Я использую ИИ каждый день, но до сих пор не знаю, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.
Предисловие
Функция потерь, несомненно, является основной функцией тестирования для машинного обучения и проверки эффекта глубокого обучения, используемой для оценки разницы между прогнозируемым значением модели и фактическим значением. Когда мы изучаем машинное обучение и глубокое обучение, мы более или менее подвержены функциям потерь, но нам не хватает подробной классификации функций потерь или систематического изучения различных применений функций потерь в разных алгоритмах и задачах. Следовательно, необходимо иметь относительно полное понимание всей системы функций потерь, чтобы мы могли иметь четкое представление о различных функциях потерь с разными функциями в будущем, и, как правило, интервью и написание статей в основном будут включать в себя многое из этого. знания. Таким образом, в этой статье мы объединим реальный код Python для реализации функции функции потерь и получим более глубокое понимание всей системы функций потерь.
В каждой статье я буду стараться изо всех сил упростить профессиональные знания, связанные с вертикальной областью, и превратить их в простые для понимания знания, которые могут быть прочитаны и поняты массами. Я разберу сложные этапы создания программ один за другим. и постепенно превращайте его из сложного в простое. Постепенно осваивая и практикуя, все учащиеся могут подписаться на блоггера, который продолжит создавать передовые статьи о практических технологиях.

1. Краткое описание генеративной модели.
Что касается генеративных моделей, когнитивные аспекты каждого человека представляют собой в основном модели языкового диалога, такие как ChatGPT или Вэнь Синьиян. Все эти модели представляют собой генеративный искусственный интеллект. Дискриминационный искусственный интеллект основан на «анализе-распознавании» и разработал ряд исследовательских приложений, таких как распознавание целей и классификационная регрессия, в то время как генеративный искусственный интеллект использует «реконструкцию и синтез» для генерации различных форм контента.
Генеративный ИИ — это технология искусственного интеллекта, которая может учиться на больших объемах данных и генерировать новые данные, аналогичные исходным. Генеративный ИИ обычно использует нейронные сети или другие алгоритмы машинного обучения для изучения закономерностей и закономерностей в данных и использования этих закономерностей и закономерностей для генерации новых данных.
В отличие от традиционных задач классификации или регрессии, цель генеративного ИИ — генерировать новые данные, а не классифицировать или регрессировать существующие данные. Здесь не будем подробно останавливаться на генеративном искусственном интеллекте. Важно понимать, что генеративная модель — это тип статистической модели, используемой для генерации новых выборок данных.
Их цель — создать новые выборки, похожие, но не идентичные обучающим данным, путем изучения распределения входных данных.

Общие генеративные модели включают:
- Вариационный автоэнкодер (VAE): VAE — это генеративная модель, которая сочетает в себе идеи автоэнкодеров и вариационного вывода, учится отображать входные данные в скрытое пространство и генерирует новые выборки посредством выборки.
- Генеративно-состязательная сеть (GAN): GAN состоит из двух частей: генератора и дискриминатора, которые борются друг с другом, чтобы выходные данные генератора могли максимально имитировать реальное распределение данных.
- Авторегрессионные модели: Модель этого типа предполагает, что характеристики каждого измерения зависят от характеристик предыдущего измерения. Типичным примером является модель генерации последовательности.
- Генеративная языковая модель искусственного интеллекта:Генеративная языковая модель искусственного интеллекта — это модель ИИ,Его основная функция — генерировать текст, аналогичный естественному языку человека. Эти модели могут адаптировать входной контекст или сигналы к,генерировать согласованность、естественный текстовый абзац、Предложение или фраза.
2. Обзор функции потерь генеративной модели
Поскольку между сгенерированным контентом и исходными данными существует разрыв, должен быть скаляр для измерения разрыва между ними. Функция потерь предназначена для измерения прямого разрыва между ними. Вообще говоря, функция потерь в основном выполняет четыре функции:
- Руководство по направлению обучения модели: Значение функции потерь сообщает алгоритму оптимизации, как обновить параметры модели, чтобы результаты прогнозирования модели были ближе к фактическим данным.
- Оцените производительность сгенерированной модели: Значение функции потерь сгенерированной модели можно использовать в качестве индикатора для оценки производительности модели. Обычно мы хотим, чтобы функция потерь была как можно меньшей, поскольку это означает, что результаты прогнозирования модели ближе к фактическим данным.
- Чтобы предотвратить переобучение: Выбирая соответствующие функции потерь и условия регуляризации, можно уменьшить степень подгонки модели к обучающим данным и улучшить способность модели к обобщению на невидимых данных.
- Оптимизация градиентного спуска: Градиент функции потерь является основой алгоритмов оптимизации (таких как стохастический градиентный спуск). Он определяет направление обновления и величину параметров, так что модель постепенно сходится к оптимальному решению.
Функция потерь генеративной модели в основном помогает модели изучить конфигурации параметров, подходящие для задачи, тем самым генерируя новые выборки, которые более соответствуют фактическому распределению данных. Выбор подходящей функции потерь является важным шагом в обучении высококачественных генеративных моделей.
3. Общие функции потерь генеративной модели
1. Потери вероятности отрицательного логарифма (потери NLL)
Отрицательная логарифмическая потеря правдоподобия (NLL Loss) — это функция потерь, обычно используемая при обучении вероятностных моделей, особенно в классификационных и генеративных моделях. Он измеряет разницу между прогнозируемым распределением вероятностей модели и фактическим распределением выборки.
В генеративных моделях, таких как вариационные автоэнкодеры (VAE) или генеративно-состязательные сети (GAN), потеря NLL обычно используется в качестве функции потерь для обучения. Это помогает модели научиться генерировать новые выборки, соответствующие фактическому распределению данных.
Предположим, у нас есть вероятностная модель, которая дает распределение вероятностей выборки, принадлежащей каждой категории, как $p(y|x)$, где y это метка категории, x Это образец.

import torch
import torch.nn as nn
# Предположим, что результат модели logits, фактические метки категорий targets
logits = torch.randn(3, 5) # 3 образца, 5 категорий
targets = torch.tensor([1, 0, 4]) # Фактические метки классов для трех образцов
# Вычислите отрицательную логарифмическую потерю правдоподобия, используя функцию перекрестной энтропийной потери
criterion = nn.CrossEntropyLoss()
nll_loss = criterion(logits, targets)
print("Отрицательная логарифмическая потеря правдоподобия:", nll_loss.item())Выходной результат отрицательная логарифмическая потеря правдоподобия: 2,210
2. Потери на реконструкцию
Потери при реконструкции относятся к мере способности модели восстанавливать входные данные в генеративной модели или автокодировщике. Он представляет собой ошибку, допущенную моделью, когда она кодирует входные данные в представление скрытого пространства, а затем декодирует их обратно в исходный вход.
В автоэнкодерах ошибка реконструкции обычно является важной частью процесса обучения. Цель автоэнкодера — минимизировать разницу между входными данными и восстановленными данными, чтобы изучить эффективное представление признаков.
Ошибка реконструкции может использоваться для обучения модели, позволяя модели уменьшить шум или ненужные детали, сохраняя при этом ключевую информацию. В целом способ расчета ошибки реконструкции зависит от используемой модели и задачи.
Для таких моделей, как вариационный автоэнкодер (VAE), ошибка реконструкции обычно измеряется потерей отрицательного логарифма правдоподобия.
В других генеративных моделях для измерения ошибки реконструкции могут использоваться различные функции потерь.
Способ его расчета зависит от используемой модели и задачи. На примере автоэнкодера ошибка его восстановления обычно выражается следующей формулой:

в,x_{i} это входные данные,\bar{x_{i}} да Модель Реконструированный выпуск,n это размер выборки. ||⋅|| здесь представляет собой некоторую меру расстояния, обычно евклидово расстояние или манхэттенское расстояние и т. д.
Мы можем использовать Pytorch для построения простой модели автокодировщика, а затем реализовать ошибку реконструкции:
import torch
import torch.nn as nn
# Определите простую модель автоэнкодера
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Linear(784, 128)
self.decoder = nn.Linear(128, 784)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# Инициализируйте модель и функцию потерь
model = Autoencoder()
criterion = nn.MSELoss()
# Предположим, что входные данные input_data
input_data = torch.randn(64, 784) # 64 образца, каждый образец имеет 784 измерения.
# Прямое распространение входных данных через автоэнкодер
output_data = model(input_data)
# Рассчитать ошибку реконструкции
reconstruction_loss = criterion(output_data, input_data)
print("Ошибка реконструкции:", reconstruction_loss.item())Ошибка реконструкции вывода результата: 1,120.
3.KLрасхождение(Расхождение Кульбака-Лейблера,KLD)
Дивергенция KL (дивергенция Кульбака-Лейблера, KLD), также известная как относительная энтропия, является индикатором в теории информации, используемым для измерения разницы между двумя распределениями вероятностей.
Конкретно,Это мера количества дополнительной информации, необходимой для представления одного распределения вероятностей вторым распределением вероятностей.。Предположим, что существуют два распределения вероятностейP(x) иQ(x) (x представляет собой случайную величину), которые соответственно описывают распределение вероятностей различных результатов наблюдения одного и того же события. Дивергенция KL определяется следующим образом:

Важные моменты:
- KL расхождениеда非对称的:D_{KL}(P||Q)!=D_{KL}(Q||P) Это означает использование Q оценить P KL-дивергенция P оценивать Q Дивергенция KL другая.
- KL расхождениенеотрицательный:D_{KL}(P||Q)≥0 , тогда и только тогда, когда P и Q При полном равенстве дивергенция KL равна нулю.
- KL Чем больше значение расхождения, тем больше разница между двумя распределениями.
- Расчет дивергенции KL обычно требует обеспечения того, чтобы знаменатель Q (x) не был равен нулю, чтобы избежать численной нестабильности.
Дивергенция KL имеет важные применения во многих областях, в том числе:
- Теория информации: Мера количества дополнительной информации, необходимой для представления одного распределения вероятностей другим распределением.
- Машинное обучение: В генеративных моделях - мера разницы между выходным распределением генеративной модели и истинным распределением.
- Проблема оптимизации: Дивергенция KL часто используется как часть целевой функции в таких задачах, как оценка максимального правдоподобия.
В генеративных моделях, особенно в таких моделях, как вариационный автоэнкодер (VAE), дивергенция KL (дивергенция Кульбака-Лейблера, KLD) часто используется для измерения разницы между двумя распределениями вероятностей. В Python для расчета расхождения KL можно использовать платформы глубокого обучения, такие как PyTorch.
import torch
import torch.nn.functional as F
def kl_divergence(mu_q, logvar_q, mu_p, logvar_p):
# Рассчитать дивергенцию KL
kl_div = -0.5 * torch.sum(1 + logvar_q - logvar_p - (logvar_q.exp() + (mu_q - mu_p).pow(2)) / logvar_p.exp(), dim=1)
return kl_div.mean()
# Предположим, что существуют два параметра нормального распределения
mu_q = torch.randn(64, 10) # иметь в виду
logvar_q = torch.randn(64, 10) # Логарифмическая дисперсия
mu_p = torch.randn(64, 10) # иметь в виду
logvar_p = torch.randn(64, 10) # Логарифмическая дисперсия
# Рассчитать дивергенцию KL
kl_loss = kl_divergence(mu_q, logvar_q, mu_p, logvar_p)
print("Расхождение KL:", kl_loss.item())Выходной результат: расхождение KL: 23,193.
4. Состязательный проигрыш
Состязательные потери — это функция потерь, используемая для обучения генеративно-состязательных сетей (GAN). Он играет жизненно важную роль в модели GAN. В GAN он обычно включает в себя два основных компонента:
- Генератор: Он пытается создать поддельные образцы данных, похожие на реальные образцы данных.
- Дискриминатор: Он пытается отличить реальные образцы данных от поддельных образцов данных, сгенерированных генератором.
Основная идея состязательных потерь состоит в том, чтобы заставить генератор генерировать реалистичные образцы путем состязательного обучения генератора и дискриминатора. В частности, состязательный проигрыш состоит из двух частей:
- Потери генератора: Цель этой части — заставить дискриминатор принять выборки, сгенерированные генератором, за реальные данные.
- Потеря дискриминатора: Цель этой части — точно отличить настоящие данные от поддельных.
Математически потери противника можно выразить как:
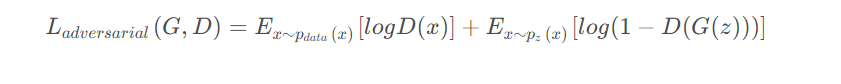
в,G это генератор,D является дискриминатором,p_{data}(x) это распределение реальных данных,p_{z}(z) вход генератора z предварительное распределение.
Целью состязательных потерь является минимизацияL_{adversarial} , так что выборки, сгенерированные генератором, могут обмануть дискриминатор и в то же время заставить дискриминатор более точно различать настоящие и ложные выборки. Посредством состязательного обучения генератор и дискриминатор конкурируют друг с другом, что в конечном итоге позволяет генератору генерировать реалистичные образцы. Состязательные потери являются очень важной частью обучения модели GAN. Они позволяют генератору постепенно улучшать качество генерируемых выборок, тем самым достигая цели создания реальных выборок.
Сначала мы определяем простой генератор и дискриминатор, а затем инициализируем их и функцию состязательных потерь (двоичная кросс-энтропийная потеря). Далее, предполагая, что генератор сгенерировал поддельные образцы, а реальные образцы готовы, мы рассчитали выходные данные генератора и дискриминатора, а затем вычислили состязательные потери, используя двоичную кросс-энтропийную потерю. Наконец, во время обратного распространения ошибки общие состязательные потери можно использовать для обновления параметров генератора и дискриминатора.
import torch
import torch.nn as nn
# Определить простой генератор и дискриминатор
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.fc = nn.Linear(100, 784) # Предположим, что входной размер равен 100, а выходной размер — 784 (28x28).
def forward(self, x):
return torch.sigmoid(self.fc(x))
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.fc = nn.Linear(784, 1) # Предположим, что входная размерность равна 784, а выходная размерность равна 1.
def forward(self, x):
return torch.sigmoid(self.fc(x))
# Инициализируйте генератор и дискриминатор
generator = Generator()
discriminator = Discriminator()
# Определите функцию состязательных потерь (двоичная кросс-энтропийная потеря)
adversarial_loss = nn.BCELoss()
# Предположим, что сэмплы, сгенерированные генератором, — это fake_samples, а настоящие семплы — это real_samples.
fake_samples = torch.randn(64, 100) # Предположим, что размер пакета равен 64, а входное измерение равно 100.
real_samples = torch.randn(64, 784) # Предположим, что размер пакета равен 64, а входное измерение равно 784.
# выход генератора
generated_samples = generator(fake_samples)
# Прогнозирование дискриминатором сгенерированных и реальных образцов
discriminator_output_fake = discriminator(generated_samples)
discriminator_output_real = discriminator(real_samples)
# Рассчитать потери противника
loss_fake = adversarial_loss(discriminator_output_fake, torch.zeros_like(discriminator_output_fake))
loss_real = adversarial_loss(discriminator_output_real, torch.ones_like(discriminator_output_real))
# полный проигрыш против
total_adversarial_loss = loss_fake + loss_real
# Значение выходных потерь
print("полный проигрыш против:", total_adversarial_loss.item())полный проигрыш против: 1.528Пожалуйста, обратите внимание, чтобы оно не потерялось. Если есть какие-либо ошибки, пожалуйста, оставьте сообщение для получения совета. Большое спасибо.
Это все по этому вопросу. Я застрял. Если у вас есть вопросы, оставьте сообщение для обсуждения. Увидимся в следующем выпуске.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
