Использование Python для анализа текста и обработки естественного языка: от основ к практике
С ростом объема данных интеллектуальный анализ текста и обработка естественного языка (НЛП) становятся все более важными. Python, как гибкий и мощный язык программирования, играет жизненно важную роль в этой области. В этой статье рассказывается, как использовать Python для анализа текста и обработки естественного языка, включая базовые концепции, часто используемые библиотеки и практические примеры кода.
1. Основные понятия интеллектуального анализа текста
Интеллектуальный анализ текста — это процесс извлечения полезной информации из крупномасштабных текстовых данных. Он охватывает такие задачи, как классификация текста, извлечение информации и анализ настроений. В Python широко используемые технологии интеллектуального анализа текста включают статистику частоты слов, тегирование частей речи, распознавание объектов и т. д.
2. Основные понятия обработки естественного языка
Обработка естественного языка — важная отрасль информатики и искусственного интеллекта, цель которой — дать возможность компьютерам понимать, обрабатывать и генерировать человеческий язык. Общие задачи обработки естественного языка включают сегментацию слов, маркировку частей речи, распознавание именованных объектов, синтаксический анализ и т. д.
3. Библиотеки интеллектуального анализа текста и обработки естественного языка в Python
Python имеет богатую библиотеку библиотек для анализа текста и обработки естественного языка, наиболее популярные из которых включают:
- NLTK(Natural Language Toolkit):NLTKдаPythonБиблиотека обработки естественного языка для,Предоставляет разнообразные инструменты и ресурсы.,В том числе причастия, тегирование части речи、Синтаксический анализ и т.д.
- spaCy:spaCyда Еще одна популярная библиотека обработки естественного языка.,Он обеспечивает эффективноетекстинструменты обработки,включить причастие、Распознавание названного объекта、тегирование части речиждать。
- gensim:gensimда Библиотека для тематического моделирования и расчета сходства документов.,Обычно используетсятекст Тематический анализ и кластеризация документов в майнинге。
- scikit-learn:Хотя в основном используется для машинного обучения,ноscikit-learnМногие из них также предусмотренытекст Инструменты и алгоритмы майнинга,нравитьсятекст Классификация、тексткластеризацияждать。
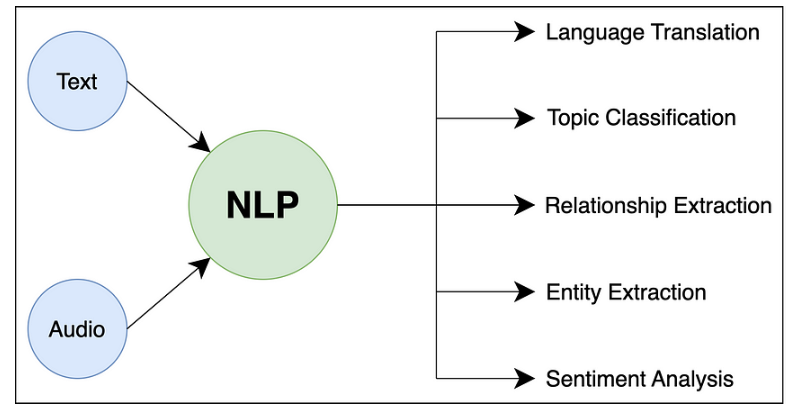
4. Реальные примеры кода
Далее мы воспользуемся библиотекой NLTK для выполнения простого примера интеллектуального анализа текста: анализа настроений.
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# Инициализировать анализатор настроений
sid = SentimentIntensityAnalyzer()
# текст
text = "NLTK is a great tool for natural language processing."
# Провести анализ настроений
scores = sid.polarity_scores(text)
# Вывод результатов
print("Результаты анализа настроений:", scores)Приведенный выше код использует анализатор тональности VADER в библиотеке NLTK для анализа тональности текста. Текущие результаты дадут оценку анализа настроений текста, включая положительные, отрицательные и нейтральные степени.
5. Передовые технологии интеллектуального анализа текста и обработки естественного языка.
Помимо базовых методов анализа текста и обработки естественного языка, существует множество продвинутых методов, которые могут еще больше повысить эффективность и точность обработки текста.
- Вложения слов:встраивание словда Методы отображения слов в низкоразмерные векторные пространства,Умение улавливать смысловые связи между словами. Обычно используемые модели встраивания слов включают Word2Vec, GloVe и т. д.,Библиотеку gensim можно использовать для обучения и применения.
- модель глубокого обучения:Глубокое обучение добилось больших успехов в обработке естественного языка.,нравиться Используйте сверточные нейронные сети(CNN)и рекуррентная нейронная сеть(RNN)руководитьтекст Классификация、Распознавание названного объектаждать Задача,А также использование модели Transformer для таких задач, как машинный перевод. Обычно используемые платформы глубокого обучения включают TensorFlow и PyTorch.
- трансферное обучение:трансферное обучение Используйте уже обученные модели для решения проблем в новых областях,Возможность достижения более высокой производительности с меньшими объемами данных. Например,Можно использовать предварительно обученные языковые модели.(нравитьсяBERT、GPT)руководитьтекст Классификация、текстгенерироватьждать Задача。
6. Практический пример: классификация текста
Далее мы воспользуемся библиотекой scikit-learn, чтобы выполнить простой пример классификации текста: классифицировать текст новостей по различным категориям.
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
# Загрузить набор данных
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
train_data = fetch_20newsgroups(subset='train', categories=categories)
test_data = fetch_20newsgroups(subset='test', categories=categories)
# Создайте классификатор
text_clf = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', LinearSVC()),
])
# Модель обучения
text_clf.fit(train_data.data, train_data.target)
# Прогнозирование и оценка моделей
predicted = text_clf.predict(test_data.data)
print("Отчет о классификации:")
print(classification_report(test_data.target, predicted, target_names=test_data.target_names))Приведенный выше код использует машину опорных векторов (SVM) в качестве классификатора и обучается на основе функций TF-IDF. По результатам работы будет выведен отчет об оценке классификатора, включая точность, полноту, значение F1 и другие показатели.
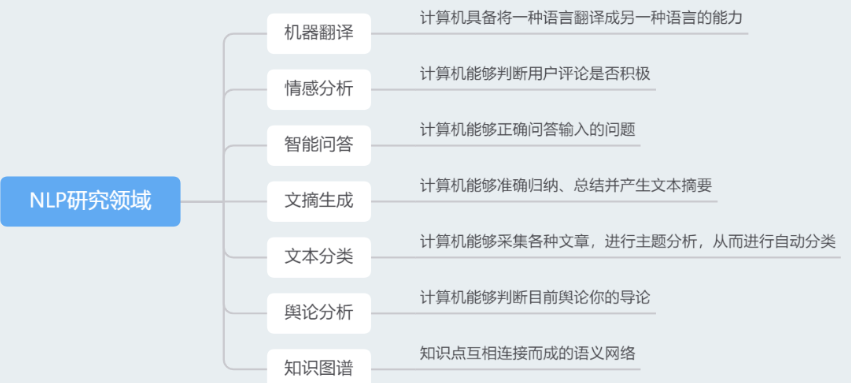
7. Перспективы на будущее
Область анализа текста и обработки естественного языка находится на стадии быстрого развития, и в будущем нас ждет множество проблем и возможностей.
- многоязычная обработка:Поскольку процесс глобализации ускоряется,многоязычная обработкастать важным направлением исследований。Будущие технологии будут уделять больше внимания межъязыковому взаимодействию.текст Возможности майнинга и обработки естественного языка,Обеспечьте плавное взаимодействие между различными языками.
- Кроссмодальная обработка данных:С изображениями、видеождать Появление неструктурированных данных,Кроссмодальная обработка данныхстать новой горячей точкой исследований。Будущие технологии будут уделять больше вниманиятекст Данные в сочетании с другими типами данныхруководитьобработка и анализ,Это обеспечивает более богатое извлечение информации и семантическое понимание.
- Персонализированный и интеллектуальный:будущеетекст Технологии обработки будут все больше Персонализированный и интеллектуальный,Возможность предоставления индивидуальных услуг на основе предпочтений и потребностей пользователей. Например,Выдавайте интеллектуальные рекомендации, интеллектуальные вопросы и ответы и т. д. на основе исторических данных пользователя и контекстной информации.
- Конфиденциальность и безопасность:вместе стекст Постоянный рост данных,Проблема Конфиденциальности и безопасности также становится все более заметной. Будущие технологии будут уделять больше внимания защите конфиденциальности пользователей и безопасности данных.,Для обеспечения безопасности и достоверности данных используются различные технологии шифрования и защиты конфиденциальности.
Заключение
Интеллектуальный анализ текста и обработка естественного языка, как важные отрасли в области искусственного интеллекта, развиваются с беспрецедентной скоростью. Python, как мощный и гибкий язык программирования, играет жизненно важную роль в этой области. Благодаря постоянному обучению и практике мы сможем лучше использовать Python для обработки и анализа текстовых данных, тем самым обнаруживая полезную информацию и внедряя различные интеллектуальные приложения и сервисы. Я надеюсь, что эта статья поможет читателям лучше понять и применить технологию Python в области обработки текста, а также заложить основу для будущих исследований и приложений.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
