[Интерпретация документа] Многомодальная большая модель LLaVA. Microsoft первой использовала GPT-4 для создания наборов данных мультимодальных инструкций для точной настройки инструкций.

Примечание. Эта картина получена в результате стабильной диффузии.
1.1 Резюме
В этой статье мы делаем первую попытку сгенерировать мультимодальную инструкцию языкового образа, следующую за данными, используя только язык GPT-4. Адаптируя инструкции к этим сгенерированным данным, мы представляем LLaVA: Large Language and Vision Assistant, комплексную обученную большую мультимодальную модель, которая соединяет визуальные кодировщики с LLM для общего зрения и понимания естественного языка.
1.2 Введение
В частности, наша статья вносит следующий вклад:
(1) Мультимодальные данные, следующие за инструкциями.
Ключевой проблемой является отсутствие визуально-вербальных инструкций для отслеживания данных. Мы предлагаем перспективу и конвейер реорганизации данных, которые используют ChatGPT/GPT-4 для преобразования пар изображение-текст в соответствующие форматы команд.
(2) Большая мультимодальная модель
Мы разрабатываем большую мультимодальную модель (LMM), которая соединяет визуальный кодер открытого набора CLIP с языковым декодером LLaMA и выполняет сквозную точную настройку генерируемых нами обучающих визуально-лингвистических данных. Наше эмпирическое исследование подтверждает эффективность настройки инструкций LMM с использованием сгенерированных данных и предоставляет практические предложения по созданию общих визуальных агентов, следующих инструкциям. С помощью GPT-4 мы достигаем самых современных результатов в решении научных вопросов, отвечая на многомодальные наборы данных для рассуждений.
1.3 Related Word
Примечание. Ниже приведены ресурсы, которые я собрал на основе статьи. Вы можете скачать и изучить самостоятельно.
1.3.1 Multimodal Instruction-following Agents
(1)InstructPix2Pix
① Ссылка на документ: https://arxiv.org/pdf/2211.09800.pdf.
② GitHub: https://github.com/timothybrooks/instruct-pix2pix(2)LangChain
① github:https://github.com/hwchase17/langchain(3)Visual ChatGPT
① Ссылка на документ: https://arxiv.org/pdf/2303.04671.pdf.
② GitHub: https://github.com/microsoft/TaskMatrix(4)X-GPT
1 Веб-сайт: https://arxiv.org/pdf/2212.11270.pdf
2 гитхаб: https://x-decoder-vl.github.io/(5)MM-REACT
① Ссылка на документ: https://arxiv.org/pdf/2303.11381.pdf.
② GitHub: https://multimodal-react.github.io/1.3.2 Instruction Tuning
(1)T5
① Бумага Связь: https://arxiv.org/pdf/1910.10683.pdf.
② github: https://github.com/google-research/text-to-text-transfer-transformer(2)PaLM
① Ссылка на документ: https://arxiv.org/pdf/2204.02311.pdf.
② GitHub: https://github.com/lucidrains/PaLM-rlhf-pytorch(3)OPT
1 Веб-сайт: https://arxiv.org/pdf/2205.01068.pdf
2 GitHub: https://github.com/facebookresearch/metaseq(4)FLAN-T5
① бумага Связь:https://arxiv.org/pdf/2210.11416.pdf
② github:https://github.com/google-research/t5x/tree/main(5)OPT-IML
1 Получено: https://arxiv.org/pdf/2212.12017.pdf.
2 GitHub: https://github.com/facebookresearch/metaseq(6)Flamingo
① Ссылка на документ: https://arxiv.org/pdf/2204.14198.pdf.
② GitHub: https://github.com/lucidrains/flamingo-pytorch(7)BLIP-2
① ссылка на документ: https://arxiv.org/pdf/2301.12597.pdf.
② GitHub: https://github.com/salesforce/LAVIS/tree/main(8)FROMAGe
① ссылка на документ: https://arxiv.org/pdf/2301.13823.pdf
② GitHub: https://github.com/kohjingyu/fromage(9)KOSMOS-1
1 Веб-сайт: https://arxiv.org/pdf/2302.14045.pdf
2 гитхаб: https://github.com/microsoft/unilm(10)PaLM-E [12]
1 Веб-сайт: https://arxiv.org/pdf/2303.03378.pdf
2 гитхаб: https://palm-e.github.io/(11)OpenFlamingo
① Ссылка на блог: https://laion.ai/blog/open-flamingo/
② github:https://github.com/mlfoundations/open_flamingo(12)LLaMA-Adapter
① бумага Связь:https://arxiv.org/pdf/2303.16199.pdf
② github:https://github.com/ZrrSkywalker/LLaMA-Adapter(13)visual prompt tuning
1 Веб-сайт: https://arxiv.org/pdf/2304.02643.pdf
2 GitHub: https://github.com/facebookresearch/segment-anything1.4 Генерация данных визуальных инструкций с помощью GPT
(1) Вдохновленные недавним успехом модели GPT в задачах текстовых аннотаций, мы предлагаем использовать ChatGPT/GPT-4 для сбора мультимодальных данных, следующих за инструкциями, на основе широко существующих данных пары изображение-текст.
(2) Чтобы закодировать изображение в его визуальные характеристики, чтобы подсказывать только текст GPT, мы используем два типа символического представления: ① Подписи обычно описывают визуальную сцену с разных точек зрения. ②Ограничительные рамки обычно определяют расположение объектов на сцене, и каждая рамка кодирует концепцию объекта и его пространственное положение.
png-01

(3) Это символическое представление позволяет нам кодировать изображения в последовательности, распознаваемые LLM. Мы используем изображения COCO и генерируем три типа инструкций, следующих за данными:
① Диалог
Мы спроектировали разговор между ассистентом и спрашивающим о фотографии. Тон ответа такой, как будто ассистент смотрит на изображение и отвечает на вопрос. Задаются различные вопросы относительно визуального содержания изображений, включая тип объекта, количество объектов, движение объекта, местоположение объекта, взаимное расположение объектов. Рассматривайте только вопросы, на которые есть однозначные ответы.
② Подробное описание
Чтобы дать подробное и исчерпывающее описание изображения, мы создали список вопросов с этой целью. Для создания списка мы используем запросы GPT-4. Для каждого изображения мы случайным образом выбираем вопрос из списка и позволяем GPT-4 сгенерировать подробное описание.
③ Сложные рассуждения
Два вышеупомянутых типа фокусируются на самом визуальном контенте, на основе которого мы далее создаем углубленные рассуждения. Ответ обычно требует поэтапного процесса рассуждений, следующего строгой логике.
(4) Всего было собрано 158 тыс. уникальных языковых команд-образов следующих образцов, в том числе 58 тыс. в диалогах, 23 тыс. в подробном описании и 77 тыс. в сложных рассуждениях.
1.5 Доработка визуальных инструкций
1.5.1 Структура
png-02
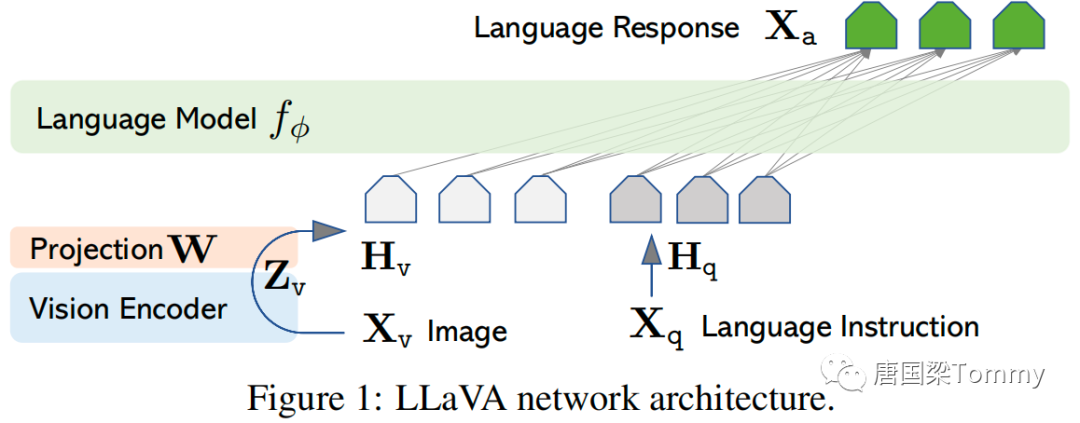
(1) Для входного изображения X_v мы рассматриваем предварительно обученный визуальный кодер CLIP ViT-L/14, который предоставляет визуальные функции Z_v = g(X_v). В наших экспериментах рассматриваются элементы сетки до и после последнего слоя Трансформера.
(2) Мы рассматриваем простой линейный слой для соединения функций изображения с пространством встраивания слов. В частности, мы применяем обучаемую матрицу проекции W для преобразования Z_v в токены встраивания языка H_q, которые имеют те же размеры, что и пространство встраивания слов в языковой модели:
png-03
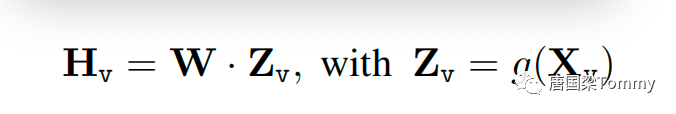
1.5.2 Обучение
Для обучения модели LLaVA мы рассматриваем двухэтапный процесс настройки инструкций:
Этап 1. Предварительное обучение выравниванию функций
① Фильтрация CC3M до 595 тыс. пар изображение-текст;
② Используйте простой метод расширения для преобразования этих пар изображение-текст в данные отслеживания инструкций. Каждый образец можно рассматривать как отдельный этап разговора;
③ Во время обучения мы сохраняем веса визуального кодировщика и LLM замороженными и максимизируем вероятность только с помощью обучаемого параметра θ = W (матрица проекции). Таким образом, признак изображения H_v может быть согласован с предварительно обученным встраиванием слов LLM;
Этот этап можно понимать как обучение совместимого визуального токенизатора для замороженного LLM.
Этап 2. Комплексная точная настройка
Мы только оставляем замороженными веса визуального кодировщика и продолжаем обновлять предварительно обученные веса проекционного слоя и LLM в LLaVA;
1.6 Эксперимент
1.6.1 Мультимодальный чат-бот
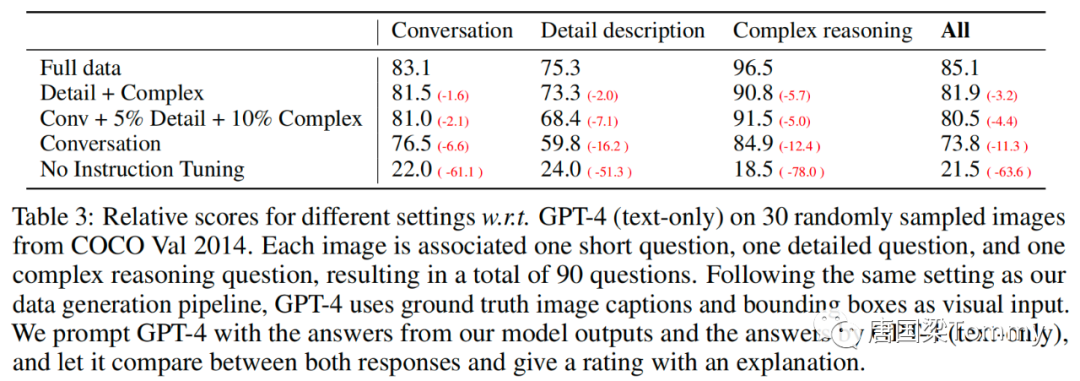
Хотя LLaVA обучался с использованием только меньшего набора данных мультимодального отслеживания инструкций (около 80 тыс. уникальных изображений), на этих двух примерах (см. скриншоты ниже в этой статье) он демонстрирует те же результаты, что и мультимодальный GPT-4. Очень похожие результаты рассуждений. Следует отметить, что хотя оба изображения находятся вне зоны действия LLaVA, LLaVA все же способна понимать сцену и отвечать в соответствии с инструкциями по вопросам.
(1) Количественная оценка
GPT-4 оценивает полезность, актуальность, точность и уровень детализации ответов помощника и присваивает общую оценку от 1 до 10, причем более высокие оценки указывают на лучшую общую производительность.
png-07
1.6.2 ScienceQA
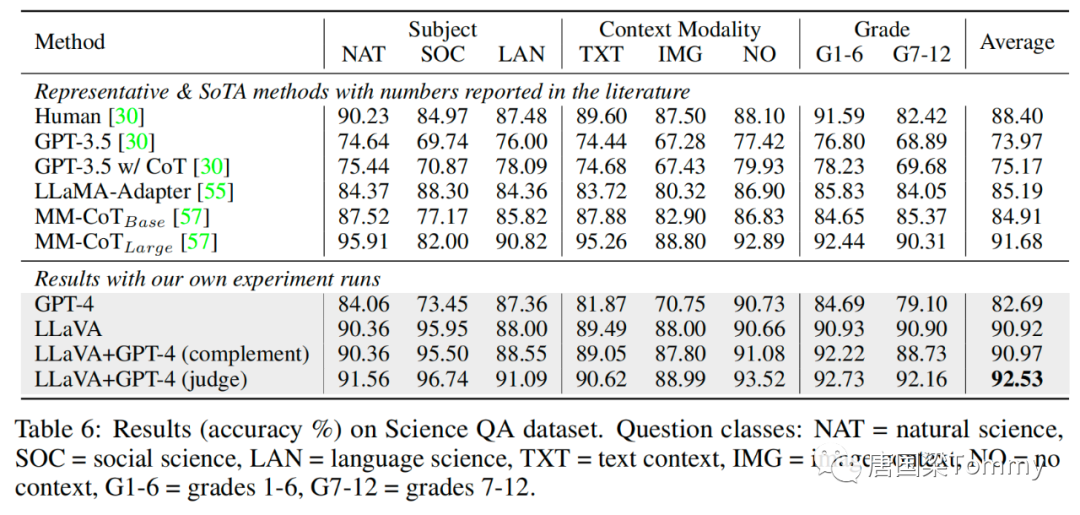
ScienceQA содержит 21 тысячу мультимодальных вопросов с несколькими вариантами ответов, охватывающих 3 предмета, 26 тем, 127 категорий и 379 навыков с богатым разнообразием областей. Набор эталонных данных разделен на обучающий, проверочный и тестовый наборы, содержащие 12726, 4241 и 4241 пример соответственно.
ScienceQA : https://arxiv.org/pdf/2209.09513.pdfpng-08
(1) Эксперимент по абляции
①Визуальные характеристики
Мы попробовали использовать функции последнего слоя визуального кодировщика CLIP и получили точность 89,96%, что на 0,96% ниже, чем функции перед последним слоем. Мы предполагаем, что это связано с тем, что последний уровень функций CLIP может больше фокусироваться на глобальных атрибутах изображения, в то время как его предыдущий уровень может больше фокусироваться на локальных атрибутах, которые помогают понять конкретные детали изображения.
②Мыслительная цепочка
Мы пришли к выводу, что стратегия, основанная на выводах, такая как CoT, может значительно улучшить скорость сходимости, но вносит относительно небольшой вклад в конечную производительность.
③ Предварительная тренировка
Мы пропустили предварительное обучение и обучили модель прямо с нуля на Science QA, и производительность упала до точности 85,81%. Абсолютное снижение на 5,11% демонстрирует важность нашего этапа предварительного обучения для согласования мультимодальных функций при сохранении большого объема предтренировочных знаний.
④ Размер модели
Мы сохраняем все те же конфигурации, что и лучшая модель 13B, и обучаем модель 7B. В результате точность составила 89,84%, что на 1,08% ниже, чем 90,92%, что указывает на важность размера модели.
>>> Результаты эксперимента <<<
Рисунок-1

Рисунок-02




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
