Инструмент исправления текстовых ошибок одним щелчком мыши объединяет модели BERT, ERNIE и другие, позволяя вам сразу же насладиться удобством и эффектом исправления ошибок.
pycorrector — это инструмент для исправления текстовых ошибок одним щелчком мыши, который объединяет модели BERT, MacBERT, ELECTRA, ERNIE и другие, позволяя вам сразу же насладиться удобством и эффектом исправления ошибок.
pycorrector: Инструмент для коррекции китайского текста. Поддерживает китайское фонетическое сходство, схожую форму и исправление грамматических ошибок, разработанное с помощью Python3. Внедрено исправление текстовых ошибок для моделей Kenlm, ConvSeq2Seq, BERT, MacBERT, ELECTRA, ERNIE, Transformer и других, а также оценено влияние каждой модели на набор данных SigHAN.
1. Задача исправления ошибок в китайском тексте, распространенные типы ошибок:
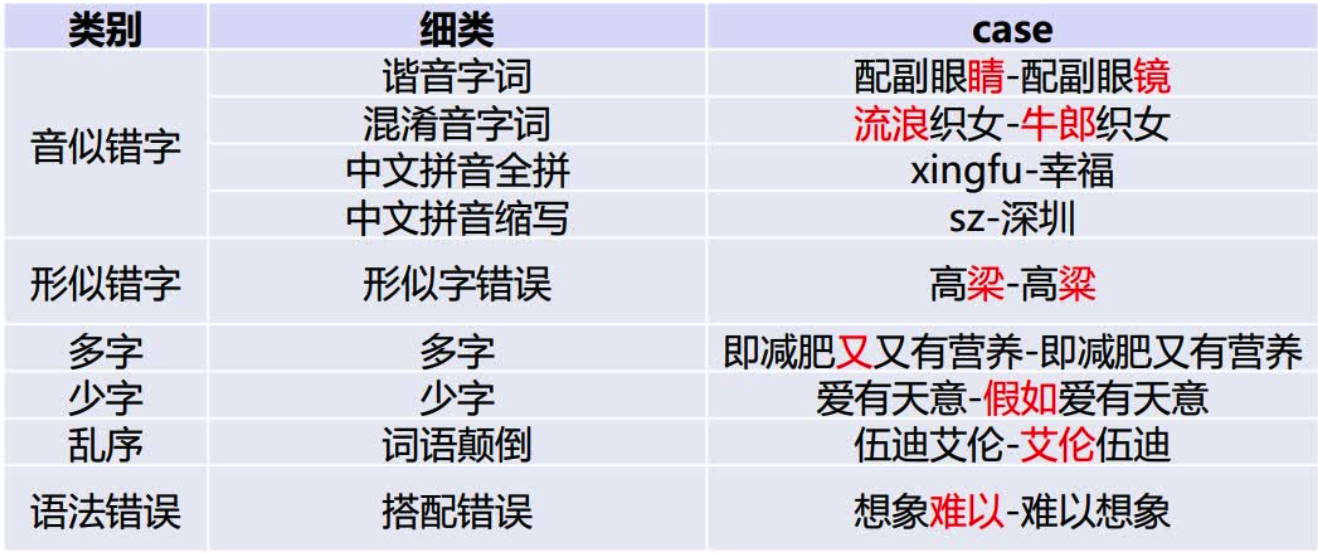
Конечно, для различных бизнес-сценариев эти проблемы могут не существовать. Например, метод ввода пиньинь и корректура распознавания речи фокусируются на ошибках, похожих на звуки, а метод ввода Wubi, а корректура OCR фокусируется на ошибках, похожих на форму.
Исправление ошибок запросов поисковых систем фокусируется на всех типах ошибок.
Этот проект направлен на решение «звукоподобных, фонетических, грамматических ошибок, ошибок в именах собственных» и других типов.
2.Решение
2.1 Решения правил
Местоположение опечатки определяется на основе языковой модели, а опечатка исправляется с помощью функции фонетического сходства пиньинь, функции расстояния редактирования штрихов и функции недоумения языковой модели.
- Исправление ошибок в китайском языке разделено на два этапа: первый этап — обнаружение ошибок, второй — исправление ошибок;
- Часть обнаружения ошибок сначала использует сегментатор заикающихся китайских слов для сегментации слов. Поскольку предложение содержит опечатки, результаты сегментации слов часто содержат ошибки сегментации. Таким образом, ошибки обнаруживаются как по детализации символов, так и по детализации слов, а также по предполагаемым ошибкам. ошибки двух степеней детализации объединяются. Результаты ошибок формируют набор возможных мест предполагаемых ошибок;
- Часть исправления ошибок заключается в том, чтобы просмотреть все предполагаемые ошибочные позиции и использовать похожие по звучанию и внешнему виду словари для замены слов в неправильных позициях. Затем с помощью языковой модели рассчитывается запутанность предложения и анализируются результаты всех наборов кандидатов. сравниваются и сортируются для получения оптимального исправленного слова.
2.2 Решения глубоких моделей
- Сквозная глубокая модель позволяет избежать ручного извлечения функций и сократить ручную рабочую нагрузку. Модель последовательности RNN обладает сильными возможностями для выполнения текстовых задач. RNN Attn заняла первое место в конкурсе по исправлению ошибок в английском языке, доказав хороший эффект применения. ;
- CRF рассчитает условную вероятность глобального оптимального выходного узла. Чтобы обнаружить определенные типы ошибок в предложении, ошибка будет определена на основе всего предложения. Али участвовал в задаче по исправлению ошибок китайской грамматики в 2016 году и занял первое место, доказав это. эффект применения хороший;
- Модель Seq2Seq использует структуру кодировщика-декодера для решения задач преобразования последовательностей. В настоящее время это одна из наиболее широко используемых и наиболее эффективных моделей в задачах преобразования последовательностей (таких как машинный перевод, генерация диалогов, суммирование текста и описание изображений).
- Мощные возможности языкового представления моделей предварительного обучения, таких как BERT/ELECTRA/ERNIE/MacBERT, внесли потрясающие изменения в область НЛП. Языковая модель, основанная на огромных данных обучения, имеет беспрецедентные эффекты, основанные на характеристиках маски MASK. , предобучающую модель можно просто трансформировать. Обучающая модель используется для коррекции ошибок, а при тонкой настройке эффект легко достигает оптимального уровня.
PS:
2.2 Рекомендации по модели
- Модель Kenlm: В рамках этого проекта была обучена китайская языковая модель NGram на основе инструмента статистической языковой модели Kenlm. Сочетание методов правил и наборов ошибок позволяет исправить орфографические ошибки на китайском языке. Этот метод является быстрым, масштабируемым и в целом эффективным.
- Модель MacBERT [Рекомендация]: в этом проекте реализована модель MacBERT4CSC для исправления текстовых ошибок на китайском языке на основе PyTorch. Модель добавляет сеть обнаружения и исправления ошибок, адаптируется к задаче исправления орфографических ошибок на китайском языке и дает хорошие результаты.
- Модель Seq2Seq. В этом проекте реализована модель Seq2Seq и модель ConvSeq2Seq для исправления текстовых ошибок на китайском языке на основе PyTorch. Среди них ConvSeq2Seq использовал одну модель и занял третье место в конкурсе по исправлению грамматических ошибок на китайском языке NLPCC-2018. параллельная модель Быстрая сходимость, средний эффект.
- Модель T5: Этот проект реализован на основе PyTorch для китайского языка. ошибок в модель текстаеизT5 с использованием Langboat/mengzi-t5-baseиз модели претренироваться точная настройка исправления ошибок на китайском языке Набор данных,Трансформация модели имеет большой потенциал,Хороший эффект
- Модель BERT: на основе PyTorch этот проект реализует метод исправления опечаток, основанный на возможности заполнения маски встроенного BERT, но эффект плохой.
- Модель ELECTRA: В этом проекте реализован метод исправления опечаток, основанный на возможности заполнения маски встроенной ELECTRA на основе PyTorch, но эффект плохой.
- Модель ERNIE_CSC: В этом проекте реализована модель ERNIE_CSC для исправления ошибок текста на китайском языке на основе PaddlePaddle. Модель точно настроена на ERNIE-1.0. Структура модели адаптирована к задаче исправления орфографических ошибок на китайском языке, и эффект хороший.
- Модель DeepContext: В этом проекте реализована модель DeepContext для исправления текстовых ошибок на основе PyTorch. Структура модели относится к модели NLC Стэнфордского университета. Она заняла первое место в конкурсе по исправлению ошибок в английском языке в 2014 году, а эффект средний.
- Модель Transformer: В этом проекте исследовалась модель Transformer для исправления текстовых ошибок на китайском языке на основе библиотеки fairseq PyTorch, и эффект был средним.
- думать
- Метод правил хорошо запоминает ошибки при детализации слов, но необходимо повысить точность исправления ошибок. Я надеюсь, что в модели алгоритма произойдет больший прорыв.
- Сегодняшние текстовые ошибки больше не ограничиваются орфографическими ошибками при детализации слов. Возможности обнаружения ошибок китайской грамматики (CGED, Chinese Grammar Error Diagnosis) и возможности исправления должны быть улучшены и перечислены в TODO для последующего исследования.
3.Демо-демо
Official Demo: https://www.mulanai.com/product/corrector/
HuggingFace Demo: https://huggingface.co/spaces/shibing624/pycorrector
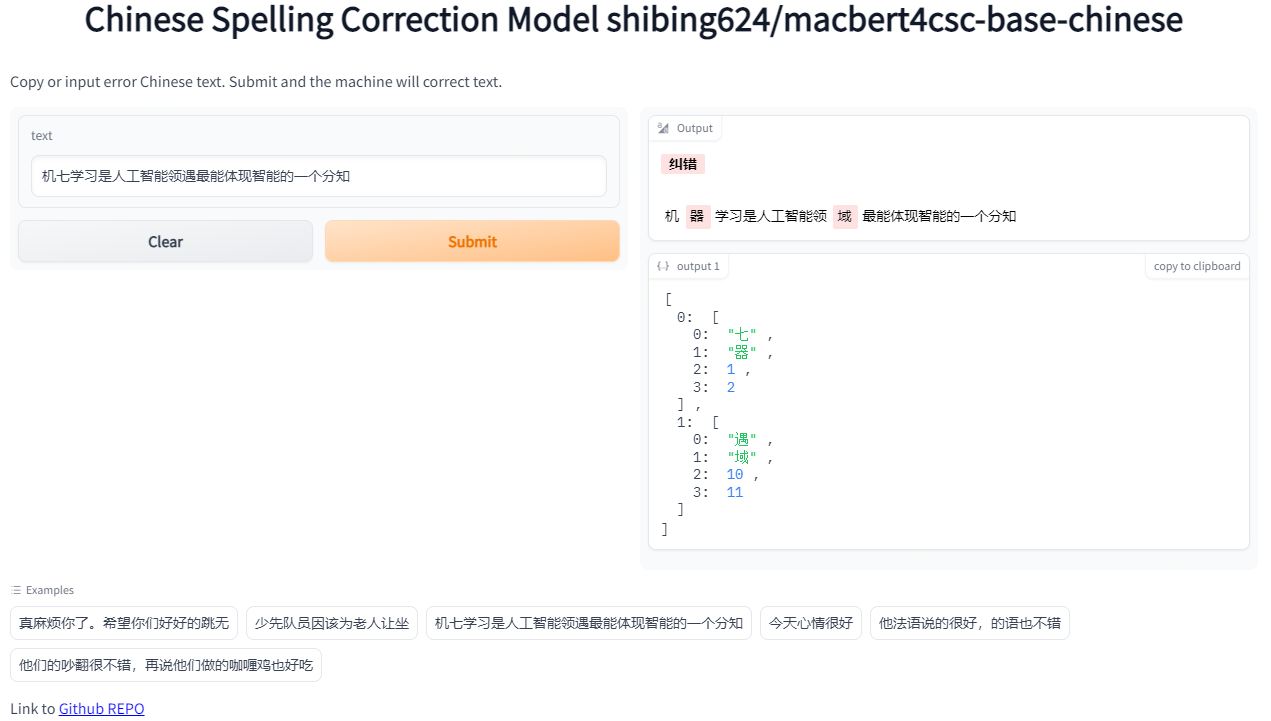
run example: examples/gradio_demo.py to see the demo:
python examples/gradio_demo.py4. Оценка модели (набор оценок sigan15)
Предоставьте примеры сценариев оценки/evaluate_models.py:
- Используйте оценочный набор SIGHAN15: тестовый набор SIGHAN2015 pycorrector/data/cn/sighan_2015/test.tsv , преобразован в упрощенный китайский язык.
- Критерии оценки: степень точности исправления ошибок, используется метод расчета строгой детализации предложения (Sentence Level), правильное предложение после исправления по модели считается правильным, в противном случае оно является неправильным.
- Результаты оценки 评估Набор данные: тестовый набор SIGHAN2015
Графический процессор: Tesla V100, видеопамять 32 ГБ
Model Name | Model Hub Link | Backbone | GPU | Precision | Recall | F1 | QPS |
|---|---|---|---|---|---|---|---|
Rule | kenlm | CPU | 0.6860 | 0.1529 | 0.2500 | 9 | |
BERT-CSC | bert-base-chinese | GPU | 0.8029 | 0.4052 | 0.5386 | 2 | |
BART-CSC | fnlp/bart-base-chinese | GPU | 0.6984 | 0.6354 | 0.6654 | 58 | |
T5-CSC | byt5-small | GPU | 0.5220 | 0.3941 | 0.4491 | 111 | |
Mengzi-T5-CSC | mengzi-t5-base | GPU | 0.8321 | 0.6390 | 0.7229 | 214 | |
ConvSeq2Seq-CSC | ConvSeq2Seq | GPU | 0.2415 | 0.1436 | 0.1801 | 6 | |
ChatGLM-6B-CSC | ChatGLM | GPU | 0.5263 | 0.4052 | 0.4579 | 4 | |
MacBERT-CSC | hfl/chinese-macbert-base | GPU | 0.8254 | 0.7311 | 0.7754 | 224 |
- в заключение
- исправление китайской орфографии Модельлучший эффектиздаMacBert-CSC,Модель名称даshibing624/macbert4csc-base-chinese,huggingface model:shibing624/macbert4csc-base-chinese
- исправление китайской грамматики Модельлучший эффектиздаBART-CSC,Модель名称даshibing624/bart4csc-base-chinese,huggingface model:shibing624/bart4csc-base-chinese
- самый потенциальныйиз МодельдаMengzi-T5-CSC,Модель名称даshibing624/mengzi-t5-base-chinese-correction,huggingface model:shibing624/mengzi-t5-base-chinese-correction,Структура модели без изменений,Только тонкая настройка китайской коррекции ошибок Набор данных,Уже в
SIGHAN 2015подойти ближеSOTAиз Эффект - Эффект исправления ошибок и тонкой настройки модели на базе ChatGLM-6Bиз тоже хорош.,Модель名称даshibing624/chatglm-6b-csc-zh-lora,huggingface model:shibing624/chatglm-6b-csc-zh-lora,Большие модели позволяют не только исправлять ошибки, но и совершенствовать предложения.,Но модель слишком большая,Рассуждение происходит медленно
5. Руководство по использованию
pip install -U pycorrectoror
pip install -r requirements.txt
git clone https://github.com/shibing624/pycorrector.git
cd pycorrector
pip install --no-deps .Вы можете завершить установку любым из двух вышеуказанных способов. Если вы не хотите устанавливать зависимые пакеты, вы можете напрямую использовать Docker, чтобы получить установленную среду развертывания.
- Установить зависимости
- использование докера
docker run -it -v ~/.pycorrector:/root/.pycorrector shibing624/pycorrector:0.0.2Вы можете использовать его, вызвав python позже. В образе уже установлены kenlm, pycorrector и другие пакеты. Подробности см. в Dockerfile.
Пример использования:

- установка кенлма
pip install kenlm- Установка других пакетов библиотеки
pip install -r requirements.txt6. Сценарии применения
6.1 Исправление текста
example: examples/base_demo.py
import pycorrector
corrected_sent, detail = pycorrector.correct('Юные пионеры должны уступить места пожилым')
print(corrected_sent, detail)output:
Юные пионеры должны уступить места старикам [('из-за', 'должен', 4, 6), ('сидеть', 'сиденье', 10, 11)]По умолчанию метод правила начинается с пути
~/.pycorrector/datasets/zh_giga.no_cna_cmn.prune01244.klmнагрузкаkenlmязык Модельдокумент,Если в обнаружении нет файла, 则程序会自动联网下载。Конечно, вы также можете загрузить его вручную.Файл модели (2,8 ГБ)и поместите его в это место。
6.2 Обнаружение ошибок
example: examples/detect_demo.py
import pycorrector
idx_errors = pycorrector.detect('Юные пионеры должны уступить места старикам')
print(idx_errors)output:
[['из-за', 4, 6, 'word'], ['сидеть', 10, 11, 'char']]返回类型да
list,[error_word, begin_pos, end_pos, error_type],posИндексная позиция начинается с0начинать。
6.3 Исправление идиом и имен собственных
example: examples/proper_correct_demo.py
import sys
sys.path.append("..")
from pycorrector.proper_corrector import ProperCorrector
m = ProperCorrector()
x = [
«Расплата скоро придет»,
«Я купил сегодня яблоки на Pinduoduo»,
]
for i in x:
print(i, ' -> ', m.proper_correct(i))output:
Возмездие приближается -> («Наступает возмездие», [('Получить последнюю версию', «Приходите друг за другом», 2, 6)])
Я купил сегодня яблоки на Pinduoduo. -> («Я купил сегодня яблоки на Pinduoduo», [('пиндуодуо', 'Пиндуодуо', 3, 6)])6.4 Пользовательский набор путаницы
Загружая собственный набор ошибок, пользователи могут исправить известные ошибки, включая две функции: 1) [Повышение точности] для добавления ложных срабатываний и отбеливания 2) [Улучшение скорости отзыва] для дополнения отзыва;
example: examples/use_custom_confusion.py
import pycorrector
error_sentences = [
«Сколько стоит купить iPhoneX»,
«Совместные контролеры Сяо Хуа, Хо Жунцюань и Чжан Цикан»,
]
for line in error_sentences:
print(pycorrector.correct(line))
print('*' * 42)
pycorrector.set_custom_confusion_path_or_dict('./my_custom_confusion.txt')
for line in error_sentences:
print(pycorrector.correct(line))output:
(«Сколько стоит купить iPhoneX», []) # "iphonex" пропущен, должно быть "iphoneX"
(«Совместные контролеры Сяо Хуа, Хо Жунцюань и Чжан Цикан», [['Чжан Цикан', «Чжан Цикан», 14, 17]]) # «Чжан Цикан» убит по ошибке, его не нужно исправлять.
*****************************************************
(«Сколько стоит купить iPhoneX», [['iphonex', 'iphoneX', 1, 8]])
(«Совместные контролеры Сяо Хуа, Хо Жунцюань и Чжан Цикан», [])в
./my_custom_confusion.txtиз Формат контента следующий,Разделяются пробелами:
айфон плохой iPhoneX
Чжан Цикан Чжан ЦиканФункция установки путаницы находится в
correctДействителен в методе;set_custom_confusion_dictметодизpathПараметры пользовательские Пользовательский набор путь к файлу путаницы (str) или словарь набора путаницы (dict).
6.5 Пользовательская языковая модель
Доступно для загрузки и использования по умолчаниюизkenlmязык Модельzh_giga.no_cna_cmn.prune01244.klmдокументда2.8G,Маленькая памятьизиспользование компьютераpycorrectorПроцедура может быть сложной。
Помогите пользователям загрузить собственную языковую модель тренироватьсяизkenlm.,Или используйте модель тренирования данных People’s Daily за 2014 год.,Маленькая модель (140М),чуть более низкая точность,Модель Скачать адрес:люди2014corpus_chars.klm (пароль o5e9)。
example:examples/load_custom_language_model.py
from pycorrector import Corrector
import os
pwd_path = os.path.abspath(os.path.dirname(__file__))
lm_path = os.path.join(pwd_path, './people2014corpus_chars.klm')
model = Corrector(language_model_path=lm_path)
corrected_sent, detail = model.correct('Юные пионеры должны уступить места старикам')
print(corrected_sent, detail)output:
Юные пионеры должны уступить места старикам [('из-за', 'должен', 4, 6), ('сидеть', 'сиденье', 10, 11)]6.6 Исправление орфографии английского языка
Поддерживает исправление орфографических ошибок на уровне английского слова.
example:examples/en_correct_demo.py
import pycorrector
sent = "what happending? how to speling it, can you gorrect it?"
corrected_text, details = pycorrector.en_correct(sent)
print(sent, '=>', corrected_text)
print(details)output:
what happending? how to speling it, can you gorrect it?
=> what happening? how to spelling it, can you correct it?
[('happending', 'happening', 5, 15), ('speling', 'spelling', 24, 31), ('gorrect', 'correct', 44, 51)]6.7 Взаимообмен между упрощенным и традиционным китайским языком
Поддерживает преобразование из традиционного китайского в упрощенный китайский, а также преобразование из упрощенного китайского в традиционный китайский.
example:examples/traditional_simplified_chinese_demo.py
import pycorrector
traditional_sentence = «Меланхолия из Тайваньской черепахи»
simplified_sentence = pycorrector.traditional2simplified(traditional_sentence)
print(traditional_sentence, '=>', simplified_sentence)
simplified_sentence = «Меланхолия из Тайваньской черепахи»
traditional_sentence = pycorrector.simplified2traditional(simplified_sentence)
print(simplified_sentence, '=>', traditional_sentence)output:
Меланхолия из Тайваня черепаха => Меланхолия из Тайваня черепаха
Меланхолия из Тайваня черепаха => Меланхолия из Тайваня черепаха6.8 Режим командной строки
Поддержка пакетного исправления текстовых ошибок
python -m pycorrector -h
usage: __main__.py [-h] -o OUTPUT [-n] [-d] input
@description:
positional arguments:
input the input file path, file encode need utf-8.
optional arguments:
-h, --help show this help message and exit
-o OUTPUT, --output OUTPUT
the output file path.
-n, --no_char disable char detect mode.
-d, --detail print detail infocase:
python -m pycorrector input.txt -o out.txt -n -d输入документ:
input.txt;输出документ:out.txt;Отключить исправление ошибок детализации слов;Распечатать подробную информацию об исправлении ошибок;Результат исправления ошибок\tинтервал
Одна из первоначальных целей этого проекта — сравнить и поделиться различными методами исправления текстовых ошибок и вдохновить других. Для меня было бы большой честью, если бы это могло вдохновить всех на задачу исправления текстовых ошибок.
В основном использовались различные глубокие модели, применяемые для исправления. ошибок в тексте Задача,分别да前面МодельВведение в разделизmacbert、seq2seq、
bert、electra、transformer
、ernie-csc、T5,каждый Модельметод内置于pycorrectorдокумент夹下,иметьREADME.mdПодробное руководство,Каждую модель можно запускать независимо,Нет зависимости друг от друга.
- Установить зависимости
pip install -r requirements-dev.txt8. Рекомендации по модели
Каждая модель может независимо предварительно обрабатывать данные, обучаться и прогнозировать.
8.1 Рекомендации по модели MacBert4csc
Модель исправления орфографии на китайском языке, основанная на MacBERT, которая меняет структуру сети. Исходный код модели выложен на HuggingFace. Models:https://huggingface.co/shibing624/macbert4csc-base-chinese
Модельная структура сети:
- Этот проект представляет собой модель исправления текстовых ошибок на китайском языке, которая меняет сетевую структуру MacBERT и может поддерживать модели типа BERT в качестве магистрали.
- на родном языке BERT В модель были внесены волшебные изменения и добавлен полносвязный слой для обнаружения ошибок. detection , MacBERT4CSC Для обучения detection слой и correction слоистый loss взвешенный, чтобы выйти в финал потеря. Используется при прогнозировании BERT MLM из correction Просто вес.
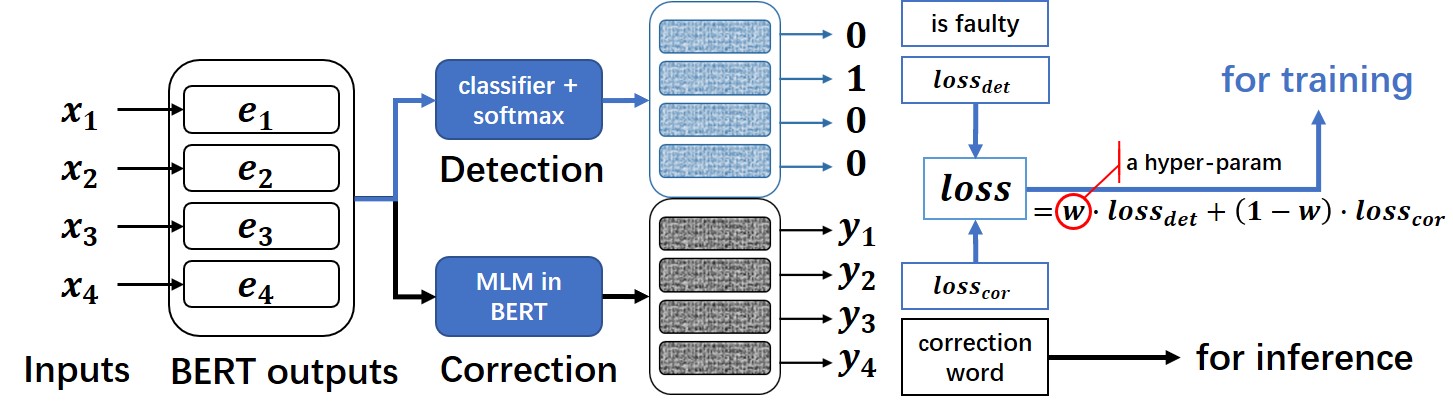
Подробные руководства см. в pycorrector/macbert/README.md.
example:examples/macbert_demo.py
- 8.1.1 Используйте pycorrector для вызова исправления ошибок:
import sys
sys.path.append("..")
from pycorrector.macbert.macbert_corrector import MacBertCorrector
if __name__ == '__main__':
error_sentences = [
— Извините, что беспокою вас. Надеюсь, ты будешь хорошо танцевать,
«Юные пионеры должны уступить места старикам»,
«Машинное обучение — лучшее выражение интеллекта и знаний в области искусственного интеллекта»,
«Небольшая рыбная лодка плывет по реке Пинцзин»,
«Мой родной город — край яркой рыбы и риса»,
]
m = MacBertCorrector("shibing624/macbert4csc-base-chinese")
for line in error_sentences:
correct_sent, err = m.macbert_correct(line)
print("query:{} => {}, err:{}".format(line, correct_sent, err))output:
запрос: Мне очень жаль, что я вас побеспокоил. надеюсь, ты будешь хорошо танцевать => Мне очень жаль, что я беспокою вас. Надеюсь, ты хорошо проведешь время, танцуя, ошибка:[('Нет', 'танец', 14, 15)]
запрос:Пионеры должны уступить места старикам => Юные пионеры должны уступить места старикам, ошибка:[('потому что', 'отвечать', 4, 5)]
Вопрос: Машинное обучение является наиболее разумным выражением интеллекта в области искусственного интеллекта. => Машинное обучение — это область искусственного интеллекта, которая лучше всего воплощает интеллект. ошибка:[('семь', 'посуда', 1, 2), ('сталкиваться', 'домен', 10, 11)]
запрос:Небольшая лодка с рыбой плывет по реке Пинцзин. => Маленькая рыбацкая лодка плывет по реке Пинцзин. err:[]
вопрос:Мой родной город — край рыбы и риса => Мой родной город известен как край рыбы и риса. ошибка:[('яркий', 'имя', 6, 7)]- 8.1.2 Используйте собственную библиотеку преобразователей для вызова исправления ошибок:
import operator
import torch
from transformers import BertTokenizerFast, BertForMaskedLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizerFast.from_pretrained("shibing624/macbert4csc-base-chinese")
model = BertForMaskedLM.from_pretrained("shibing624/macbert4csc-base-chinese")
model.to(device)
texts = ["Новая ситуация сегодня очень хорошая", «Я очень рада, что ты нашел свою любимую работу».]
text_tokens = tokenizer(texts, padding=True, return_tensors='pt').to(device)
with torch.no_grad():
outputs = model(**text_tokens)
def get_errors(corrected_text, origin_text):
sub_details = []
for i, ori_char in enumerate(origin_text):
if ori_char in [' ', '“', '”', '‘', '’', '\n', '…', '—', 'Дуть']:
# add unk word
corrected_text = corrected_text[:i] + ori_char + corrected_text[i:]
continue
if i >= len(corrected_text):
break
if ori_char != corrected_text[i]:
if ori_char.lower() == corrected_text[i]:
# pass english upper char
corrected_text = corrected_text[:i] + ori_char + corrected_text[i + 1:]
continue
sub_details.append((ori_char, corrected_text[i], i, i + 1))
sub_details = sorted(sub_details, key=operator.itemgetter(2))
return corrected_text, sub_details
result = []
for ids, (i, text) in zip(outputs.logits, enumerate(texts)):
_text = tokenizer.decode((torch.argmax(ids, dim=-1) * text_tokens.attention_mask[i]),
skip_special_tokens=True).replace(' ', '')
corrected_text, details = get_errors(_text, text)
print(text, ' => ', corrected_text, details)
result.append((corrected_text, details))
print(result)output:
Сегодняшняя новая любовь очень хороша => У меня сегодня хорошее настроение [('новый', 'Сердце', 2, 3)]
Я также очень рада, что вы нашли свою любимую работу. => Я также рада, что вы нашли свою любимую работу. [('Сердце', 'процветать', 15, 16)]Файл модели:
macbert4csc-base-chinese
├── config.json
├── added_tokens.json
├── pytorch_model.bin
├── special_tokens_map.json
├── tokenizer_config.json
└── vocab.txt8.2 Модель ErnieCSC
на основеERNIEизисправление китайской орфографии Модель,Модель Уже открытый исходный код вPaddleNLPиз
Модельбиблиотекаhttps://bj.bcebos.com/paddlenlp/taskflow/text_correction/csc-ernie-1.0/csc-ernie-1.0.pdparams。
Модельная структура сети:
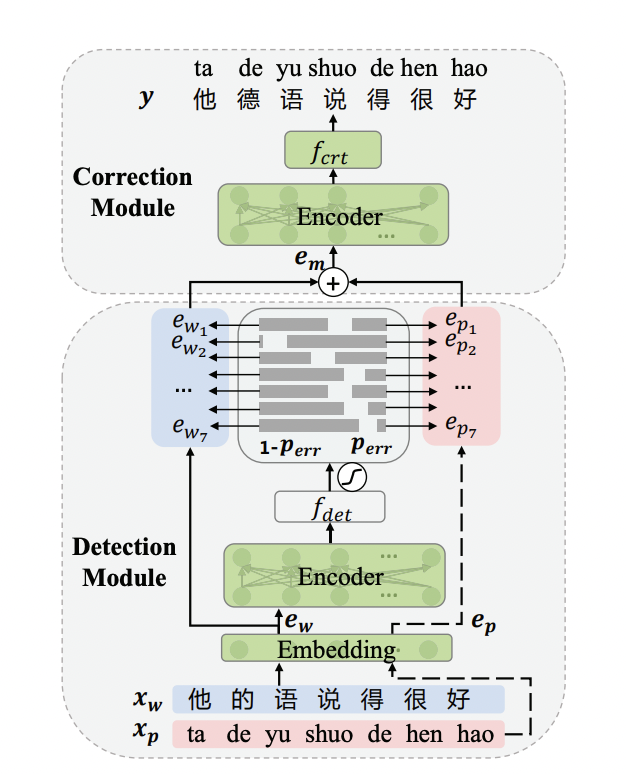
Подробные руководства см. в pycorrector/ernie_csc/README.md.
example:examples/ernie_csc_demo.py
- Используйте pycorrector для вызова исправления ошибок:
from pycorrector.ernie_csc.ernie_csc_corrector import ErnieCSCCorrector
if __name__ == '__main__':
error_sentences = [
— Извините, что беспокою вас. Надеюсь, ты будешь хорошо танцевать,
«Юные пионеры должны уступить места старикам»,
«Машинное обучение — лучшее выражение интеллекта и знаний в области искусственного интеллекта»,
«Небольшая рыбная лодка плывет по реке Пинцзин»,
«Мой родной город — край яркой рыбы и риса»,
]
corrector = ErnieCSCCorrector("csc-ernie-1.0")
for line in error_sentences:
result = corrector.ernie_csc_correct(line)[0]
print("query:{} => {}, err:{}".format(line, result['target'], result['errors']))output:
запрос: Мне очень жаль, что я вас побеспокоил. надеюсь, ты будешь хорошо танцевать => Мне очень жаль, что я беспокою вас. Надеюсь, ты хорошо проведешь время, танцуя, err:[{'position': 14, 'correction': {'никто': 'танец'}}]
запрос:Пионеры должны уступить места старикам => Юные пионеры должны уступить места старикам, err:[{'position': 4, 'correction': {'потому что': 'отвечать'}}, {'position': 10, 'correction': {'сидеть': 'сиденье'}}]
Вопрос: Машинное обучение является наиболее разумным выражением интеллекта в области искусственного интеллекта. => Машинное обучение — это область искусственного интеллекта, которая лучше всего воплощает интеллект. err:[{'position': 1, 'correction': {'Семь': 'Инструмент'}}, {'position': 10, 'correction': {'сталкиваться': 'домен'}}]
запрос:Небольшая лодка с рыбой плывет по реке Пинцзин. => Маленькая рыбацкая лодка плывет по реке Пинцзин. err:[]
вопрос:Мой родной город — край рыбы и риса => Мой родной город известен как край рыбы и риса. err:[{'position': 6, 'correction': {'яркий':'имя'}}]- Используйте библиотеку PaddleNLP для вызова исправления ошибок:
Вы можете использовать инструмент Taskflow, предоставляемый PaddleNLP, для исправления ошибок во входном тексте одним щелчком мыши. Конкретное использование заключается в следующем:
from paddlenlp import Taskflow
text_correction = Taskflow("text_correction")
text_correction('Когда мы сталкиваемся с невзгодами, мы должны иметь смелость противостоять им, и мы должны становиться более мужественными с каждой неудачей, чтобы мы могли двигаться вперед по пути к успеху.')
text_correction('人生就да如此,Только благодаря тренировкам можно стать сильнее,Чтобы стать более оптимистичным. ')output:
[{'source': «Когда мы сталкиваемся с невзгодами, мы должны смело противостоять им и становиться более мужественными с каждой неудачей, чтобы мы могли двигаться вперед по пути к успеху. ',
'target': «Когда мы сталкиваемся с невзгодами, мы должны смело противостоять им и становиться более мужественными с каждой неудачей, чтобы мы могли двигаться вперед по пути к успеху. ',
'errors': [{'position': 3, 'correction': {'на самом деле': 'территория'}}]}]
[{'source': «Жизнь такова. Только закалившись, можно стать сильнее и оптимистичнее. ',
'target': «Жизнь такова. Только закалившись, можно стать сильнее и оптимистичнее. ',
'errors': [{'position': 18, 'correction': {'мне': 'β'}}]}]8.3 Модель Барта
from transformers import BertTokenizerFast
from textgen import BartSeq2SeqModel
tokenizer = BertTokenizerFast.from_pretrained('shibing624/bart4csc-base-chinese')
model = BartSeq2SeqModel(
encoder_type='bart',
encoder_decoder_type='bart',
encoder_decoder_name='shibing624/bart4csc-base-chinese',
tokenizer=tokenizer,
args={"max_length": 128, "eval_batch_size": 128})
sentences = [«Пионеры должны уступить места старикам»]
print(model.predict(sentences))output:
['Юные пионеры должны уступить места старикам']Если вам нужно обучить модель Барта, см. https://github.com/shibing624/textgen/blob/main/examples/seq2seq/training_bartseq2seq_zh_demo.py
- Release models
Модель Барта, обученная на основе китайского набора данных для исправления ошибок SIGHAN+Wang271K, была опубликована в HuggingFace Models:
- Модель BART: исходный код модели открыт на HuggingFace. Models:https://huggingface.co/shibing624/bart4csc-base-chinese
№3 8.4 Модель ConvSeq2Seq
Пример использования модели pycorrector/seq2seq:
- тренироваться data example:#train.txt: Вы правы по сравнению с теми безработными, вам повезло. Вы правы по сравнению с теми безработными, вам повезло.
cd seq2seq
python train.pyconvseq2seqтренироватьсяsighanНабор данных(2104полосовой образец),200 эпох,Одна карта P40GPUтренироваться занимает: 3 минуты.
- предсказывать
python infer.pyoutput:
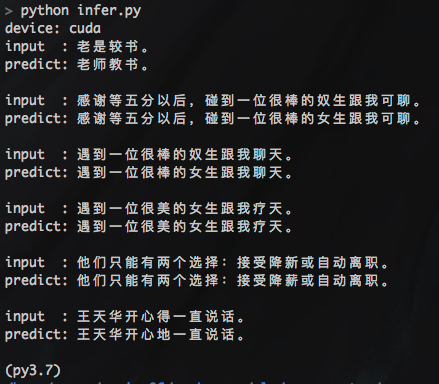
- Если тренироваться данных слишком мало (менее 10 000 позиций),Глубокая подгонка модели,появитсяпредсказывать Результаты все
unkиз Состояние,Решение: увеличить выборку тренироваться.,Используйте исправление ошибок, представленное ниже (nlpcc2018+hsk,1,3 миллиона пар предложений) попробуйте. - глубина Модельтренироваться Кропотливый,Если у вас есть графический процессор, попробуйте использовать его,ускорятьсятренироваться,Экономьте время.
- Release models
Модель convseq2seq, обученная на основе набора данных SIGHAN2015, была опубликована на github:
- convseq2seq model url: https://github.com/shibing624/pycorrector/releases/download/0.4.5/convseq2seq_correction.tar.gz
9.Набор данных
9.1 Наборы данных с открытым исходным кодом
Набор данных | корпус | Ссылка для скачивания | Размер сжатой упаковки |
|---|---|---|---|
| СИГАН+Ванг271K(270 000 шт.) | 106M | |
| SIGHAN13 14 15 | 339K | |
| Wang271K | 93M | |
| People's Daily, выпуск 2014 г. | 383M | |
| NLPCC2018-GEC | 114M | |
| nlpcc2018+hsk+CGED | 215M | |
| HSK+Lang8 | 81M | |
| Chinese Text Correction(CTC) | - |
проиллюстрировать:
- SIGHAN+Wang271K Набор для исправления ошибок на китайском языке данных (270 000 элементов), прошедших через исходный SIGHAN13, 14 и 15 лет. данныхиWang271KНабор После преобразования формата данных получается формат json с информацией о позиции символа ошибки, SIGHAN — это test.json, Модель macbert4csc тренироваться можно использовать непосредственно с этим набором. данные воспроизводят точные результаты статьи, подробности см. на pycorrector/macbert/README.md.
- NLPCC 2018 Официальная коллекция GEC данныхNLPCC2018-GEC, тренироватьсянаборtrainingdataПосле декомпрессии114.5MB,Формат данных — необработанный текст.,Никакой обработки сегментации слов не проводилось.
- Тест на знание китайского языка(HSK)иlang8оригинальный平行корпусHSK+Lang8(https://pan.baidu.com/s/1DaOX89uL1JRaZclfrV9C0g),Набор данных был сегментирован,Может использоваться для усиления данных.
- NLPCC 2018 + HSK + Данные CGED16, 17 и 18 сегментируются по символам, преобразуются из традиционного в упрощенный и перемешиваются в порядке данных. После предварительной обработки они генерируются для исправления ошибок корпус(nlpcc2018+hsk). ,Baidu Netdisk (пароль: m6fg) 1,3 миллиона пар предложений, 215 МБ
SIGHAN+Wang271K Набор для исправления ошибок на китайском языке данные, формат данных:
[
{
"id": "B2-4029-3",
"original_text": «Вы будете слышать голоса ночью. Днем люди не обращают на них особого внимания, но когда они спят, голоса становятся кошмаром для каждого».
"wrong_ids": [
5,
31
],
"correct_text": «Ночью вы услышите шум. Днем люди не обращают на него особого внимания, но во время сна шум становится кошмаром для каждого».
}
]Объяснение поля:
- id: уникальный идентификатор, бессмысленный
- original_text: исходный текст ошибки
- неправильные_идсы: неправильная позиция слова, начиная с 0.
- correct_text: Исправленный текст
9.2 Собственный набор данных
Вы можете использовать свой собственный набор данныхтренироваться Коррекция Модель,Отметьте себя Набор данных,Сохранить как следоватьтренироваться样本набор一样изформат json,然后нагрузка数据тренироваться Модель Вот и все。
- Уже существует большое количество примеров ошибок, связанных с бизнесом.,В основном отмечайте место ошибки (wrong_ids) и исправленное предложение (correct_text).
- Готового образца ошибки нет,Вы можете написать скрипт для генерации образцов ошибок (original_text),Измените правильное предложение из символов указанной позиции (wrong_ids) на опечатки на основе таких характеристик, как фонетическое сходство и сходство формы.,прикреплять 第三方同音字生成脚本Замена омофона
10. Резюме
Что такое языковая модель? -вики
язык Модель对于Коррекция步骤至关重要,В настоящее время используется по умолчаниюизда从千兆中文文本тренироватьсяиз中文язык Модельzh_giga.no_cna_cmn.prune01244.klm(2.8G),
ОбеспечитьPeople's Daily, выпуск 2014 г.корпустренироватьсяполучатьиз轻量版язык Модельлюди2014corpus_chars.klm (пароль o5e9)。
Вы можете использовать китайскую Wiki(Преобразование традиционного китайского языка в упрощенный китайский,Эта функция доступна в pycorrector.utils.text_utils) и других корпусах данныхтренироваться в общих чертах из языковой модели.,Или вы можете использовать более специализированную языковую модель в профессиональной сфере корпустренироваться. Больше подходит для языковой модели,Эффект исправления ошибок будет лучше улучшен.
- kenlmязык Модельтренироватьсяинструментизиспользовать,Посмотреть блог:http://blog.csdn.net/mingzai624/article/details/79560063
- прикреплятьтренироватьсякорпус<People's Daily, выпуск 2014 г.Спелыйкорпус>,включать: 1) Стандартная ручная сегментация слов и данные о частях речиpeople2014.tar.gz, 2) Неразрезанные текстовые данные слова People2014_words.txt, 3) kenlmтренироваться файл языковой модели словесной детализации и его двоичный файл People2014corpus_chars.arps/klm, 4) файл языковой модели слов kenlm и его двоичный файл People2014corpus_words.arps/klm.
- Todo
- Оптимизируйте словарь похожих слов и улучшите точность исправления ошибок похожих слов.
- Организовать китайскую коррекцию ошибок тренировать данные,использоватьseq2seq做глубина中文Коррекция Модель
- Добавлены возможности обнаружения и исправления ошибок китайской грамматики.
- Метод правила добавляет определяемый пользователем набор исправлений ошибок и устанавливает для него наивысший приоритет исправления ошибок.
- seq2seq_attention добавляет отсев, чтобы уменьшить переобучение
- В структуру модели seq2seq добавлены новые функции, такие как сеть генератора указателей, поиск по лучу, замена неизвестных слов и механизм покрытия.
- Обновите bertizfine-tuned для использования вики, адаптируйте библиотеку Transformers 2.10.0
- Код обновления, совместимый с библиотекой TensorFlow 2.0.
- Обновите логику коррекции ошибок bert, чтобы улучшить эффект коррекции ошибок на основе маски.
- 新增на основеelectraМодельиз Коррекция逻辑,Параметры меньше,предсказывать更快
- 新增专用于Коррекция Задачаглубина Модель,использоватьbert/ernieпредварительнотренироваться Модель,Добавьте текстовые фонетические и фигурные функции.
- Reference
- Китайская система исправления ошибок на основе грамматической модели
- Norvig’s spelling corrector
- Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape[Yu, 2013]
- Chinese Spelling Checker Based on Statistical Machine Translation[Chiu, 2013]
- Chinese Word Spelling Correction Based on Rule Induction[yeh, 2014]
- Neural Language Correction with Character-Based Attention[Ziang Xie, 2016]
- Chinese Spelling Check System Based on Tri-gram Model[Qiang Huang, 2014]
- Neural Abstractive Text Summarization with Sequence-to-Sequence Models[Tian Shi, 2018]
- Исследование и внедрение автоматической корректуры китайских текстов на основе глубокого обучения [Ян Цзунлинь, 2019]
- A Sequence to Sequence Learning for Chinese Grammatical Error Correction[Hongkai Ren, 2018]
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
- Revisiting Pre-trained Models for Chinese Natural Language Processing
- Ruiqing Zhang, Chao Pang et al. "Correcting Chinese Spelling Errors with Phonetic Pre-training", ACL, 2021
- DingminWang et al. "A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check", EMNLP, 2018
Справочная ссылка:https://github.com/shibing624/pycorrector



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
