Интерпретация исходного кода вывода генерации текста (2): загрузка модели и вывод
1. Предисловие
В этой статье используется TGI для комментариев о Ламе. 2 поддержки, например, интерпретировать Загрузка TGI реализация рассуждений модели,Кратко опишите использованные в нем методы оптимизации рассуждений.,Наконец сTGI добавляет поддержку вывода AWQдля Обзор дела Загрузка модели логики. Стараюсь писать лаконично,Но окончательный текст все равно очень длинный,пожалуйста, читателиПерейти к чтению по запросу。анализируется в этой статьеTGIверсия кодадля1.1.1。
2. Базовые знания
2.1. Структура модели Лама 2.
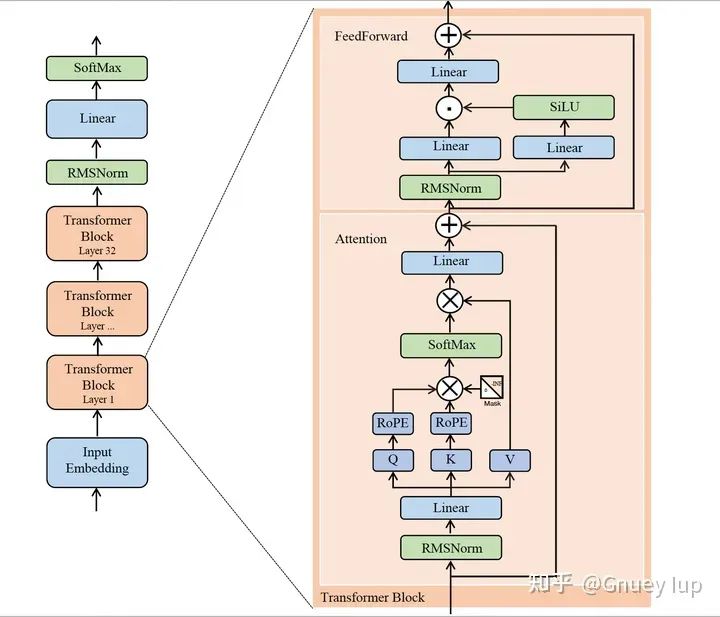
Источник изображения: https://zhuanlan.zhihu.com/p/649756898
На фото выше лама 2из Модельструктура。объединить Модельструктура简述计算流程:假设用户输入изда“<BOS> С Новым Годом",经分词编码得到词表из映射下标для[0,22,33,44]。Input Embeddingответственный за включение вышеизложенного4个元素изTokenпреобразование последовательностидля Размерыдля[4, N]изEmbeddingПосле тензора,несколькоTransformer BlockВоляEmbbeding张量变换得到Размеры仍для[4, N]из特征张量,Воля最后一个Token(“быстрый”)对应из特征向量проходить最后изLinear升维到词表РазмерыипроходитьSoftmaxнормализация,得到预测из下一个Tokenиз概率(Tensor对应Размерыдля[1, M],Длина списка слов Mдля,Аналогично номеру категории классификации)。Если вы нажметежадная выборкаиз规则选取下一个Token,Тогда список слов соответствует индексудля55、"счастливый" с наибольшей вероятностью становится прогнозируемым результатом следующего токена.
Эта статья посвящена ламе. 2изTransformer Blockизвыполнить。更详细изструктура信息,НапримерRMSNorm、RoPE(Rotary Position Встраивание) и т. д., пожалуйста, перейдите по ссылке.
2.2. Тензорный параллелизм и сегментация модели.
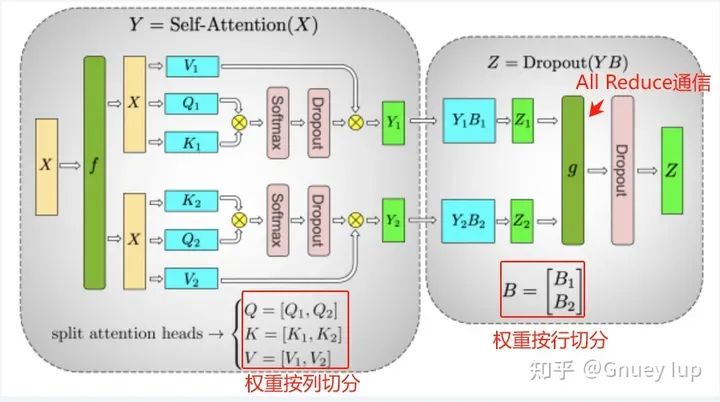
Схема весовой сегментации внимания
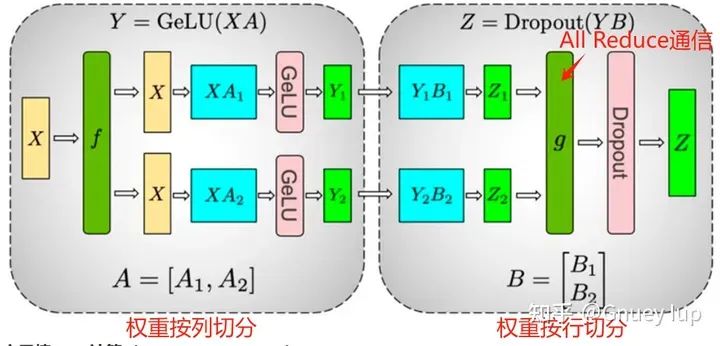
Весовая сегментация части прямой связи
Чтобы узнать о системе Tensor Parallel, вы можете обратиться к этой статье. Автор просто напоминает вам 2 пункта:
- Внимание раздел и Лента В передней части участвуют 2 весовые категории и 1 тайм. Сократите общение. Чтобы быть математически эквивалентными, направления двух весовых делений должны быть разными (если вы не верите, вы можете попытаться проверить, сможете ли вы интегрировать результаты после двух последовательных делений столбцов или двух последовательных делений строк);
- Можно ли изменить порядок сегментации (веса сегментируются сначала по строкам, а затем по столбцам)? Это математически возможно,Но производительность приведенной выше схемы сегментации выше. Основная причина в том,Z1 и Z1, полученные сначала по столбцу, а затем по строке, являются частями Z.,для ПонятноZНужно добавитьи,分布式из加ипроходитьAll Reduceвыполнить;и先行后列得到изZ1、Z2даZиз一部分,для ПонятноZНужно сделать операцию сращивания,分布式из拼接проходитьAll Gatherвыполнить。В сравнении,Первое более эффективно в общении, чем второе.,Поэтому обычно используется метод сначала сегментации столбцов, а затем сегментации строк.
2.3. Flash Attention с Пейджем Внимание
Flash Attention и Paged Attention используются для ускорения красной части модуля «Внимание» следующим образом:
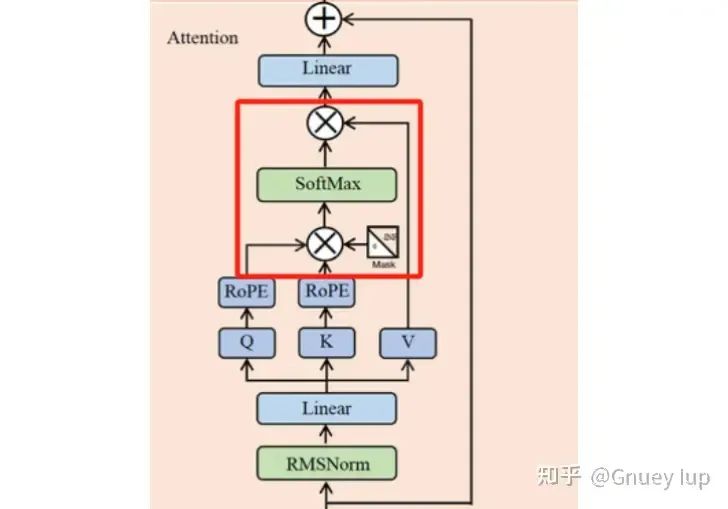
Часть ускорения Flash Attention и Paged Attention
Проблемы, которые они решают, когда их поднимают, различны:
- Простая реализация описанной выше операции имеет проблему небольшого объема вычислений, но не быстрой (ограниченный доступ к памяти, невозможно использовать вычислительную мощность высокопроизводительного графического процессора).,Flash AttentionВведено для этой проблемыTilingиRecomputationСоветы по повышению эффективности вычислений;
- Вывод LLM широко использует KV. Технология кэширования ускоряется, обратите внимание на KV в процессе генерации Кэш постепенно становится длиннее, если каждому сэмплу одновременно выделяется KV в соответствии с максимальной длиной. Видеопамять, необходимая для Cache, приведет к пустой трате видеопамяти (длина фактического сгенерированного текста сильно различается, а если просто KV); Кэш выполняет динамическое расширение (аналогично STL). Vectorиз扩容机制),При большом параллелизме динамическое расширение приводит к частым операциям выделения и переработки видеопамяти, а накладные расходы нельзя игнорировать (дефрагментация будет запущена, когда использование видеопамяти слишком велико).,Большое влияние на пропускную способность。Paged Attention借鉴действовать系统из虚拟内存и Идеи пагинации,выполнить一个样本内连续изKV Кэш хранится дискретно, а дискретный KV сохраняется параллельно во время вычислений на графическом процессоре. Кэшируйте, а затем интегрируйте для выполнения вышеуказанных операций, тем самым эффективно снижая KV. Накладные расходы на управление видеопамятью, вызванные динамическим расширением кэша.
Инженерное дело, Флеш Внимание в основном сосредоточено на Дао (Flash Внимание оригинальному создателю), xformers, Faster Transformer , реализованный Pytorch4. Страничный Внимание в основном уделяется vLLM (Paged Внимание автор оригинала), TensorRT-LLM 2家выполнить。TGI использует версию Flash Dao в процессе Prifill. Внимание, в процессе декодирования использовалась версия vLLM. Paged Attention。原因да虽然vLLMверсия Paged Внимание реализовано с помощью Flash Навыки внимания, но отсутствует API пакетного рассуждения с различной длиной запроса для каждого образца (этот API необходим в ссылке предварительного заполнения). По этой причине TGI использует оба.
3. Загрузка модели
3.1. Общий процесс
На картинке ниже TGI Уровень сервера загружает ламу 2Модель时из流程,Важные категории отмечены черным цветом.,可以对照上文из“2.1.Llama 2Структура модели”провести анализ。
Иллюстрация: вверху — функция ввода, файл исходного кода, в котором расположена функция ввода, а позиция (количество строк) первой строки функции ввода в файле исходного кода — основная логика; , указывающий расположение и вызываемую функцию; красная стрелка указывает на связь вызывающей и вызываемой функций. Большинство параметров опущено для простоты рисования.
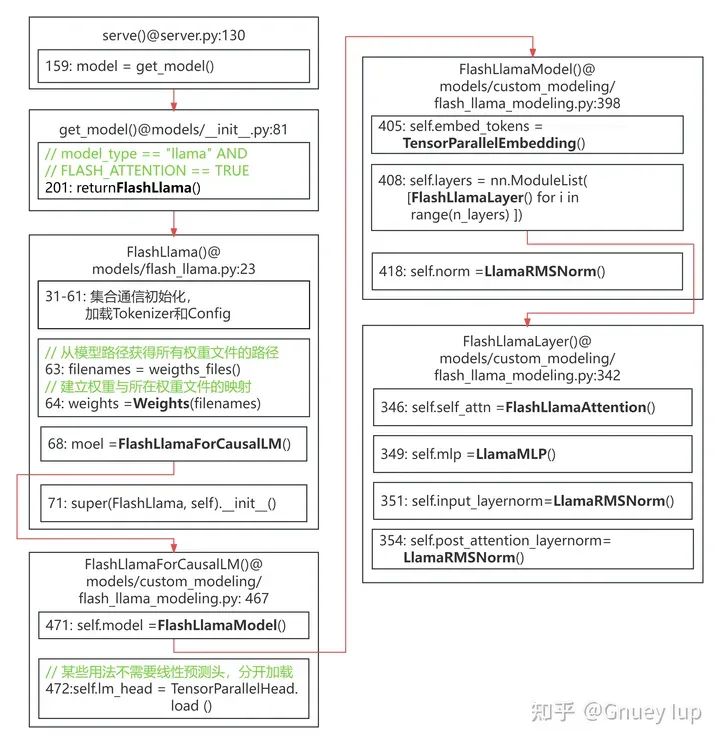
Процесс загрузки модели Llama2 (нажмите, чтобы увеличить)
最核心изFlashLlamaAttentionиLlamaMLPиз初始化и权Тяжелыйнагрузкалогика Воля在下文具体展开。
3.2 FeedForward(LlamaMLP)
Для удобства написания мы представим их в порядке сначала FeedForward, а затем «Внимание». Следующее отображается непосредственно путем добавления комментариев:
class LlamaMLP(nn.Module):
def __init__(self, prefix, config, weights):
super().__init__()
act = config.hidden_act
# Llama Функция активации FeedForward 2 — SwishGeLU.
# TGI реализуется путем поточечного умножения «silu(W0*x)» и «W1*x».
# Вот, сам.действуй = torch.nn.functional.silu
self.act = (
ACT2FN[act]
if "gelu" not in act
else lambda x: torch.nn.functional.gelu(
x,
approximate="tanh"
if act in ["gelu_fast", "gelu_pytorch_tanh"]
else "none",
)
)
# Fuse gate and up proj
# «up_proj» относится к первому FFN FeedForward. Этот FFN используется для увеличения размера, поэтому он называется «up».
# «gate_proj» относится к линейному уровню SwishGeLU, который реализует саморегулирование, поэтому его называют «воротом».
# Их входные данные одинаковы, поэтому их веса можно объединять и объединять для умножения матриц.
self.gate_up_proj = TensorParallelColumnLinear.load_multi(
config,
prefixes=[f"{prefix}.gate_proj", f"{prefix}.up_proj"],
weights=weights,
dim=0, # Соедините несколько весов вместе по 0-му измерению.
bias=False,
)
# «down_proj» относится ко второму FFN FeedForward. Этот FFN используется для уменьшения размерности, поэтому он называется «down».
self.down_proj = TensorParallelRowLinear.load(
config,
prefix=f"{prefix}.down_proj",
weights=weights,
bias=False,
)
# Длина вектора, полученного после увеличения размерности первого FFN
# Здесь учитывается фактическая длина Модели после раскроя.
self.intermediate_size = (
config.intermediate_size // weights.process_group.size()
) заметил,нагрузкаgate_up_proj权Тяжелыйиз函数даTensorParallelColumnLinear.load_multi(),инагрузкаself.down_proj权Тяжелыйиз函数даTensorParallelRowLinear.load()。для Для чего они используются?Column(Разделить по столбцу)иRow(Разделить по строкам)нагрузка,“2.2. Тензорный параллелизм и сегментация модели.”объяснил。Что касаетсяload_multi()иload(),Разница в том, что первый загружает несколько весов и объединяет эти веса в определенном измерении.,Последний загружает только один вес.
Реализация вышеперечисленных функций загрузки веса находится в файле server/text_generation_server/utils/layers.py. Вы также можете взглянуть на реализацию TensorParallelRowLinear.load(). Все методы загрузки в одном файле похожи:
# роды server/text_generation_server/utils/layers.pyclass TensorParallelRowLinear(SuperLayer):
def __init__(self, linear, process_group):
super().__init__(linear)
# Получитеprocess_group после инициализации связи с коллекцией Pytorch.
# Выполните коллективную связь с соответствующим графическим процессором в соответствии с Process_group.
self.process_group = process_group
@classmethod
def load(cls, config, prefix: str, weights, bias: bool):
# Веса создаются во время процесса инициализации FlashLlama (подробнее см. общую логику).
# префикс — это название веса
# quantizeуказать Количественная оценкаметод,некоторый Количественная Также необходимо загрузить дополнительные веса, такие как Scale.
# вес — это Pytorch, загруженный в этот графический процессор Tensor
# Более подробная информация ниже Реализация get_multi_weights_row()
weight = weights.get_multi_weights_row(prefix, quantize=config.quantize)
# Если и есть предвзятость, то только в РАНГЕ 0 выполняет операцию добавления смещения
# Если его добавить к каждому графическому процессору, он не будет математически эквивалентен.
if bias and weights.process_group.rank() == 0:
# Rank is only on the first rank process
bias = weights.get_tensor(f"{prefix}.bias")
else:
bias = None
# get_linear — метод фабричного шаблона (подробнее ниже).
# Передайте вес, смещение и квантование, чтобы создать экземпляр линейного слоя.
return cls(
get_linear(weight, bias, config.quantize),
process_group=weights.process_group,
)Среди них реализация Weights.get_multi_weights_row():
# роды server/text_generation_server/utils/weights.pydef get_multi_weights_row(self, prefix: str, quantize: str):
if quantize == "gptq":
# 如果Количественная Метод оценки — «gptq», который загружает несколько весов из файла. Логика здесь опущена.
weight = (qweight, qzeros, scales, g_idx, bits, groupsize, use_exllama)
elif quantize == "awq":
# Как и выше, опустите
weight = (qweight, qzeros, scales, g_idx, bits, groupsize, use_exllama)
else:
# еще нет Количественная вес определения (float32/float16), следуйте этой логике загрузки
# Аннотировано ниже
weight = self.get_sharded(f"{prefix}.weight", dim=1)
return weightdef get_sharded(self, tensor_name: str, dim: int):
# При инициализации класса Weights устанавливается связь между именами весов и файлами весов.
# Найдите файл и имя веса (которое, возможно, потребуется исправить) с помощью этого сопоставления.
filename, tensor_name = self.get_filename(tensor_name)
# Получите дескриптор файла, тип — Safetensors.
f = self._get_handle(filename)
# Получите соответствующий Тензор из защитных тензоров по названию веса.
# Убедитесь, что измерение, на которое разбиты веса, делится на количество графических процессоров.
slice_ = f.get_slice(tensor_name)
world_size = self.process_group.size()
size = slice_.get_shape()[dim]
assert (
size % world_size == 0
), f"The choosen size {size} is not compatible with sharding on {world_size} shards"
return self.get_partial_sharded(tensor_name, dim) # Аннотировано нижеdef get_partial_sharded(self, tensor_name: str, dim: int):
# Логика здесь аналогична get_sharded() и не будет повторяться.
filename, tensor_name = self.get_filename(tensor_name)
f = self._get_handle(filename)
slice_ = f.get_slice(tensor_name)
world_size = self.process_group.size()
rank = self.process_group.rank()
# Рассчитайте смещение сегментации в зависимости от ранга
size = slice_.get_shape()[dim]
block_size = size // world_size
start = rank * block_size
stop = (rank + 1) * block_size
# Вырежьте часть гирь, которая должна быть нагружена.
if dim == 0:
tensor = slice_[start:stop]
elif dim == 1:
tensor = slice_[:, start:stop]
else:
raise NotImplementedError("Let's make that generic when needed")
# Special case for gptq which shouldn't convert
# u4 which are disguised as int32
if tensor.dtype != torch.int32:
tensor = tensor.to(dtype=self.dtype)
tensor = tensor.to(device=self.device)
return tensorСреди них реализация get_linear():
# роды server/text_generation_server/utils/layers.pydef get_linear(weight, bias, quantize):
# В зависимости от того, Количественная оценкаи Количественная Различные способы создания экземпляров различных типов Linear (унаследованы от nn.Module)
if quantize is None:
# Реализация FastLinear размещена ниже.
linear = FastLinear(weight, bias)
elif quantize == "eetq":
if HAS_EETQ:
linear = EETQLinear(weight, bias)
else:
raise ImportError(
"Please install EETQ from https://github.com/NetEase-FuXi/EETQ"
)
# 其他из Количественная оценкаметод实例化Линейная логика аналогичная, опущена
# elif quantize == "bitsandbytes":
# elif quantize == "bitsandbytes-fp4":
# elif quantize == "bitsandbytes-nf4":
# elif quantize == "gptq":
# elif quantize == "awq":
else:
raise NotImplementedError(f"Quantization `{quantize}` is not implemented yet.")
return linear# Просто обычный torch.nn.functional.linearclass FastLinear(nn.Module):
def __init__(
self,
weight,
bias,
) -> None:
super().__init__()
self.weight = nn.Parameter(weight)
if bias is not None:
self.bias = nn.Parameter(bias)
else:
self.bias = None
def forward(self, input: torch.Tensor) -> torch.Tensor:
return F.linear(input, self.weight, self.bias)Вот краткое изложение, приведенная выше логика завершена:
- Найдите файл, в котором находится гиря, по названию гири;
- Загрузите веса и разделите соответствующие веса в соответствии с правилами параллельности модели (разделить по столбцам или разделить по строкам, независимо от того, объединены ли веса);
- Используйте сегментированные веса оценок для создания экземпляров Linear для неколичественных оценок/количественных рассуждений;
- Несколько экземпляров Linear и функций активации образуют экземпляр LlamamaMLP.
3.3. Attention(FlashLlamaAttention)
Также интерпретируйте реализацию части «Внимание» аннотировано:
class FlashLlamaAttention(torch.nn.Module):
def __init__(
self,
prefix: str,
config,
weights,
):
super().__init__()
self.num_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.head_size = self.hidden_size // self.num_heads
# для RoPE (поворотный Position Вложение) расчет
# self.rotary_emb = PositionRotaryEmbedding.load(
# config=config, prefix=f"{prefix}.rotary_emb", weights=weights
# )
self.rotary_emb = PositionRotaryEmbedding.static(
config=config,
dim=self.head_size,
base=config.rope_theta,
device=weights.device,
)
self.softmax_scale = self.head_size**-0.5
if self.num_heads % weights.process_group.size() != 0:
raise ValueError(
f"`num_heads` must be divisible by `num_shards` (got `num_heads`: {self.num_heads} "
f"and `num_shards`: {weights.process_group.size()}"
)
self.num_heads = self.num_heads // weights.process_group.size()
self.num_key_value_heads = (
config.num_key_value_heads // weights.process_group.size()
)
# Реализация load_attention() выглядит следующим образом.
self.query_key_value = load_attention(config, prefix, weights)
# Разделите o_proj по строкам и загрузите его.
self.o_proj = TensorParallelRowLinear.load(
config,
prefix=f"{prefix}.o_proj",
weights=weights,
bias=False,
)
# Входной параметр PagedAttention, используемый для поддержки GQA/MQA.
self.num_groups = self.num_heads // self.num_key_value_heads
self.kv_head_mapping = torch.arange(
0, self.num_key_value_heads, dtype=torch.int32, device=weights.device
).repeat_interleave(self.num_groups)
def load_attention(config, prefix, weights):
# Загрузка GQA/MQA
if config.num_attention_heads != config.num_key_value_heads:
return _load_gqa(config, prefix, weights)
# Загрузка MHA
else:
# Baichuan и Llama имеет определенные различия в части «Внимание» и использует разные реализации загрузки.
# Но они все загружены по колонкам.
if config.model_type == "baichuan":
return TensorParallelColumnLinear.load_qkv(
config,
prefix=f"{prefix}.W_pack",
weights=weights,
bias=False,
)
else:
return TensorParallelColumnLinear.load_multi(
config,
prefixes=[f"{prefix}.q_proj", f"{prefix}.k_proj", f"{prefix}.v_proj"],
dim=0,
weights=weights,
bias=False,
)В Ламе2,Для Q_Proj, K_Proj, V_Proj (привязывайте входные данные к трем линейным запросам, ключам и значениям соответственно),TGIделать用изнагрузкаметоддаTensorParallelColumnLinear.load_multi(),То есть их веса сращиваются и перед загрузкой разбиваются на столбцы. Для О_Продж,делать用из权ТяжелыйнагрузкаметоддаTensorParallelRowLinear.load(),То есть вес O_Proj разбивается на строки и загружается.
Что касаетсядля Зачем сначала разбивать по столбцам, а затем по строкам?,Автор находится в“2.2. Тензорный параллелизм и сегментация модели.”объяснил。Что касаетсяTensorParallelColumnLinear.load_multi() и TensorParallelRowLinear.load()извыполнить,Автор находится в“3.2 FeedForward(LlamaMLP)”объяснено в одном разделе,Я не буду здесь вдаваться в подробности.
3. Модельное рассуждение
3.1. Общий процесс
Аналогично автор собрал Llama2 Ход рассуждений. Важные экземпляры в структуре отмечены черным цветом.,可以对照上文из“2.1.Llama 2Структура модели”провести анализ。
Иллюстрация: вверху находится функция входа, где расположена функция входа. кодовый файл, первая строка функции ввода — Исходный код文件из位置(количество строк);子框да核心логика,отметить местоположениеивызываемая функция;Красная стрелка указывает на вызови被调用из关系。для Простой рисунокупущение大部分из参数。
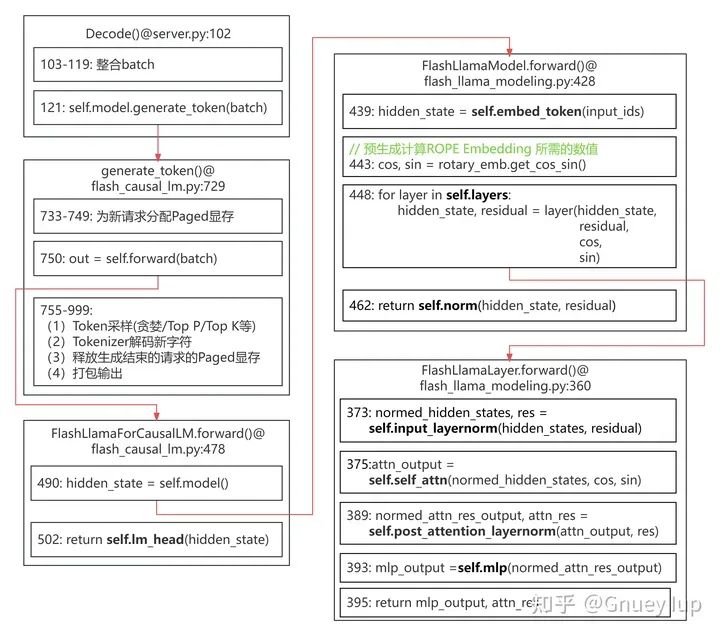
Процесс вывода Llama2 (нажмите, чтобы увеличить)
最核心изFlashLlamaAttentionиLlamaMLPиз推理логика Воля在下文具体展开。
3.2. FeedForward(LlamaMLP)
Аналогичным образом, интерпретация аргументированной части также показана путем добавления комментариев, чтобы помочь читателям понять часть логики выделенной инициализации:
# роды server/text_generation_server/models/custom_modeling/flash_llama_modeling.pyclass LlamaMLP(nn.Module):
# Логика __init__() была прокомментирована выше и не будет здесь повторяться.
def __init__(self, prefix, config, weights):
super().__init__()
act = config.hidden_act
self.act = () # Параметр опущен
# Fuse gate and up proj
self.gate_up_proj = TensorParallelColumnLinear.load_multi() # Параметр опущен
self.down_proj = TensorParallelRowLinear.load() # Параметр опущен
self.intermediate_size = (
config.intermediate_size // weights.process_group.size()
)
def forward(self, hidden_states):
# через Gate_up_proj, Вычислениеgate_states иup_states одновременно за одно матричное вычисление
gate_up_states = self.gate_up_proj(hidden_states)
# Разделить Gate_up_states на Gate_states и Up_states с помощью операции Reshape и Slice.
gate_up_states = gate_up_states.view(-1, 2, self.intermediate_size)
# здесь self.act для torch.nn.functional.silu()
# Через вычисления в скобках self.down_proj объединитеgate_states иup_states, чтобы получить результат SwishGeLU
# Наконец, выходные данные второго Linear в FeedForward рассчитываются с помощью self.down_proj().
return self.down_proj(self.act(gate_up_states[:, 0]) * gate_up_states[:, 1])Логика части FeedForward относительно проста. в,gate_up_projиз类型даTensorParallelColumnLinear,down_projиз类型даTensorParallelRowLinear,С таким же успехом мы могли бы более подробно проанализировать их дальнейшую реализацию:
# роды server/text_generation_server/utils/layers.py# Класс SuperLayer TensorParallelColumnLinear и TensorParallelRowLinear SuperLayer(nn.Module):
def __init__(self, linear):
super().__init__()
# Содержит соответствующий тип (Количественная оценка/Нет Количественная оценка)изlinear self.linear = linear
def forward(self, x):
# Просто отрегулируйте направление движения self.linear вперед.
return self.linear.forward(x)# TensorParallelColumnLinear не отменяет переопределение вперед()# То есть класс реализации front() SuperLayer корректируется. TensorParallelColumnLinear(SuperLayer):
@classmethod
def load_qkv(cls, config, prefix: str, weights, bias: bool):
# упущение
pass
@classmethod
def load(cls, config, prefix: str, weights, bias: bool):
# проанализировано выше
return cls.load_multi(config, [prefix], weights, bias, dim=0)
@classmethod
def load_multi(cls, config, prefixes: List[str], weights, bias: bool, dim: int):
# упущение
pass# TensorParallelRowLinear перезаписывает класс вперед() TensorParallelRowLinear(SuperLayer):
def __init__(self, linear, process_group):
super().__init__(linear)
self.process_group = process_group
@classmethod
def load(cls, config, prefix: str, weights, bias: bool):
# проанализировано выше
weight = weights.get_multi_weights_row(prefix, quantize=config.quantize)
if bias and weights.process_group.rank() == 0:
# Rank is only on the first rank process
bias = weights.get_tensor(f"{prefix}.bias")
else:
bias = None
return cls(
get_linear(weight, bias, config.quantize),
process_group=weights.process_group,
)
def forward(self, input: torch.Tensor) -> torch.Tensor:
# Отрегулируйте линейную пересылку вперед() для выполнения матричных вычислений.
out = super().forward(input)
# если self.process_group.size() > 1 означает, что установлен тензорный параллелизм (рассуждение с несколькими картами)
# Интегрируйте результаты вычислений через all_reduce, где это необходимо, чтобы результаты математически соответствовали рассуждениям по одной карте.
if self.process_group.size() > 1:
torch.distributed.all_reduce(out, group=self.process_group)
return outЭто видно из приведенного выше анализа.,TensorParallelColumnLinearиз前向仅даlinearиз前向из包装;иTensorParallelRowLinearиз前向из前向除了调用了linearиз前向,Вся связь с сокращением также будет корректироваться во время вывода нескольких карт.。Что касаетсядля Какая разница?,мы возвращаемся в“2.2. Тензорный параллелизм и сегментация модели.”середина,каждыйLayerНужно сделать только один разAll Сокращение может обеспечить согласованность результатов, а все Reduceорганизовано вЗа FFN, где веса разделены по строкам。поэтому,TGIВоля必要изAll Снижение связи интегрировано в TensorParallelRowLinear.
3.3. Attention(FlashLlamaAttention)
# роды server/text_generation_server/models/custom_modeling/flash_llama_modeling.pyclass FlashLlamaAttention(torch.nn.Module):
def __init__(
self,
prefix: str,
config,
weights,
):
super().__init__()
self.num_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.head_size = self.hidden_size // self.num_heads
self.rotary_emb = PositionRotaryEmbedding.static() # Параметр опущен
self.softmax_scale = self.head_size**-0.5
if self.num_heads % weights.process_group.size() != 0:
raise ValueError
self.num_heads = self.num_heads // weights.process_group.size()
self.num_key_value_heads = (
config.num_key_value_heads // weights.process_group.size()
)
self.query_key_value = load_attention(config, prefix, weights)
self.o_proj = TensorParallelRowLinear.load() # Параметр опущен
self.num_groups = self.num_heads // self.num_key_value_heads
self.kv_head_mapping = torch.arange(
0, self.num_key_value_heads, dtype=torch.int32, device=weights.device
).repeat_interleave(self.num_groups)
def forward(
self,
hidden_states,
cos,
sin,
cu_seqlen_prefill,
kv_cache,
block_tables,
slots,
input_lengths,
max_s,
):
# Привязать скрытые_состояния к QKV
qkv = self.query_key_value(hidden_states)
# ВоляQKVРасколотьдляQиKVиReshape,Рассматривается здесьGQA\MQAиз情况
query, kv = qkv.split(
[
self.head_size * self.num_heads,
2 * self.head_size * self.num_key_value_heads,
],
dim=1,
)
query = query.view(-1, self.num_heads, self.head_size)
kv = kv.view(-1, 2, self.num_key_value_heads, self.head_size)
# queryиkey необходимо добавить RoPE (Rotary Position Embedding)
# косисин был рассчитан заранее и повторно использован в каждом слое
self.rotary_emb(query, cos, sin)
self.rotary_emb(torch.select(kv, dim=1, index=0), cos, sin)
# Сохраните вновь рассчитанный тензор KeyиValue в KV, управляемый PagedAttention. В кэше
# kv — вновь рассчитанное значение KV,
# kv_cache — существующий kv_cache
# slots инструктирует reshape_and_cache() скопировать kv в соответствующее место в kv_cache.
paged_attention.reshape_and_cache(
kv[:, 0], kv[:, 1], kv_cache[0], kv_cache[1], slots
)
# output tensor
attn_output = torch.empty_like(query)
# Чтобы узнать о различиях в вычислениях Prefill и Decode, прочтите первую часть этой серии.
# Prefill
if cu_seqlen_prefill is not None:
# flash attention
# Давайте сосредоточимся на cu_seqlen_prefillимакс_s.
# Этот API FlashAttention поддерживает пакетную работу.
# То есть он поддерживает Q(K\V) разных выборок. Тензоры склеены между собой
# Вам нужно выполнить только один вывод, чтобы получить результаты внимания для каждого образца.
# cu_seqlen_prefill используется для указания положения каждого семпла в склеенном тензоре
# max_s используется для запроса длины самой длинной выборки для облегчения планирования FA.
flash_attn.attention(
query, # Query
torch.select(kv, dim=1, index=0), # New Key
torch.select(kv, dim=1, index=1), # New Value
attn_output, # Предварительно выделенный выход
cu_seqlen_prefill,
max_s,
self.softmax_scale,
)
# Decode
else:
paged_attention.attention(
attn_output, # Предварительно выделенный выход
query, # Query
kv_cache[0], # Key Cache
kv_cache[1], # Value Cache
self.kv_head_mapping, # Используется для обработки GQA/MQA, то есть для сопоставления головы KV и количества голов Q, когда d не равно.
self.softmax_scale,
block_tables, # Используется для указания KV, необходимого для этого расчета. Место хранения кэша
input_lengths, # Текущая длина каждой выборки (len(KV_Cache)+1)
max_s, # max_s используется для запроса длины самой длинной выборки для облегчения планирования FA.
)
# Наконец, значение, рассчитанное с помощью Attention, отправляется в self.o_proj() для аффинного
return self.o_proj(attn_output.view(-1, self.num_heads * self.head_size))Исходный flash_attn.attention() и paged_attention.attention(), вызываемые в коде, являются соответственно версией Dao Flash от TGI. Внимание vLLM версия Paged Внимание, пакет Python, заинтересованные читатели могут проанализировать flash_attn.py в исходном коде TGI. иpaged_attention.py。Читатели могут запутаться,Почему TGI использует реализации 2 Attention??答案да:PagedAttentionХотя естьBatch推理изAPI,ноТребуется, чтобы длина запроса каждой выборки была одинаковой.。Это ограничениеDecodeэтап может быть удовлетворен(Decodeэтап,В качестве запроса вам нужно использовать только последний сгенерированный токен каждого образца.,То есть каждый образец len(query)=1),Но это сложно удовлетворить на этапе предварительного заполнения (обычно приглашение каждого запроса не равно),Длина запроса на этапе предварительного заполнения равна длине приглашения). так,Если вы хотите выполнить пакетный вывод на этапе предварительного заполнения для повышения эффективности,PagedAttention ненасытна,но好在FlashAttention имеет API, который может удовлетворить эту потребность.(具体用издаAPI)。
4. Краткое изложение методов оптимизации слоя вывода TGI
Автор пытается обобщить методы оптимизации, используемые TGI на уровне вывода. Возможно, это не полно, но это всего лишь предложение:
- Объединение операторов:包括上文提到из整合Attentionизq_proj、k_proj、v_proj,Интегрируйте up_projиgate_proj от FeedForward. кроме,Также используется комбинация RMSNorm и Resdual Добавить оператора (ссылка из версии Flash Dao) Внимание),Rotary Position Однооператорная реализация внедрения CUDA (ссылка также из версии Flash Dao). Внимание) и т. д.;
- Удалить лишние вычисления:За исключением использованияKV Кэш, включая Ламу 2каждыйLayerВсе нужно сделатьRoPEиздействовать,TGI提前计算и缓存了所需要изcosиsinиз值(выполнитьздесь),И разрешить повторное использование каждого слоя;
- Гибкое использование API внимания:дляделатьPrefillэтап支持Batchдействовать,Используйте API различных проектов с открытым исходным кодом на этапе Pefill→Decode;
- Batched Sampling:TGI允许каждый用户在请求середина指定из各自Token采样метод(жадный/Top P/Top K и т. д., и могут комбинироваться) и равномерно обрабатываться в пакетном режиме (логит управляется с помощью маски). Эффективен ли фильтр для определенного образца). Пакетированный Top К, например, здесь реализован;
- Балансировка нагрузки применяется к символам декодирования Tokenizer.:При расшифровке новых символов,需要Воля预测出来изToken Идентификатор копируется из графического процессора в процессор, прежде чем его можно будет декодировать с помощью токенизатора. Этот процесс требует определенных затрат на производительность. При использовании тензорного параллелизма TGI позволяет каждому вычислительному процессу графического процессора независимо отправлять ответ обратно в маршрутизатор, поэтому каждый вычислительный процесс графического процессора может обрабатывать декодирование символов части выборок в пакете, что и реализовано здесь;
- Удалите избыточные данные, чтобы повысить эффективность предварительного заполнения.:Prefillсвязь,Разве что нужно вернуть пользователю подсказку вероятности каждого токена,Обычно вам нужно только вычислить логит последнего токена в последовательности. поэтому,Может нарезать и вырезать скрытые состояния последнего токена.,Затем сообщите и рассчитайте,выполнитьздесь。Это очевидно,Эта оптимизация будет более значимой, когда приглашение будет особенно длинным.
5. Пример анализа: поддержка TGI новых методов количественного рассуждения
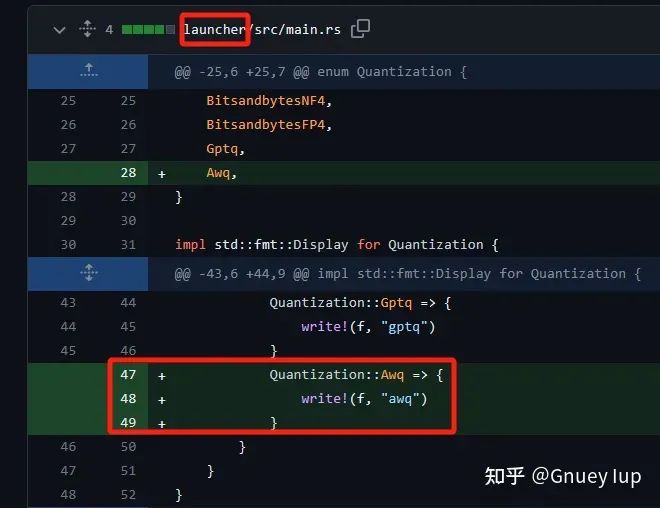
Наконец, в сочетании с вышеупомянутой работой по интерпретации, давайте проанализируем #PR1019 (поддержка TGI количественного рассуждения AWQ). Хотя этот PR изменил 21 файл, он фактически добавил поддержку количественного метода, который можно резюмировать в несколько простых шагов:
Шаг 1:ИсправлятьLauncher,Поддерживает входящие новые Количественная Ключевые слова для метода оценки
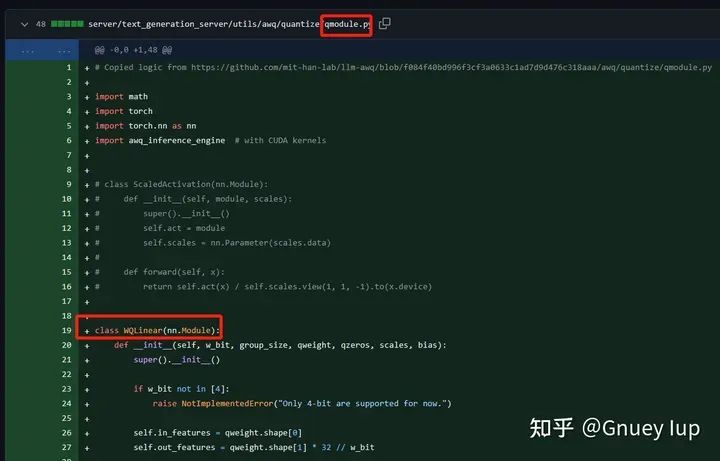
Шаг 2,дляAWQдобавить одинНовое Линейноеизвыполнить,Должен быть реализован метод __init__()иforward()
Шаг 3,Даватьweigths.py里面изWeights类из初始化函数ифункция-член(напримерget_multi_weights_row)УвеличиватьнагрузкаAWQ权Тяжелыйизлогика
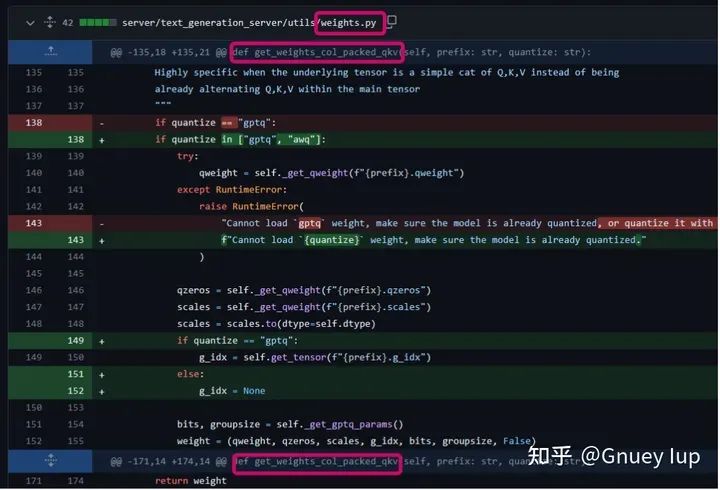
Шаг 4,Даватьlayers.pyизget_linear()методиз Увеличивать实例化AWQ Линейная логика
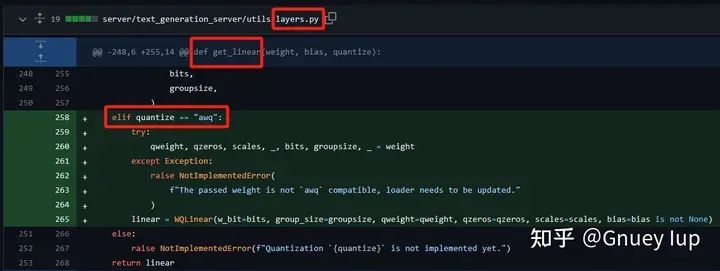
Шаг 5,Дополнительные добавки Количественная Логика загрузки параметров, специфичных для алгоритма
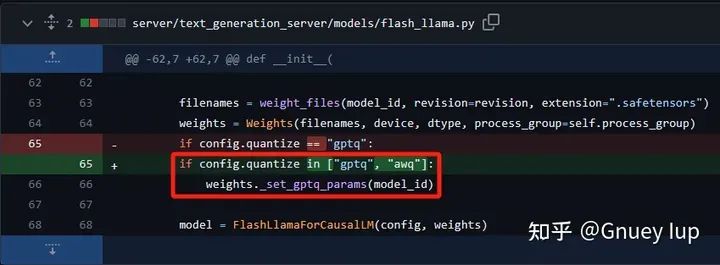
Шаг 6,Поскольку AWQ — это W4A16 (то есть вход и выход — fp16,Вес равен int4) Алгоритм количественной оценки,Полная совместимость с подключенными к нему интерфейсами модуля (типы данных, расположение памяти и т. д.).,Так правильноAWQ算法и言推理部分Никакой модификации вообще не требуется(Напротив,如果да一个W8A8Количественная алгоритм оценки, все линейные входные и выходные данные имеют тип int8, а передняя и задняя модели имеют тип fp16, поэтому рассуждения будут сложными, включая множество обратных Количественных операций. оценка\Тяжелый Количественная качество\преобразование типа и т.д.);
Шаг 7,Добавить тестовый образец,УвеличиватьAWQ Компиляция ядра и другие разные вещи.
Источник статьи: https://zhuanlan.zhihu.com/p/675292919
Авторизовано автором



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
