Используйте TensorRT для ускорения нейронных сетей (прочитайте модель ONNX и запустите ее)
Предисловие
Эта статья продолжает предыдущую статью и объясняет, как конкретно использовать TensorRT.
Я уже написал статью, чтобы представить, что такоеTensorRT:Используйте Тензор РТверноглубокое обучение Ускорение,В этой статье, вероятно, в основном обсуждалось, что такое TensorRT и как его использовать.
В этой статье мы в основном рассказываем, как использовать его для ускорения в наших реальных задачах.
Результаты моих экспериментов показывают, что,С точностью FP32,использоватьTensorRT和不использоватьTensorRTсуществоватьGPUПередаточное отношение работает на3:1,То есть по предпосылке моей Модели,TensorRTсуществоватьGPUсделай мой Модель Скорость увеличилась3 раз (разные модели, разные видеокарты, разные архитектуры имеют разную скорость улучшения).
Возможности, которыми обладает TensorRT
В настоящее время последняя версия TensorRT — 5.0. TensorRT уже давно разработана. Модели, поддерживающие преобразование, также включают caffe, tensorflow и ONNX. Мы должны знать, что TensorRT имеет собственную структуру моделей. Сначала мы должны обучить другие модели. Фреймворк можно использовать путем преобразования кода в код TensorRT. TensorRT имеет высочайшую поддержку моделей Caffe, а также поддерживает преобразование моделей Caffe в точность int8.
Трансформация модели ONNX — результат последних шести месяцев.,В настоящее время поддерживает большинство операций (проверено,我们平常использоватьиз90%из Модель都可以использоватьONNX-TensorRTконвертировать)。Единственное сожаление заключается в том, что модель ONNX на данный момент не поддерживает преобразование типов int8.
Приведенное выше предложение является спорным.,感谢评论区изcuijyerправильный,Акцент здесь,Это предложение было написано 19 апреля 2020 года:
Более года назад TRT5.0 не поддерживал количественную оценку onnx, но конкретная причина заключалась в том, что пакет tar TRT5.0 в то время не имел кодов, связанных с квантованием, и файлов калибровки (официальная ошибка), поэтому модель ONNX (fp32) не удалось сначала импортировать. Затем выполните количественный анализ (в TR). T-сторона), а модели в caffe и других форматах поддерживают int8 (уже квантованные перед импортом на сторону TRT). Вы можете напрямую импортировать модель int8 и запустить ее напрямую. Однако ONNX в то время не поддерживал тип int8 и мог это сделать. не импортировать напрямую квантованную модель int8.
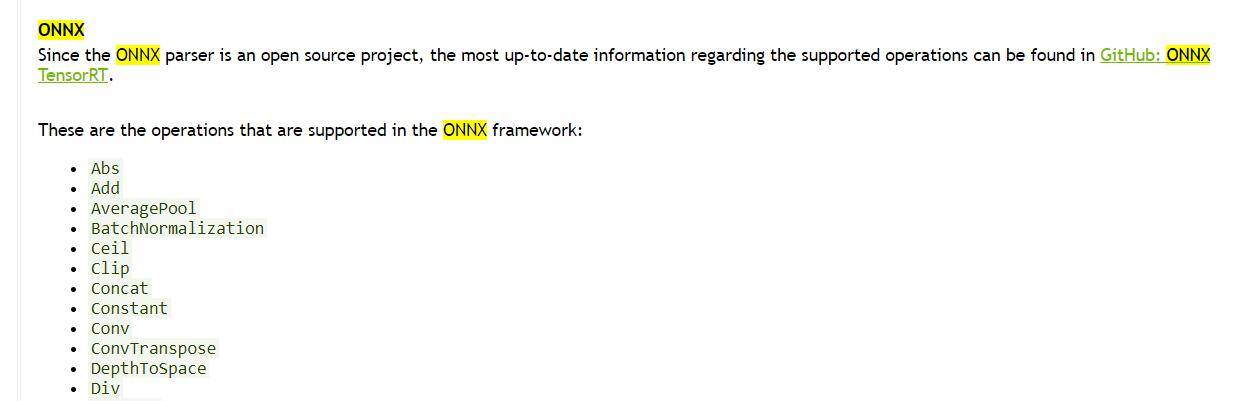
Зачем нужно преобразование? Потому что TensorRT — это просто библиотека, которая может работать независимо от графического процессора и не может выполнять полный процесс обучения. Поэтому мы обычно обучаемся с помощью других фреймворков нейронных сетей (Pytorch, TensorFlow), а затем экспортируем модель и затем используем TensorRT. Инструмент преобразования преобразует его в формат TensorRT, а затем запускает.
Преимущества TensorRT были упомянуты в предыдущей статье.,Я не буду здесь вдаваться в подробности.。Если вы столкнулись с чем-то оTensorRTПожалуйста, ознакомьтесь с предыдущей статьей для установки и основных понятий.:Используйте Тензор РТверноглубокое обучение Ускорение。
В этой статье мы поговорим о внутренней работе TensorRT и о том, как мы его используем.
Используйте Тензор РТ
После установки TensorRT (процесс установки см. в предыдущей статье), если мы хотим использовать TensorRT, нам сначала нужна обученная модель. Здесь я использую ONNX, потому что я часто использую Pytorch. для экспорта модели ONNX.
device = torch.device('cuda:0')
body = create_body(mobilenetv2(pretrained=False), -1)
nf = num_features_model(body) * 2 # Here we get the output channel from last layer
head = create_head(nf, 3, None, ps=0.5, bn_final=None)
model = nn.Sequential(body, head)
state = torch.load('new-mobilenetv2-128_S.pth', map_location=device)
model.load_state_dict(state['model'], strict=True)
example = torch.rand(1, 3, 128, 128).cuda()
model.to(device)
# ExportonnxМодель
torch_out = torch.onnx.export(model,
example,
"new-mobilenetv2-128_S.onnx",
verbose=True,
export_params=True
)В приведенном выше коде показан мой процесс экспорта с использованием улучшенной модели mobilenetv2, затем считывание весов версии .pth и, наконец, экспорт onnx. Этот шаг подробно описан официальным лицом. официальный учебник. Проверьте это.
так,я экспортировал этоONNXВерсияиз Модель:new-mobilenetv2-128_S.onnx
这里建议использоватьnetron来可视化我们из Модель:
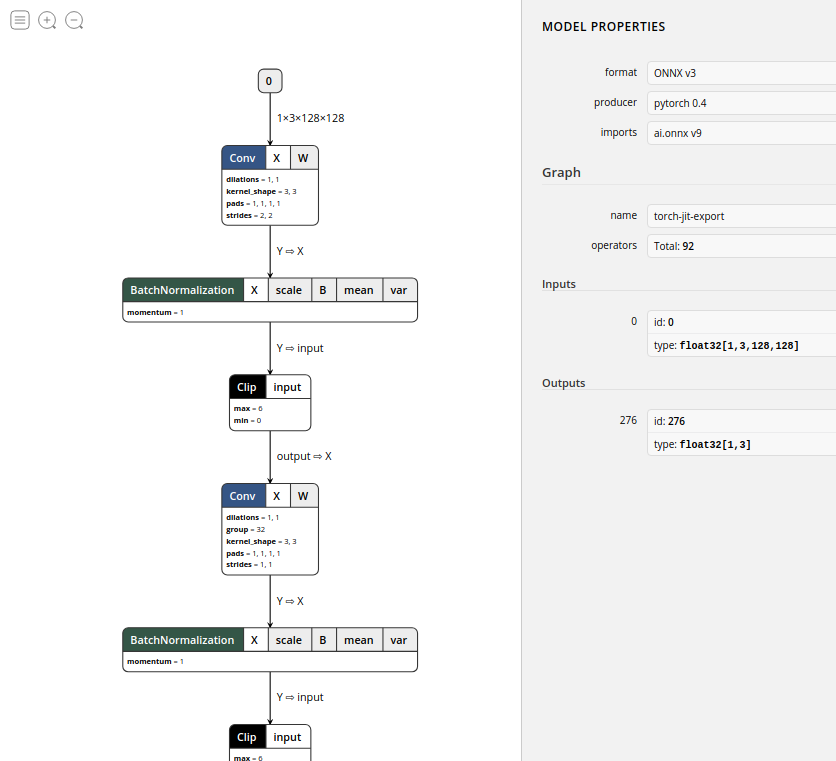
Как показано выше, это визуализация модели, которую я только что экспортировал. Мы видим, что имена операций на диаграмме модели немного отличаются от тех, которые мы обычно используем. Например, Clip представляет собой Relu, который мы обычно используем. Из вводного столбца справа вы можете видеть, что версия ONNX — v3, версия op — v9, а общее количество операций — 92. Следует отметить, что эти версии тесно связаны с поддерживаемыми операциями.
Подготовьте видеокарту
Выше мы экспортировали нужную нам модель ONNX.,Теперь мы собираемся начать использовать TensorRT.,Но нужно обратить внимание,TensorRT можно использовать только на стороне графического процессора.,Его нельзя запустить на чистом процессоре,Нам нужна видеокарта, поддерживающая сопутствующие операции. Вот я 1080TI,1080TI поддерживает точные операции fp32 и int8.,Последняя серия RTX2080TI поддерживает fp16.,关于видеокартавычислительная мощность和支持из运算可以看:Поскольку выпущена новая видеокарта, давайте поговорим об архитектуре видеокарты и связанных с ней технологиях, связанных с глубоким обучением.。
Видеокарта готова, также должны быть установлены соответствующие драйверы. Конкретные действия можно найти в статье, упомянутой в начале.
Программа TensorRT работает
Сначала мы модифицируем официальный образец (sampleOnnxMNIST). Общие шаги — использовать инструмент преобразования ONNX-TensorRT для преобразования модели ONNX, а затем использовать TensorRT для построения модели и ее запуска.
Опуская другие части кода (если вы хотите увидеть полный код, вы можете непосредственно проверить официальный пример), здесь показана только часть измененной основной функции:
IHostMemory* trtModelStream{nullptr};
// Прочтите здесь только что экспортированную модель.
onnxToTRTModel("new-mobilenetv2-128_S.onnx", 1, trtModelStream);
assert(trtModelStream != nullptr);
// UseOpencv устанавливает входную информацию и представляет заголовочный файл Opencv.
cv::Mat src_host(cv::Size(128,128),CV_32FC3);
// deserialize the engine
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream->data(), trtModelStream->size(), nullptr);
assert(engine != nullptr);
trtModelStream->destroy();
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
float prob[OUTPUT_SIZE];
// Преобразование формата входных данных изображения от 0-255 до 0-1.
for (int i = 0; i < INPUT_H * INPUT_W * 3; ++i)
data[i] = float(src_host.data[i] / 255.0);
// Здесь я проверил время
auto startTime = std::chrono::high_resolution_clock::now();
for(int i = 0 ; i < 10000 ; i++)
doInference(*context, data, prob, 1);
auto endTime = std::chrono::high_resolution_clock::now();
float totalTime = std::chrono::duration<float, std::milli>(endTime - startTime).count();
std::cout << "Time used one image (measured by chrono):" << totalTime/10000 << " ms" << std::endl;
// destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();Приведенный выше код предназначен для проверки скорости использования Тензор РТ под управлением ONNXModel.
Следует отметить, что при тестировании работы графического процессора нам необходимо использовать следующую функцию для синхронизации графического процессора и процессора, чтобы мы могли точно измерить время работы графического процессора. Конечно, использовалось следующее утверждение. в процедуре TensorRT Синхронные операции.
cudaStreamSynchronize(): этот метод принимает поток ID, он будет блокировать выполнение процессора до тех пор, пока соответствующий поток не будет завершен на стороне графического процессора. Все задачи CUDA ID, а также задачи CUDA в других потоках могут быть выполнены или не выполнены.
Далее начинаем компилировать,Зависит от于官方提供из示例程序серединаиспользоватьиз是makefileдокумент,Это не способствует нашим последующим модификациям.,所以为了方便我们根据官方提供изmakefileдокумент编写成了CmakeListВерсия,Чтобы облегчить последующую модификацию:
cmake_minimum_required(VERSION 3.12)
project(tensorrt)
#set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11") # -std=gnu++11
set(CUDA_HOST_COMPILER ${CMAKE_CXX_COMPILER})
# Найти CUDA
find_package(CUDA)
# Измените вычислительную мощность нашей видеокарты здесь. Вот я sm_61
set(
CUDA_NVCC_FLAGS
${CUDA_NVCC_FLAGS};
-O3
-gencode arch=compute_61,code=sm_61
)
set(PROJECT_OUTPUT_DIR ${PROJECT_BINARY_DIR}/${CMAKE_SYSTEM_PROCESSOR})
set(PROJECT_INCLUDE_DIR ${PROJECT_OUTPUT_DIR}/include)
file(MAKE_DIRECTORY ${PROJECT_INCLUDE_DIR})
file(MAKE_DIRECTORY ${PROJECT_OUTPUT_DIR}/bin)
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${PROJECT_OUTPUT_DIR}/bin) # .exe .dll
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${PROJECT_OUTPUT_DIR}/lib) # .dll .so
set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${PROJECT_OUTPUT_DIR}/lib) # .lib .a
include_directories(${PROJECT_INCLUDE_DIR})
include_directories(${PROJECT_SOURCE_DIR}/include)
file(GLOB Sources *.cpp)
file(GLOB Includes include/*.h)
foreach(include ${Includes})
message("-- Copying ${include}")
configure_file(${include} ${PROJECT_INCLUDE_DIR} COPYONLY)
endforeach()
find_package(Protobuf)
if(PROTOBUF_FOUND)
message(STATUS " version: ${Protobuf_VERSION}")
message(STATUS " libraries: ${PROTOBUF_LIBRARIES}")
message(STATUS " include path: ${PROTOBUF_INCLUDE_DIR}")
else()
message(WARNING "Protobuf not found, onnx model convert tool won't be built")
endif()
set(TENSORRT_ROOT /home/prototype/Downloads/TensorRT-5.0.2.6)
find_path(TENSORRT_INCLUDE_DIR NvInfer.h
HINTS ${TENSORRT_ROOT} ${CUDA_TOOLKIT_ROOT_DIR}
PATH_SUFFIXES include)
MESSAGE(STATUS "Found TensorRT headers at ${TENSORRT_INCLUDE_DIR}")
find_library(TENSORRT_LIBRARY_INFER nvinfer
HINTS ${TENSORRT_ROOT} ${TENSORRT_BUILD} ${CUDA_TOOLKIT_ROOT_DIR}
PATH_SUFFIXES lib lib64 lib/x64)
find_library(TENSORRT_LIBRARY_INFER_PLUGIN nvinfer_plugin
HINTS ${TENSORRT_ROOT} ${TENSORRT_BUILD} ${CUDA_TOOLKIT_ROOT_DIR}
PATH_SUFFIXES lib lib64 lib/x64)
set(TENSORRT_LIBRARY ${TENSORRT_LIBRARY_INFER} ${TENSORRT_LIBRARY_INFER_PLUGIN})
MESSAGE(STATUS "Find TensorRT libs at ${TENSORRT_LIBRARY}")
find_package_handle_standard_args(
TENSORRT DEFAULT_MSG TENSORRT_INCLUDE_DIR TENSORRT_LIBRARY)
if(NOT TENSORRT_FOUND)
message(ERROR
"Cannot find TensorRT library.")
endif()
LINK_LIBRARIES("/home/prototype/Downloads/TensorRT-5.0.2.6/lib/libnvonnxparser.so")
find_package(OpenCV REQUIRED)
cuda_add_executable(tensorrt benchmark.cpp)
target_include_directories(tensorrt PUBLIC ${CUDA_INCLUDE_DIRS} ${TENSORRT_INCLUDE_DIR})
target_link_libraries(tensorrt ${CUDA_LIBRARIES} ${TENSORRT_LIBRARY} ${CUDA_CUBLAS_LIBRARIES} ${CUDA_cudart_static_LIBRARY} ${OpenCV_LIBS})Основные моменты, на которые следует обратить внимание в файле cmake, — это поиск динамически подключаемых библиотек cuda и TensorRT. Пока эти необходимые динамически подключаемые библиотеки найдены с помощью cmake, компиляция может пройти успешно. Кроме того, поскольку я использовал Opencv. также добавлен скомпилированный Opencv.
компилироватьбежать за,Обнаружить Используйте Тензор РТсуществоватьFP32Работает с той же точностью Модель比существоватьPytorchизC++Конечный пробег почти быстрее3 раза!效果还是很显著из,Почему именно так быстро?,Условно его можно разделить на следующие пункты:
- ONNX-TensorRT преобразует модель ONNX в модель, которую может прочитать TensorRT;
- TensorRT изменил Модель, преобразованную на предыдущем шаге.,Интегрируйте некоторые операционные уровни и этапы операций.,Сформирована новая объединенная модель.
- Дальнейшая сериализация объединенной модели в графический процессор.,и оптимизированные операции для конкретных графических процессоров,Сделайте вывод болеебыстрый。
Вышеупомянутые шаги можно четко увидеть в официальном руководстве по разработке:
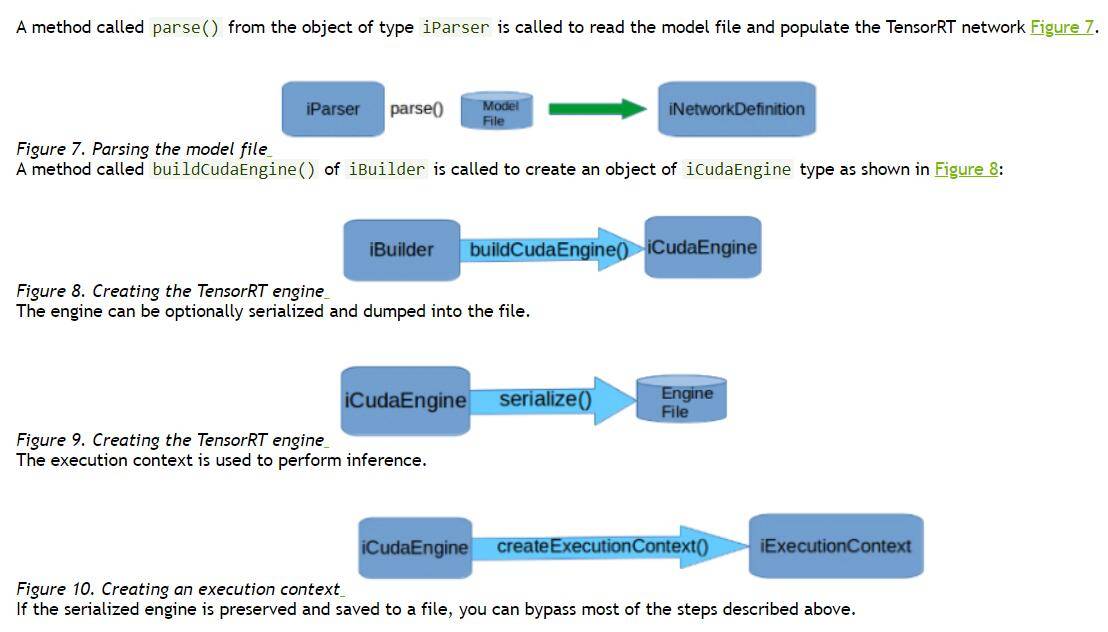
TensorRT имеет закрытый исходный код.,Официальный представитель сообщает только, как его использовать, но не предоставляет нам исходный код.,Основными моментами вышеупомянутого улучшения скорости являются интеграция моделей и упрощение работы (поскольку мой 1080Ti не поддерживает FP16, я использую FP32 по умолчанию.,И ONNX-TensorRT в настоящее время не поддерживает преобразование int8),Для поддерживаемых моделей Fusion вы можете просмотреть официальный список.,最常用из即conv+bn+relu也就是下图середина红箭头指向из地方:

На самом деле эффект ускорения int8 тоже велик. Есть официальный пример INT8 в MNIST. В простой задаче MNIST ускорение может достигать 20% (чем крупнее задача, тем очевиднее скорость). -вверх). В других задачах так и должно быть. Это тоже дает хороший эффект улучшения.
Известные ошибки TensorRT
Хотя TensorRT был обновлен, в нем все еще есть много ошибок. Проблемы, представленные на рисунке ниже, встречались и в TensorRT-5.0:
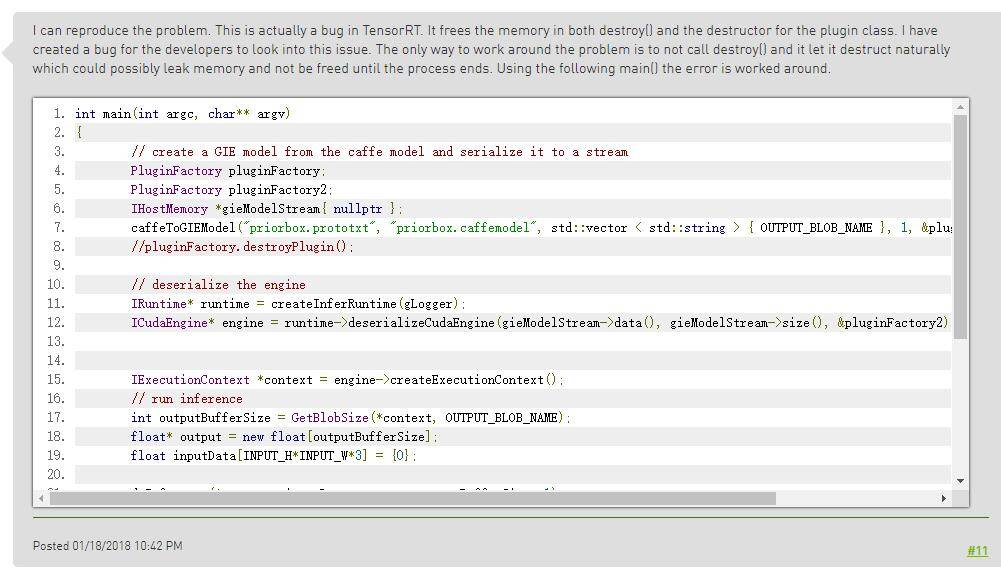
也就是我们существоватьиспользоватьTensorRTсуществовать进行Модель转化из过程середина会出现:Signal: SIGSEGV (Segmentation fault)。
Конкретный код ошибки встречается в следующих операторах. Причина ошибки, скорее всего, заключается в том, что освобожденная память освобождается снова.
engine->destroy();
network->destroy();
builder->destroy();Введение в знания TensorRT
Никакой другой информации о TensorRT, кроме официальной, нет. К счастью, комментарии в базе кода TensorRT очень подробные. Мы можем понять библиотеку TensorRT максимально подробно через код заголовочного файла TensorRT.
Типы данных в TensorRT
В настоящее время TensorRT поддерживает следующие четыре типа данных. Помимо kFLOAT (тип с плавающей запятой одинарной точности), который мы обычно используем, TensorRT также поддерживает тип с плавающей запятой половинной точности, квантованный тип INT8 и тип INT32:
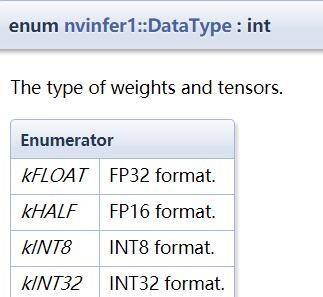
Эти четыре типа используются в информации о весе и тензорной информации. Например, когда мы используем библиотеку TensorRT для проектирования сетевого уровня, нам необходимо указать:
// ITensor — класс, определяющий тензоры в TensorRT.
// Ниже мы напрямую используем метод в TensorRT для определения входных данных сети. где dt — параметр Зависит от DataType dt пройти внутрь
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W});Определите нейронные сети с помощью INetworkDefinition
существоватьsampleMNISTAPIВ этой официальной рутине,
// Creat the engine using only the API and not any parser.
ICudaEngine* createMNISTEngine(unsigned int maxBatchSize, IBuilder* builder, DataType dt)
{
INetworkDefinition* network = builder->createNetwork();
// Create input tensor of shape { 1, 1, 28, 28 } with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W});
assert(data);
// Create scale layer with default power/shift and specified scale parameter.
const float scaleParam = 0.0125f;
const Weights power{DataType::kFLOAT, nullptr, 0};
const Weights shift{DataType::kFLOAT, nullptr, 0};
const Weights scale{DataType::kFLOAT, &scaleParam, 1};
IScaleLayer* scale_1 = network->addScale(*data, ScaleMode::kUNIFORM, shift, scale, power);
assert(scale_1);
// Add convolution layer with 20 outputs and a 5x5 filter.
std::map<std::string, Weights> weightMap = loadWeights(locateFile("mnistapi.wts"));
IConvolutionLayer* conv1 = network->addConvolution(*scale_1->getOutput(0), 20, DimsHW{5, 5}, weightMap["conv1filter"], weightMap["conv1bias"]);
assert(conv1);
conv1->setStride(DimsHW{1, 1});
// Add max pooling layer with stride of 2x2 and kernel size of 2x2.
IPoolingLayer* pool1 = network->addPooling(*conv1->getOutput(0), PoolingType::kMAX, DimsHW{2, 2});
assert(pool1);
pool1->setStride(DimsHW{2, 2});
// Add second convolution layer with 50 outputs and a 5x5 filter.
IConvolutionLayer* conv2 = network->addConvolution(*pool1->getOutput(0), 50, DimsHW{5, 5}, weightMap["conv2filter"], weightMap["conv2bias"]);
assert(conv2);
conv2->setStride(DimsHW{1, 1});
// Add second max pooling layer with stride of 2x2 and kernel size of 2x3>
IPoolingLayer* pool2 = network->addPooling(*conv2->getOutput(0), PoolingType::kMAX, DimsHW{2, 2});
assert(pool2);
pool2->setStride(DimsHW{2, 2});
// Add fully connected layer with 500 outputs.
IFullyConnectedLayer* ip1 = network->addFullyConnected(*pool2->getOutput(0), 500, weightMap["ip1filter"], weightMap["ip1bias"]);
assert(ip1);
// Add activation layer using the ReLU algorithm.
IActivationLayer* relu1 = network->addActivation(*ip1->getOutput(0), ActivationType::kRELU);
assert(relu1);
// Add second fully connected layer with 20 outputs.
IFullyConnectedLayer* ip2 = network->addFullyConnected(*relu1->getOutput(0), OUTPUT_SIZE, weightMap["ip2filter"], weightMap["ip2bias"]);
assert(ip2);
// Add softmax layer to determine the probability.
ISoftMaxLayer* prob = network->addSoftMax(*ip2->getOutput(0));
assert(prob);
prob->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*prob->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
builder->setMaxWorkspaceSize(1 << 20);
samplesCommon::enableDLA(builder, gUseDLACore);
ICudaEngine* engine = builder->buildCudaEngine(*network);
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*) (mem.second.values));
}
return engine;
}
Непосредственное чтение сети, изначально поддерживаемой TensorRT.

Установите OpenCV с поддержкой CUDA.
Большая часть OpenCV, которую мы обычно устанавливаем, работает только в среде ЦП.,Прямо говоря, поддержки CUDA нет. Принудительное использование модуля CUDA приведет только к ошибке. кроме того,Начиная с OpenCV-4.0 и далее,CUDAМодуль перенесен вopencv_contribсередина,Исходный пакет по умолчанию без CUDA:

Следовательно, это не сработает, если мы загрузим только исходный код OpenCV, скомпилированный.,Необходимо добавить модуль contrib.,После загрузки,существоватьCmakeкомпилировать Добавить когдаcontrib模块из路径:-DOPENCV_EXTRA_MODULES_PATH=<opencv_contrib>/modulesи включи-DWITH_CUDA=ON。
Таким образом, после включения CUDA и компиляции мы можем использовать функцию OpenCV и напрямую передавать данные изображения графического процессора в TensorRT.
Если мы не устанавливаем версию OpenCV CUDA, мы можем использовать формат матового изображения версии ЦП, определенный в TensorRT, а затем преобразовать его в формат данных, который может принять TensorRT.
// Определите переменную для приема данных Mmat
float data[INPUT_H * INPUT_W * 3];
// Преобразование данных изображения OpenCV в чистый массив с плавающей запятой
void Mat_to_CHW(float *data, cv::Mat &frame)
{
assert(data && !frame.empty());
unsigned int volChl = INPUT_H * INPUT_W;
// unsigned int volImg = INPUT_H * INPUT_W * INPUT_C;
for(int c = 0; c < INPUT_C; ++c)
{
for (unsigned j = 0; j < volChl; ++j)
data[c*volChl + j] = float(frame.data[j * INPUT_C + c]) / 255.0;
}
return;
}
...
// Поместите сюда предыдущие данные Передано в графический процессор для расчета
// DMA the input to the GPU, execute the batch asynchronously, and DMA it back:
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_H * INPUT_W * INPUT_C * sizeof(float), cudaMemcpyHostToDevice, stream));
...Квантованный INT8 для TensorRT
INT8 по сравнению с FLOAT16,Может лучше оптимизировать использование памяти,И скорость значительно улучшена по сравнению с FLOAT16 (меньшая задержка и более высокая пропускная способность). Но предполагается, что наша видеокарта должна иметь достаточное количество вычислительных блоков INT8.,官方建议использовать6.1 и 7.хвычислительная мощностьGPUвидеокарта,1080TI, который мы часто используем, соответствует требованиям,Его вычислительная мощность составляет 6,1. Иметь достаточное количество вычислительных блоков INT8.
不懂вычислительная мощностьиз可以看这篇文章:Поскольку выпущена новая видеокарта, давайте поговорим об архитектуре видеокарты и связанных с ней технологиях, связанных с глубоким обучением.。
Диапазон точности Int8:
| Диапазон значений | минимальное положительное значение |
|---|---|---|
F32 | -3.4 x 10^38 ~ +3.4 x 10 ^38 | 1.4 x 10^45 |
F16 | -65504 ~ 65504 | 5.96 x 10^8 |
INT8 | -127 ~ 128 | 1 |
Квантование INT8 не приводит к большой потере точности и в настоящее время является одной из наиболее зрелых технологий квантования.
Конкретные этапы Количественной оценки здесь описываться не будут.,TensorRTизINT8из实现可以查看Nvidia相关изPPT:http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
Однако в PPT говорится только об общем процессе квантования. Количественное определение в TensorRT имеет закрытый исходный код. В настоящее время поддерживается только квантование INT8 для моделей Caffe и TensorFlow, а модель ONNX еще не поддерживается.
Другие подобные технологии посадки
Реализация технологий также является важной частью глубокого обучения. В настоящее время существует множество технологий реализации: Glow, TVM, Tensor Comprehensions, ncnn и т. д., все из которых предназначены для оптимизации моделей, которые мы реализовали в мобильных устройствах и встраиваемых устройствах. Я считаю, что реализация глубокого обучения получит широкое развитие в ближайшие два-три года.
Ссылки
https://mxnet.incubator.apache.org/tutorials/tensorrt/inference_with_trt.html
https://devtalk.nvidia.com/default/topic/1030042/jetson-tx1/loading-of-the-tensorrt-engine-in-c-api/
https://petewarden.com/2015/05/23/why-are-eight-bits-enough-for-deep-neural-networks/
https://blog.csdn.net/zhangjunhit/article/details/84562334
https://www.jianshu.com/p/43318a3dc715
https://arleyzhang.github.io/articles/923e2c40/
https://mp.weixin.qq.com/s/F_VvLTWfg-COZKrQAtOSwg
https://mp.weixin.qq.com/s/wyqxUlXxgA9Eaxf0AlAVzg
https://elinux.org/Jetson/Performance
https://www.leiphone.com/news/201610/s2fwkopa5E1oCJxD.html
https://yq.aliyun.com/articles/600425?spm=a2c4e.11153940.blogcont497080.17.a3ac2f68x2E2bh



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
