Исследование SPSS о покупательском поведении студентов в Интернете: факторный анализ, основные компоненты, кластеризация, перекрестные таблицы и тесты хи-квадрат
С ростом популярности Интернета и бурным развитием электронной коммерции,Сетевой шопинг стал неотъемлемой частью повседневной жизни студентов. Студенты колледжа — главная сила в покупках,Его концепции потребления, поведенческие характеристики и влияющие факторы имеют важное исследовательское значение для развития индустрии электронной коммерции. поэтому,Целью данной статьи является использование анкетного опроса.,Помогите клиентам провести углубленное исследование и анализ покупательского поведения студентов колледжей.,Чтобы предоставить целевые предложения по рыночной стратегии предприятиям электронной коммерции.(Нажмите «Прочитать исходный текст» в конце статьи, чтобы получить полные данные кода.)。
Похожие видео
В этом опросе мы тщательно разработали анкету, которая охватывает многие аспекты онлайн-покупок студентов, включая частоту покупок, выбор торговой платформы, мотивацию покупок, удовлетворенность покупками и т. д. Что касается постановки вопросов в анкете, мы приняли две формы вопросов с одним и несколькими вариантами ответов, чтобы обеспечить полноту и точность результатов опроса. Каждый вопрос занимает один столбец в таблице данных, что облегчает последующую сопоставление и анализ данных.
Для анализа данных мы использовали различные методы. Во-первых, с помощью выборочной описательной статистики мы использовали таблицы частотного распределения для проведения детального анализа выборки, включая общий процент выборки, действительный процент и совокупный процент. Эти данные дают нам базовый обзор поведения студентов в Интернете при совершении покупок. В то же время мы также используем профессиональное программное обеспечение для статистического анализа для обработки данных и визуально отображаем значение каждого состояния переменной с помощью гистограмм и круговых диаграмм, что делает результаты анализа более интуитивно понятными и простыми для понимания.
Во-вторых,Мы использовали метод факторного анализа,по объяснениюпеременнаявыявить взаимосвязь междуданныеструктура。факторный Являясь эффективным инструментом анализа данных, анализ способен разбивать большое количество переменных на несколько измерений, тем самым упрощая структуру данных. В данном исследовании мы используем факторный Анализ изучил факторы, влияющие на поведение студентов в сетевых покупках, а также выявил глубинные причины поведения студентов в сетевых покупках.
также,Также мы использовали метод кластеризационного анализа.,Особенно алгоритм кластеризации k-means. Этот метод помогает нам классифицировать группы студентов со схожими характеристиками покупательского поведения.,Это приводит к лучшему пониманию различий и сходств между различными группами.
Наконец, чтобы изучить влияние различных образов жизни на поведение студентов в онлайн-покупках, мы объединили перекрестные таблицы и тесты хи-квадрат. С помощью теста хи-квадрат мы проверили правдоподобие исходной гипотезы на уровне значимости. Впоследствии была использована перекрестная таблица, чтобы показать различия в поведении онлайн-покупок среди студентов с разными типами образа жизни, что оказало мощную поддержку компаниям электронной коммерции в разработке персонализированных рыночных стратегий для студентов колледжей с разным образом жизни.
Используйте описательную статистику
Гендерная статистика опрошенных студентов: 67 мальчиков и 140 девочек. Соотношение мужчин и женщин близко к 1:2.
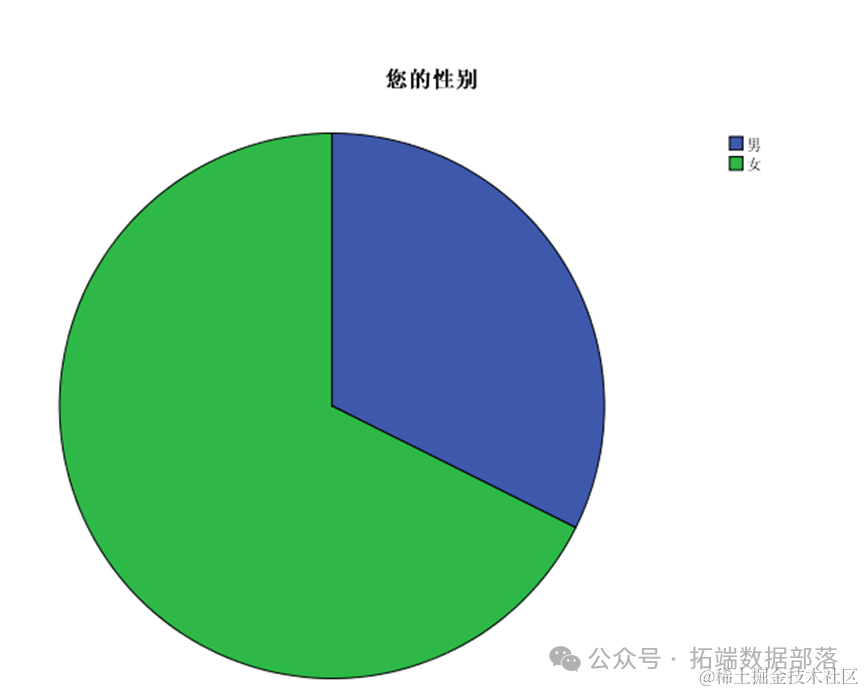
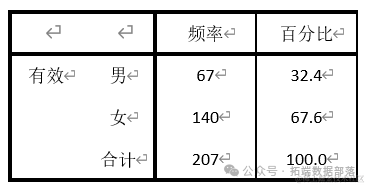
Из таблицы частот соотношения полов видно, что девочек 140, что составляет 67,6%, и мальчиков 67, что составляет 32,4%. Таким образом, среди респондентов больше девочек и меньше мальчиков.
Затем мы смотрим на пропорции во всех классах.
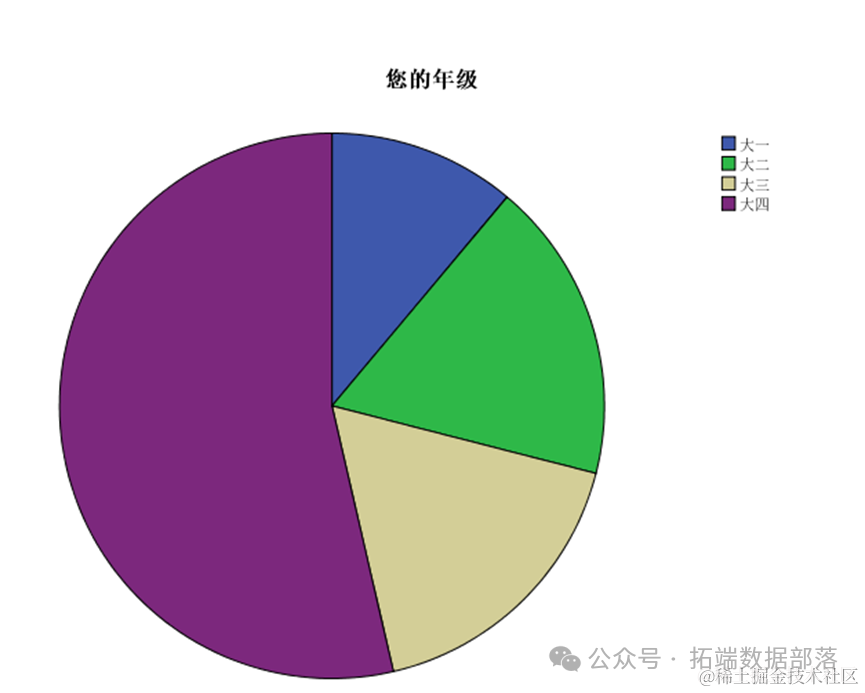
На круговой диаграмме мы видим, что пожилые люди составляют большинство, за ними следуют юниоры.

Из таблицы частот мы видим, что есть 111 старших классов, что составляет 53,6%, 36 младших, что составляет 17,4%, и 37 второкурсников, что составляет 17,9%.
Затем мы посмотрели на ежемесячные расходы на проживание респондентов.
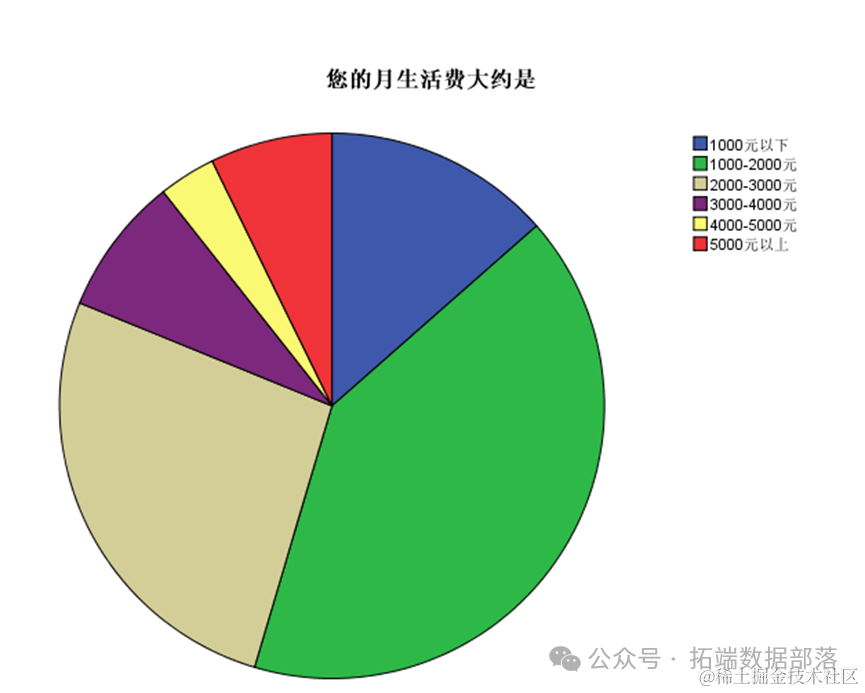
Из расходов на жизнь в отрасли мы видим, что ежемесячные расходы на жизнь большинства респондентов составляют от 1000 до 2000 юаней, а затем от 2000 до 3000 юаней.
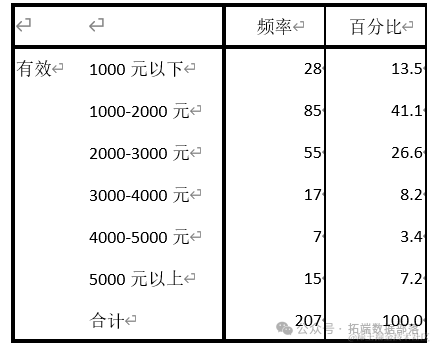
Из таблицы мы видим, что 15 человек имеют расходы на жизнь более 5000 юаней, что составляет 7,2%, а 7 человек имеют ежемесячные расходы на жизнь от 4000 до 5000 юаней, что составляет 3,4%. Есть 55 человек с расходами на проживание от 2000 до 3000 юаней, что составляет 26,6%.
Затем мы изучили ежемесячную частоту покупок респондентов в Интернете.
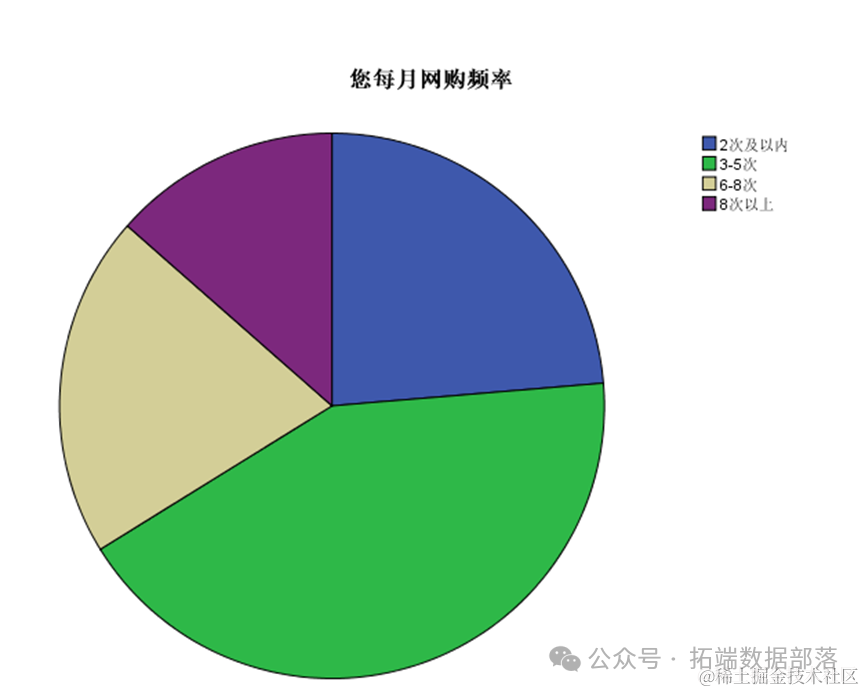
На картинке мы видим, что подавляющее большинство людей делают покупки онлайн от 3 до 5 раз.
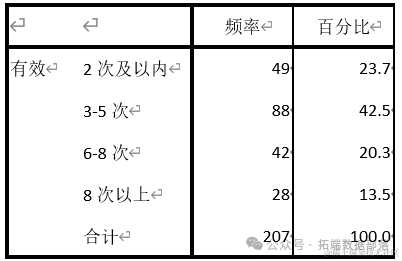
Из таблицы мы видим, что 28 человек совершают покупки онлайн более восьми раз, что составляет 13,5%. 42 человека, что составляет 20,3%, совершают покупки онлайн от 6 до 8 раз. 88 человек пользуются Интернетом от 3 до 5 раз, что составляет 42,5%.
01
02
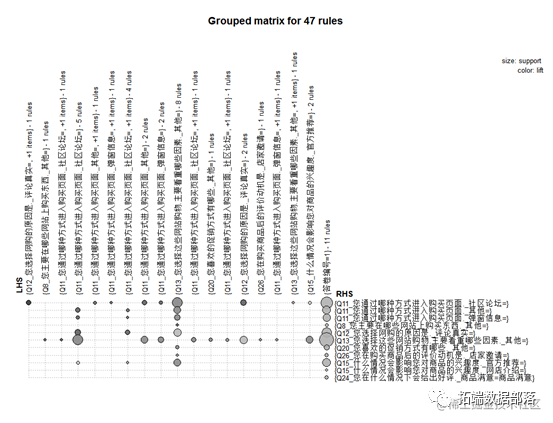
03
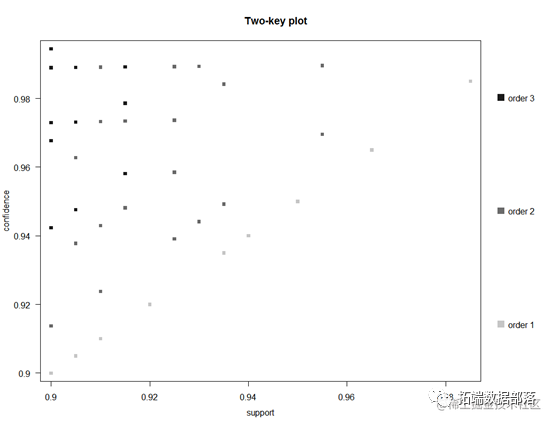
04

Анализ надежности
Надежность — это степень, в которой весы дают стабильные результаты, если измерение повторяется много раз. Анализ надежности называется анализом надежности. Анализ надежности определяется путем получения доли систематических отклонений по шкале, что может быть выполнено путем определения корреляции между баллами, полученными при различных применениях шкалы. Следовательно, если корреляция в анализе надежности высока, шкала дает согласованные результаты и, следовательно, является надежной.
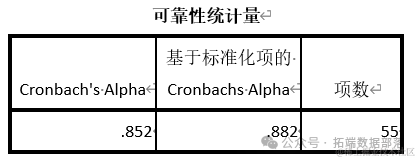
В целом мы считаем, что коэффициент надежности составляет около 0,8, что является хорошей степенью доверия. Из результатов мы видим, что коэффициент составляет около 0,8, что указывает на то, что опрос имеет определенную степень доверия.
Анализ достоверности
Валидность – это концепция, Степень, в которой вывод или измерение обоснованы и точно соответствуют реальному миру. Слово «действительный» происходит от латинского слова validity, что означает сильный. Валидность средства измерения (например, теста в образовании) считается степенью, в которой этот инструмент измеряет то, для измерения чего он предназначен; В этом случае достоверность соответствует точности. Проверьте, подходит ли переменная для факторной Обычно используемые методы анализа — это тест сферичности Бартлетта и тест сферичности.
Предварительные результаты тестирования шкалы образа жизни в этой статье следующие:

Результаты таблицы показывают,Приблизительное значение хи-квадрат для теста на сферичность составляет 3259,28.,Меньше чем означает, что исходная матрица не может быть единичной матрицей.,То есть существует высокая корреляция между исходной переменной. Значение метрики,По результатам проверки двух вышеуказанных пунктов можно сделать вывод, что данные в данном опроснике подходят для факторного анализа.
факторный анализ
факторный Анализ — это способ объяснить структуру данных путем объяснения корреляции между переменными. факторный анализ Разделение данных на несколько измерений путем сокращения большого количества переменных в меньший набор потенциальных переменных или факторов. Он обычно используется в социальных науках, исследованиях рынка и других отраслях, где используются большие наборы данных.
Факторный анализ — это метод моделирования переменных наблюдений и их ковариационной структуры с точки зрения меньшего числа потенциально ненаблюдаемых (скрытых) «факторов». Эти факторы часто рассматриваются как широкие концепции или идеи, которые могут описать наблюдаемое явление. Например, базовое желание достичь определенного социального уровня может во многом объяснить потребительское поведение. Эти ненаблюдаемые факторы более интересны для социологов, чем наблюдаемые количественные показатели.
Сделать переменную лучше адаптированной к факторной анализпомещение,Нам необходимо очистить исходную переменную на основании полученных результатов. Обычно используемой мерой является универсальность переменной (дисперсия общего фактора).,То есть вклад одного элемента в общую дисперсию. Вообще говоря,Начальная переменная необходима для удаления переменной, которая обычно не используется с переменной.,Следующим шагом является извлечение факторов, которые имеют большую общность, чем исходная переменная.
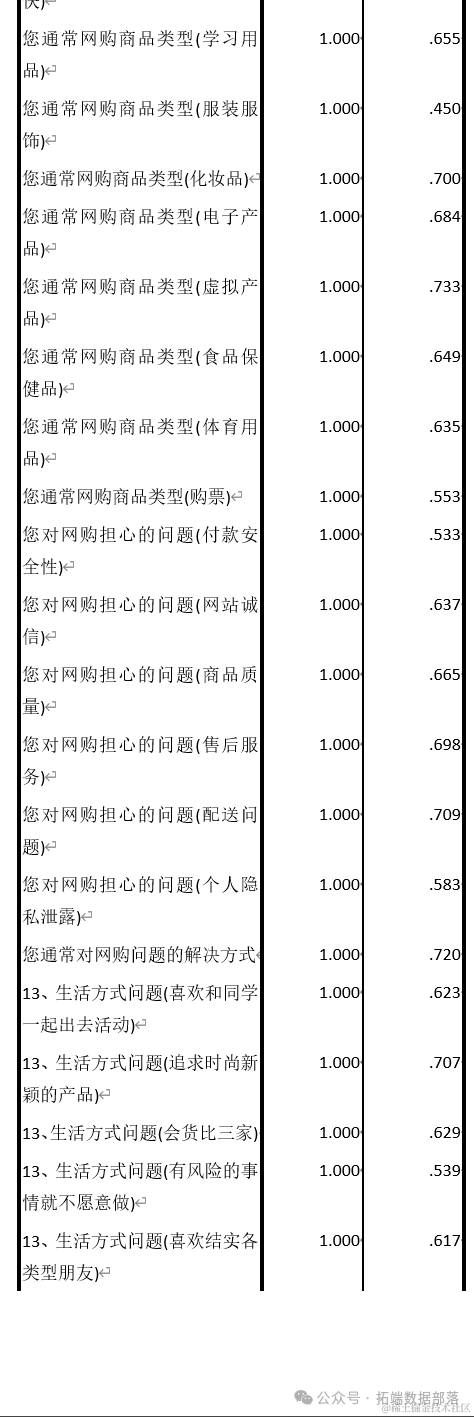
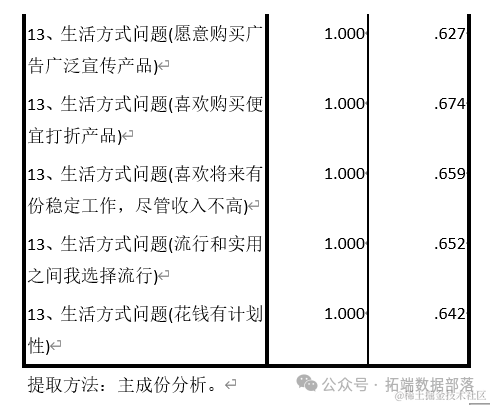
Посредством приведенного выше анализа для извлечения факторов используется анализ главных компонентов, а для получения вышеуказанной шкалы факторной нагрузки используется дисперсия максимального повернутого фактора. В соответствии со стандартом извлечения, собственные значения, абсолютное значение которых больше, чем коэффициент. нагрузки извлекаются и превышают коэффициент. Этот коэффициент убирает из вопроса «вопрос о типе товаров, которые вы обычно покупаете онлайн (одежда и аксессуары)» и сохраняет значение нагрузки больше 0,5.
Количество факторов обычно определяется с помощью индексов или собственных значений.
Извлеченные квадраты и столбцы нагрузки дают коэффициент вклада дисперсии извлеченного фактора, а коэффициент вклада дисперсии извлеченных общих факторов после вращения определяется количеством факторов. Собственное значение представляет собой двумерную пространственную диаграмму, которая может более интуитивно отображать распределение. каждого фактора.
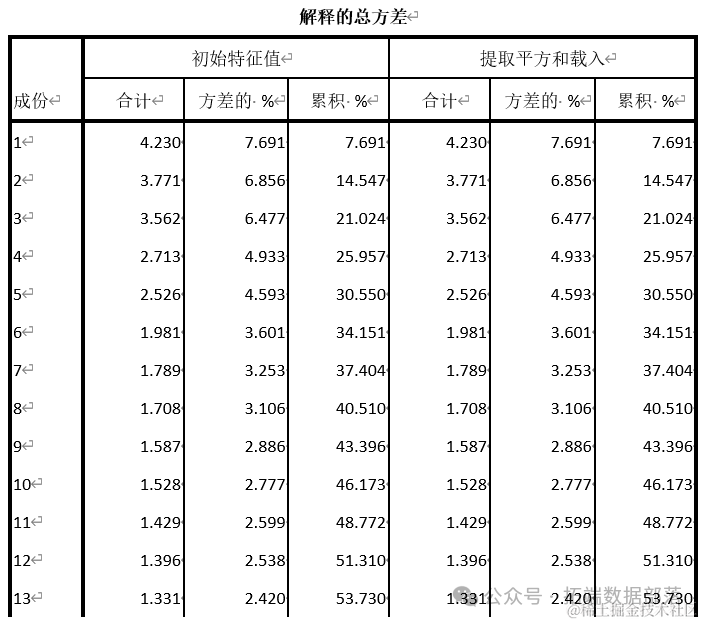
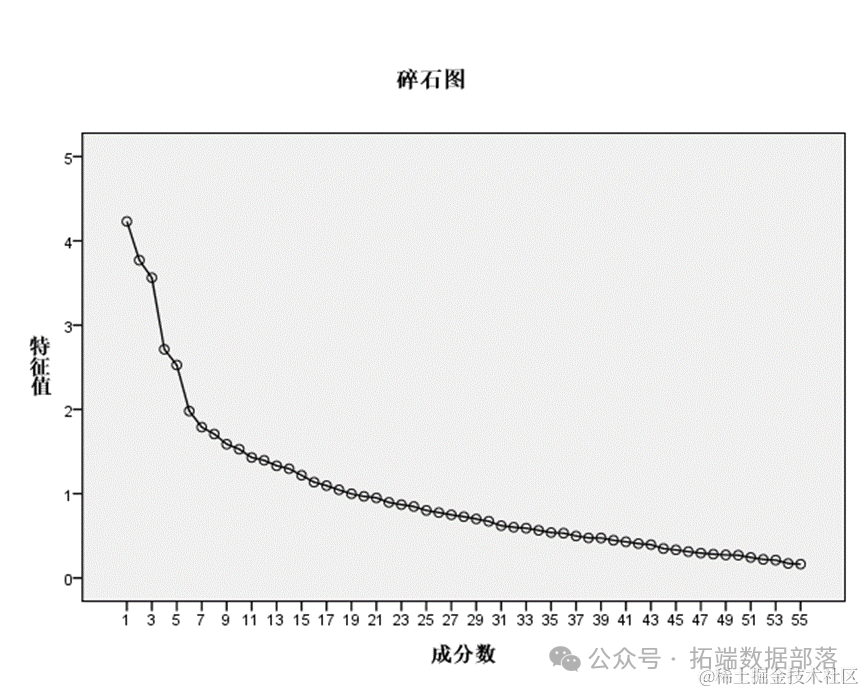
Как видно из рисунка выше, на кривой 6-го фактора имеется очевидный пик. Кривая перед 6-м фактором очень крутая, тогда как кривая после седьмого фактора имеет тенденцию быть плоской. В таблице вкладов характеристического корня и дисперсии первый общий фактор объясняет общую дисперсию переменной, второй общий фактор объясняет общую дисперсию переменной, третий общий фактор объясняет общую дисперсию переменной, а четвертый общий фактор объясняет общую дисперсию переменной, пятый общий фактор объясняет общую дисперсию переменной, шестой общественный фактор дисперсии объясняет общую дисперсию переменной, совокупную ставку вклада, и эти 6 факторов могут быть хорошими представителями переменной. информация.
При анализе главных компонентов количество переменных с самыми высокими нагрузками для фактора сокращается для получения окончательного фактора, как показано в следующей таблице:
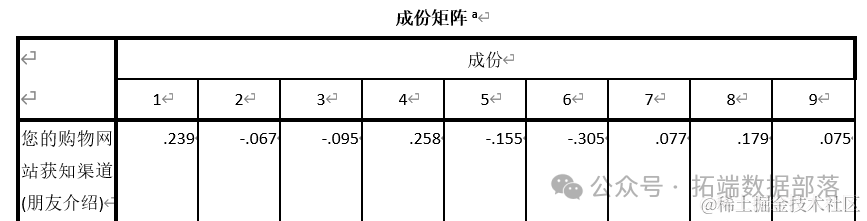
Из нагрузки первого фактора мы можем обнаружить, что крупнейшими факторами являются «онлайн-покупки из-за обновлений продуктов», «причина, по которой вы выбираете онлайн-покупки (модные тенденции)», «причина, по которой вы выбираете онлайн-покупки (быстрый продукт)». обновление)» «Проблемы образа жизни (погоня за модными и новыми продуктами)» — это спонтанное, бессознательное и незапланированное покупательское поведение, имеющее определенную сложность и эмоциональные факторы, поэтому мы можем думать о нем как об импульсивной покупке.
кластеризация
k-meansкластеризация — метод векторного квантования.,Первоначально из обработки сигналов,Добро пожаловать в анализ кластеризации при раскопках данных. Целью k-meansкластеризации является разделение n наблюдений на k кластеров.,где каждое наблюдение принадлежит кластеру с ближайшим средним значением,Используется как прототип кластера.
Проблема вычислительно сложна (однако NP-трудна);,Обычно используются эффективные эвристики, которые быстро сходятся к локальному оптимуму. Эти алгоритмы обычно аналогичны алгоритму максимизации ожидания для смесей гауссовских распределений с помощью итерационных методов уточнения, используемых обоими алгоритмами. также,Однако все они используют кластерные центры для моделирования данных;,Кластеризация k-средних имеет тенденцию находить кластеры сопоставимой пространственной протяженности.,Механизм максимизации ожидания позволяет кластерам иметь разную форму.
Этот алгоритм имеет слабую связь с классификатором k-ближайших соседей.,Это популярный метод машинного обучения для классификации.,из-за буквы К в имени,Часто путают с k-средними. Новые данные можно классифицировать по существующей кластеризации, применяя классификатор 1-ближайшего соседа к центрам кластеризации, полученным с помощью k-средних. Это называется классификатором ближайшего центроида или алгоритмом Роккио.
Путем спаривания Эти шесть факторов выполняют анализ динамической кластеризации. По статистическим принципам,Заявка окончательно выбрала три центра кластеризации,Разделите образ жизни студентов колледжа на три категории.,Результаты дискриминантного анализа представлены в таблице.
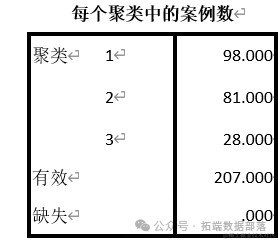
кластеризацияназад,Мы можем получить количество образцов в каждой кластеризации.,Количество образцов и доли выборок, входящие в каждый кластер, показаны в таблице:
Конкретные три категории из шести факторов перечислены в таблице. Чем выше положительный балл данных в таблице, тем выше степень идентификации индекса; чем меньше отрицательное значение, тем выше степень идентификации индекса.
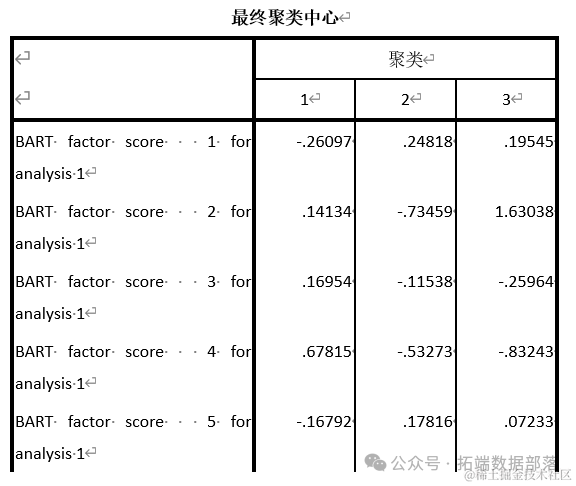
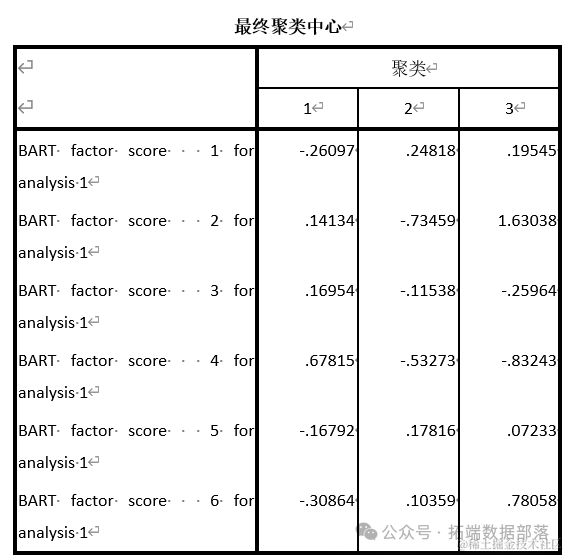
В соответствии с оценкой фактора образа жизни каждой группы и информацией, содержащейся в факторе, каждая группа описывается и называется:
Видно, что наиболее узнаваемым фактором в первой категории является фактор № 4: использование стипендий для покупки, типы товаров, которые вы обычно покупаете онлайн (покупка билетов), ваши опасения по поводу онлайн-покупок (утечка личной информации), проблемы образа жизни. (готовность покупать рекламу) Широко продвигать товар), тип товаров, обычно покупаемых в Интернете (школьные принадлежности).
Анализ хи-квадрат
Критерий хи-квадрат (также называемый тестом χ2) — это любой тест статистической гипотезы, в котором выборочное распределение тестовой статистики представляет собой распределение хи-квадрат, когда нулевая гипотеза верна. Без других оговорок «критерий хи-квадрат» часто используется как сокращение для теста хи-квадрат Пирсона.
Критерии хи-квадрат обычно состоят из квадратов ошибок или выборочных дисперсий. Статистика испытаний, следующая за распределением хи-квадрат, получена из предположения о независимых нормально распределенных данных, что справедливо во многих случаях из-за центральной предельной теоремы. Вы можете использовать тест хи-квадрат, чтобы попытаться отвергнуть нулевую гипотезу о независимости данных.
Также считается, что критерий хи-квадрат является таким асимптотически верным тестом, что означает, что распределение выборки (если нулевая гипотеза верна) может сделать размер выборки достаточно большим, чтобы в достаточной степени аппроксимировать желаемое распределение хи-квадрат. Критерии хи-квадрат используются для определения наличия существенных различий между ожидаемыми и наблюдаемыми частотами в одной или нескольких категориях.
Сначала мы проводим тест хи-квадрат по аспектам пола и частоты покупок в Интернете. Мы определяем, существуют ли различия в частоте покупок в Интернете для разных полов.
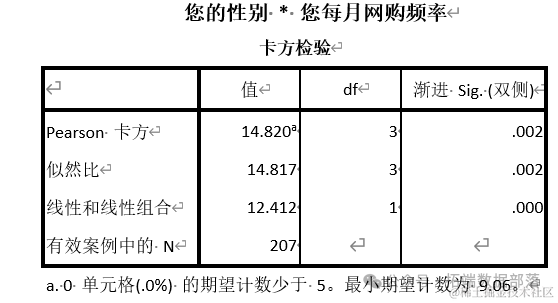
Из таблицы ниже мы видим, что он всегда меньше 0,05, что отвергает нулевую гипотезу и указывает на значительную разницу в частоте онлайн-покупок между студентами колледжей разного пола.
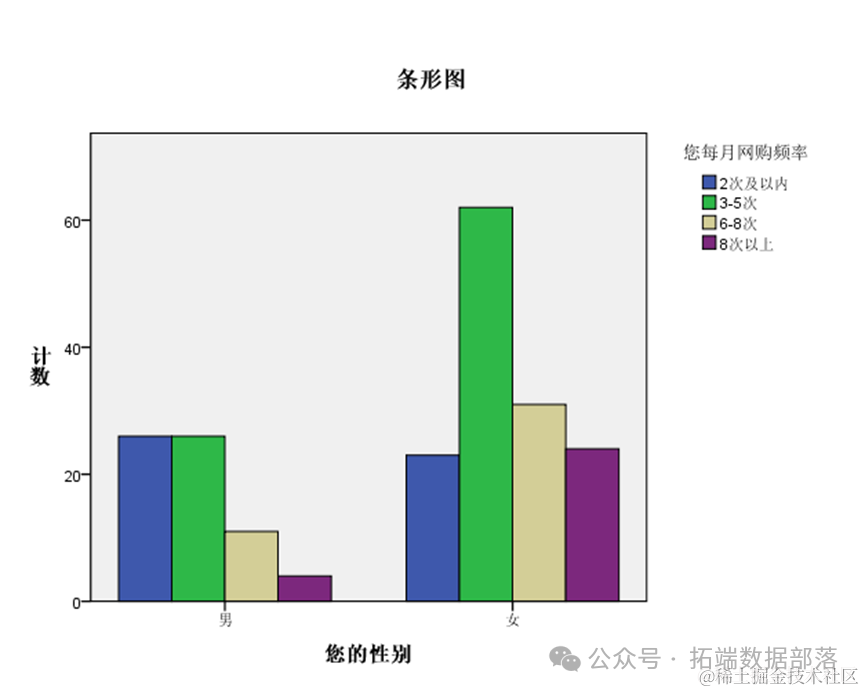
Из приведенной выше гистограммы мы также можем определить очевидные различия в частоте онлайн-покупок, соответствующих разным полам.
Затем мы оцениваем размеры частоты сети, соответствующие различным ежемесячным расходам на проживание, и проводим тест хи-квадрат, чтобы увидеть, есть ли значительная разница?
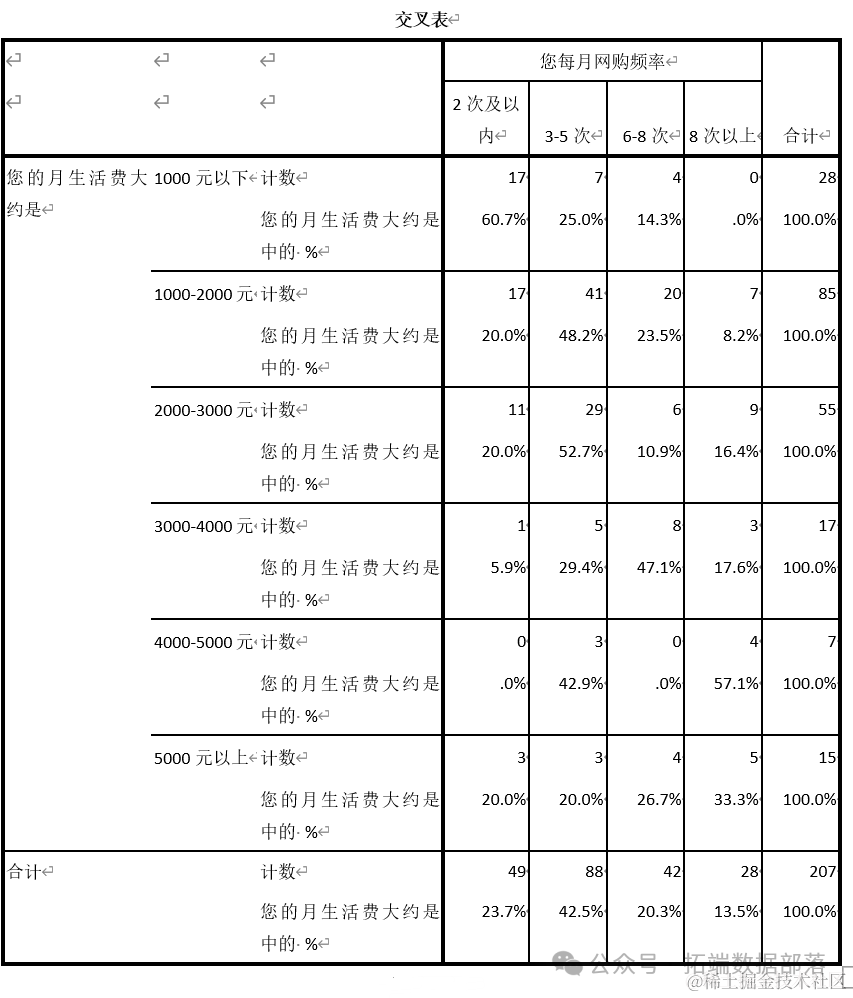
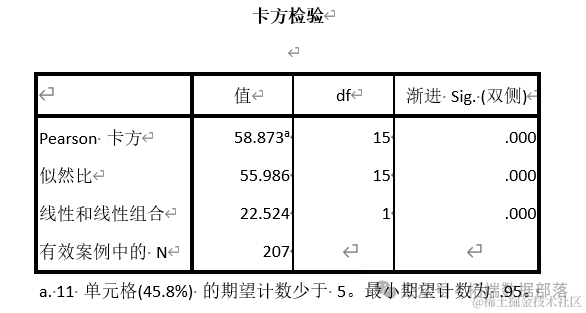
Из приведенной выше таблицы мы видим, что p меньше 0,05, поэтому мы считаем, что существует значительная разница в доле онлайн-покупок, соответствующей различным расходам на жизнь.
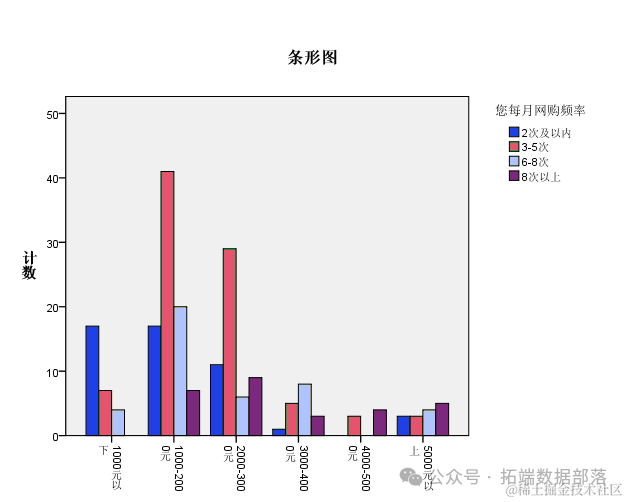
Из приведенной выше гистограммы мы видим, что те, у кого ежемесячные расходы на жизнь составляют от 1000 до 2000, совершают самые частые онлайн-покупки. Из разницы в частоте онлайн-покупок видно, что существуют значительные различия в доле онлайн-покупок, соответствующей разным расходам на жизнь. Существуют значительные различия в частоте онлайн-покупок между студентами колледжей разного пола.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
