Изучите Apache Beam с Java

Автор | Фабио Хироки
Переводчик |
Планирование | Дин Сяоюнь
В этой статье мы представим Apache Beam, мощный проект с открытым исходным кодом для пакетной и потоковой обработки, используемый крупными компаниями, такими как eBay, для интеграции потоковых конвейеров и Mozilla для безопасного перемещения данных между системами.
Обзор
Apache Beam — это модель программирования для обработки данных, которая поддерживает как пакетную, так и потоковую обработку.
Вы можете разрабатывать конвейеры, используя предоставляемые им пакеты SDK для Java, Python и Go, а затем выбирать серверную часть, на которой будет запускаться конвейер.
Преимущества Apache Beam
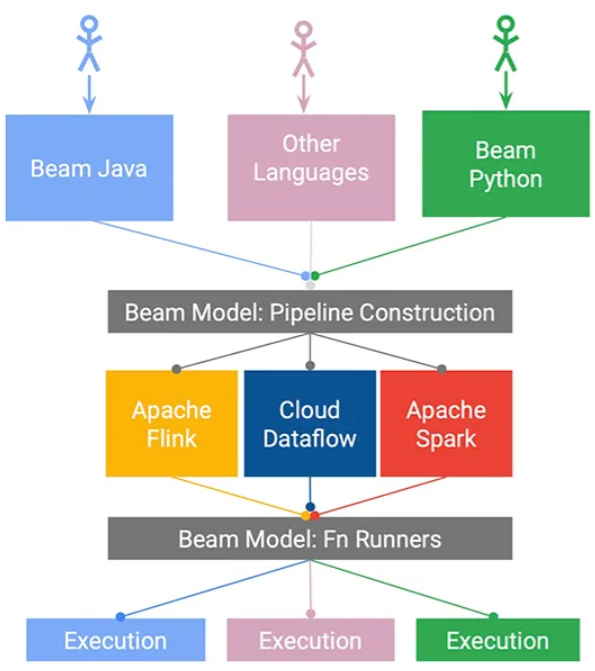
Модель программирования Beam
- Встроенный разъем ввода-вывода
- Разъем Apache Beam можно использовать для легкого извлечения и загрузки данных из нескольких типов хранилищ.
- Основные типы разъемов:
- На основе файлов (например, Apache Parquet, Apache Thrift);
- Файловые системы (например, Hadoop, Google Cloud Storage, Amazon S3);
- Обмен сообщениями (например, Apache Kafka, Google Pub/Sub, Amazon SQS);
- данные Библиотека(Например Apache Cassandra、Elastic Search、MongoDB)。
- Поскольку это проект OSS, поддержка новых коннекторов постоянно растет (например, InfluxDB, Neo4J).
- портативность:
- Beam предоставляет несколько Runner для запуска конвейеров, поэтому вы можете выбрать наиболее подходящий в зависимости от вашего сценария и избежать привязки к поставщику.
- Серверы распределенной обработки, такие как Apache Flink, Apache Spark или Google Cloud Dataflow, могут выступать в качестве Runner.
- Распределенная параллельная обработка:
- По умолчанию,Каждый элемент набора данных обрабатывается независимо.,Следовательно, оптимизация может осуществляться параллельно.
- Разработчикам не нужно вручную распределять нагрузку, поскольку Beam предоставляет для этого абстракцию.
Модель программирования Beam
Ключевые понятия модели программирования Beam:
- PCollection: сбор данных, представляющих данные, такие как число или множество слов, извлеченных из текста.
- PTransform: функция преобразования, которая получает и возвращает PCollection, например сумму всех чисел.
- Конвейер: управляет взаимодействием между PTransform и PCollection.
- PipelineRunner: указывает, где и как должен выполняться конвейер.
Быстрый старт
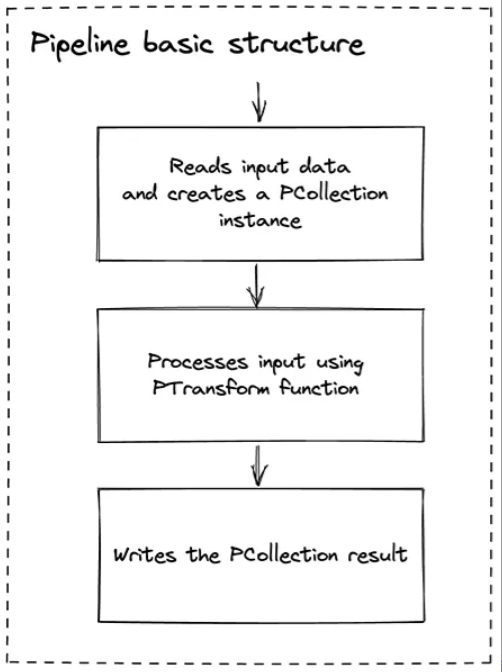
Базовая операция конвейера состоит из трех этапов: чтение, обработка и запись результатов преобразования. Каждый шаг здесь определяется программно с использованием SDK, предоставленного Beam.
В этом разделе мы создадим конвейер с использованием Java SDK. Вы можете создать локальное приложение (созданное с помощью Gradle или Maven) или использовать онлайн-песочницу. В примере будет использоваться локальный Runner, поскольку результаты легче проверять с помощью утверждений JUnit.
Собственные зависимости Java
- луч-sdk-java-core: содержит все классы модели Beam.
- beam-runners-direct-java: по умолчанию Beam SDK будет напрямую использовать локальный Runner, что означает, что конвейер будет работать на локальном компьютере.
Операция умножения на 2
В первом примере канал получит массив чисел и умножит каждый элемент на 2.
Первым шагом является создание экземпляра конвейера, который будет получать входной массив и выполнять функцию преобразования. Поскольку мы используем JUnit для запуска Beam, мы можем легко создать TestPipeline и сделать его полем тестового класса. Если вы предпочитаете использовать основной метод, вам необходимо установить параметры конфигурации конвейера.
@Rulepublic final transient TestPipeline pipeline = TestPipeline.create();Теперь мы можем создать PCollection в качестве входных данных для канала. Это массив, экземпляр которого создается непосредственно в памяти, но его также можно прочитать из любого места, поддерживающего Beam.
PCollection<Integer> numbers = pipeline.apply(Create.of(1, 2, 3, 4, 5));Затем мы применяем нашу функцию преобразования, умножая каждый элемент на 2.
PCollection<Integer> output = numbers.apply( MapElements.into(TypeDescriptors.integers()) .via((Integer number) -> number * 2) );Чтобы проверить результат, мы можем написать утверждение.
PAssert.that(output) .containsInAnyOrder(2, 4, 6, 8, 10);Обратите внимание, что результаты не сортируются, поскольку Beam параллельно обрабатывает каждый элемент как отдельный элемент.
На этом тест завершен, мы запускаем конвейер, вызвав следующий метод:
pipeline.run();Сокращение операций
Операция сокращения объединяет несколько входных элементов для создания меньшего набора, обычно содержащего только один элемент.
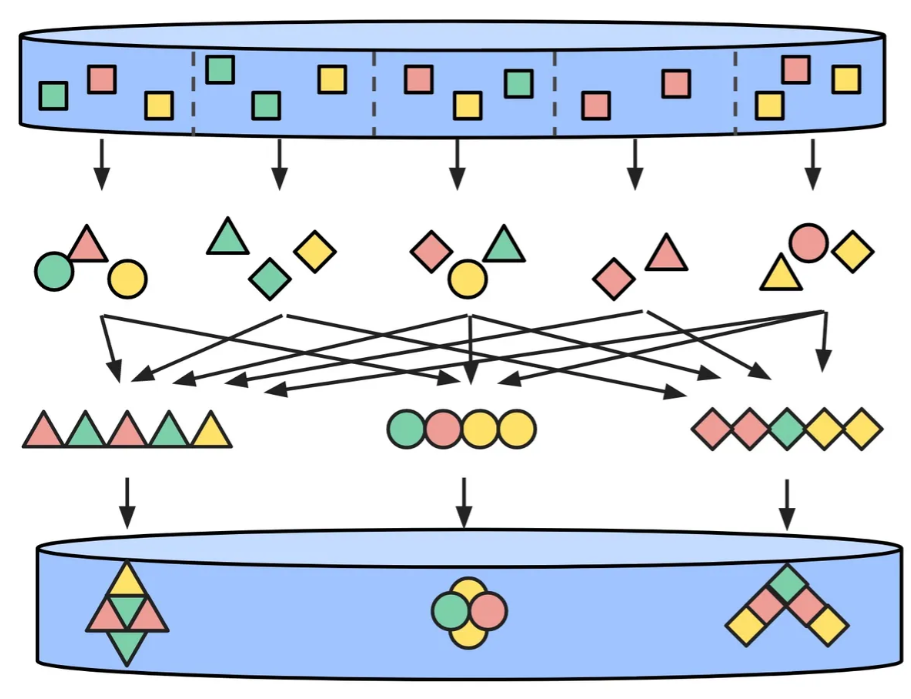
MapReduce
Теперь давайте расширим приведенный выше пример, умножив все члены на 2, а затем суммировав их, в результате чего получится операция преобразования MapReduce.
Каждое преобразование PCollection создает новый экземпляр PCollection, что означает, что мы можем объединить преобразования вместе, используя метод apply. В этом примере операция Sum будет использоваться после умножения каждого элемента на 2:
PCollection<Integer> numbers = pipeline.apply(Create.of(1, 2, 3, 4, 5));
PCollection<Integer> output = numbers .apply( MapElements.into(TypeDescriptors.integers()) .via((Integer number) -> number * 2)) .apply(Sum.integersGlobally());
PAssert.that(output) .containsInAnyOrder(30);
pipeline.run();Операции FlatMap
FlatMap сначала применяет сопоставление к каждому входному элементу и возвращает новую коллекцию, в результате чего создается коллекция коллекций. Затем примените операцию Flat, чтобы объединить все вложенные коллекции и, наконец, создать коллекцию.
В следующем примере массив строк преобразуется в массив, содержащий уникальные слова.
Сначала мы объявляем список слов, которые будут вводиться в канал:
final String[] WORDS_ARRAY = new String[] { "hi bob", "hello alice", "hi sue"};
final List<String> WORDS = Arrays.asList(WORDS_ARRAY);Затем мы создаем входную PCollection, используя приведенный выше список:
PCollection<String> input = pipeline.apply(Create.of(WORDS));Теперь мы выполняем преобразование FlatMap, которое разделит слова в каждом вложенном массиве и объединит результаты в список:
PCollection<String> output = input.apply( FlatMapElements.into(TypeDescriptors.strings()) .via((String line) -> Arrays.asList(line.split(" "))));
PAssert.that(output) .containsInAnyOrder("hi", "bob", "hello", "alice", "hi", "sue");
pipeline.run();Групповая операция
Распространенной задачей обработки данных является агрегирование или подсчет на основе определенных ключей. Мы посчитаем, сколько раз каждое слово встречается в предыдущем примере.
После того, как у нас есть сглаженный массив строк, мы можем связать еще один PTransform:
PCollection<KV<String, Long>> output = input .apply( FlatMapElements.into(TypeDescriptors.strings()) .via((String line) -> Arrays.asList(line.split(" "))) ) .apply(Count.<String>perElement());дает результат:
PAssert.that(output).containsInAnyOrder( KV.of("hi", 2L), KV.of("hello", 1L), KV.of("alice", 1L), KV.of("sue", 1L), KV.of("bob", 1L));прочитать из файла
Один из принципов Beam заключается в том, что данные можно читать откуда угодно, поэтому давайте посмотрим, как на практике использовать текстовые файлы в качестве источников данных.
В следующем примере считывается файл «words.txt», содержащий текст «Расширенная модель унифицированного программирования». Затем функция преобразования вернет PCollection, содержащую каждое слово.
PCollection<String> input = pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));
PCollection<String> output = input.apply( FlatMapElements.into(TypeDescriptors.strings()) .via((String line) -> Arrays.asList(line.split(" "))));
PAssert.that(output) .containsInAnyOrder("An", "advanced", "unified", "programming", "model");
pipeline.run();Запись результатов в файл
Как видно из предыдущего примера ввода, Beam предоставляет несколько встроенных выходных разъемов. В следующем примере мы посчитаем количество каждого слова, которое появляется в текстовом файле «words.txt» (который содержит только одно предложение «Расширенная модель унифицированного программирования»), и выходные данные будут записаны в текстовый файл.
PCollection<String> input = pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));
PCollection<KV<String, Long>> output = input .apply( FlatMapElements.into(TypeDescriptors.strings()) .via((String line) -> Arrays.asList(line.split(" "))) ) .apply(Count.<String>perElement());;
PAssert.that(output) .containsInAnyOrder( KV.of("An", 1L), KV.of("advanced", 1L), KV.of("unified", 1L), KV.of("programming", 1L), KV.of("model", 1L) );
output .apply( MapElements.into(TypeDescriptors.strings()) .via((KV<String, Long> kv) -> kv.getKey() + " " + kv.getValue())) .apply(TextIO.write().to("./src/main/resources/wordscount"));
pipeline.run();По умолчанию запись файлов также оптимизирована для параллелизма, а это означает, что Beam определит оптимальное количество шардов (файлов) для сохранения результатов. Эти файлы расположены в папке src/main/resources, а имена файлов включают префикс «wordcount», номер фрагмента и общее количество фрагментов.
Запустив его на моем ноутбуке, я получил 4 осколка:
Первый осколок (имя файла:wordscount-00001-of-00003):
An 1advanced 1Второй осколок (имя файла:wordscount-00002-of-00003):
unified 1model 1Третий осколок (имя файла:wordscount-00003-of-00003):
programming 1Последний осколок пуст, поскольку все слова обработаны.
Удлинить луч
Мы можем расширить Beam, написав собственные функции преобразования. Пользовательские преобразователи улучшат удобство сопровождения кода и устранят дублирование усилий.
По сути, нам нужно создать подкласс PTransform и объявить типы ввода и вывода как дженерики Java. Затем переопределите метод расширения и добавьте нашу логику, которая будет принимать одну строку и возвращать PCollection, содержащую каждое слово.
public class WordsFileParser extends PTransform<PCollection<String>, PCollection<String>> {
@Override public PCollection<String> expand(PCollection<String> input) { return input .apply(FlatMapElements.into(TypeDescriptors.strings()) .via((String line) -> Arrays.asList(line.split(" "))) ); } }Использование WordsFileParser для реконструкции тестового сценария становится следующим:
public class FileIOTest {
@Rule public final transient TestPipeline pipeline = TestPipeline.create();
@Test public void testReadInputFromFile() { PCollection<String> input = pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));
PCollection<String> output = input.apply( new WordsFileParser() );
PAssert.that(output) .containsInAnyOrder("An", "advanced", "unified", "programming", "model");
pipeline.run(); }
@Test public void testWriteOutputToFile() { PCollection<String> input = pipeline.apply(TextIO.read().from("./src/main/resources/words.txt"));
PCollection<KV<String, Long>> output = input .apply(new WordsFileParser()) .apply(Count.<String>perElement());
PAssert.that(output) .containsInAnyOrder( KV.of("An", 1L), KV.of("advanced", 1L), KV.of("unified", 1L), KV.of("programming", 1L), KV.of("model", 1L) );
output .apply( MapElements.into(TypeDescriptors.strings()) .via((KV<String, Long> kv) -> kv.getKey() + " " + kv.getValue())) .apply(TextIO.write().to ("./src/main/resources/wordscount"));
pipeline.run(); }}В результате получается более чистый и модульный конвейер.
временное окно
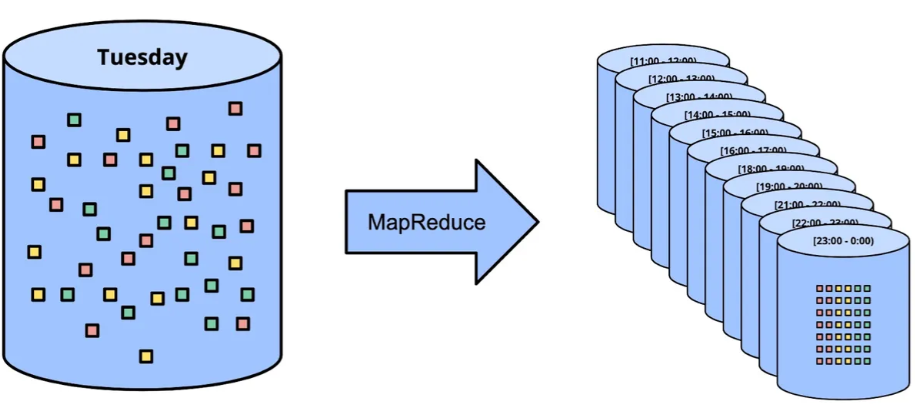
Временное окно луча
Распространенной проблемой потоковой передачи является группировка входящих данных по определенным временным интервалам, особенно при обработке больших объемов данных. В этом случае более полезно анализировать совокупные данные за час или день, а не анализировать каждый элемент набора данных.
В приведенном ниже примере мы предположим, что находимся в сфере финансовых технологий и получаем события, содержащие сумму и время транзакции, и хотим получить общее количество транзакций в день.
Beam предоставляет возможность украсить каждый элемент PCollection меткой времени. Мы можем создать PCollection, представляющую 5 транзакций, следующим образом:
- Суммы 10 и 20 были перечислены 1 февраля 2022 года;
- Суммы 30, 40 и 50 были переведены 05.02.2022.
PCollection<Integer> transactions = pipeline.apply( Create.timestamped( TimestampedValue.of(10, Instant.parse("2022-02-01T00:00:00+00:00")), TimestampedValue.of(20, Instant.parse("2022-02-01T00:00:00+00:00")), TimestampedValue.of(30, Instant.parse("2022-02-05T00:00:00+00:00")), TimestampedValue.of(40, Instant.parse("2022-02-05T00:00:00+00:00")), TimestampedValue.of(50, Instant.parse("2022-02-05T00:00:00+00:00")) ) );Далее мы применим две функции преобразования:
- Используйте однодневный временной интервал для группировки транзакций;
- Сложите количества в каждой группе.
PCollection<Integer> output = Transactions .apply(Window.into(FixedWindows.of(Duration.standardDays(1)))) .apply(Combine.globally(Sum.ofIntegers()).withoutDefaults());Ожидается, что в первом временном окне (01 февраля 2022 г.) общая сумма составит 30 (10+20), а во втором окне (05 февраля 2022 г.) мы должны увидеть общую сумму 120 ( 30 +40+50).
PAssert.that(output) .inWindow(new IntervalWindow( Instant.parse("2022-02-01T00:00:00+00:00"), Instant.parse("2022-02-02T00:00:00+00:00"))) .containsInAnyOrder(30);
PAssert.that(output) .inWindow(new IntervalWindow( Instant.parse("2022-02-05T00:00:00+00:00"), Instant.parse("2022-02-06T00:00:00+00:00"))) .containsInAnyOrder(120);Каждый экземпляр IntervalWindow должен точно соответствовать временным меткам начала и окончания выбранного периода времени, поэтому выбранное время должно быть «00:00:00».
Подвести итог
Beam — это мощная, проверенная в боевых условиях платформа данных, поддерживающая как пакетную, так и потоковую обработку. Мы использовали Java SDK для таких операций, как отображение, сокращение, группирование и временное окно.
Beam идеально подходит для разработчиков, выполняющих параллельные задачи и способных упростить механизм крупномасштабной обработки данных.
Его разъемы, SDK и поддержка различных Runners обеспечивают нам гибкость. Вам нужно всего лишь выбрать собственный Runner, например Google Cloud Dataflow, чтобы реализовать автоматическое управление вычислительными ресурсами.
Об авторе:
Фабио Хироки — инженер-программист, работающий в сфере финансовых услуг в Mollie Corporation.
Оригинальная ссылка:
https://www.infoq.com/articles/apache-beam-intro/
нажмите внизу Прочитайте оригинальную статью доступ InfoQ Официальный сайт для более интересного контента!
Рекомендуемые статьи сегодня
Цифровизация — это не то, что вы пробуете, это то, что вы пробуете | Xingzhi Digital China
Эту любовь можно запомнить: золотой век Java-версии для Mac
Глобальные изменения в облачных вычислениях и история Китая

Нажмите один, чтобы увидеть меньше bug 👇



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
