[Искусственный интеллект] Конвейер трансформеров (1): аудиоклассификация (аудиоклассификация)
1. Введение
Pipeline (конвейер) — это минималистичный способ использования абстракции рассуждений больших моделей в библиотеке преобразователей Huggingface. Все большие модели делятся на аудио (Audio), компьютерное зрение (Computer Vision), обработку естественного языка (NLP), мультимодальные (Multimodal). ) и другие 4 большие категории, а также 28 малых категорий задач (задач). Охватывает в общей сложности 320 000 моделей.
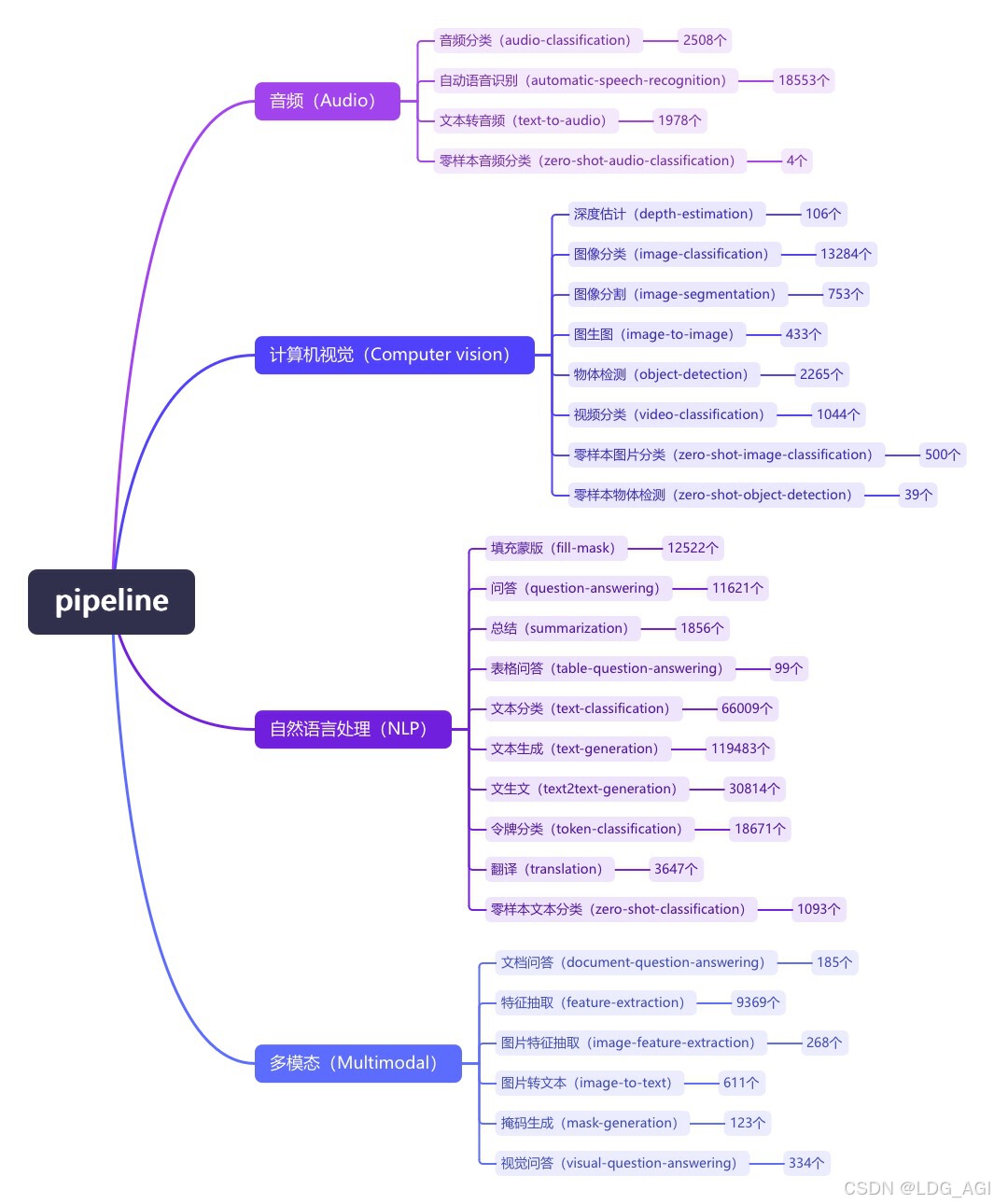
Сегодня я представляю первую статью об аудио-аудио, аудио-классификации. В библиотеке HuggingFace имеется 2500 моделей классификации аудио.
2. Аудио-классификация
2.1 Обзор
Классификация аудио,Как следует из названия, это означает Аудио Ярлыкилиназначенная категория Задача。Основные сценарии применения:Классификация речевых эмоций、Категории голосовых команд、Классификация динамиков、Определение музыкального стиля、языковая дискриминацияждать。
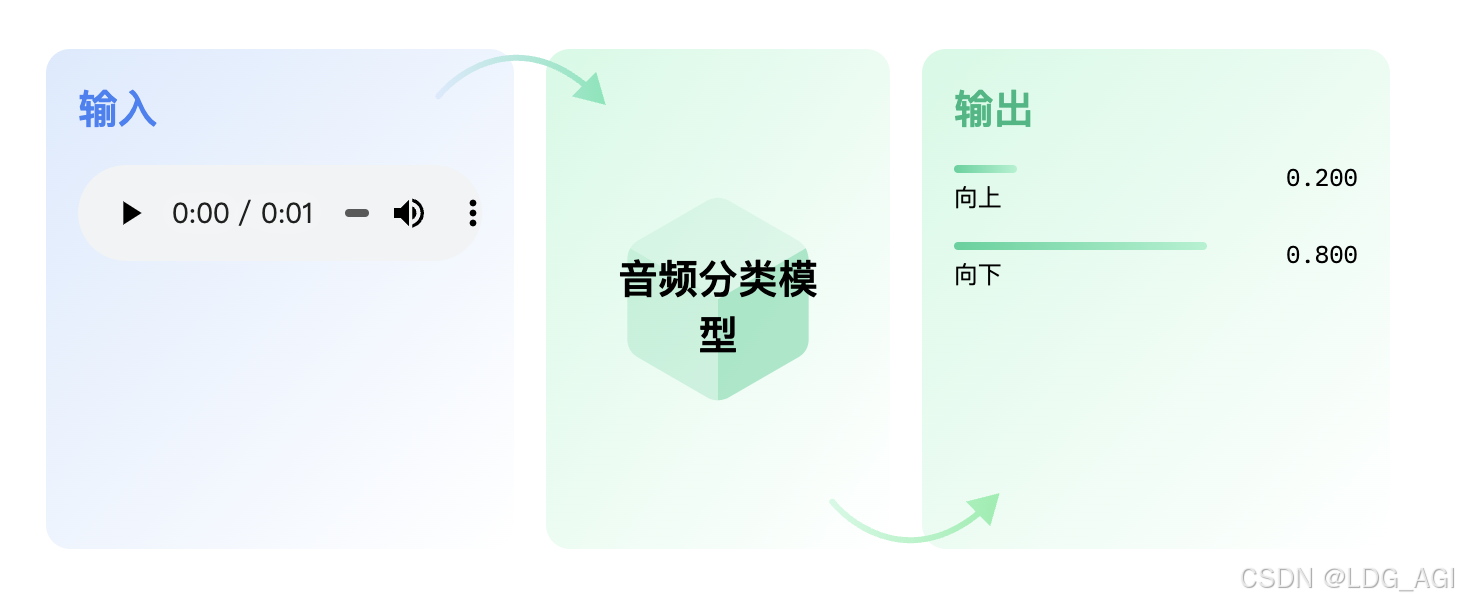
2.2 Технические принципы
Основная идея классификации звука состоит в том, чтобы разрезать спектр звука на сегменты по 25–60 мс, извлечь признаки с помощью моделей сверточных нейронных сетей, таких как CNN, и встроить их, а также обучить на основе выравнивания преобразователя с текстовыми категориями. Ниже представлены две репрезентативные модели:
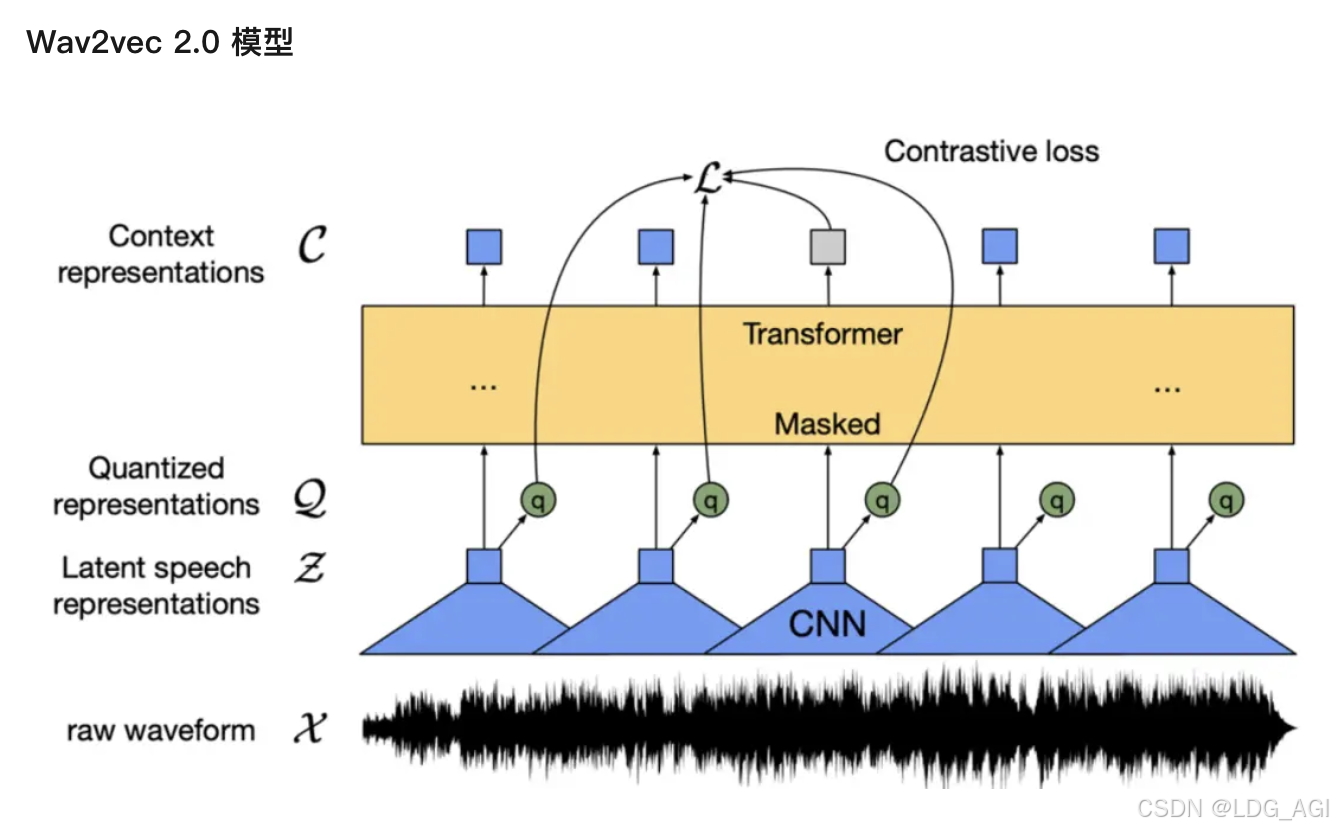
2.2.1 Модель Wav2vec 2.0
Wav2vec 2.0 — это модель предварительной тренировки речи без учителя, опубликованная Meta в 2020 году. Его основная идея состоит в том, чтобы создать самостоятельно созданную контролируемую обучающую цель с помощью векторного квантования (VQ), замаскировать входные данные в больших количествах, а затем использовать функцию контрастных потерь обучения для обучения. Структура модели показана на рисунке. Экстрактор признаков на основе сверточной нейронной сети (CNN) кодирует исходный звук в последовательность признаков кадра и преобразует каждый признак кадра в дискретный признак Q через используемый модуль VQ. как самоконтролируемая цель. В то же время последовательность признаков кадра подвергается операции маскировки и затем поступает в модель Трансформера [5] для получения контекстного представления C. Наконец, благодаря контрастной функции потерь обучения расстояние между контекстным представлением положения маски и соответствующим дискретным признаком q, то есть парой положительных образцов, сокращается.
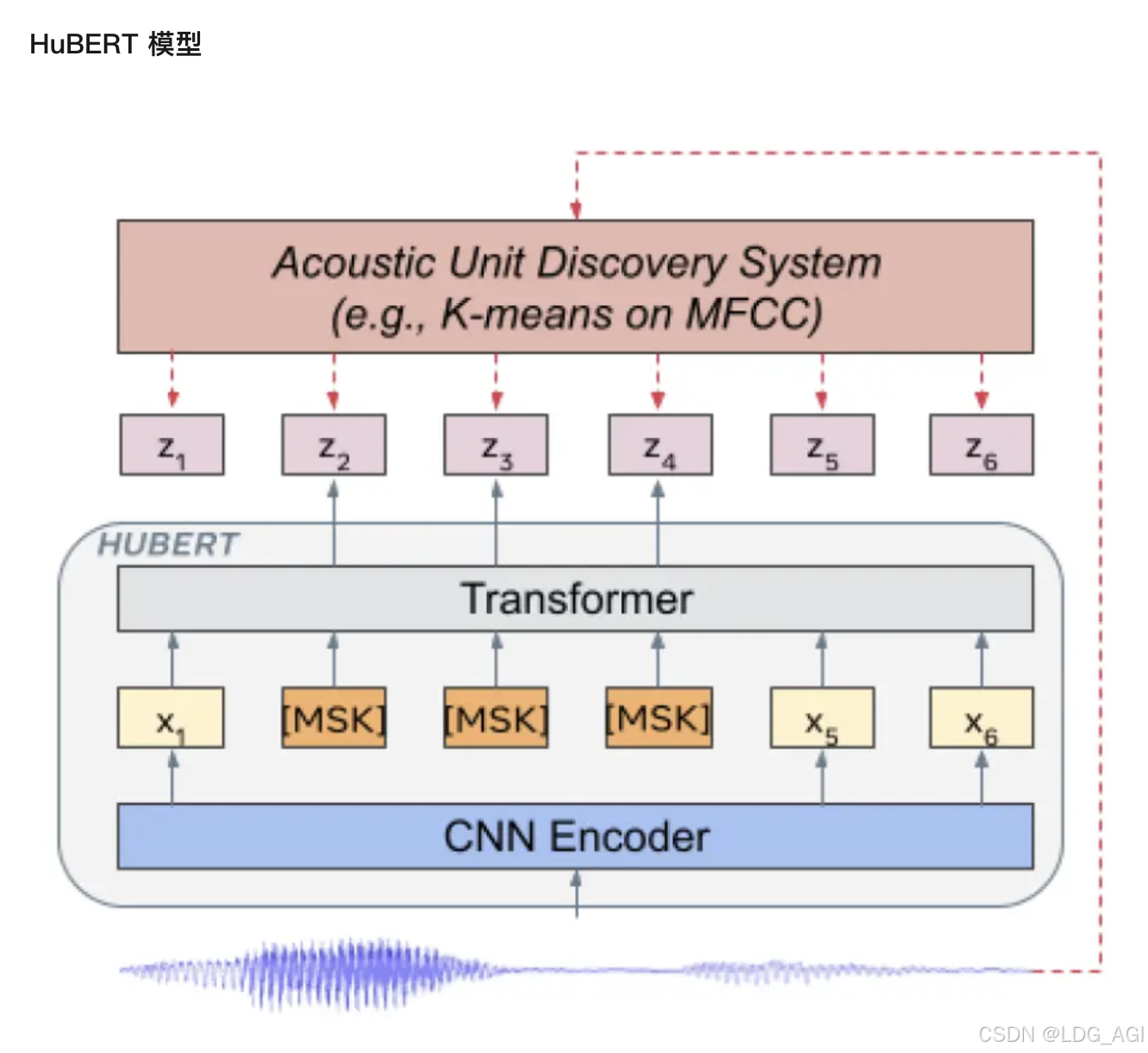
2.2.1 Модель HuBERT
HuBERT — модель, выпущенная Meta в 2021 году. Структура модели аналогична Wav2vec 2.0, но разница заключается в методе обучения. Wav2vec 2.0 дискретизирует речевые характеристики как самоконтролируемую цель во время обучения, в то время как HuBERT получает цель обучения, выполняя кластеризацию K-средних по функциям MFCC или функциям HuBERT. Модель HuBERT использует итеративный метод обучения. Первая итерация модели BASE выполняет кластеризацию по признакам MFCC. Вторая итерация выполняет кластеризацию по функциям среднего уровня модели HuBERT, полученным в первой итерации. Модели LARGE и XLARGE используют. вторая итерация модели BASE извлекает функции для кластеризации. Судя по экспериментальным результатам оригинальной статьи, модель HuBERT лучше, чем Wav2vec 2.0, особенно когда последующие задачи имеют очень мало данных контролируемого обучения, например 1 час или 10 минут.
2.3 параметры трубопровода
2.3.1 Параметры создания объекта конвейера
- Модель(PreTrainedModelилиTFPreTrainedModel)— Модель, которую конвейер будет использовать для прогнозирования. для PyTorch,Это требуетPreTrainedModelнаследовать;для TensorFlow,Это требуетУнаследовано от TFPreTrainedModel.
- feature_extractor ( SequenceFeatureExtractor ) — Экстрактор функций, который конвейер будет использовать для кодирования данных для модели. Этот объект наследуется от SequenceFeatureExtractor。
- modelcard(
strилиModelCard,Необязательный) — Карты моделей, принадлежащие этому конвейеру Модель. - framework(
str,Необязательный)— структура для использования,"pt"Применимо к PyTorch или"tf"TensorFlow。Указанный фреймворк должен быть установлен。 Если платформа не указана, по умолчанию используется установленная в данный момент платформа. Если платформа не указана и установлены две платформы, по умолчанию используется значение рамкаmodel,Если Модель не указана,По умолчанию используется PyTorch. - Задача(
str,По умолчанию"")— Идентификатор задачи канала. - num_workers(
int,Необязательный,По умолчанию 8)— Когда трубопровод будет использоватьDataLoader(При передаче набора данных,существовать Pytorch Модель的 GPU выше), количество рабочих, которые будут использоваться. - batch_size(
int,Необязательный,По умолчанию 1)— Когда трубопровод будет использоватьDataLoader(При передаче набора данных,Когда на графическом процессоре модели Pytorch,Размер используемой партии,для рассуждений,Это не всегда выгодно,Пожалуйста, прочитайтеИспользование конвейеров для пакетной обработки。 - args_parser(ArgumentHandler,Необязательный) - Ссылка на объект, ответственный за анализ предоставленных параметров конвейера.
- оборудование(
int,Необязательный,По умолчанию -1)— CPU/GPU Поддерживаемые серийные номера оборудования. установите его на -1 будет использовать ЦП, установка положительного числа приведет к соответствующему CUDA оборудование ID беги дальше Модель。Вы можете передать роднойtorch.deviceилиstrслишком - torch_dtype(
strилиtorch.dtype,Необязательный) - Отправить напрямуюmodel_kwargs(Просто более простой ярлык)использовать это Модельдоступная точность(torch.float16,,torch.bfloat16...или"auto") - binary_output(
bool,Необязательный,По умолчаниюFalse)——Флаг, указывающий, должен ли вывод канала быть в сериализованном формате.(即 рассол) или необработанные выходные данные (например, текст).
2.3.2 Параметры использования объекта конвейера
- входить(
np.ndarrayилиbytesилиstrилиdict) — входитьможет быть:strЭто Аудиоимя файла,Файл будет читаться с правильной частотой дискретизации.ffmpegПолучить сигнал。这需要существовать系统上安装ffmpeg 。bytesэто должно быть Аудиосодержимое файла,и таким же образом черезffmpeg объясняет.- (
np.ndarrayФорма(n,)Типnp.float32илиnp.float64)Правильная частота дискретизации оригинала Аудио(никаких дополнительных проверок) dictФорма может использоваться для передачи произвольных выборок необработанных данных.Аудиоsampling_rate,и пусть этот конвейер выполнит повторную выборку。Словарь должен использовать или Формат{"sampling_rate": int, "raw": np.array},{"sampling_rate": int, "array": np.array}где ключ"raw"или"array"используется для обозначения оригинала Аудиоформа волны。
- top_k(
int,Необязательный,По умолчанию None)— Количество верхних меток, которые вернет конвейер.。如果提供的数字ждать于Noneиливыше, чем Модель Количество тегов, доступных в конфигурации,по умолчанию будет указано количество тегов.
2.4 конвейер, реальный бой
2.4.1 Идентификация инструкций (модель по умолчанию)
Модель конвейера для классификации звука по умолчанию — super/wav2vec2-base-superb-ks. Если при использовании конвейера вы задаете только Task=audio-classification и не задаете модель, будет загружена и использована модель по умолчанию.
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="audio-classification")
result = pipe(speech_file)
print(result)Это модель распознавания инструкций «вверх», «вниз», «влево», «вправо» и «нет», которая напоминает дрессировку животного.
[{'score': 0.9988580942153931, 'label': '_unknown_'}, {'score': 0.000909291033167392, 'label': 'down'}, {'score': 9.889943612506613e-05, 'label': 'no'}, {'score': 7.015655864961445e-05, 'label': 'yes'}, {'score': 5.134344974067062e-05, 'label': 'stop'}]2.4.2 Распознавание эмоций
Мы указываем модель как модель распознавания эмоций ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition. Конкретный код:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="audio-classification",model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition")
result = pipe(speech_file)
print(result)На входе — фрагмент речи в формате mp3, на выходе —
[{'score': 0.13128453493118286, 'label': 'angry'}, {'score': 0.12990005314350128, 'label': 'calm'}, {'score': 0.1262471228837967, 'label': 'happy'}, {'score': 0.12568499147891998, 'label': 'surprised'}, {'score': 0.12327362596988678, 'label': 'disgust'}]2.5 Рейтинг моделей
На HuggingFace мы фильтруем модели классификации аудио и сортируем их по объему загрузки от высокого к меньшему:
3. Резюме
В этой статье представлена аудиоклассификация (аудиоклассификация) конвейера трансформаторов с точки зрения обзора, технических принципов, параметров конвейера, практики работы с конвейерами, ранжирования моделей и т. д. Читатели могут использовать код в статье для обоснования классификации аудио на основе находится в стадии разработки и применить его к бизнес-сценариям, таким как распознавание звуковых эмоций и определение музыкального жанра.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
