Избегайте JVM и помогите оптимизировать код Java на уровне кода.
Предисловие
В Java, когда упоминается слово «оптимизация», многие люди в первую очередь думают об оптимизации JVM. Действительно, JVM предоставляет множество параметров, делающих оптимизацию более интуитивно понятной. Например, мы можем настроить загрузочную память программы через Xms и Xmx. -XX:+UseG1GCмы можем использоватьG1сборщик мусора。
В моей разработке больших данных я столкнулся с преобразованием данных и доступом к большим объемам данных. Чтобы избежать OOM программы, помимо добавления хоста обработки на ранней стадии, позже была проведена дополнительная оптимизация на уровне кода. Итак, сегодня я рассмотрю, какие оптимизации я могу сделать на уровне кода во время разработки кода.
собирать
В Java мы чаще используем список, набор и карту. Возьмем, к примеру, список. Часто используемые классы реализации включают ArrayList и LinkedList. Для выбора этих двух списков нам все равно необходимо сделать это на основе реального бизнеса.
Когда я изучал структуру данных в колледже,,написано в книгеМассивы имеют быстрый доступ,Но удаление и добавление затруднены. Доступ к связанным спискам медленный.,Но удаление и добавление происходят быстро。В то время я вообще не понял этого предложения.,Позже я постепенно понял эту истину во время разработки кода.
ArrayList
ArrayListИспользовать массивelementDataхранить данные。
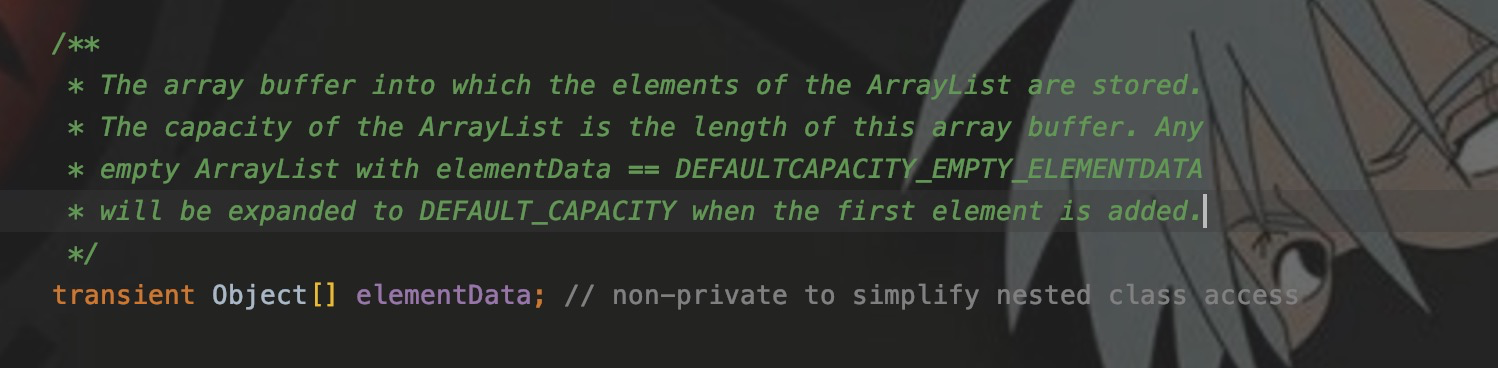
Для массива использование нижнего индекса для прямого доступа к элементам не требует обхода всего массива, а временная сложность равна 0(1). Если вы удалите или добавите элемент, индексы последующих элементов будут изменены. Например, если вы удалите элемент с индексом 7, то элемент с индексом 8 переместится вперед на 1 и станет элементом с индексом 7, а затем станет элементом с индексом 7. всем элементом. Двигайтесь вперед.
Итак, при удалении ArrayList,использоватьarrayCopyнапрямуюelementDataвторая половина данных,Переместитесь вперед на одну позицию.
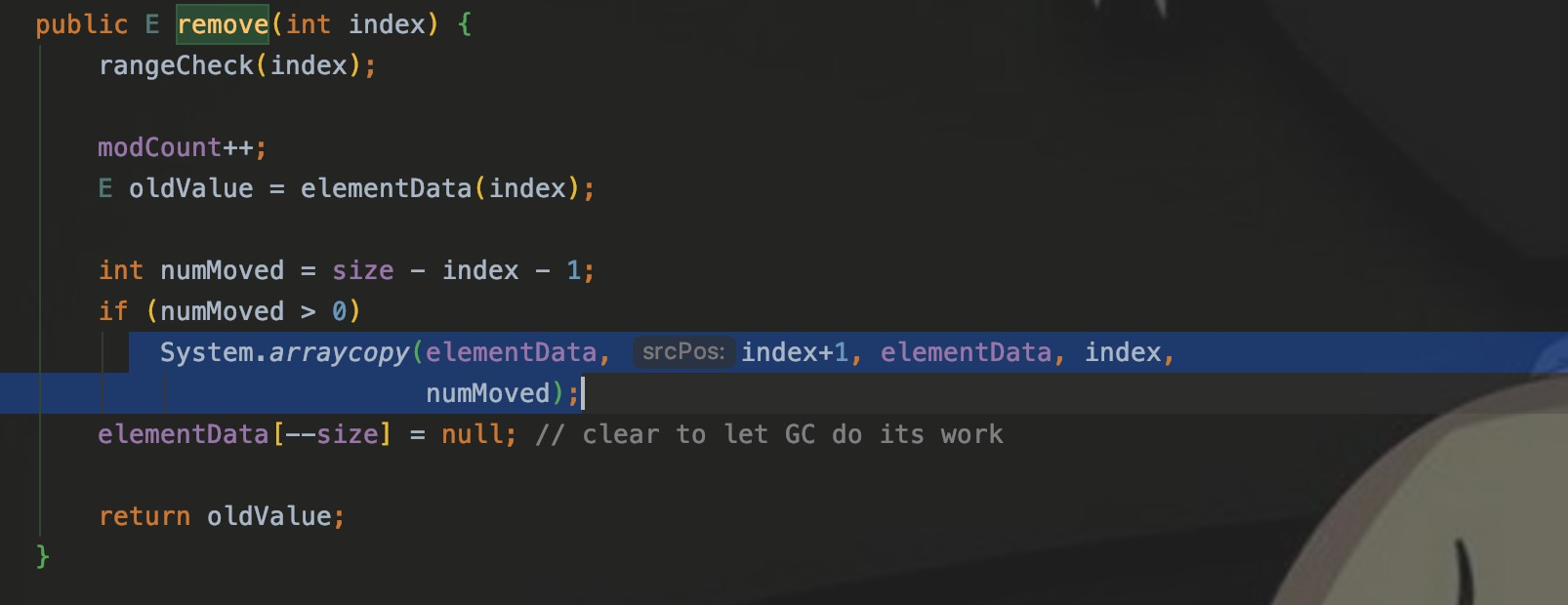
Поэтому каждый раз, когда вы удаляете или добавляете данные, вы должны вызывать arrayCopy для копирования массива.
LinkedList
Для LinkedList структура хранения — Node, и будет первый головной узел и последний хвостовой узел.
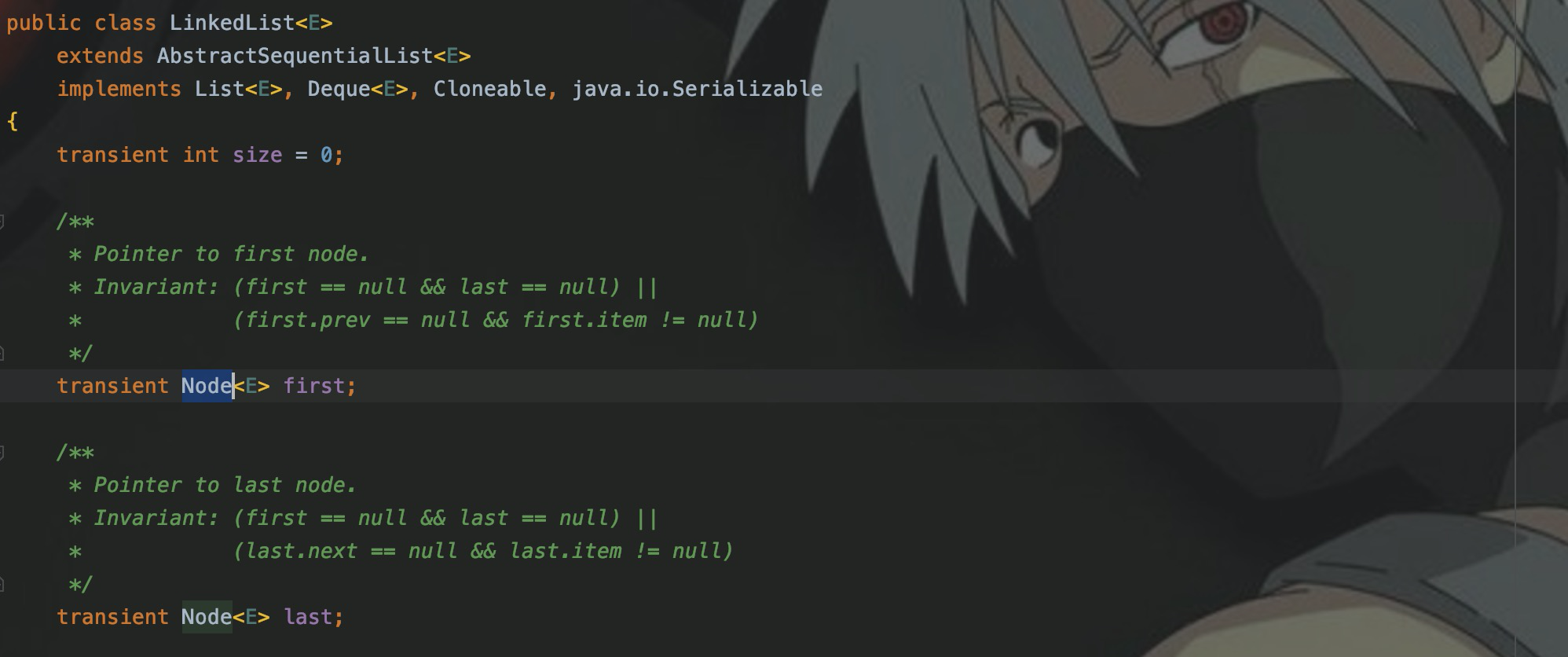
Для каждого объекта Node будет предыдущий узел, указывающий на предыдущий узел, и следующий узел-преемник, указывающий на следующий узел.
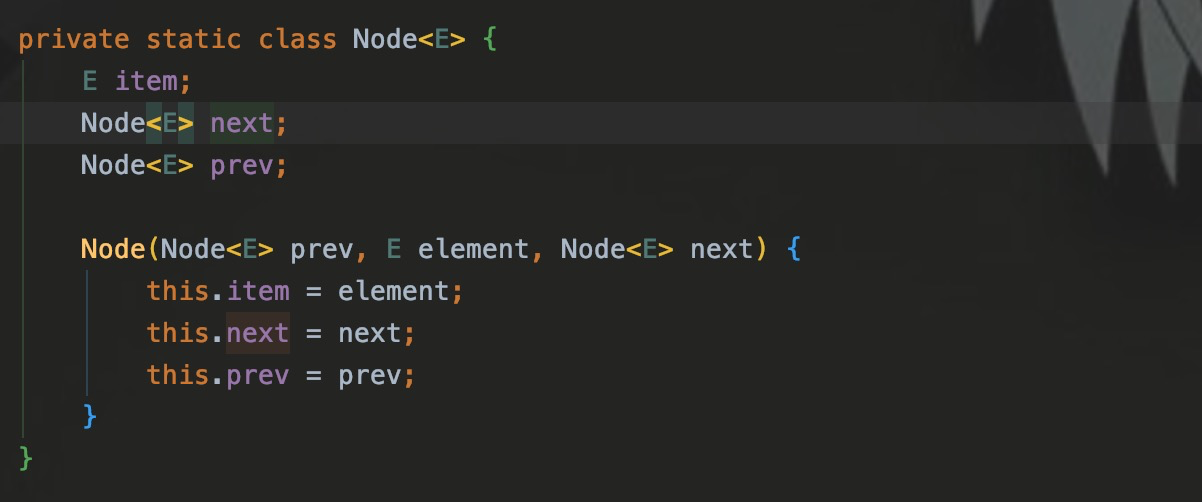
Структура хранения связанного списка примерно такая: у головного узла нет предыдущего узла, а у основного узла нет следующего узла-преемника. Кроме того, у каждого узла есть предыдущий и следующий узлы.
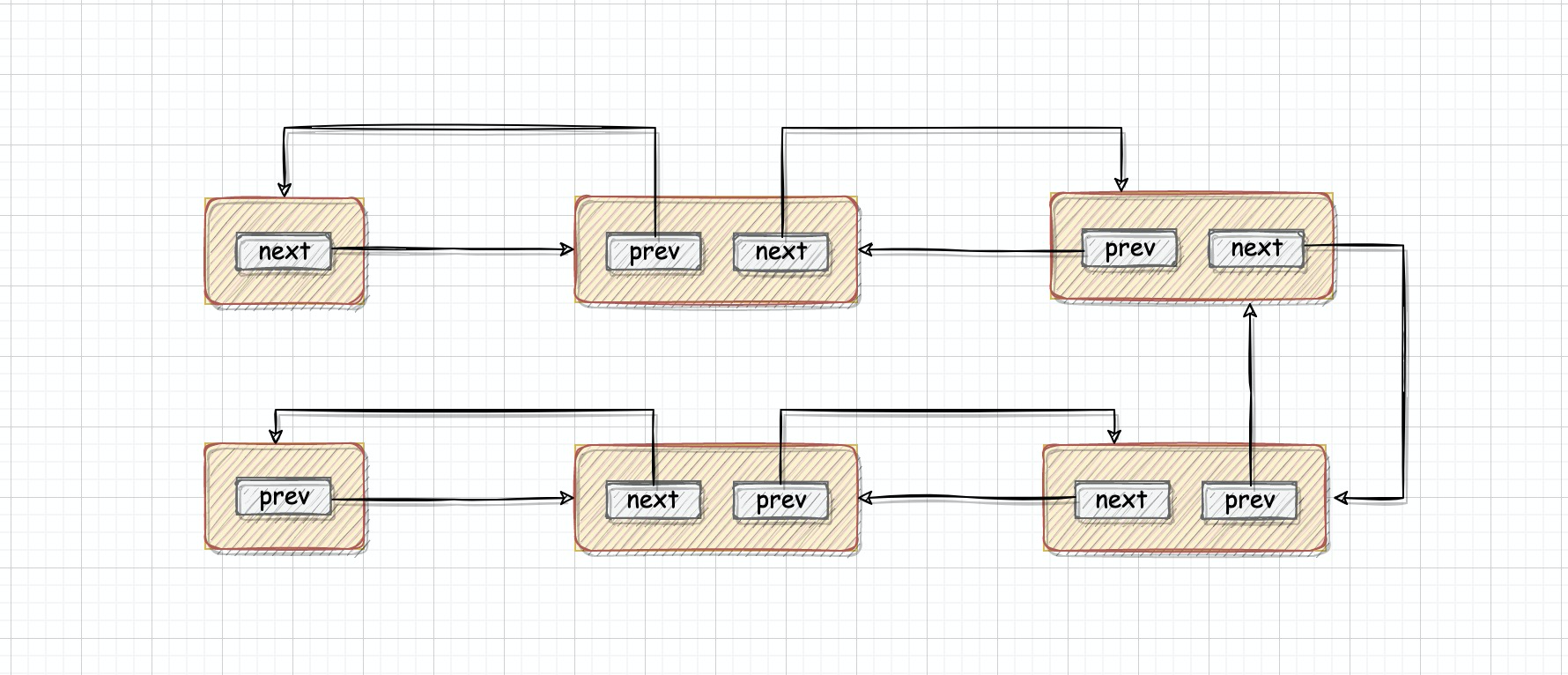
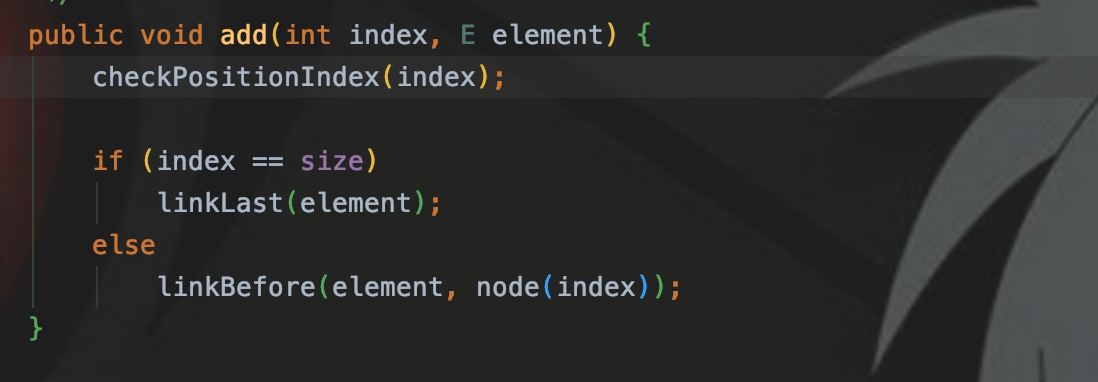
В LinkedList при вставке по указанному индексу, если индекс и размер равны, это означает, что вставка происходит в конец, то есть вставляется конечный узел. Если нет, вызовите linkBefore, чтобы вставить узел.
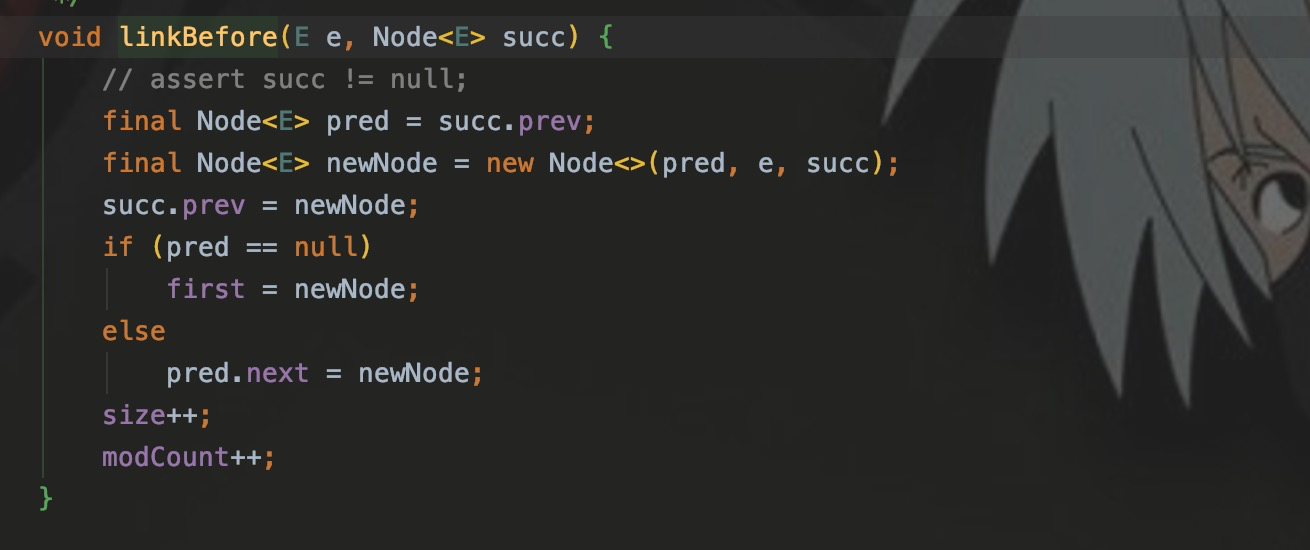
В linkeBefore мы видим, что когда узел добавляется в нижний индекс в связанном списке, предыдущий узел индекса будет изменен на новый узел, а следующий из исходного предыдущего узла индекса указывает на новый. узел. Для нового узла next указывает на индексный узел, а prev указывает на исходный предыдущий узел индексного узла.
Процесс показан на рисунке:
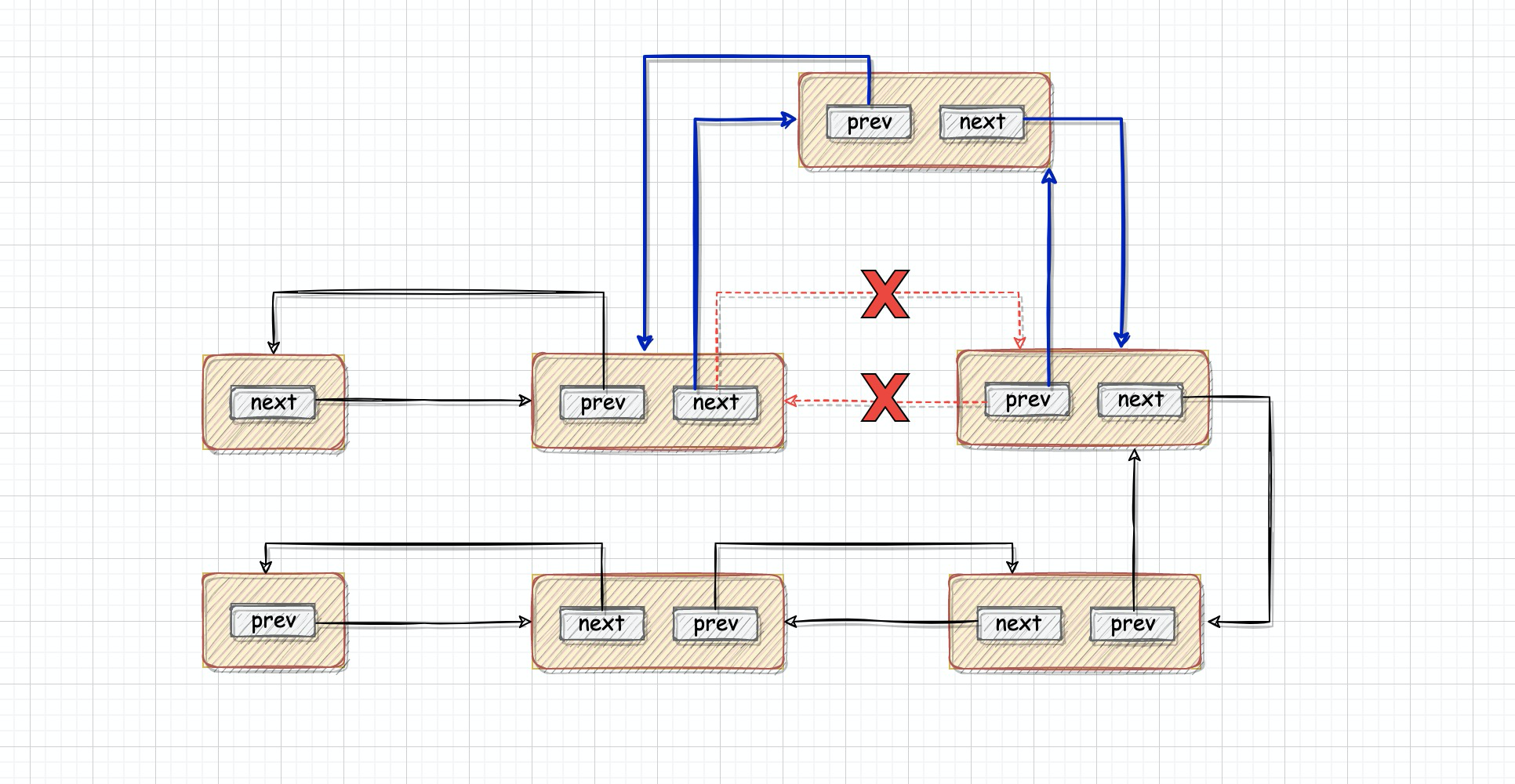
Таким образом, когда LinkedList добавляет или удаляет элементы,,Нет необходимости делать копирование данных и смещение индекса,Необходимо изменить только несколько узловprevиnextузла достаточно。Поэтому при выборе списка,Если имеется много операций запроса,Просто выберите ArrayList,Удалить или добавить дополнительные элементы,Просто выберите LinkedList.
Map
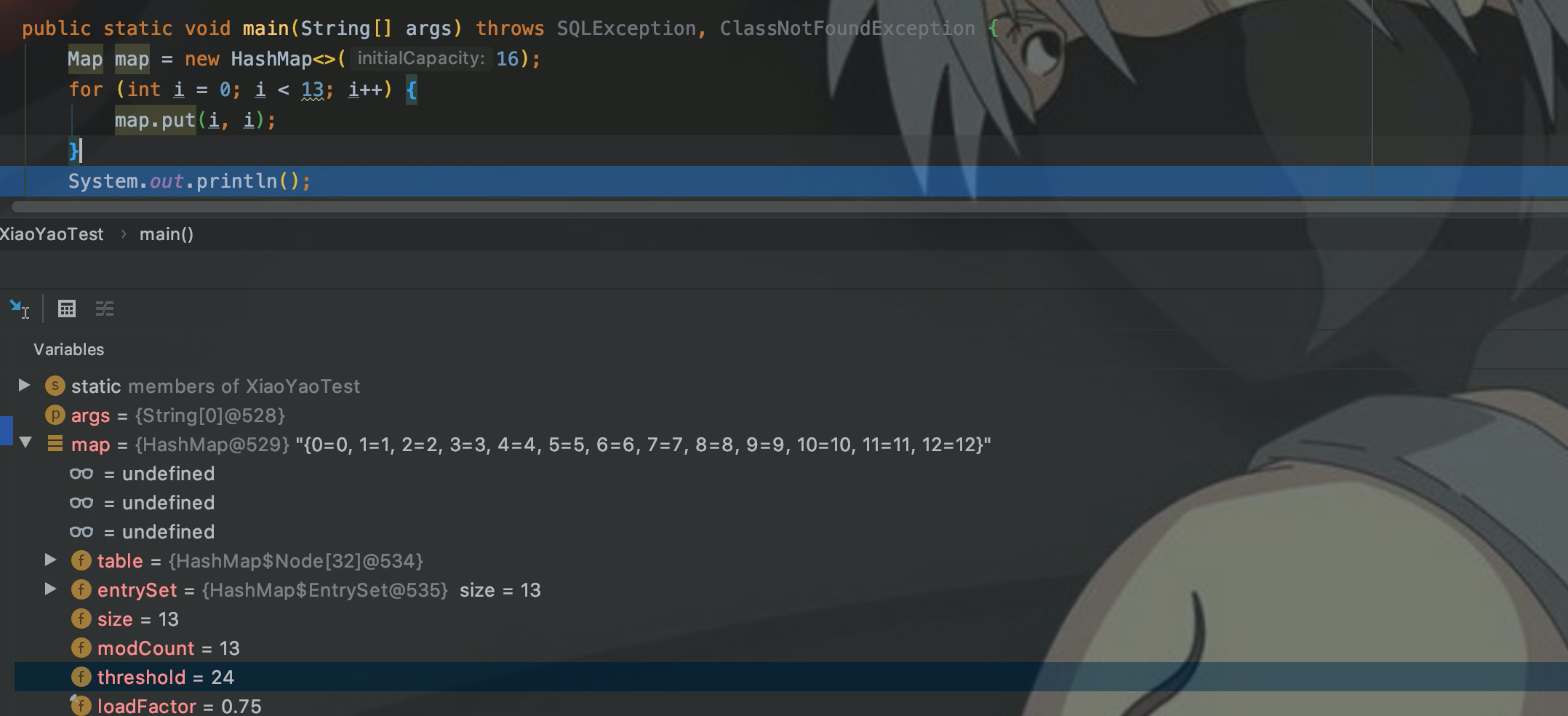
Для Map главное обратить внимание на инициализацию емкости Map. Емкость по умолчанию — 16, а loadFactor — 0,75.

Я создаю новый HashMap, а затем вставляю данные. Вы можете найти его через точки останова, когда ++size. > порог, вызовите изменение размера, чтобы расширить емкость.
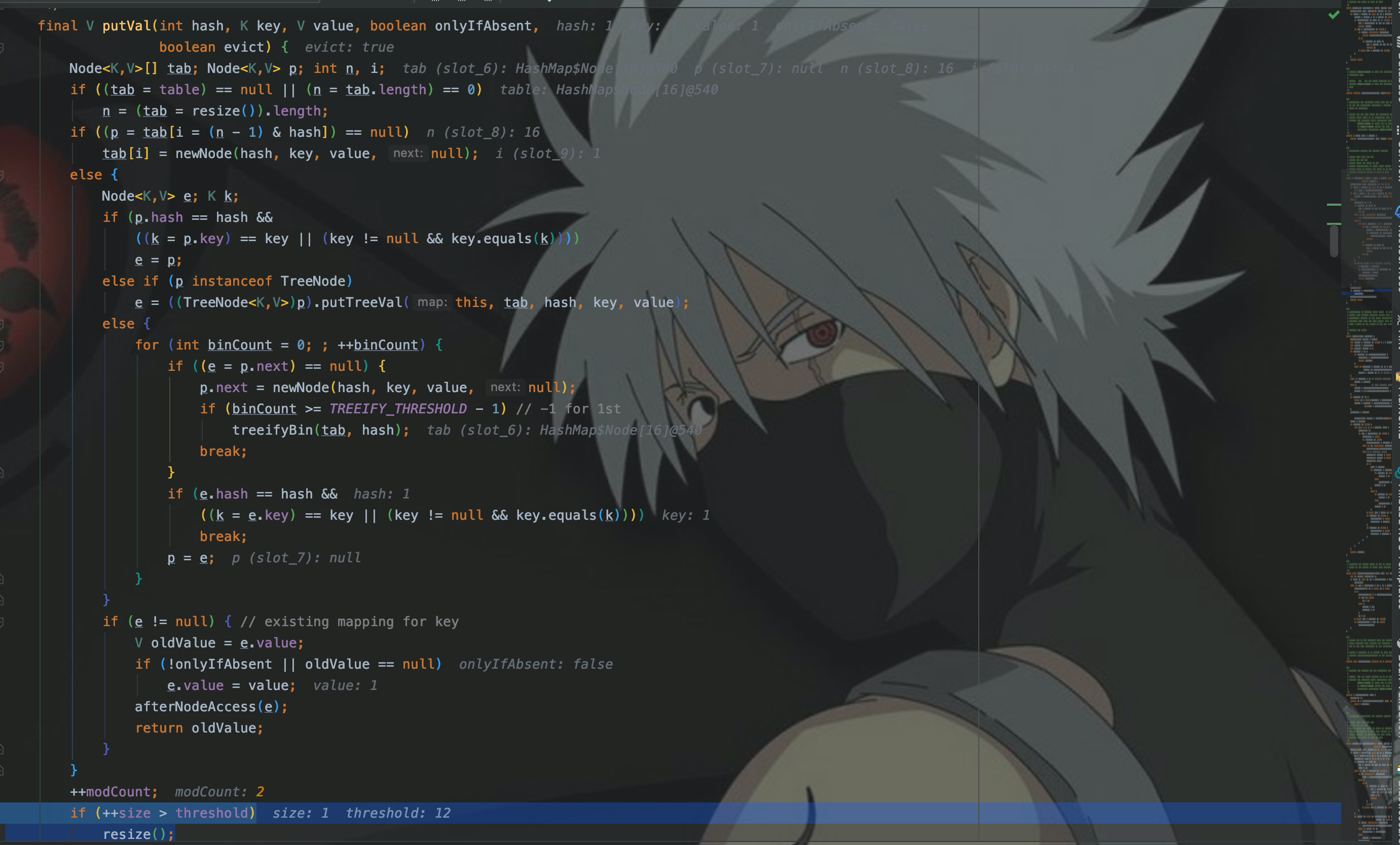
ТакthresholdОткуда это взялось?путем спариванияmapемкостьcapacity loadFactor* приходит.
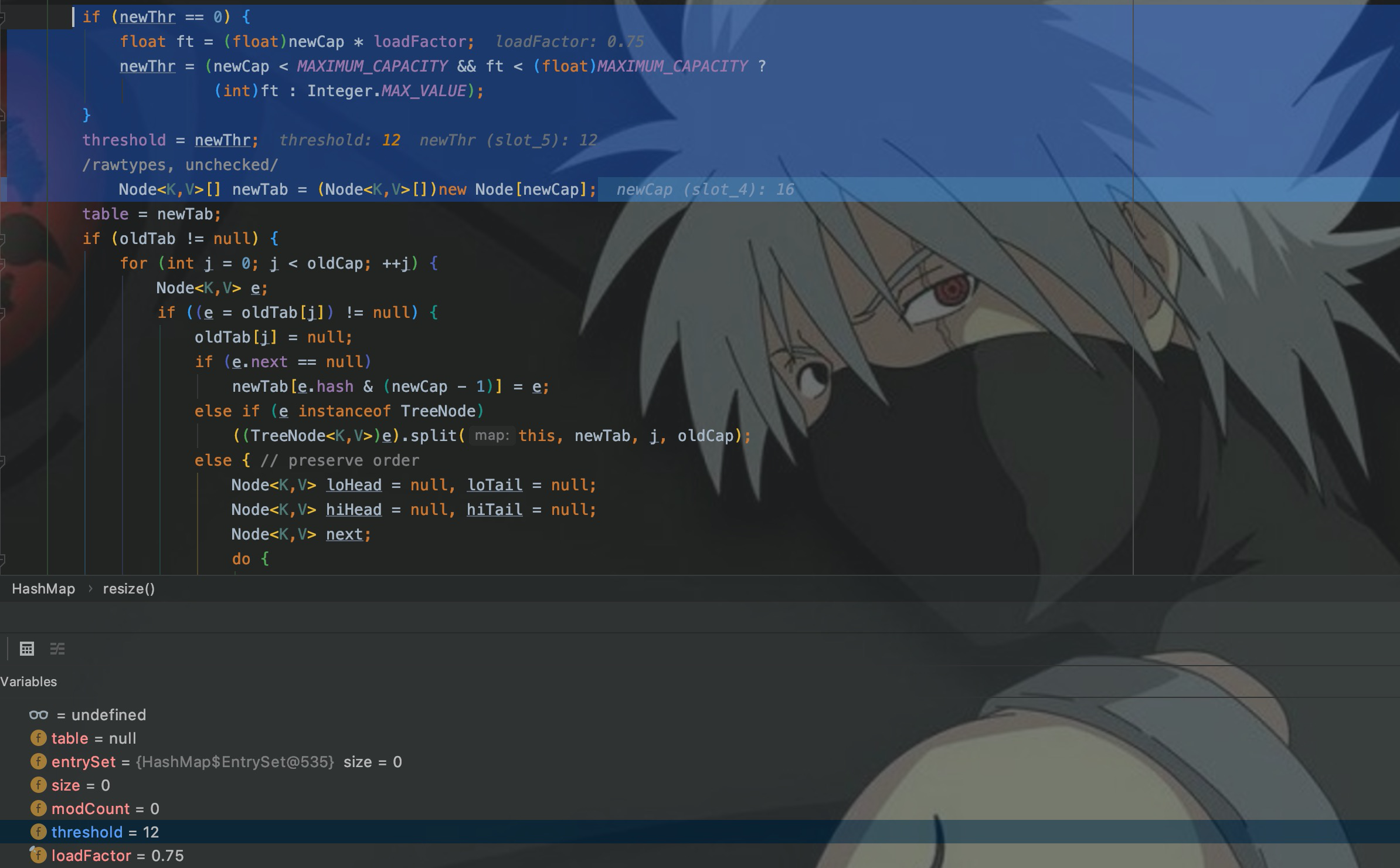
Другими словами, карта с емкостью 16 может хранить только 12 элементов. Когда сохраняется 13-й элемент, емкость будет расширена. В это время порог становится 24, а емкость равна 24/0,75 = 32. расширение в 2 раза.
в изменении размера(),newCapУказывает на новую емкость,Алгоритм расширения основан на oldCap,<<Сдвиг вправо на одну позицию,Это *2.
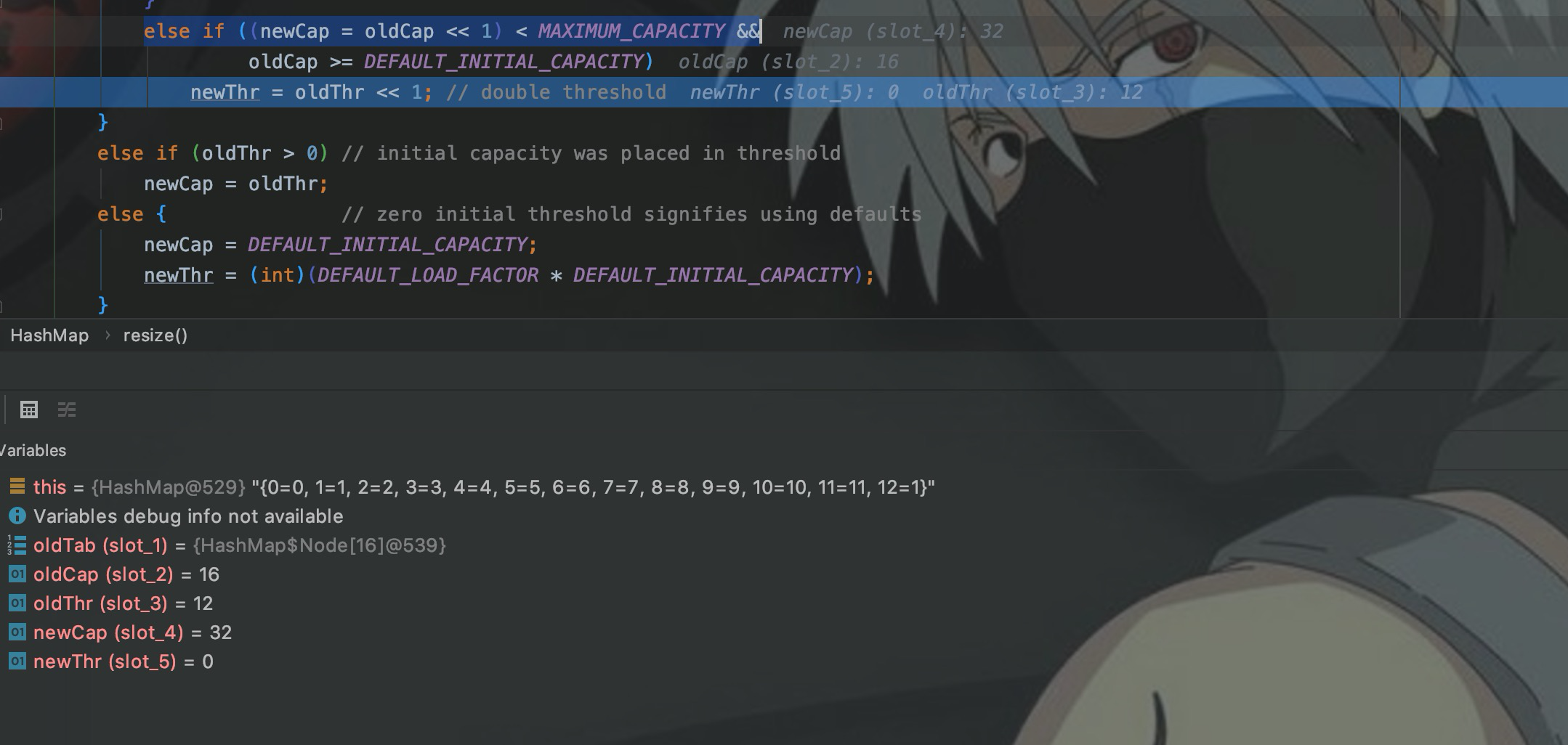
После расширения для карты будет создана новая структура данных Node емкостью 32, а затем элементы исходного Node из 16 будут скопированы в новый Node.
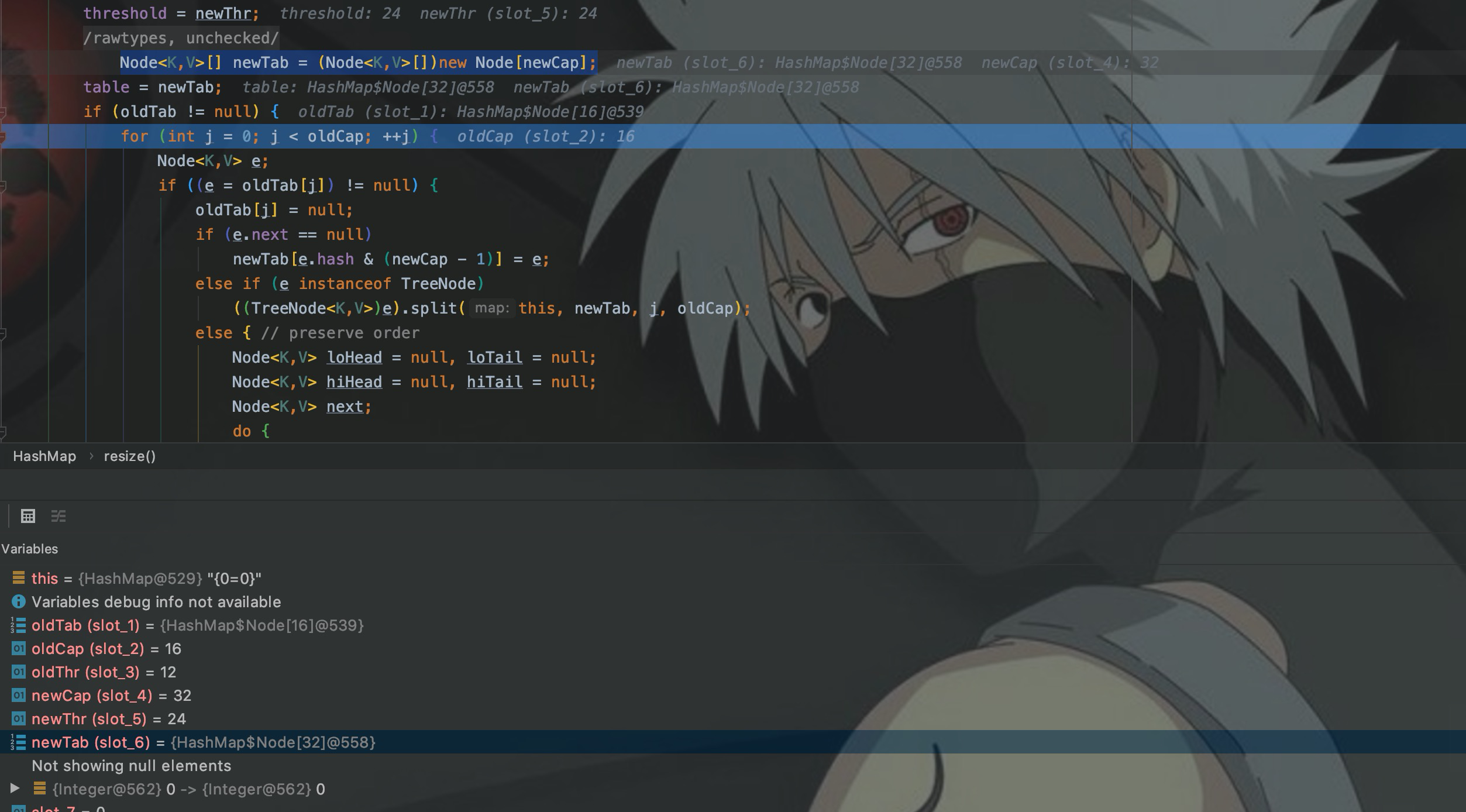
Поэтому при использовании карты необходимо оценить количество сохраняемых элементов, а затем указать начальный размер, чтобы избежать проблем с производительностью, вызванных расширением.
ConcurrentLinkedQueue
Я столкнулся с таким сценарием: получение данных в Kafka и их последующая обработка. Однако раздел в какфе может быть использован только одним потоком, поэтому количество потоков не превышает количества разделов. Но эти потоки не могут удовлетворить мои потребности в производительности обработки.
Таким образом, код логики потребления и обработки данных Kafka разделен.,Сначала используйте небольшое количество потоков для использования Kafka.,Поместить данные в очередь,Затем модуль обработки данных считывает очередь на потребление. Чтобы обеспечить безопасность данных потока при высоком параллелизме,использовать了ConcurrentLinkedQueue。
Преимущество ConcurrentLinkedQueue в том, что он не требует блокировки. В poll() нет блокировки (синхронизированной, блокировки и т. д.).
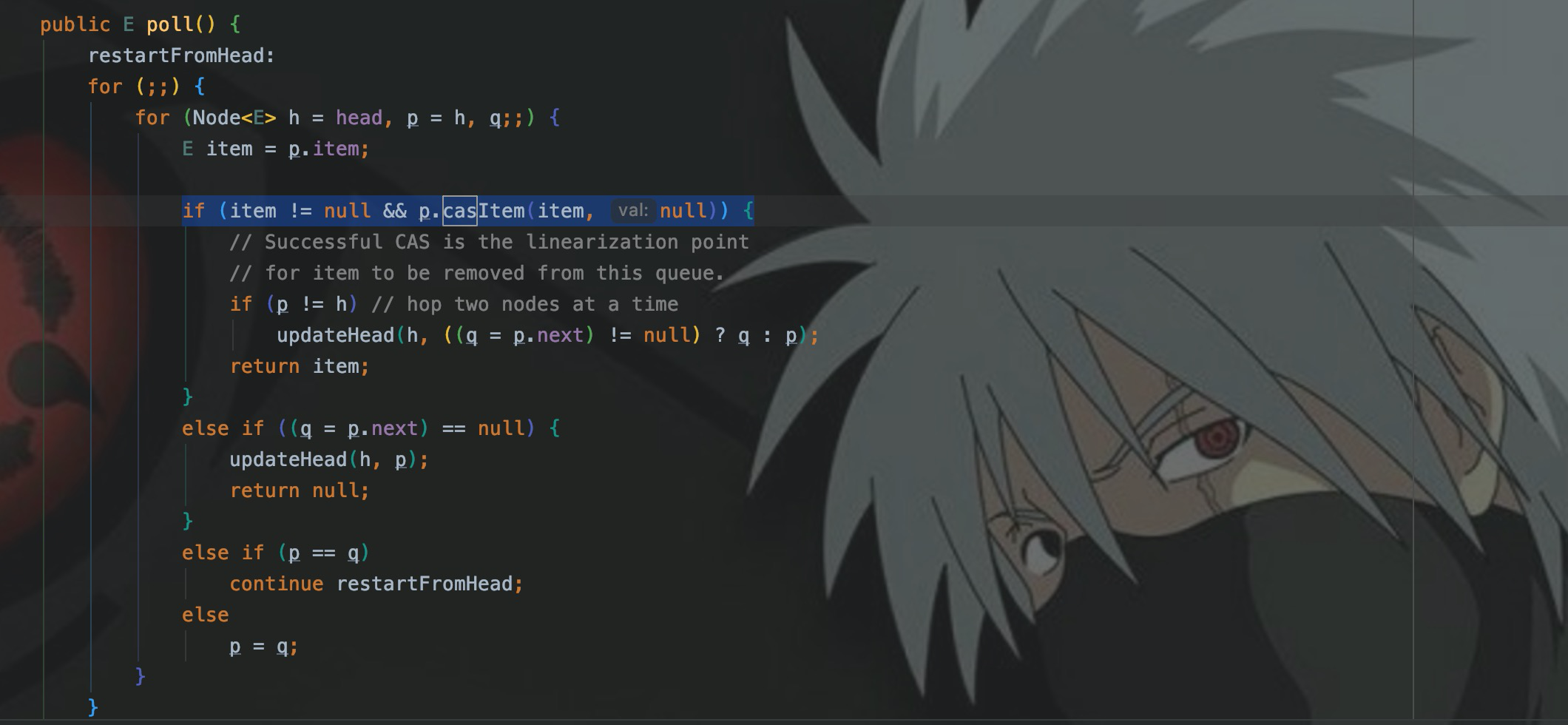
Итак, как ConcurrentLinkedQueue обеспечивает потокобезопасность? Это подводит нас к CAS, показанному на картинке выше.
CAS
CAS, сравни и поменяй местами, первый раз я с ним столкнулся на уроке Atomic Java. CAS — это не блокировка, а инструкция атомарной операции, предоставляемая ЦП. Класс UnSafe напрямую используется для реализации атомарной операции на аппаратном уровне для решения проблемы ABA.
Метод casItem вызывается в poll().,иcasItemЗвонокUNSAFE.compareAndSwapObject。
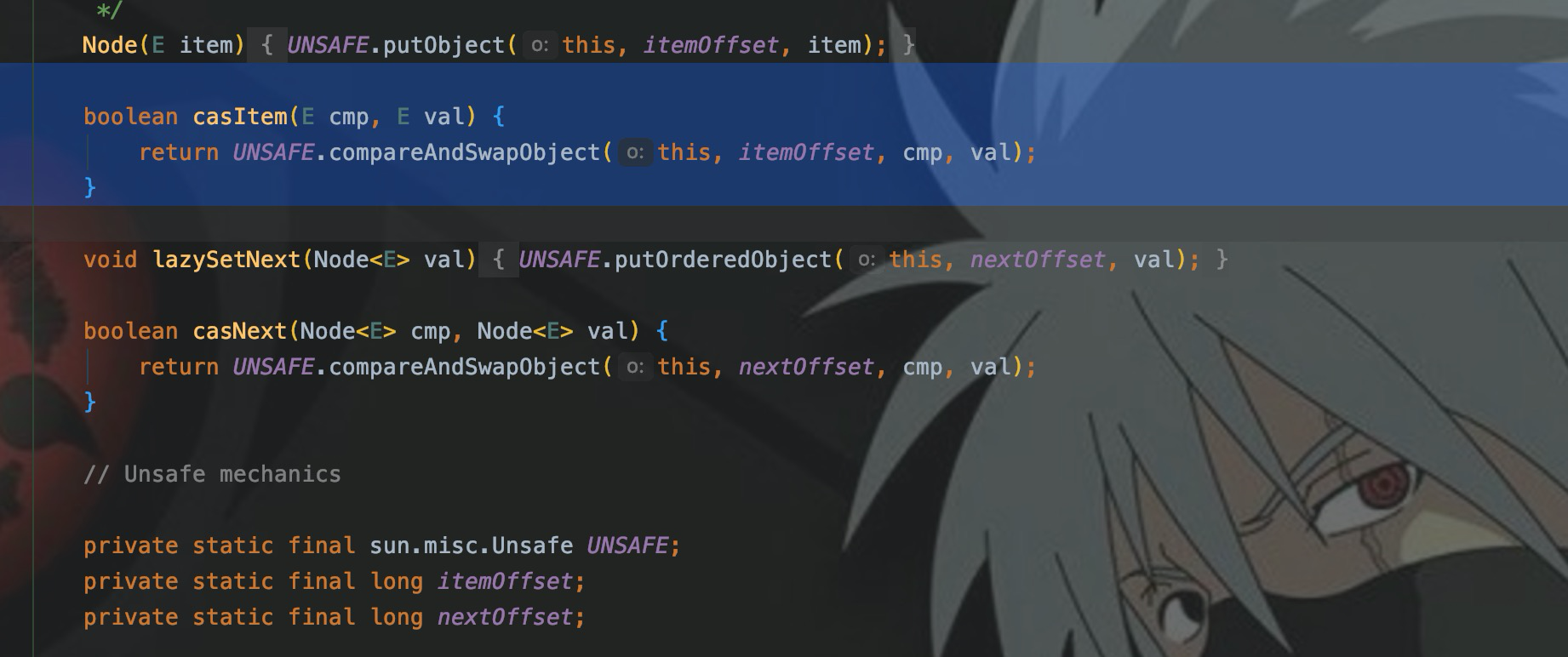
Если элемент головного узла (элемент) в очереди равен 1, а элементу присвоено значение null, это означает, что узел был удален и заголовок указывает на следующий элемент. Использование CompareAndSwapObject предназначено для замены (обмена) элемента в элементе нулевым значением, но перед заменой необходимо сравнить. Является ли этот элемент предыдущим элементом? Только если элемент остается предыдущим, его можно поменять местами.
Вы можете видеть, что в самом начале poll() есть for(;;;). Это способ написания бесконечного цикла, аналогичный while. true,Но здесь это называетсяВращаться,Если несколько потоков вызывают poll(),Тогда каждый поток застрянет во вращении,Подождите, пока поток не получит данные головного узла.,И через процесс CompareAndSwap,Измените его на ноль.
- Получить головной узел очереди
- Вызовите casItem, чтобы попытаться изменить элемент узла p (головной узел) на ноль.
- Когда значением элемента является item (элемент похож на номер версии), CompareAndSwapObject изменяет элемент на ноль.
- Если вышеуказанные шаги не увенчаются успехом, они будут повторены, что обычно называется вращением.
Поэтому ConcurrentLinkedQueue использует CAS вместо блокировок для обеспечения безопасности потоков. Однако одна проблема заключается в том, что если в очереди нет данных, вызов poll() возвращает значение null, поэтому во время обработки данных необходимо добавить ненулевое решение.
Если вы хотите еще больше повысить производительность, рекомендуется использовать Disruptor вместо ConcurrentLinkedQueue.
disruptor
Disruptor также представляет собой конструкцию CAS без блокировки, с высоким уровнем параллелизма и высокой пропускной способностью, а также имеет определение производителей и потребителей, аналогичное Kafka.
Нижний уровень — это буфер RingBuffer, реализованный на основе массива. Производитель и потребитель имеют свою собственную независимую последовательность. В буфере RingBuffer последовательность отмечает ход записи. Например, каждый раз, когда производитель хочет записать данные в буфер. , , всем необходимо вызвать RingBuffer.next(), чтобы получить следующую доступную относительную позицию.
1. Событие: объект передается между производителями и потребителями.
Если вы хотите использовать прерыватель, вам необходимо сначала создать носитель событий, который является объектом данных.
public class ByteArrayEvent {
private byte[] bytes;
public void setBytes(byte[] bytes) {
this.bytes = bytes;
}
}2. EventFactory: фабричный класс для создания событий.
public class ByteArrayEventFactory implements EventFactory<ByteArrayEvent> {
@Override
public ByteArrayEvent newInstance() {
return new ByteArrayEvent();
}
}3. EventHandler: логика потребительского потребления
public class ByteArrayEventHandler implements EventHandler<ByteArrayEvent> {
@Override
public void onEvent(ByteArrayEvent byteArrayEvent, long sequence, boolean endOfBatch) throws Exception {
// Логика обработки событий
}
}4. Нарушитель сборки
По умолчанию Disruptor указывает для производителя многопоточный режим, ProducerType.SINGLE, чтобы установить для производителя однопоточный режим.
// Должно быть степень 2
int bufferSize = 1024;
/**
DaemonThreadFactory: пул потоков, создать threads for processors.
ProducerType#SINGLE: один кольцевой буфер поддерживает несколько издателей; ProducerType#MULTI: поддерживает несколько издателей.
BlockingWaitStrategy: стратегия ожидания потребителя. SleepingWaitStrategy: мало влияет на производителей. BlockingWaitStrategy использует блокировку, которая не очень эффективна.
YieldingWaitStrategy имеет лучшую производительность и стратегию без блокировок, используя Thread.yield() Поочередное выполнение нескольких потоков
**/
disruptor = new Disruptor<>(new ByteArrayEventFactory(), bufferSize, DaemonThreadFactory.INSTANCE, ProducerType.SINGLE, new BlockingWaitStrategy());
// handleEventsWith: потреблять данные, привязывать потребителя каждый раз, затем вы можете использовать их для обработки цепочки.
// Обработчик является потребителем
disruptor.handleEventsWith(new ByteArrayEventHandler());
// запускать
disruptor.start(); volatile
Можно обратиться кЧтобы изучить модель памяти Java (JMM), я изучил некоторые инструкции по сборке.упомянуто вvolatileиsynchronizedчасть
clone()
Недавно я столкнулся с необходимостью преобразовать двоичные данные в формате TLV в двоичный текст. Что означает TLV? Это означает, что каждое поле каждого фрагмента данных представлено в формате TLV. T представляет собой тег, который является уникальным идентификатором поля. L — это длина, которая представляет длину V, следующего за значением. Каждый фрагмент данных имеет фиксированное количество полей, но если некоторые поля данных пусты, то это поле не обязательно должно быть представлено TLV, и оно перейдет непосредственно к следующему полю.
Структура данных, используемая здесь для хранения полей, представляет собой массив, поскольку поиск по индексу выполняется быстро. Здесь сначала создайте класс DataObject.
private Object[] data;
private static final String KAFKA_SEPARATOR = "|";
public DataObject(Object[] data) {
this.data = data;
}
@Override
public void setData(int index, Object f) {
data[index] = f;
}
@Override
public void data2String(StringBuilder sb) {
sb.append(data[0]).append(KAFKA_SEPARATOR);
sb.append(data[1]).append(KAFKA_SEPARATOR);
// Опустить другие поля...
}При разборе каждого поля,Сначала разберите тег,Затем используйте тег в качестве индекса,вызовsetDataВоляvalueвставитьArrayсередина。
int tag = buffer[off] & 0xFF;
int formatAndTagHigh = buffer[off + 1] & 0xFF;
int format = ((buffer[off + 1] & 0xFF) >> 4) & 0X0F;
off += 2;
int length = 0;
switch (format) {
case 1:
length = 1;
dataObject.setData(tag, buffer[off] & 0xff);
break;
case 4:
xdr.dataObject(tag, ConvToByte.byteToUnsignedInt(buffer, off));
length = 4;
break;Но в Java значение массива по умолчанию равно нулю, но я хотел установить значение по умолчанию в поле как нулевой символ, поэтому я подумал о нескольких решениях в то время.
Первый вариант — использовать replace для замены строки при преобразовании данных массива в String. Но этот план был мной прямо отвергнут. Для парсинга программ с большими объемами данных и высокими требованиями к реальному времени замена — это очень производительная штука.
Второй вариант — использовать массив как частное свойство объекта данных, инициализировать массив в конструкторе и пройтись по нему в цикле, чтобы установить для каждого значения значение «». Но проблема, которую это приносит, также очевидна: каждый раз, когда создается объект данных, массив будет зацикливаться, и каждый фрагмент данных имеет 200 полей, что означает, что он будет зациклен 200 раз, что также вызовет проблемы с производительностью. .
Итак, я выбрал третий вариант, который заключался в том, чтобы создать массив извне, пройти по нему и установить для каждого значения значение «». Перед созданием каждого объекта данных я вызывал array.clone() для копирования массива и в новом. объект данных Когда он присваивается частной переменной объекта данных в качестве параметра конструкции. Это полностью соответствует моим потребностям.
private Object[] data;
public DataDecode() {
int length = 200;
data = new Object[length];
data20 = new Object[length20];
for (int i = 0; i < length; i++) {
data[i] = "";
}
}
DataObject dataObject = new DataObject(data.clone());
// Логика обработки декодирования опущена....
dataObject.data2String(sb);Каковы преимущества метода clone()?
- Быстрее, чем новый объект, нет необходимости вызывать конструктор
- В моем сценарии требований массив нужно инициализировать только один раз.
- Объект, созданный функцией clone(), и исходный объект являются двумя независимыми объектами.
Исходя из вышеизложенного, выбор clone() является хорошим выбором в подходящих сценариях.
Заключение
При разработке Java во многих случаях конечной целью является создание функций и часто игнорируются различные варианты для одних и тех же функций, что улучшит производительность и технический уровень вашего собственного кода.
Эта статья представляет собой лишь микрокосм оптимизируемых частей всей разработки Java, особенно в области высокого параллелизма, многопоточности и блокировок. Есть еще много оптимизируемых областей.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
