Извлечение вокала из аудио: краткое руководство
В современную эпоху развития технологий применение искусственного интеллекта (ИИ) в обработке мультимедиа стало более обширным и сложным. В частности, технология точного извлечения фрагментов человеческой речи из различных фоновых шумов стала горячей точкой исследований в области интеллектуального аудиоанализа. В этой статье мы углубимся в то, как использовать усовершенствованную модель детектора голосовой активности Silero (VAD) для достижения цели получения четких голосовых сегментов из аудиофайлов, а затем раскроем огромный потенциал этой технологии в практическом применении.
Обзор Silero VAD
Silero VAD — это предварительно обученный детектор голосовой активности корпоративного уровня, известный своей исключительной точностью, возможностями высокоскоростной обработки, легкой архитектурой, а также высокой степенью универсальности и портативности. Эта модель, основанная на глубоком обучении, продемонстрировала впечатляющую производительность в идентификации звука из разных фоновых шумов, разных языков и разных уровней качества.
Основные особенности
- Превосходная точность: Silero VAD достигает выдающихся результатов в задачах обнаружения речи, демонстрируя свою способность обрабатывать сложные аудиоданные.
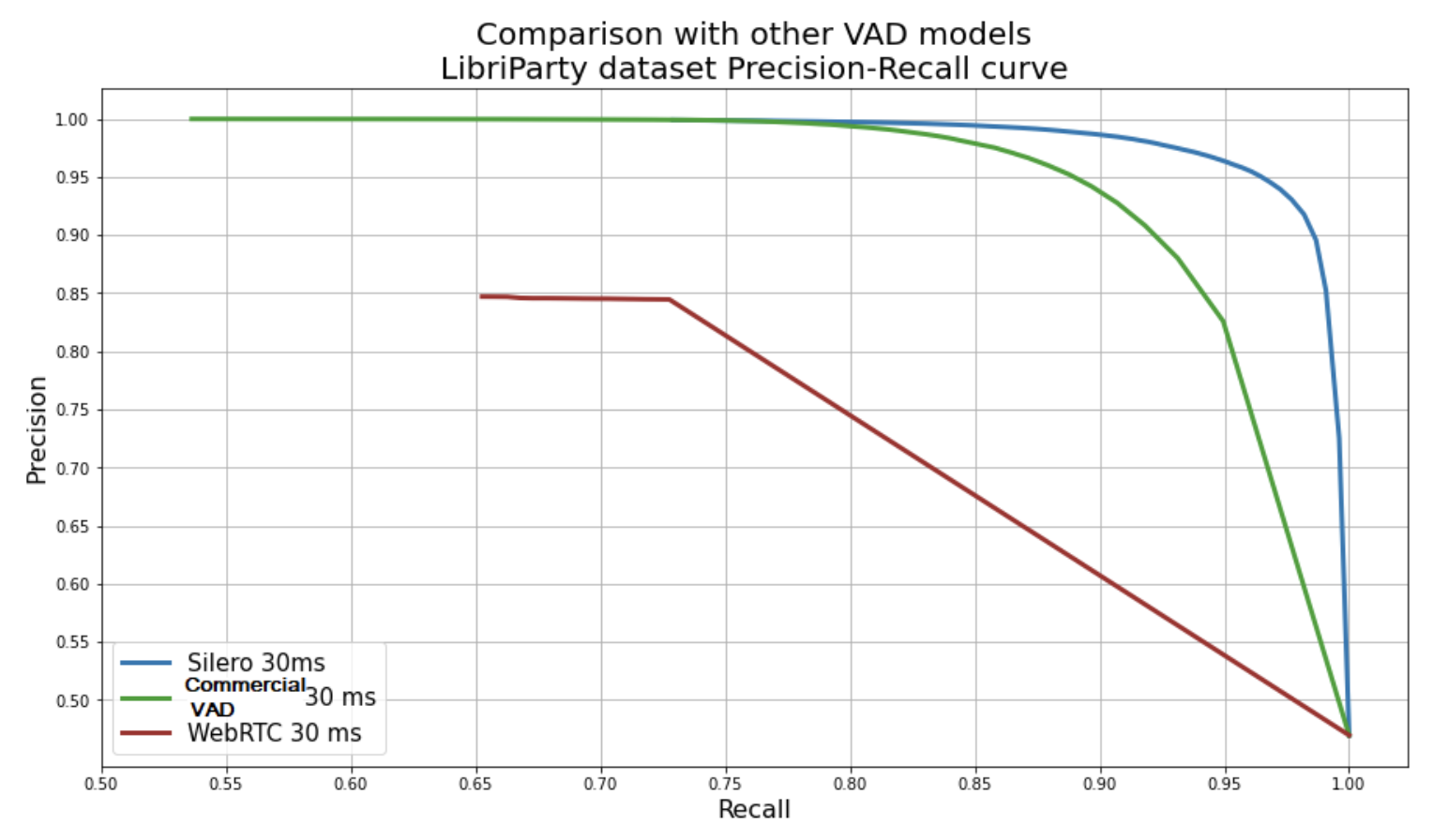
- Быстрая обработка: один аудиоблок (30+ мс) обрабатывается менее чем за 1 мс на однопоточном процессоре. Производительность можно значительно улучшить за счет пакетной обработки или использования графического процессора. При определенных условиях версия ONNX может даже добиться ускорения в 4-5 раз.
- Легкость: размер JIT-модели составляет примерно один мегабайт, что упрощает ее развертывание в средах с ограниченными ресурсами.
- Высокая универсальность: поддерживает частоту дискретизации 8000 Гц и 16 000 Гц, а обучение охватывает более 100 языков, обеспечивая хорошую производительность в различных областях и при фоновом шуме.
- Чрезвычайная портативность: благодаря экосистеме PyTorch и ONNX Silero VAD можно использовать везде, где поддерживаются эти среды выполнения.
- Никаких условий: выпущено под разрешительной лицензией MIT, без какой-либо регистрации, без встроенного срока действия и без привязки к поставщику.
Извлечение человеческих голосов из аудио
Начиная
Во-первых, убедитесь, что в вашей рабочей среде установлены необходимые библиотеки Python, включая pydub, numpy и torch. Эти библиотеки используются для загрузки и обработки аудиофайлов, научных вычислений и выполнения моделей глубокого обучения.
В этом примере мы используем модель silero-vad (вид обнаружения акустических событий), которая способна идентифицировать речевую активность в аудиопотоке. silero-vad — это модель, основанная на глубоком обучении, которая может эффективно распознавать человеческие голоса в различных фоновых шумах.
Этапы реализации
Предварительная обработка звука: сначала преобразуйте исходный аудиофайл в монофонический формат WAV и унифицируйте частоту дискретизации до 16000 Гц. Этот шаг необходим для того, чтобы модель могла правильно обрабатывать аудиоданные.
- Обработка кадров. Далее мы разделяем обработанный звук на несколько кадров, чтобы модель могла анализировать их один за другим. В этом примере длина кадра установлена на 600 мс. Чтобы повысить точность распознавания модели, мы разрезаем исходные аудиоданные на непрерывные кадры фиксированной длины.
- VAD (обнаружение голосовой активности): обнаружение голосовой активности в каждом кадре аудиоданных с помощью модели silero-vad и утилит от PyTorch. Если прогноз модели превышает определенный порог (например, 0,5), считается, что кадр содержит человеческий голос.
- Объединение речевых сегментов: обнаруженные голосовые сегменты будут дополнительно обработаны и объединены на основе их временных меток, чтобы исключить чрезмерно фрагментированные сегменты и создать более непрерывные и естественные речевые сегменты.
- Вывод и сохранение. Наконец, отфильтрованные и объединенные вокальные клипы будут сохранены в виде новых файлов WAV, каждый из которых будет содержать отдельный речевой клип для последующей обработки или анализа.
import os
import sys # импортировать sys модуль
import contextlib
import wave
import pydub
import numpy as np
import torch
torch.set_num_threads(1)
# Настройки параметров
sample_rate = 16000
min_buffer_duration = 0.6 # Это минимальная длина аудиобуфера в секундах.
# инициализация VAD
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
source='github')
def int2float(sound):
abs_max = np.abs(sound).max()
sound = sound.astype('float32')
if abs_max > 0:
sound *= 1/32768
sound = sound.squeeze() # depends on the use case
return sound
def audio_to_wave(audio_path, target_path="temp.wav"):
audio = pydub.AudioSegment.from_file(audio_path)
audio = audio.set_channels(1).set_frame_rate(sample_rate)
audio.export(target_path, format="wav")
def frame_generator(frame_duration_s, audio, sample_rate):
n = int(sample_rate * frame_duration_s * 2) # Длина кадра в байтах хранения
offset = 0 # Смещение байта
timestamp = 0.0 # смещение времени
duration = frame_duration_s * 1000.0 # Единица миллисекунда
while offset + n < len(audio):
yield Frame(audio[offset:offset + n], timestamp, duration)
timestamp += duration
offset += n
class Frame:
def __init__(self, bytes, timestamp, duration):
self.bytes = bytes # Размер этого кадра в байтах
self.timestamp = timestamp # Время начала этого кадра,Единица миллисекунда
self.duration = duration # Продолжительность этого кадра,Единица миллисекунда
def vad_collector(frames, sample_rate):
voiced_frames = []
for frame in frames:
audio_frame_np = np.frombuffer(frame.bytes, dtype=np.int16)
audio_float32 = int2float(audio_frame_np)
with torch.no_grad():
new_confidence = model(torch.from_numpy(
audio_float32), sample_rate).item()
if new_confidence > 0.5:
is_speech = True
else:
is_speech = False
if is_speech:
voiced_frames.append(frame)
elif voiced_frames:
start, end = voiced_frames[0].timestamp, voiced_frames[-1].timestamp + \
voiced_frames[-1].duration
voiced_frames = []
yield start, end
if voiced_frames:
start, end = voiced_frames[0].timestamp, voiced_frames[-1].timestamp + \
voiced_frames[-1].duration
yield start, end
def merge_segments(segments, merge_distance=3000):
merged_segments = []
for start, end in segments:
if merged_segments and start - merged_segments[-1][1] <= merge_distance:
merged_segments[-1] = (merged_segments[-1][0], end)
else:
merged_segments.append((start, end))
return merged_segments
def format_time(milliseconds):
seconds, milliseconds = divmod(int(milliseconds), 1000)
minutes, seconds = divmod(seconds, 60)
return f"{minutes:02d}:{seconds:02d}.{milliseconds:03d}"
def read_wave(path):
with contextlib.closing(wave.open(path, 'rb')) as wf:
sample_rate = wf.getframerate()
pcm_data = wf.readframes(wf.getnframes())
return pcm_data, sample_rate
def write_wave(path, audio: np.ndarray, sample_rate):
audio = audio.astype(np.int16) # Converting to int16 type for WAV format
with contextlib.closing(wave.open(path, 'wb')) as wf:
wf.setnchannels(1) # Mono channel
wf.setsampwidth(2) # 16 bits per sample
wf.setframerate(sample_rate)
wf.writeframes(audio.tobytes())
def detect_speech_segments(audio_path, output_folder="output"):
audio_to_wave(audio_path)
pcm_data, sample_rate = read_wave("temp.wav")
audio_np = np.frombuffer(pcm_data, dtype=np.int16) # Преобразование данных PCM в массив numpy
frames = frame_generator(min_buffer_duration, pcm_data, sample_rate)
segments = list(vad_collector(list(frames), sample_rate))
merged_segments = merge_segments(segments)
os.makedirs(output_folder, exist_ok=True) # Убедитесь, что выходная папка существует
for index, (start, end) in enumerate(merged_segments):
start_sample = int(start * sample_rate / 1000)
end_sample = int(end * sample_rate / 1000)
segment_audio = audio_np[start_sample:end_sample]
segment_path = os.path.join(
output_folder, f"segment_{index+1}_{format_time(start)}-{format_time(end)}.wav")
write_wave(segment_path, segment_audio, sample_rate)
print(f"Speech segment saved: {segment_path}")
# Чтение параметров из командной строки
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python3 detect_talk.py <audio_file.wav> <output_folder>")
else:
audio_file = sys.argv[1]
output_folder = sys.argv[2]
detect_speech_segments(audio_file, output_folder)Приведенный выше код выполняет детектор_voice.py в текущем каталоге, извлекает голосовые фрагменты из wav-файла audio_file.wav и сохраняет их в каталоге выходных_папок в текущем каталоге:
python3 detect_voice.py <audio_file.wav> <output_folder>Подвести итог
Silero VAD устанавливает новый стандарт в области обработки звука благодаря превосходным характеристикам обнаружения, высокой скорости обработки, легкой конструкции и широкой применимости. Благодаря обсуждению и представлению примеров в этой статье мы не только понимаем технические детали того, как эффективно извлекать отрывки человеческой речи из сложного аудио, но также видим огромный потенциал использования этой технологии в различных сценариях применения. В будущем, благодаря технологическому прогрессу, Silero VAD и связанная с ним технология обработки звука будут способствовать дальнейшему развитию инноваций в области интеллектуального анализа речи.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
