Использование ChatGLM-6B, тонкая настройка, обучение
представлять
- Лаборатория Инженерии знаний Университета Цинхуа (KEG) и компания Wisdom AI совместно обучали языку Модель в 2023 году.
- ChatGLM-6B Ссылка ChatGPT Идеи дизайна, в базе 100 миллиардов Модель GLM-130B В него вводится предварительное обучение кода, и оно согласовывается с намерениями человека с помощью таких методов, как контролируемая точная настройка (то есть приведение ответов машины в соответствие с человеческими ожиданиями и ценностями).
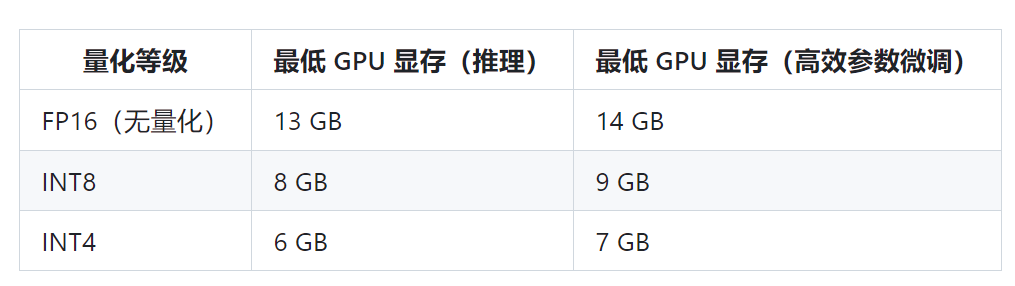
- Отличается от обучения ChatGPT, для которого требуется более 10 000 видеокарта А100,ChatGLM-6B можно запустить на отдельной видеокарте потребительского уровня (13G может работать,Рекомендуется видеокарта 16-24G),Есть много возможностей для будущего.
После того, как 14 марта исходный код модели https://github.com/THUDM/ChatGLM-6B был открыт, Github Темпы роста Star поразительны: она занимает первое место в глобальном списке загрузок крупных моделей в течение 12 дней подряд.
На основе ГЛМ (General Language Model) Архитектура с 6,2 миллиардами параметров, без Количественной оценказанимает меньше видеопамяти13G,Поддерживает одну видеокарту потребительского уровня в соответствии с количественной оценкой INT.(нравиться2080Ti)рассуждения оКвантование INT8это глубокое обучение Модельвмассаизначение активации от16бит число с плавающей запятой(FP16)уменьшено до8битовое целое число INT8, что позволяет сократить использование памяти и сложность вычислений, сократить вычислительные ресурсы и повысить скорость вывода.
- ChatGLM уже имеет возможность диалога вопросов и ответов, предпочитаемого человеком, но для некоторых инструкций возникают такие проблемы, как непонимание инструкций, непонимание концепций предметной области и создание вредоносного контента.
- ChatGLM уже имеет возможность диалога вопросов и ответов, предпочитаемого человеком, но для некоторых инструкций возникают такие проблемы, как непонимание инструкций, непонимание концепций предметной области и создание вредоносного контента.
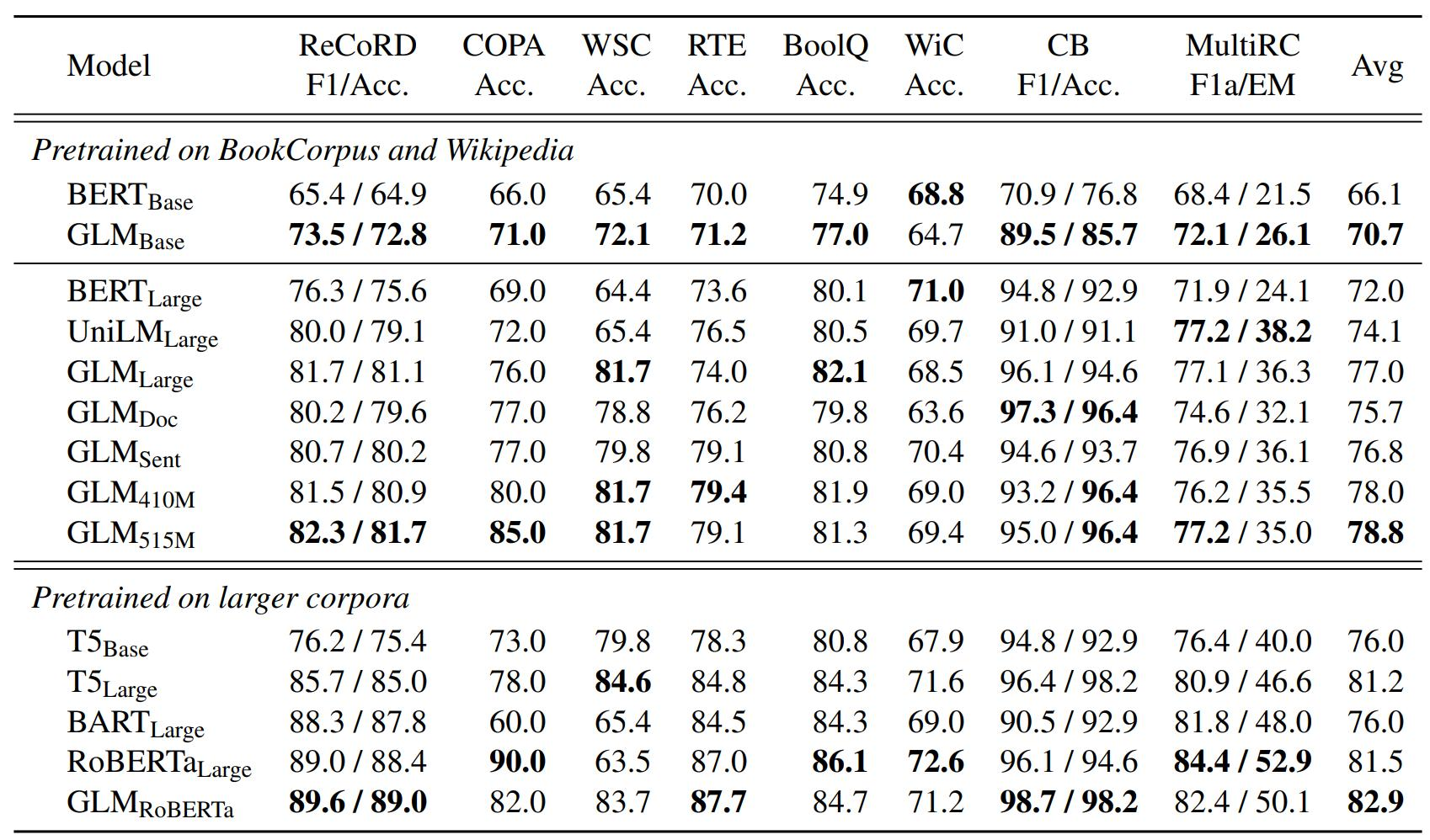
GLM-130B
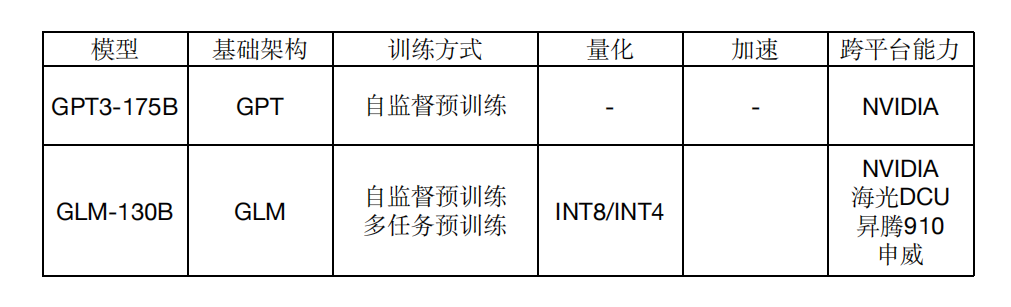
август 2022 г.,Интеллектуальный спектр AIНа основе структуры ГЛМ,Выпущена китайско-английская двуязычная плотная модельGLM-130B со 130 миллиардами параметров.,Комплексные возможности эквивалентны GPT3.
Экономия памяти 75 %,Доступно в одном устройстве3090 (*4) или один 2080 (*8) для вывода без потерь
Высокая скорость рассуждений,В 7-8 раз быстрее, чем Pytorch
Кросс-платформенный,Поддержка адаптации и приложений для различных вычислительных платформ.
https://github.com/THUDM/GLM-130B
Функция

Дополнительная ссылка: https://github.com/THUDM/ChatGLM-6B.
Цель
GLM
GLM: Предварительное обучение общей языковой модели https://aclanthology.org/2022.acl-long.26.pdf
Отправной точкой GLM является объединение трех основных моделей предварительного обучения:
- GPT, внимание одностороннее и не может использовать следующую информацию.
- BERT, где внимание двунаправлено, хорошо работает с NLU, но не подходит для задач генерации.
- Т5, внимание в кодере двунаправленное, а внимание в декодере однонаправленное. из. Может использоваться как для задач NLU, так и для задач генерации, но требует большего количества параметров.
https://github.com/THUDM/GLM
использовать
предположениеиспользоватьColab,и включите графический процессор A100,demo1.py Исходный код: https://github.com/dlimeng/awesome-ai-generated/blob/main/ChatGLM%E4%BD%BF%E7%94%A8/demo1.ipynb
# Step1, Установить пакеты зависимостей
!pip install transformers
!pip install sentencepiece
!pip install cpm_kernels
!pip install gradio
!pip install mdtex2html
# Step2,использоватьпредварительная подготовка Модель
from transformers import AutoTokenizer, AutoModel
tokenizer =AutoTokenizer.from_pretrained("THUDM/chatglm-6b",trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b",trust_remote_code=True).half().cuda()
# Шаг 3, создайте чат-чат
response, history = model.chat(токенайзер,"Привет", history=[])
print(response)
response, history = model.chat(tokenizer,"Что делать, если я не могу спать по ночам",history=history)
print(response)
сделанный на заказ
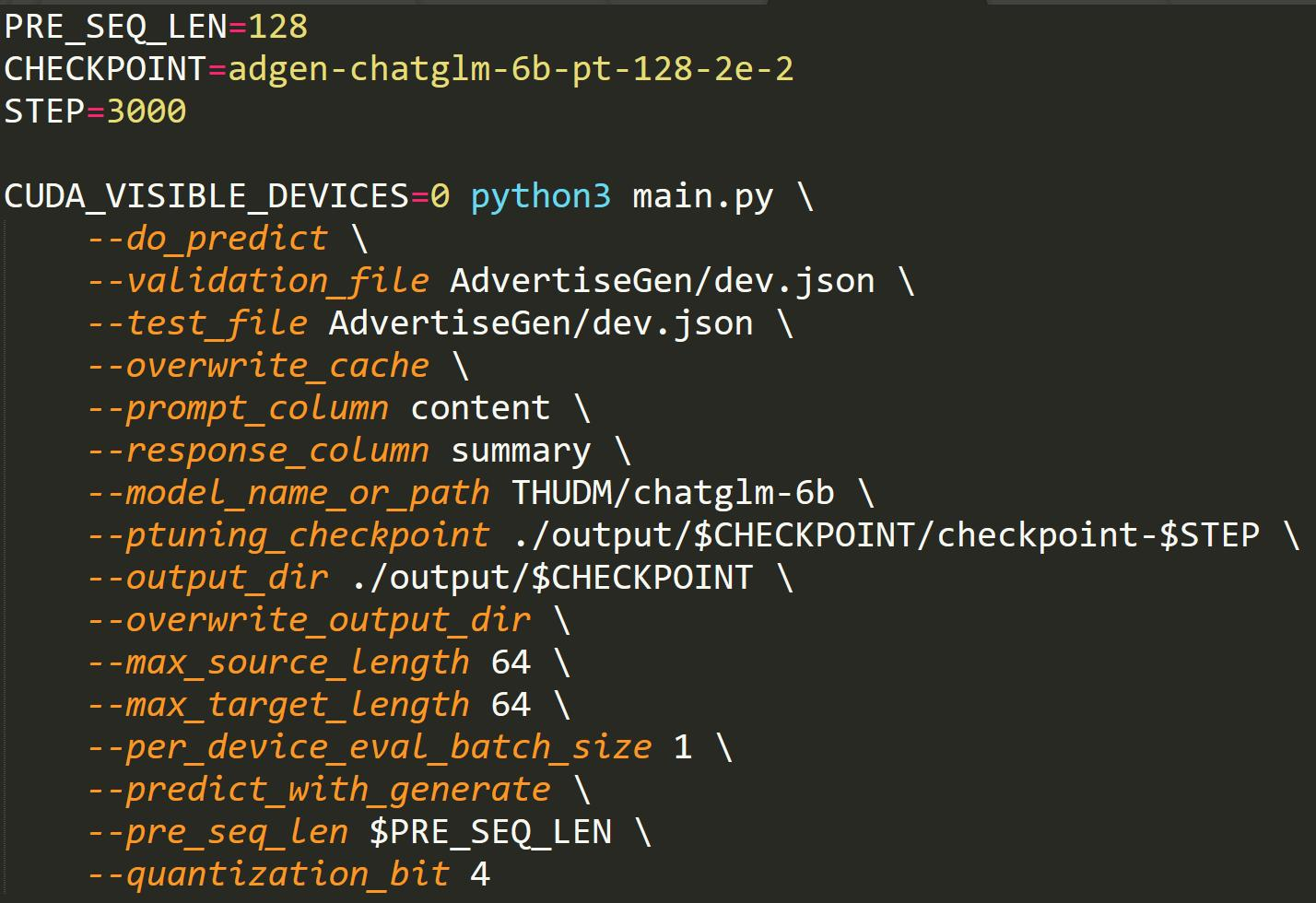
Исходный код: https://github.com/dlimeng/awesome-ai-generated/blob/main/ChatGLM%E4%BD%BF%E7%94%A8/ptuning1.ipynb Ссылка: https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md. P-Tuning
- Точная настройка модели ChatGLM с использованием собственного набора данных.
- В P-Tuning V2 количество параметров, требующих точной настройки, уменьшено до 0,1–3% от исходного, что значительно ускоряет обучение и требует минимального объема памяти графического процессора. Для 7G (рекомендуется 16–24G)
- TIPS:AdvertiseGenданныенабор,Тренировка 3000 шагов,Это занимает примерно Для тренировки в течение 2 часов необходимо убедиться, что на вашем графическом процессоре достаточно вычислительных блоков.
использоватьP-Tuning v2 для тренировок
!bash train.sh

- Думая: будет train.sh в THUDM/chatglm-6b Изменение пути к локальной модели (Ссылка на train2.sh)
- Думаем: как использовать обученную модель ChatGLM для выполнения inferenceuseevaluate.sh, здесь нужно изменить имя_модели_или_путь и ptuning_checkpoint
- СОВЕТЫ: в P-tuning v2 Во время обучения Модель сохраняет только параметры PrefixEncoder, поэтому необходимо одновременно загружать исходные параметры во время вывода. ChatGLM-6B Модель и PrefixEncoder масса

легкая библиотека
Библиотека Peft: https://github.com/huggingface/peft легко преобразует обычные модели HF в модели, поддерживающие легкую точную настройку. В настоящее время она поддерживает 4 стратегии: 1) LoRA: адаптер низкого ранга для больших моделей 2) Настройка префиксов: оптимизация непрерывных подсказок для генерации 3) P-Tuning: GPT тоже понимает 4) Быстрая настройка: сила масштабирования для быстрой настройки с эффективным использованием параметров

«Дао порождает одно, одно порождает два, два порождает три, а три порождает все вещи». Только пониманием и пониманием мы можем преодолеть ограничения и создать будущее.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
