Использование преимуществ искусственного интеллекта: от текста к звуку для изучения технологического прогресса и применения современного синтеза речи
Достижения в технологии синтеза речи и ее применение в AIGC
введение
Технология синтеза речи (Text-to-Speech, TTS) является важным компонентом контента, генерируемого искусственным интеллектом (AIGC). С развитием моделей глубокого обучения технология TTS добилась значительного прогресса, и генерируемая ею речь становится все ближе и ближе к выражениям естественного языка человека. В этой статье будет обсуждаться история развития технологии синтеза речи и ее применения в AIGC, а также приводятся соответствующие примеры кода для углубления понимания.
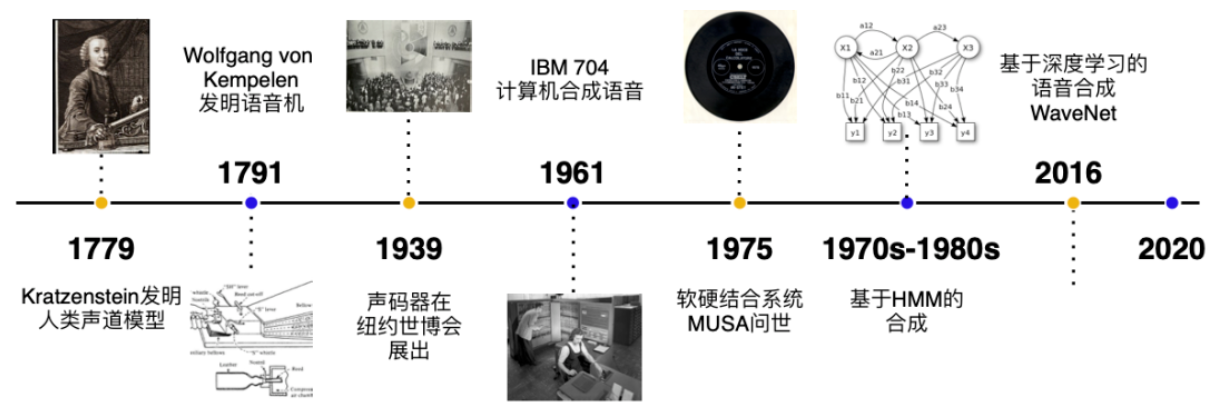
Достижения в технологии синтеза речи
1. Синтез речи на основе правил
Ранняя технология синтеза речи использовала модели, основанные на правилах, которые преобразуют текст в речь с помощью заранее определенных лингвистических правил. Однако речь, создаваемая этим методом, часто бывает неестественной, лишенной беглости и эмоциональной выразительности.
2. Синтез статистических параметров
Позже методы синтеза статистических параметров (такие как скрытые модели Маркова, HMM) постепенно заменили синтез на основе правил. В этом типе подхода используются статистические модели для генерации параметров речи и управления генерацией речи с помощью этих параметров. Однако, хотя эффект генерации улучшился по сравнению с более ранними технологиями, ощущение синтеза все еще сохраняется.
3. Синтез речи на основе глубокого обучения
В последние годы, с развитием глубокого обучения, синтез речи на основе нейронных сетей (таких как WaveNet, Tacotron, FastSpeech и т. д.) совершил огромный прорыв. Нейронная сеть может автоматически изучать сложные звуковые шаблоны и генерировать более естественную и эмоционально выразительную речь.
- WaveNet: Модель WaveNet, предложенная Google, представляет генеративную нейронную сеть, которая может напрямую генерировать исходные данные формы сигнала, а качество сгенерированной речи очень близко к реальной речи.
- Tacotron: Tacotron — это комплексная система TTS, которая может генерировать речь непосредственно из текста без необходимости традиционных этапов извлечения признаков.
- FastSpeech: FastSpeech повышает скорость и стабильность генерации речи за счет введения неавторегрессивной структуры.

Применение технологии синтеза речи в AIGC
AIGC в основном включает в себя генерацию текста, изображений, видео и другого контента, а технология синтеза речи, как важная ее часть, значительно расширила форму генерируемого контента. Ниже приведены несколько сценариев применения технологии синтеза речи в AIGC.
1. Виртуальный человеческий якорь
Виртуальные человеческие якоря используют технологию TTS для имитации голоса и эмоциональных выражений человеческих якорей. В AIGC виртуальные ведущие могут обеспечить зрителям более захватывающий опыт, генерируя естественные голоса.
2. Автоматизированное обслуживание клиентов.
Автоматизированная система обслуживания клиентов, основанная на синтезе речи, может взаимодействовать с пользователями, генерируя речь на естественном языке, заменяя ручное обслуживание клиентов и обеспечивая эффективное обслуживание клиентов.
3. Игровые и развлекательные площадки
В играх технология TTS позволяет дублировать виртуальных персонажей и создавать персонализированные интерактивные диалоги. В контенте, созданном AIGC, синтез речи также может обеспечивать аудиоподдержку автоматически создаваемых видео или сюжетных линий.
Пример кода: генерация речи с помощью Tacotron 2
В приведенном ниже примере кода показано, как использовать модель Tacotron 2 для преобразования текста в речь.
Экологическая подготовка
Сначала установите необходимые библиотеки и модели.
pip install transformers
pip install torchaudioЗагрузите модель и сгенерируйте речь
Следующий код демонстрирует, как использовать Hugging Лицо transformers Загрузка библиотеки Tacotron 2 и преобразуйте входной текст в речь.
import torch
from transformers import Tacotron2ForConditionalGeneration, Tacotron2Tokenizer
import torchaudio
# Загрузите предварительно обученную модель и токенизатор
tokenizer = Tacotron2Tokenizer.from_pretrained("tacotron2")
model = Tacotron2ForConditionalGeneration.from_pretrained("tacotron2")
# Введите текст
text = "Hello, welcome to the future of AI-generated speech."
# Преобразование текста в токен
inputs = tokenizer(text, return_tensors="pt")
# Генерация речевых функций
with torch.no_grad():
outputs = model.generate(**inputs)
# Преобразование сгенерированных речевых характеристик в аудио
mel_spectrogram = outputs[0]
waveform = torchaudio.transforms.MelSpectrogram()(mel_spectrogram.squeeze(0))
# Сохранить аудиофайл
torchaudio.save("output.wav", waveform, 22050)Анализ кода
- Загрузка модели: Используйте объятия Лицо
transformersЗагрузка библиотеки Tacotron 2 Предварительно обученная модель и соответствующий токенизатор. - Ввод и обработка текста: Преобразуйте входной текст в формат токена, понятный модели.
- Генерация речевых функций: Используйте модель для генерации соответствующих речевых характеристик, и на выходе будет Мел. Карта объектов в форме спектрограммы.
- Генерация и хранение звука: Мел будет сгенерирован SpectrogramПреобразование в звуковой сигнал,и сохранить как
.wavдокумент。
эффект генерации речи
После запуска приведенного выше кода сгенерированный речевой файл будет имитировать естественное речевое выражение входного текста. Здесь показано, как использовать модели глубокого обучения для достижения высококачественного синтеза речи.
Будущее развитие и проблемы
Хотя технология синтеза речи достигла значительного прогресса, все еще существуют некоторые проблемы, которые необходимо решить.
1. Разнообразие речевого порождения
Хотя текущая модель TTS может генерировать высококачественную речь, у нее все еще есть недостатки в создании разнообразной и персонализированной речи. Будущий синтез речи должен еще больше улучшить гибкость модели и иметь возможность генерировать речь с разными эмоциями и интонациями.
2. Интеграция голоса и видения
С развитием AIGC контент, создаваемый в будущем, не будет ограничиваться одной формой текста, голоса или изображения, а будет интегрировать множество медиа. Следующее направление исследований — как объединить синтез речи с другими технологиями генерации, такими как генерация видео, виртуальная реальность и т. д.
3. Генерация в реальном времени и эффективность вычислений
Существующие модели TTS требуют больших вычислительных затрат при генерации высококачественной речи. Как улучшить производительность в реальном времени, обеспечив при этом качество генерации, является важным направлением развития технологии синтеза речи в будущем.
Эмоциональный синтез и персонализация
Современная технология синтеза речи не только совершила прорыв в создании естественной речи.,Прогресс также был достигнут в генерации звуков речи. через модели глубокого обучения,Эмоциональные проявления порожденной речи становятся более разнообразными. Например,Такие модели, как Tacotron и WaveNet, оптимизированы для генерации различных эмоциональных состояний.,такой же счастливый、грустный、Возбуждён и т. д.
Эмоциональная регуляция Такотрона
Улучшенные версии модели Tacotron могут генерировать речь с эмоциональными характеристиками за счет введения дополнительных параметров кодирования эмоций или управления. Ниже приведен пример кода синтеза эмоциональной речи, показывающий, как генерировать речь в различных эмоциональных состояниях путем настройки параметров.
Пример кода: синтез эмоций
import torch
from transformers import Tacotron2ForConditionalGeneration, Tacotron2Tokenizer
# Загрузить модель и токенизатор
tokenizer = Tacotron2Tokenizer.from_pretrained("tacotron2")
model = Tacotron2ForConditionalGeneration.from_pretrained("tacotron2")
# Введите текст
text = "I'm so happy to see you!"
# Преобразование текста в токен
inputs = tokenizer(text, return_tensors="pt")
# Добавьте эмоциональную кодировку (Предполагая, что модель поддерживает регулирование эмоцийпараметр)
emotion_code = torch.tensor([1]) # Гипотеза 1 представляет собой «счастливую» эмоцию.
# Генерация речевых функций
with torch.no_grad():
outputs = model.generate(**inputs, emotion_code=emotion_code)
# Извлеките сгенерированный Мел Spectrogram
mel_spectrogram = outputs[0]
waveform = torchaudio.transforms.MelSpectrogram()(mel_spectrogram.squeeze(0))
# Сохранить аудиофайл
torchaudio.save("happy_output.wav", waveform, 22050)Анализ кода
- регулирование эмоций: Введение эмоционального кодирования в процесс генерации позволяет модели генерировать речь с определенными эмоциями.
- Генерировать речь для разных эмоциональных состояний: Изменяя значение кодирования эмоций, модель может генерировать речь с разными эмоциями, такими как счастье, гнев, печаль и т. д.
персонализированный синтез
персонализированный синтез — еще одно важное достижение в области синтеза речи. С предварительно обученными речевыми моделями,TTS может генерировать речь с персонализированными характеристиками на основе индивидуальных параметров. Это особенно критично в таких приложениях, как виртуальные помощники и дублирование игровых персонажей. Создается посредством персонализированной речи,Пользователи могут создавать индивидуальные голосовые впечатления, соответствующие определенным интонациям, скорости или акцентам.
многоязычный синтез
Технология синтеза речи может не только генерировать речь на одном языке.,Также постепенно поддерживается многоязычный синтез. в глобальных приложениях,Технология TTS, поддерживающая несколько языков, чрезвычайно практична. Например,В системе обслуживания клиентов транснациональных компаний,TTS может автоматически генерировать голосовые ответы на соответствующем языке в соответствии с потребностями клиента.
многоязычный Модели синтеза, такие как Translatotron от Google, сочетают перевод текста с генерацией речи, обеспечивая сквозное межъязыковое взаимодействие. синтез речь. Эта технология не только повышает эффективность, но и сохраняет фонетические особенности и выражения эмоций на языке оригинала.
Пример кода: многоязычный синтез
from transformers import MBartForConditionalGeneration, MBartTokenizer
# Загрузка предварительно обученной модели MBart (поддерживает многоязычный синтез)
tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
# Введите текст (предположим, мы хотим преобразовать английский текст во французскую речь)
text = "Hello, how are you?"
inputs = tokenizer(text, return_tensors="pt", src_lang="en_XX")
# Генерация речевых функции (многоязычный синтез)
translated_tokens = model.generate(inputs['input_ids'], forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"])
# Преобразуйте сгенерированную речь и сохраните ее
translated_text = tokenizer.decode(translated_tokens[0], skip_special_tokens=True)
print("Translated Text in French: ", translated_text)Анализ кода
- Модель многоязычного синтеза: В этом примере используется многоязычная модель MBart, которая может переводить английский текст на французский и выводить его.
- межъязыковый синтез речи: С помощью этого метода вы можете свободно переключаться между разными языками, обеспечивая удобство для многоязычных приложений.
Будущие перспективы синтеза речи и AIGC
У AIGC блестящее будущее. Благодаря постоянному развитию технологии TTS,,Синтез речи будет играть большую роль во многих областях,Особенно в интерактивных сценариях, таких как виртуальная реальность, виртуальные люди и интеллектуальные устройства.,Синтез речи сольется с другими генеративными технологиями,Создавайте более умные и захватывающие впечатления.
Виртуальная реальность и голосовое взаимодействие
В сценариях виртуальной реальности (VR) и дополненной реальности (AR) взаимодействие с пользователем не ограничивается зрением и прикосновением, а голос станет важным средством взаимодействия. Благодаря виртуальной среде, созданной AIGC, виртуальные персонажи могут создавать диалоги, соответствующие сцене в реальном времени, улучшая погружение пользователя. Технология TTS сочетается с технологией обработки естественного языка (NLP) для генерации естественной речи на основе изменений сцены.
Синтез речи и персональные рекомендации
С применением AIGC в сфере электронной коммерции и развлечений персонализированные системы голосовых рекомендаций станут тенденцией будущего. Технология синтеза речи может генерировать персонализированную голосовую рекламу и рекомендации по контенту на основе интересов и предпочтений пользователей. Это приложение использует голос в качестве средства передачи информации, улучшая взаимодействие между пользователями и создаваемым контентом.
Автоматическая генерация голосового контента и создание подкастов
В области создания контента технология TTS существенно изменит способ производства контента. Например, автоматически сгенерированный голосовой контент можно использовать в новостном вещании, создании подкастов, аудиокнигах и других областях. Генерируя естественную, эмоционально выразительную речь, авторы могут создавать высококачественный аудиоконтент с меньшими затратами.
Технические проблемы и решения
Хотя технология синтеза речи продемонстрировала широкие перспективы применения в AIGC, проблемы, с которыми она сталкивается, по-прежнему нельзя игнорировать. Ниже приведены несколько ключевых проблем и возможных решений.
Достоверность и детальность сгенерированной речи
Хотя современная технология синтеза речи значительно улучшила естественность, ей по-прежнему не хватает деталей генерируемой речи. Например, эмоции речи, тонкие изменения интонации и реальные характеристики акцента трудно идеально смоделировать. Для систем TTS, используемых в сложных сценариях, особенно в виртуальных людях с высокой степенью моделирования, сгенерированная речь должна быть легко связана с реальной речью.
- Направление решения: Аутентичность генерируемой речи можно повысить, внедрив более подробный механизм эмоционального контроля и объединив его с моделью генерации речи на уровне фонем.
Генерация речи в реальном времени и производительность системы
В некоторых интерактивных приложениях реального времени, таких как виртуальная реальность или автоматизированные системы обслуживания клиентов, TTS необходимо генерировать высококачественную речь за очень короткое время. Это предъявляет чрезвычайно высокие требования к вычислительной производительности системы. Хотя существующие модели нейронных сетей, такие как WaveNet, обладают отличным эффектом генерации, скорость их генерации медленная и с трудом соответствует требованиям реального времени.
- Направление решения: С помощью моделей генерации речи без авторегрессии, таких как FastSpeech и FastPitch, можно значительно повысить скорость генерации при сохранении качества речи. Кроме того, методы сжатия и оптимизации моделей, такие как квантование и сокращение, также могут помочь снизить потребление вычислительных ресурсов.
Междоменное мультимодальное слияние
Будущие приложения AIGC будут не только генерировать единую форму контента, но также будут генерировать интегрированный контент в различных модальностях, таких как текст, изображения, видео и голос. Например, в виртуальных сценах пользователи ожидают увидеть виртуальных персонажей, которые не только обладают естественными голосами, но и хотят, чтобы их визуальное исполнение соответствовало голосовому контенту. Генерация кросс-модального контента ставит перед моделью большие проблемы.
- Направление решения: Сочетание синтеза речи с генерацией изображений, захватом движения и другими технологиями для формирования мультимодальной системы совместной генерации. Улучшите согласованность и координацию создаваемого контента за счет совместного обучения мультимодальных моделей.
Вопросы конфиденциальности и безопасности
Технология синтеза речи также вызывает проблемы конфиденциальности и безопасности, особенно то, что технология клонирования голоса, основанная на глубоком обучении, может использоваться для подделки голоса других. Это создает потенциальные риски для системы голосовой аутентификации и защиты личной жизни.
- Направление решения: В будущем необходимо разработать более безопасную технологию генерации речи.,Например, добавив звуковой водяной знак, который нельзя копировать.,Или используйте более сложные алгоритмы шифрования, чтобы обеспечить уникальность и безопасность сгенерированного голоса.
Подвести итог
Технология синтеза речи достигла значительного прогресса в области AIGC. Благодаря мощным возможностям моделей глубокого обучения нынешняя система TTS может генерировать естественную и реалистичную речь и реализовывать множество приложений. В этой статье рассматриваются методы синтеза, основанные на таких технологиях, как Tacotron и WaveNet, и показано, как генерировать более разнообразную речевую продукцию посредством эмоциональной регуляции и персонализированных параметров. Синтез речи не только совершил прорыв в создании естественной речи, но и постепенно распространился на такие области, как многоязычная генерация в реальном времени и синтез эмоций. Перспективы его применения очень широки.
Однако технология синтеза речи по-прежнему сталкивается со многими проблемами, включая подлинность генерируемой речи, производительность в реальном времени, кросс-модальное объединение контента, а также проблемы конфиденциальности и безопасности. Будущие направления развития включают оптимизацию эффективности генерации модели, улучшение возможностей эмоционального контроля, достижение мультимодальной объединенной генерации, а также повышение безопасности и защиты конфиденциальности генерации речи.
Благодаря постоянному развитию технологии синтеза речи сценарии применения AIGC станут более разнообразными: от голосового взаимодействия в виртуальной реальности до персонализированных рекомендаций автоматически генерируемого контента, технология TTS глубоко изменит способ взаимодействия человека с компьютером и будет способствовать внедрению новых технологий. Контент, созданный искусственным интеллектом. Новая эра, более разумная и гуманная.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
