Используйте несколько Lora для экономии затрат на развертывание крупных моделей|Dewu Technology
1. Предыстория
Недавно мы столкнулись с некоторыми проблемами при развертывании крупных модельных кластеров. У компании есть несколько бизнес-сценариев, каждый из которых дорабатывается на основе собственных данных, а соответствующие крупные модели обучаются и выкладываются в Интернет. Однако объем вызовов в этих сценариях невелик, а стоимость развертывания больших моделей относительно высока, что приводит к пустой трате ресурсов.
В этой статье будет показано, как мы используем технологию multi-Lora для объединения и развертывания нескольких сценариев для эффективного решения этой проблемы. В то же время мы также будем изучать применение технологии Lora в процессе обучения и вывода больших моделей.
2. Что такое Лора?
Концепция Лоры
Если вы поищите в Интернете ключевое слово «Лора», вы обязательно найдете следующую статью.

Отсюда и произошло слово Лора. Эту концепцию предложил Эдвард Дж. Ху, известный исследователь искусственного интеллекта, в 2021 году. Полное имя Лоры — Адаптация Низкого Ранга. Хотя название сложное, основную концепцию относительно легко понять.
Если взять в качестве примера GPT3, эта модель имеет 175 миллиардов параметров. Чтобы адаптировать большую модель к конкретному бизнес-сценарию, нам часто требуется ее тонкая настройка. Если полнопараметрическая тонкая настройка выполняется на большой модели, стоимость будет очень высокой из-за большого количества параметров. Решение Lora technology заключается в точной настройке менее 2% параметров, оставляя остальные параметры неизменными. По сравнению с полностью параметрически настроенным GPT-3 (175B) Lora может сократить количество обучающих параметров примерно в 10 000 раз, а требования к памяти графического процессора также уменьшаются в три раза.
Итак, как Лора замораживает параметры? Далее мы покажем классическую схему Лоры.
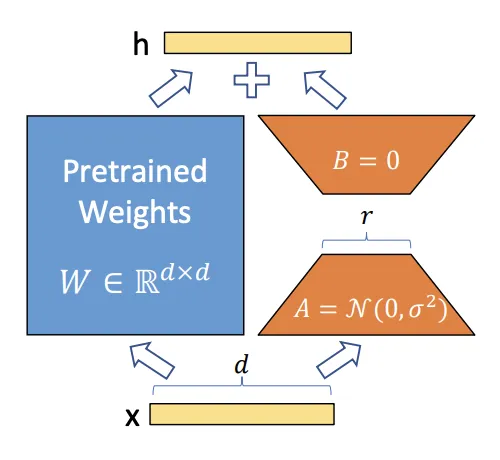
На рисунке выше W представляет исходную матрицу параметров большой модели. Идея Лоры состоит в том, чтобы разбить матрицу W на две матрицы низкого ранга A и B. В процессе обучения обучаются только параметры A и B, что позволяет значительно сократить количество необходимых параметров обучения по сравнению с обучением параметров всего W, тем самым снижая стоимость обучения.
Как включить тонкую настройку Lora для больших моделей
Хотя принцип Lora, описанный в статье, относительно сложен, процесс тонкой настройки Lora для больших моделей на самом деле относительно прост. Многие платформы алгоритмов поддерживают быстрый запуск и тонкую настройку. В качестве примера возьмем LLaMA-Factory, фреймворк для тонкой настройки больших моделей. Чтобы включить тонкую настройку Lora, вам нужно всего лишь настроить следующие параметры:

Затем выполните команду обучения, чтобы начать тонкую настройку Lora:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
С помощью этой команды платформа LLaMA-Factory прочитает файл конфигурации и начнет тонкую настройку Lora. Весь процесс относительно прост, что позволяет пользователям быстро адаптироваться и использовать технологию Lora для точной настройки больших моделей.
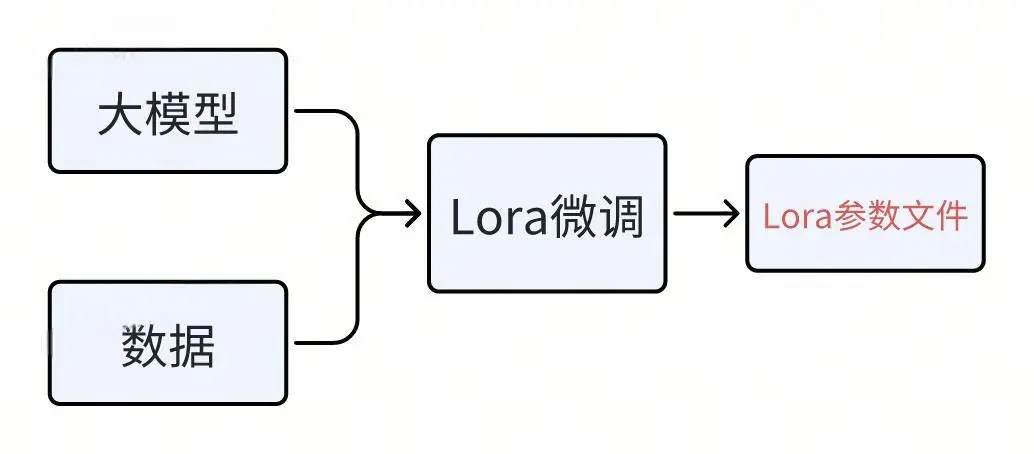
После завершения тонкой настройки Lora будет создан файл, содержащий только некоторые параметры (т.е. параметры Lora), называемый Lora Adaptor. Этот файл параметров очень мал по сравнению со всеми параметрами всей большой модели.
3. Как развернуть большие модели на базе Лоры
Объединение параметров Лоры
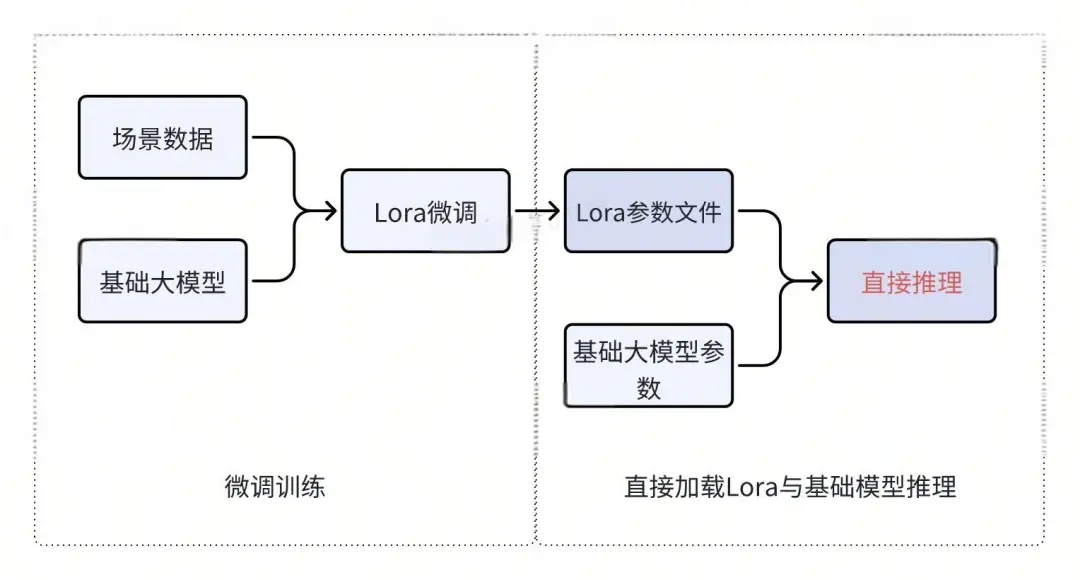
После тонкой настройки будет сгенерирован файл Lora, содержащий лишь некоторые параметры. Как использовать этот файл Lora для развертывания большой модели?
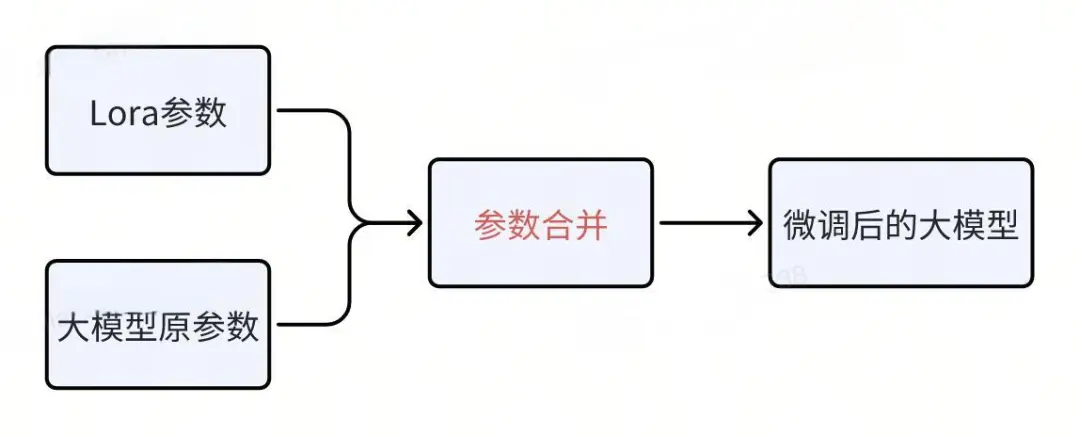
Ранее мы упоминали, что параметры Лоры на самом деле — это то, что осталось после заморозки остальных параметров более крупной модели. Сам параметр Лора также является частью больших параметров модели, обычно составляя менее 2% от общего числа. После объединения точно настроенных параметров Lora с исходными параметрами большой модели можно создать новую точно настроенную большую модель, а затем просто развернуть новую модель напрямую.
Этапы слияния также относительно просты. Возьмем в качестве примера LLaMA-Factory, среду обучения для точной настройки большой модели.
Сначала выполните следующую конфигурацию:

Далее выполните команду
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
Параметры можно объединить в новую большую модель.
Как развернуть объединенную большую модель
Объединенная большая модель содержит только несколько файлов параметров. Если вы хотите ее развернуть, вам нужно выбрать соответствующий механизм вывода. В настоящее время рекомендуется использовать VLLM, механизм вывода с открытым исходным кодом, который широко поддерживается моделями многих крупных производителей. VLLM превосходен как с точки зрения производительности, так и с точки зрения простоты использования.

Первоначально VLLM была инициирована группой докторов наук из Калифорнийского университета в Беркли, состоящей из трех человек. Основатель впервые разработал концепцию PageAttention. Это нововведение значительно повышает производительность крупных моделей в десятки раз. PageAttention теперь стал важным навыком для основных механизмов вывода.

Если вы хотите использовать VLLM для развертывания большой модели, действия очень просты. Сначала выполните следующую команду для установки VLLM:
pip install vllm
Затем выполните следующую команду, чтобы запустить службу.
vllm служить {адрес файла модели}
Что не так с таким процессом развертывания?
Сначала давайте рассмотрим предыдущий процесс обучения и развертывания.
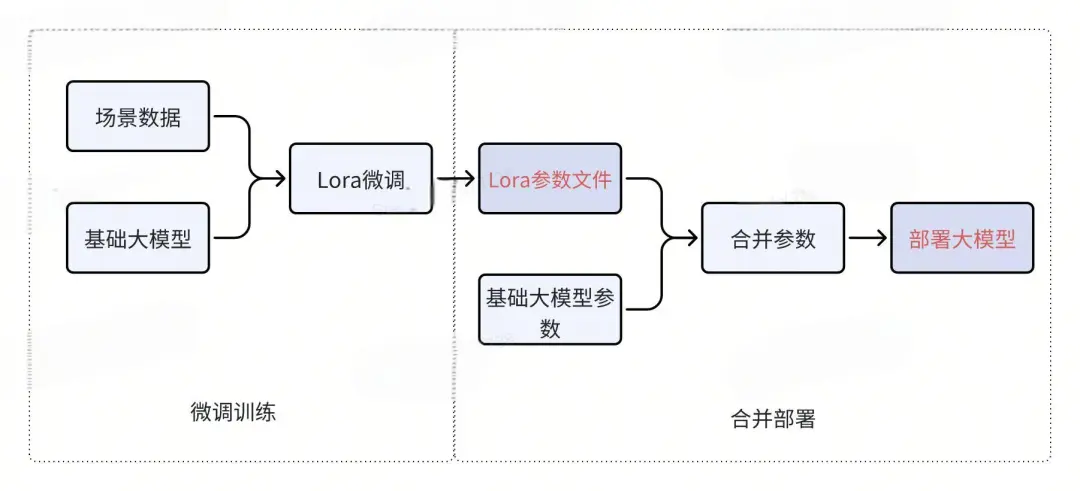
Для каждого бизнес-сценария мы сначала создаем файл параметров Lora посредством точной настройки, затем объединяем файл параметров Lora с базовой большой моделью и, наконец, развертываем большую модель. Это классический процесс.
Однако если существует множество бизнес-сценариев и трафик каждого сценария невелик, необходимо развернуть несколько наборов крупных моделей. Если взять в качестве примера обычную большую модель 7B, для ее работы требуется как минимум одна видеокарта с видеопамятью 22 ГБ, в то время как для модели 14B требуются две видеокарты с видеопамятью 22 ГБ, а для большой модели 70B требуется более высокая стоимость. Эта ситуация может привести к пустой трате ресурсов графического процессора.
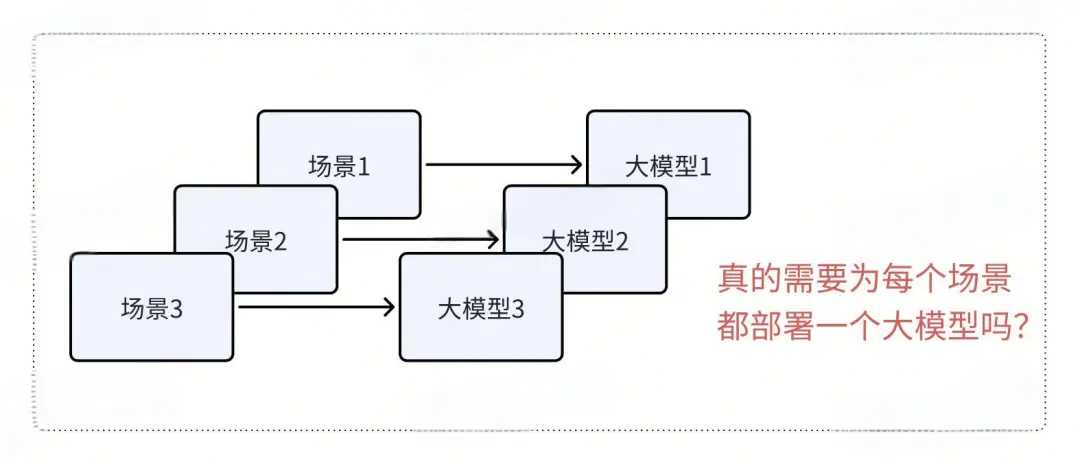
4. Что такое большая модель развертывания нескольких Лора?
Каков технический принцип Мульти-Лора?
В описанном выше процессе развертывания файл Lora будет создан после точной настройки большой модели, которую необходимо объединить с базовой большой моделью, чтобы сформировать новую большую модель. Однако на самом деле мы можем не объединять файлы Lora, а напрямую загружать исходные параметры большой модели и параметры Lora в видеопамять, а затем выполнять логический вывод. Этот метод также возможен.
Ссылаясь на приведенную выше схематическую диаграмму Лоры, W представляет собой исходную матрицу параметров большой модели. Идея Лоры состоит в том, чтобы разделить матрицу W на две матрицы низкого ранга A и B и обучить эти две матрицы. После обучения мы можем объединить матрицы A и B с матрицей W или не объединять их. Вместо этого используйте W и A/B для вычислений соответственно, а затем объедините результаты вычислений. Конечный эффект тот же.
Поэтому наш процесс развертывания можно скорректировать следующим образом: Бизнес-сторона генерирует файл Lora после тонкой настройки Lora. Далее мы загружаем базовую большую модель в видеопамять, а также загружаем файл Lora бизнес-стороны для непосредственного выполнения вывода. Если задействовано несколько бизнес-сторон, каждая бизнес-сторона создаст файл Lora, поэтому этот процесс развертывания можно продвигать, как показано на рисунке ниже.
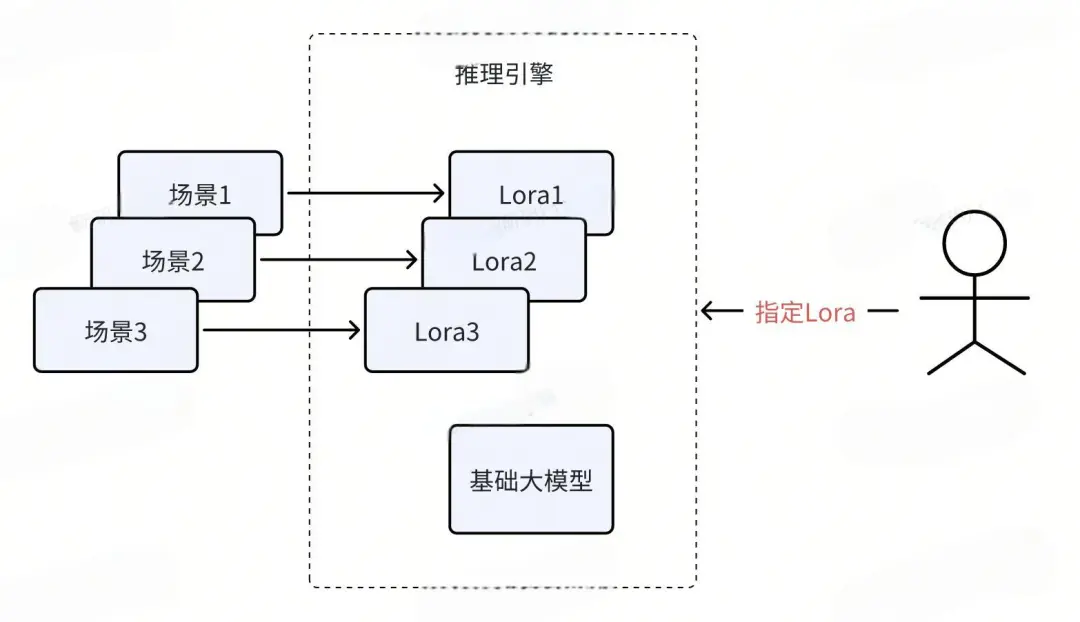
Каждый бизнес-сценарий обучает файл Lora на основе собственных бизнес-данных. При развертывании нам нужно только выбрать базовую большую модель и одновременно загрузить в видеопамять несколько файлов Lora. Таким образом, одну видеокарту можно использовать для одновременного удовлетворения потребностей нескольких бизнес-сценариев. Когда пользователь делает запрос, он должен указать в запросе, какую модель Lora необходимо вызвать.
Для каких сценариев подходит Мульти-Лора?
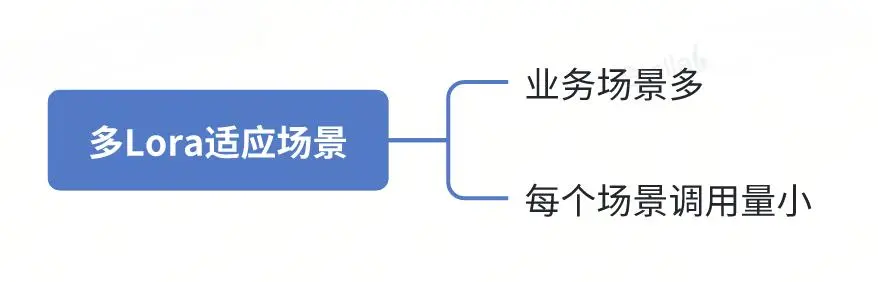
Мульти-Лора подходит для следующих сценариев:
- Разнообразные бизнес-сценарии:Когда у вас много бизнес-сценариев,И каждый сценарий необходимо доработать, чтобы на основе его конкретных данных создать собственную большую модель.
- Небольшой объем звонков:Если количество звонков на бизнес-сценарий относительно невелико,Тогда стоимость развертывания большой модели отдельно для каждой сцены будет очень высокой.
Использование нескольких Lora для развертывания больших моделей может эффективно решить эти проблемы. Загружая только одну базовую большую модель и одновременно загружая в видеопамять несколько файлов Lora меньшего размера, мы можем значительно снизить стоимость повторного развертывания. Таким образом, можно поддерживать несколько бизнес-сценариев, сохраняя при этом эффективное использование ресурсов.
Какие платформы вывода поддерживают несколько Lora
В настоящее время VLLM является рекомендуемым выбором среди платформ вывода, поддерживающих несколько Lora. Мы провели стресс-тест производительности VLLM с несколькими Lora, и результаты показали, что он работает очень хорошо с точки зрения производительности и простоты использования.
Если вы хотите использовать VLLM для развертывания нескольких Lora, просто выполните следующую команду:
vllm служить {адрес вашей модели} --enable-lora --lora-modules {адрес lora1} {адрес lora2}
Таким образом, вы можете легко включить функциональность мульти-Лора в VLLM.
Какова производительность мульти-Лора и какие ограничения?
Чтобы проверить производительность нескольких Lora, мы специально использовали модель Llama3-8b и видеокарту L20GPU для сравнения стресс-тестов. Данные следующие:

видимый,Влияние многократного Лора на пропускную способность и скорость рассуждения практически незначительно.。
Итак, каковы ограничения по применению Мульти-Лора?

- Общая базовая большая модель:Все несколько бизнес-сценариев, которые необходимо развернуть вместе, должны использовать одну и ту же базовую большую модель.。Это потому, что существует многоLoraПри развертывании,Вам нужно загрузить только одну копию базовой большой модели.,Чтобы поддержать рассуждения нескольких Лора.
- Ограничения ранга Лора:Если вы используетеVLLMпродолжай дальшеLoraразвертывать,При тонкой настройке обучения,Значение ранга Лоры R не должно превышать 64. большую часть времени,Все эти условия могут быть выполнены,Но на это нужно обратить внимание в определенных сценариях.
Поэтому перед развертыванием нескольких Лора необходимо убедиться в выполнении вышеуказанных требований для обеспечения нормальной работы системы.
5. Резюме
Эта статья начинается с того, как сэкономить на развертывании больших моделей в нескольких бизнес-сценариях.,Пошаговое введение в концепцию Лоры и способы тонкой настройки Lora на больших моделях.,И как включить параметры Lora для развертывания больших моделей после тонкой настройки. затем,Мы подняли вопрос: При развертывании нескольких бизнес-сценариев,Как снизить стоимость развертывания больших моделей. с этой целью,Мы представили способы использования нескольких Lora,Для консолидации развертывания нескольких бизнес-сценариев.
В конце статьи мы поделились результатами стресс-теста режима развертывания мульти-Лора. Результаты показывают, что производительность режима мульти-Лора практически незначительна по сравнению с методом объединенного развертывания. Мы также рекомендуем механизм вывода, поддерживающий несколько Lora, чтобы помочь читателям лучше применять эту технологию.
Конечно, вам также необходимо обратить внимание на некоторые ограничения при использовании нескольких Loras. Например, несколько сцен должны использовать одну и ту же базовую большую модель. Если у вас есть похожие сценарии или вы заинтересованы в технологии больших моделей, вы можете общаться, учиться вместе с нами и добиваться прогресса вместе.
*искусство / неделя
Эта статья является оригинальной работой Dewu Technology. Перепечатка без разрешения Dewu Technology строго запрещена, в противном случае будет предусмотрена юридическая ответственность в соответствии с законом!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
