Искусственный интеллект Python: метод реализации алгоритма классификации случайных лесов на основе sklearn
1. Введение в алгоритмы ансамблевого обучения.
Ансамбльное обучение — это популярный метод машинного обучения, который строит несколько моделей на основе набора данных и объединяет результаты анализа и прогнозирования всех моделей. Общие алгоритмы ансамблевого обучения включают в себя: случайный лес, дерево повышения градиента, Xgboost и т. д.
- Цель ансамблевого обучения: проанализировать результаты, учитывая прогнозы нескольких оценщиков.,После агрегирования получается комплексный результат,Для достижения лучших результатов регрессии/классификации, чем при использовании одной модели.
Модель, объединяющая несколько моделей, называется оценщиком ансамбля (ансамбль). оценщик), каждая модель в нем называется базовым оценщиком (base оценщик). С точки зрения метода интеграции базового оценщика,интегрированныйалгоритмможно разделить на:Упаковка(Bagging)、метод продвижения(Boosting)и способ укладки(Stacking)。вBaggingМетоды иboostingметоды — два наиболее распространенных метода интеграции,Их схемы показаны ниже:
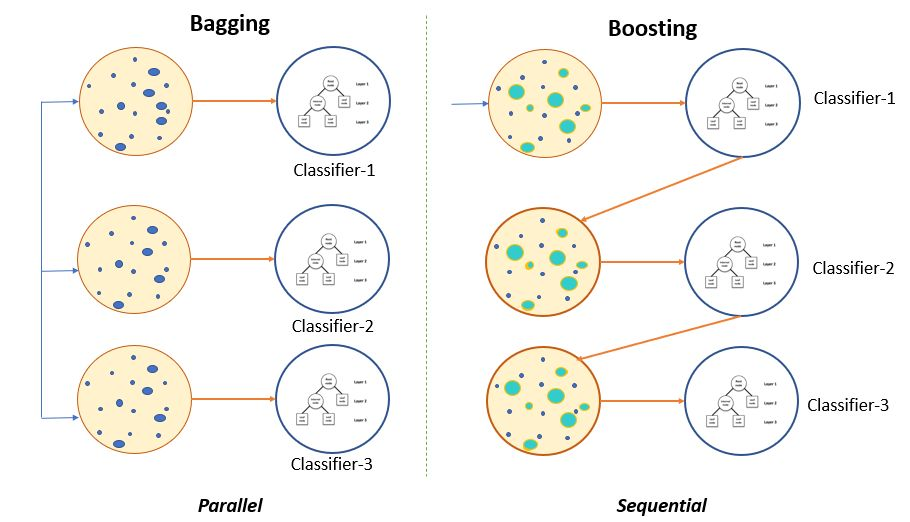
BaggingОсновная идея метода:Создайте несколько независимых оценщиков,Затем результат оценщика ансамбля определяется на основе среднего или большинства голосов.,Типичным представителем является Модель случайного леса.BoostingОсновная идея метода:его оценка уместна,То есть интегрированный оценщик строится в определенном порядке. Затем объедините возможности слабых оценщиков, чтобы постепенно улучшить возможности оценки интегратора.,Наконец получите сильную оценку。常见的метод продвижения МодельиметьAdaboostingс деревом повышения Модель。
Случайный лес — это типичный алгоритм пакетной интеграции. Все его базовые оценщики представляют собой деревья решений. Лес, состоящий из деревьев классификации, называется классификатором случайного леса, а лес, состоящий из деревьев регрессии, — регрессором случайного леса.
2. Функция алгоритма классификации случайного леса
2.1 на основеsklearnСлучайный лес Алгоритм классификации Пример реализации
sklearn中Случайный лес Алгоритм классификацииAPIдляsklearn.ensemble.RandomForestClassifier,Его обычно используемый параметр выглядит следующим образом:
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(
n_estimators = 100, # Количество деревьев в случайном лесу
criterion = "gini", # Мера примеси
max_depth = 5, # максимальная глубина на дерево
min_samples_leaf = 10, # Минимальное количество выборок, которое должен содержать каждый дочерний узел узла после ветвления.
min_samples_split = 10, # Узел должен содержать минимальное количество выборок
max_features = "sqrt", # Количество признаков при ветвлении
min_impurity_decrease = 1e-3 # Размер информационного прироста
)
проходитьsklearnБиблиотеки упрощают реализацию случайных лесов Алгоритм классификации, сначала дайте случайный лес Алгоритм пример реализации организации, можно комбинировать с 2.2 Важные параметры функции классификации случайного леса и 2.3. Важные атрибуты и интерфейсы функции классификации случайного леса — это две части, необходимые для понимания кода.
Чтобы отразить превосходство алгоритма случайного леса,Одновременно реализовать алгоритм случайного леса и дерево решений.,и, наконец, сравните эффективность прогнозирования двух。использоватьsklearn.ensemble.RandomForestClassifierРеализовать случайный лес Алгоритм Основные этапы алгоритма классификации и принятия решений следующие:
- (1) Импортируйте необходимый набор данных и разделите его на обучающий и тестовый набор;
- (2) Алгоритм Организация Создание экземпляров, обучение и оценка эффективности прогнозирования;
- (3) Выведите результаты прогноза.
Код реализации следующий:
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
# 1. Импортируйте необходимый набор данных и разделите его на обучающий набор и тестовый набор.
wine = load_wine()
X_train, X_test, y_train, y_test = train_test_split(
wine.data, wine.target, test_size=0.3
)
# 2. Алгоритм Организация Создание экземпляров, обучение и оценка эффективности прогнозирования
clf = DecisionTreeClassifier() # Создание экземпляра дерева решений
rfc = RandomForestClassifier() # Случайное создание леса
# Модельное обучение и оценка эффективности
clf = clf.fit(X_train, y_train) # Дерево решений Модель обучения
rfc = rfc.fit(X_train, y_train) # Обучение модели случайного леса
# Оценка эффективности
score_clf = clf.score(X_test, y_test) # Схема принятия решений эффективностирезультат
score_rfc = rfc.score(X_test, y_test) # Оценка случайного леса эффективностирезультат
# 3. Выведите результаты прогнозирования двух моделей
print("Результаты прогнозирования классификации для одного дерева решений:{}\n".format(score_clf),
«Результаты прогнозирования случайной классификации леса: {}\n».format(score_rfc))

Видно, что точность прогнозирования алгоритма случайного леса значительно выше, чем точность прогнозирования одного дерева решений.
2.2 Важные параметры функции классификации случайного леса
sklearnсредний случайный лес Алгоритм Основной параметр системы API включает две категории: параметр на основе базового оценщика и параметр интегрированного оценщика.
- 1. Базовый параметр оценщика
Как показано в таблице ниже, основные параметры базового оценщика такие же, как и у дерева решений:
параметр | описывать |
|---|---|
criterion | Индикаторы измерения примесей, обычно используемые методы включают Джини и энтропию. |
max_depth | Максимальная глубина каждого дерева, ветки, превышающие максимальную глубину, будут обрезаны. |
min_samples_leaf | Каждый дочерний узел узла после ветвления должен содержать как минимум обучающие выборки min_samples_leaf, иначе операция ветвления не будет выполнена. |
min_samples_split | Узел должен содержать как минимум min_samples_split обучающие выборки, прежде чем узел сможет выполнять операции ветвления. |
max_features | Укажите количество объектов, которые необходимо учитывать при ветвлении. Любые объекты, превышающие лимит, будут отброшены. По умолчанию используется квадратный корень из общего числа объектов. |
min_impurity_decrease | Ограничьте размер прироста информации. Если прирост информации меньше установленного значения, операция ветвления выполняться не будет. |
- 2. Параметр интегрированного оценщика
Просто нужнососредоточиться на Количество деревьев в случайном лесуn_estimatorsпараметр Вот и все。Вообще говоря,Этот параметр оказывает монотонное влияние на точность модели случайного леса.,n_estimatorsЧем больше,Результаты часто лучше с Моделью. Но соответствующее,Любая Модель имеет границу решения,n_estimatorsПосле достижения определенного уровня,Точность случайного леса имеет тенденцию переставать расти или начинает колебаться.,и,n_estimatorsЧем больше,Требуемый объем вычислений и памяти также больше.,Время обучения также будет становиться все длиннее и длиннее.
На основе кода из раздела 2.1.,Исследование ниже Количество деревьев в случайном лесуn_estimatorsпараметрверно Модель Влияние на производительность。Нарисуйте случайный лес нижеn_estimatorsкривая обучения,Код выглядит следующим образом:
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc_performance = [] # Хранить результаты прогнозирования случайного леса
# рисовать Количество деревьев в случайном лесуn_estimatorsкривая обучения
for i in range(100):
rfc = RandomForestClassifier(
n_estimators=i+1,
n_jobs=-1
) # Создание экземпляра модели классификации случайного леса
# 下面использовать10折交叉验证方法вернослучайный лес进行训练与Оценка эффективности
rfc_score = cross_val_score(
rfc, wine.data, wine.target, cv=10
).mean()
rfc_performance.append(rfc_score) # Сохраняйте результаты прогнозирования для разного количества деревьев решений.
# Нарисуйте кривую обучения
plt.figure(figsize=[10,4])
plt.plot(range(1,101), rfc_performance)
plt.show()
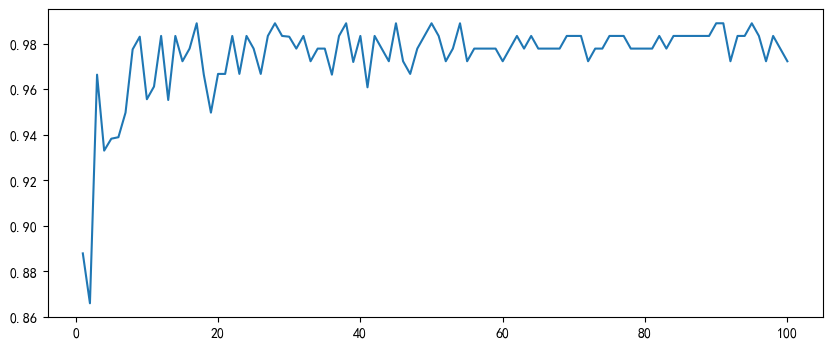
Зависит отn_estimatorsпараметркривая обучения可以看出,Алгоритм от Random Forest классификациивместе сn_estimatorsРастущая производительность также постепенно увеличивается,Но когда она увеличивается до определенной величины, появляется так называемая граница решения.,То есть точность классификации случайным образом колеблется вокруг этой небольшой амплитуды.
2.3 Важные атрибуты и интерфейсы функции классификации случайного леса
- 1. Важность функции классификации случайного леса.
свойство | эффект |
|---|---|
.estimators_ | Используется для просмотра списка всех деревьев в случайном лесу. |
oob_score_ | Забит за пределами сумки. Поскольку случайный лес использует метод выборки с заменой,,Это приведет к тому, что некоторые данные не будут выбраны во время обучения.,Эти данные называются исходными данными. Поскольку исходные данные не используются для обучения Моделью,Мы можем использовать их в качестве набора тестовых данных. Таким образом, мы можем использовать свойство oob_score_this, чтобы получить результаты оценки модели исходных данных в качестве индекса производительности модели. |
.feature_importances_ | Возвращает важность функции |
- 2. Часто используемые методы функции классификации случайного леса.
интерфейс | эффект |
|---|---|
fit | Модельное обучение |
predict | Введите наблюдения и верните предсказанные метки |
score | Введите значения наблюдения и целевые значения и верните точность прогнозирования их моделей. |
predict_proba | Возвращает вероятность того, что каждый тестовый образец будет присвоен соответствующей метке каждой категории. Существует несколько вероятностей того, сколько категорий имеет метка. |
apply | Возвращает индекс конечного узла дерева, где находится образец. |
3. Общая идея настройки параметров интегрированного алгоритма обучения
✨ В машинном обучении ошибка обобщения (Genelization Error) используется в качестве индикатора для измерения точности модели на основе данных о местоположении. Чтобы получить идеальную модель, я обычно сосредотачиваюсь на следующих трех аспектах:
- (1) Модель слишком сложна (переобучение) или слишком проста (недооснащение),увеличит ошибку обобщения;
- (2) Для древовидной модели и древовидной модели интеграции.,Чем глубже дерево,Чем больше ветвей и листьев,Модель более сложная;
- (3) Из-за сложности интеграции этой статьи,в практическом применении,Цель модели дерева и интеграция модели дерева,Все они призваны уменьшить сложность модели.,Чтобы уменьшить переобучение модели.
случайный лесалгоритм的调参过程可以很方便地проходитьsklearn.model_selection.GridSearchCVметод достижения,Подробности программирования можно найти в разделе примеров в части 4.
4. Пример реализации алгоритма классификации случайных лесов - на основе набора данных о раке молочной железы.
Реализация алгоритма классификации случайного леса на основе набора данных о раке молочной железы в основном включает в себя следующие этапы:
- (1) Импортируйте необходимые библиотеки и наборы данных;
- (2) Реализация случайной классификации леса Модель、Модель Количество тренировок и деревьев решений
n_estimatorsкривая обучениярисовать。Зависит от于决策树数量n_estimatorsвернослучайный лес分类Модель具иметь重要的影响,Поэтому сначала необходимо изучить ее влияние на производительность Модели.,Определить границу решения, где количество деревьев решений превышает параметр; - (3) 进而использовать
sklearn.model_selection.GridSearchCVверно其他超параметрпо очереди Выполните поиск по сетке。
# 1. Импортируйте необходимые библиотеки и наборы данных.
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
data = load_breast_cancer()
# 2. Реализация модели случайной классификации леса, обучение модели и построение кривой обучения для количества деревьев решений.
# Постройте кривую обучения случайного леса. Номер дерева решений модели `n_estimator`
performance_score = [] # Сохраните эффективность прогнозирования Модели с разным количеством деревьев решений.
for i in range(0,200,10):
rfc = RandomForestClassifier(
n_estimators=i+1,
n_jobs=-1,
) # Классификация случайного леса. Создание экземпляра модели.
score = cross_val_score(
rfc, data.data, data.target, cv=10
).mean() # Модель обучения и перекрестной проверки
performance_score.append(score)
# Выведите наибольший результат прогноза и его метку.
print(
max(performance_score),
(performance_score.index(max(performance_score))*10)+1
)
# Нарисуйте кривую обучения
plt.figure(figsize=[10, 4])
plt.plot(range(1,201,10), performance_score)
рисовать的n_estimatorsКривая обучения выглядит следующим образом:
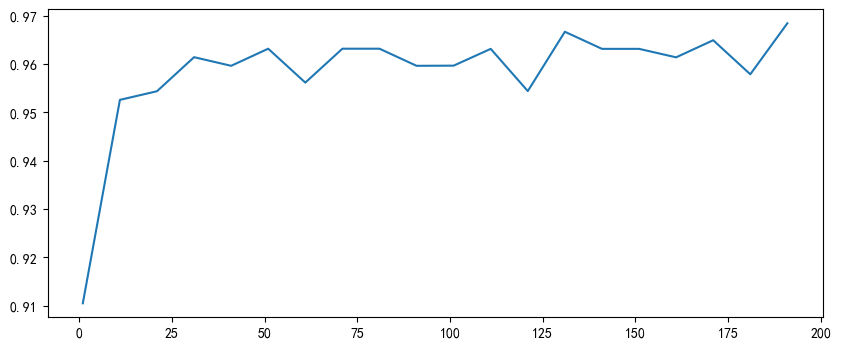
таким образом,可以确定верно于n_estimatorsГраница решения находится на[30 75]между,在此基础上进而верно其他超параметрпо очереди Выполните поиск по сетке。
Затем объединитеn_estimatorsграница решения[30 75],вернослучайный лес中每个决策树的最大深度超параметрmax_depthВыполните поиск по сетке,Код выглядит следующим образом:
# 3. Затем выполните поиск по сетке для других суперпараметров.
# Поиск по сетке максимальной глубины каждого дерева решений в случайном лесу, превышающем параметр`max_eep`
param_grid = {
"n_estimators": [*np.arange(30, 71, 5)],
'max_depth': [*np.arange(1, 21, 1)]
}
rfc = RandomForestClassifier() # Создание экземпляра случайной классификации леса Модель
GS = GridSearchCV(rfc, param_grid, cv=10) # Создание экземпляра объекта поиска по сетке
GS.fit(data.data, data.target) # Выполните поиск по сетке
# Просмотр оптимальной комбинации параметров и результатов точности прогноза
# Вернуться к лучшим комбинациям суперпараметров
print("\nЛучшая комбинация суперпараметров:\n", GS.best_params_)
# Вернуть лучшие результаты обзора моделей
print("\nЛучший результат оценки классификации:\n", GS.best_score_)
Результат выполнения кода показан на рисунке ниже:
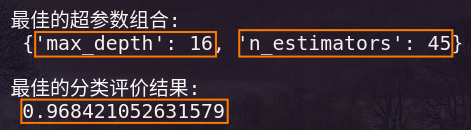
таким образом Видно, что число деревьев решенийn_estimators的最佳数量для
,且случайный лес中每个决策树的最大深度超параметрmax_depth最佳层数для
. Чтобы облегчить процесс оптимизации, конкретные значения этих двух суперпараметров можно определить при последующей оптимизации другого суперпараметра.
在上面的基础上верно其他超параметр Выполните поиск по сетке,Выполните максимальную функцию суперпараметрmax_featuresпоиск по сетке,Настройка параметров в этой статье является лишь примером.,Читатели могут полностью настроить другие параметры или каждый диапазон параметров по своему усмотрению.
Код выглядит следующим образом:
# использовать`sklearn.model_selection.GridSearchCV`верно其他超параметрпо очереди Выполните поиск по сетке
param_grid = {
"max_features": [*np.arange(5, 21, 1)],
"min_samples_leaf": [*np.arange(1, 21, 2)],
"criterion": ("gini", "entropy")
}
rfc = RandomForestClassifier(
n_estimators=45,
max_depth=16
)
GS = GridSearchCV(rfc, param_grid, cv=10) # Создание экземпляра объекта поиска по сетке
GS.fit(data.data, data.target) # Выполните поиск по сетке
# Просмотр оптимальной комбинации параметров и результатов точности прогноза
# Вернуться к лучшим комбинациям суперпараметров
print("\nЛучшая комбинация суперпараметров:\n", GS.best_params_)
# Вернуть лучшие результаты обзора моделей
print("\nЛучший результат оценки классификации:\n", GS.best_score_)
Результат выполнения следующий:

Из этого видно, что за счет корректировки параметров точность прогнозирования модели увеличивается с исходных 96,8% до 97%.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
