Исследование Меты о законе масштабирования для рекомендательных систем глубокого обучения
Автор | Помидор любит яйца Организация | https://zhuanlan.zhihu.com/p/688913185
Привет всем, это NewBeeNLP. Сегодня взгляните на исследование Meta о законе масштабирования, системе рекомендаций по глубокому обучению.
Ноль, бумажная информация
- Название диссертации: Вуконг: К закону масштабирования для крупномасштабных рекомендаций
- Ссылка на статью: https://arxiv.org/abs/2403.02545.
- Информация об авторе: Все авторы из Meta.
1. Общее резюме
В данной статье рассматривается вопрос. Поскольку количество параметров в плотном слое рекомендательной системы (то есть в слое расчета, отличном от таблицы внедрения) продолжает увеличиваться, будут ли постепенно увеличиваться рекомендуемые показатели?
В этой статье дан однозначный ответ, т. Внутренний набор данных со 146 миллиардами записей и 720 функциями. постепенно расширяйте параметры Плотного слоя, Объем расчета обучения WuKong, модели, предложенной в этой статье, варьируется от 1GFLOP/пример увеличивается до 100 GFLOP/example(100 GFLOP/пример эквивалентен шкале вычислений GPT3), шкала параметра плотного слоя варьируется от 0,74B до 17B, а соответствующие показатели производительности демонстрируют тенденцию к постоянному улучшению.
Общий вклад этой статьи:
- Предложена новая структура кроссовера признаков.,По имени Вуконг,Наилучшие результаты достигнуты в эпизодах с офлайн-данными
- Об этом сообщает Система рекомендацийсерединаизScale Law,Что касается вычислительной сложности, модель Воконга обеспечивает стабильность роста примерно на два порядка. Учетверение обучающих вычислений приведет к улучшению производительности на 0,1%.
Я имею в виду, что Meta недавно сообщила о явлении закона масштаба в модели генеративных рекомендаций, предложенном различными группами. Для получения подробной информации обратитесь к следующим вопросам:
- Как оценить последний документ Meta об алгоритме рекомендаций: унифицированные генеративные рекомендации впервые победили иерархическую архитектуру глубинных системных рекомендаций? https://www.zhihu.com/question/646766849
2. Стратегии Укуна и Чешуи
2.1 Функциональный модуль
Элементы имеют блочную конструкцию: размер каждого элемента имеет Меньшие подразмерности служат базовыми единицами. (Например, обычно используются 32 измерения, которые можно разделить на четыре базовые единицы по 8 измерений), а затем для важных функций можно использовать больше базовых единиц, чтобы получить более длинные размеры объекта.
Функции переменной длины могут принести некоторые эффекты. Вы также можете обучать блоки полной длины во время обучения, а затем использовать функцию Featuredropout для удаления соответствующих блоков.
Во время кроссовера объектов каждая единица будет использоваться как независимый объект для участия в кроссовере (сохранение постоянной длины единицы будет способствовать кроссоверу функций).
2.2 Wukong
В целом, Wukong — это относительно распространенная категория моделей CTR. Она использует структуру, которая сначала использует слой Wukong для выполнения пересечения функций, а затем использует MLP для генерации результатов прогнозирования.
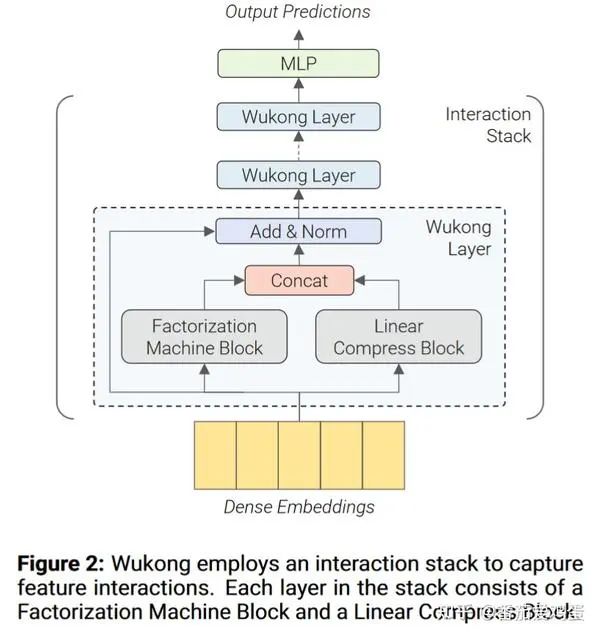
Как показано на рисунке выше, каждый уровень Wukong содержит блок машины факторизации (сокращенно FMB) и блок линейного сжатия (сокращенно LCB). Наконец, выходные данные двух модулей соединяются и добавляются остаточные связи и LayerNorm.
Предположим, что характеристическая матрица определенного образца. Конкретная формула расчета слоя Вуконг выглядит следующим образом:
ФМБ работает следующим образом:
FM — это модуль функционального кроссовера, и в этой статье для захвата кроссовера высокого порядка используется структура, аналогичная DCNv2. Среди них, то есть сначала сжать количество признаков до , а затем вычислить перекрестный результат. Наконец, FMB выводит матрицу функций.
LCB выглядит следующим образом
где — весовая матрица, — гиперпараметр, определяющий количество выходных сжатых вложений, — количество вложений в i-м слое.
2.3 Параметры, соответствующие шкале
Вуконг в основном настраивает следующие параметры масштаба.
- l : Количество уровней в стеке взаимодействия.
- n_F: количество вложений, созданных FMB
- n_L: количество вложений, сгенерированных LCB
- k: Оптимизировать количество вложений сжатия в FM.
- MLP: количество слоев и размер FC в MLP FMB.
В статье упоминается, что они сначала усилили l, а затем усилили другие параметры.
3. Результаты экспериментов
3.1 Офлайн-сравнение общедоступных наборов данных
Вот краткий обзор результатов сравнения. Для детальных настроек вы можете обратиться непосредственно к статье.
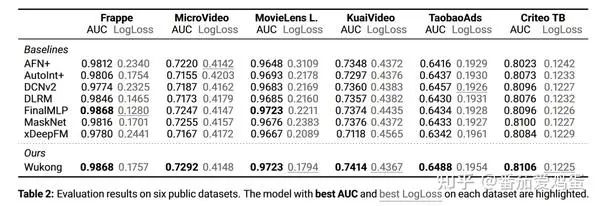
Видно, что Wukong также хорошо работает с этими наборами данных.
3.2 Эксперименты на внутреннем наборе данных Meta
Это основное содержание данной статьи. Давайте уделим пристальное внимание его настройкам подробно.
3.2.1 Набор данных и экспериментальная установка
- Сбор данных: этот сборник данных содержит в общей сложности 146B предметы, есть 720 разные характеристики. Каждая характеристика описывает элемент или атрибут пользователя. С этим набором данных связаны две задачи: (Задача1) Предсказать, проявит ли пользователь интерес к элементу (например, клик) и (Задача2) Произойдёт ли конверсия (например, лайк, внимание) на)。
- Настройки обучения:Длина всех вложений установлена равной 160, а размер не увеличивается с увеличением масштаба плотного слоя.. Используйте Adam для обучения плотного слоя и обучения внедрению. Для стола Rowwise Adagrad。Размер пакета установлен на 262 144, каждый обучающий экземпляр будет использовать 128 или 256 графических процессоров H100.。
- Введение в некоторые показатели
- GFLOP/пример: Гига операций с плавающей запятой в примере
- PF-days:PF-days Общий объем обучающих вычислений эквивалентен запуску компьютера с более чем 1 PetaFLOP/s беговая машина 1 небо.
- #Params: Размер модели измеряется количеством параметров в модели. встраивание Размер таблицы фиксирован 627B параметр.
- Relative LogLoss: относительно фиксированной базовой линии. LogLoss улучшать.Относительное улучшение LogLoss на 0,02% в этом наборе данных считается значительным.。
3.2.2 Экспериментальные результаты
Согласно приложению параметры каждой точки отбора проб Укун устанавливаются следующим образом:
График улучшения производительности строится в зависимости от объема расчета следующим образом:
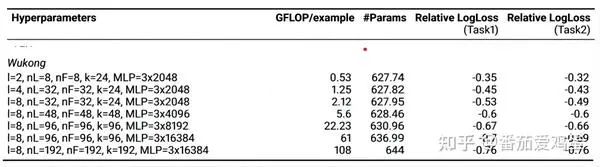
Видно, что по мере увеличения объема обучающих вычислений логарифмические потери неуклонно уменьшаются. Согласно заключению статьи, Wukong Поддерживает правило масштабирования на два порядка сложности модели, что примерно эквивалентно увеличению сложности каждый раз, когда она увеличивается в четыре раза. 0.1%。
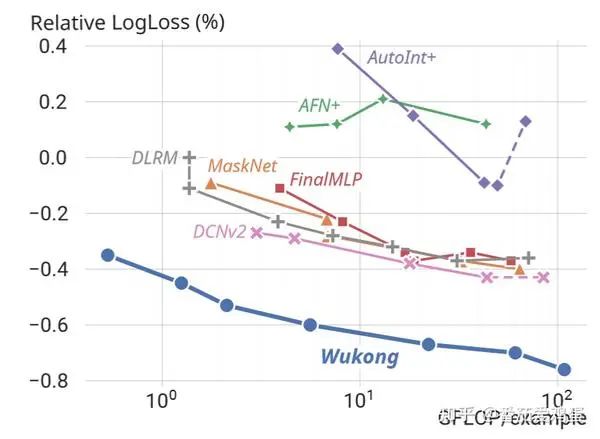
Авторы также построили аналогичные результаты на основе количества параметров модели.
Так в какие же модули эффективнее добавлять параметры и расчеты? Рисунок ниже также дает определенный ответ.
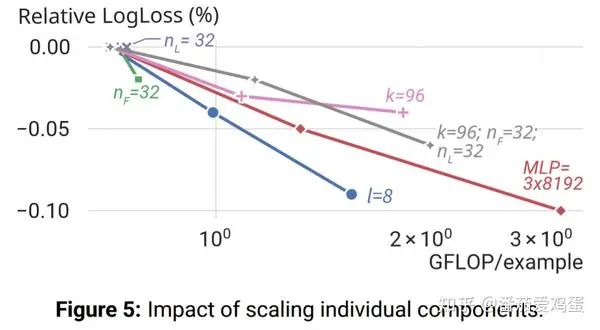
Можно заметить, что параметры n_F и l, связанные с поперечным сечением объекта, значительно улучшились. Комбинация k, n_F, n_L также дает хороший эффект. Улучшение параметров MLP также дает эффект, но увеличение n_L само по себе не дает эффекта. (Я считаю, что большинство из них, связанных с пересечением функций и, наконец, с MLP, более эффективны)
Приложение: Чепуха
Закон масштабирования все еще относительно ясен. За счет увеличения вычислительных затрат на взаимодействие функций можно добиться повышения производительности, что также очень интуитивно понятно. Немного жаль, что он не предполагает моделирования последовательностей. Конечно, рекомендуемые требования к задержке вычислений намного превышают требования LLM. Как уместить больше вычислений в единицу времени — это тоже техническая задача.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
