Используйте сценарий оболочки для объединения файлов субтитров srt (srtcat)
фон
Некоторое время назад я увлекся созданием видеороликов для B-сайтов, в основном делясь знаниями о мотоциклах. Работа тоже относительно черновая, всего несколько картинок с озвучкой и субтитрами для пояснения. Я попытался объяснить это сам и обнаружил, что требования к ритму для видеозаписи все еще относительно высоки, а вода здесь слишком глубока, чтобы ее можно было контролировать. К счастью, я поискал по ключевому слову «бесплатное онлайн-преобразование текста в речь» и нашел полезный веб-сайт — Субтитры. Существуют тысячи полезных инструментов синтеза речи. Почему именно этот мне особенно нравится? Оказывается, он одновременно с преобразованием текста рукописи в речь выводит еще и файл субтитров (srt). Его можно импортировать прямо в облачном редакторе станции Б, что очень удобно:
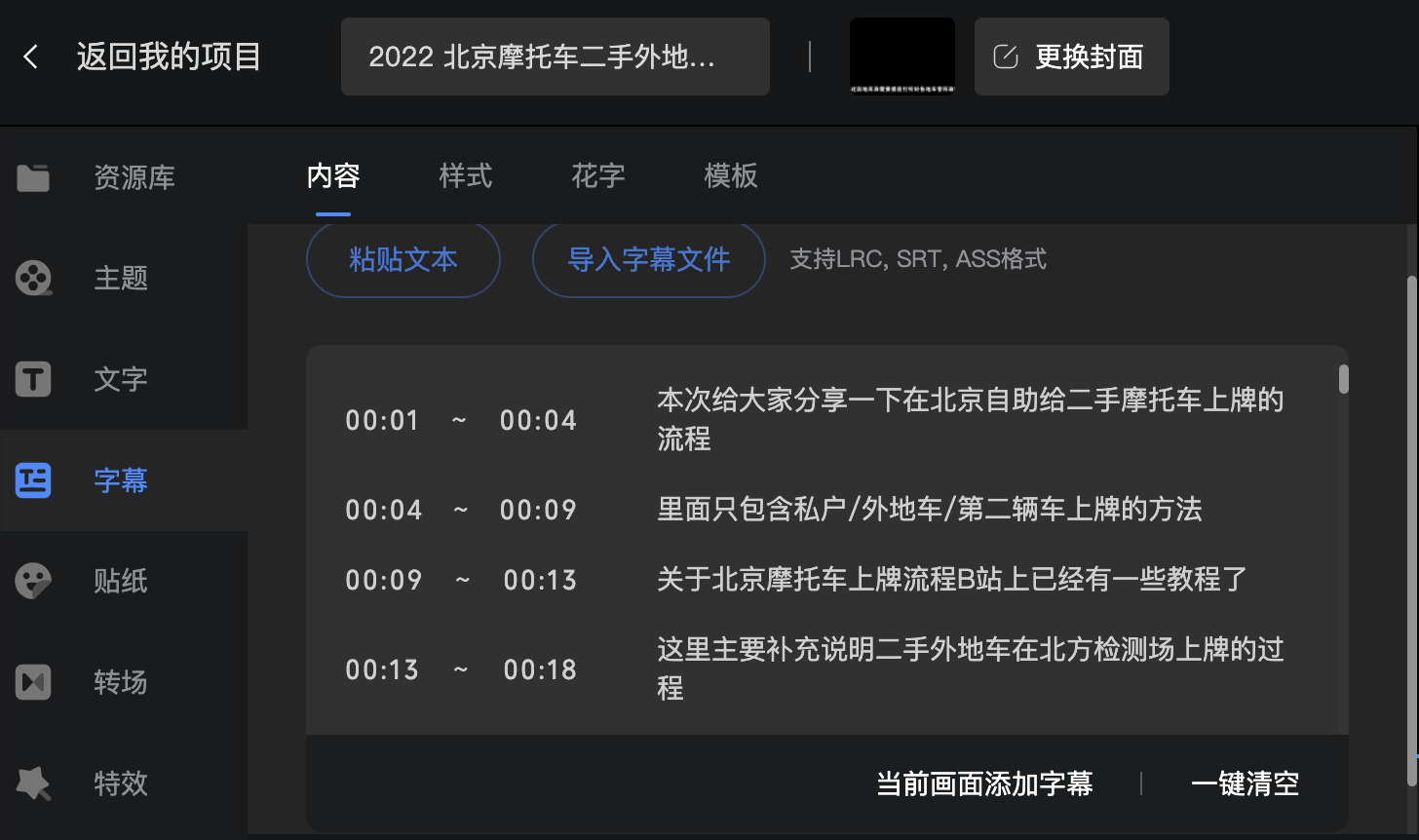
Конечный эффект будет заключаться в том, что субтитры будут воспроизводиться одновременно с голосом под видео:

Это кажется гораздо более точным, чем автоматически распознаваемые субтитры.
Белая проституция в субтитрах гласит:
Как и большинство бесплатных инструментов, бесплатность — это всего лишь знак для привлечения клиентов. Ведь в мире не существует бесплатных обедов. В подзаголовках написано, что одна конверсия ограничена не более чем 1000 китайскими иероглифами:
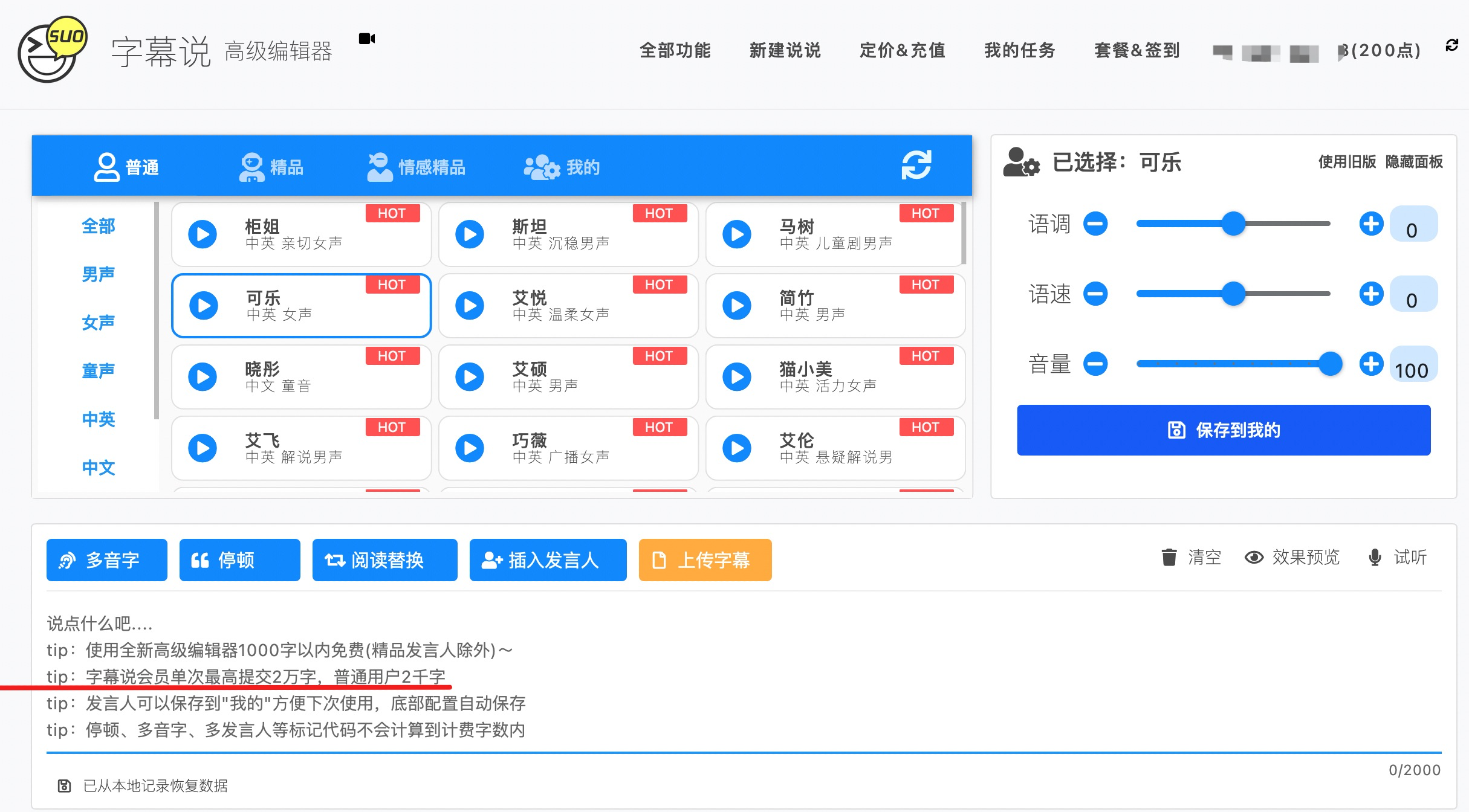
Хоть он и отмечен как 2000 слов, на самом деле, если он превышает 1000 слов, баллы уже начинают подсчитываться:
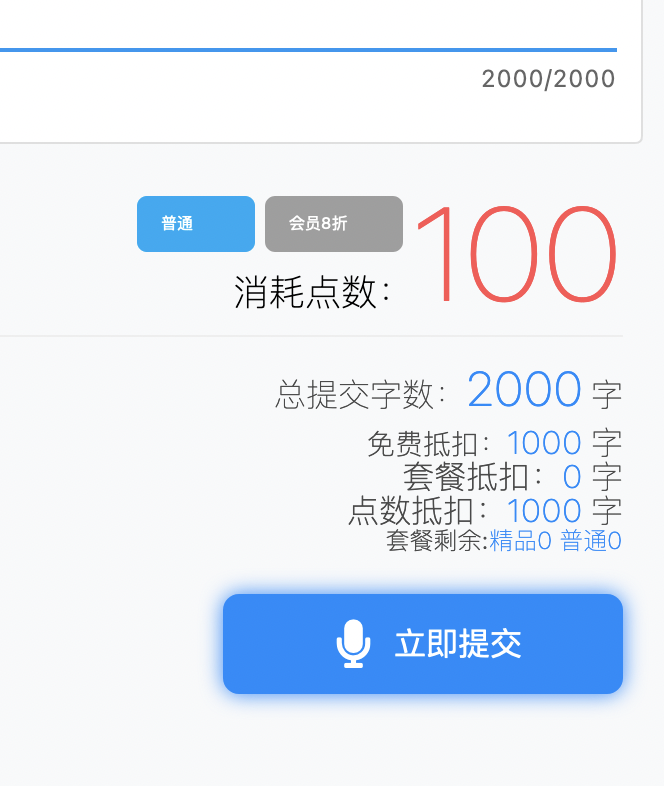
Речь идет о методе погашения 1 балл и 10 слов. Первоначальный аккаунт имеет около 200 баллов и может превышать 2000 слов. При этом эти 2000 слов также должны соответствовать лимиту, не превышающему 2000 слов за раз. 3000 слов, все равно будет засчитано дважды для генерации голоса и субтитров.
Как пользователь бесплатной проституции, не говоря уже о том, чтобы тратить деньги на покупку баллов, вы не рады их использовать. Разве не существует ограничения в 1000 слов на каждое бесплатное. Тогда разделите рукопись в соответствии с этим лимитом:
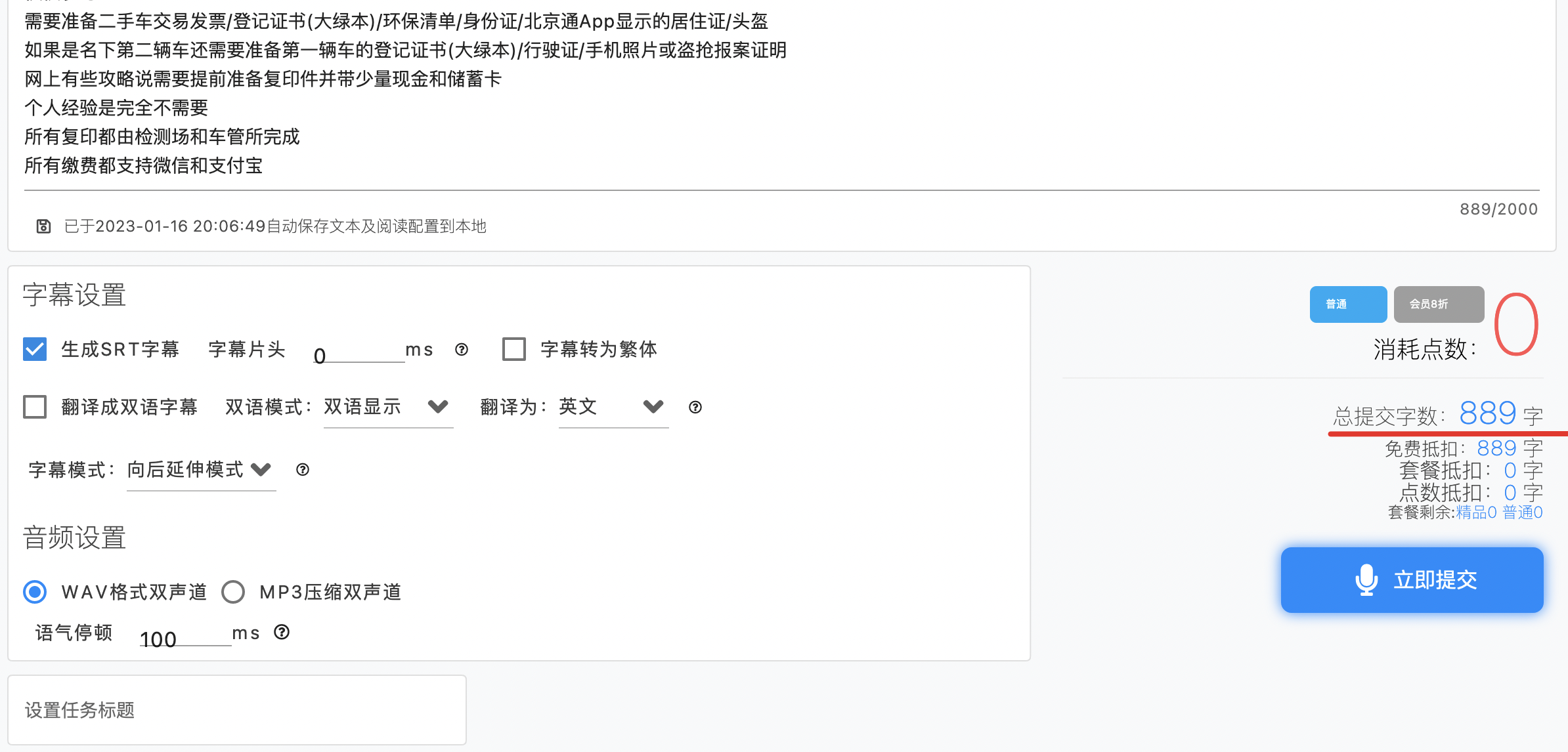
Ха-ха, как и ожидалось, бесплатная проституция прошла успешно. После нажатия «Отправить сейчас» вы можете перейти к интерфейсу запроса задачи:

После завершения конвертации вы можете выбрать для загрузки соответствующие аудиофайлы и файлы субтитров. Загруженный файл srt выглядит следующим образом:
1
00:00:00,000 --> 00:00:04,600
На этот раз я поделюсь с вами процессом самостоятельной регистрации подержанных мотоциклов в Пекине.
2
00:00:04,600 --> 00:00:08,680
Сюда входит только способ регистрации личного транспорта/внегородского транспорта/второго транспорта.
3
00:00:08,680 --> 00:00:12,560
На станции B уже есть несколько руководств по процессу регистрации мотоциклов в Пекине.
4
00:00:12,560 --> 00:00:17,120
Вот основное дополнительное объяснение процесса лицензирования подержанных иномарок в Северном инспекционном центре.
...Используйте пустую строку между каждым субтитромточкаразделенный,Разделен на три строки содержания,Это серийный номер, время воспроизведения и текст некоторых относительно длинных строк рукописи.,Фон будет автоматически расколоть несколько абзацев субтитров.
сращивание файлов SRT
Следующее будет Расколотьназадиз Аудиои Импорт субтитров B Редактирование облака станций. Звук относительно прост. После загрузки файла просто перетащите его сегмент за сегментом в синтезированное видео. Cloud Clip поддерживает импорт только одного файла субтитров за раз. Импорт новых субтитров автоматически очистит предыдущий контент. для его сегментации. Окончательные файлы субтитров объединяются в один файл и импортируются.
Вначале я использовал cat, и сгенерированный файл содержал весь контент. Однако после импорта я обнаружил, что вступила в силу только последняя часть субтитров, а часть предыдущих субтитров сохранилась в конце. все перепутано:
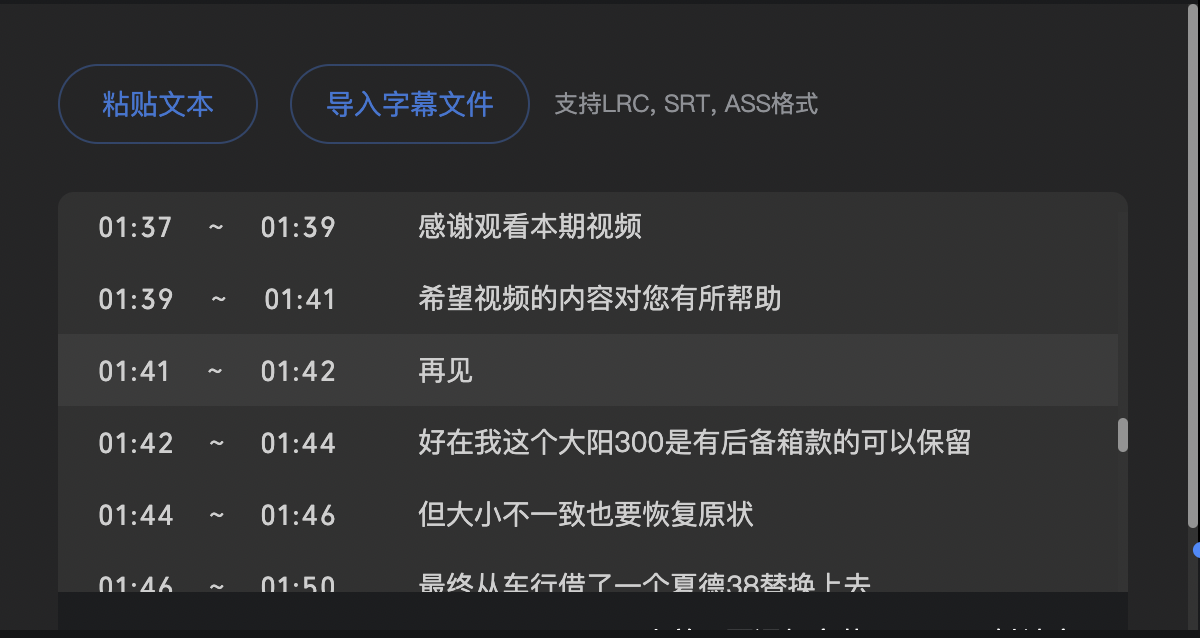
Оказывается, если не отрегулировать серийный номер и время воспроизведения субтитров, предыдущие субтитры будут перезаписаны последующими субтитрами с тем же серийным номером. Кажется, мне нужно найти инструмент для объединения файлов субтитров. После работы с Baidu я в основном нашел следующие инструменты:
SrtEdit
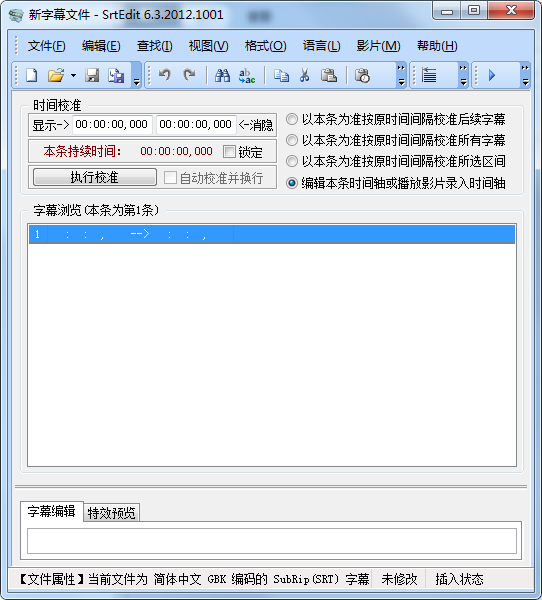
Это инструмент, который специализируется на различной обработке файлов субтитров. После открытия файла субтитров вы можете соединить файлы, напрямую добавив:
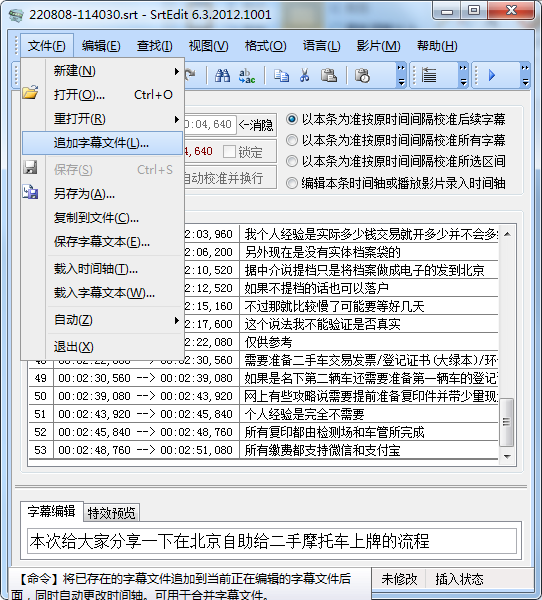
Вы также можете выбрать время начала нового файла при добавлении:
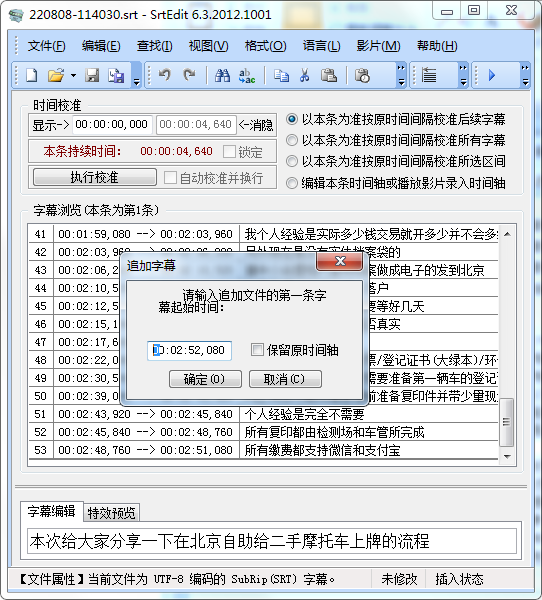
По умолчанию используется время окончания последнего файла плюс 1 секунда. После добавления вы можете напрямую сохранить его как смонтированный файл.
Srt Sub Master
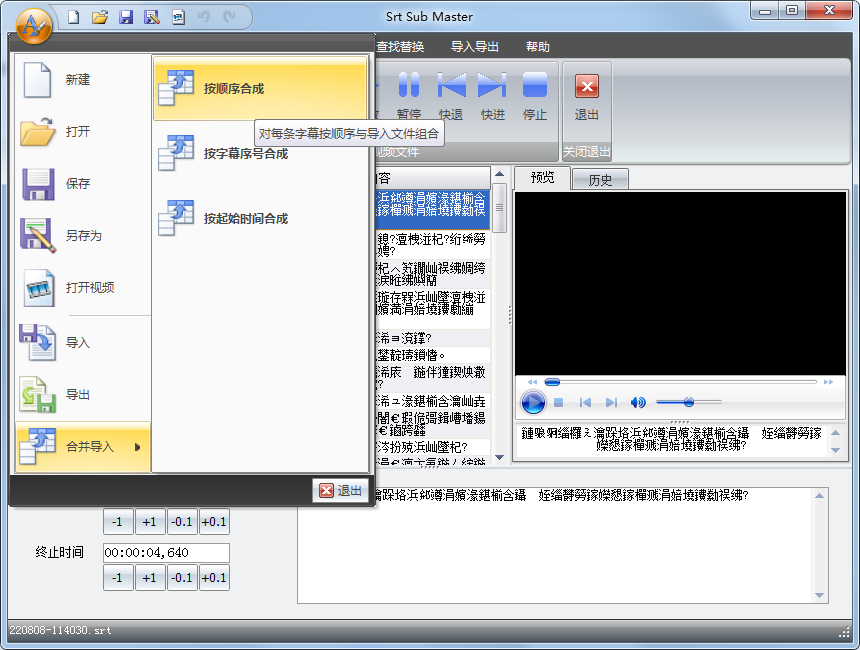
Откройте первыйдокументназадвыбирать:документ->Объединить импорт->Синтезируйте последовательно,Выполните настройки во всплывающем окне опций:
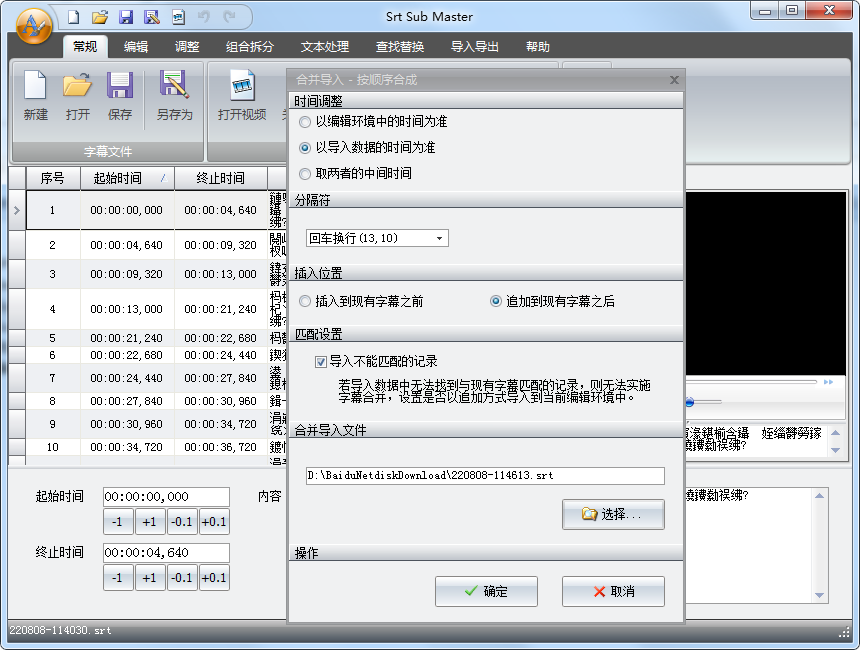
После того, как вы выбрали файлы, которые хотите объединить, вот и все:
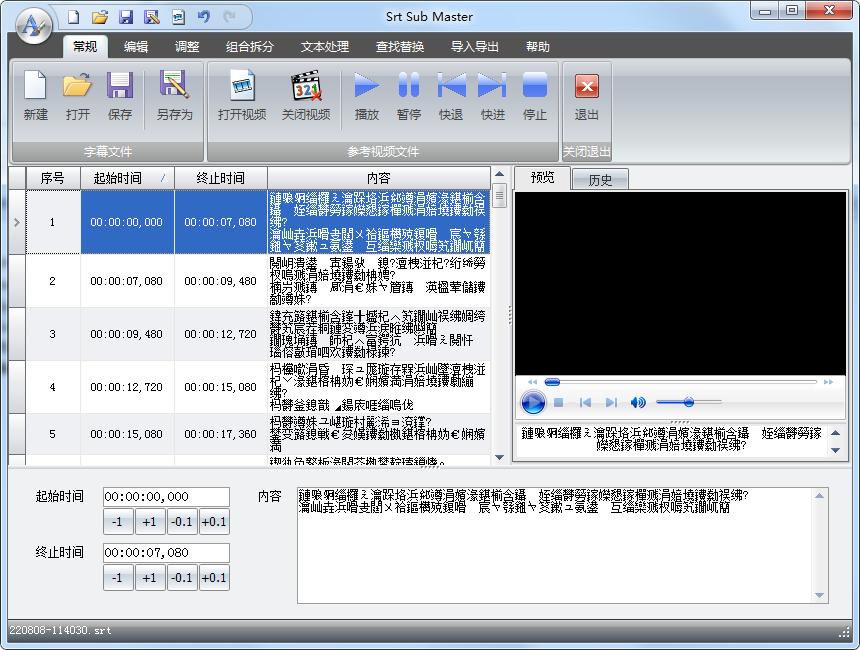
Однако конечный эффект, похоже, заключается в объединении нескольких субтитров в один период времени, который, по-видимому, используется для интеграции китайских и английских субтитров. Я просмотрел другие меню функций, предоставляемые приложением, и не нашел функции прямого сращивания двух файлов субтитров Pass.
Subtitle Workshop
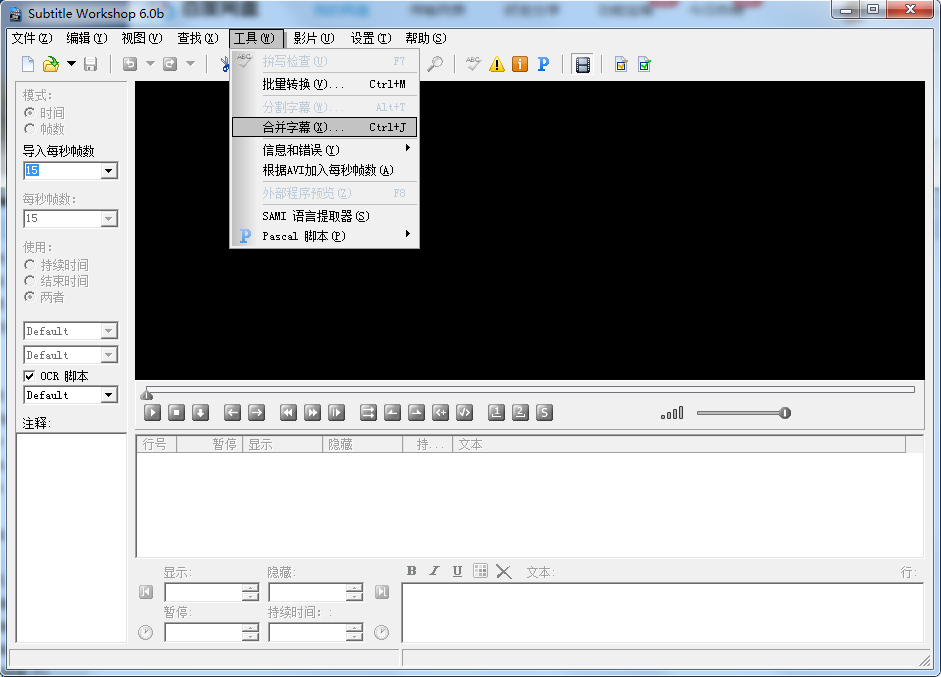
Откройте программное обеспечениеназадпрямойвыбирать:инструмент->Объединить субтитры
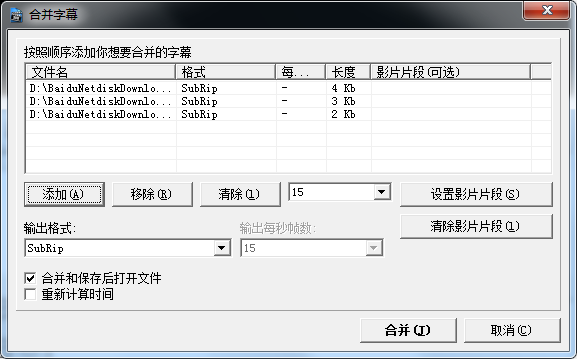
Выберите файлы во всплывающем окне выбора и объедините их:
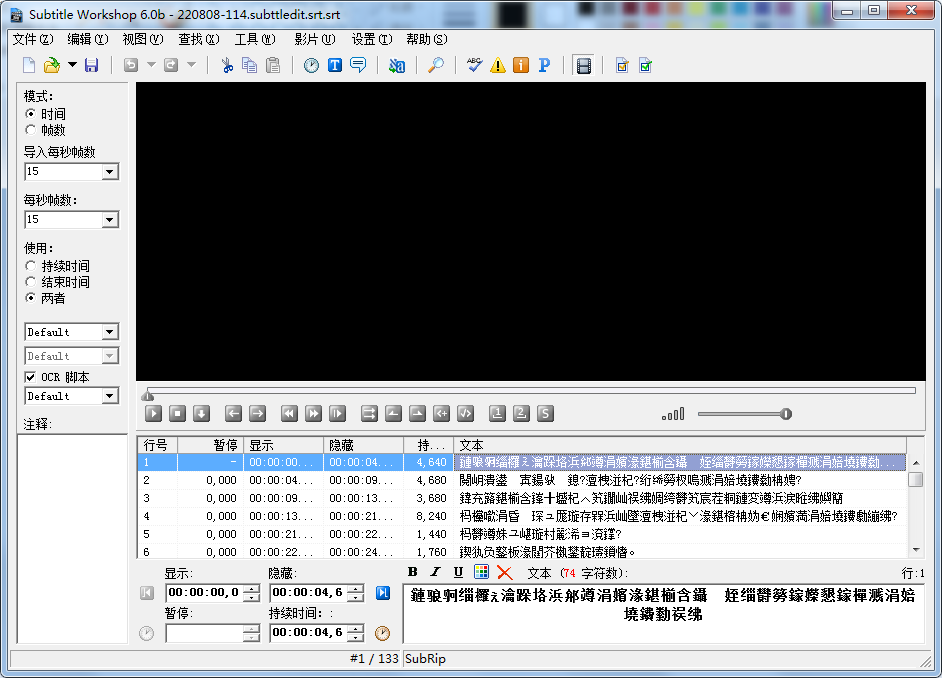
Наконец сохраните объединенный файл.
Китайские иероглифы в субтитрах здесь отображаются искаженными. Сначала я подумал, что это потому, что при экспорте файла srt из субтитров не был выбран формат utf-8 с BOM:
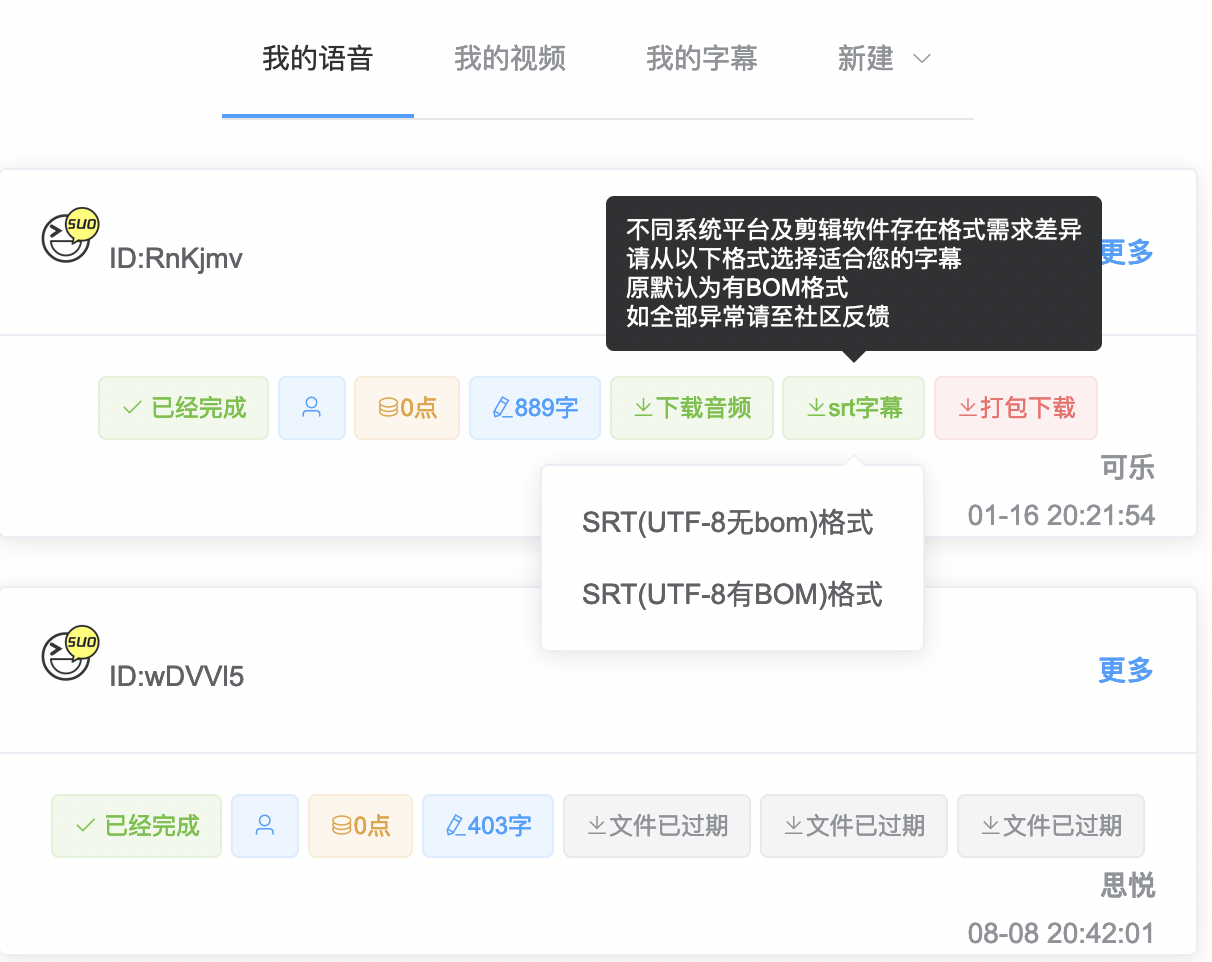
После перехода на формат с помощью bom он по-прежнему не работает:
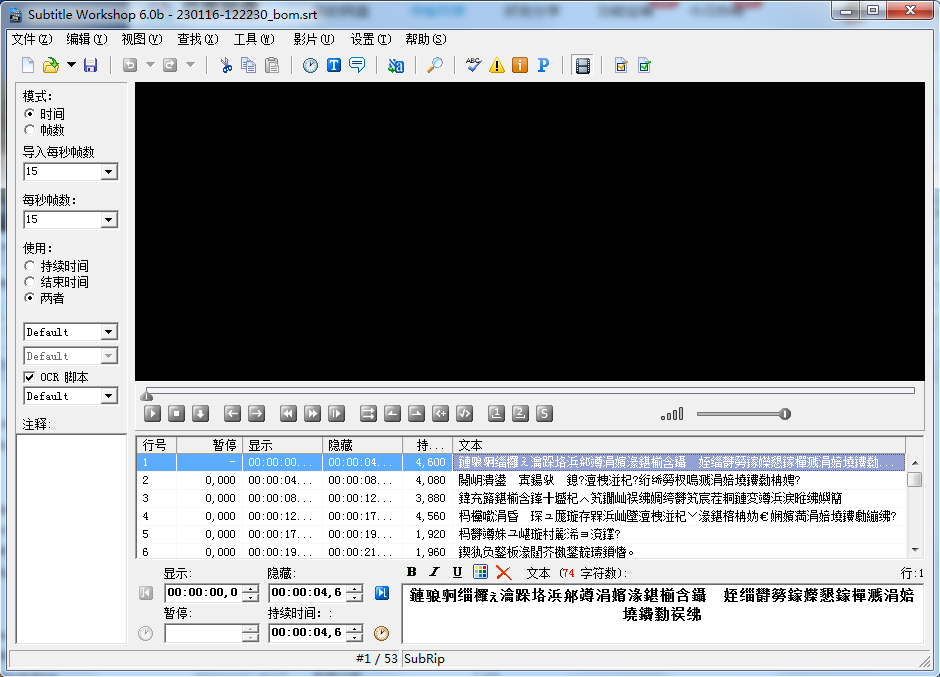
Но ту же проблему с искаженным кодом можно решить с помощью описанного выше метода для Srt Sub Master:
Давно не понимал, что такое Subtitle Workshop, проходите
Хэнпин
После некоторого сравнения Sub Srt Master не нашел соответствующей функции. У Subtitle Workshop возникли проблемы с кодировкой китайских символов, и в конце концов он выбрал SrtEdit. Поскольку в то время я очень спешил, я использовал файл субтитров, созданный выбранным инструментом, чтобы импортировать его в Bilibili Cloud Clip для создания видео.
srtcat
Инструменты с графическим интерфейсом просты в использовании, но есть две проблемы:
- Зависит от определенных платформ, таких как Windows, что очень недружелюбно для пользователей Mac.
- Графические инструменты в виде IDE, как правило, универсальны, и мой сценарий был очень одномерным с множеством установленных ненужных функций.
Второй пункт неочевиден для SrtEdit. Если посмотреть на два других, некоторые из них также связаны с видеофайлами, а субтитры — лишь малая часть их функциональности. Фактически, философия Unix заключается в предоставлении набора инструментов, а не в том, чтобы быть всеобъемлющей платформой. Жизненный цикл инструмента намного длиннее, чем платформы, поскольку никогда нельзя предсказать, как будущие пользователи будут его использовать. это. Лучший способ — предоставить пользователям однофункциональные инструменты, которые они смогут выбирать и интегрировать в свои сценарии.
Основываясь на этой идее, а также на том факте, что функция сращивания файлов srt не сложна, в основном это обработка серийных номеров и времени, я решил использовать сценарий оболочки для создания его вручную и назвать его srtcat:
> sh srtcat.sh
Usage: srtcat [-t timespan] file1 file2 ...Его очень просто использовать. Список параметров представляет собой файл SRT, который необходимо объединить. Содержимое начинается с серийного номера 1. Время начала первого файла должно начинаться с 00:00:00,000. Опция -t указывает время; интервал между файлами по умолчанию 1000 миллисекунд. Результат склейки будет выведен на стандартный вывод, который можно перенаправить в новый файл. Ошибки и предупреждения будут выводиться в поток stderr, чтобы предотвратить загрязнение содержимого stdout.
Адрес проекта:https://github.com/goodpaperman/srtcat
Этот инструмент содержит только сценарий оболочки srtcat.sh, содержащий более 230 строк, который относительно легко читается. Я не буду объяснять его здесь построчно, а только объясню выбор ключевых функций.
В процессе сращивания важным вопросом является обработка времени.,По последовательности обработки делится на Расколоть, Перейти к включению.,подточка Не объясняй。
Расколоть
в форме hh:mm:ss,xxx Форматизвремя,Во-первых, нуждаться извлекает из строки часы, минуты, секунды и миллисекунды.,Эта частьточка В основном хочу что-то сказать Расколотьвремянитьизтри видаплан。
cut
Самый интуитивный способ — использовать команду вырезания для перехвата одного за другим:
hour=$(echo "${line}" | cut -b 1-2)
min=$(echo "${line}" | cut -b 4-5)
sec=$(echo "${line}" | cut -b 7-8)
msec=$(echo "${line}" | cut -b 10-12)Недостаток вызова команды обрезки для обработки строк заключается в том, что за один раз обработки необходимо запустить четыре подпроцесса. Большое количество таких операций со строками определенно снизит эффективность скрипта. это собственный перехват строки оболочки:
hour=${line:0:2}
min=${line:3:2}
sec=${line:6:2}
msec=${line:9:3}Хотя это позволяет избежать вышеупомянутых проблем с производительностью, оно также перехватывается на основе фиксированной длины, которая основана на часах, минутах и секундах. 2 биты, миллисекунды заняты 3 битовая гипотеза, если hour занимал более 2 слова (hour > 99), это совершенно неправильное решение с точки зрения масштабируемости. 1 Этот метод фиксированной длины pass .
awk
Вместо использования фиксированной длины разделите ее по ключевым символам. Первое, что приходит на ум, — это команда awk, в которой вы можете указать несколько разделителей с помощью опции -F:
line="00:01:02,003 --> 04:05:06,007"
echo "${line}" | awk -F':|,| ' '{ for (i=1; i<=NF; i++) { print $i }}'Обратите внимание на переход между несколькими символами | В отдельности эффект следующий:
> sh awk.sh
00
01
02
003
-->
04
05
06
007Итак, как присвоить разделенную строку переменной оболочки? Методов много, здесь используется eval:
line="00:01:02,003 --> 04:05:06,007"
val=$(echo "${line}" | awk -F':|,| ' '{print "hour1="$1";min1="$2";sec1="$3";msec1="$4";hour2="$6";min2="$7";sec2="$8";msec2="$9";"}')
echo "${val}"
eval "${val}"
echo "${hour1}:${min1}:${sec1},${msec1}"
echo "${hour2}:${min2}:${sec2},${msec2}"Эффект от бега следующий:
> sh awk.sh
hour1=00;min1=01;sec1=02;msec1=003;hour2=04;min2=05;sec2=06;msec2=007;
00:01:02,003
04:05:06,007eval можно использовать после shell переменнаяhour1/min1/sec1/msec1Сначала цитируйтевремя、использоватьhour2/min2/sec2/msec2Цитирую второевремя,Имя переменной здесь можно задать произвольно.
IFS
awk Хотя это интуитивно понятно, дочерний процесс все равно нужно запустить. Есть ли более эффективный способ? Я нашел в Интернете статью, в которой говорилось, что его можно использовать shell Входит в комплект IFS точкаразделенный Настройки символов для обработки дат Расколоть,Кажется, это вполне подходит для моей сцены.,Давайте попробуем:
#! /bin/sh
line="00:01:02,003 --> 04:05:06,007"
OLD_IFS="${IFS}"
IFS=":, "
arr=(${line})
IFS="${OLD_IFS}"
for var in "${arr[@]}"
do
echo "${var}"
doneКаждый символ строки IFS является разделителем. Запустите приведенный выше скрипт и получите:
> sh ifs.sh
00
01
02
003
-->
04
05
06
007использовать {arr[0]}:{arr[1]}:{arr[2]},{arr[3]} Сначала цитируйтевремя,{arr[5]}:{arr[6]}:{arr[7]},{arr[8]} Цитирую второй раз.
Хэнпин
С точки зрения производительности, IFS Метод является оптимальным решением, оболочка Перехват символов — второй, awk+eval Во-вторых, вырезать Наконец, с точки зрения масштабируемости; (hour > 99),IFS、awk намного лучше, чем shell Усечение символов и сокращение, интуитивно говоря, awk+eval; оптимальный, оболочка Усечение символов и cut Во-вторых, ИФС (использовать arr[N] Цитировать) В конце. Учитывая сцену после «Скриптиспользовать», лицо сравнительно большое. srt файл, производительность станет узким местом, поэтому выберите IFS Чтобы максимально повысить производительность скриптов, хотя интуитивность приносится в жертву, масштабируемость сохраняется.
Перейти к нулю
Расколоть после того, как переменная времени является строкой,Когда есть ведущие нули,При непосредственном участии в операциях сложения,Иногда возникает следующая ошибка:
srtcat.sh: line 8: 080: value too great for base (error token is "080")Причина в том, что миллисекунда 080 распознается как восьмеричная (префикс 0 — восьмеричная, префикс 0x — шестнадцатеричная), а наибольшее число в восьмеричной системе — 7. Если встречается число, превышающее 7, будет сообщено об ошибке.
Вот несколько решений:
${var##0*}
Сначала я хотел использовать shell Перехват строк через ## Реализуйте самый длинный матч слева направо,проходить0*Сопоставить все нулевые строки,Но я обнаружил, что этот план не сработал:
> var=080
> echo ${var##0*}
> echo ${var#0*}
80
> var=007
> echo ${var##0*}
> echo ${var#0*}
07В основном shell Воля##0*Поймите, что для сопоставления всех чисел,Сопоставление будет остановлено до тех пор, пока не встретится символ или буква.,Результат в сопоставлении ненулевых чисел. проходить
sed
Затем на ум приходит обычное сопоставление и извлечение чисел в sed:
> var=007
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
7
> var=080
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
80
> var=123
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
123проходить0*Сопоставить ведущие нули、[0-9]*оставшийся матчизчисло。этотплан Недостатки очевидны,Время из каждого компонента нуждаться запускает отдельный дочерний процесс и предыдущий вырезает то же самое.,Спектакль, безусловно, хороший.
$(())
Ссылка Статья в Интернете, использование оболочки Хитрости операторов:
> var=080
> echo $((1${var}-1000))
80
> var=007
> echo $((1${var}-1000))
7
> var=123
> echo $((1${var}-1000))
123То есть, уточнив количество цифр в строке, добавьте начальную 1 сделай это 1xxxx В виде 1 В результате значение численного роста (Например, для 3 Цифры 1000), восстанавливается исходное число, а также удаляются ведущие нули. Недостатки этого метода также очевидны. (hour>99) не хорошо.
awk
Сравнивая раньше Расколотьпланоднажды представленный awk,еслииспользовать awk+eval схеме, то удаление ведущих нулей — дело несложное:
line="00:01:02,003 --> 04:05:06,007"
val=$(echo "${line}" | awk -F':|,| ' '{print "hour1="$1/1";min1="$2/1";sec1="$3/1";msec1="$4/1";hour2="$6/1";min2="$7/1";sec2="$8/1";msec2="$9/1";"}')
echo "${val}"
eval "${val}"
echo "${hour1}:${min1}:${sec1},${msec1}"
echo "${hour2}:${min2}:${sec2},${msec2}"По сравнению с предыдущим вариантом, при построении выражения присваивания внутри команды awk к каждому полю добавляется только операция деления на 1 (/1), и awk автоматически преобразует строку в число:
> sh awk.sh
hour1=0;min1=1;sec1=2;msec1=3;hour2=4;min2=5;sec2=6;msec2=7;
0:1:2,3
4:5:6,7фактическое влияниеное умножение 1 (*1) Да, это слишком удобно.
Хэнпин
При сочетании Расколоти Перейти к ошибке возникают следующие комбинации:
- $((var:0:2)) + sed
- ((var:0:2)) + ((1
- awk+eval
- IFS + sed
- IFS + ((1var-100))
потому что cut План явно уступает shell Производительность перехвата строк хорошая, вот это унифицированное использование ((var:0:2)) заменять Cut, образующий первые два решения, второе явно лучше awk+eval; Он может сам удалять ведущие нули, и нет необходимости снова суммировать их. sed или ((1
- ((var:0:2)) + ((1
- awk+eval
- IFS + ((1var-100))
Большой разницы между Вариантом 1 и Вариантом 3 нет. Преимуществами являются высокая производительность, недостатком — плохая масштабируемость. Преимуществом Варианта 2 является хорошая масштабируемость и высокая читаемость, а недостатком — низкая производительность.
Если я сужу сценарии применения, независимо от размера файла субтитров, их будет очень мало. hour > 99 Однако когда содержимое файла велико, можно легко обработать десятки тысяч строк, что предъявляет относительно высокие требования к производительности и относительно небольшие требования к масштабируемости. После всестороннего рассмотрения мы решили пожертвовать масштабируемостью и сосредоточиться на производительности. 2 проходить. план 1 и планировать 3 В любом случае, в настоящий моментинструментиспользоватьиздаплан 3。
Заключение
На тот момент у нас была острая необходимость в создании видеороликов.,Этот инструмент не используется,прямойиспользовать Понятно SrtEdit выход. Этот инструмент может run Позже я специально поискал для проверки предыдущие файлы и обнаружил, что склеенные файлы такие же, как и SrtEdit Сгенерированные видео будут точно такими же. Если вы в следующий раз сделаете подобное видео, вы сможете сделать это, не выходя. mac Платформа, хаха.
В настоящее время инструмент srtcat поддерживает три платформы: Mac, Linux и Windows (для Windows требуется git bash). Короче говоря, поддерживаются все системы, которые могут запускать оболочку.
Раньше при выборе решений особое внимание уделялось ориентации на производительность. Действительно ли решение, используемое в настоящее время, имеет более высокую производительность? Проведем эксперимент и выберем три тестовых файла общим количеством более 500 строк:
> wc -l 220808*
211 220808-114030.srt
183 220808-114613.srt
135 220808-114838.srt
532 220808.txt
1061 totalВыберите два варианта, один из них awk+eval, другой IFS+((1var-100)),Давайте посмотрим на первое выступление планиз:
> time sh srtcat.awk.sh 220808-114*.srt > 220808.txt
...
real 0m1.826s
user 0m0.822s
sys 0m1.186sОбщее затраченное время составляет 1,826 с. Рассмотрим второй вариант:
> time sh srtcat.ifs.sh 220808-114*.srt > 220808.txt
...
real 0m1.539s
user 0m0.669s
sys 0m1.037sОбщее время составляет 1,539 с, что на 0,287 с и примерно в 1,2 раза быстрее. Я не пробовал решения Cut и sed, потому что они определенно смехотворно медленны.
ссылка
[1]. субтитры говорят
[2]. sed Извлечение строк с фиксированным интервалом
[3]. [Любовный занавес] Онлайн-редактор субтитров
[4]. 【Linux】Команда оболочки Подробное объяснение использования getopts/getopt.
[5]. ошибка сценария оболочки value too great for base
[7]. использоватьSubtitle Мастерская поставила несколько срт Объединение файлов субтитров
[8]. Оболочка удаляет все нули перед строкой.
[9]. shell Скрипт для удаления ведущих нулей из месяцев и дней
[10]. Подробный анализ переменных IFS в Shell
[11]. Сценарий оболочки реализует цифровое преобразование printf с заполнением нулями N-значными числами.
[12]. Формат субтитров SRT



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
