Изучите распределенную базу данных Cloud Native
автор:Цзян Сяовэй (Протон База)
Введение: В эпоху быстрого развития технологий искусственного интеллекта у нас есть возможность более глубоко изучить потенциальную ценность данных, и обработка данных не должна быть препятствием. Облачная распределенная база данных откроет новую парадигму обработки данных. Она позволит вернуть данные в их первоначальный вид. Будь то хранение или запрос, одна система может удовлетворить всесторонние потребности бизнеса в данных. Разрушьте ограничения сложной архитектуры данных, значительно снизьте порог использования данных, высвободите потенциал данных и позвольте данным появляться интеллектуально. |
|---|
1. Предыстория
1. История развития больших данных за последние два десятилетия
В 2002 году я присоединился к команде разработчиков Microsoft SQL Server. Рынок баз данных в то время был относительно простым и состоял из трех основных поставщиков: Oracle, IBM (DB2) и Microsoft (SQL Server). Индустрия баз данных, кажется, уже достаточно повзрослела, развитие стабилизировалось, и у новых продуктов/поставщиков больше нет шансов. Однажды я задумался о том, было ли продолжение работы над базами данных правильным выбором карьеры. По сравнению со зрелостью и стабильностью индустрии баз данных, интернет-бизнес процветает, а требования к возможностям и производительности баз данных растут с каждым днем. Война за решение проблемы горизонтального расширения незаметно началась.
Microsoft SQL Server У традиционных баз данных есть серьезное ограничение: поскольку это автономная архитектура, ее можно расширить только за счет использования более крупной машины, поэтому производительность всегда будет ограничиваться узким местом автономной производительности. Преобразование этого в распределенную архитектуру — очень сложная задача. хотя SQL Server Были некоторые попытки сделать это, но именно несколько статей, опубликованных Google, по-настоящему возглавили революцию распределенного ПО.
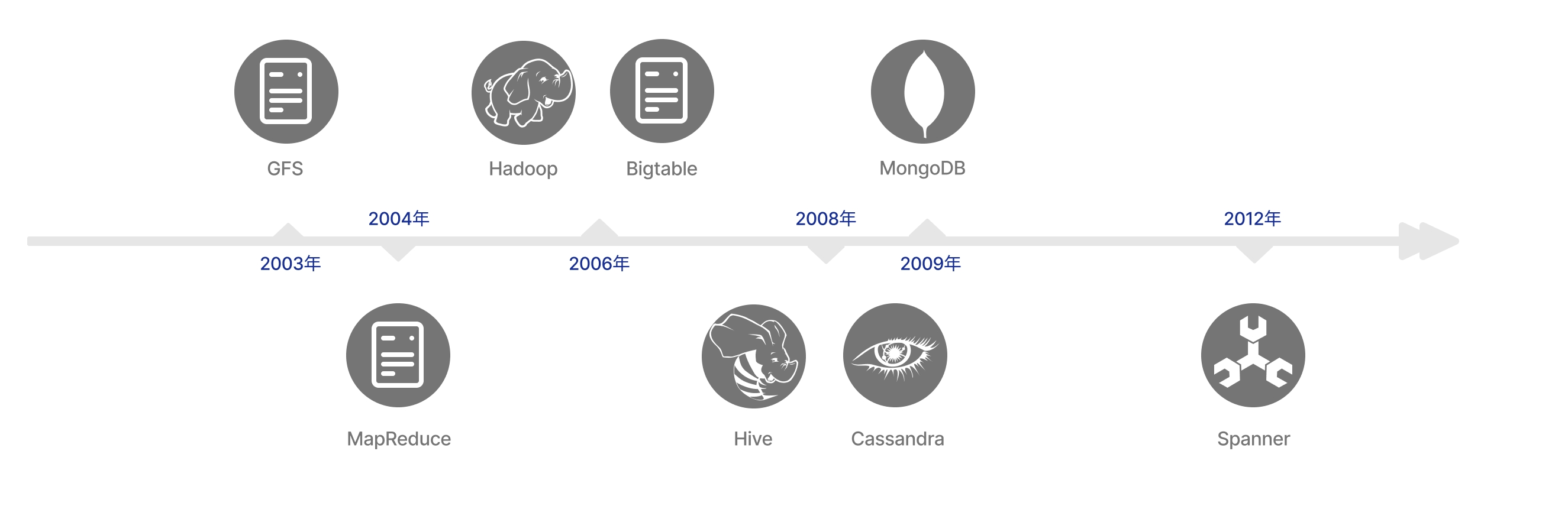
GFS и MapReduce:Google отличается от 2003 и 2004 Эти две статьи были опубликованы в 2006 году. СГФ Он описывает реализацию распределенной файловой системы и указывает направление хранения больших объемов данных. MapReduce Это архитектура для крупномасштабной обработки данных. Эти две статьи оказали глубокое влияние на всю отрасль. Они заставили отрасль осознать, что хранение и вычисление огромных объемов данных могут быть достигнуты с использованием обычного оборудования.
Hadoop:получать GFS и MapReduce Вдохновленный платформой с открытым исходным кодом Hadoop существовать 2006 Наступил год, и в последующие более десяти лет вся Hadoop Экосистема больших данных находится на подъеме.
Bigtable:2006 В 2016 году Google опубликовал Bigtable В этой статье представлена распределенная система хранения, целью которой является решение проблем хранения и доступа к крупномасштабным структурированным данным. Большой стол Запуск оказал существенное влияние на последующую технологическую эволюцию, ознаменовав NoSQL Начало эпохи способствовало включению HBase、Cassandra и MongoDB Жди серию NoSQL Разработка системы.
Hive:2008 лет, Фейсбук запущен Hive, основанный на MapReduce Технология значительно упростила процесс обработки больших данных. Пользователям достаточно пройти всего один этап. SQL Сложные запросы можно выполнять с помощью всего одного оператора, что значительно повышает эффективность работы в области анализа.
Spanner:2012 В 2016 году Google выпустила Spanner В документе представлена реализация настоящей распределенной реляционной базы данных, разработанной внутри компании. Промышленность наконец осознает возможность создания распределенной реляционной базы данных.
с Двадцать лет с 2003 года,Индустрия данных пережила поразительно быстрое развитие,Продвигал ряд технологических прорывов и инноваций. Основной движущей силой этого процесса является удовлетворение растущих потребностей бизнеса.,Особенно хранение и обработка больших объемов данных. По мере увеличения объема данных,Отрасль продолжает развиваться, обеспечивая более эффективные и надежные возможности управления данными.
2. Бизнес-перспектива: в качестве примера возьмем приложение B&B.
Вот отель типа «ночлег и завтрак» Приложение использует в качестве примера существующие потребности в хранении и обработке данных приложения для анализа.
Прежде всего, необходима система для хранения основной информации о каждом отеле типа «постель и завтрак» и различных пользовательских данных, таких как географическое положение отеля типа «постель и завтрак», количество номеров, график работы, удобства, цена, отзывы пользователей о пребывании и журналы взаимодействия с пользователем с помощью приложения. и т. д. Эти данные можно разделить на следующие категории:
1. структурированные данные:Основная информация о B&B,Например, количество комнат, цена и т. д.,Их можно описать с помощью структурированных данных.
2. полуструктурированные данные:Различные типы объектов、Параметры функции и т. д.,Они включают в себяполуструктурированные данные требуют более сложного способа хранения.
3. неструктурированные данные:Например, фотографии B&B.и Текстовые комментарии и т. д.,типичны неструктурированные данные。
Во-вторых, пользователи могут использовать эти данные в приложении различными способами:
1. Простой запрос:Пользователь знает название B&B,Задавайте вопросы напрямую.
2. Условный поиск:Пользователи на основе некоторых условий,Такие как цена, местоположение, состояние здоровья и т. д.,Найдите отель типа «постель и завтрак», который соответствует вашим потребностям.
3. Семантический поиск:Пользователь выполняет некоторый смысловой уровеньпоиск,Например, ищите отель типа «постель и завтрак» с хорошими санитарными условиями, высокой стоимостью и простым стилем.,Для этого система должна понимать семантику изображения и комментариев.
4. Сводный анализ:Пользователь хочет увидеть отели типа «постель и завтрак» с самым высоким рейтингом в определенном городе за последние несколько дней или месяца.,Для этого система должна оценить все отели типа «постель и завтрак» в городе.
3. Недостатки существующей архитектуры данных
Это приложение для проживания в семье должно иметь возможность эффективно хранить структурированные и полуструктурированные инеструктурированные данные, вам также необходимо иметь возможность запрашивать и анализировать различными способами. Как приложение уровня Интернета, его горизонтальная Масштабируемость также является обязательным условием. Однако ни один продукт на рынке не может полностью удовлетворить все потребности, поэтому отрасли часто приходится объединять несколько продуктов данных, таких как структурированные системы хранения данных. MySQL/PostgreSQL База эквивалентного типа отношений данныхсередина,Воляполуструктурированные данныехранилищесуществовать MongoDB Здесь потребуется наличие хранилища данных поиска. ElasticSearch Средний и так далее. Эта сложная бизнес-архитектура может вызвать ряд проблем:
Порог развития
существовать в условиях такой сложной бизнес-структуры,Разработка любой новой бизнес-функции, скорее всего, потребует использования нескольких продуктов обработки данных.,Это означает, что для развития бизнеса необходимо изучить множество продуктов данных.,Понять применимые сценарии, а также плюсы и минусы каждого из них.,и как объединить эти продукты для решения бизнес-задач,Это значительно повышает порог развития. Особенно существуют малые и средние предприятия,Из-за нехватки данных талантов,Это часто приводит к тому, что коммерческая ценность большого количества данных не используется в полной мере.
Эффективность разработки
Даже если организации посчастливилось иметь экспертов, умеющих ориентироваться в различных продуктах данных.,Им также пришлось потратить много времени на внедрение сложных архитектур данных.,Это влияет на эффективность итераций бизнеса. Они могли бы потратить это драгоценное время на развитие бизнеса.,Лучше поддерживать рост бизнеса.
Комплексная эксплуатация и обслуживание/стабильность системы
У каждого информационного продукта есть недостатки,Есть всевозможные проблемы. поэтому,Эксплуатацию и техническое обслуживание необходимо настраивать индивидуально для каждого продукта.,Поймите и научитесь избегать этих проблем. Проблемы с любым продуктом могут повлиять на стабильность системы. В дополнение к проблемам стабильности отдельных продуктов,Эта архитектура часто требует синхронизации данных.,Это еще больше повлияет на стабильность системы.:еслихранилищеопределенный фрагмент данныхпродукт(Например HBase не может эффективно поддерживать определенные требования к запросам (например, поиск по ключевым словам или семантический поиск), поэтому вам необходимо синхронизировать данные из одного продукта в другой с помощью задач синхронизации, а затем использовать целевой продукт для выполнения соответствующего запроса. Синхронизация данных часто является одним из самых хрупких звеньев во всей системе данных и может легко повлиять на стабильность системы. При возникновении проблемы данные, видимые разными системами, могут оказаться несогласованными.
задержка данных
Даже если нет сбоя в синхронизации данных,Задержка синхронизации также будет сохранена. Даже благодаря различным оптимизациям задержка сокращается в среднем до одной-двух секунд.,Однако задержки могут возникать из-за неконтролируемых сбоев из-за горячих точек заданий синхронизации и аварийного переключения. Представьте, что домовладелец меняет свойства своего отеля типа «постель и завтрак».,Тогда я сразу отправился в свой B&B с новой атрибутикой, но не смог его найти из-за периодических задержек и глюков.,Это, несомненно, приносит пользователям плохой опыт. И полностью решить эту проблему,Практически невозможно гарантировать, что задержка будет существовать навсегда в течение короткого периода времени.,В бизнесе зачастую мы можем лишь снизить вероятность его возникновения различными методами. Архитектуре, которая опирается на большой объем синхронизации данных, сложно обеспечить хорошее решение для сценариев интерактивного добавления, удаления и изменения.
расходы
В бизнес-использовании часто наблюдаются пики и спады, и рост трудно точно предсказать. Помимо предварительной покупки необходимого оборудования в зависимости от пиков, чтобы справиться с внезапным трафиком, необходимо зарезервировать дополнительное оборудование. определенное количество отходов. В то же время аппаратные ресурсы разделены на несколько измерений, таких как хранилище и вычисления. Недостаток ресурсов в одном измерении и добавление большего количества компьютеров может привести к пустой трате ресурсов в другом измерении.
2. Облачное распространение. Data Warebase: интеграция базы данных и больших данных
Можно ли объединить сильные стороны массовых продуктов?,А как насчет разработки продукта данных, который может удовлетворить обе вышеуказанные потребности? Я думаю, что ответ - да,Развитие технологий за последние два десятилетия позволило изучить и решить различные подзадачи.,Сейчас существуют комплексные решения этих проблем,Пришло время существенно снизить порог использования данных.
Такой продукт имеет следующие характеристики:
облачный родной
Развертывание, эксплуатация и обслуживание являются очень важной частью продуктов обработки данных.,Контейнеризация может обеспечить согласованное рабочее поведение в различных вычислительных средах.,Значительно упростите развертывание, эксплуатацию и обслуживание продуктов в различных средах. Запланируйте эти контейнеры через Kubernetes,Система может легко расширяться и сжиматься в зависимости от изменений в трафике. Используя архитектуру разделения ресурсов хранения и вычислений.,Сделайте расширение и сокращение ресурсов в различных измерениях более гибким.,Дальнейшая оптимизация использования ресурсов,уменьшатьрасходы。
распределенный
Развитие информационных продуктов за последние два десятилетия почти полностью вращалось вокруг решения проблемы.,Это горизонтальная масштабируемость системы. Только распределенная система может полностью убрать потолок производительности,Удовлетворите потребности любого бизнеса в производительности.
Data Warebase
Продукты данных можно в общих чертах разделить на реляционные базы данных, NoSQL. база данные, система поиска, хранилище данных векторного поиска и другие категории. "Данные Термин «Хранилище данных» представляет собой сочетание термина «Хранилище данных». Warehouse)”и“база Два слова «данные (база данных)» используются для обозначения продукта, который сочетает в себе функции нескольких вышеупомянутых типов продуктов. Этот тип продукта может одновременно удовлетворять потребности бизнеса в различных возможностях хранения данных и вычислений.

В этот момент внезапно возникает вопрос: означает ли это также компромисс в производительности? Неужели эта система не способна обеспечить оптимальное решение в любом сценарии? это хороший вопрос,Суть его существования заключается в том, существует ли фундаментальный и непримиримый конфликт между этими функциями.,и дает ли их сочетание синергетический эффект,Для достижения суперпозиции производительности,Сделайте так, чтобы эффект целого превышал сумму его частей.,выполнить 1 + 1 > 2。
На примере уравнений Максвелла
Максвелл был одним из величайших физиков-теоретиков.,Он соединил четыре уравнения электричества и магнетизма, открытые предшественниками.,Сформировал знаменитые уравнения Максвелла. Решая эту систему уравнений,Максвелл открыл электромагнитные волны,Потом был свет! Хотя этот процесс слияния кажется простым,,Но это способствовало качественному скачку,Создание новых явлений, превосходящих ожидания,Вот и всетипично 1 + 1 > 2 сцена.

Путем объединения дополнительных данных, полученных из разных сценариев. Интеграция Вместе с технологией «существовать» она может не только хорошо обслуживать эти сценарии, но и решать межсценарные проблемы, которые не могут быть решены с помощью одной технологии. Этот интегрированный опыт значительно снизит порог использования данных в бизнесе, повысит эффективность развития бизнеса и полностью решит проблему задержек. данныхи Проблема несоответствия,Ускорьте создание бизнес-ценности на основе данных! В то же время простая архитектура бизнес-данных значительно упростит эксплуатацию и обслуживание.,Улучшите стабильность системы.
три、Строитьоблачный роднойраспределенный Data Warebase элементы
почему должен Database и Data Warehouse Сложить вместе? Давайте сначала рассмотрим обратную задачу: почему долженбаза Разделены ли данные, поиск и несколько складов? Отель типа «ночлег и завтрак» сверху APP На примере видно, что бизнес не требует от нас разделения этих систем. Каждый, кто разделяет его на разные продукты, на самом деле ограничен технологиями. Далее мы объясним возникшие технические проблемы и способы их решения.
1. Возможность горизонтального расширения
1.1 Преимущества баз данных NoSQL
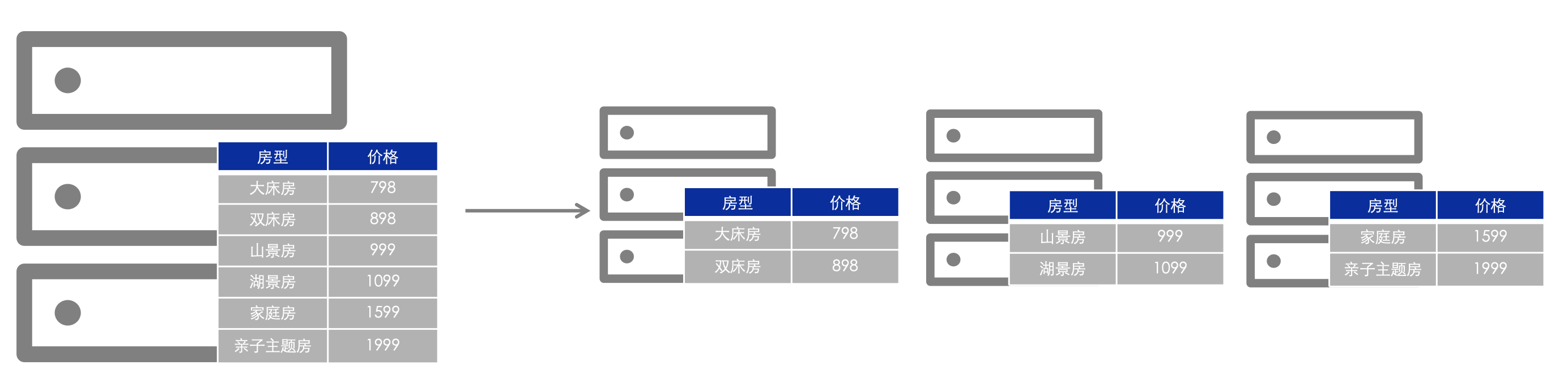
хотетьсуществовать Реляционныйбаза данных Достижение горизонтального расширения — это вопрос, полный технических проблем. Однако бизнес не может стагнировать и не будет ждать появления идеального технического решения, поэтому мы быстро разработали серию продуктов, которую можно расширять по горизонтали. NoSQL база данных Сразудакогдасерединакатегория,Лучше решает проблему горизонтального расширения.,Конечно, в этой проблеме были сделаны некоторые упрощения и компромиссы.
Далее мы используем NoSQL Тип документа база, широко используемый в данные в качестве примера анализировать с некоторыми мыслями, стоящими за этим. Огромной проблемой при переходе от одной машины к распределенной является распределенная транзакция, но в особом случае реализация транзакций будет значительно упрощена. Это сценарий одной машинной транзакции, то есть всех записей чтения и записи. транзакция точно такая же. Мы можем существовать в этом случае, используя что-то вроде автономной базы. Как сделать данные. Однако в существовании реляционной модели данные, связанные с бизнесом, будут храниться отдельно в нескольких таблицах в соответствии с тремя парадигмами построения реляционной модели, что часто приводит к модификации бизнеса. Необходимо обновить несколько фрагментов данных, распределенных в нескольких таблицах. Эти данные, скорее всего, будут распределены по разным машинам. Поэтому реляционная модель ограничивает применимые сценарии оптимизации транзакций на одном компьютере. Тип документабаза В этот момент в игру вступают преимущества данных. Поскольку модель документа организует связанные данные в один документ, во многих бизнес-сценариях требуется обновлять только один документ, что позволяет избежать дополнительных накладных расходов, связанных с транзакциями с несколькими машинами. Такое упрощение делает тип документа базой. данныхможет быть легко достигнуто посредством сегментирования данныхвыполнить Горизонтальное расширение,Для удовлетворения требований к производительности быстрого роста интернет-услуг.,Широко использовался.

Тип документабаза данных Еще одним преимуществом является хранение полуструктурированных Возможности данных, различные документы не обязательно должны быть полностью изоморфны. Например, при описании удобств отеля типа «постель и завтрак» у холодильника может быть поле для обозначения вместимости, а у фена этого поля нет. Такая гибкость избавляет разработчиков от необходимости искать DBA Измените структуру таблицы и улучшите эффективность. разработки, становясь хорошим выбором для гибкой разработки.
1.2 Преимущества реляционной базы данных
Поскольку модель документа имеет множество преимуществ,Должны ли мы отказаться от реляционной модели и использовать модель документа? существуютбаза раннего развития,Между документоподобной моделью и реляционной моделью произошла битва.,В результате реляционная модель почти доминирует в мире. Важная причина, почему реляционная модель побеждает, заключается в том, что она может лучше поддерживать согласованность данных.
Как упоминалось выше, проектирование реляционной моделитрипарадигма,Они иллюстрируют способы эффективной организации данных и предотвращения дублирования с точки зрения зависимости данных. Разработчики могут использовать связь между сущностями (один-к-одному).,один ко многим,или многие-ко-многим) структура таблицы параметров. Модели документов могут быть встроены в индивидуальный иодин ко многимреляционная сущность,Но эффективного решения для отношений «многие ко многим» не существует.,Может привести к дублированию хранения данных. Когда данные сохраняются неоднократно, обеспечение их согласованности становится проблемой.,Когда бизнес-код существует, необходимо изменить несколько копий данных одновременно, чтобы сохранить эту согласованность.,Бизнес-код станет более сложным. Что хуже,Данные, которые необходимо изменить одновременно, могут быть распределены на разных машинах.,Это делает оптимизацию транзакций на одной машине больше не применимой. Чтобы добиться согласованности данных в таких сценариях, как существование,распределенная транзакция — это препятствие, которое не может обойти ни одна система. Документная база данных существует только в определенных сценариях и решает проблему организации данных.,Реляционная модель полностью решает эту проблему.
Модель документа позволяет легче выражать полуструктурированные данные, поскольку она не имеет определенной табличной структуры, но это также палка о двух концах. Эта ситуация аналогична динамически типизированным языкам, таким как JavaScript) по сравнению со статически типизированными языками, такими как С++). Динамически типизированные языки не требуют предопределенных типов переменных и просты в использовании, но в больших проектах ремонтопригодность может быть сложной задачей. Машинопись Он появился на свет и нашел широкое применение в масштабных проектах, что полностью иллюстрирует этот момент. Некоторые типы документов базы данных Тоже в курсе этой проблемы,Позволяя пользователям определять схему документа,Это дает определенную гарантию внутренней непротиворечивости документа.
Помимо ограничений внутри документа, также могут существовать некоторые ограничения между различными объектами данных. Например, база реляционного типа Данные способны поддерживать согласованность между объектами посредством внешних ключей. Эта функция является базой типа документа. данные обычно отсутствуют, поэтому трудно поддерживать согласованность данных в нескольких документах. Другим примером является уникальный вторичный индекс. Поскольку он не поддерживает распределенные транзакции, уникальность между узлами трудно гарантировать, поэтому для этого типа системы часто требуется уникальный вторичный индекс, содержащий ключ раздела, что ограничивает сценарии его применения. Таким образом, по сравнению с базой реляционного типа данных,База данных типа документа имеет слабую поддержку ограничений.,Таким образом, существуют также пробелы в предоставляемых гарантиях целостности и согласованности данных.
Помимо преимущества согласованности данных, еще одной сильной стороной реляционной модели является SQL поддержка, которая позволяет передать реализацию запроса оптимизатору, тем самым значительно повышая Эффективность разработки。Тип документабаза данныепотому что полный SQL, существующие запросы, также сталкивается с некоторыми проблемами. Этот тип продукта, как правило, Join Возможности относительно скудны или не поддерживаются Присоединиться. Следовательно, их сценарии существования, включающие объединение содержимого нескольких документов, часто требуют, чтобы бизнес-конец существования реализовал некоторую логику запроса.
1.3 NoSQL и реляционная база данныхслияние
NoSQL Когда-то база данных была очень популярна, поскольку она взяла на себя ведущую роль в решении проблемы горизонтального расширения и поддержки модели гибкой разработки. Некоторые даже так думают. NoSQL Это будущее баз данных. Но последующие разработчики постепенно осознали только что упомянутые проблемы, поэтому NoSQL Продукты также начали поглощать базу отношений. Некоторые возможности данных. Эти события даже свидетельствуют о существовании NoSQL по объяснению этого названия. NoSQL первое предложенное существование 1998 Годы, первоначальное значение этого слова действительно было «ничего». SQL" означает, что SQL антоним. NoSQL Движение действительно начинает набирать обороты надасуществовать 2009 около лет。существовать 2009 На конференции, посвященной нереляционным базам данных в 2010 году, это название было переосмыслено как «Нереляционные базы данных». Only SQL», первоначальная цель этой встречи заключалась в том, чтобы удвоить усилия SQL Как язык запросов, он не принимает концепцию реляционной модели и полностью не строит новую архитектуру данных. NoSQL Когда-то оно также стало синонимом горизонтального расширения и гибкого развития. Но в последние годы некоторые NoSQL В системе также начали реализовываться распределенные транзакции (хотя это не рекомендуется для производственного использования существования), а также реализованы некоторые SQL Язык запросов. Благодаря этим возможностям реляционных баз данных NoSQL Внедрение продукта, NoSQL Это также объяснялось всеми как «не просто SQL", больше нет SQL антоним к , но как антоним к SQL расширение.
За последнее десятилетие или около того продукты реляционных баз данных также осознали важность полуструктурированных данных и начали внедрять JSON или JSONB типы для выражения полуструктурированных данных, таких как PostgreSQL имеет очень полный JSON поддерживать. Пользователи могут существовать за любым столом JSON столбец, один JSON Столбец соответствует документу в базе данных документов. Реляционные базы данных внезапно получили возможность, как и базы данных документов, гибко выражать полуструктурированные данные. Помимо простого извлечения полей, он также вводит JSON Запрос (содержит JSON PATH QUERY) Этот мощный язык запросов может быть очень удобен для выполнения запросов и операций. JSON данные. Благодаря этим расширениям база реляционного типа модель данныхсуществовать и возможности запросов уже есть NoSQL база Расширенный набор данных с более гибкой и эффективной организацией данных и возможностями запросов. Мы видим, что реляционная модель и модель документа не являются взаимоисключающими отношениями. JSON Тип расширенной реляционной модели: мы можем получить преимущества обеих моделей в одном продукте.
После решения проблемы объединения моделей данных,,Остальное – вопрос горизонтального расширения. Как объяснялось выше, помимо использования технологии сегментирования данных,Распределенные транзакции — это препятствие, которое не может обойти любой распределенный продукт, желающий полностью гарантировать согласованность данных.,Проблемы достижения этого также огромны,Мы можем только столкнуться с этим и решить эту проблему.。хорошийсуществоватьSpanner В статье хорошо показано, как существуют базы реляционного типа. данных реализует внешне согласованные распределенные транзакции. С помощью распределенной транзакции вы можете предоставить реляционную базу данные полностью работоспособны. Эти функции включают внешние ключи, глобально уникальные вторичные индексы и т. д., обеспечивая комплексные гарантии согласованности и целостности данных. Гаечный ключ Хотя это очень сложная распределенная база данных, но сложность остается на ваше усмотрение, и пользователи используют ее так, как если бы они использовали автономную реляционную базу данных так же просто и даже более мощно. Эта простота использования делает Spanner существовать Google Интерьер удался на славу.
Или NoSQL база база данных или реляционного типа данныесуществовать Проблемы, возникающие при реализации распределенных транзакций, аналогичны. В то же время JSON Типы продуктов реляционных данных также могут быть NoSQL база данных также поддерживает сценарии, которые можно оптимизировать как отдельные транзакции, поэтому этот новый распределенный продукт реляционных данных полностью включает в себя NoSQL Преимущества баз данных.
2. Поиск
Самый простой режим запроса — найти соответствующую запись (проверить) на основе определенного значения ключа. Это традиционный реляционный запрос. Данные очень хороши и эффективны для сцены. Чтобы повысить производительность запросов этого типа, используется реляционная база. данныепред представляют собой функцию вторичного индекса,Используйте вторичные индексы для прямого поиска соответствующих записей на основе значений ключей индекса.,Это значительно ускоряет запросы. Например, мы можем создать индекс названий B&B для таблицы B&B.,Таким образом, вы сможете быстро найти соответствующий отель типа «постель и завтрак» по названию.
Чуть более сложные запросы требуют фильтрации по нескольким полям (поиск). Вторичный индекс существования Этот сценарий имеет определенные ограничения. Потому что вторичный индекс может работать лучше, только если условием запроса является префикс ключа индекса.,Поэтому для разных режимов запросов может потребоваться создание разных вторичных индексов. существующий режим запроса фиксирован и имеет меньше случаев,Эти запросы можно ускорить, используя несколько вторичных индексов. Однако некоторые режимы запросов бизнес-сценариев очень гибки и даже не могут быть полностью определены заранее. Например, помимо поиска отелей типа «постель и завтрак» по названию,,Пользователям может потребоваться следить за ценой номера.,Найдите отели типа «постель и завтрак» на основе сочетания условий, таких как удобства. Комбинации этих условий поиска будут увеличиваться в геометрической прогрессии по мере увеличения количества возможных полей поиска. Если мы создадим вторичный индекс для каждого возможного шаблона запроса,Количество вторичных индексов, которые необходимо создать, также будет увеличиваться в геометрической прогрессии. Помимо того, что эти вторичные индексы занимают место для хранения,,Это также увеличит стоимость обслуживания индекса, вызванную каждой операцией добавления, удаления и изменения данных.,Создание большого количества вторичных индексов становится невозможным.
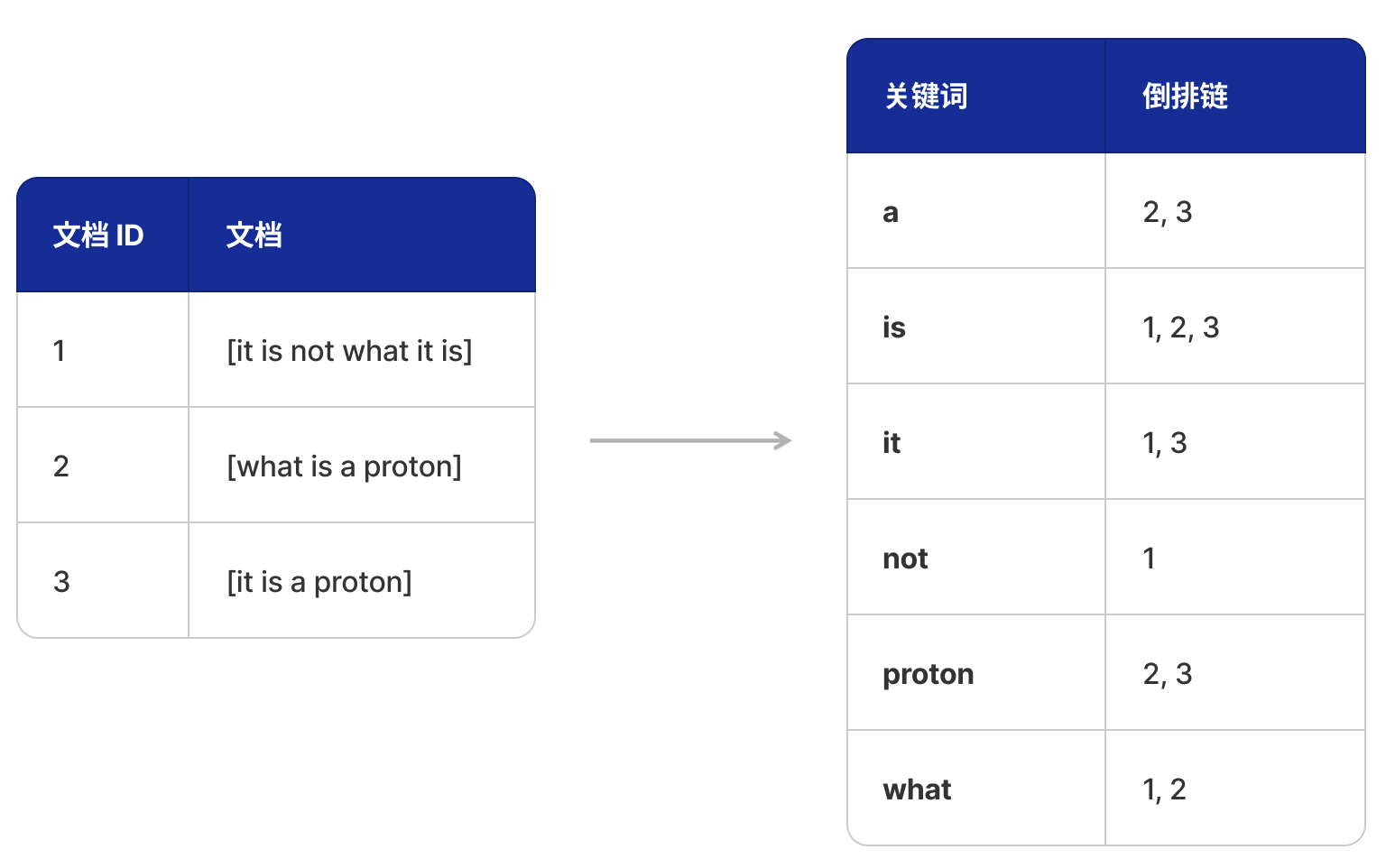
Поиск Для решения этой проблемы Двигатель использовал технологию инвертированного индекса.,Этот индекс сопоставляет поле со списком документов, которые его содержат (инвертированная цепочка). Эти инвертированные цепочки могут эффективно выполнять операции над множествами (например, пересечение,союз и др.). Технология инвертированного индекса широко используется в сфере полнотекстового поиска.,нода Его принцип структурный. / То же самое относится и к запросам к полуструктурированным данным. Нам нужно всего лишь создать инвертированный индекс одного поля для полей, которые могут быть извлечены, а затем мы сможем ускорить совместную фильтрацию этих полей за счет операции установки нескольких инвертированных цепочек.
существоватьраспределенныйсистемасередина,Метод секционирования индекса окажет большое влияние на производительность запросов. Существует два распространенных способа: один — разделить в соответствии со значением индексного поля.,Преимущество заключается в том, что по заданному значению поля можно найти определенный раздел.,Таким образом, запрос по одному полю очень эффективен.,Однако совместный запрос нескольких полей требует агрегации инвертированных цепочек, распределенных по нескольким машинам.,Это окажет относительно большое влияние на производительность. Второй способ — поместить данные и соответствующий им индекс в один раздел. Таким образом, даже при поиске по одному полю потребуется найти несколько разделов.,Поэтому эффективность поиска по одному полю не такая высокая, как у первого метода. Но преимущество состоит в том, что совместный поиск по нескольким полям может эффективно завершить операцию сбора инвертированных цепей внутри существующего раздела. Поэтому вторичные индексы, оптимизированные для точечных запросов, часто используют первый метод.,Инвертированные индексы, оптимизированные для гибкого поиска, обычно используют второй метод.
Этот инвертированный индекс и технология секционирования существуют. Elastic Реализованные в других продуктах и широко используемые, эти технологии легко данные поглощают их, чтобы обеспечить эффективный полнотекстовый поиск и структурирование. / Возможность поиска полуструктурированных данных.
3. Векторный поиск
существуют В течение последних двух лет, исходя из Transformer Большая языковая модель архитектуры достигла быстрого развития, что значительно способствовало обработке естественного языка, распознаванию изображений, а также пониманию и созданию аудио- и видеоконтента. Как эффективно использовать возможности этих моделей, особенно приложений для данных частных доменов, стало чрезвычайно важным вопросом. Генеративные модели с расширенным поиском (RAG) представляют собой инновационное решение, которое умело объединяет Возможности запроса данных или поисковой системы сочетаются с технологией генеративного искусственного интеллекта. Например, чтобы ответить на вопрос на естественном языке, мы сначала используем базу данныхили Поиск Двигатель Найдите связанные с ним записи. Результаты этих первоначальных экранов затем передаются в более крупную модель.,Пусть большая модель существования разбирается в этих записях и дает качественные ответы.
Помимо использования упомянутых выше возможностей полнотекстового поиска и структурированного поиска,,Также был разработан режим поиска на основе встраивания. Извлечение встраивания путем вычисления многомерного вектора встраивания для каждой записи.,И используйте расстояние или внутренний продукт этих векторов, чтобы измерить их семантическую релевантность или сходство.,Таким образом реализуется векторный метод поиска. существуют при использовании запроса на языке сран,Мы можем вычислить многомерный вектор вложения для самой задачи.,Затем найдите документы, соответствующие векторам, подобным этому вектору.
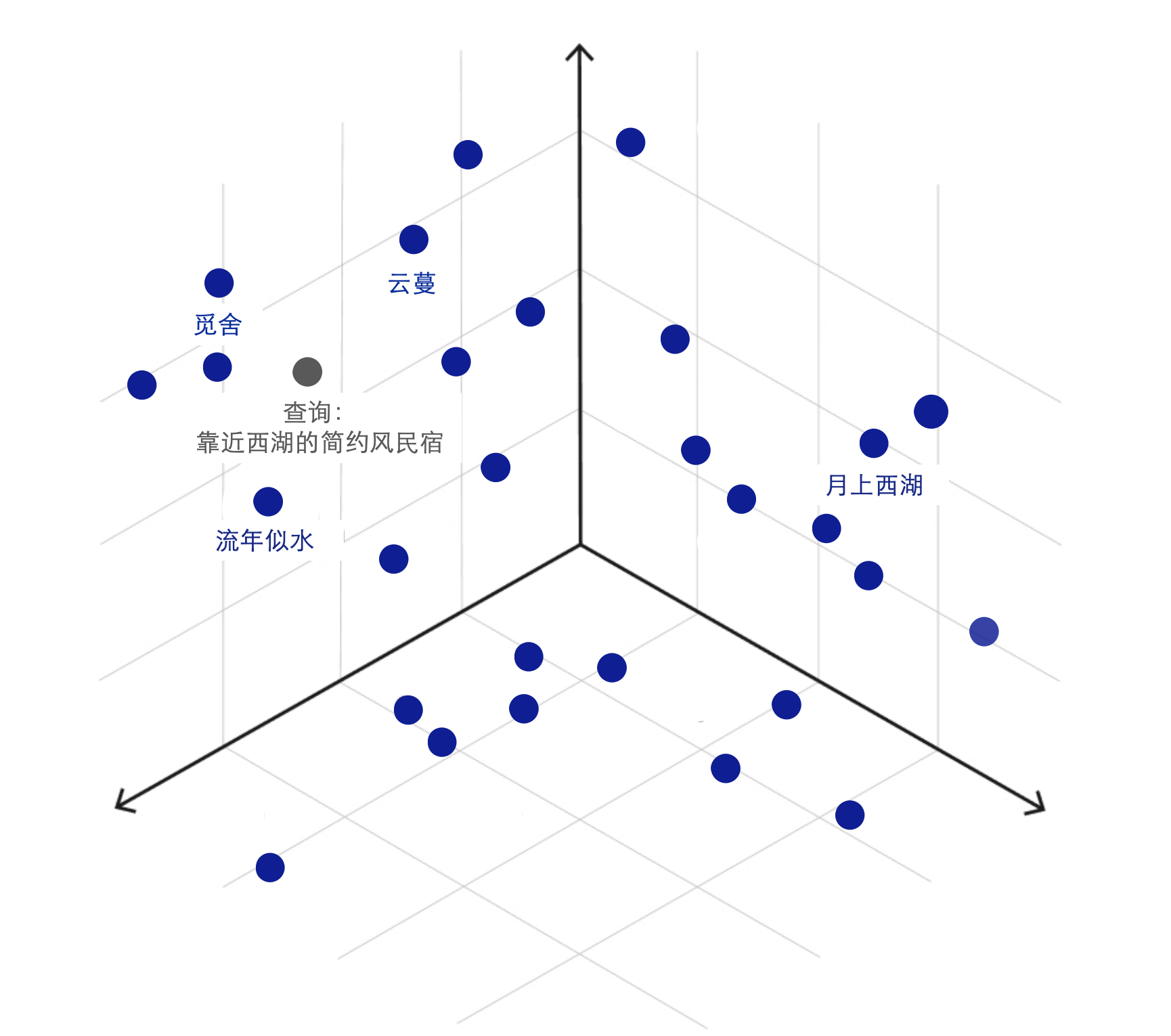
Чтобы облегчить хранение и обработку этих многомерных векторов в системе,Мы можем возглавить векторный тип данных,Это позволяет легко сохранить встроенное представление этих записей. Однако,Когда количество записей чрезвычайно велико,Быстро найти векторы, очень похожие на конкретный вектор, среди сотен миллионов записей — это сложная задача. Чтобы достичь этого с высокой производительностью,索引这些向量Сразу显得尤为重хотеть。В настоящее время распространенные типы векторных индексов включают в себя IVFFlat и HNSW. Те реляционные типы, которые объединяют многомерные векторные типы и функции индексации. данных, является отличным решением этой проблемы. По сравнению с профессиональной векторной базой данных, звание имеет более низкий порог для продуктов реляционных данных векторного типа, а также может использовать полнотекстовый поиск на основе ключевых слов, структурированный / Извлечение полуструктурированных данных и совместный запрос на основе поиска семантических векторов — это возможности, которыми не обладает ни один продукт в отдельности.
4. Анализ
Традиционный дизайн хранилища данных для сложных запросов ианализировать,Данные, которые он хранит, относительно статичны.,Часто импортируется один раз в день,Нет необходимости учитывать параллельные транзакции,Следовательно, обработка транзакций записи данных может быть значительно упрощена.,Например, этого можно добиться, заблокировав таблицу. Поскольку данные в течение дня не импортируются,Таким образом, запросу не нужно беспокоиться о том, что он застрянет в транзакции записи. Однако по мере роста бизнес-требований к данным в реальном времени,Существует потребность в хранилище данных в реальном времени. Данные необходимо постоянно импортировать в систему в режиме реального времени.,В то же время мы надеемся, что процесс опроса существующих не будет заблокирован. Простой и грубый импорт данных путем блокировки таблицы явно больше не отвечает этому требованию. Управление несколькими версиями (MVCC) — эффективный способ разрешения таких конфликтов чтения и записи. Каждый записанный фрагмент данных будет иметь временную метку записи.,Несколько версий части данных будут сосуществовать в системе в течение определенного периода времени. При чтении вы можете выбрать временную метку, когда новых записей больше не будет.,Это дает вам полный снимок, соответствующий этой временной метке. существуют. Выполняйте различные сложные запросы анализа к этому моментальному снимку, не блокируясь при записи. Эту технологию многоверсионного управления использовали многие люди. используемые продукты данных, такие как упомянутые выше Spanner, та же технология может также использоваться в хранилищах данных в реальном времени.
Потому что объем данных в сценарии хранилища данных огромен.,Если эти огромные объемы данных необходимо записывать в режиме реального времени,Потребуется огромный объем работы. Распределенные транзакции с высокой пропускной способностью являются сложной проблемой,Может привести к дополнительным накладным расходам в системе.,Это одна из причин, почему все (в том числе и я) когда-то подумали, что хранилище данных необходимо разделить. Давайте подробно проанализируем проблему записи сцены хранилища данных. Существует два основных режима записи для сценариев хранилища данных: один — пакетный импорт больших объемов данных.,Например, полная замена данных в таблице, другой — писать в реальном времени по одному;,Хотя можно реализовать обновления посредством пакетной обработки.,Но по сути каждая запись представляет собой независимую транзакцию. К счастью, в обоих режимах записи есть возможности для оптимизации. Хотя объем данных в первом режиме записи огромен,,Но количество транзакций невелико,Таким образом, беспокоиться о дополнительных расходах, которые принесет распределенная фирма, в принципе не стоит.,Потому что объем вычислений, вызванный записью такого большого количества данных, ничтожен по сравнению с ним. Во втором типе режима записи каждый фрагмент данных можно рассматривать как независимую транзакцию.,Это делает возможной упомянутую ранее оптимизацию транзакций на одной машине.,Следовательно, нет необходимости нести дополнительные расходы, приносимые распределенными делами. Пока мы можем выполнить целевую оптимизацию для этих двух типов сценариев,,Он может поддерживать запись больших объемов данных в несколько хранилищ в одном продукте.
Один из секретов современных хранилищ данных — использование столбцового хранилища.,Поисковая система решает проблему совместной фильтрации нескольких полей путем установления инвертированного индекса.,существоватьанализироватьзапрос классасередина,Нам также может потребоваться выполнить быстрое агрегирование по некоторым столбцам. Если данные хранятся в традиционном формате строк,Это означает, что агрегация одного столбца требует чтения всех данных.,Система будет считывать много ненужных данных, из-за чего запросы станут очень медленными. А если организовать хранение в столбцах,Храните данные всех строк в одном столбце вместе,Это агрегирование может быть эффективно достигнуто без чтения дополнительных данных. В то же время, благодаря возможности эффективного чтения данных одного столбца,,Также возможно добиться эффективной фильтрации без инвертированного индекса. Кроме того, поскольку данные в разных строках одного и того же столбца имеют высокое сходство,Это обеспечивает эффективное кодирование и сжатие.,Это еще больше снижает объем операций ввода-вывода, необходимых для чтения данных, и повышает производительность запросов. Помимо хранения,Для полного использования преимуществ хранения столбцов также используется механизм векторизованных запросов. Конечно, хранилище столбцов и векторизованные запросы не являются оптимальными во всех сценариях.,существуют сценарии, в которых необходимо прочитать небольшое количество целых строк данных.,Хранение строк и обработка строк могут быть лучшим выбором. Но мы также можем объединить хранилище строк и хранилище столбцов.,Позвольте оптимизатору при запросе выбрать наиболее подходящий метод хранения и обработки в соответствии с конкретным сценарием.
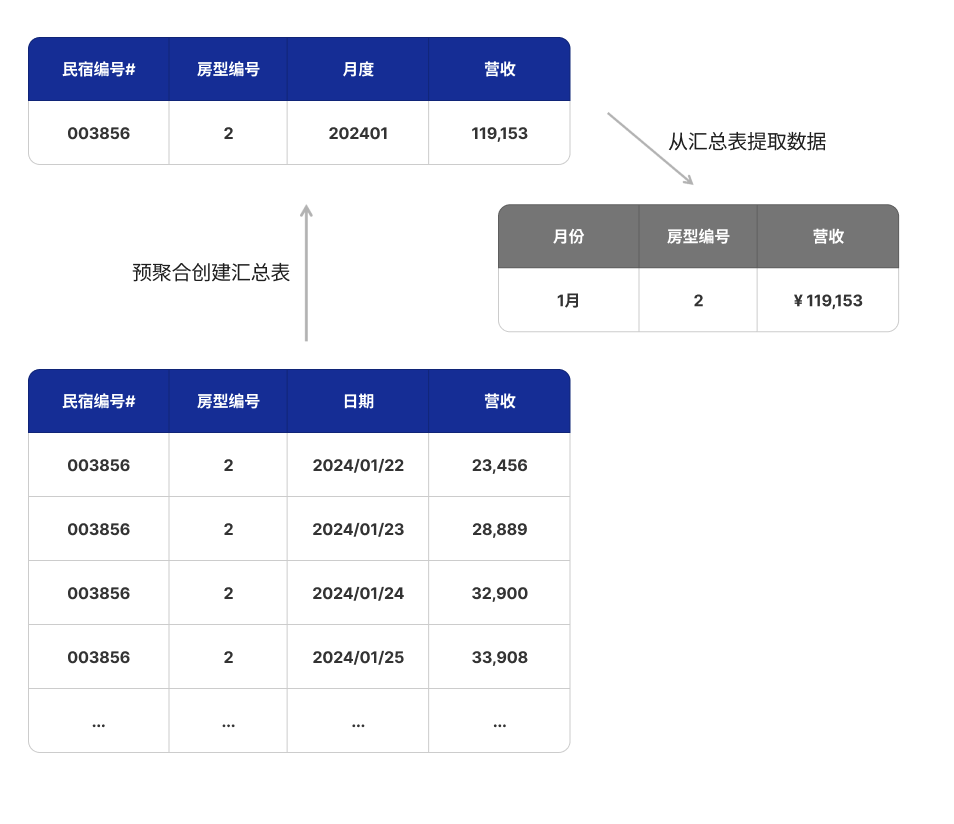
Предварительные вычисления также являются распространенной оптимизацией в хранилищах данных.,Этот тип предварительного расчета включает в себя общее и среднее значение、считать、максимальное значение / Минимальное значение Жди сериюиндекс,Эти агрегированные данные хранятся в существующей системе.,Для быстрого доступа ианализировать,Уменьшить вычислительную нагрузку запросов,Это ускоряет время ответа на запрос. Эти предварительные вычисления для одной таблицы можно хорошо абстрагировать и реализовать с помощью индексов. Более сложную логику предварительных вычислений, включающую несколько таблиц, также можно абстрагировать с помощью материализованных представлений. Эти материализованные представления можно обновить вручную через систему.
4. Откройте дверь к инновациям
Теперь, когда мы понимаем каждый аспект технологических инноваций, создание совершенно новой технологии является само собой разумеющимся.
1. Интеграция технологий
Мы видим, что различные продукты используют ряд технологий для оптимизации соответствующих сценариев. Эти оптимизации включают в себя:
• NoSQL Горизонтальное масштабирование достигается за счет сегментирования данных. Модель документа также была добавлена, чтобы уменьшить потребность в распределенных транзакциях и в то же время улучшить поддержку модели документа. данные;
• Поисковая система использует инвертированные индексы и различные стратегии сегментирования индексов, которые могут эффективно поддерживать различные комбинации условий поиска;
• Векторный движок главы имеет векторный индекс, помогающий быстро найти вектор с высоким сходством среди массивных векторов;
• В хранилище данных реализовано множество оптимизаций для записи больших объемов данных. Хранилище данных также обеспечивает хранение столбцов.,Возможность лучшего сжатия данных,Поддержка эффективной агрегацииифильтр。В то же время вы можете предварительно вычислить Уменьшить вычислительную нагрузку запросов Улучшение производительности запросов。
Точно так же, как уравнения электричества и магнетизма,Хотя они происходят из разных сценариев,Но эти технологии не противоречат друг другу,Совершенно возможно использовать оба следующих компонента в одном продукте:
• Архитектура распределения должностей обеспечивает горизонтальное расширение за счет сегментирования данных;
• Внедрение распределенных транзакций для обеспечения целостности, согласованности и долговечности данных;
• Расширить реляционную модель, ввести тип JSON и объединить преимущества модели документа;
• инвертированный индекс высокого ранга и новая стратегия сегментирования индекса поддерживают эффективный текстовый поиск и структурированный многомерный поиск;
• тип вектора высоты и соответствующий индекс вектора, обеспечивающие эффективный семантический поиск;
• Внедрение механизма MVCC, гарантирующего, что запросы не блокируются при записи;
• Провести соответствующую оптимизацию режима записи больших объемов данных в сценариях хранилищ данных;
• представлять Список,Улучшите степень сжатия данных,Эффективный векторизованный механизм выполнения,Обеспечивает возможность эффективной фильтрации и агрегирования. В то же время он обеспечивает возможность сосуществования строк и столбцов. Оптимизатор использует соответствующие режимы хранения и выполнения на основе выбора запроса;
• преполимеризация достоинства и материализованный вид,Оптимизатор разумно использует эти предварительно вычисленные данные.,Уменьшите объем вычислений во время запроса,Значительно улучшить производительность запросов.
2. Опыт
В только что приведенном примере Максвелла я упустил важную деталь: он не просто соединил вместе четыре совместимых уравнения, чтобы образовать систему уравнений. Он заметил, что электромагнитная индукция не оказывает соответствующего магнитного эффекта.,Отсутствие симметрии и изящества.,Я лишь внес «небольшую» модификацию в систему уравнений существования.,В последнее уравнение добавляется термин для тока смещения. это именно эта модификация,Решите задачу о противоречии между уравнениями и законом сохранения заряда. Именно из-за этой модификации,Именно тогда были созданы электромагнитные волны!
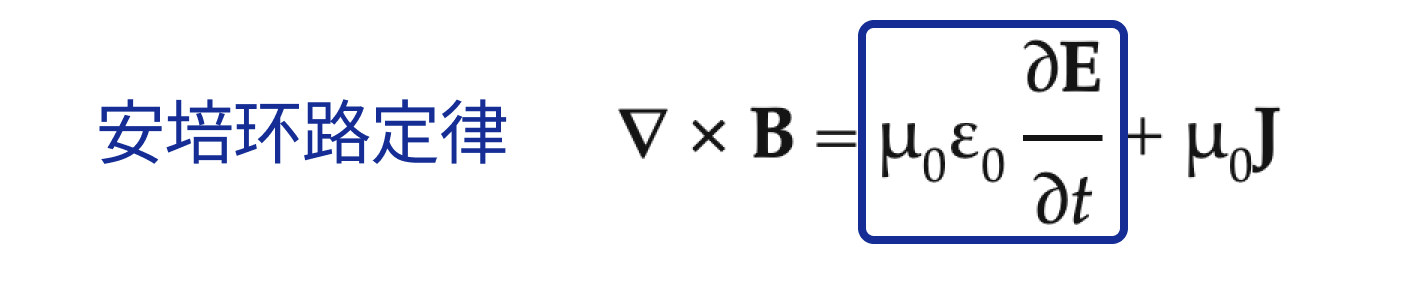
Просто реализовать эту серию технологий в одном продукте недостаточно.,Если пользователю необходимо внести множество корректировок параметров для разных сценариев,Продукт по-прежнему будет приносить пользователям фрагментацию. Чтобы удалить эти параметры,Система должна хорошо адаптироваться. Выше упомянуто несколько примеров оптимизации: оптимизатор решает использовать хранилище строк или хранилище столбцов на основе запроса.,Определите, можно ли использовать предварительно вычисленные данные; система выполняет одноэтапную оптимизацию фиксации в зависимости от того, является ли это транзакцией с одним компьютером. Но мы действительно должны хорошо провести опыт,Этого недостаточно,Все аспекты системы, от хранения и управления памятью до управления параллелизмом, должны быть разработаны с учетом адаптации.,Вместо того, чтобы рассматривать адаптацию как второстепенную оптимизацию. Эта способность подобна току совместного смещения Максвелла.,Он объединяет точечные возможности в различных продуктах данных.,Нарушая границы сцены,Предлагает совершенно новый продукт.
Когда один и тот же продукт используется в разных сценариях,Изоляция между различными рабочими нагрузками становится особенно важной. Изоляция может быть достигнута за счет мягкой изоляции на уровне программного обеспечения.,Заинтересованные читатели могут обратиться к HSAP статьи。Изоляция также может быть достигнута за счет жесткой изоляции на уровне ресурсов.выполнить,То есть разные запросы, которые необходимо изолировать, выполняются на разных вычислительных узлах. Но иногда на одних и тех же данных приходится разные рабочие нагрузки, которые необходимо изолировать.,Архитектура разделения хранения и вычислений позволяет легко добиться такой изоляции, позволяя различным вычислительным узлам читать одно и то же хранилище. Конечно, кроме изоляции.,Архитектура раздельного хранения и вычислений также дает множество преимуществ для эффективного использования ресурсов и быстрого расширения и сжатия.
Мы являемся свидетелями глубокой трансформации продуктов обработки данных. за последние двадцать лет,Вся отрасль стремится к повышению производительности,для удовлетворения растущих потребностей бизнеса. Однако,В настоящее время улучшение производительности больше не является ведущей силой перемен.。Поскольку проблемы с производительностью постепенно решаются,Это превратилось в основное, обязательное требование.,Больше не является серьезным препятствием для развития бизнеса. Поскольку эта основная потребность широко удовлетворяется,Начинают проявляться более глубокие потребности пользователей в продуктах.,Это стремление к опыту. будущее,Успех продуктов обработки данных будет все больше зависеть от обеспечения высокого качества обслуживания пользователей – это станет решающим критерием для дифференциации различных типов продуктов.。
5. Новая парадигма разработки данных
На данный момент у нас наконец-то есть совершенно новый продукт для обработки данных. – облачный роднойраспределенный Data Складская база. Появление этих новых продуктов знаменует собой возврат к основам управления данными.,Его концепция дизайна заключается в удовлетворении потребностей бизнеса.,Или Хранение или извлечение данных,Один продукт может обеспечить комплексное покрытие. Это основано на бизнес-принципе,Предоставьте пользователям возможность по-настоящему использовать данные и наслаждаться продуктами,Больше не попали в ловушку многочисленных информационных продуктов.
Эта новая парадигма значительно упростит архитектуру бизнес-данных, и пользователям не придется разбивать свой бизнес на отдельные данныхсцена、NoSQL Сцена, сцена поиска и сцена номерного склада. Используйте распределенный Data Warebase час,Порог использования данных был значительно снижен. Пользователи познакомятся с чрезвычайно упрощенным продуктом, обеспечиваемым системой с опытом адаптируемости.,Пусть потенциал данных будет раскрыт более просто и напрямую,Это значительно повышает гибкость бизнеса.
Принятие новой парадигмы не означает, что пользователи должны изучать совершенно новые технологии. Такие продукты данных могут быть разработаны так, чтобы быть совместимыми со зрелыми реляционными системами. данных(НапримерPostgreSQL)совместимый,Воспользуйтесь преимуществами его мощной экологии. Этот подход позволяет пользователям использовать новые технологии практически без необходимости обучения.,Наслаждайтесь преимуществами новых технологий,Не выходя из технической среды, с которой они уже знакомы и которым доверяют.
Давайте рассмотрим приложение B&B, упомянутое в начале статьи. Бизнес никогда не требовал использования нескольких продуктов для обработки данных. Так почему же первым инстинктом разработчика является разбиение требований к данным на несколько сценариев, а затем выбор подходящего для каждого. сценарий А как насчет продуктов данных? Это связано с тем, что все виды информационных продуктов, появившиеся за последние два десятилетия, имеют свои ограничения, и эти ограничения постоянно внушают пользователям мысль о том, что разные сценарии необходимо решать с помощью разных продуктов.

Я помню, как смотрел видео, где маленькая девочка впервые увидела бумажный журнал и попыталась увеличить его содержимое двумя пальцами. После нескольких неудач она наконец поняла: журнал — не более чем сломанный iPad! Возможно, однажды мы поймем, что нынешнее хранилище данных или база данных на самом деле представляет собой хранилище данных с неполными возможностями!
Об авторе:
Цзян Сяовэй (Протон База)
- Работал исследователем в Alibaba и основал Alibaba Cloud. Flink и Hologres командаипродукт
- Подается Facebook Система планирования, график и Messenger технический директор
- Подается Майкрософт SQL Server Инженер-архитектор
- Степень магистра теоретической физики Северо-Западного университета, степень бакалавра теоретической физики Университета науки и технологий Китая.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
