.

👉Введение
Квалифицированному администратору базы данных, когда объем данных в одной онлайн-таблице превышает десятки миллионов, пользователям часто советуют уменьшить объем данных в одной таблице путем разделения таблиц. Когда пользователи спрашивают, почему объем данных в одной таблице. таблица не может превышать десятки миллионов, администраторы баз данных часто говорят, что если объем данных в одной таблице превышает десятки миллионов, это повлияет на производительность запросов. Зная это, но не зная почему, технология обучения не может оставаться на поверхности, а должна глубже вникать в принципы, чтобы мы могли продолжать прогрессировать и расти. Возвращаясь к вопросу: почему объем данных одной таблицы не может превышать 20 миллионов? Что является для этого основанием? Добро пожаловать к прочтению.
👉Содержание
1 Угол первичного ключа с автоприращением
2 Угол страницы данных
3 мысли
Вот что происходит:
Сяо Ван недавно принял участие в техническом интервью в Tencent. Интервьюер задал ему классический вопрос на собеседовании: Расскажите мне о вашей практике использования подбаз данных и подтаблиц в ваших ежедневных проектах? Поэтому Сяо Ван ответил, используя в качестве примера случай из прошлого проекта:
Проект, за который я отвечал, включал функцию хранения записей пользовательских операций. Поскольку объем данных каждый день был относительно большим, почти более 50 миллионов, я также выполнял отдельные операции с базой данных и таблицами. Система будет автоматически генерировать 3 таблицы через равные промежутки времени и хранить данные в них отдельно, чтобы предотвратить снижение производительности запросов из-за помещения их всех в одну таблицу.
Интервьюер снова спросил: Зачем нам нужно выполнять здесь операцию с подбазой данных и подтаблицей? Почему производительность запросов снизится, если их поместить в одну таблицу? Внутренняя ОС Сяо Вана: почему 1+1=2? Но он все равно ответил нормальным тоном:
По сути, в отрасли принято мнение, что одна таблица MySQL не должна превышать 20 миллионов строк. Только когда количество строк в одной таблице превышает 5 миллионов или емкость одной таблицы превышает 2 ГБ, мы обычно рекомендуем сегментировать базы данных и таблицы.
Интервьюер одобрительно кивнул, но не стал углубляться в этот вопрос. Затем он задал другие вопросы, и интервью вскоре закончилось. После того, как Сяо Ван пришел в себя и просмотрел процесс собеседования, он почувствовал, что не особенно хорошо ответил на вопрос о подбазе данных MySQL и подтаблице, поэтому он начал глубже вникать в этот вопрос «1+1=2».
01Автоматическое увеличение угла первичного ключа
Давайте сначала посмотрим, каково теоретическое максимальное значение объема данных в одной таблице?
Предположим, мы создаем таблицу, и ее идентификатор представляет собой автоматически увеличивающийся первичный ключ, а это означает, что размер первичного ключа может ограничивать верхний предел таблицы. Если первичный ключ объявлен как тип int, то максимальный тип int равен 2 в 32-й степени – 1, что составляет около 2,1 миллиарда;
Если первичный ключ объявлен как тип bigint, то максимальный тип bigint равен 2 в 64-й степени - 1. Это число слишком велико. Обычно диск не сможет поддерживать его до достижения этого предела;
Если первичный ключ объявлен как тип tinyint, то максимальный размер типа tinyint равен 2 в восьмой степени – 1, что равно 255, поэтому, если я вставлю фрагмент данных с ID=256, будет сообщено об ошибке;
Выше речь идет о теоретическом максимальном объеме данных одной таблицы с точки зрения автоматического увеличения первичных ключей. Далее давайте объясним с другой точки зрения «страницу данных», каков максимальный объем данных одной таблицы и что является основой. ?
02Угол страницы данных
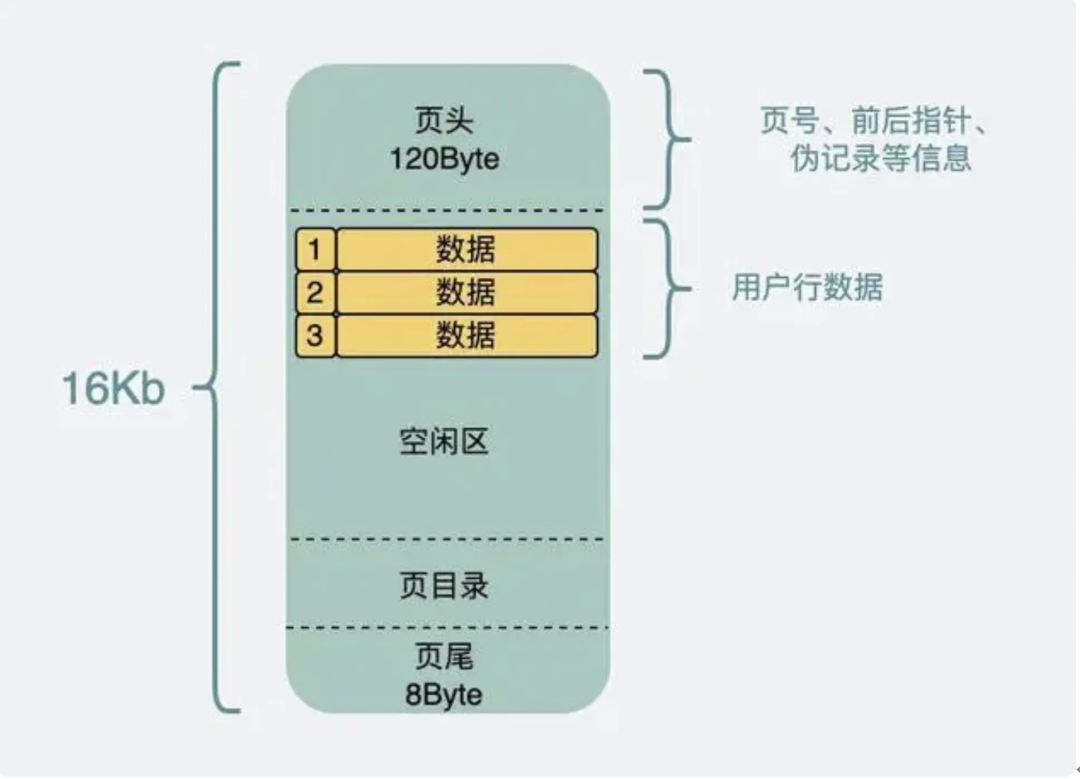
Предположим, у нас есть таблица пользователей, в которой ID является автоматически увеличивающимся первичным ключом, тогда таблица на жестком диске имеет имя user.ibd (файл данных innodb, также называемый файлом табличного пространства). Этот файл данных разделен на множество страниц данных, размер каждой страницы данных составляет 16 КБ.
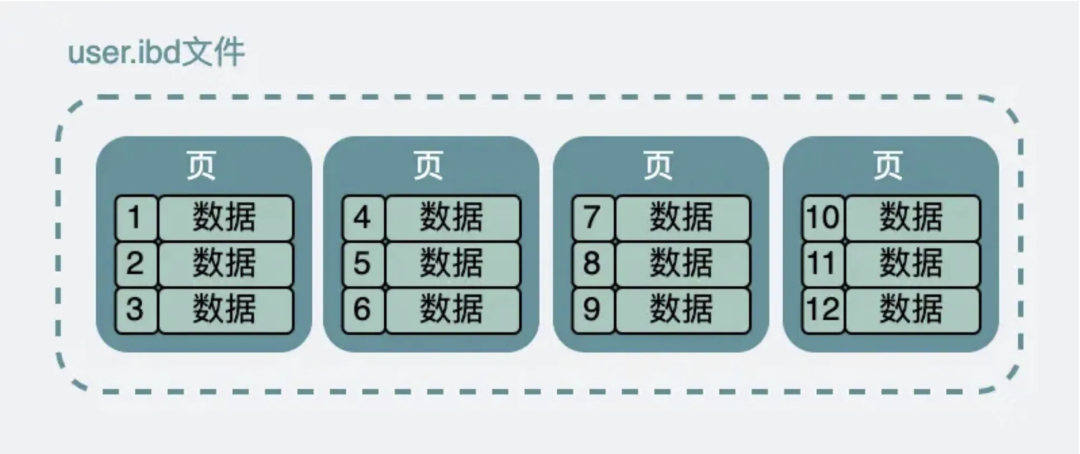
▶︎ Размер страницы данных составляет 16 КБ. В таблице много данных. Одна страница данных может не поместиться в такое количество данных, поэтому данные делятся на множество частей и хранятся на разных страницах данных, чтобы определить, какая именно страница данных. то есть для идентификации требуется номер страницы;
▶︎ В то же время, чтобы связать эти страницы данных, на которых хранятся данные, вводятся передние и задние указатели, указывающие на переднюю и заднюю страницы;
▶︎ Страница данных должна быть прочитана и записана. Во время процесса записи может произойти неожиданное отключение электроэнергии. Поэтому, чтобы гарантировать точность страницы данных, также вводится проверочный код;
▶︎ В то же время, чтобы повысить эффективность поиска данных на странице данных, внутри страницы данных также создается каталог страниц;
▶︎ Помимо вышесказанного, оставшееся место на странице данных используется для хранения фактических данных;
То есть структура страницы данных следующая:
Данные хранятся в виде страниц данных, а страницы данных связаны в виде деревьев B+, например:
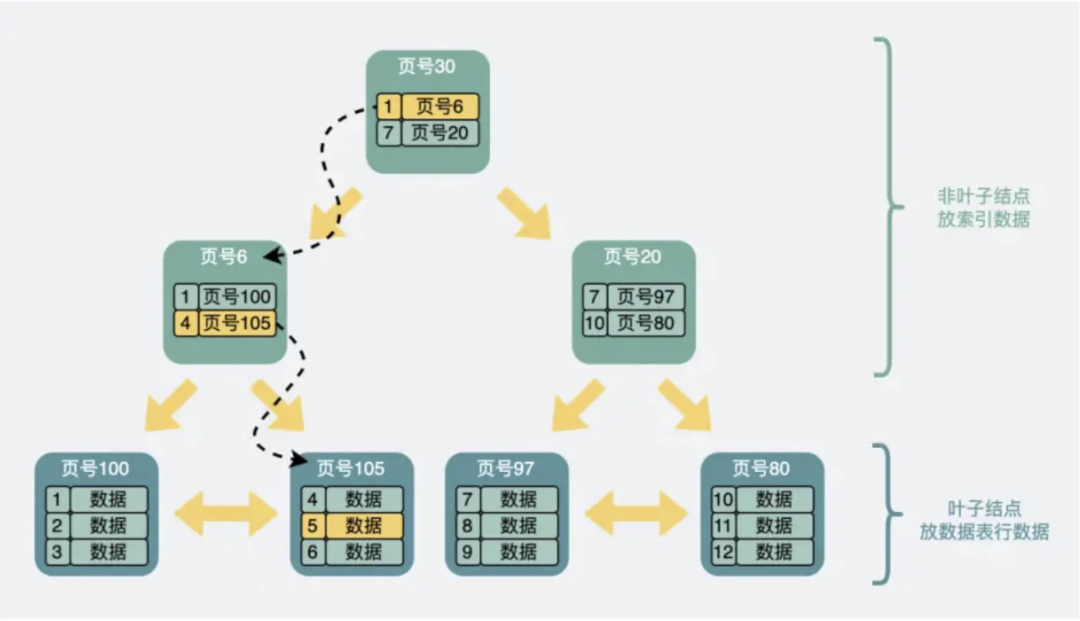
Среди них страницы данных конечных узлов хранят фактически сохраненные данные, а нелистовые узлы хранят содержимое индекса. Каждый уровень дерева B+ представляет собой дисковый ввод-вывод. Например, если я хочу найти запись с ID=5, я начну поиск с верхнего нелистового узла. Поскольку ID=5 больше 1 и меньше 7, мне следует искать влево и перейти к верхнему узлу. страница данных с номером страницы 6. Поскольку 5 больше 4, вам следует выполнить поиск вправо, перейти на страницу данных с номером страницы 105, найти запись с идентификатором = 5 и завершить запрос. В этом процессе запрашиваются три страницы данных. Если эти три страницы данных не загружены в память, потребуются три запроса ввода-вывода к диску.
Поняв, как дерево B+ хранит данные, мы можем начать оценивать данные.
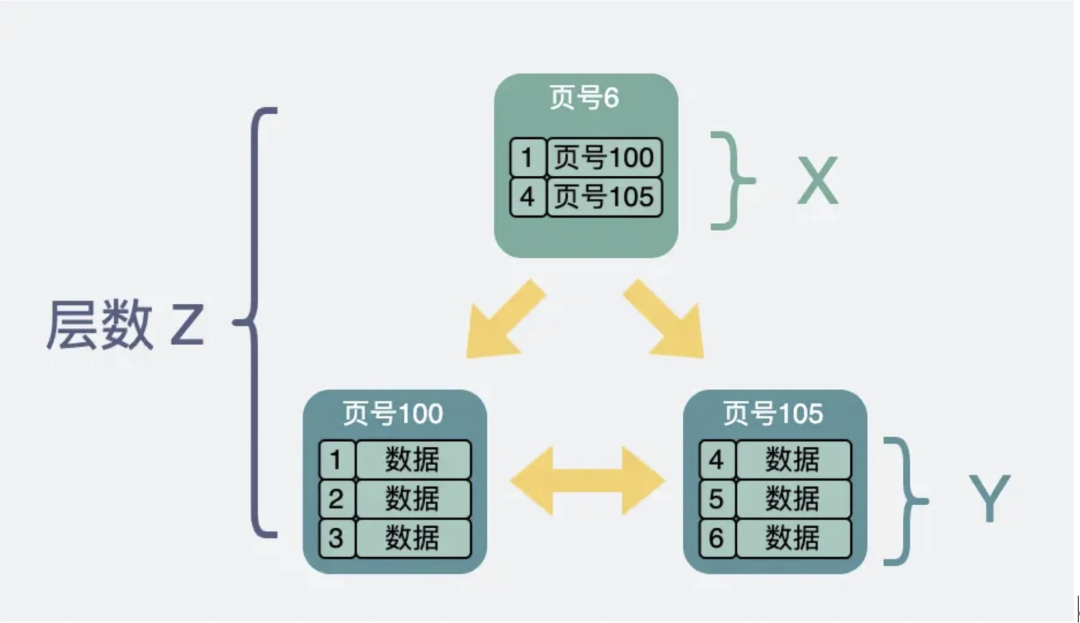
Предположим: количество указателей, указывающих на другие страницы данных в нелистовых узлах, равно X (то есть максимальное количество дочерних узлов нелистовых узлов равно B + количество слоев дерева);
Для дерева B+ высотой N, если на верхнем уровне (корневом узле) есть нелистовой узел, то есть X узлов на втором уровне, X 2 узлов на третьем уровне и X узлов на четвертом уровне. Кубические узлы и так далее, N-й уровень (то есть N-й уровень, на котором расположены листовые узлы) имеет X до N-1-го узла мощности в дереве B+, все записи хранятся в листовых узлах, предполагая; Число записей строк, которые может хранить каждый листовой узел, равно Y; Общий объем данных, который может хранить дерево B+, равен общему количеству конечных узлов, умноженному на количество записей, хранящихся в каждом листовом узле, то есть: M = (X в степени N-1), умноженное на Y; |
|---|
- Для дерева B+ высотой N, если на верхнем уровне (корневом узле) есть нелистовой узел, то есть X узлов на втором уровне, X 2 узлов на третьем уровне и X узлов на четвертом уровне. Кубические узлы и так далее, N-й уровень (то есть N-й уровень, где расположены листовые узлы) имеет X до N-1-го узла мощности;
- существовать B+ В дереве все записи находятся в конечных узлах, и каждый листовой узел может иметь определенное количество записей строк. Y;
- Так B+ В дереве можно хранитьизданные итоговые значения для общего числа конечных узлов, умноженного на количество записей на листовой узел хранилища, то есть: M = (X из N-1 мощность) раз Y;
Подставляем в расчет:
Размер страницы данных составляет 16 КБ. Если вычесть номер страницы, передний и задний указатели, каталог страницы, код проверки и другую информацию, фактический объем данных, которые можно сохранить, составит около 15 КБ, если предположить, что идентификатор первичного ключа имеет формат bigint. идентификатор первичного ключа занимает 8 байт, а номер страницы — 4 байта, тогда X=15*1024/(8 + 4) Равен 1280; фактический размер пространства, в котором страница данных может хранить данные, составляет около 15 КБ. Если предположить, что пространство, занимаемое записью строки, составляет 1 КБ, то страница данных может хранить 15 записей строки, то есть Y = 15; дерево B+ двухуровневое: Тогда N=2, т.е. M=1280 в степени (2-1) * 15 ≈ 2w. Предположим, что дерево B+ трехуровневое: Тогда N=3, т.е. M=1280 во 2-й степени * 15 ≈ 2,5 к Вт. Предположим, что дерево B+ четырехслойное: тогда N=4, т. е. M=1280 в 3-й степени * 15 ≈ 30 миллиардов; |
|---|
- Размер одной страницы данных 16 КБ.,Вычесть номер страницы, передний и задний указатель, оглавление страницы.,Проверьте код и другую информацию,На самом деле это может быть около 15 тыс.,гипотеза идентификатора первичного ключа для типа bigint,Такпервичный ключ ID Занимает 8 байт, номер страницы занимает 4 байт, тогда X=15*1024/(8 + 4) равно 1280;
- Сколько места на самом деле может иметь одна страница данных?,Около за15К,гипотеза Запись в одну строку занимает размер места для 1К,Так Одна страница данных может хранить 15 строк записей.,Это Y=15;
- гипотеза Дерево B+ является двухслойным: тогда N=2, то есть M=1280из(2-1)вторая власть * 15 ≈ 2w ;
- гипотеза Дерево B+ трехслойное: тогда N=3, то есть M=1280из2вторая власть * 15 ≈ 2.5 kw;
- гипотеза Дерево B+ состоит из четырех слоев: тогда N=4, то есть M=1280из3вторая власть * 15 ≈ 30 миллиардов ;
Подводя итог, мы рекомендуем, чтобы размер данных одной таблицы составлял 20 миллионов. Конечно, эти данные оцениваются на основе размера каждой записи строки, равного 1 КБ, что может не соответствовать этому значению в реальных ситуациях, поэтому предлагаемое значение в 20 миллионов — это всего лишь предложение, а не стандарт.
03 Мысли
И последний вопрос: 4-слойное дерево B+ с первичным ключом bigint и средней длиной записи 1 КБ. Сколько записей можно хранить без учета фрагментации?
Отвечать:
Формула расчета хранения данных по дереву B+: M = N-1 степень X*Y:
Размер страницы данных составляет 16 КБ. После вычета номера страницы, переднего и заднего указателей, каталога страницы, кода проверки и другой информации фактический размер данных, которые можно сохранить, составляет около 15 КБ. Если предположить, что идентификатор первичного ключа имеет тип bigint. тогда идентификатор первичного ключа занимает 8 байт, а номер страницы - 4 байта, тогда X=15*1024/(8 + 4) равно 1280;
Размер каждой записи составляет 1 КБ, а для хранения данных используется 15 КБ одной страницы данных, поэтому на одной странице данных может храниться 15 записей;
Количество всех листовых узлов — это степень N-1 числа .
Выше приведена вся информация об этой статье. Если она вам полезна, перешлите ее и поделитесь ею.
ты,учиться(устаревший)Это сделано?
-End-
Автор оригинала|Сяо Хаотэн



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
