Используйте Docker и Diffusers, чтобы быстро начать работу с большой моделью видео Stable Video Diffusion Tusheng.
В этой статье рассказывается о том, как быстро начать работу. Stable Video Diffusion (SVD) Видеомодель Тушэна.
напиши впереди
В конце месяца мы планируем поделиться практической информацией по использованию модели с открытым исходным кодом «Stable Diffusion Model» для создания интересных видеороликов на «Форуме AI Technology Forum» Machine Heart.
Поскольку время участия в конференции, как и прежде, ограничено, более простые части будут дополняться и распространяться в виде сообщений в блогах.
Эта статья представляет собой сопутствующий дополнительный контент, в основном рассказывающий о том, как быстро начать работу со Stable Video Diffusion, созданным с помощью отраслевого эталонного теста с открытым исходным кодом Stability.ai.
Код, связанный с этой статьей, сохранен в soulteary/docker-stable-video-diffusion[1],Вы можете забрать его при необходимости,Добро пожаловать в «Один клик, три соединения».
Stable Video Diffusion
2023 Год 11 Конец месяца, Stability.ai Опубликовано Stable Video Diffusion[2],Модель все еще распространяется,Но технология изображения распространилась и на видео. Возможность использовать статичные изображения в качестве рамки условий.,и на Основано на создании видео. если ты прав Stable Diffusion упражнятьсяи Заинтересованы в анализе основных компонентов программного обеспечения с открытым исходным кодом.,Может двигатьсяПредыдущий похожий контент для совместного использования[3]。
Подробности модели,мыОфициальная страница пресс-релиза[4]способен найти,Я не буду вдаваться в подробности. Метод модельиспользовать аналогичен предыдущей картине Винсента. Stable Диффузия по-прежнему представляет собой простой трехэтапный метод использования: «Ввод содержимого», «Ожидание обработки и генерации модели», «Получение ИИ». Генерировать результаты».
Таким образом, теперь мы можем использовать модель с открытым исходным кодом для относительно быстрого создания короткого видео с очень релевантным контентом с использованием изображения.
Есть две связанные модели с официально открытым исходным кодом. Одна из них — базовая версия, которая может генерировать. 14 рамка 1024x576 Базовая модель для контента с разрешением stabilityai/stable-video-diffusion-img2vid[5],Другойна основе База Модель выполнена finetune полученный “XT” Модель:stabilityai/stable-video-diffusion-img2vid-xt[6],Он способен выдавать такое же разрешение 25 рамку контента. С помощью AutoencoderKL[7](В официальной документации это называется F8 декодер) и пара VAE модель точная настройка дополнительно улучшает качество и согласованность видеоконтента, а также уменьшает проблему мерцания экрана.
В официальном представлении эффект генерации на момент выпуска модели был более популярен среди пользователей, чем GEN-2 и PikaLabs.
Конечно, эта модель еще относительно ранняя и имеет некоторые очевидные недостатки:
• В настоящее время используется напрямую SVD Создаваемые видеоролики короткие, обычно не более 5 Всего несколько секунд, и временно невозможно добиться реалистичности изображения на фотоуровне. • Добиться результатов и как можно раньше Stable Diffusion Точно так же он относительно неуправляем и может производить выстрел без движения или с особенно медленной частотой движений, которая сильно отклоняется от ожидаемого расстояния. •Временно невозможно вмешиваться в генерацию видео посредством текстового управления. •В настоящее время отображение открытого текстового содержимого невозможно. •Контент с людьми, особенно лица, часто обрабатывается неправильно. •модель clip_vision_model Кодер потеряет некоторую информацию при анализе содержимого изображения.
конечно,Решение вышеперечисленных проблем – лишь вопрос времени.,Модель с открытым исходным кодом развивается очень быстро,Так что ты можешь сначала забрать этот билет.,Давайте отправимся в плавание вместе.
Базовая подготовка среды
Лично я предпочитаю использовать Docker в качестве рабочей среды. При небольших вложениях дополнительных ресурсов я могу быстро получить чистую, воспроизводимую и согласованную среду.
если ты выберешь Docker маршрут,Имеет ли ваше устройство видеокарту или нет,Вы можете настроить его в соответствии с предпочтениями вашей операционной системы.,Пожалуйста, обратитесь к этим двум статьям, чтобы завершить База Конфигурация среды《на основе Docker Среда глубокого обучения: Windows Глава[8]》、《на основе Docker Среда глубокого обучения: введение [9]》。конечно,использовать Docker после,Есть много вещей, которые вы можете сделать,например:Десятки предыдущих статей, связанных с Docker Практика[10],Я не буду здесь вдаваться в подробности о Ла.
кроме,Для эффективности Запустите модель,Я рекомендуюиспользовать Nvidia официальный контейнерзеркало(nvcr.io/nvidia/pytorch:23.12-py3[11]),а также HuggingFace произведено Diffusers набор инструментов.
На основе приведенного выше содержания мы можем быстро создать чистую и эффективную базовую операционную среду:
FROM nvcr.io/nvidia/pytorch:23.12-py3
RUN pip install transformers==4.35.2 gradio==4.13.0 diffusers==0.25.0 accelerate==0.25.0
RUN pip install opencv-fixer==0.2.5
RUN python -c "from opencv_fixer import AutoFix; AutoFix()"
WORKDIR /appСоздайте локальный файл с именем docker каталог, сохраните приведенный выше код в папке, имя файла Dockerfile,Затем используйте следующую команду, чтобы завершить создание зеркала.,База Работа наполовину готова:
docker build -t soulteary/svd-runtime -f docker/Dockerfile .Конечно, если вы похожи на меня и любите «лениться», вы можете начать работать непосредственно с файлами в примере проекта, упомянутом в начале текста:
# Скачать код проекта
git clone https://github.com/soulteary/docker-stable-video-diffusion.git
# Переключить рабочий каталог
cd docker-stable-video-diffusion
# Создание базы окружающей средызеркало
docker build -t soulteary/svd-runtime -f docker/Dockerfile .
# Если вы хотите, чтобы это было быстрее, вы можете использовать эту команду вместо приведенной выше команды.
docker build -t soulteary/svd-runtime -f docker/Dockerfile.cn .После того, как изображение построено, мы приступаем к подготовке файла модели.
Исправлена проблема с зависимостью OpenCV в образах Nvidia.
Если вы внимательно посмотрите на содержимое файла подготовки образа Docker выше, вы обнаружите следующие две строки:
RUN pip install opencv-fixer==0.2.5
RUN python -c "from opencv_fixer import AutoFix; AutoFix()"Эти две команды могут решить проблему из 2023 Год 6 месяц начался Nvidia Официальная адаптация изображения Stable Diffusion Video Сопутствующие модели, используемые Diffusers ждать HuggingFace Когда инструмент сохраняет видеофайлы, по сути, он module 'cv2.dnn' has no attribute 'DictValue' Связанные проблемы с отчетами об ошибках.
Об этой проблеме сообщалось ранее в сообществе.(opencv/opencv-python #884[12]),Основная причина – установка numpy Версия, которую принесли для установки, была слишком старой. opencv вызывая проблемы совместимости. Сравнивать Trick Что не так, так это то, что мы не можем просто выполнить pip install Чтобы обновить пакет программного обеспечения, вам необходимо следовать сообщению и выполнить ручную очистку и установку, чтобы решить проблему.
так,Я написал простой гаджет с открытым исходным кодом,Этот вопрос возникает из-за автоматического исправления,Адрес открытого исходного кода проекта::soulteary/opencv-fixer[13],Если вы столкнулись с подобными проблемами в других моделях, связанных с использованием,Вы можете попробовать.
Скачать модель
Завершаем подготовку зеркала 50% подготовительные работы, Скачать модель. Независимо от того, где вы получили Модель, рекомендуется подать файл после получения Модели. Hash проверять:
shasum svd_xt.safetensors
a74f28bca18f1814b1447c391450b7f720b3b97e
shasum svd_xt_image_decoder.safetensors 1d6f36c441df4a17005167986b12720db1b118f2Вы можете в зависимости от реальных условий сети,Приходи и выбирайот HuggingFace Скачать модель[14]все ещеот ModelScope Приходить Скачать модель[15],если ты выберешьда Model Scope, не забудьте скачать модель с HuggingFace Обновите содержимое хранилища, за исключением двух файлов модели большого размера.
О модели быстрая загрузка,Я много раз об этом упоминал в предыдущих статьях,если ты выберешьиспользовать HuggingFace Приходить Скачать модели содержат последние программные файлы репозитория:
# Установить инструмент загрузки
pip install huggingface-cli
# Качаем то, что нам нужно Модель
huggingface-cli download --resume-download --local-dir-use-symlinks False stabilityai/stable-video-diffusion-img2vid-xt --local-dir ./models/Если у вас возникли проблемы при доступе к Интернету, вы можете использовать изображение ускорения, предоставленное пользователями сети:
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download --resume-download --local-dir-use-symlinks False stabilityai/stable-video-diffusion-img2vid-xt --local-dir ./models/Или воспользуйтесь новой версией официального инструмента для более быстрой загрузки:
HF_ENDPOINT=https://hf-mirror.com HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download --resume-download --local-dir-use-symlinks False stabilityai/stable-video-diffusion-img2vid-xt --local-dir ./models/если ты выберешьиспользовать ModelScope также относительно прост, но следует отметить, что ModelScope Часто содержимое в HuggingFace Содержимое на нем старое, поэтому после скачивания рекомендуется проверить, нужно ли вам его использовать. HuggingFace Обновите и замените содержимое выше:
# Загрузите и установите инструменты
pip install modelscope
# Скачать модель
from modelscope import snapshot_download
snapshot_download('AI-ModelScope/stable-video-diffusion-img2vid-xt', cache_dir="./models/")После загрузки модели мы можем организовать структуру каталогов и сохранить загруженную модель в каталоге Models:
├── docker
│ ├── Dockerfile
│ └── Dockerfile.cn
├── models
│ └── stabilityai
│ └── stable-video-diffusion-img2vid-xt
└── webНапишите программу вывода модели
полная программаФайл здесь[16],Подсчитайте пробелы и красивые переносы строк,Вероятно, меньше, чем 150 Хорошо, позвольте мне сделать некоторые упрощения, в основном объясняя процесс работы программы:
# Введение нескольких зависимостей
import gradio as gr
from diffusers import StableVideoDiffusionPipeline
from diffusers.utils import export_to_video
from PIL import Image
# ... опустить другие ссылки
# Чтобы было веселее, увеличьте диапазон случайных чисел.
max_64_bit_int = 2 ** 63 - 1
# ... Опустить другие подготовительные работы
# использовать diffusers создать AI Pipeline
pipe = StableVideoDiffusionPipeline.from_pretrained(
"/app/models/stabilityai/stable-video-diffusion-img2vid-xt",
torch_dtype=torch.float16,
variant="fp16",
)
pipe.to("cuda")
# нагрузка UNET и VAE Модель, чтобы улучшить генерируемые результаты (о том, что делают эти две Модели, предыдущая Stable Diffusion Статья расширена, поэтому не буду вдаваться в подробности.
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
pipe.vae = torch.compile(pipe.vae, mode="reduce-overhead", fullgraph=True)
# Основная логика генерации видео
def sample(
image: Image,
seed: Optional[int] = 42,
randomize_seed: bool = True,
motion_bucket_id: int = 127,
fps_id: int = 6,
version: str = "svd_xt",
cond_aug: float = 0.02,
decoding_t: int = 3, # Настройте его в соответствии с емкостью вашей видеокарты. Если у вас мало видеопамяти, вы можете настроить ее. 1
device: str = "cuda",
output_folder: str = output_folder,
):
# ... Пропустить некоторые подготовительные работы
# вызов AI Pipeline генерироватьвидеорамкасодержание frames = pipe(
image,
decode_chunk_size=decoding_t,
generator=torch.manual_seed(seed),
motion_bucket_id=motion_bucket_id,
noise_aug_strength=0.1,
num_frames=25,).frames[0]
# держатьвидео export_to_video(frames, video_path, fps=fps_id)
return video_path, seed
# Отрегулируйте размер загружаемого изображения. Модель предъявляет требования к размеру обрабатываемых изображений.
def resize_image(image: Image, output_size: Tuple[int, int] =(1024, 576)):
# ...Опустить некоторую логику настройки изображения, режим изображения, обрезку размера, подождать
return cropped_image
# Используется для подключения видеогенераторов Gradio «Инструментарий» интерфейса
def generate(image, seed, randomize_seed, motion_bucket_id, fps_id):
img = resize_image(image, output_size=(1024, 576))
video, seed = sample(img, seed, randomize_seed, motion_bucket_id, fps_id)
return video, seed
# Настройте Gradio веб-интерфейс
app = gr.Interface(
fn=generate,
inputs=[
gr.Image(label="Upload your image", type="pil"),
gr.Slider(label="Seed", ...),
gr.Checkbox(label="Randomize seed", value=True),
gr.Slider(label="Motion bucket id", ...),
gr.Slider(label="Frames per second", ...),
],
outputs=[
gr.PlayableVideo(label="Generated video"),
gr.Textbox(label="Seed", type="text"),
],
)
# Запустите сервис и разрешите нам играть
if __name__ == "__main__":
app.queue(max_size=2)
app.launch(share=False, server_name="0.0.0.0", ssl_verify=False)После подготовки программы мы помещаем программу в корень каталога и тогда мы готовы запускать и играть.
├── app.py
├── docker
│ ├── Dockerfile
│ └── Dockerfile.cn
└── models
└── stabilityai
└── stable-video-diffusion-img2vid-xtЗапустите модель
из-за использования Docker ,Итак, запустите модель очень просто.,Просто выполните следующую команду:
docker run --rm -it -p 7860:7860 -p 7680:7680 -p 8080:8080 --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`:/app soulteary/svd-runtime python app.pyКогда команда будет выполнена, мы увидим журнал, подобный следующему:
=============
== PyTorch ==
=============
NVIDIA Release 23.12 (build 76438008)
PyTorch Version 2.2.0a0+81ea7a4
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
WARNING: CUDA Minor Version Compatibility mode ENABLED.
Using driver version 525.147.05 which has support for CUDA 12.0. This container
was built with CUDA 12.3 and will be run in Minor Version Compatibility mode.
CUDA Forward Compatibility is preferred over Minor Version Compatibility for use
with this container but was unavailable:
[[Forward compatibility was attempted on non supported HW (CUDA_ERROR_COMPAT_NOT_SUPPORTED_ON_DEVICE) cuInit()=804]]
See https://docs.nvidia.com/deploy/cuda-compatibility/ for details.
The cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a one-time only operation. You can interrupt this and resume the migration later on by calling `transformers.utils.move_cache()`.
0it [00:00, ?it/s]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 12.41it/s]
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.Затем мы можем начать испытывать и проверять SVD, получив доступ к IP: 7860 хоста контейнера, на котором работает контейнер, в браузере.
Браузер открывает интерфейс приложения по умолчанию.
На момент написания этой статьи новая версия Chrome имеет некоторые проблемы с совместимостью с Gradio. Она может только загружать видео, но не может автоматически воспроизводить видео на веб-странице, поэтому, если у вас есть другие браузеры, вы можете попробовать использовать другие браузеры. создавать видео с искусственным интеллектом. Здесь я использую Safari.
После открытия страницы,Мы можем выбрать картинку, которая нам интересна, и создать ее.,Я выбрал ракету, которую запускают。здесь Я рекомендую Изменить параметрырамка Ставка подтянута к 25 кадр, чтобы получить шелковистые результаты видео и подтянуть как можно больше видео “motion” чтобы улучшить результаты видео.
Загрузить изображения в WebUI
когда мы Загрузить изображения в WebUI После этого нажмите «Подай», дай «запуск ракеты». При первом выполнении это займет много времени и может занять 1~3 минут, программа автоматически загрузит соответствующие SVD、UNET、VAE Затем модель преобразует указанное нами изображение в видео.
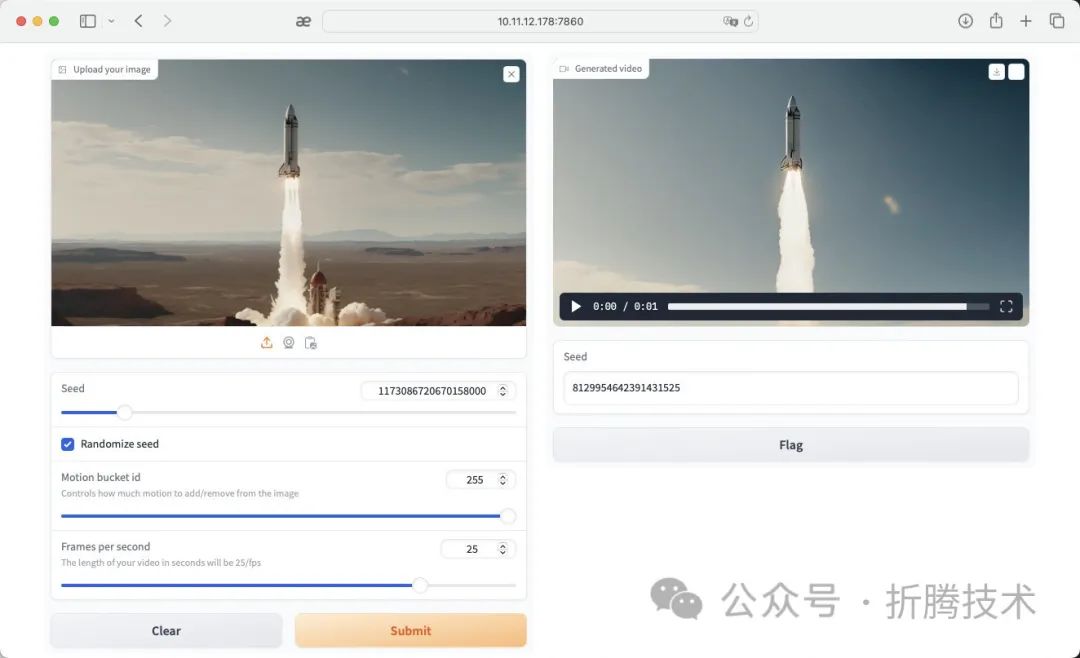
После ожидания генерируется видео.
ждать После обработки модели мы заставляем ракету продолжать полет вверх.

По умолчанию модель потребляет ресурсы
Без оптимизации по умолчанию будем использовать видеопамять 23G+.
Если вы хотите завершить генерацию видеовывода в среде небольшой памяти, вы можете удалить комментарии в исходном коде проекта, который я предоставил, в соответствии с вашими потребностями:
# According to your actual needs
#
# pipe.enable_model_cpu_offload()
# pipe.unet.enable_forward_chunking()при включении pipe.enable_model_cpu_offload() Наконец, потребность в видеопамяти можно контролировать в пределах 8GB Разумеется, время генерации видео также станет очень медленным.
Во время реальной работы основное состояние видеокарты следующее:
Every 1.0s: nvidia-smi LEGION-REN9000K-34IRZ: Sun Jan 8 14:48:34 2024
Sun Jan 8 14:48:34 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 41% 51C P2 71W / 450W | 23200MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1497 G /usr/lib/xorg/Xorg 75MiB |
| 0 N/A N/A 1606 G /usr/bin/gnome-shell 16MiB |
| 0 N/A N/A 5880 C python 23104MiB |
+-----------------------------------------------------------------------------+наконец
На этом статья заканчивается. В процессе подготовки к публикации контента я продолжу делиться интересным контентом, связанным с SD. Увидимся в следующей статье.
--EOF
Справочная ссылка
[1] soulteary/docker-stable-video-diffusion: https://github.com/soulteary/docker-stable-video-diffusion
[2] Stable Video Diffusion: https://stability.ai/stable-video
[3] Ранее опубликованный контент: https://soulteary.com/tags/stable-diffusion.html
[4] Официальная страница пресс-релиза: https://stability.ai/news/stable-video-diffusion-open-ai-video-model
[5] stabilityai/stable-video-diffusion-img2vid: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
[6] stabilityai/stable-video-diffusion-img2vid-xt: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
[7] AutoencoderKL: https://huggingface.co/docs/diffusers/api/models/autoencoderkl#loading-from-the-original-format
[8] на основе Docker Среда глубокого обучения: Windows Глава: https://soulteary.com/2023/07/29/docker-based-deep-learning-environment-under-windows.html
[9] на основе Docker Среда глубокого обучения: начало работы https://soulteary.com/2023/03/22/docker-based-deep-learning-environment-getting-started.html
[10] Десятки предыдущих статей, связанных с Docker Упражняться: https://soulteary.com/tags/docker.html
[11] nvcr.io/nvidia/pytorch:23.12-py3: https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-23-12.html
[12] opencv/opencv-python #884: https://github.com/opencv/opencv-python/issues/884
[13] soulteary/opencv-fixer: https://github.com/soulteary/opencv-fixer
[14] от HuggingFace Скачать модель: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
[15] от ModelScope Приходить Скачать модель: https://modelscope.cn/models/AI-ModelScope/stable-video-diffusion-img2vid-xt/files
[16] Файлы находятся здесь: https://github.com/soulteary/docker-stable-video-diffusion/blob/main/app.py
[17] Новым друзьям: голосуйте за жизнь и продолжайте искать лучших друзей: https://zhuanlan.zhihu.com/p/557928933
[18] По поводу объединения людей в группы: https://zhuanlan.zhihu.com/p/56159997



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
