Интегрированное озеро и склад: практика интегрированной архитектуры озера и склада на основе Айсберга на станции B
Введение
На станции B данные уровня PB вводятся в платформу больших данных каждый день. После моделирования ETL в автономном режиме или в реальном времени они предоставляются для последующего анализа, рекомендаций, прогнозирования и других сценариев. Столкнувшись с такими крупномасштабными данными, мы всегда фокусировались на том, как эффективно и с минимальными затратами удовлетворить потребности в анализе последующих данных.
Наш предыдущий процесс обработки данных в основном был таким: на этапе сбора собираются скрытые точки клиента, скрытые точки сервера, журналы, бизнес-базы данных и другие данные в системы хранения, такие как HDFS и Kafka, а затем отключаются через Hive, Spark, Flink и т. д. Он выполняет обработку ETL и моделирование хранилища данных с помощью механизмов реального времени. Для хранения данных используется формат столбчатого хранения ORC. Пользователи могут использовать такие механизмы, как Presto и Spark, для исследования данных и построения отчетов BI на основе данных после моделирования хранилища данных. Для большинства служб данных и некоторых отчетов BI доступ Presto и Spark к данным формата ORC может не соответствовать требованиям времени ответа на запрос пользователя. В этом случае данные необходимо записать в специализированный механизм OLAP, такой как ClickHouse, или выполнить дальнейшую обработку и запись. Используйте системы хранения KV, такие как HBase и Redis, чтобы решить эту проблему.
Хотя текущий процесс обработки данных может в определенной степени удовлетворить текущие потребности бизнеса, все еще остается много возможностей для повышения эффективности и стоимости всего процесса, что в основном отражается в:
- 1. Чтобы повысить эффективность запросов,Экспортируйте таблицу Hive во внешние системы, такие как ClickHouse, HBase, Redis, ElasticSearch, Mysql и т. д.,Требуется дополнительная работа по разработке данных,Дополнительное резервирование хранилища,Но в то же время он имеет меньшую гибкость данных.,Поддержка сложных компонентов увеличивает стоимость разработки сервисов обработки данных.,Более длительный поток обработки данных также снижает стабильность и надежность.
- 2. Для данных, не выпущенных со склада.,Проводят ли пользователи исследование данных или используют отчеты BI,Все еще страдаюSQL on Собственные ограничения производительности Hadoop далеки от интерактивного ответа, ожидаемого пользователями.
В этой статье в основном представлены некоторые из наших исследований и практик в направлении интеграции озер и складов для решения вышеуказанных проблем.
Почему необходимо объединить озеро и склад?
прежде чем обсуждать этот вопрос,Возможно, сначала нам потребуется прояснить две концепции: что такое озеро данных? Что такое хранилище данных? Обе концепции широко обсуждались в отрасли.,История каждого человека разная,Мы пытаемся сделать следующее.,Для данных озера:
- Используйте единую распределенную систему хранения,Можно предположить, что он имеет неограниченную емкость.
- Существует единая система управления данными Yuan.
- Используйте открытый формат хранилища данных.
- Данные обрабатываются и анализируются с использованием механизма обработки открытых данных.
Наша предыдущая архитектура больших данных представляла собой типичную архитектуру озера данных, использующую HDFS в качестве унифицированной системы хранения метаданных Hive. Данные хранятся в HDFS в открытых форматах хранения, таких как CSV, JSON и ORC. API на различных уровнях, таких как SQL, DataSet и FileSystem, для доступа к данным с использованием платформ или языков, таких как Hive, Spark, Presto и Python.
Преимущество архитектуры озера данных заключается в том, что она обладает большой гибкостью. В озере данных можно размещать структурированные, полуструктурированные и неструктурированные данные. Пользователи могут использовать любой подходящий механизм для проведения гибкого исследования практически всех данных. ограничений, но у него также есть большие недостатки, наиболее важными из которых являются управление данными и эффективность запросов.
Для хранилища данных:
- Индивидуальный формат хранилища данных.
- Организационный метод управления данными самостоятельно.
- Сильные схемы, обеспечивающие стандартный интерфейс SQL для внешнего мира.
- Он имеет эффективную интегрированную вычислительную базу данных и богатые функции ускорения запросов.
Хранилища данных (механизмы OLAP) предъявляют относительно строгие требования к данным. Если взять в качестве примера ClickHouse, предопределенные данные строгой схемы должны быть записаны в ClickHouse через JDBC. ClickHouse использует собственный формат хранения для хранения данных и сортировки файлов данных. Или оптимизация организации данных. например, объединение файлов, предоставляемое внешнему миру Интерфейс SQL не предоставляет доступ к внутренним файлам данных и обеспечивает расширенные функции ускорения запросов, такие как индексирование. Внутренний вычислительный механизм и формат хранения также будут иметь множество встроенных совместных оптимизаций. Обычно считается, что эффективность запросов специализированного хранилища данных будет выше. быть лучше, чем архитектура озера данных, в практике Bilibili большинство сценариев, таких как ClickHouse по сравнению со Spark и Presto, действительно имеют повышение производительности на порядок.

В наших реальных сценариях обработки данных, помимо таких сценариев, как искусственный интеллект и исследование данных, исследование неизвестных проблем с помощью неизвестных данных больше зависит от гибкости архитектуры озера данных. Фактически, большинство сценариев основаны на известных данных, то есть на наших данных. Разработка данных Classmate, на самом деле это сильная схема, основанная на таблице Hive Данные, выполняют иерархическое построение различных хранилищ бизнес-данных от ODS, DWD, DWB до ADS. По сути, мы в основном создаем хранилища бизнес-данных на основе архитектуры озера данных. Как повысить эффективность запросов и стоимость использования этой части. сценарий? и пользовательский опыт лежат в основе нашей работы в этой области.
Интеграция озер и складов стала очень популярным направлением в области больших данных в последние два года. Ключевым моментом является сохранение гибкости озер и эффективности складов на одной и той же технической архитектуре. Существует два общих технических пути: один — перейти от распределенного хранилища данных к интегрированному озерному хранилищу. В распределенном хранилище данных поддерживаются открытые форматы хранения, такие как CSV, JSON, ORC и PARQUET, а также осуществляется процесс обработки данных. преобразуется из ETL в ELT, после того как данные вводятся в распределенное хранилище данных, работа по моделированию хранилища бизнес-данных выполняется в распределенном хранилище данных, например AWS. RedShift и SnowFlake и т. д.; другой — это эволюция от озера данных к озерному хранилищу на основе механизма открытых запросов и нового формата хранения открытых таблиц для достижения эффективности обработки распределенного хранилища данных. Представитель коммерческого хранилища с закрытым исходным кодом. продуктами в этом отношении являются DataBricks SQL, они основаны на ядре Photon с закрытым исходным кодом, совместимом с Spark API, и интегрированной архитектуре Lake-warehouse формата хранения DeltaLake и объектного хранилища S3, утверждая, что производительность превышает производительность выделенного облачного хранилища данных. SnowFlake в тесте TPC-DS. В области сообществ открытого исходного кода появление таких проектов, как Iceberg, Hudi и DeltaLake, также предоставило базовые технические резервы для реализации интеграции озер и хранилищ с помощью технологического решения озера данных SQL на Hadoop. На станции B, основываясь на нашем предыдущем технологическом стеке и реальных бизнес-сценариях, мы выбрали второе направление, развиваясь от архитектуры озера данных к интегрированному озеру и хранилищу.
Практика объединения озер и складов на станции Б
Для интегрированной архитектуры озера и склада Bilibili мы хотим решить две основные проблемы: во-первых, ввиду сложности и дополнительных затрат на разработку хранилища, вызванных перемещением таблиц Hive из хранилища во внешние системы (ClickHouse, HBase, ES и т. д.), постарайтесь уменьшить необходимость выхода со склада в этом сценарии. Второе — повысить эффективность запросов и сократить затраты на анализ и сценарии запросов на основе SQL на Hadoop. Мы построили нашу интегрированную архитектуру озера и склада на основе Iceberg. Прежде чем подробно рассказать об интегрированной архитектуре озера и склада на станции B, я думаю, необходимо сначала обсудить два вопроса. Почему Iceberg может построить интегрированную архитектуру озера и склада? мы выбрали Айсберг?
1. Почему на основе Iceberg можно построить интегрированную архитектуру озера и склада? Сравнивая реализацию открытых механизмов SQL, форматов хранения, таких как Presto, Spark, ORC, Parquet, и распределенных хранилищ данных, таких как ClickHouse и SnowFlake, на самом деле особой разницы нет. Распределенные механизмы с открытым исходным кодом постепенно дополняют среду выполнения SQL и уровни хранения. Некоторые расширенные функции, влияющие на производительность, такие как Runtime CodeGen, векторизованный механизм выполнения, CBO на основе статистики, индексирование и т. д. Самая большая разница между ними в настоящее время заключается в возможностях управления организацией данных. Для архитектуры озера данных организация распределения файлов данных в HDFS определяется задачей записи, тогда как для распределенного хранилища данных данные обычно записываются через JDBC, а метод организации хранения данных определяется хранилищем данных. , поэтому хранилище данных может организовать хранение данных более удобным для запросов способом, например, регулярно сжимать файлы данных до соответствующих размеров или разумно сортировать и группировать данные. Для крупномасштабных данных оптимизированная организация данных может значительно улучшить запросы. эффективность. Наиболее важной особенностью появления новых форматов хранения таблиц, таких как Iceberg, Hudi и DeltaLake, является то, что они могут самоорганизовываться и управлять информацией метаданных таблиц в HDFS, тем самым обеспечивая моментальные снимки данных таблиц и возможности поддержки крупномасштабных транзакций. При этом данные в форматах Iceberg, Hudi и DeltaLake могут быть реорганизованы и оптимизированы асинхронно и прозрачно вне механизма открытых запросов, тем самым достигая эффектов, аналогичных распределенным хранилищам данных.
2. Почему стоит выбрать «Айсберг»? Iceberg, Hudi и DeltaLake — проекты форматов хранения таблиц с открытым исходным кодом, появившиеся в одно и то же время. Общие функции и позиционирование в основном одинаковы. В Интернете есть много связанных с ними сравнительных статей. Я не буду здесь их подробно сравнивать. Причина, по которой мы выбрали Iceberg, заключается в следующем: Iceberg является лучшим среди трех форматов хранения абстрактных таблиц, включая механизмы чтения и записи, Table Схема и формат хранения файлов являются подключаемыми, что позволяет нам гибко расширяться и обеспечивать совместимость с открытым исходным кодом и предыдущими версиями. Исходя из этого, мы также с оптимизмом смотрим на долгосрочное развитие проекта.
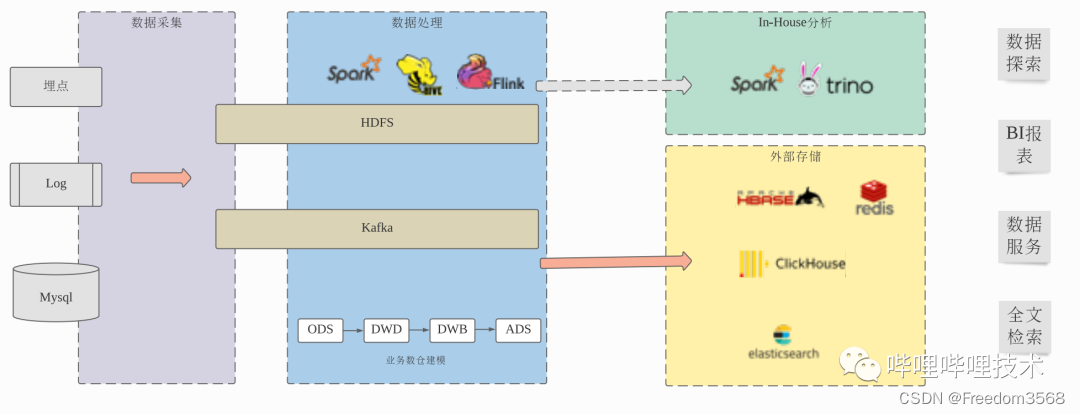
На рисунке ниже показана наша общая интегрированная архитектура озера и хранилища, которая поддерживает открытые Spark, Flink и другие механизмы для доступа к данным из Kafka и HDFS. Затем сервис Magnus будет асинхронно подтягивать задачи Spark для повторного хранения и оптимизации данных Iceberg. Используйте Trino в качестве механизма запросов и внедрите Alluxio для ускорения кэширования метаданных и индексных данных Iceberg.
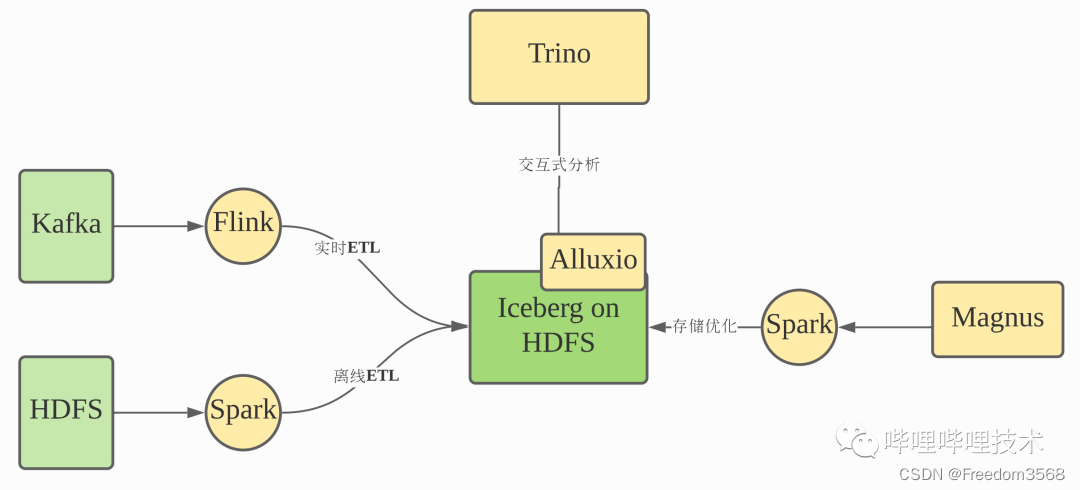
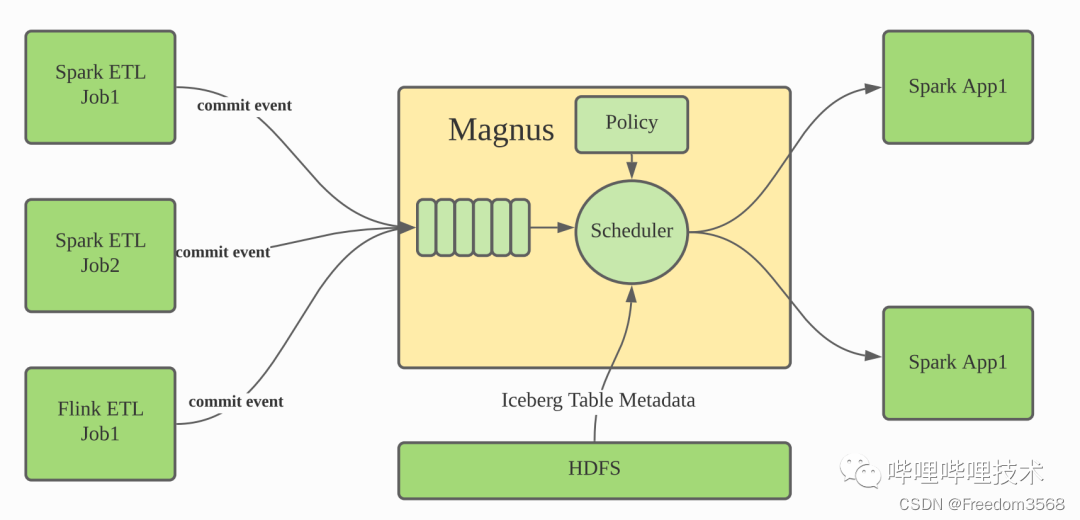
Магнус — это основной компонент нашей интегрированной архитектуры хранилища на озере. Он отвечает за управление и оптимизацию данных во всех таблицах Iceberg. Сам Iceberg представляет собой формат хранения таблиц. Хотя сам проект предоставляет задания действий на основе Spark, Flink и т. д. для слияния небольших файлов, файлов метаданных или очистки просроченных данных моментальных снимков, для планирования этих заданий действий он полагается на внешние службы. Магнус должен взять на себя эту роль. Мы расширили Iceberg. Когда таблица Iceberg обновляется, информация о событиях будет отправлена в службу Magnus. Служба Magnus поддерживает очередь для сохранения этой информации о событиях фиксации. В то же время внутренний планировщик Magnus продолжает работать. использовать очередь событий и решить, следует ли и как запускать задачу Spark для оптимизации организации данных таблицы Iceberg на основе информации метаданных и связанных стратегий, соответствующих таблице Iceberg.
Для сценариев многомерного анализа мы также внесли целевые индивидуальные улучшения в ядро Iceberg и другие аспекты. Ниже приводится краткое введение в два аспекта: сортировку и индексирование по Z-порядку.
Сортировка по Z-порядку
Iceberg записывает информацию MinMax каждого столбца на уровне файла в метаданные таблицы и поддерживает объединение небольших файлов и глобальную линейную сортировку (т. е. порядок Объединив их, мы можем добиться очень хороших эффектов пропуска данных во многих сценариях запросов. Например, после глобальной сортировки файлов данных таблицы Iceberg по полю a, если последующий запрос содержит условие фильтра a, Механизм запросов перенесет условия фильтрации на уровень доступа к файлам через PredictePushDown. Мы можем напрямую пропускать все ненужные файлы на основе индекса MinMax и получать доступ только к тем файлам, в которых расположены данные.
В реальных сценариях многомерного анализа обычно используется несколько часто используемых полей фильтрации. Линейный порядок оказывает лучший эффект пропуска данных только на передних полях. Обычно в качестве передних полей сортировки используются поля с низкой мощностью, чтобы обеспечить также определенный пропуск данных. эффект для последующих полей сортировки при фильтрации, но это не может фундаментально решить проблему. Необходимо ввести новый механизм сортировки, чтобы несколько часто используемых полей фильтрации могли получить лучший эффект пропуска данных. чередующийся Порядок (т. е. Z-порядок) — это метод сортировки, используемый при обработке изображений и хранилище данных. Кривая Z-ORDER может представлять собой бесконечно длинную одномерную кривую, проходящую через все пространства любого измерения. Поля сортировки можно рассматривать как несколько измерений. Многомерные данные сами по себе являются Естественного порядка нет, но Z-Order отображает многомерные данные в одномерные с помощью определенных правил и создает z-значение, чтобы их можно было сортировать на основе одномерных данных. Кроме того, правила отображения Z. -Порядок гарантирует, что одномерные данные сортируются в соответствии с одномерными данными. Сортированные данные агрегируются на основе нескольких полей сортировки одновременно.
индекс Icebergпо умолчаниюхранилище Уровень файла на столбецMin、Maxинформация,И используется для фильтрации файлов на этапе TableScan.,По сути эквивалент MinMax в распределенном хранилище данных.,MinMaxindex хорошо работает для пропуска данных полей после сортировки.,Но для несортированных полей,данные случайным образом разбросаны по файлам,При фильтрации с использованием этого поля,MinMaxindex в принципе трудно добиться эффекта пропуска файла.,Индекс BloomFilter работает лучше в этом сценарии,Особенно, когда мощность поля велика. Фильтр Блума на самом деле представляет собой длинный двоичный вектор и несколько хэш-функций.,данные сопоставляются с битами двоичного вектора с помощью нескольких функций.,Фильтры Блума очень экономят пространство и время запроса.,Отлично подходит для получения информации о том, существует ли элемент в коллекции.
Фильтры Блума очень экономят пространство и время запроса.,Но есть и ограничения в использовании,Основная причина заключается в том, что условия фильтрации, которые он может поддерживать, ограничены.,Применимо только к: =, IN, NotNull и другим выражениям значений.,Для общей фильтрации диапазона,например>、>=、<、<=Подождите, не поддерживается。Для поддержки более расширенных выражений фильтра,Мы представили BitMapиндекс. BitMap также является очень распространенной структурой данных.,Сопоставьте набор данных положительных целых чисел с битами,По сравнению с BloomFilter,Нет конфликта хэшей,Таким образом, ложное срабатывание не появится.,Но обычно требуется больше места для хранения. BitMapиндекс для полей с высокой мощностью,Основными проблемами при реализации являются:
- требуется база полей хранилища, соответствующая BitMap,хранилище Цена слишком высока.
- Во время фильтрации диапазона при использовании BitMap для определения возможности пропуска файла требуется доступ к большому количеству BitMap, а стоимость чтения слишком высока.
Реализация закодированного растрового изображения. Конкретные подробности можно найти в ссылке [2] (ускорение комплексного анализа озер и складов с помощью индекса).
Подвести итог
По сравнению с традиционным стеком технологий SQL on Hadoop интегрированная архитектура озера-хранилища на базе Iceberg обеспечивает эффективность анализа, близкую к эффективности распределенного хранилища данных, обеспечивая при этом совместимость с существующим стеком технологий Hadoop и принимая во внимание гибкость озера. Характер и эффективность хранилища, судя по нашему практическому опыту, в основном прозрачны для пользователей. Это просто новый формат хранения таблиц Hive. Больше нет порогов для использования и распознавания, нет существующих инструментов платформы больших данных. услуги. Его также можно интегрировать с очень небольшими затратами. Чтобы еще больше повысить эффективность запросов и удобство работы пользователей в различных сценариях, мы усовершенствовали Iceberg в следующих направлениях:
- организация распределения данных звездной модели,Поддерживает сортировку организации и индексацию данных таблицы фактов в соответствии с полями таблицы измерений.
- Предварительные вычисления, которые ускоряют фиксированные шаблоны запросов посредством предварительного вычисления.
- Разумный,Автоматически собирать историю запросов пользователей,Анализ шаблонов запросов,Адаптивная настройка данных, сортировка организации, индекс и т. д.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
