Исследование и практика создания хранилища данных реального времени, интегрированного с озерами и складами Сельскохозяйственного банка Китая.
введение
Благодаря цифровой трансформации требования реального времени все чаще становятся новой нормой для приложений обработки данных в финансовой отрасли. Традиционная модель предоставления данных в автономном хранилище данных «T+N» трудно удовлетворить потребности сценариев высокой своевременности, таких как «T+0», поскольку для обеспечения этого используются вычислительные среды реального времени, такие как Storm, Spark Streaming и Flink; «сквозная» модель обработки в реальном времени не может быть ускорена. Ресурсы данных в реальном времени имеют такие недостатки, как низкая возможность повторного использования данных в реальном времени и вертикальная конструкция в стиле «дымохода».
С этой целью вышеуказанные проблемы могут быть решены путем создания хранилища данных в реальном времени. Хранилище данных в реальном времени дополнительно отвечает требованиям своевременности на основе автономного хранилища данных. Оно опирается на такие технологии, как потоковая пакетная интеграция. интеграция хранилища-озера и облачные вычисления для достижения своевременности и гибкости. Преимущества: его можно использовать в качестве платформы для производства, хранения и использования данных в реальном времени в финансовой отрасли.
Чтобы решить проблему низкой своевременности данных в традиционных хранилищах данных, хранилища данных реального времени имеют несколько путей технического маршрута:
- • Один из них — Хранилище, основанное на архитектуре Lambda. данных в режиме реального времени, как нынешний мейнстрим Хранилище данных в режиме реального времени Архитектура,Он основан на существующем зрелом канале автономной обработки.,Добавить ссылку на вычисления в реальном времени,См. ODS, DWD, DWS и другие концепции иерархической организации модели.,Реализуйте сотрудничество с автономным хранилищем данных,Обычно реализуется с использованием комбинации очереди сообщений Kafka, вычислительного механизма Flink и т. д.,Затраты на строительство ниже,Но структура сложная,Затраты на эксплуатацию и техническое обслуживание высоки;
- • Один из них - Хранилище, основанный на архитектуре Каппы. данных в режиме реального времени,По сравнению с архитектурой Lambda,Удаляет ссылку на автономное производство.,Полностью зависит от каналов обработки в реальном времени,Преимущество в том, что источники данных унифицированы.,Архитектура относительно упрощена,Сэкономьте затраты на разработку, ежедневную эксплуатацию и обслуживание.,Но выполнить вычисления с обратным отслеживанием данных непросто.,Сравнительное потребление вычислительных ресурсов памяти;
- • Кроме того, существует также категория, которая использует технологию OLAP в реальном времени, где расчет агрегированного анализа выполняется механизмом OLAP, что снижает нагрузку на обработку агрегирования в части вычислений в реальном времени. Анализ имеет высокую степень свободы. и снижает нагрузку на вычислительный механизм, но накладывает большую нагрузку на пропускную способность, хранение и обработку в реальном времени. Требования к производительности приема и анализа высоки, например, Хранилище. данных в режиме реального времени обычно основан на коммерческих продуктах библиотеки данных, таких как Hologres, GaussDB и т. д.
В то же время с Худи, Айсбергом, Дельтой Lakeждатьозеро данные технологического развития, опираясь на озеро данныхпьедесталСтроительство хранилищ данных реального времени, интегрированных с озерами и складами, находится на подъеме и имеет большое значение для содействия цифровой трансформации предприятий:
- • Первая – восполнить недостатки существующей структуры.Озеро и склад интегрированы Хранилище данных в режиме реального времени Это компенсирует традиционные хранилища данных.данные Отсутствие возможностей обработки в реальном времени.,Обладать возможностями обработки данных с несколькими механизмами и разными типами.,Богатые типы пакетной обработки,Это позволяет избежать таких проблем, как неспособность традиционных хранилищ данных анализировать неструктурированные данные.
- • Во-вторых, сократить расходы бизнеса,Озеро и склад интегрированы Хранилище данных в режиме реального время предоставляет унифицированную базу данных потоковой партии,Избегайте перемещения между разными платформами,Сократите затраты на разработку и накладные расходы на вычислительное хранилище, вызванные потоком данных.,Повышайте эффективность бизнеса.
- • В-третьих, улучшение возможностей анализа и интеграции данных на уровне предприятия.Озеро и склад интегрированы Хранилище данных в режиме реального время разбило озеро Система, разделяющая хранилища данных и данных, будет Гибкость данных, разнообразие данных и богатая экосистема объединены с аналитическими возможностями хранилища данных корпоративного уровня.
Идеи построения хранилища данных в реальном времени
С момента создания платформы больших данных Сельскохозяйственного банка Китая, после многих лет непрерывного развития, она накопила множество активов моделей автономных хранилищ данных, имеет возможности хранения и обработки данных на петабайтном уровне и поддерживает сотни сценариев применения. Однако в целом текущая своевременность предоставления услуг передачи данных по-прежнему в основном составляет T+N дней. Хотя платформа потоковых вычислений в реальном времени поддерживает приложения с высокой производительностью, такие как большие экраны для депозитов в реальном времени, модель сквозной обработки потоков. трудно добиться накопления и повторного использования данных в реальном времени.
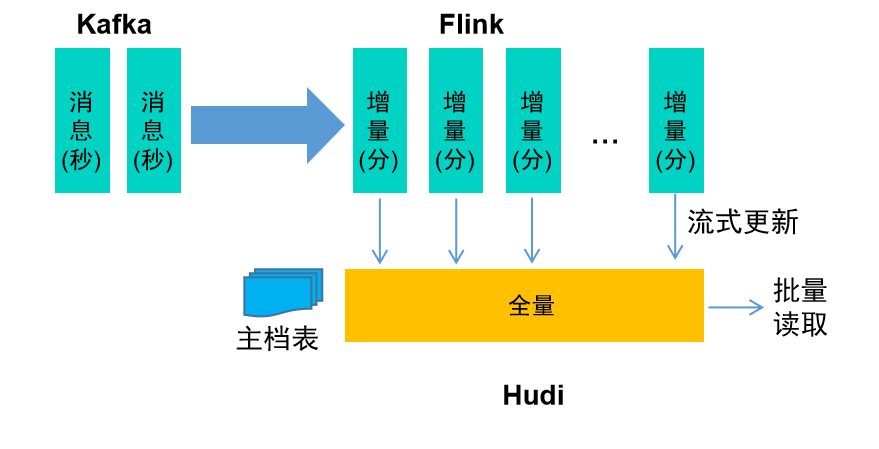
Основываясь на технических возможностях озера данных, хранилище данных в реальном времени поддерживает построение стабильного, комплексного и хорошо масштабируемого уровня базы данных в реальном времени, создает и накапливает общие активы данных в реальном времени ABC, соответствует данным требованиям различных приложений анализа в реальном времени и повышает своевременность обработки модели данных (см. рисунок ниже) в сочетании с вычислительными механизмами хранения озера данных, такими как Flink и Hudi, поддерживает потоковую передачу данных, файлов и других данных в озеро и использует Интегрированный потоково-пакетный вычислительный механизм Flink для иерархической организации активов реального времени на уровне предприятия, способствующий унификации приложений анализа в реальном времени во всем банке.

По сравнению с ранними платформами потоковых вычислений в реальном времени, она обладает характеристиками предметно-ориентированного, интегрированного и относительно стабильного хранилища данных. Она обеспечивает стабильные и непрерывные возможности унифицированной интеграции данных в реальном времени и поддерживает создание общих объектов. и персонализированные иерархические модели данных в реальном времени, чтобы удовлетворить требования различных типов приложений для режима потоковой пакетной обработки данных.
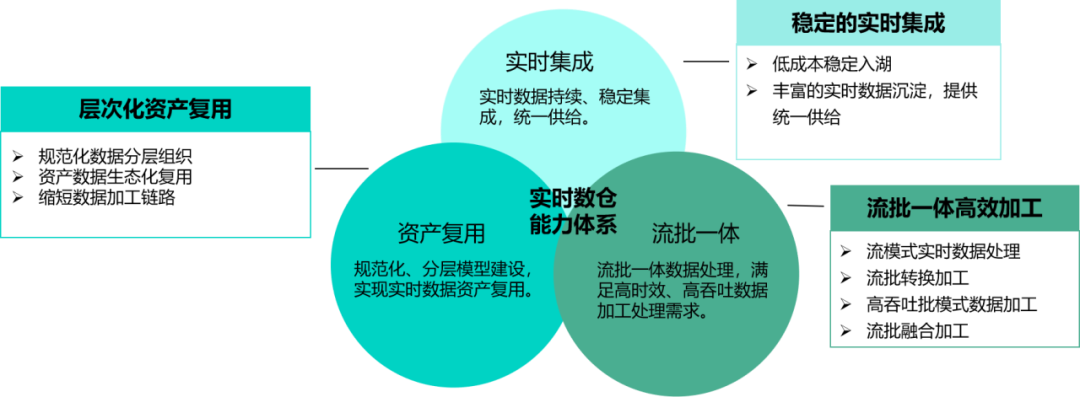
Чтобы улучшить возможность повторного использования ресурсов данных в реальном времени и поддержать различные приложения, хранилище данных в реальном времени использует концепцию многоуровневого хранения данных для организации активов данных в реальном времени. В то же время, учитывая, что повышение уровней приведет к увеличению затрат и задержек на обработку данных, чтобы сократить канал обработки, активы хранилища данных реального времени организованы в ODS, DWD, DWS, а также уровень DIM.

слой LODS
На основе Hudi для хранения исходных данных сообщения журнала Binlog преобразуются в Upsert и передаются в озеро. Данные согласуются с данными производственной исходной системы и поддерживают атомарную детализацию данных.
слой lDWD
Это соответствует тематическому разделению слоя DWD в автономном хранилище данных, главным образом для решения проблем шума, неполных данных и противоречивых форматов данных в некоторых исходных данных, а также для формирования стандартизированного и унифицированного источника данных. Уровень DWD включает анализ данных, бизнес-интеграцию, очистку грязных данных и стандартизацию моделей.
слой lDIM
Уровень DIM — это многомерные данные в хранилище данных реального времени, которые в основном делятся на две категории: многомерные данные с низкой частотой изменения и многомерные данные с высокой частотой изменения. Для многомерных данных, которые изменяются реже, таких как институциональная информация и т. д., вы можете синхронизировать их с кэшем через автономные размерные данные или запросить их через общедоступные многомерные сервисы для получения часто изменяющихся многомерных данных, таких как обменные курсы, цены и т. д.; другую информацию, вам необходимо отслеживать ее изменения и поддерживать информацию об изменениях.
слой LDWS
Уровень DWS представляет собой сводный уровень, который в основном унифицированно обрабатывает общие показатели и выполняет многомерные сводные операции на основе тем. В частности, агрегирование временных интервалов может быть реализовано с использованием богатых временных окон в Flink.
Ключевые технологии построения хранилищ данных в режиме реального времени
3.1 Данные в реальном времени, поступающие в озеро
Данные, поступающие в озеро в реальном времени, являются основой для построения модели данных интегрированного хранилища данных озера в реальном времени. В отличие от стратегии обработки данных «использовать и выбросить» в режиме потоковых вычислений, интегрированное хранилище данных озера. Хранилище данных в реальном времени использует механизм хранения озера данных Hudi для обработки потоковых данных в реальном времени. Выполняйте прием и хранение для поддержки интегрированной потоковой пакетной обработки, такой как потоковое чтение и пакетное чтение. Чтобы поддерживать семантику Upsert данных в реальном времени и обеспечивать гарантии транзакций ACID, канал входа в озеро в реальном времени потребует больших накладных расходов на обработку, чтобы обеспечить непрерывную и стабильную интеграцию крупномасштабных данных в реальном времени в систему. Lake, эта ссылка требует, чтобы типы таблиц Hudi, механизмы сжатия, настройка интервала контрольной точки Flink и т. д. предъявляли более высокие требования.
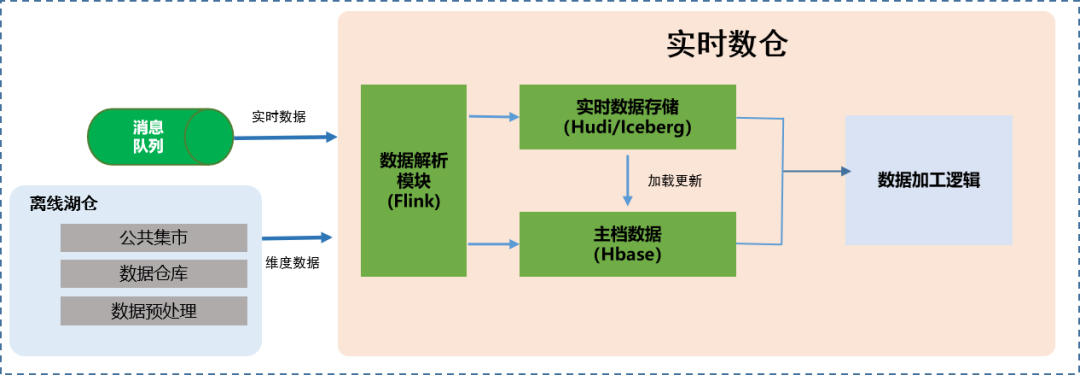
Что касается выбора типа таблицы озера в реальном времени, типы таблиц Hudi делятся на режимы MOR (объединение при чтении) и COW (копирование при записи) на основе различных характеристик чтения и записи. Метод MOR непрерывно добавляет журналы и объединяет их во время чтения, что подходит для сценариев записи с высокой пропускной способностью. Метод COW выполняет операции слияния во время записи и подходит для сценариев быстрого чтения. Чтобы обеспечить попадание в озеро высокопроизводительных транзакций и других данных Сельскохозяйственного банка Китая в режиме реального времени, метод MOR предпочтителен для больших таблиц, таких как подробные сведения о личных текущих транзакциях.
Непрерывная одновременная запись в процессе входа в озеро может легко привести к расширению и увеличению размера данных, что требует периодического сжатия. В то же время видимость данных Hudi зависит от настройки интервала CheckPoint вычислительного механизма Flink. Под двойным давлением операций записи и операций сжатия, чтобы избежать взаимных препятствий между операциями сжатия и контрольными точками, можно использовать автономный режим сжатия. используется для повышения стабильности работы.
Кроме того, в соответствии с различными объемами данных каждой таблицы хранилище данных в реальном времени будет регулировать ЦП и память задания обработки в реальном времени в соответствии с текущими потребностями задания доступа, чтобы обеспечить последующее отслеживание происхождения данных; В качестве хранилища технических метаданных используется Hive MetaStore.
3.2 Потоковая пакетная обработка модели данных
После того, как данные в реальном времени будут централизованно подключены к озеру данных посредством ввода данных в реальном времени, они будут преобразованы в формат данных, объединяющий потоковую передачу и пакетную обработку, который поддерживает чтение и обработку потоковой передачи и пакетной обработки с учетом характеристик зависимости данных. процесс построения модели данных в реальном времени, хранилище данных в реальном времени находится в данных. Существуют различные направления поддержки возможностей обработки моделей активов.
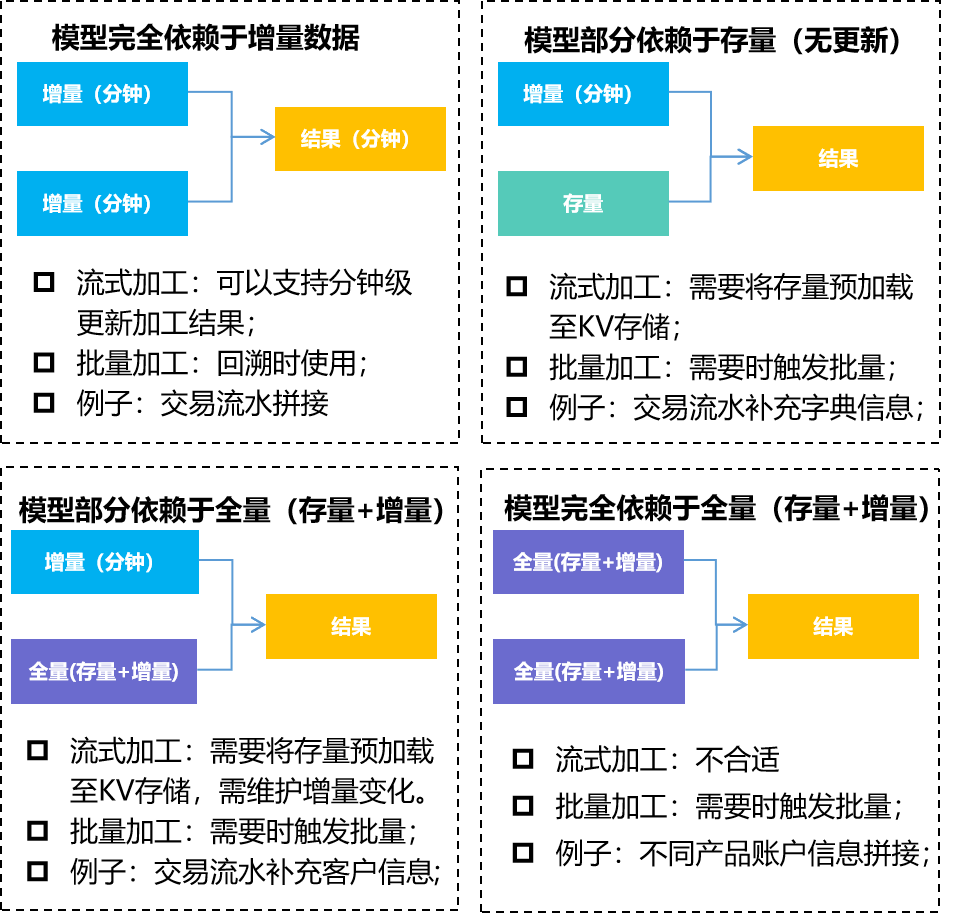
Ситуация первая:данные Модель Полная зависимость от прибавокданные:Приращениеданные Вы можете войти на склад в режиме реального времени,И завершить передачу последующих ссылок в режиме реального времени,Получайте результаты на уровне минут;
Сценарий второй:данные Модель Частично зависит от наличия(Без изменений)данные:На полную суммуданные Без измененийзависимостьданные,Инвентаризацию можно ускорить (кэшировать в Redis/Hbase и т. д.).,Достичь создания модели на минутном уровне,Но требования к управлению запасами данных очень высоки.
Сценарий третий:данные Модельчастично зависит от полной суммы(Запас+Приращение)данные:На полную суммуданные Медленно меняющиеся зависимостиданные,Инвентаризацию можно ускорить (кэшировать в Redis/Hbase и т. д.).,И сохраняйте изменения данных в режиме реального времени,Достичь создания модели на минутном уровне,Но требования к управлению полным объемом данных очень высоки.
Сценарий четвертый:данные Модельполностью зависит от общего количества(Запас+Приращение)данные:Готово за считанные минуты,Запуск выполнения пакетного планирования при необходимости,Доступно в пакетном режиме дополнительно;,В сочетании с характеристиками Сельскохозяйственного банка Китая,Хранилище данных в режиме реального времениверно Подробные данные в реальном времени、Данные в реальном времени основного Стратегия обработки файлов другая.
① Подробные данные в реальном времени Для подробных данных транзакций корреляция между данными низкая и может обрабатываться поэтапно путем потоковой записи и потокового чтения.
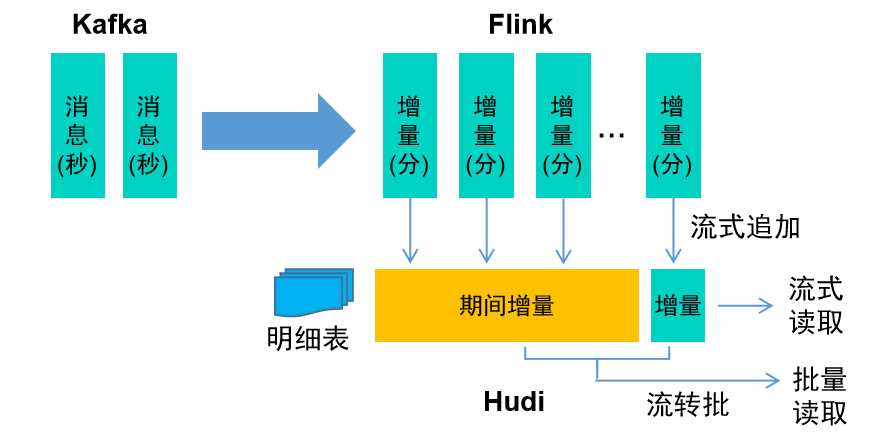
② Данные в реальном времени основного файла Для данных основного файла необходимо учитывать взаимосвязь между запасом и приращением. Данные запаса часто содержат большой объем данных и не могут быть напрямую связаны с данными. Для подготовки полного объема можно использовать режимы потокового обновления и пакетного чтения. данных своевременно для обеспечения своевременной обработки моделей.
3.3 Служба данных о размерах
Чтобы повысить своевременность обработки данных, модель данных в реальном времени заранее завершает часто используемые базовые измерения. Когда пропускная способность достигается, реализуется расширение измерений данных в реальном времени, пространство заменяется временем и выполняется базовая подготовка данных. предусмотрена группировка и обобщение данных. Например, модели с существующими данными, такими как основной класс файлов, могут храниться в механизмах хранения KV, таких как Hbase и Redis. Объединение данных реализуется на основе специальных методов поиска для ускорения канала обработки. Присоединение данных класса основного файла приведет к снижению своевременности всей ссылки. В качестве специального метода интеграции служба измерений обеспечивает режимы полного онлайн-обновления в реальном времени и пакетного добавочного обновления.

Размер загрузки
При первом подключении к сети полные и полные данные извлекаются из основной базы данных платформы больших данных, а полноразмерные данные размещаются на основе метода автономной загрузки, например, загрузки полных данных в Hbase на основе массовой загрузки. .
Обновление измерения
После того как измерение будет подключено к сети, чтобы своевременно отражать изменения в информации измерения, служба измерения также будет получать доступ к потоковым данным об изменениях измерения в режиме реального времени для обновлений.
Коррекция размеров
Чтобы уменьшить усиление отклонений в данных измерений офлайн-канала и канала реального времени, служба измерений будет периодически обновлять и исправлять данные измерений одновременно, чтобы обеспечить согласованность между последними данными измерений и данными автономных измерений, а также избегать больших отклонений в последующих калибрах вычислений. .
3.4 Обработка широкотабличной модели
Широкая таблица представляет собой таблицу модели данных уровня предприятия, сформированную путем стандартизации и организации основных данных в центре обработки данных в соответствии с методом «приближения к основным стандартам» в качестве спецификации модели больших данных нового поколения Сельскохозяйственного банка. Китай, после непрерывных итераций и развития, сформировал финансовый менеджмент, кредитную широкую таблицу в различных областях. Ядро автономной модели широкой таблицы основано на автономной обработке данных T+N, поэтому она обладает характеристиками строгой согласованности и высокой пропускной способности. С другой стороны, для обеспечения большей гибкости автономная модель широкой таблицы имеет сложные зависимости. и циркуляционные ссылки длиннее.
Для широких таблиц реального времени копирование модели широкой таблицы в режиме реального времени напрямую в модель широкой таблицы в реальном времени обходится дорого. Кроме того, взаимные ограничения каналов обработки ограничивают улучшение своевременности, и сложно максимизировать затраты. и технико-экономическое значение. В реальных бизнес-сценариях многие сценарии на самом деле не требуют, чтобы все поля были в реальном времени, а сосредоточены на получении фактических данных в реальном времени. Таким образом, хранилище данных в реальном времени основано на широкой автономной таблице T-1 путем расширения. -Поля эффективности использования времени. Дальнейшее удовлетворение сценариев с высокой эффективностью использования времени.
Исследование и практика построения хранилищ данных в реальном времени.
4.1 Исследование широких таблиц финансового управления в режиме реального времени
Чтобы изучить способы повышения своевременности широких таблиц, хранилище данных реального времени использует широкие таблицы финансового управления в качестве пилотного проекта для изучения идей по созданию широких таблиц реального времени. Разобравшись в общей цепи обработки, мы обнаружили, что текущая автономная модель широкой таблицы имеет следующие существенные особенности:
- • Во-первых, существует мало инкрементных моделей и много тотальных инкрементных моделей.Среди них общая широкая таблица сращивания транзакций Приращение Отношение обработки к увеличенной полной сумме составляет(3/25),Общая широкая таблица истории финансовых продуктов (0/6),Общая широкая таблица сращивания контрактов на финансовое управление (0/43).
- • Во-вторых, модель имеет много уровней.Ссылки на обработку обычно длинные.,Уровни обычно варьируются от 3 до 7.
- • В-третьих, зависимости между моделями сложны.Есть еще связи,Между Моделью существует большое количество операций соединения.,Индивидуальная модель имеет одновременно 11 связей между таблицами.
Таким образом, чтобы повысить своевременность вышеупомянутых сложных ссылок для подробных данных, хранилище данных в реальном времени реализует обслуживание подробных данных на основе режима Upsert, разделяет потоковые записи на минутном уровне по времени, обеспечивает потоковую передачу инкрементальных данных, и поддерживает потоковую запись на уровне минут.
Для данных основного типа файла, поскольку они содержат исторические данные, хранилище данных в реальном времени использует режим массовой вставки для внедрения данных о запасах в озеро и использует Hudi для подключения полных данных к инкрементным данным для решения проблемы загрузка исторических данных в первый раз и плавное подключение дополнительных данных. В то же время последние полные результаты моментальных снимков предоставляются на основе обновления состояния данных на уровне минут потоковой записи и режима пакетного чтения.

Благодаря обработке в реальном времени подробных и основных базовых данных данные минутного уровня могут быть предоставлены для моделей широких таблиц, что улучшает своевременность вывода широких таблиц и поддерживает своевременность предоставления данных минутного уровня и общего T + 0 для ветвей ключевых связей.
4.2 Практика сценариев маркировки в реальном времени
В ответ на потребности интернет-финансовых и других компаний в создании меток в реальном времени хранилище данных в реальном времени создается с помощью подробных моделей личных текущих транзакций и новых зарегистрированных клиентов мобильного банкинга на основе повторного использования одних и тех же общих реальных данных. данные модели времени, они разделены на три категории: межбанковские транзакции, личные средства и выплата заработной платы агентства. Данные темы поддерживают создание различных типов тегов реального времени в центре тегов. Этот режим управляет управлением по темам и выполняет унифицированную обработку, такую как очистка, фильтрация, расширение измерений и т. д., предоставляя непосредственно доступные данные последующим пользователям, избегая повторной обработки данных, а также реализуя хранение данных в реальном времени и обратную трассировку, что может удовлетворить потребности последующей обработки в реальном времени. Теги и другие многосценарные конструкции.

В практике создания активов общей модели деталей личных текущих транзакций, чтобы обеспечить высокую пропускную способность одной таблицы со средним ежедневным количеством сотен миллионов в озере, хранилище данных в реальном времени оптимизирует конфигурацию из таблицы Hudi. типы, разделы данных, сжатие Hudi и другие меры для достижения высокой пропускной способности потоковой передачи в реальном времени. Стабильный вход в озеро в сценариях данных:
1) Что касается выбора таблицы Худи,Обнаружено в ходе долгоцикловых испытаний на усталость.,В этом сценарии операции, основанные на типе COW, будут испытывать сильное противодавление и постепенно усиливающиеся задержки.,Чтобы избежать задержек,Хранилище данных в режиме реального время основано на модели таблицы MOR, которая отвечает требованиям высокой пропускной способности и быстрого ввода данных в реальном времени в озеро;
2) Что касается разделения данных,Хранилище данных в режиме реального время выполняет разбиение данных на детали данных Модель. Принимая во внимание характеристики данных данных с небольшим количеством обновлений и т. д., чтобы уменьшить давление индекса Худи и еще больше сократить время хранения индекса;
3) По степени сжатия,Хранилище данных в режиме реального времени Принимая во внимание онлайн-сжатиеверно Нестабильность, вызванная миссией в озеро,Используется автономное сжатие.,Контролируйте выполнение планов сжатия с помощью скриптов.,Убедитесь, что нет проблем с отставанием.
На основе накопленных общих ресурсов модели хранилище данных в реальном времени последовательно поддерживает создание нескольких сценариев, таких как подсказки в реальном времени для больших динамических учетных записей, теги в реальном времени для новых клиентов в Palm Banking и теги в реальном времени. для расчета заработной платы агентства.
прогноз на будущее
Интегрированное хранилище данных реального времени с озером и хранилищем объединяет гибкость, разнообразие данных и богатую экологию озера данных с возможностями анализа данных на уровне предприятия, что имеет большое значение для построения хранилища данных в реальном времени. модели данных. В будущем, с созданием озера данных Сельскохозяйственного банка Китая, хранилище данных в реальном времени будет интегрировать построение базовой базы озера данных для создания стабильного, комплексного и хорошо масштабируемого уровня базы данных в реальном времени. и ускорять общие активы данных в реальном времени Сельскохозяйственного банка Китая и удовлетворять потребности различных приложений анализа в реальном времени. Хранилище данных реального времени основано на интегрированной потоково-пакетной интеграции данных, которая повышает своевременность обработки данных, способствует унификации архитектуры аналитических приложений банка в реальном времени и имеет большое значение для поддержки построения сценариев в реальном времени.
5.1 Непрерывное и стабильное предоставление данных в режиме реального времени
Хранилище данных в реальном времени основано на возможностях интеграции в реальном времени на базе платформы Lake, которые могут интегрировать обширные потоковые данные в реальном времени и в то же время снизить затраты на интеграцию данных в реальном времени для различных приложений реального времени. время, опираясь на функции потокового и пакетного хранения озера данных, он может реализовать некоторые новые технологии, такие как функции путешествий во времени, для удовлетворения требований надежности и других сценариев, таких как повторная обработка данных в реальном времени в определенный момент времени. , и т. д.
5.2 Богатые ресурсы модели данных в реальном времени
Хранилище данных в реальном времени координирует и предоставляет общие активы модели данных в реальном времени, избегая сквозной повторной обработки каждого приложения реального времени. Например, на основе модели детальных слоев операции могут получать сводные результаты на уровне агентства, маркетинг может суммировать результаты на уровне продукта и т. д. без необходимости детальной обработки, реализуя вывод данных в реальном времени за один раз.
5.3 Создание возможностей открытого мультиарендатора
Арендаторы хранилища озера данных полагаются на унифицированную базу данных и вычислительную базу озера данных, чтобы осуществить переход с низкими затратами и реализовать распределение ресурсов, авторизацию данных в реальном времени и обнаружение активов. Они используют хранилище данных в реальном времени для непрерывного предоставления реальных ресурсов. -временные данные и общие модели, а также объединить их с универсальной стандартизацией DataOps озера данных. Технология устраняет необходимость экспорта данных в озеро, повышает своевременность обработки данных, отвечает потребностям быстрого внедрения реальных данных. время сценариев приложений и максимизирует ценность озера данных. На следующем этапе хранилище данных в реальном времени будет глубоко интегрировано в комплексное построение озер и хранилищ. С помощью современных стеков данных будут реализованы унифицированная линия передачи данных, управление и контроль безопасности, совместное использование услуг и т. д. помочь развитию экосистемы приложений данных в реальном времени на уровне предприятия Сельскохозяйственного банка Китая.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
