Используйте XXL-JOB для гибкого управления обработкой сегментирования.
В этой статье описан метод использования XXL-JOB для обработки сегментированных задач и добавлен гибкий контроль над количеством исполнительных узлов.
сцена
Теперь в таблице данных имеется большой объем данных, которые необходимо обработать серверному приложению. Требования:
- Возможность параллельной обработки;
- Умеет гибко контролировать количество параллельных задач.
- Давление распределяется по разным узлам равномерно;
Идеи
Поскольку данные в одной и той же таблице данных должны обрабатываться параллельно, естественно подумать о сегментировании для запроса данных. Вы можете использовать метод получения модуля идентификатора для сегментирования данных, чтобы избежать их повторной обработки. данные.
Согласно требованиям пунктов 1 и 2, я изначально хотел добиться этого за счет динамической настройки пула потоков, но учитывая пункт 3, количество узлов сервера может измениться, и узлы не имеют никакой осведомленности или связи друг с другом, поэтому их можно реализовать в приложении. Механизм планирования может быть сложным.
Если бы было неплохо иметь готовый планировщик, независимый от этих серверных узлов. Вслед за этим я подумал о подключенной платформе распределенного планирования задач. XXL-JOB во время чтения Официальная документация Позже выяснилось, что «фрагментная трансляция» & «Динамическое шардинг» очень хорошо подходит для этой ситуации.
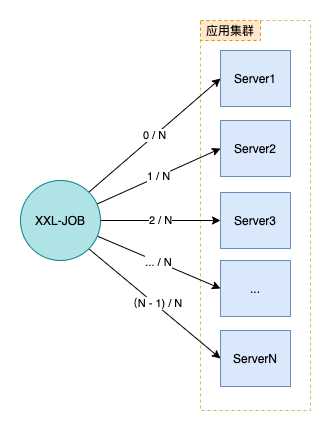
план
- использовать XXL-JOB Стратегия маршрутизации «фрагментированная трансляция» используется для планирования запланированных задачи;
- Передайте количество узлов, выполняющих задачу, через параметры задачи;
- запланированные В логике задачи, согласно полученным параметрам фрагментации, Количество узлов, выполняющих задачи,Определить, нужно ли выполнять текущий узел,Данные и обработка сегментированных запросов:
- если порядковый номер фрагмента > (Количество узлов, выполняющих задачи - 1),Тогда текущий узел не выполняет задачу,Возврат напрямую;
- В противном случае возьмите порядковый номер фрагмента и Количество узлов, выполняющих задачи В качестве параметра сегментирования запросите данные и обработайте их.
Таким образом, мы можем гибко запланировать 1, N узлов для параллельного выполнения задач по обработке данных.
Пример основного кода
Пример JobHandler:
@XxlJob("demoJobHandler")
public void execute() {
String param = XxlJobHelper.getJobParam();
if (StringUtils.isBlank(param)) {
XxlJobHelper.log("Параметры задачи пусты");
XxlJobHelper.handleFail();
return;
}
// Количество узлов, выполняющих задачи
int executeNodeNum = Integer.valueOf(param);
// порядковый номер фрагмента
int shardIndex = XxlJobHelper.getShardIndex();
// Общее количество осколков
int shardTotal = XxlJobHelper.getShardTotal();
if (executeNodeNum <= 0 || executeNodeNum > shardTotal) {
XxlJobHelper.log("Количество узлов, выполняющих диапазон значений задачи [1, общее количество узлов]");
XxlJobHelper.handleFail();
return;
}
if (shardIndex > (executeNodeNum - 1)) {
XxlJobHelper.log("Текущая фрагментация {} Не надо исполнять", shardIndex);
XxlJobHelper.handleSuccess();
return;
}
shardTotal = executeNodeNum;
// Данные и обработка сегментированных запросов
process(shardIndex, shardTotal);
XxlJobHelper.handleSuccess();
}Пример сегментированных данных запроса:
select field1, field2
from table_name
where ...
and mod(id, #{shardTotal}) = #{shardIndex}
order by id limit #{rows};дальнейшие мысли
- если нужно большее количество одновременно,Необходимо, чтобы параллелизм задач превышал количество узлов приложения.,Как бороться с? Два вида идей:
- Одновременно передать число через параметр задачи. Когда один узел обрабатывает задачу, он разделяет запрошенные данные в соответствии с этим числом и передает их в пул. параллельная обработка потоков;
- Конфигурация M индивидуальныйзапланированные задача, указав то же самое JobHandler, пронумеруй их 0、1、2…M,и будетзапланированные задачисерийный номери M Эти два числа передаются параметрами задачи, запланированные В логике задачи сначала на основе параметров фрагментации планируются номер задачи, M, пересчитать новые параметры шардинга, например _порядковый номер фрагмента = (порядковый номер фрагмента \* M) + запланированные задачисерийный номер_,_Общее количество осколков = Общее количество осколков \* M_, затем запросите данные и обработайте их. если можно часто корректировать логику выполнения задач, в том числе возможно добавлять новые параметры задач и т.п. без перезапуска сервера Как решить?
Можно рассмотреть возможность использования XXL-JOB Задачи «GLUE Mode» можно редактировать и обновлять онлайн, запланированные. логика выполнения задачи.ссылка
Информация о документе
- Автор этой статьи:Zhuang Ma
- Ссылка на эту статью:https://cloud.tencent.com/developer/article/2349709
- Заявление об авторских правах:Бесплатное воспроизведение-Некоммерческий-непроизводный-сохранить подпись(Лицензия Creative Commons 3.0)



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
