[Источник живой воды] Mamba-YOLO имеет лучшие характеристики, чем YOLO! : Новая магистральная сеть SSM+CNN.
Автор предложил Mamba-YOLO, который основан на SSM и устанавливает новый стандарт для серии YOLO в обнаружении целей. Результаты экспериментов показывают, что Mamba-YOLO очень конкурентоспособен в общих задачах обнаружения объектов: mAP на MSCOCO на 8,1% выше, чем базовый YOLOv8.

Благодаря быстрому развитию технологий глубокого обучения серия YOLO устанавливает новый стандарт для детекторов объектов в реальном времени. Исследователи продолжают изучать инновационные применения репараметризации, эффективных сетей агрегации слоев и технологии точек без привязки на основе YOLO. Для дальнейшего повышения эффективности обнаружения введена структура на основе трансформатора, которая значительно расширяет восприимчивое поле модели и обеспечивает значительное улучшение производительности. Однако за такие улучшения приходится платить, поскольку гиперболическая сложность механизма самообслуживания увеличивает вычислительную нагрузку модели. К счастью, появление модели пространства состояний (SSM) как инновационной технологии эффективно облегчает проблемы, вызванные гиперболической сложностью.
Учитывая эти достижения, авторы представляют Mamba-YOLO, новую модель обнаружения объектов, основанную на SSM. Mamba-YOLO не только оптимизирует основу SSM, но и специально адаптирует ее под задачу обнаружения целей.
Ввиду возможных ограничений SSM при моделировании последовательностей, таких как недостаточные рецептивные поля и слабая локальность изображения, авторы разработали LSBlock и RGBlock. Эти модули позволяют более точно фиксировать локальные зависимости изображений и значительно повышают надежность модели.
Обширные экспериментальные результаты на общедоступных наборах эталонных данных COCO и VOC показывают, что Mamba-YOLO превосходит существующие модели серии YOLO как по производительности, так и по конкурентоспособности, демонстрируя свою силу и конкурентоспособность.
Код PyTorch доступен по следующей ссылке: https://github.com/HZAI-ZJNU/Mamba-YOLO.
1 Introduction
В последние годы глубокое обучение быстро развивалось, особенно в области компьютерного зрения, и ряд мощных архитектур достигли впечатляющей производительности. Применение различных структур из сверточных нейронных сетей (CNN) [1; 2; 3 4 5] и трансформеров в архитектурах Mamba продемонстрировало их большой потенциал в компьютерном зрении.
В последующих задачах обнаружения целей в основном используются структуры CNN и Transformer [11, 13]. CNN и ряд его улучшений обеспечивают высокую скорость выполнения, обеспечивая при этом точность. Однако из-за плохой корреляции изображений исследователи внедрили в область обнаружения целей трансформеры, такие как серия DETR [11, 12, 14], которые полагаются на мощную способность глобального моделирования собственного внимания для решения проблемы небольших Рецептивные поля CNN. К счастью, с развитием аппаратного обеспечения увеличение объема вычислений памяти, обеспечиваемое этой структурой, не представляет большой проблемы. Однако в последние годы все больше работ [5, 59, 60] начали переосмысливать, как проектировать CNN, чтобы сделать модель быстрее, и все больше практиков были недовольны квадратичной сложностью структуры Трансформера и начали использовать гибридные структуры для реконструкции моделей. И уменьшите сложность, например MobileVit [61], EdgeVit [62], EfficientFormer [43]. Однако гибридные модели также создают проблемы, а также значительное снижение производительности, поэтому поиск баланса между производительностью и скоростью был в центре внимания исследователей.
Серия YOLO всегда была знаковым детектором реального времени в области обнаружения целей. CSPNet [63] был представлен из YOLOv4 [25], YOLOv6 [27] начал интегрировать репараметризацию, YOLOv7 [28] использовал ELAN для реконструкции модели, а YOLOv8 [42] принял конструкцию с разделенной головкой и без опорной точки. Недавно предложенный YOLOv10 [48] объединяет элементы структуры Transformer в свою конструкцию и вводит модуль частичного самообслуживания (PSA), целью которого является расширение возможностей глобального моделирования модели при одновременном контроле вычислительных затрат. Это доказывает, что эта серия всегда имела большую жизненную силу. Кроме того, структура CNN обеспечивает модели высокую скорость выполнения, и многие специалисты использовали механизмы внимания для улучшения этой модели и достижения желаемого повышения производительности в своих областях.
ViT-YOLO [38] вводит MHSA-Darknet в YOLO и применяет расширенные стратегии обучения, такие как TTA и технологию слияния взвешенных кадров. Однако увеличение количества параметров и FLOP не принесло ожидаемого улучшения производительности, показывая ограничения масштабируемости Transformer в задачах обнаружения объектов, особенно в YOLO. YOLOS [37] использует минималистскую схему преобразования, основанную на исходной архитектуре ViT, заменяя маркеры CLS в ViT маркерами DET и используя потерю двоичного сопоставления в методе ансамблевого прогнозирования. Однако его производительность разочаровывает и очень чувствительна к схеме предварительной тренировки: YOLOS демонстрирует большую вариабельность при различных стратегиях предварительной тренировки. Gold-YOLO [29] предложил метод улучшения многомасштабного слияния признаков путем извлечения и объединения информации о признаках с помощью примитивов свертки и внимания. Однако при интеграции структуры Transformer эти методы теряют свои основные преимущества, а именно мощный механизм глобального внимания и возможности обработки длинных последовательностей, и пытаются уменьшить объем вычислений, вызванный квадратичным уменьшением сложности, что обычно ограничивает производительность модели.
В последнее время методы, основанные на моделях пространства состояний (SSM), такие как Mamba [32], предоставляют новые идеи для решения этих проблем благодаря своим мощным возможностям моделирования зависимостей на больших расстояниях и превосходным свойствам линейной временной сложности. Примечательно, что исследователи успешно внедрили архитектуру Mamba в область зрения и достигли успеха в классификации изображений [31, 33].
Вдохновленный этим, автор поднял вопрос: может ли структура SSM быть внедрена в область обнаружения целей и объединена с современными детекторами реального времени, чтобы воспользоваться преимуществами SSM и внести новые улучшения производительности в серию YOLO?
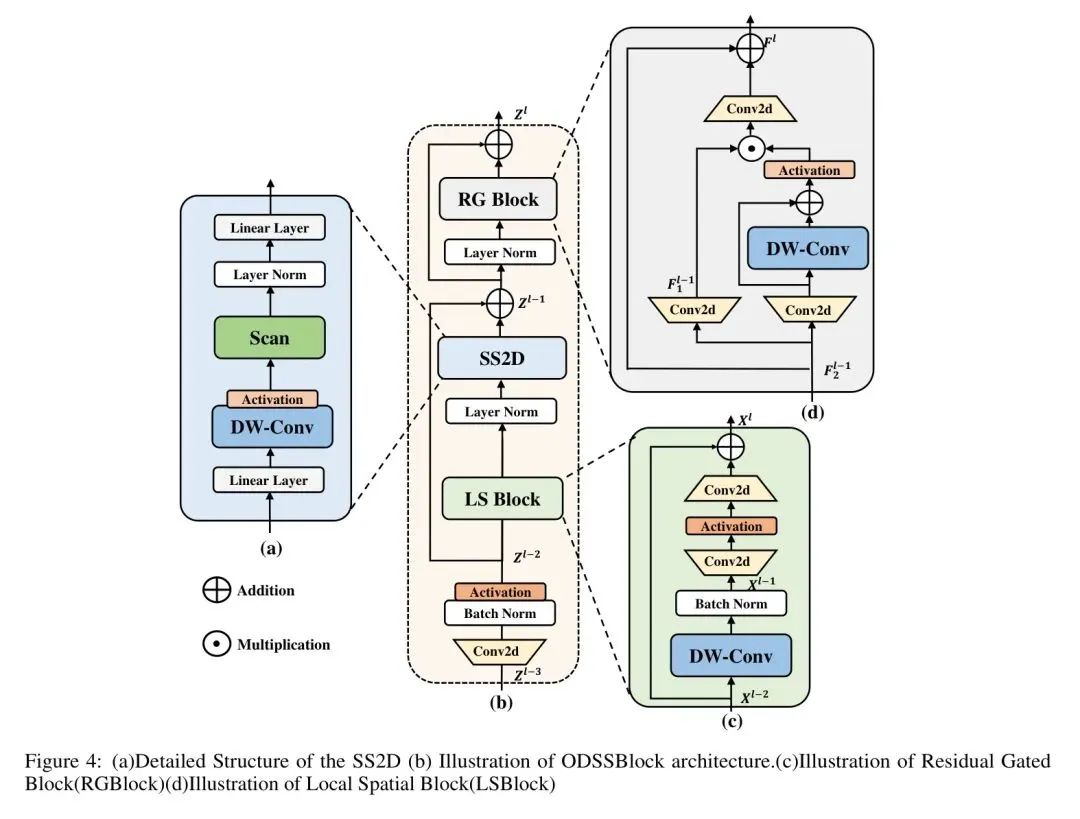
В данной статье предлагается модель детектора под названием Mamba-YOLO. Автор представил модуль ODSSBlock, как показано на рисунке 4, для применения структуры SSM в области обнаружения целей. В отличие от VSSBlock для классификации изображений, входное изображение для обнаружения цели имеет более крупные пиксели. Поскольку модели SSM обычно моделируют текстовые последовательности и не имеют возможности выражать каналы изображений, автор предложил LSBlock для моделирования функций каналов. Используя более крупные пиксели и больший размер канала в изображении, авторы предлагают структуру RGBlock, которая дополнительно декодируется после вывода SS2D, используя многомерное выражение скалярного произведения для улучшения корреляции каналов. Mamba-YOLO — это важное достижение в задачах визуального распознавания и обнаружения, направленное на создание новой магистральной сети, сочетающей в себе преимущества SSM и CNN. Архитектура применяет модель преобразования пространства состояний на основе SSM к слоям YOLO для эффективного захвата глобальных зависимостей и использования преимуществ локальной свертки для повышения точности обнаружения и понимания модели сложных сцен при сохранении производительности в реальном времени. Ожидается, что эта гибридная архитектура преодолеет ограничения существующих моделей машинного зрения при обработке крупномасштабных изображений или изображений с высоким разрешением и обеспечит мощную и гибкую поддержку базовых моделей машинного зрения следующего поколения. Автор провел подробные эксперименты на PASCAL VOC[35], COCO[36], и результаты показывают, что Mamba-YOLO очень конкурентоспособен в общих задачах обнаружения целей, а mAP на MSCOCO на 8,1% выше, чем базовый YOLOv8.
Основные положения данной статьи можно резюмировать следующим образом:
-Автор предложил Mamba-YOLO, основанный на SSM, устанавливая новый эталон для серии YOLO в обнаружении целей и закладывая прочную основу для будущей разработки более эффективных и действенных детекторов на основе SSM.
-Автор предложил ODSSBlock, в котором блок LS может эффективно извлекать локальную пространственную информацию входной карты объектов, чтобы компенсировать возможности локального моделирования SSM. Переосмысливая конструкцию слоя MLP, автор предлагает блок RG, который сочетает в себе идеи вентилируемой агрегации и эффективных сверточных остаточных связей, что эффективно фиксирует локальные зависимости и повышает надежность модели.
-Автор разработал набор моделей Mamba-YOLO (Tiny/Base/Large) разных размеров для поддержки развертывания задач разных размеров и масштабов, а также провел эксперименты на двух наборах данных COCO и VOC, как показано на рисунке 1, результаты показывают, что авторский метод Mamba-YOLO обеспечивает значительное улучшение производительности по сравнению с существующими современными методами.

2 Related Work
Область компьютерного зрения претерпела трансформацию с появлением глубокого обучения, что привело к значительным улучшениям в решении самых разных задач: от классификации изображений до обнаружения объектов и семантической сегментации. В последние годы механизм внимания, первоначально предложенный в области обработки естественного языка, также был внедрен в компьютерное зрение и дал обнадеживающие результаты.
Real-time Object Detectors
От YOLOv1 до YOLOv3 [22, 23, 24] являются пионерами моделей серии YOLO. Их улучшения производительности тесно связаны с улучшением магистральной сети, что делает DarkNet широко используемым. YOLOv4 [25] представляет большое количество предлагаемых проектов остаточной структуры магистральных сетей CSPDarknet53, эффективно уменьшая вычислительную избыточность и достигая высокопроизводительного выражения функций и эффективного обучения. YOLOv7[28] предложил структуру E-ELAN, которая расширила возможности модели, не разрушая исходную модель. YOLOv8 [42] сочетает в себе характеристики предыдущих поколений YOLO и использует структуру C2f с более богатыми градиентными потоками, чтобы обеспечить точность, но при этом быть легким и адаптируемым к различным сценариям. Недавно Gold Yolo [29] представил новый механизм под названием GD (сбор и распределение) для решения проблемы объединения информации традиционной сети пирамиды функций [52] и Rep-PAN [27] посредством операции самообслуживания и успешно реализовал SOTA. Фактически, из-за локального рецептивного поля и иерархической структуры традиционная CNN имеет определенные ограничения в решении проблем резких изменений масштаба, сложного фона и интерференции нескольких изображений в изображениях.
End-to-end Object Detectors
DETR [11] впервые применил Transformer для обнаружения целей, используя архитектуру кодера-декодера Transformer, минуя традиционные компоненты, созданные вручную, такие как генерация опорных точек и немаксимальное подавление, и рассматривая обнаружение как задачу прогнозирования прямой интеграции. Деформируемый DETR [12] представляет деформируемое внимание, вариант Трансформатора внимания для выборки разреженного набора ключевых точек вокруг контрольных мест, решая ограничения DETR при обработке карт признаков пола с высоким разрешением. DINO [13] объединяет гибридную стратегию выбора запроса, деформируемое внимание и демонстрирует повышение производительности за счет демонстрационного обучения введенному шуму и оптимизации запросов. RT-DETR [14] предложил гибридный кодер для разделения одномасштабных взаимодействий и межмасштабного слияния для эффективной многомасштабной обработки признаков. Тем не менее, у DETR есть проблемы со сходимостью обучения, вычислительными затратами и обнаружением небольших целей, в то время как серия YOLO по-прежнему поддерживает SOTA сбалансированной точности и скорости в области небольших моделей.
Vision State Space Models
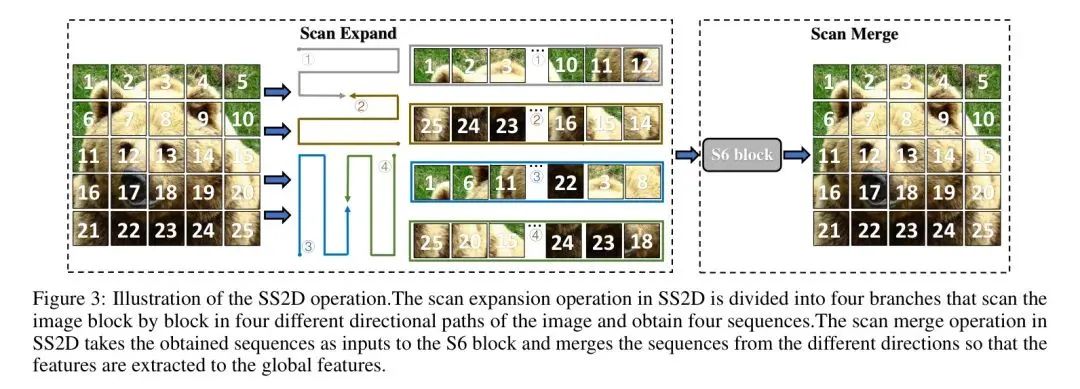
В последнее время модель пространства состояний (SSM) стала горячей темой исследований. Основываясь на исследованиях SSM [39, 40, 41], Мамба [32] демонстрирует линейную сложность в зависимости от размера входных данных и решает проблему вычислительной эффективности Трансформатора на длинных последовательностях моделирования пространства состояний. В области обобщенных зрительных магистральных сетей компания Vision Mamba [33] предложила чисто визуальную магистральную модель, основанную на SSM, что стало первым случаем, когда Mamba была введена в поле зрения. VMamba [31] представила модуль Cross-Scan, который позволяет модели выборочно сканировать 2D-изображения, расширяет возможности визуальной обработки и демонстрирует преимущества в задачах классификации изображений. LocalMamba [34] фокусируется на стратегии оконного сканирования модели визуального пространства, оптимизирует визуальную информацию для захвата локальных зависимостей и представляет метод динамического сканирования для поиска лучшего выбора для разных уровней. MambaOut [49] исследовал необходимость архитектуры Mamba в задачах машинного зрения. Он отметил, что SSM не нужен для задач классификации изображений, но его ценность для задач обнаружения и сегментации, которые следуют характеристикам длинной последовательности, заслуживает дальнейшего изучения. В задачах последующего зрения Mamba также широко использовалась в исследованиях сегментации медицинских изображений [53, 54, 55] и сегментации изображений дистанционного зондирования [56, 57]. Вдохновленная замечательными результатами, достигнутыми В.Мамбой [31] в области задач зрения, в этой статье впервые предлагается мамба YOLO, новая модель SSM, которая направлена на учет глобального поля восприятия, одновременно демонстрируя ее потенциал в задачах обнаружения целей.
3 Method
Preliminaries
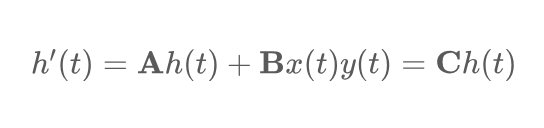
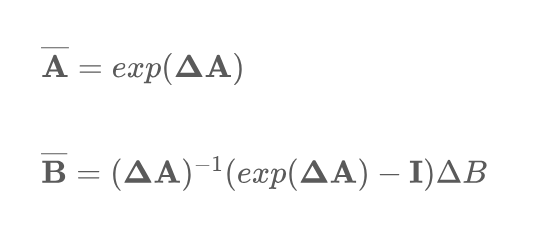
В уравнении (4) представьте параметры, которые регулируют временное разрешение модели, соответствующее представлению непрерывных параметров в дискретном времени в пределах заданного временного интервала. Здесь представляет единичную матрицу. После преобразования модель рассчитывается в линейно-рекурсивной форме, которую можно определить следующим образом:
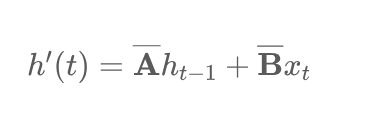
Полное преобразование последовательности также можно выразить в форме свертки, определяемой следующим образом:
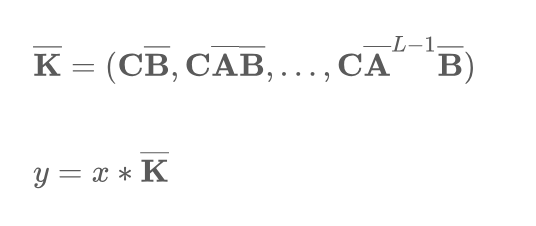
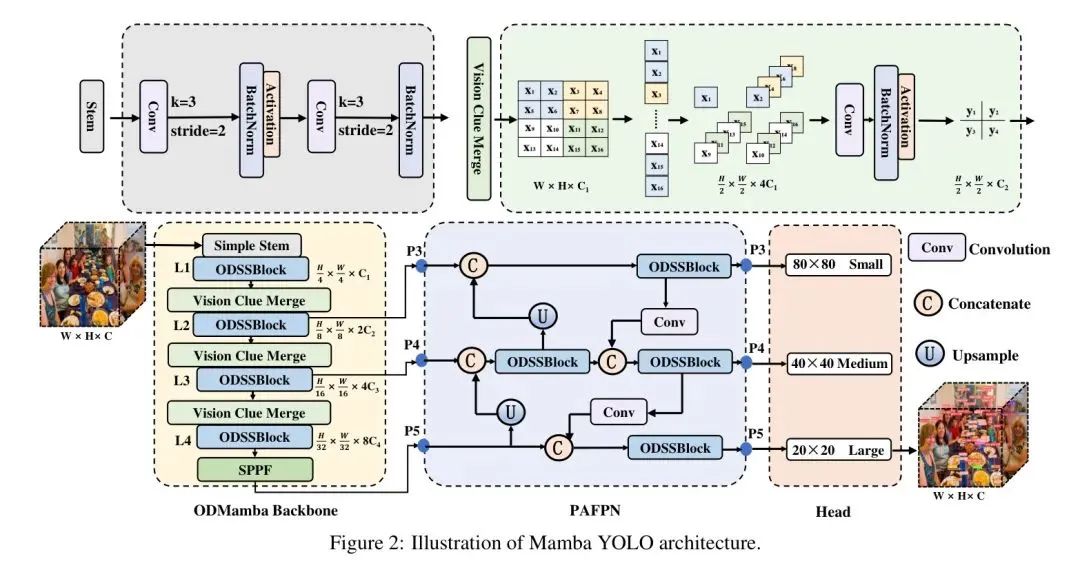
Современные преобразователи зрения Simple Stem (ViT) обычно используют фрагменты сегментированного изображения в качестве исходных модулей, чтобы разделить изображение на непересекающиеся сегменты. Эта сегментация достигается с помощью операции свертки с размером ядра 4 и шагом 4. Однако недавние исследования, такие как EfficientFormerV2 [43], показали, что этот метод может ограничить возможности оптимизации ViT и повлиять на общую производительность. Чтобы найти баланс между производительностью и эффективностью, авторы предлагают упрощенный слой стебля. Вместо использования непересекающихся патчей изображений авторы используют две свертки с шагом 2 и размером ядра 3.
Хотя структуры сверточных нейронных сетей (CNN) и визуальных преобразователей (ViT) обычно используют свертку для понижения дискретизации, авторы обнаружили, что этот подход мешает выборочной работе SS2D [31] на разных стадиях потока информации. Чтобы решить эту проблему, VMamba [31] разбивает 2D-карту объектов и уменьшает размерность, используя свертку 1x1. Результаты авторов показывают, что сохранение большего количества визуальных подсказок для моделей пространства состояний (SSM) полезно для обучения моделей. В отличие от традиционного подхода к уменьшению размерности вдвое, авторы упрощают этот процесс путем: 1) удаления нормализации; 2) разделения карты измерений; 3) добавления дополнительных карт признаков к размерности канала; 4) использования 4-кратной свертки точек для понижения разрешения. Вместо использования свертки 3x3 с шагом 2 наш метод сохраняет карту объектов, выбранную предыдущим слоем SS2D.
ODSS Block
Как показано на рисунке 4, блок ODSS является основным модулем Mamba YOLO. После серии обработок на этапе ввода сеть может изучать более глубокие и богатые представления функций, сохраняя при этом эффективность и стабильность процесса обучения в пакетном режиме. нормализация.
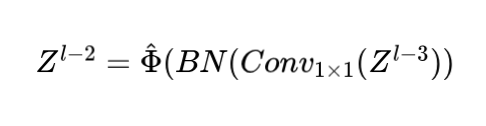
где представляет собой функцию активации (нелинейная SiLU). Нормализация слоев и конструкция остаточных соединений блоков ODSS основаны на архитектуре стиля Transformer Blocks [6], которая позволяет модели работать эффективно при глубоком стеке и обучении в ситуациях глубокого стека. Формула расчета следующая:
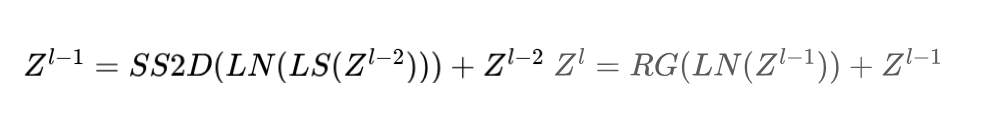
LocalSpatial и ResGated.
3.3.1 LocalSpatial Block
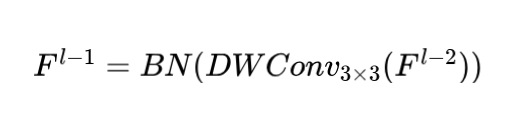
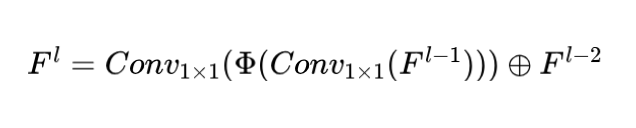
3.3.2 ResGated Block
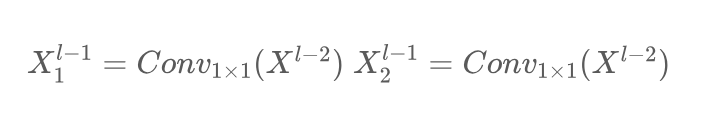

4 Experiments
В этом разделе авторы проводят комплексные эксперименты с Mamba YOLO для задачи обнаружения объектов и некоторых задач последующего зрения. Автор использует набор данных MS COCO[36] для проверки превосходства предлагаемого Mamba YOLO. По сравнению с текущим состоянием техники автор обучался на наборе данных COCO2017train и проверял набор данных COCO2017val. В эксперименте по абляции авторы проверили эффективность каждой части предложенного метода, используя набор данных VOC0712 [35], где обучающий набор содержит примерно 16 551 изображение из обучающих наборов VOC2007 и VOC2012, а проверочный набор состоит из 4952 изображений из композиция изображения тестового набора VOC2007. Все модели, упомянутые автором, используют стратегию обучения с нуля, а общее количество раз обучения составляет 500 раз. Дополнительные настройки см. в приложении. Все модели автора обучены на 8 графических процессорах NVIDIA H800.
Comparison with state-of-the-arts
На рисунке 1 и в таблице 1 показаны результаты MS-COCO2017val по сравнению с существующими современными детекторами объектов, где метод, предложенный в этой статье, обеспечивает наилучший комбинированный компромисс между FLOP, Params и точностью. В частности, по сравнению с самой эффективной облегченной моделью DAMO YOLO-T/YOLO MS-XS, Mamba YOLO-Th значительно улучшила AP на 3,4%/2,0%, а по сравнению с базовой моделью YOLOv8-S Params снизилась на 45,5. %, FLOP уменьшаются на 50%, при этом точность примерно такая же. Сравнивая Mamba YOLO-B с Gold-YOLO-M с аналогичными параметрами и FLOP, у первого AP на 4,5% выше, чем у второго. Даже по сравнению с Gold-YOLO-M при той же точности Params снижены на 47,2%, а FLOPs снижены на 43,2%. В больших моделях Mamba YOLO-L также обеспечивает лучшую или аналогичную производительность по сравнению с любым современным детектором объектов. По сравнению с наиболее эффективным Gold-YOLO-L, AP Mamba YOLO-L увеличился на 0,3%, а Params снизился на 0,9%. Приведенные выше результаты сравнения показывают, что предложенная авторами модель обеспечивает значительные улучшения по сравнению с существующими современными методами в Mamba YOLO в различных масштабах.
Ablation study
Начало исследования абляции.
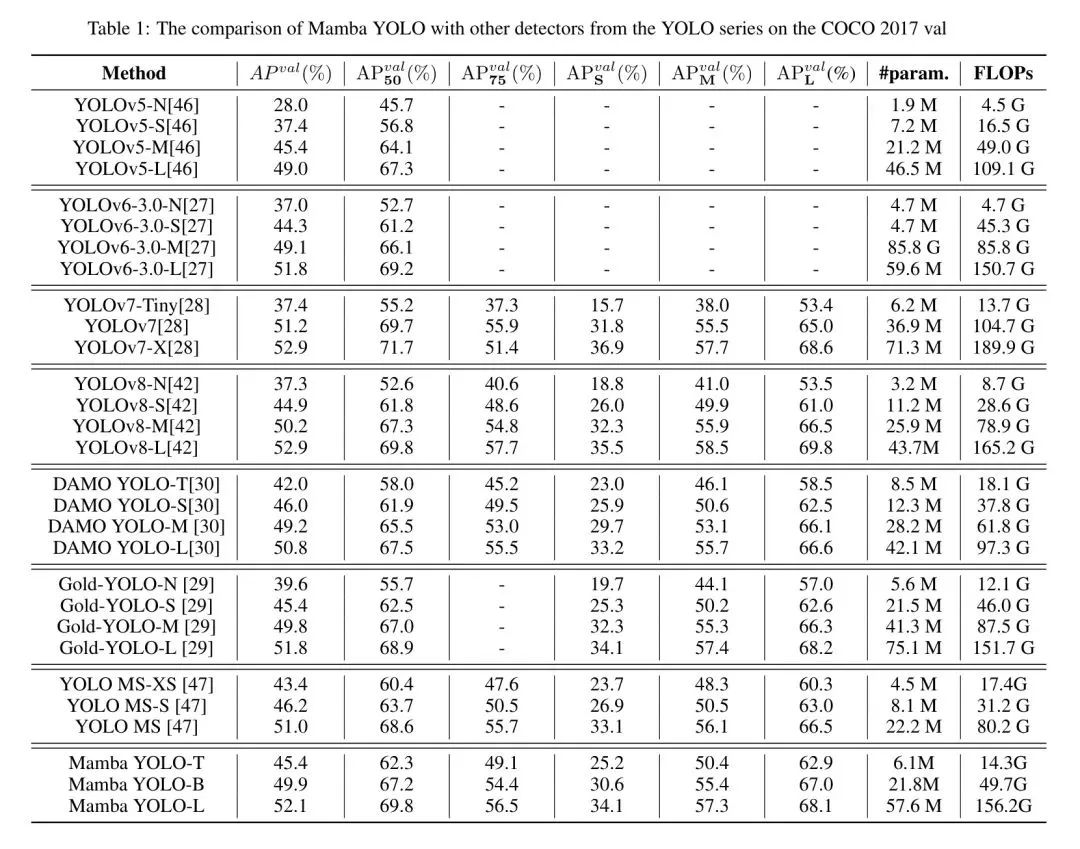
4.2.1 Ablation study on Mamba YOLO
В этом разделе мы исследуем каждый модуль в блоке ODSS независимо, без слияния сигналов, используя традиционный сверточный метод Visual Transformer для понижения дискретизации, чтобы оценить влияние слияния визуальных сигналов на точность. Эксперименты по абляции проводились на Mamba YOLO с использованием набора данных VOC0712, а тестовой моделью была Mamba YOLO-T. Результаты авторов в таблице 2 показывают, что слияние сигналов сохраняет больше визуальных сигналов для модели пространства состояний (SSM) и подтверждает утверждение о том, что структура блоков ODSS действительно оптимальна.
4.2.2 Абляционное исследование структуры блока РГ
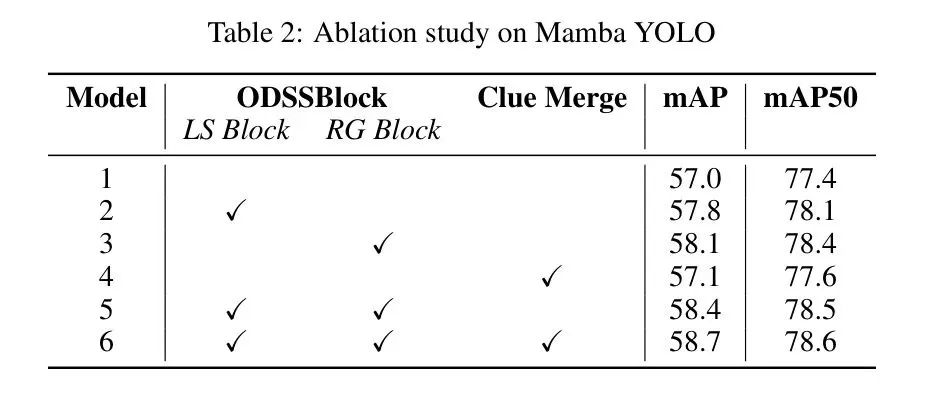
RGDlock фиксирует попиксельные локальные зависимости, получая глобальные зависимости и глобальные функции. Что касается деталей конструкции блока RG, автор также рассмотрел три варианта, основанные на многоуровневом восприятии: 1) Сверточный MLP, добавляющий DW-свертку к исходному MLP 2) Res-сверточный MLP, с использованием остаточной DW-свертки; к исходному МЛП в связном порядке 3) Gated MLP, вариант МЛП, выполненный под литниковый механизм; На рисунке 5 показаны эти варианты, а в таблице 3 показаны характеристики исходного MLP, блока RG и каждого варианта в наборе данных VOC0712 для проверки эффективности авторского анализа MLP. Тестовая модель — Mamba YOLO-T. Авторы заметили, что введение одной только свертки не привело к эффективному улучшению производительности, в то время как выходные данные закрытого варианта MLP на рисунке 5 (d) состоят из поэлементного произведения двух линейных проекций, одна из которых соединена Остаток Комбинация DWConv и стробируемых функций активации фактически дает модели возможность распространять важные функции через иерархическую структуру и эффективно повышает точность и надежность модели. Этот эксперимент показывает, что повышение производительности за счет введения сверток при работе со сложными задачами обработки изображений во многом связано с механизмами стробируемой агрегации, при условии, что они применяются в контексте остаточных соединений.
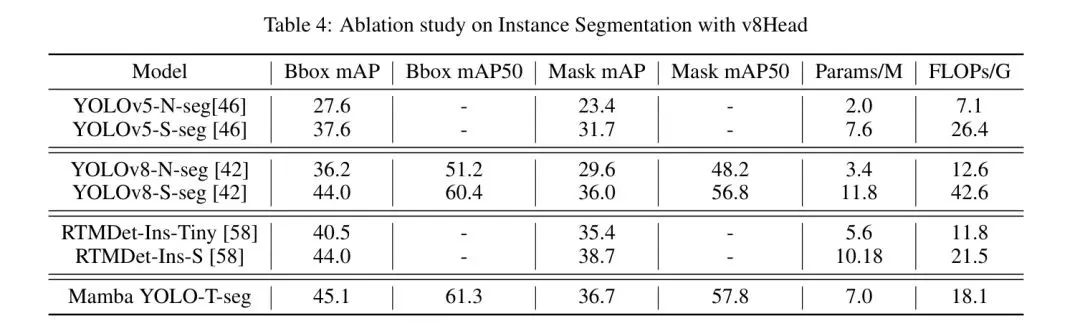
4.2.3 Исследования абляции на других моделях и сегментация экземпляров
Чтобы оценить превосходство и хорошую масштабируемость предложенной автором архитектуры Mamba YOLO на основе SSM, помимо области обнаружения объектов, автор также применил ее к задаче сегментации экземпляров. Автор использует головку сегментации v8 [42] на Mamba YOLO-T, обучает и тестирует набор данных COCOseg и оценивает производительность модели с помощью таких индикаторов, как Bbox AP и Mask AP. Mamba YOLO-T-seg значительно превосходит модели сегментации YOLOv5 [46] и YOLOv8 [42] при любом размере. На основе RTMDet [58], который содержит основные строительные блоки глубоких сверток с большим ядром, мягкие метки вводятся в процесс динамического назначения меток для расчета стоимости сопоставления, что хорошо работает в нескольких задачах машинного зрения, в то время как Mamba YOLO-T- seg сопоставим с Tiny Compared, он по-прежнему сохраняет преимущество в 2,3 по маске mAP. Результаты показаны в таблице 4 и на рисунке 8.

5 Conclusion
В этой статье автор повторно анализирует преимущества и недостатки сверточной нейронной сети (CNN) и архитектуры Transformer в области обнаружения целей и указывает на ограничения их слияния.
Основываясь на этом, автор предложил детектор, основанный на дизайне архитектуры модели пространства состояний, и расширил его с помощью YOLO. Автор повторно проанализировал ограничения традиционного многослойного перцептрона (MLP) и предложил блок RG, механизм пропускания которого и глубокая свертка. остаточные связи предназначены для того, чтобы модель могла распространять важные функции по иерархии.
Кроме того, чтобы устранить ограничения архитектуры Mamba при захвате локальных зависимостей, LSBlock расширяет возможности захвата локальных функций и объединения их с исходными входными данными для улучшения представления функций, что значительно улучшает возможности обнаружения модели.
Цель автора — установить новый стандарт для YOLO и доказать, что Mamba YOLO высококонкурентна. Работа автора — это первое исследование архитектуры Mamba в задачах обнаружения целей в реальном времени, и автор также надеется принести новые идеи исследователям в этой области.
ссылка
[1].Mamba YOLO: SSMs-Based YOLO For Object Detection.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
