Исследование стратегии A-share на основе трех основных графовых сетей и модели HIST.

основные идеи
- В данной статье объединены производственные цепочки, взаимосвязи сети, цепочка Сеть отношений поставок, сеть отношений совместного появления новостей, обнаружение сообщества и атрибуты изкластера в соответствии с предопределенными концепциями, введите HIST Прогнозирование будущей доходности акций в Модели,Вышеупомянутые три индивидуальные диаграммы сети соответственно представляют бизнес компании. экономическая деятельность、Инвесторы обращают внимание на эти три аспекта информации.
- По сравнению с традиционным прямым бизнесом компании основным направлением деятельности является продукт и другие концепции.,Производительность концепции изкластера улучшилась после кластеризации сети графов,Атрибут кластера содержит значение «have» инкрементной информации.
- В то же время для тестирования стратегии используются три заранее определенных концепции кластера. Одна из субстратегий topk=90 & n_drop=9 , после вычета трансакционных издержек, в 20220101-20230630 полученный во время 14.10% годовая избыточная доходность, коэффициент информации равен 2.061, максимальный ретрейсмент -5.08%。
Предисловие
В предыдущей статье мы построили сеть отношений производственной цепочки, сеть отношений цепочки поставок и сеть отношений совместного появления новостей соответственно, выполнили кластеризацию графов и проанализировали корреляцию между доходностью при различных отношениях, а также между акциями внутри и вне кластера. В конце концов все они пришли к выводу, что «родственные акции демонстрируют более сильную корреляцию, чем несвязанные акции, а акции внутри кластера также демонстрируют более сильную корреляцию, чем акции вне кластера». Три основных сетевых взаимосвязи и три основных атрибута кластера. может предоставить полезную дополнительную информацию. В этой статье эти атрибуты кластеров будут далее использоваться в качестве предопределенных концепций, а модель HIST будет использоваться для извлечения общей информации о кластерах для прогнозирования будущей доходности акций.
Обзор трех основных графовых сетей
В предыдущей серии статей мы использовали три основных альтернативных данных ChinaScope (данные отраслевой цепочки, данные цепочки поставок, а также новости и данные общественного мнения) для построения трех основных графовых сетей: сети взаимоотношений в производственной цепочке, сети взаимоотношений в цепочке поставок и сети новостей. Сеть отношений возникновения. Отношения, изображенные тремя основными графовыми сетями, соответствуют бизнес-операциям компании, экономической деятельности компании и вниманию инвесторов. После построения трех основных графовых сетей мы также провели обнаружение сообществ в каждой из них, чтобы дополнительно изучить атрибуты кластера между компаниями в рамках вышеупомянутых отношений и усовершенствовать способ классификации акций. Три этапа построения карты и некоторые визуализации следующие:
Шаги по построению сети взаимоотношений в производственной цепочке:
1. Для компаний, зарегистрированных на бирже с долей А, на основе исходной детализированной таблицы и таблицы словаря продуктов в данных производственной цепочки ChinaScope доход от продукта подчиненных уровней равномерно сопоставляется с вторичными продуктами базы данных, тем самым формируя доход от вторичного продукта компании. вектора распределения базы данных.
2. Для разных компаний в одном отчетном периоде рассчитайте корреляцию между компанией и продукцией компании. Конкретный метод расчета следующий:
A и B соответственно представляют два предприятия, 𝑤𝑒walk𝑔ℎfalcon𝐴,𝐵, — родственные отношения между предприятием A и предприятием B в отчетном периоде i, 𝑠𝑢𝑚(𝐴∪𝐵) — отношения между предприятием A или предприятием B в отчетном периоде i Общая сумма выручки по продукции с выручкой, 𝑠𝑢𝑚(𝐴 ∩ 𝐵) — общая сумма выручки, соответствующая продукции с выручкой на предприятии А и предприятии Б в отчетном периоде i. Степень корреляции рассчитывается следующим образом:
3. На основе рассчитанной выше корпоративной корреляции удалите связи с корреляцией 0 и постройте взвешенную ненаправленную сетевую диаграмму производственной цепочки, соответствующую отчетному периоду. Точки на диаграмме — это котирующиеся на бирже компании с долей А, а вес — преимуществом является компания. Соответствие продуктам компании.
4. Дополнение: если операционный доход вторичного продукта отрицательный, установите отрицательный операционный доход равным 0, если конечный вес ребра равен 0, замените его минимальным значением всех весов ребер в поперечном сечении, чтобы запасы под продуктом могут быть сохранены.
Этапы построения сети взаимоотношений в цепочке поставок:
1. Существующая промежуточная таблица цепочки поставок ChinaScope представляет собой сеть взаимоотношений цепочки поставок, но исходная таблица содержит узлы символов, двусторонние ребра, в которых «сопряженные компании являются поставщиками и клиентами друг друга», а «поставщики и клиенты являются самими компаниями». «Автоматическая петля и другие ситуации требуют дальнейшей обработки.
2. Непосредственное удаление узлов символов и ребер с самозацикливанием для выбора двунаправленных ребер, в основном следуйте следующим правилам: ①; Сохраняйте направление с большей суммой, Приоритет суммыдля Сумма транзакции>Конечный баланс>Резерв по безнадежным долгам;② если ① Если оно не может быть удовлетворено, выберите направление, которое чаще всего встречается в истории ③; если ② Если оно не может быть удовлетворено, будет выбрано случайное направление.
Этапы построения сети отношений совместного появления новостей:
1. Сначала используйте 15:00 каждого торгового дня в качестве времени резки, считайте новости после закрытия новостями следующего торгового дня и сопоставляйте календарный день с торговым днем.
2. Удалите нерелевантные новости и оставьте только relevance>10% новости компании.
3. Базовая сеть совместного появления новостей: непосредственное преобразование ежедневных новостей компании в форму совместного появления новостей. Каждая строка данных содержит: дату, совпадающую компанию a, совпадающую компанию b и время совместного появления. Новостные данные представляют собой базовые сети для одновременного появления новостей.
4. Сеть расширения одновременного появления новостей: ежедневное совпадение акций меняется относительно часто и A Охват запасов низкий, поэтому матрица совпадений рассчитывается в конце каждого месяца. 90 Общее количество сторон в день, то есть компания a и компания b в прошлом 90 Если в Японии и Китае есть одновременное появление новостей, то они также будут включены в сеть одновременного появления новостей. Эта сеть имеет более высокий охват, и взаимосвязь одновременного появления акций относительно более стабильна. Последующий анализ в основном основан на. расширенная сеть одновременного появления новостей.
Обнаружение сообщества:
1. Используйте алгоритм Лейдена для обнаружения сообществ в трех основных сетях.
2. Относительно того, содержит ли сеть вес и направление: связь производственной цепочки сетии новости связь совместного появления сетьдля неориентированного графа, цепочка поставоксвязьсетьдляиметьк графику(направлениедля:Поставщик указывает на клиента);Ребра сети взаимоотношений цепочки поставок не имеют веса, тогда как веса ребер сети взаимоотношений производственной цепочки представляют собой степени корреляции.,Отношения совместного появления новостей. Вес края сети для количества одновременного появления новостей.
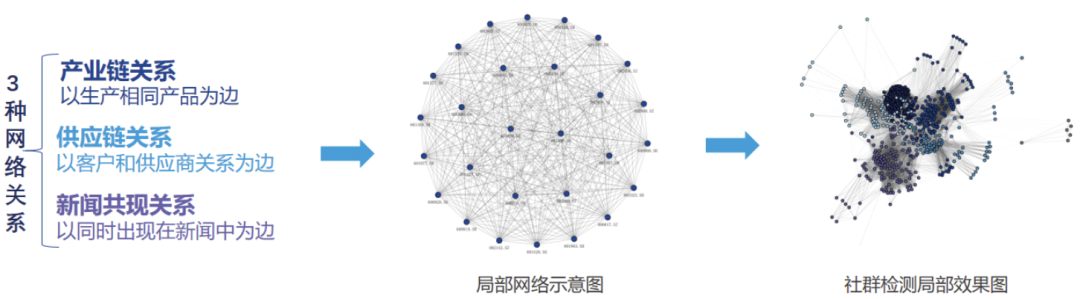
Рисунок 1. Частичная визуализация графовой сети и обнаружение сообщества.
Конфигурация параметров модели HIST
Английское сокращение модели HIST — (информация о акциях для прогнозирования трендов акций), которая представляет собой «структуру прогнозирования на основе графиков, которая может прогнозировать тенденции акций путем анализа общей информации о концепциях». Основной особенностью модели HIST является то, что неполнота и динамическая изменчивость концепции учитываются при извлечении общей информации из концепции, а заранее определенные концепции (такие как отрасль, основной бизнес, сфера деятельности и другие концепции) вводятся в модель. Модель HIST Далее модель будет динамически изучать неявные концепции, которые не включены в предопределенные концепции. На основе предопределенных концепций и скрытых концепций модель разлагает характерную информацию об акциях на три части: информацию, общую для заранее определенных концепций, информацию, общую для скрытых концепций, и информацию, специфичную для акций. Эти три части информации соответственно соответствуют трем различным связям в компании. Двойная остаточная структура затем использует эти три части информации одновременно для прогнозирования будущей тенденции цен на акции.
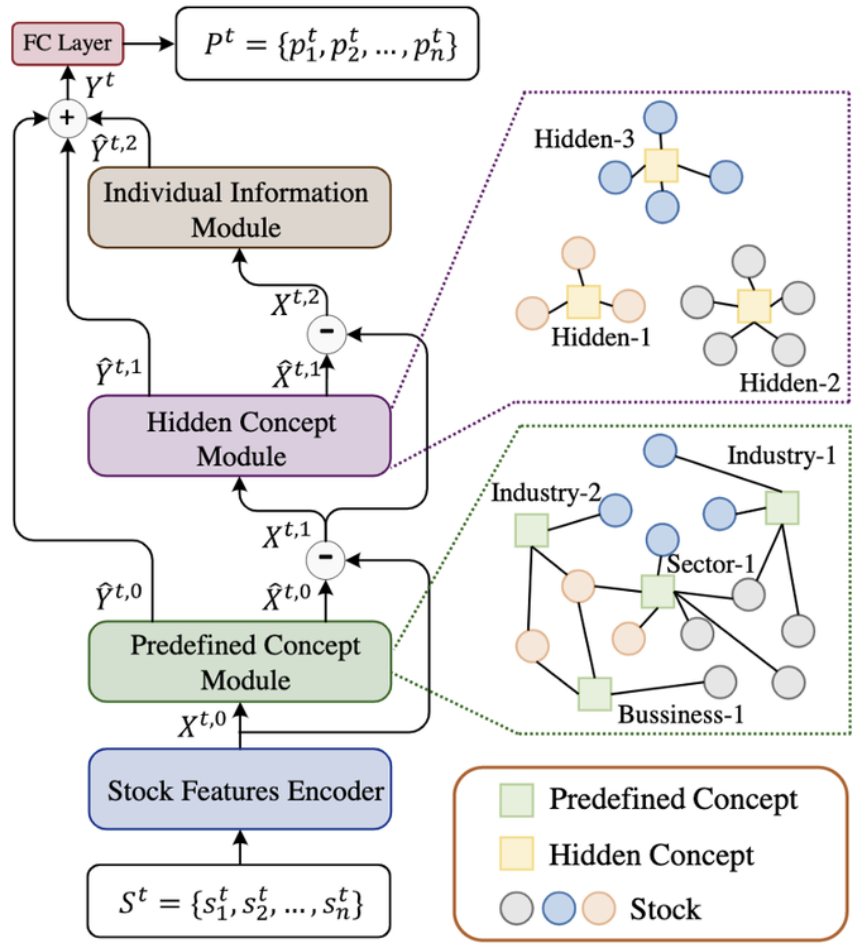
Рисунок 2: Структура модели HIST
Набор акций, используемый для обучения, — это акции, составляющие CSI 300, интервал обучения — 20170201 ~ 20201231, интервал проверки — 20210101 ~ 20211231, интервал тестирования — 20220101 ~ 20230630. Для стандартного представления объектов были выбраны Alpha360 и GRU Qlib: двухслойная сеть с 64 скрытыми блоками. Чтобы избежать переобучения, было установлено отсев 0,5. Первоначальное предопределенное представление концепции взвешивается по общей рыночной капитализации, а в качестве неявных концепций выбираются верхние концепции K = 3 с наибольшим сходством по cos. Метка обучения — Ref($close, -2)/ Ref($close, -1)- 1, функция потерь — регулярная mse, скорость обучения — 0,001, эпоха — 200, а ранняя остановка — 15. Чтобы уменьшить влияние случайности при обучении модели (например, случайность начальных параметров, влияние ранней остановки на окончательное локальное оптимальное решение и т. д.), каждая модель обучается независимо 5 раз, а окончательный результат прогнозирования равен среднее из 5 прогнозов.
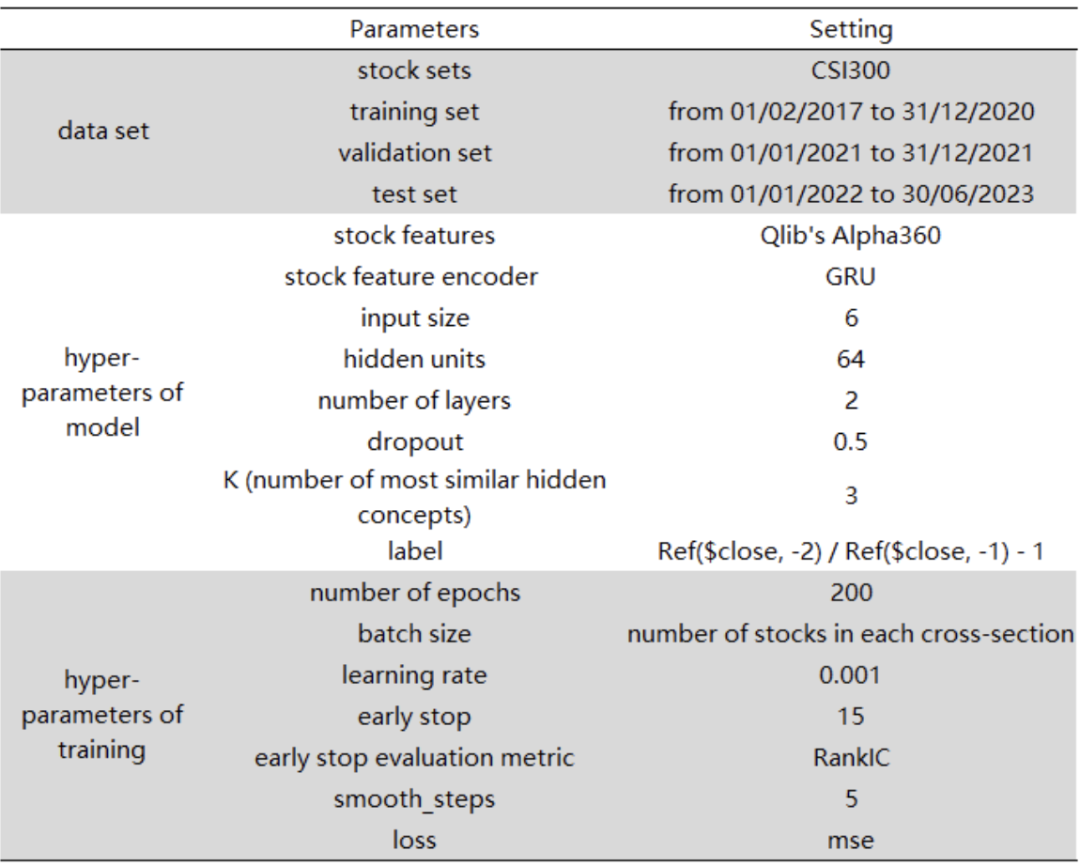
Таблица 1: Подробности конфигурации параметров модели HIST
Кластеры после обнаружения сообществ в различных типах сетей представляют собой предопределенные концепции модели HIST. Из-за различий в предопределенных концепциях в этом отчете было протестировано в общей сложности 5 моделей HIST:
- industry_chain_relation - Предопределенная концепция, основанная на отношениях производственной цепочки HIST
- supply_chain_relation - кцепочка отношения поставок сетькластердля заранее определенной концепции из HIST
- news_cooccurance - Отношения совместного появления новостей в сетикластередля заранее заданной концепции из HIST
- all_relation - В то же время три вышеуказанных предопределенных понятия из HIST
- sam_last_product - В основном занимается продуктом для заранее определенных концепций на самом детальном уровне компании. HIST
На следующем рисунке показана часть структуры данных предопределенной концепции all_relation (состояние расширения недвоичной классификационной диаграммы), где nc_xx соответствует кластеру сети одновременного появления новостей, sc_r_xx соответствует кластеру сети промышленной цепочки, sc_t_xx соответствует поставке. кластер цепной сети, а число, соответствующее xx, представляет собой номер кластера, среднее количество предопределенных концепций в одном сечении составляет 176, из которых насчитывается около 49 кластеров промышленной цепочки, около 100 кластеров цепочки поставок и около. 26 кластеров одновременного появления новостей. индивидуальный. Структура данных остальных предопределенных понятий аналогична показанной на рисунке.

Рисунок 3. Частичная структура данных предопределенной концепции all_relation.
Анализ результатов прогноза
Значение прогноза дохода y, полученное с помощью HIST, можно использовать в качестве синтезированного отдельного фактора, и на нем можно выполнить серию однофакторных тестов, таких как анализ IC, анализ группового дохода и отраслевой анализ, чтобы изучить способность прогнозируемого выбора акций к выбору. ценить.
IC-анализ
В таблице 2 ниже приведены RankIC и точность модели значений прогнозирования модели по 5 предопределенным концепциям. На рисунке 4 ниже показан среднемесячный дневной рейтинг RankIC в пределах тестового интервала. По сравнению с основными предопределенными концепциями исходной компании, предопределенные концепции кластера из трех основных сетей работают лучше. Ее RankIC составляет 3,86–4,25%, а годовой ICIR — 4,368–4,812, но общая точность модели не очень высока, менее 50%, и точность также показывает, что «коэффициент отзыва положительной доходности выше; чем уровень отзыва отрицательной прибыли. «Гораздо более высокие» характеристики. В рейтинге RankIC с 2023 года также наблюдается резкий спад с частыми сменами направления.
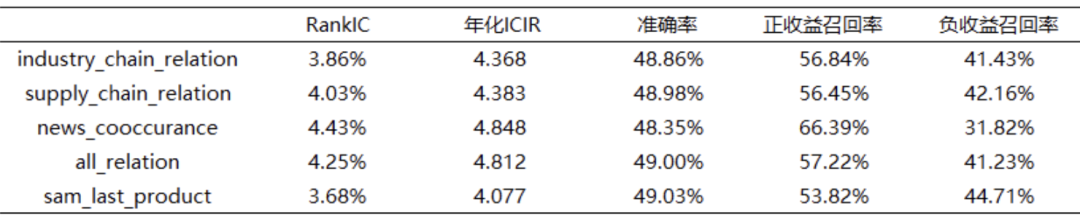
Таблица 2. Производительность IC для прогнозирования дохода и точность модели
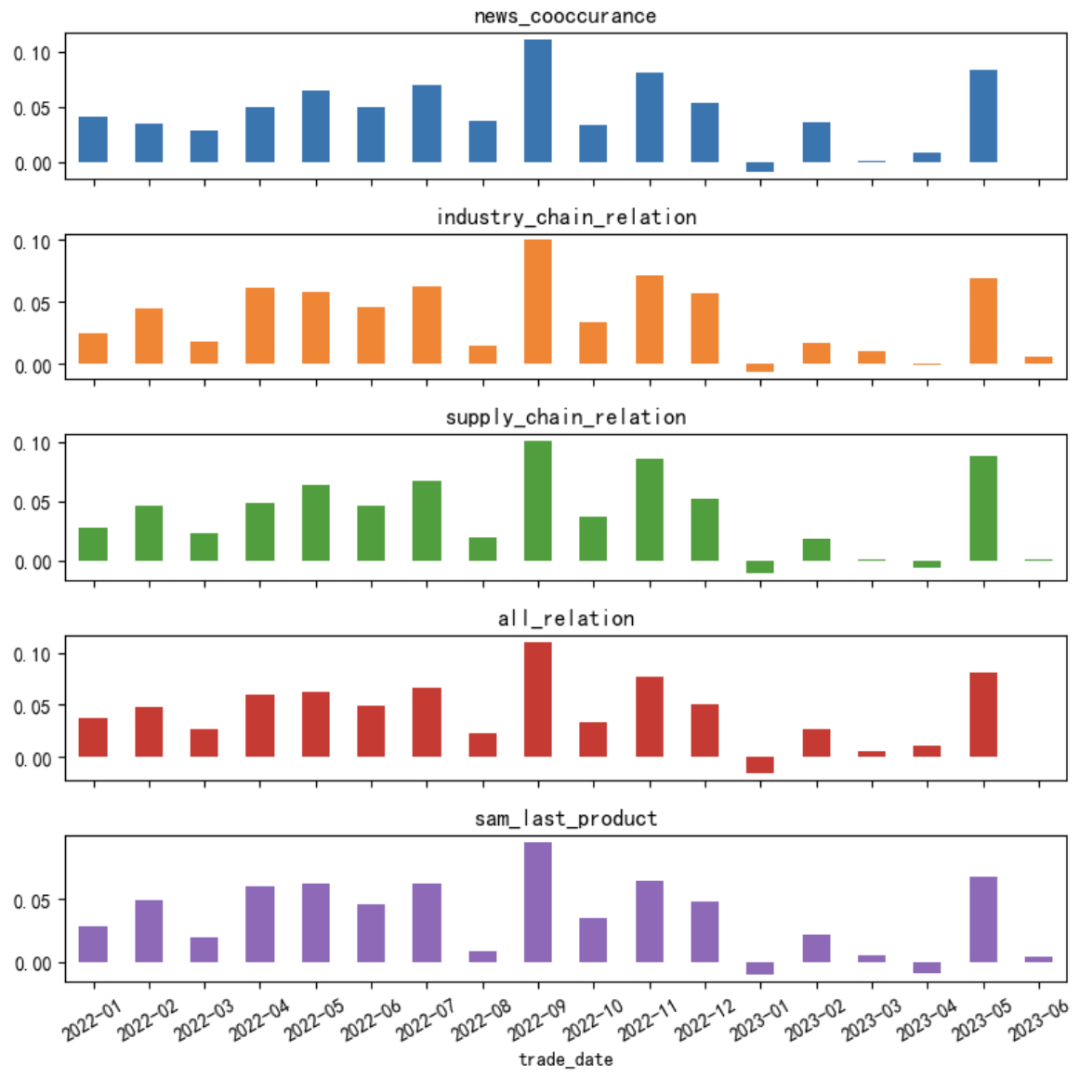
Рисунок 4. Среднемесячный дневной рейтинг RankIC
Чтобы найти причины вышеупомянутого явления, мы дополнительно построили график изменений временных рядов точности модели и распределения значений прогноза будущей прибыли и исходных значений. Что касается точности модели, то на рисунке 5 хорошо видно, что начиная с 2023 года уровень отзыва отрицательной доходности значительно снизился, и более отрицательная доходность прогнозируется как положительная доходность, что увеличивает частоту отрицательных IC и снижает общий средний показатель. IC даже меняет направление IC. В этом тесте проводилось только одно обучение модели, то есть использовались данные до 2022 года для обучения и отладки модели для прогнозирования дохода с 2022 по 2023 год. Время прогнозирования и исторический интервал времени, используемые для обучения модели, велики, а также существует период между В случае эпидемии вы можете перейти на скользящее обучение или исключить время до эпидемии во время обучения, и эффект прогнозирования модели будет значительно улучшен.
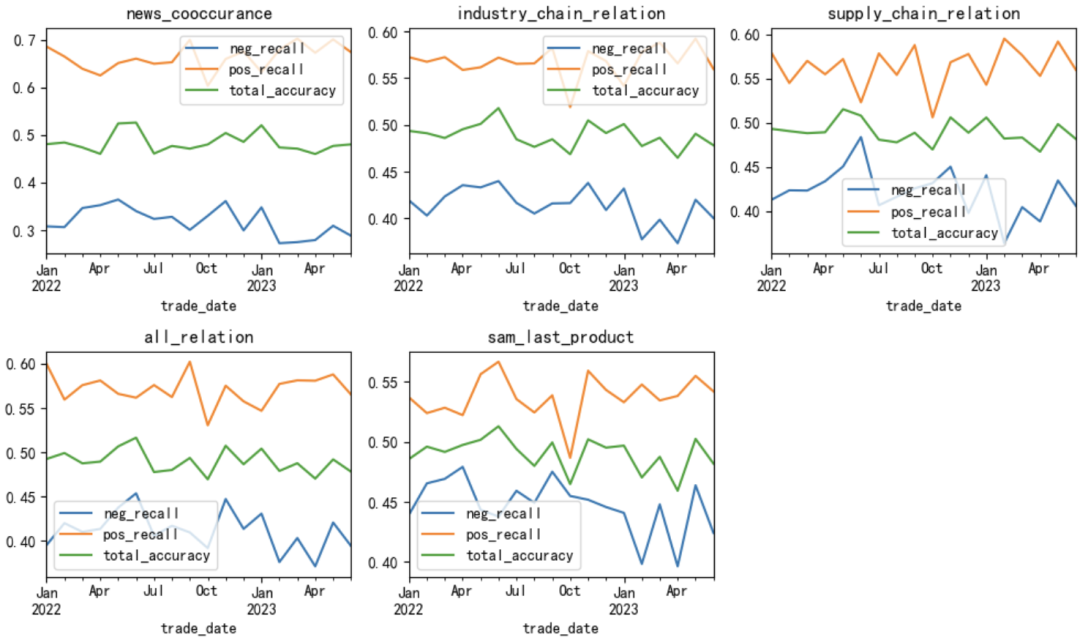
Рисунок 5. Среднемесячные показатели точности модели, а также положительные и отрицательные показатели возврата.
Судя по приведенной ниже диаграмме распределения, распределение прогнозируемых значений будущей прибыли, выдаваемых моделью HIST, относительно смещено влево. В среднем только 39% прогнозируемых значений каждый день меньше 0. производительность CSI 300 в тестовом диапазоне уже очень плохая. В среднем каждый день 52% акций имеют отрицательную доходность, что увеличивает скорость отзыва положительной доходности и снижает скорость отзыва отрицательной доходности.
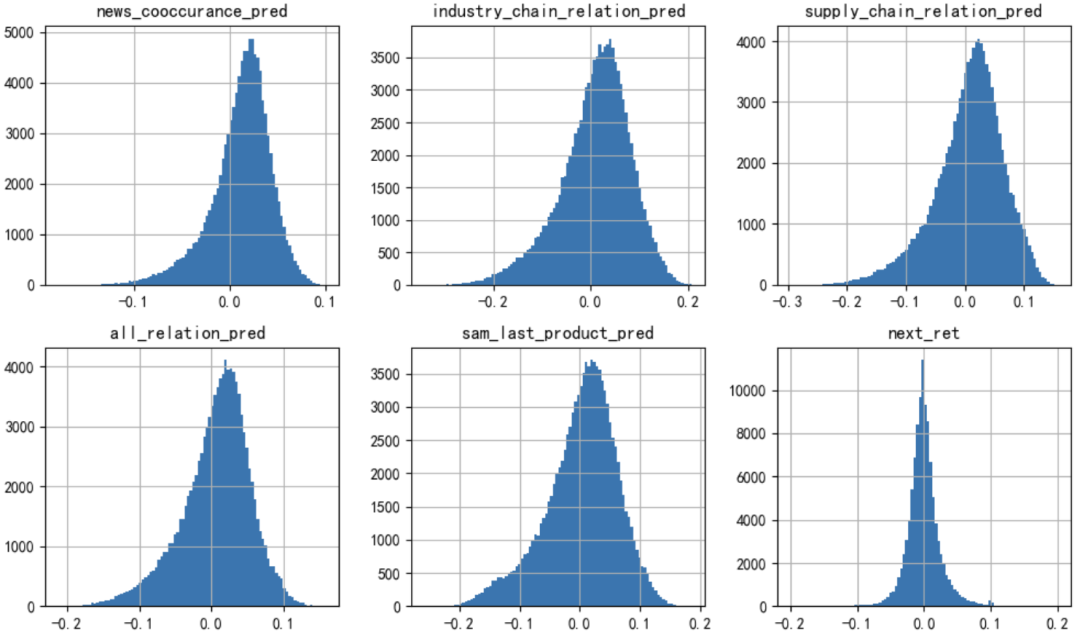
Рисунок 6. Диаграмма распределения прогнозируемой модели будущей стоимости дохода и фактической стоимости будущего дохода.
Анализ доходов группы
Анализ доходов метод группировки акций группысерединаиздля Каждый срез основан на прогнозируемом значении будущей прибыли от малого к большому для Шанхая и Шэньчжэня. 300 Составляющие сортируются, а запасы делятся на 8 группа, которая возвращается раньше top30% Склад находится в г. 8 Группа, 1-7 Каждая группа нажимает 10% Разделите те, у которых наихудшая доходность bottom 10% Склад находится по адресу 1 Группа. Причиной такого разделения является то, что прогнозируемая величина прибыли 70% Квантиль — это очевидная точка отсечения, при которой прогнозируемая прибыль выше, чем 70% Квантильный портфель акций может обеспечить стабильную положительную доходность. поверхность 3 и диаграмма 7-8 Подробно показано 5 Групповые возвраты значений прогнозирования модели в соответствии с заранее определенной концепцией. верх-низ Хотя доходность хеджирования длинных и коротких позиций превосходна, мы обычно больше заботимся о доходности длинной группы, чем короткой группы. Самая высокая годовая доходность длинной группы — это комбинация трех кластеров. all_relation Прогнозируемое значение дохода.
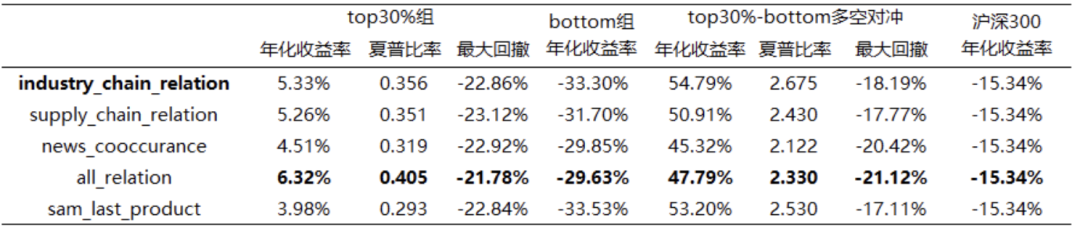
Таблица 3: Показатели оценки дохода группы акций, входящих в CSI 300
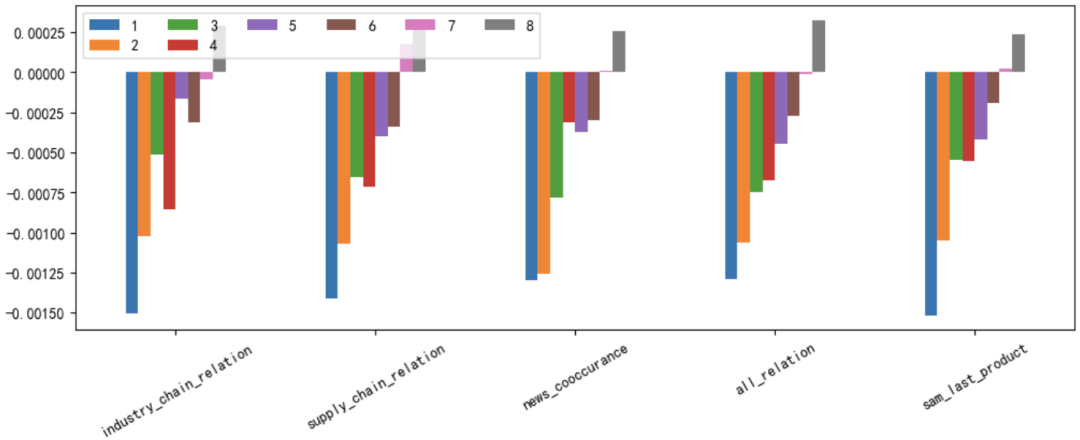
Рисунок 7. Средняя доходность по группе акций, входящих в CSI 300.
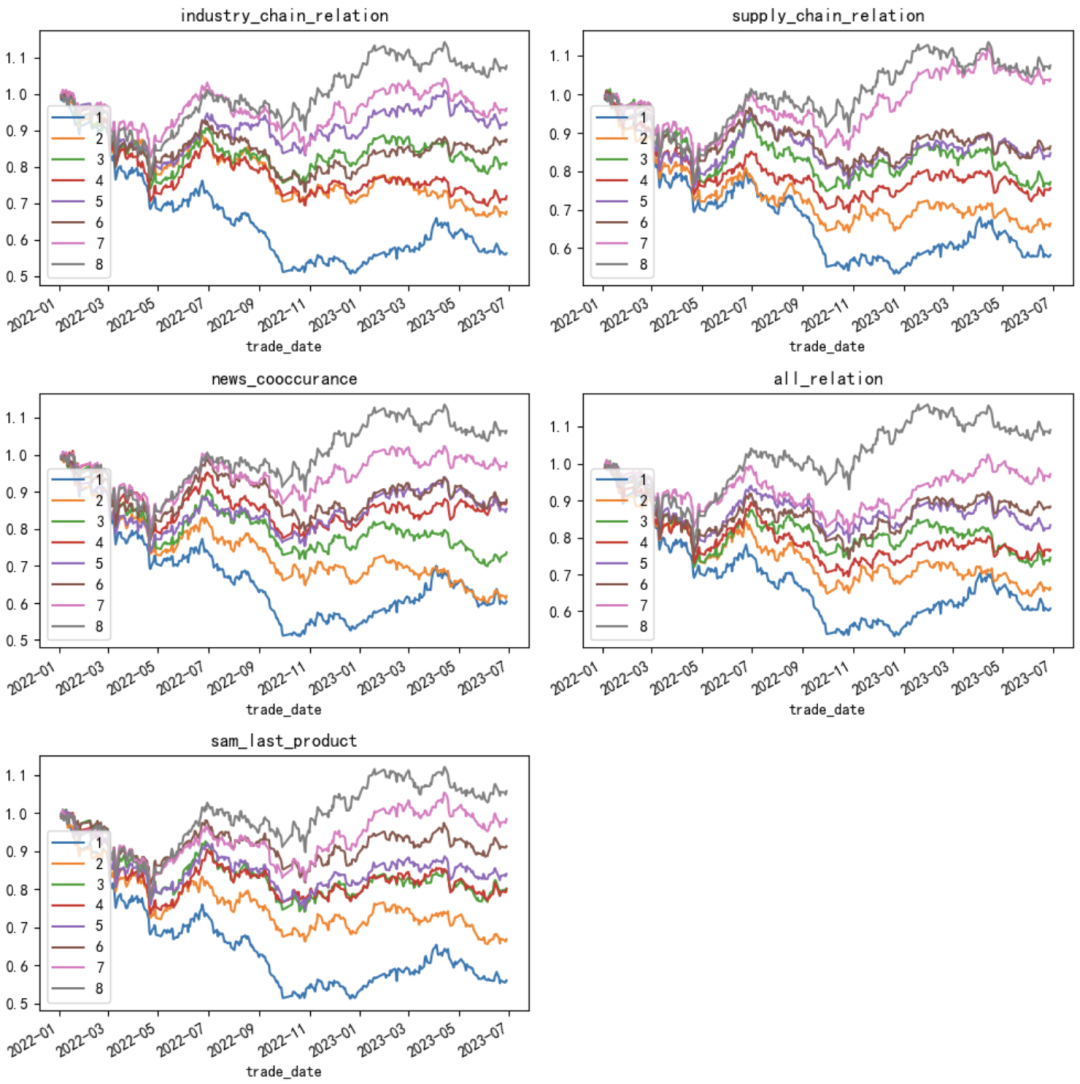
Рисунок 8: Групповая кривая совокупной доходности акций, входящих в CSI 300.
таблица ниже 4 и диаграмма 9 Протестировано дальше top30% Группа относительно Шанхая и Шэньчжэня 300 Сравнительные показатели прибыли. В соответствии с производительностью сгруппированных выше результатов, производительность прогнозируемого значения модели, использующей три кластера графовых сетей в качестве предопределенных концепций, в целом лучше, чем у исходной модели. sam Основным продуктом является прогнозная ценность модели для заранее определенных концепций, которая показывает, что общая информация, представленная кластерами, включая отношения между кластерами, также может использоваться для прогнозирования тенденций акций, что делает ее эффективным альтернативным источником информации. Среди них наиболее результативными all_relation Годовая избыточная доходность равна 25,63%, коэффициент информации составляет 3.135, максимальный ретрейсмент равен -4.2 %. Традиционные основные продукты sam_last_product и кластеры промышленных цепочек industry_chain_relation Все они отражают взаимосвязь между направлениями бизнеса компании, но последнее работает лучше, чем первое.
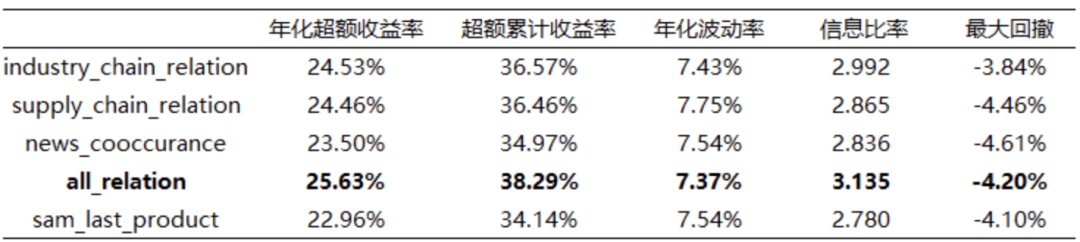
Таблица 4: Шанхай и Шэньчжэнь 300 Акции крупнейших компаний-участников 30% Группа относительно Шанхая и Шэньчжэня 300 Сравнительная прибыль
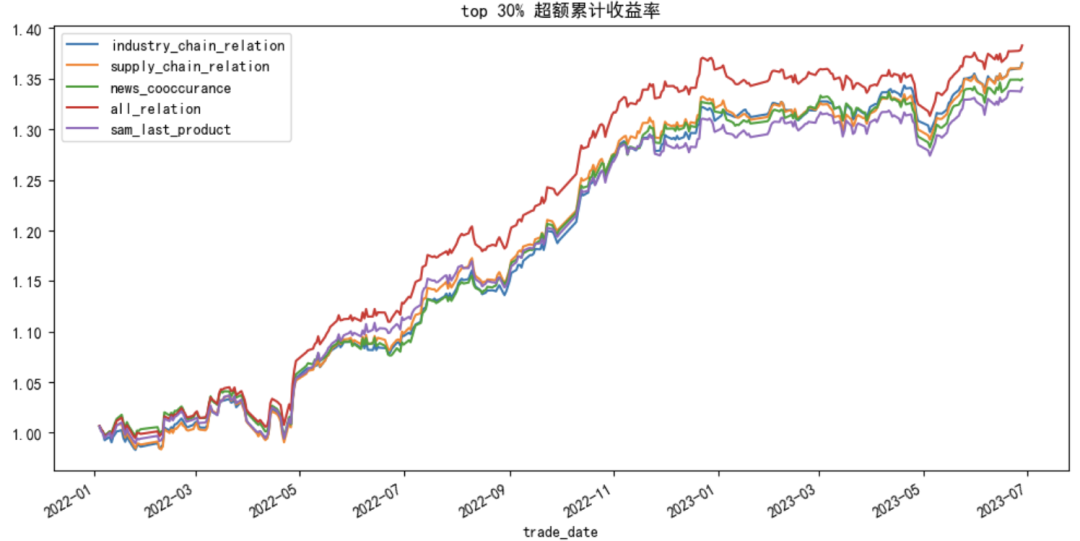
Рисунок 9: Шанхай и Шэньчжэнь 300 Акции крупнейших компаний-участников 30% Кривая избыточной совокупной доходности портфеля акций
Секторальный анализ
Изображение ниже 10 и диаграмма 11 Распределение рыночной капитализации и распределение отрасли внутри каждой группы после группировки значений прогноза модели. С картинки 10 Можно видеть, что распределение акций с большой и малой рыночной капитализацией внутри каждой группы относительно рассредоточено, и ни одна группа не включает только акции с большой рыночной капитализацией или акции с малой рыночной капитализацией, распределение рыночной капитализации между каждой группой также не сильно отличается и относительно; последовательный. С картинки 11 Видно, что распределение отраслей внутри каждой группы относительно рассредоточено и не сконцентрировано на отдельных отраслях; распределение отраслей между каждой группой также относительно последовательно. С точки зрения размеров отрасли и рынка инвестиционные портфели, построенные на основе прогнозируемых значений модели, не будут подвергаться концентрированному воздействию одного риска.
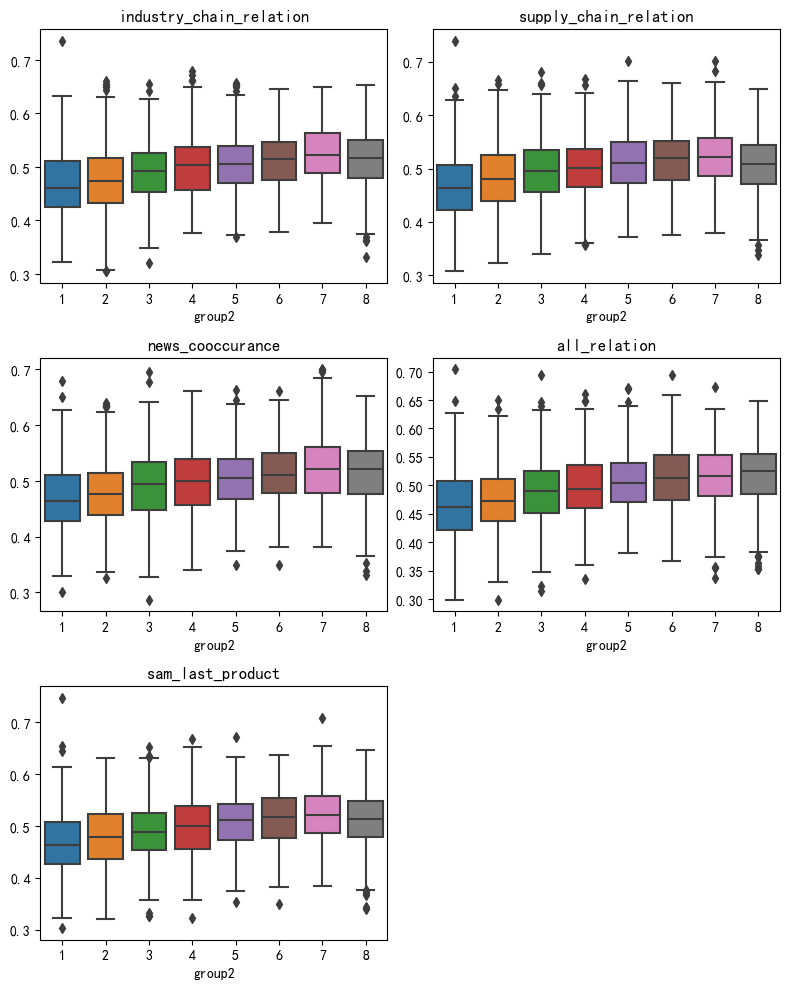
Рисунок 10. Распределение рыночной капитализации внутри каждой группы после группировки акций, входящих в CSI 300.

Рисунок 11. Распределение основных отраслей CITIC внутри каждой группы после группировки акций, входящих в CSI 300.
стратегические исследования
В приведенной выше статье в основном анализируется способность выбора акций по прогнозируемому значению дохода. Влияние реальных торговых условий, таких как комиссии за обработку, не учитывается при расчете дохода. Ниже мы дополнительно проверим встроенную стратегию Topkdropout в qlib для построения прогноза. стоимости, чтобы получить более реалистичные показатели прибыли в торговых условиях. Чтобы сделать начальную позицию относительно совместимой с 30% акций топ-30% с прогнозируемой доходностью, пусть позиция topk=90, n_drop=9, а остальные параметры бэктеста установлены следующим образом:
account=100000000, эталонный показатель, CSI300, цена_сделки, close, open_cost = 0,0005, close_cost = 0,0015, min_cost = 5, limit_threshold = 0,095.
Topkdropout Доход стратегии ниже после вычета комиссий за транзакции, но его все равно можно получить. 10% Вышеуказанная годовая избыточная доходность. Лучшие показатели дохода all_relation, годовая избыточная доходность равна 14.10%,соотношение информациииметь 2.061,Максимальная просадка составляет всегоиметь -5.08%,Интеграция информации из большего количества измерений может сделать прогнозируемое значение и производительность более надежными.
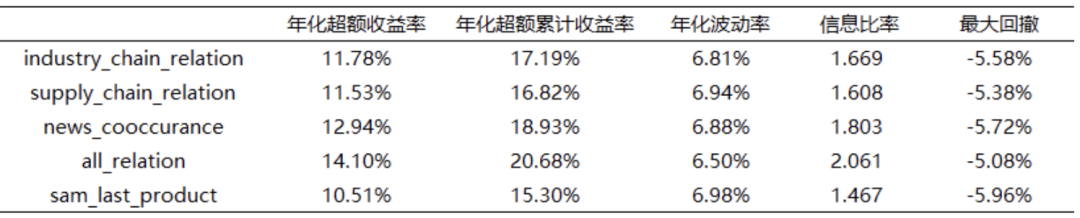
Таблица 5. Эффективность стратегии Qlib TopKdropout (за вычетом транзакционных издержек, topk=90, n_drop=9)
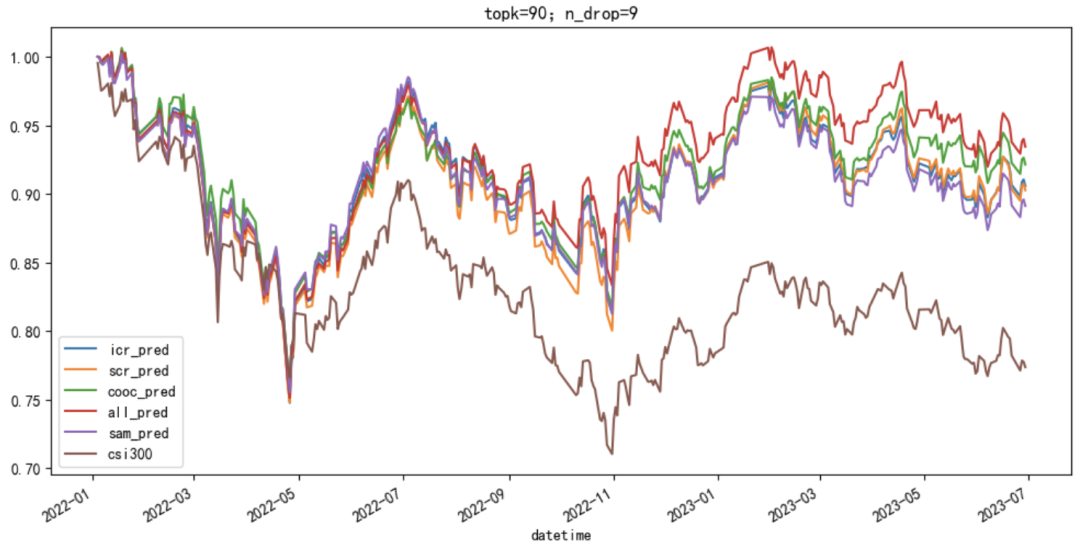
Рисунок 12. Кривая совокупной доходности стратегии Qlib TopKdropout (за вычетом транзакционных издержек, topk=90, n_drop=9)
Подвести итог
В этой статье в качестве предопределенных концепций используются кластеры, полученные в результате обнаружения сообществом сети графов промышленных цепочек, сети графов цепочек поставок и сети графов одновременного появления новостей, а также вводятся данные модели HIST для прогнозирования будущей тенденции цен на акции. С точки зрения выбора акций и эффективности стратегии для прогнозирования прибыли, по сравнению с традиционными концепциями, такими как основные продукты компании или отраслевые классификации, атрибуты кластера, полученные в результате кластеризации в сети графов, действительно содержат ценную дополнительную информацию. В рамках модели HIST, чем богаче информационная составляющая модели (например, одновременное рассмотрение информации из трех измерений операционной деятельности компании, экономической деятельности компании и внимания инвесторов), тем большему объему знаний может научиться модель, и эффективность прогнозирования дохода будет лучше. Это отражает способность модели HIST к обучению многомерной информации. Отношения между акциями сложны и разнообразны. Изучение большего количества связей и извлечение большего количества дополнительной информации также является важным способом улучшить информационное преимущество.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
