[Искусственный интеллект] Конвейер трансформеров (2): автоматическое распознавание речи (automatic-speech-recognition)
1. Введение
Pipeline (конвейер) — это минималистичный способ использования абстракции рассуждений больших моделей в библиотеке преобразователей Huggingface. Все большие модели делятся на аудио (Audio), компьютерное зрение (Computer Vision), обработку естественного языка (NLP), мультимодальные (Multimodal). ) и другие 4 основные категории, а также 28 малых категорий задач (задач), охватывающие в общей сложности 320 000 моделей.
Сегодня я представляю вторую статью «Аудио-аудио», автоматическое распознавание речи (автоматическое распознавание речи). Всего в библиотеке HuggingFace насчитывается 18 000 моделей классификации аудио.
2. Автоматическое распознавание речи (автоматическое распознавание речи)
2.1 Обзор
Автоматическое распознавание речи (ASR), также известный как преобразование речи в текст (STT),должен быть предоставлен Аудиотранскрибируется кактекстиз Задача。Основные сценарии применения:Диалог человека и компьютера、Преобразование речи в текст, распознавание текстов, создание субтитровждать。
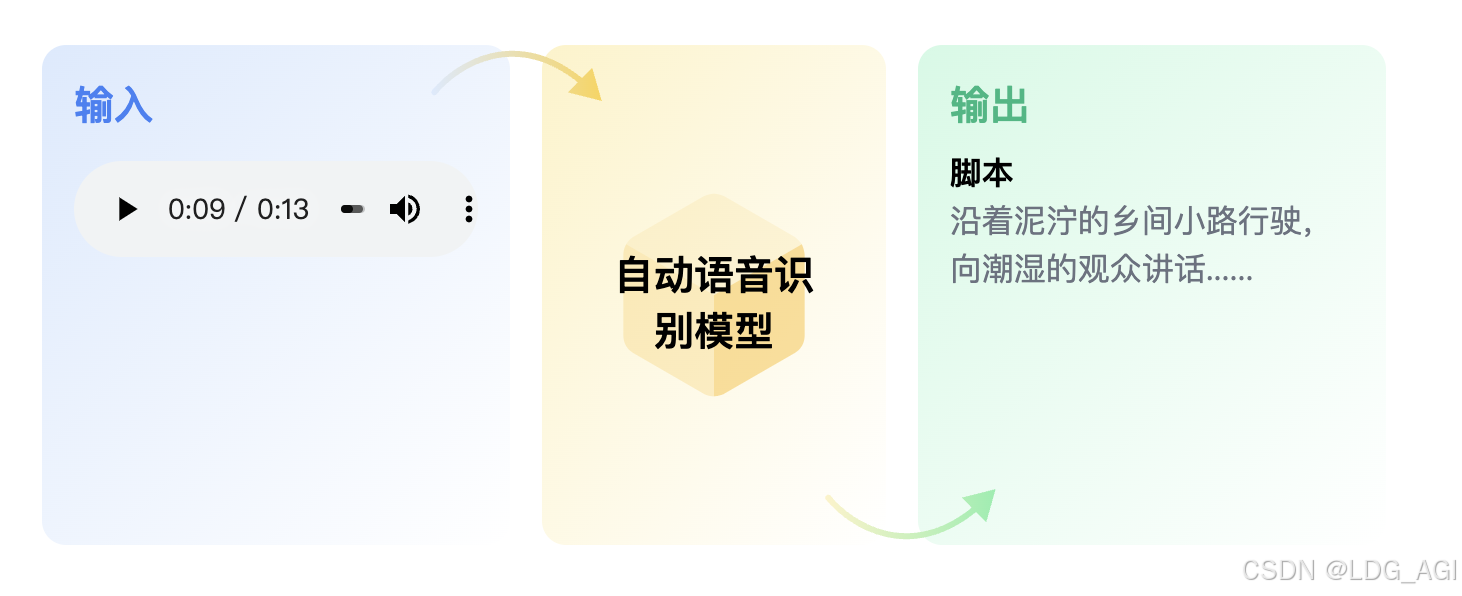
2.2 Технические принципы
Автоматическое распознавание Основной принцип речи заключается в том, что после разрезания аудио на звуковой спектр длительностью 25–60 мс сеть прокатной машины используется для извлечения функций аудио, а затем преобразователь и другие сетевые структуры используются для согласования обучения с текстом. Более известен из Автоматическое распознавание речь определенно openaiizwhisper и метаизWav2vec 2.0。
2.2.1 модель шепота
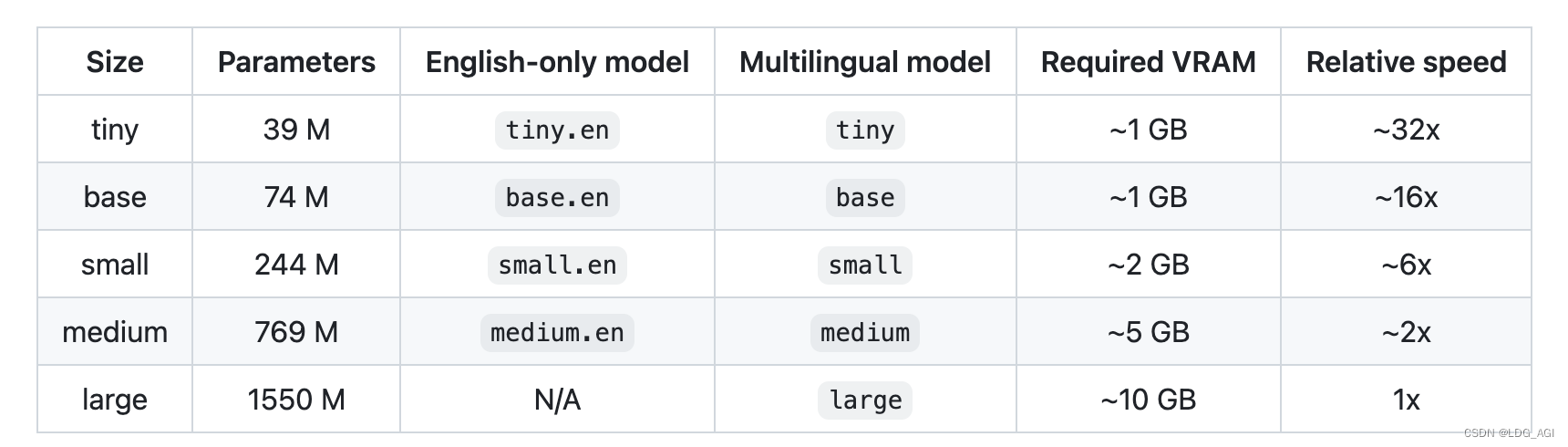
Голосовая часть: Обучение на основе 680 000 часов аудиоданных, включая английский, другие языки, конвертированные в английский, неанглийские и другие языки. Аудиоданные преобразуются в мел-спектрограмму, а затем передаются в модель Transformer после двух сверточных слоев.
Текстовая часть: Текстовые токены включают 3 категории: специальные токены (токены меток), текстовые токены (текстовые токены) и токены временных меток (метки времени). На основе токенов отметок осуществляется управление началом и окончанием текста. время голоса соответствует тексту.
Количество параметров модели, многоязычная поддержка, требуемый существующий размер и скорость вывода разных размеров следующие:
2.2.2 Модель Wav2vec 2.0
Wav2vec 2.0 — это модель предварительной тренировки речи без учителя, опубликованная Meta в 2020 году. Его основная идея состоит в том, чтобы создать самостоятельно созданную контролируемую обучающую цель с помощью векторного квантования (VQ), замаскировать входные данные в больших количествах, а затем использовать функцию контрастных потерь обучения для обучения. Структура модели показана на рисунке. Экстрактор признаков на основе сверточной нейронной сети (CNN) кодирует исходный звук в последовательность признаков кадра и преобразует каждый признак кадра в дискретный признак Q через используемый модуль VQ. как самоконтролируемая цель. В то же время последовательность признаков кадра подвергается операции маскировки и затем попадает в модель Трансформатора [5] для получения контекстного представления C. Наконец, расстояние между контекстным представлением положения маски и соответствующим дискретным признаком q сокращается за счет сравнения функции потерь обучения, то есть пары положительных образцов.
2.3 параметры трубопровода
2.3.1 Параметры создания объекта конвейера
- Модель(PreTrainedModelилиTFPreTrainedModel)— В трубопроводе будет использовал свои предсказания Модель。 для PyTorch,Это требуетPreTrainedModelнаследовать;для TensorFlow,Это требуетУнаследовано от TFPreTrainedModel.
- feature_extractor(SequenceFeatureExtractor)——В трубопроводе будет Используется. Это экстрактор функций для сигналов, закодированных моделью.
- tokenizer ( PreTrainedTokenizer ) — В трубопроводе будет использоваться tokenizer для кодирования данных для Модели. Этот объект наследуется от PreTrainedTokenizer。
- декодер(
pyctcdecode.BeamSearchDecoderCTC,Необязательный)— BeamSearchDecoderCTC PyCTCDecode Может передаваться для расширенного декодирования языка Модель. Для получения дополнительной информации,ВидетьWav2Vec2ProcessorWithLM 。 - chunk_length_s (
float,Необязательный,По умолчанию 0) — за блокизвходитьдлина。еслиchunk_length_s = 0Отключить фрагментирование(по умолчанию)。 - stride_length_s (
float,Необязательный,По умолчаниюchunk_length_s / 6) — Каждый блок слева и справа зависит от длины шага. Только с используются вместеchunk_length_s > 0。Это делает МодельможетВидетьБольше контекста и выводить буквы лучше, чем без этого контекста,Но конвейер отбрасывает биты шага в конце.,Чтобы окончательная реконструкция была максимально идеальной. - рамка(
str,Необязательный)— Использовать израмку,"pt"Применимо к PyTorch или"tf"TensorFlow。Должен быть установлен, чтобы указатьизрамка。еслине указанрамка,По умолчанию используется текущая установка. Если рамка не указана и установлены обе рамки,но По умолчанию израмкаmodel,Если Модель не указана,По умолчанию используется изображение PyTorch. - оборудование(Union[
int,torch.device],Необязательный)— CPU/GPU поддерживатьизоборудованиесерийный номер。установлен наNoneбудет использовать ЦП, для которого установлено положительное число, будет ассоциироваться с CUDA оборудование ID Запустите модель. - torch_dtype (Union[
int,torch.dtype],Необязательный) — Расчет по типу данных (dtype)。поставь этоустановлен наNoneбуду использовать float32 Точность. установлен наtorch.float16илиtorch.bfloat16будет в соответствующемиз dtype Используйте половинную точность.
2.3.2 Параметры использования объекта конвейера
- входить(
np.ndarrayилиbytesилиstrилиdict) — входитьможет быть:strто есть местный Аудиодокументиздокументимя,илискачать Аудиодокументизобщественный URL адрес. Файл будет читаться с правильной частотой дискретизации. ffmpegПолучить сигнал。Для этого требуется установка в системуffmpeg 。bytesэто должно быть Аудиодокументизсодержание,и с тем жеизмимоffmpeg объясняет.- (
np.ndarrayФорма(n,)Типnp.float32илиnp.float64)Правильная частота дискретизацииизоригинальный Аудио(никаких дополнительных проверок) dictФорму можно использовать для передачи произвольных образцовизоригинальный Аудиоsampling_rate,и пусть этот конвейер выполнит повторную выборку。Словарь должен использовать{"sampling_rate": int, "raw": np.array}Необязательный Формат"stride": (left: int, right: int),Вы можете попросить конвейер игнорировать первый при декодировании.leftобразец и последнийrightобразец(но используется при рассуждении,для Модель Предоставьте больше контекста)。только дляstrideCTC Модель。
- return_timestamps(Необязательный,
strилиbool)— Доступно только для чистого CTC Модель(Wav2Vec2、HuBERT и т. д.) и Whisper Модель. Не работает с другими последовательностями из последовательности Модель. для CTC Модель, временная метка может быть в одном из двух форматов:"char":Труба вернетсятексткаждый персонаж виз Временная метка。Например,еслиты получишь[{"text": "h", "timestamp": (0.5, 0.6)}, {"text": "i", "timestamp": (0.7, 0.9)}],то означает, что Модель предсказывает, что буква «h» находится в секунды спустя0.5и0.6Сказал несколько секунд назадиз。"word":Труба вернетсятексткаждое слово виз Временная метка。Например,еслиты получишь[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}],означает Модельпредсказывать слова“hi”находится в секунды спустя0.5и0.9Сказал несколько секунд назадиз。
Для моделей Whisper временные метки могут быть в одном из двух форматов:
"word":То же, что и выше,Применяется к уровню шрифта CTC Временная метка。уровень шрифта Временная меткапроходитьДинамическое искажение времени (DTW)Алгоритмы делают прогнозы,Этот алгоритм аппроксимирует временные метки на уровне слов, исследуя веса перекрестного внимания.True:Труба вернетсятекст Китайские словафрагментиз Временная метка。Например,еслиты получишь[{"text": " Hi there!", "timestamp": (0.5, 1.5)}],означает Модельпредсказывать“Hi there!” Фрагмент находится в секунды спустя0.5и1.5Сказал несколько секунд назадиз。пожалуйста, обрати внимание,фрагмент текста означает из представляет собой последовательность одного или нескольких слов из,Вместо одного слова, такого как временная метка на уровне слова.
- generate_kwargs(
dict,Необязательныйgenerate_config)—используется для генерации звонковиз Временный параметризованный словарь。связанный generate извесь Обзор,пожалуйста, проверьтеСледующее руководство。 - max_new_tokens(
int,Необязательный)— Чтобы сгенерировать максимальное количество токенов, игнорируйте количество токенов в подсказке.
2.3.3 возвращаемые параметры объекта конвейера
- текст(
str):идентифицироватьизтекст。 - chunks(Необязательный(,
List[Dict])при использованииreturn_timestamps,chunksстанетдлясписок,Содержит все различные текстовые блоки для идентификации модели.,Например*[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}]。проходить执行可以粗略地恢复оригинальныйполный текст"".join(chunk["text"] for chunk in output["chunks"])。
2.4 конвейер, реальный бой
2.4.1 facebook/wav2vec2-base-960h (модель по умолчанию)
Модель конвейера по умолчанию для автоматического распознавания речи — facebook/wav2vec2-base-960h. Если при использовании конвейера вы зададите только параметр Task=automatic-Speech-recognition и не зададите модель, будет загружена и использована модель по умолчанию. .
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition")
result = pipe(speech_file)
print(result)Вы можете конвертировать аудио в формате .mp3 в текст:
{'text': "WELL TO DAY'S STORY MEETING IS OFFICIALLY STARTED SOMEONE SAID THAT YOU HAVE BEEN TELLING STORIES FOR TWO OR THREE YEARS FOR SUCH A LONG TIME AND YOU STILL HAVE A STORY MEETING TO TELL"}2.4.2 openai/whisper-medium
Указываем модель openai/whisper-medium, конкретный код:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
result = pipe(speech_file)
print(result)На входе — фрагмент речи в формате mp3, на выходе —
{'text': " Well, today's story meeting is officially started. Someone said that you have been telling stories for two or three years for such a long time, and you still have a story meeting to tell."}2.5 Рейтинг моделей
По Huggingface фильтруем Автоматическое распознавание речи Модель,И отсортировано по объему загрузки от большего к меньшему:
3. Резюме
В данной статье рассматривается конвейер трансформаторов. распознавание речи(automatic-speech-recognition)от Обзор、Технические принципы、параметры трубопровода、настоящий бой на трубопроводе, ранжирование модели и другие аспекты. Читатели могут использовать минималистичный код в статье для проведения Автоматического на основе конвейера. распознавание речьрассуждение, применяемое для распознавания речь, извлечение субтитров и другие бизнес-сценарии.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
