Используйте модель LSTM для прогнозирования временных рядов многофункциональных переменных.
Привет, я Джонго~
Сегодня я хочу поговорить с вами о「Используйте модель LSTM для прогнозирования временных рядов многофункциональных переменных.」Простой проект для。
ЛСТМ ЛСТМ Концепция., может помочь нам делать более точные прогнозы в различных практических приложениях. Эти приложения включают прогнозирование финансового рынка.、прогноз погоды、Прогноз энергопотребления и т.д.
В этом проекте используется Python и платформа TensorFlow/Keras для реализации модели LSTM для прогнозирования данных временных рядов многофункциональных переменных.
Процесс реализации
- Подготовка данных
- Сбор и подготовка наборов данных временных рядов.
- Обработка пропущенных значений и выбросов.
- нормализацияданные。
- Предварительная обработка данных
- Создание входных объектов и целевых переменных.。
- Разделите данные на обучающий набор и тестовый набор.。
- Измените данные в формат, подходящий для модели LSTM.
- Создайте и обучите модель LSTM.
- использоватьKerasЗдание LSTMМодель。
- Скомпилировать модельи установите оптимизатор и функцию потерь。
- Модель обученияи проверить。
- Оценка модели и прогнозирование
- Модель оценкипроизводительность。
- Используйте Модель, чтобы делать прогнозы на будущие моменты времени.
- Предварительный просмотр результатов прогнозаи фактическая стоимость。
Реализация кода
В этом примере,Создайте смоделированный набор данных многофункциональных временных рядов.,и Сохранить как файл CSV以供использовать。你可以использовать以下代码生成一个模拟的данныенабор,затем сохраните какmulti_feature_time_series.csvдокумент。
Создайте набор данных моделирования и сохраните его в виде файла CSV.
import numpy as np
import pandas as pd
# Установите случайное начальное число, чтобы обеспечить повторяемость.
np.random.seed(42)
# Сгенерируйте смоделированные данные временных рядов
time_steps = 1000
data = {
'temperature': np.random.normal(20, 5, time_steps), # Имитация температурных данных
'humidity': np.random.normal(50, 10, time_steps), # имитировать влажностьданные
'wind_speed': np.random.normal(10, 2, time_steps), # Имитация скорости ветра
'power_consumption': np.random.normal(200, 50, time_steps) # Имитировать энергопотреблениеданные
}
# CreateDataFrame
df = pd.DataFrame(data)
# Сохранить как файл CSV
df.to_csv('multi_feature_time_series.csv', index=False)
print("Набор данных моделирования был сохранен как multi_feature_time_series.csv")
Запустите приведенный выше код набор данных моделирования и сохраните его в виде файла CSV.。
Затем вы можете использовать сгенерированный файл CSV для построения и обучения последующей модели прогнозирования временных рядов LSTM.
весь Реализация кода
Ниже представлена полная реализация кода,включить генерациюданныенабор、Предварительная обработка данные, построение и обучение модели LSTM, а также оценка модели и прогнозирование。
1. Создайте набор данных моделирования и сохраните его в виде файла CSV.
import numpy as np
import pandas as pd
# Установите случайное начальное число, чтобы обеспечить повторяемость.
np.random.seed(42)
# Сгенерируйте смоделированные данные временных рядов
time_steps = 10000
data = {
'temperature': np.random.normal(20, 5, time_steps), # Имитация температурных данных
'humidity': np.random.normal(50, 10, time_steps), # имитировать влажностьданные
'wind_speed': np.random.normal(10, 2, time_steps), # Имитация скорости ветра
'power_consumption': np.random.normal(200, 50, time_steps) # Имитировать энергопотреблениеданные
}
# CreateDataFrame
df = pd.DataFrame(data)
# Сохранить как файл CSV
df.to_csv('multi_feature_time_series.csv', index=False)
print("Набор данных моделирования был сохранен как multi_feature_time_series.csv")
2. Подготовка и предварительная обработка данных
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# нагрузкаданные
data = pd.read_csv('multi_feature_time_series.csv')
# исследоватьданные
print(data.head())
# Обработка пропущенных значений (если есть)
data = data.dropna()
# нормализацияданные
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
# Создание входных объектов и целевых переменных.
def create_dataset(dataset, time_step=1):
dataX, dataY = [], []
for i in range(len(dataset) - time_step - 1):
a = dataset[i:(i + time_step), :]
dataX.append(a)
dataY.append(dataset[i + time_step, -1]) # Предположим, что целевая переменная — это последний столбец.
return np.array(dataX), np.array(dataY)
time_step = 10
X, y = create_dataset(scaled_data, time_step)
# Разделите данные на обучающий набор и тестовый набор.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Проверьте форму
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
3. Создайте и обучите модель LSTM.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# Здание LSTMМодель
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, X_train.shape[2])))
model.add(LSTM(50, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
# Скомпилировать модель
model.compile(optimizer='adam', loss='mean_squared_error')
# Модель обучения
history = model.fit(X_train, y_train, epochs=100, batch_size=64, validation_data=(X_test, y_test), verbose=1)
# Предварительный просмотр тренировочного процесса
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
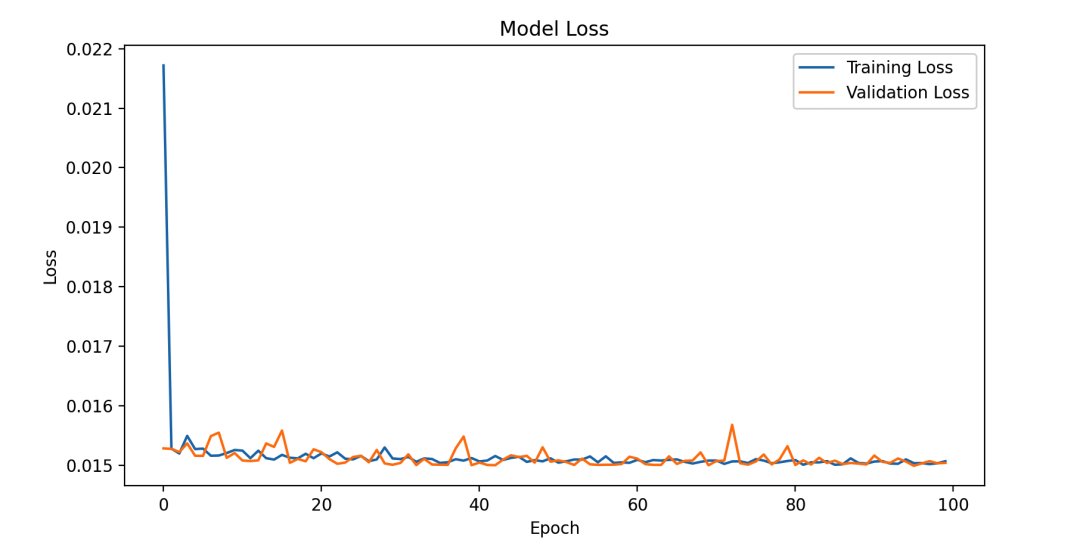
4. Оценка модели и прогнозирование
# Модель оценки
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# денормализованное прогнозируемое значение
train_predict = scaler.inverse_transform(np.concatenate((np.zeros((train_predict.shape[0], scaled_data.shape[1]-1)), train_predict), axis=1))[:, -1]
test_predict = scaler.inverse_transform(np.concatenate((np.zeros((test_predict.shape[0], scaled_data.shape[1]-1)), test_predict), axis=1))[:, -1]
# денормализованное фактическое значение
y_train_actual = scaler.inverse_transform(np.concatenate((np.zeros((y_train.shape[0], scaled_data.shape[1]-1)), y_train.reshape(-1, 1)), axis=1))[:, -1]
y_test_actual = scaler.inverse_transform(np.concatenate((np.zeros((y_test.shape[0], scaled_data.shape[1]-1)), y_test.reshape(-1, 1)), axis=1))[:, -1]
# Предварительный просмотр результатов прогноза
plt.figure(figsize=(14, 5))
plt.plot(y_test_actual, color='blue', label='Actual Value')
plt.plot(test_predict, color='red', label='Predicted Value')
plt.title('Actual vs Predicted')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()
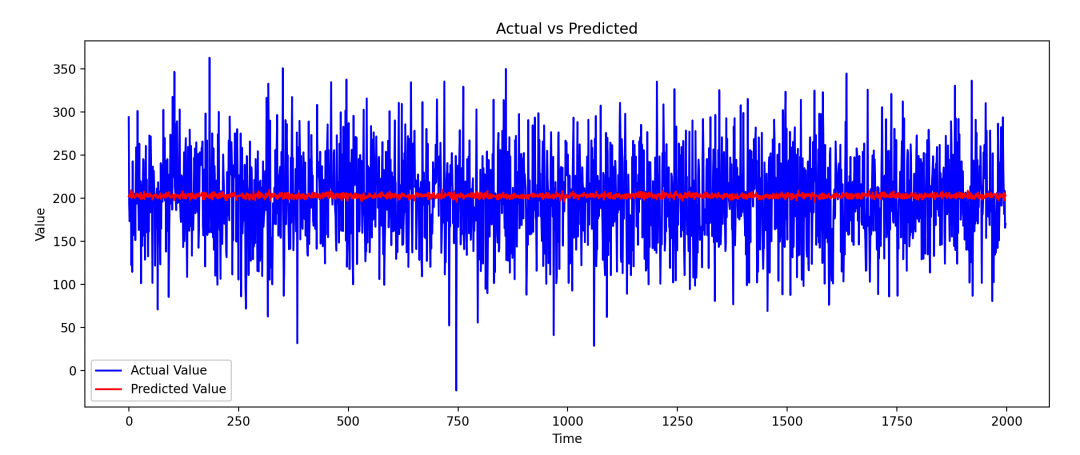
Подвести итог
проходить Создайте набор данных моделирования и сохраните его в виде файла CSV.,Мы можем использовать описанные выше шаги для завершения построения и обучения многофункциональной модели прогнозирования переменных временных рядов на основе LSTM. Модель способна эффективно обрабатывать и прогнозировать данные многомерных временных рядов.,И может быть применен к различным практическим сценариям.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
