Иметь деньги на покупку карт недостаточно. Насколько сложно построить кластер H100 на 100 000 карт? Статья, анализирующая ключевые моменты технологии кластерной вычислительной мощности.
Монтажер: Цяо Ян Со сонный
【Шин Джиген Введение】Рыночная стоимость Nvidia резко выросла、Технологические гиганты копят чипы,Мы склонны упускать из виду, как чипы графических процессоров преобразуются в вычислительную мощность центров обработки данных. недавний,Техническая статья SemiAnaанализа дает подробное объяснение процесса создания H100кластера на 100 000 калорий.
В условиях бушующей конкуренции ИИ «война за вычислительные мощности» также находится в самом разгаре.
Несколько ведущих компаний, включая, помимо прочего, OpenAI, Microsoft, xAI и Meta, пытаются создать кластеры графических процессоров с более чем 100 000 картами. В этом масштабе стоимость одних только серверов превышает 4 миллиарда долларов США. Это ограничивается многими факторами. например, мощность центра обработки данных и недостаточная мощность.
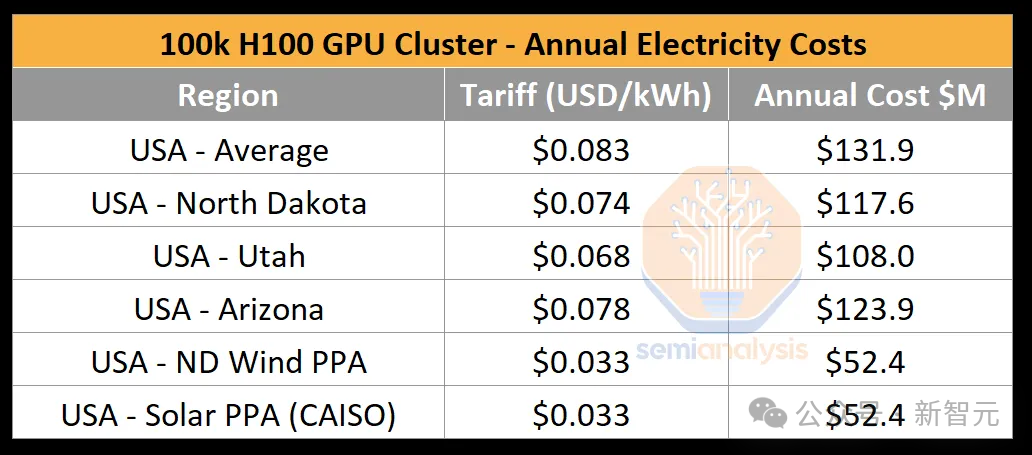
Мы можем сделать простую оценку. Кластер из 100 000 карт потребляет около 1,59 тераватт-часов (тераватт-ч, или 10,9 киловатт-часов) в год. Согласно стандартному тарифу на электроэнергию в США, равному 0,78 доллара США за киловатт-час, годовое потребление энергии только стоимость электроэнергии достигла 124 миллионов долларов США.
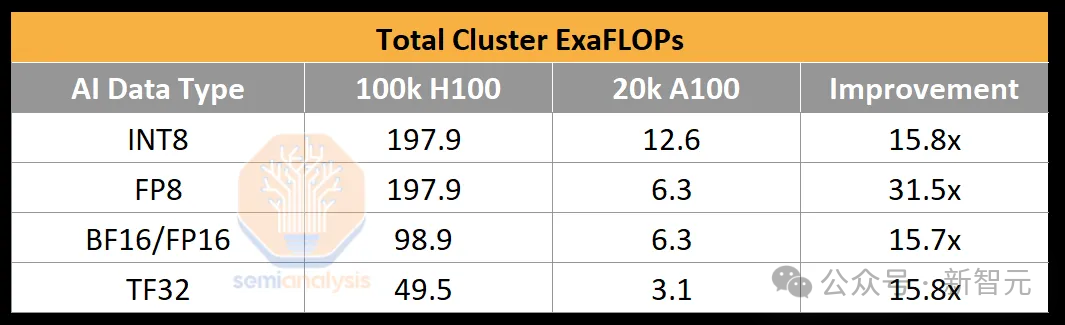
Чтобы проиллюстрировать мощную вычислительную мощность 100 000 кластеров графических процессоров, OpenAI использовала примерно 2,15e25 BF16 FLOP (21,5 квадриллиона ExaFLOP) при обучении GPT-4, обучении примерно на 20 000 A100 в течение 90–100 дней. Пиковая пропускная способность составляет всего 6,28 ExaFLOPs.
Если вместо A100 использовать 100 000 H100, пиковое значение взлетит до 198/99 FP8/FP16 ExaFLOPS, увеличившись в 31,5 раза.
На H100, когда лаборатория искусственного интеллекта обучает модель с триллионом параметров, коэффициент использования FLOP (MFU) модели FP8 может достигать 35%, а MFU FP16 — 40%.
MFU, что означает полное использование модели, является мерой эффективной пропускной способности и пикового использования потенциальных FLOP с учетом различных узких мест, таких как ограничения мощности, нестабильность связи, пересчет, задержка и неэффективные ядра.
Используя FP8, кластер H100 на 100 000 карт может обучить GPT-4 всего за 4 дня. Если вы тренируетесь в течение 100 дней, вы можете достичь эффективного FP8 FLOP примерно 6e26 (600 exaFLOPs). Однако низкая надежность аппаратной части может существенно снизить MFU.
Многие люди считают, что среди трех основных инфраструктур ИИ: данных, алгоритмов и вычислительной мощности, самой низкой пороговой величиной является вычислительная мощность. Пока у вас есть деньги и ресурсы и вы покупаете достаточно чипов, нехватка вычислительной мощности не будет проблемой.
Однако в недавней статье SemiAnaанализа указывается, что это совершенно не так. Создать кластер вычислительной мощности определенно сложнее, чем потратить много денег.
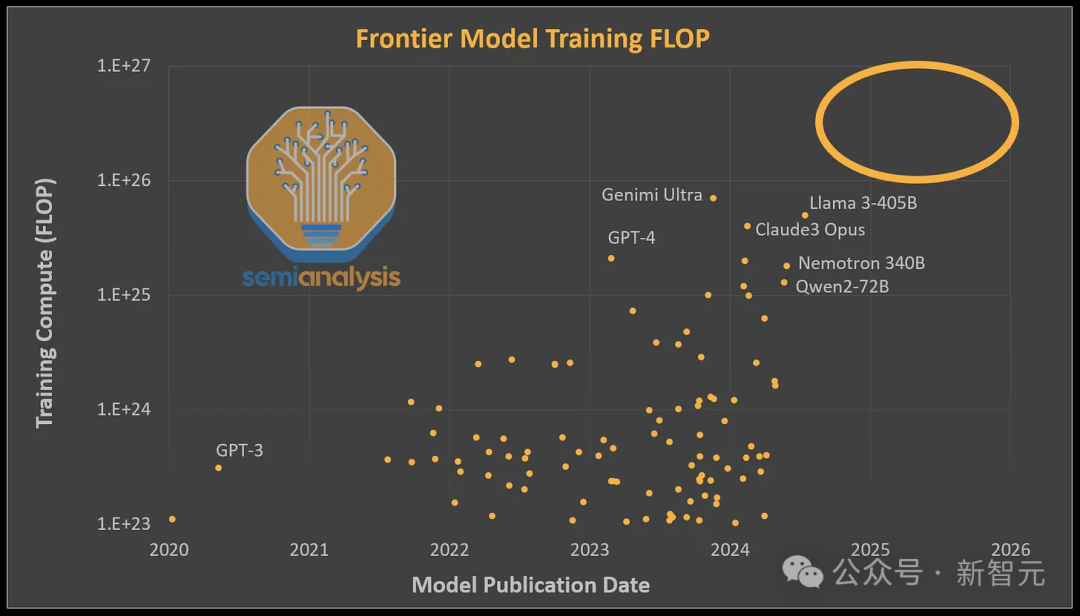
С момента выпуска GPT-4 кажется, что следующее поколение LLM с более мощными возможностями еще не появилось. Важная причина заключается в том, что немногие организации могут увеличить объем вычислений, посвященных одной модели в больших масштабах.
Такие модели, как Gemini Ultra, Nemotron 340B и Llama 3, имеют аналогичные требования к вычислительным вычислениям для обучения, что и GPT-4 (около 2e25 FLOP), или даже выше, но используют плохую кластерную архитектуру, что не позволяет им дальше раскрывать свои возможности.
Итак, с какими препятствиями сталкиваются гиганты в процессе развертывания кластеров графических процессоров на 100 000 карт?
Силовой вызов
Общая мощность ключевых ИТ-компонентов, необходимых для кластера из 100 000 карт, составляет около 150 МВт. Для сравнения, ключевая ИТ-мощность El Capitan, крупнейшего национального лабораторного суперкомпьютера в США, составляет всего 30 МВт, что составляет примерно одну пятую. затмевает это.
При всей этой мощности сам графический процессор фактически потребляет меньше половины.
По официальным параметрам мощность каждого H100 составляет 700Вт, но на сервере есть и такие устройства, как ЦП, сетевая карта (NIC), блок питания (блок питания) и мощность около 575Вт.
Помимо серверов H100, в кластере необходимо развернуть ряд серверов хранения, сетевых коммутаторов, узлов ЦП, оптоволоконных приемопередатчиков и многих других устройств, на которые приходится около 10% энергопотребления ИТ.
В настоящее время ни одно здание центра обработки данных не имеет возможности разместить оборудование мощностью 150 МВт. Таким образом, построенные 100 000 кластеров графических процессоров обычно распределяются по всему кампусу, а не по одному зданию.
Имея ограниченное количество центров обработки данных, компания xAI даже решила преобразовать старую фабрику в Мемфисе, штат Теннесси, в центр обработки данных.
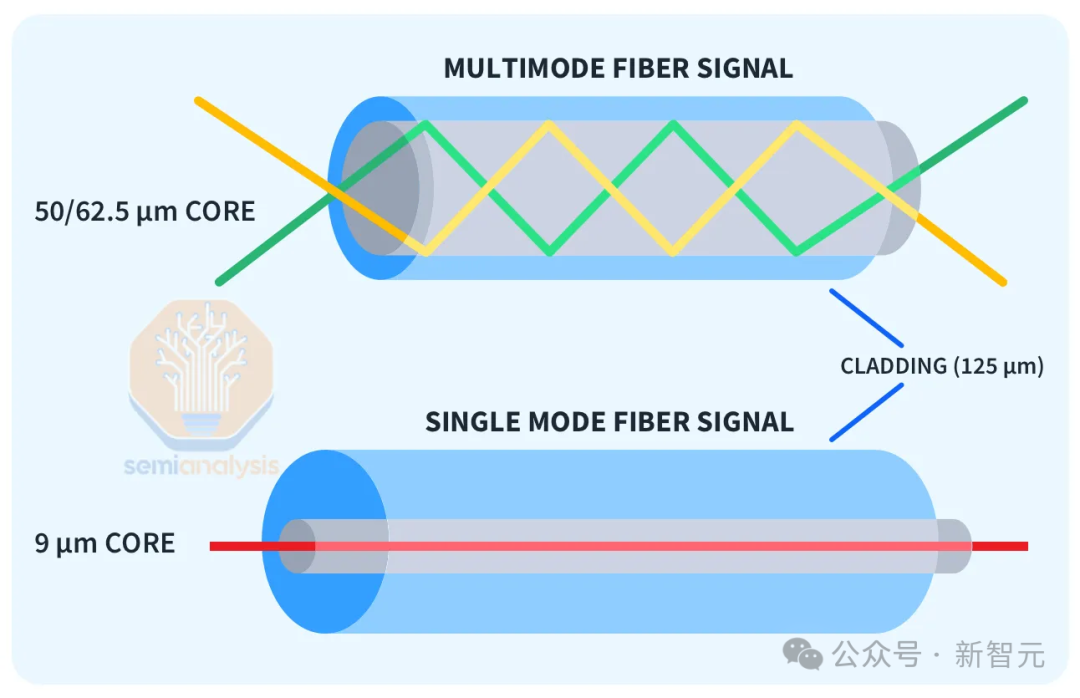
Поскольку серверы распределены по всему кампусу, а не в одном здании, сетевые затраты возрастут незаметно, поскольку стоимость оптоволоконных трансиверов пропорциональна расстоянию передачи.
«Многомодовые» трансиверы SR и AOC поддерживают передачу только на расстояния до 50 м и, очевидно, недоступны. «Одномодовые» трансиверы DR и FR на большие расстояния могут надежно передавать сигналы в диапазоне от 500 м до 2 км, но стоимость в 2,5 раза выше.
Кроме того, дальность передачи когерентных оптических трансиверов 800 паркового уровня может превышать 2 км, но цена дороже, более чем в 10 раз.
В небольших кластерах H100 обычно используются только многомодовые трансиверы для соединения каждого графического процессора на скорости 400G через один или два уровня коммутаторов. Если это большой кластер, потребуется добавить больше уровней коммутаторов, а оптоволоконное оборудование также будет чрезвычайно дорогим.
В больших кластерных кампусах каждое здание содержит один или несколько модулей, соединенных многомодовыми приемопередатчиками (или более дешевыми медными кабелями), образующими «вычислительный остров». Каждый вычислительный остров соединен между собой посредством трансиверов дальней связи. Пропускная способность внутри острова высокая, а полоса пропускания между островами низкая.
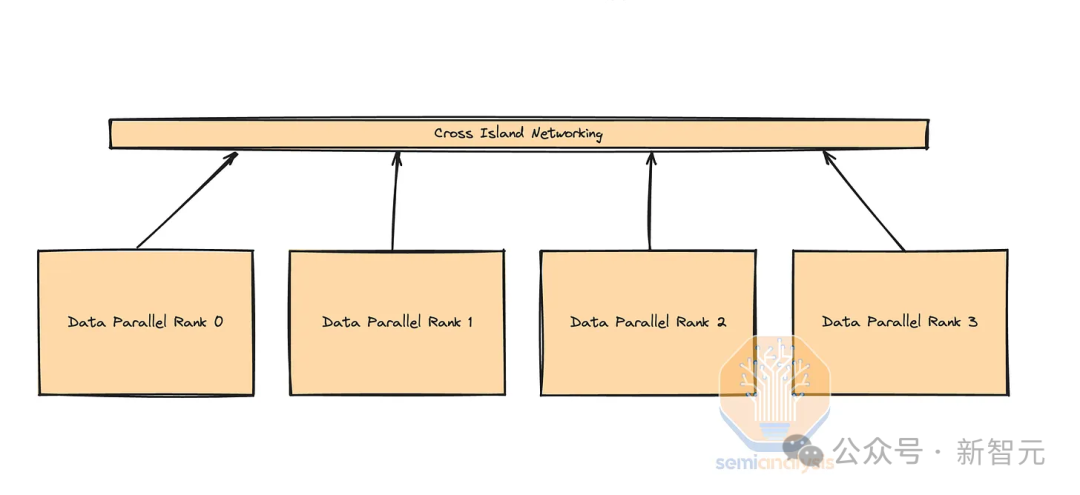
Схема распараллеливания
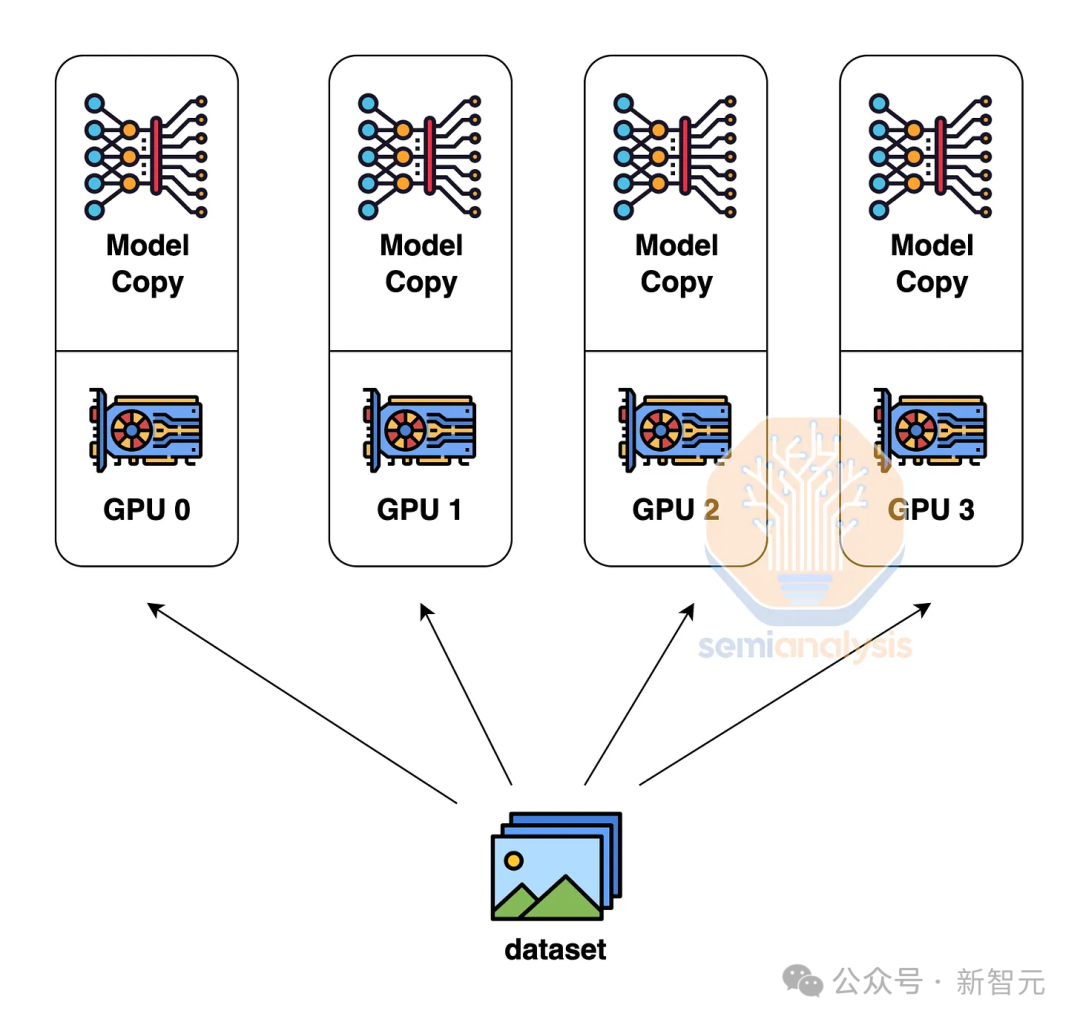
параллелизм данных
При обучении с более крупными параметрами обычно существует три различных типа распараллеливания: параллелизм данных, тензорный параллелизм и конвейерный конвейер. параллелизм).
параллелизм данных — это самый простой параллельный метод: каждый GPU имеет все копии весов модели и сохраняет часть данных отдельно.
Во время прямого расчета графический процессор работает самостоятельно.,При обновлении градиента добавьте градиенты, рассчитанные всеми графическими процессорами.,Обновляемся снова вместе,Итак, тремя способами,параллелизм данных имеет минимальные требования для связи между графическими процессорами.
Однако этот подход требует, чтобы каждый графический процессор имел достаточно памяти для хранения весов всей модели, функций активации и состояния оптимизатора. LLM такого уровня, как GPT-4, может достигать 1,8 триллиона параметров и требует 10,8 ТБ памяти, которую явно не втиснуть в один GPU.
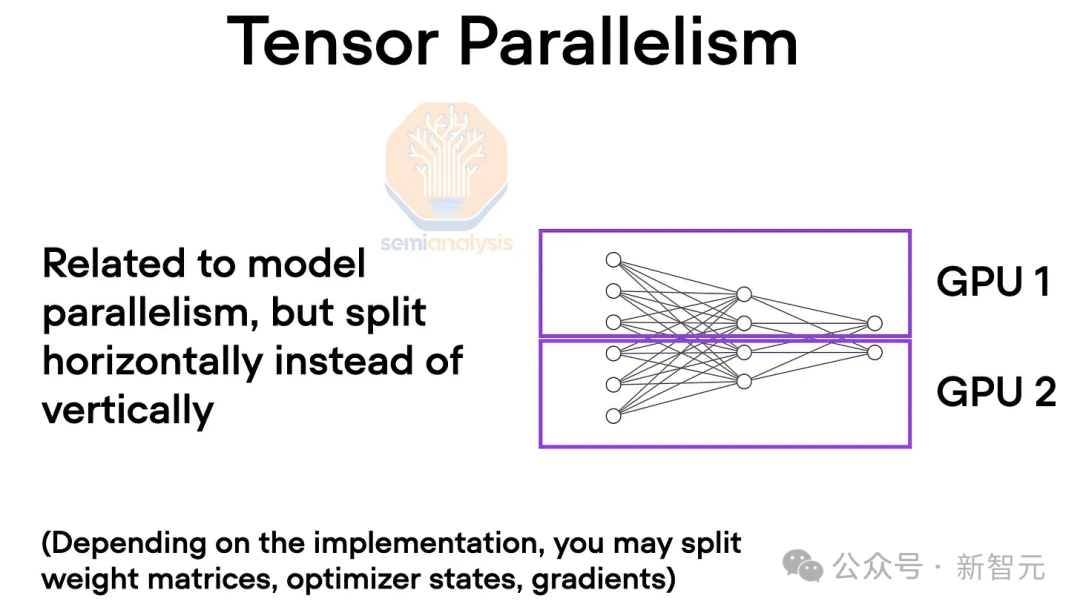
тензорный параллелизм
Чтобы преодолеть ограничения памяти,Кто-то предложил тензорный параллелизм: веса и вычисления каждого слоя нейронной сети распределяются по нескольким графическим процессорам.,Как правило, все скрытые слои будут скрыты. В таких операциях, как самообслуживание, сеть прямой связи и нормализация каждого слоя.,Все они требуют многократного сокращения между устройствами.
Можно представить, что при прямом вычислении каждого слоя все графические процессоры работают вместе, как если бы они образовывали гигантский графический процессор.
В настоящее время в NVLink обычно используется 8 уровней тензорного параллелизма, что эквивалентно уменьшению потребления памяти каждого графического процессора до одной восьмой от исходного.
Поскольку этот метод требует частого обмена данными между устройствами, для него требуется сетевая среда с высокой пропускной способностью и малой задержкой.
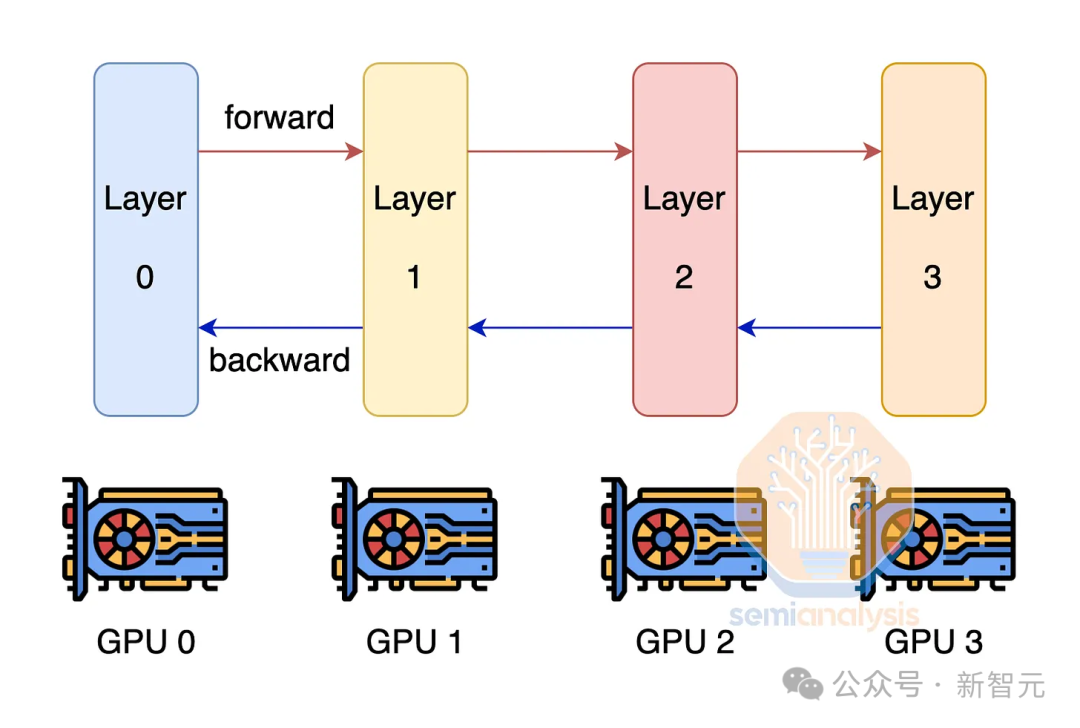
Параллелизм трубопроводов
Кроме тензорного параллелизм, другое решение проблемы нехватки памяти графического процессора - параллелизм. трубопроводов。
Как следует из названия, это решение рассматривает прямые вычисления как конвейер. Каждый графический процессор отвечает за одно соединение, то есть за один или несколько слоев в сети. После завершения расчета результаты передаются следующему графическому процессору.
Параллелизм трубопроводов также предъявляет высокие требования к междевайсной коммуникации, но нет тензорного параллелизм настолько суров.
Чтобы максимизировать использование модели FLOP, три параллельных режима обычно используются в комбинации для формирования 3D-параллелизма.
тензорный параллелизм предъявляет самые высокие требования к связи, поэтому его следует использовать на нескольких графических процессорах одного сервера, Затем используйте конвейерный параллелизм между узлами на одном вычислительном острове.
Благодаря параллелизму данные имеют минимальный объем передачи, а скорость сети между островами низкая, поэтому используйте параллелизм при пересечении вычислительных островов. данных。

веб-дизайн
Топология
При проектировании топологии сети необходимо также учитывать использованную Схему распараллеливания.
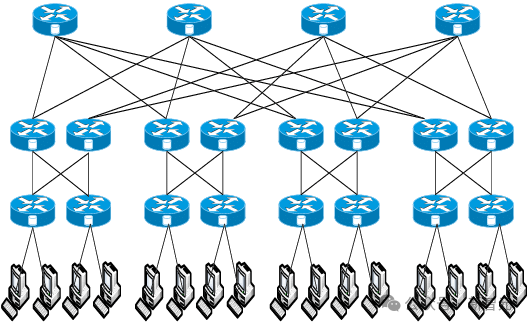
еслииспользоватьтолстое дерево Топология(fat-tree топологии) каждые два графических процессора соединены с максимальной пропускной способностью, что требует 4 уровней коммутации, что очень затратно.
бумага《Адаптивная схема балансировки нагрузки для сетей центров обработки данных с использованием программно-конфигурируемой сети》
Таким образом, ни один крупный кластер графических процессоров не сможет использовать полную архитектуру «толстого дерева». Вместо этого решение состоит в том, чтобы создать вычислительные острова с полной архитектурой «толстого дерева» при одновременном уменьшении пропускной способности между островами.
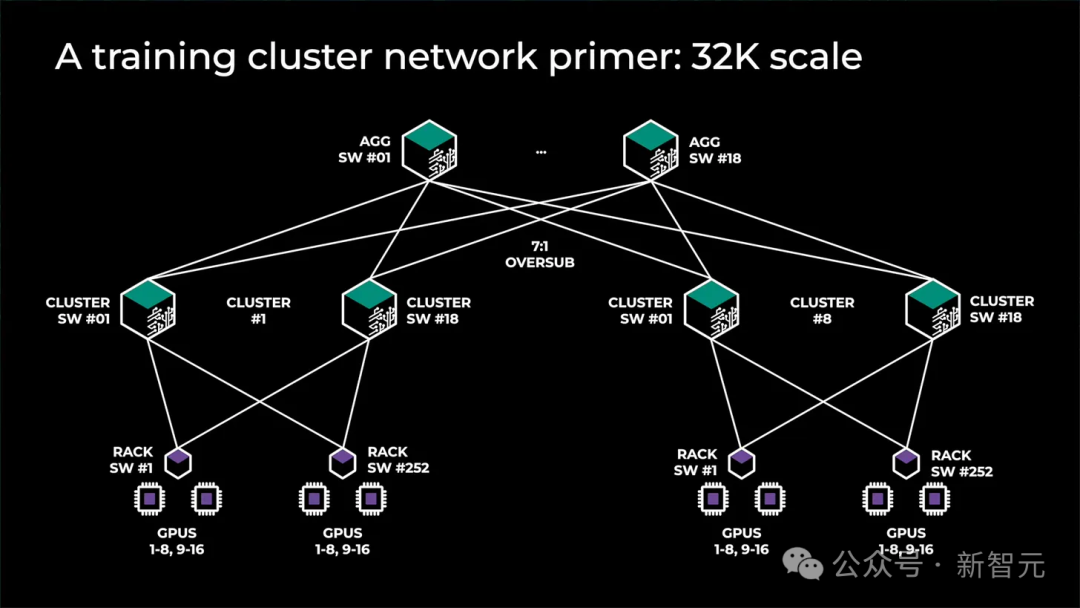
Например, кластерная архитектура графического процессора Meta предыдущего поколения использовала 32 000 чипов, всего 8 вычислительных островов. Между островами была развернута полноскоростная полоса пропускания, а затем был добавлен дополнительный уровень коммутации с коэффициентом конвергенции 7:1 (переподписка). сверху, поэтому скорость интернета между островами составляет одну седьмую от скорости внутри острова.
Развертывание сетевого оборудования
Графические процессоры развертываются в различных сетях, включая внешние сети, внутренние сети и расширенные сети (NVLink), при этом в каждой сети работают разные параллельные решения.
Для тензорного Что касается требований к полосе пропускания для параллелизма, NVLinkсеть, пожалуй, единственный достаточно быстрый. Серверная часть обычно легко справляется с большинством других типов параллелизма, но обычно может обрабатывать большинство других типов параллелизма только при наличии «коэффициента сходимости». данных。
Кроме того, в некоторых центрах обработки данных даже нет островков полосы пропускания «коэффициента конвергенции», настроенных на верхнем уровне. Вместо этого они переносят внутреннюю сеть во внешнюю сеть.
Крупная компания использует внешний Ethernet для обучения на нескольких вычислительных островах InfiniBand. Это связано с тем, что внешние сети обходятся гораздо дешевле и могут использовать существующие сети кампусов центров обработки данных и региональную маршрутизацию между зданиями.
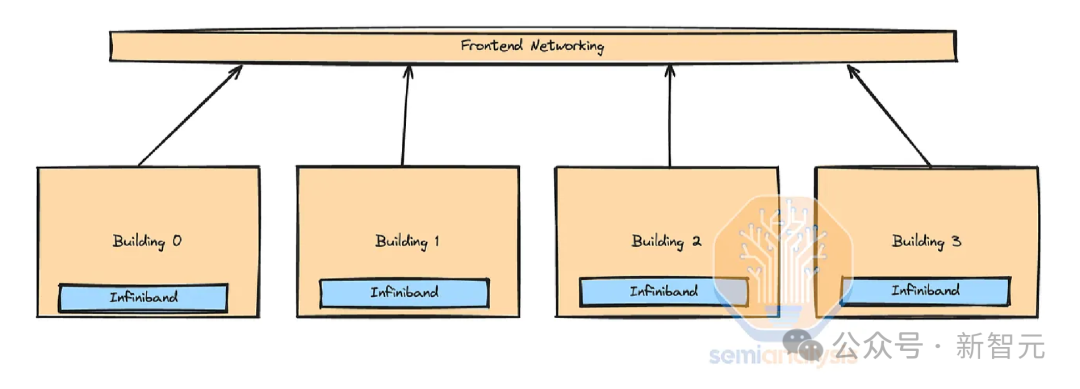
К сожалению, из-за внедрения редких технологий, таких как MoE, размеры моделей растут быстрее, а объем трафика, который должна обрабатывать интерфейсная сеть, увеличивается.
Этот компромисс должен быть тщательно оптимизирован, иначе вы столкнетесь с расходами на сеть между двумя вариантами, поскольку пропускная способность внешней сети в конечном итоге вырастет до уровня пропускной способности внутренней сети.
Стоит отметить, что Google использует интерфейсную сеть только при обучении модулей с несколькими TPU. Их «вычислительная структура», называемая ICI, может масштабироваться максимум до 8960 чипов, а каждая стойка с водяным охлаждением, содержащая 64 TPU, требует дорогостоящих оптоволоконных и оптических коммутаторов 800G для соединения между ними.
Поэтому Google должен сделать интерфейсную сеть TPU более мощной, чем большинство интерфейсных сетей графического процессора, чтобы компенсировать этот недостаток.
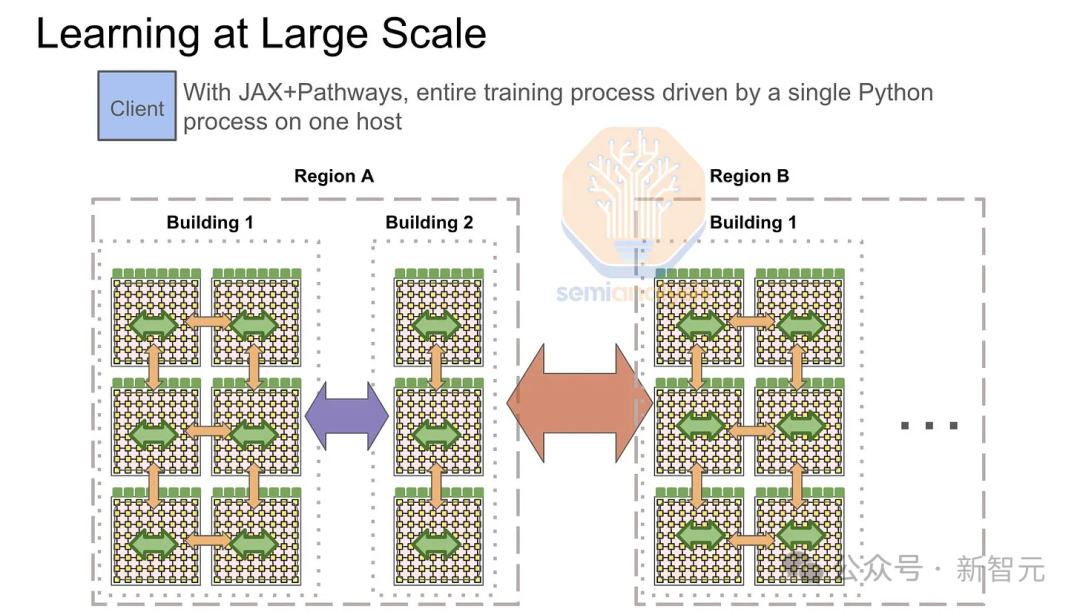
При использовании внешнего интерфейса во время обучения операция глобального сокращения должна иметь возможность полагаться на сетевую топологию между вычислительными островами.
Во-первых, каждый модуль или вычислительный остров будет выполнять локальные операции уменьшения-дисперсии внутри внутренней сети InfiniBand или ICI, так что каждый GPU/TPU будет владеть частью суммы градиентов.
Затем внешний Ethernet будет использоваться для выполнения перекрестного сокращения между каждым классом хостов, и, наконец, каждый модуль будет выполнять полную коллекцию на уровне модуля.
Интерфейсная сеть также отвечает за загрузку данных. По мере развития мультимодальных изображений и видеообучающих данных требования к внешним сетям будут расти в геометрической прогрессии.
В этом случае загрузка большого видеофайла и его уменьшение будут конкурировать за пропускную способность внешней сети.
Кроме того, из-за нерегулярного трафика сети хранения весь процесс сокращения замедлится, и прогнозное моделирование невозможно будет выполнить, тем самым увеличивая проблему задержек.
Другой метод — использовать 4-уровневую сеть InfiniBand с коэффициентом конвергенции 7:1, 4 модуля, каждый модуль имеет 24576 H100, и неблокируемую трехуровневую систему.
Это обеспечивает большую гибкость для увеличения пропускной способности в будущем, чем использование интерфейсной сети, поскольку добавление большего количества оптоволоконных трансиверов между коммутаторами в двух зданиях требует больше усилий, чем модернизация интерфейсных сетевых карт для каждого шасси в кластере. Гораздо проще.
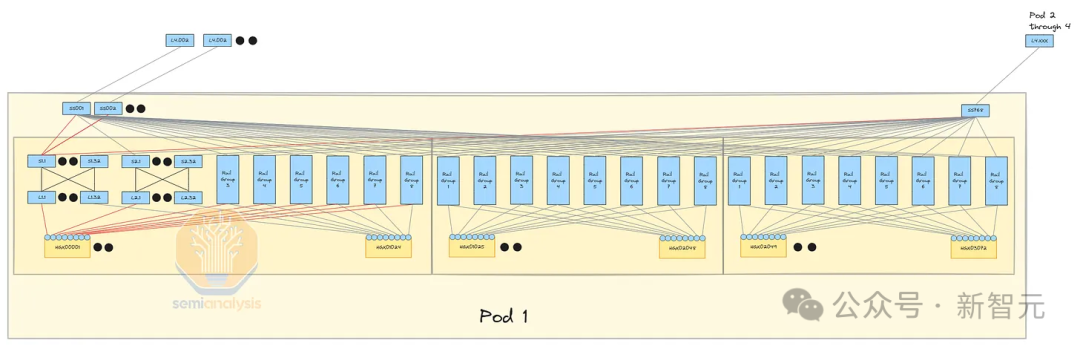
Это создает более стабильную сетевую модель, поскольку интерфейсная сеть может сосредоточиться исключительно на загрузке данных и проверке контрольных точек, а внутренняя сеть может сосредоточиться исключительно на взаимодействии между графическими процессорами. К сожалению, сети Infiniband уровня 4 очень дороги из-за необходимости использования дополнительных коммутаторов и трансиверов.
Оптимизация трека и промежуточный кадр
Для повышения удобства обслуживания и добавления медных кабелейсеть(<3рис)и многомодовыйсеть(<50рис)Использование,Некоторые клиенты предпочитают отказаться от дизайна, оптимизированного для направляющих, и перейти на средний дизайн рамы (дизайн Middle of Rack), рекомендованный NVIDIA.
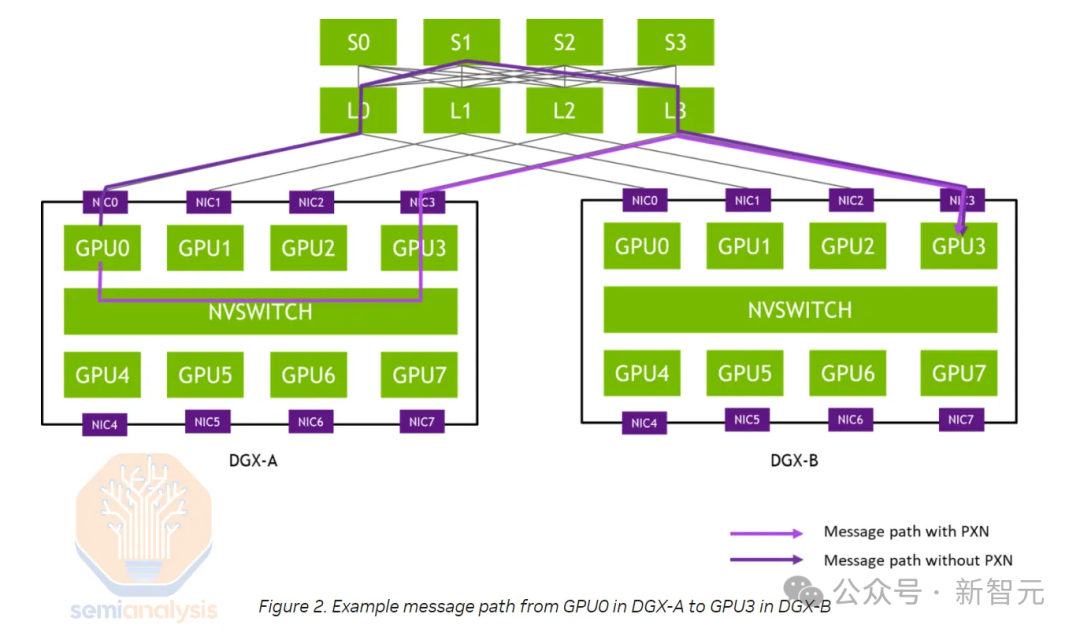
Орбитальная оптимизация — это технология, которая позволяет каждому серверу H100 подключаться к 8 различным конечным коммутаторам (вместо того, чтобы все они были подключены к коммутаторам в одной стойке), так что каждому графическому процессору достаточно подключить только один коммутатор для связи с этими дополнительными графическими процессорами для улучшения связи. эффективность коллективного общения «все на всех».
Например, при смешанном экспертном параллелизме (МОЭ) широко используется коллективное общение «все со всеми».

Недостаток конструкции, оптимизированной для рельсового подключения, заключается в том, что ее необходимо подключать к разным конечным коммутаторам на разных расстояниях, а не располагать один коммутатор в середине стойки рядом со всеми восемью графическими процессорами сервера.
Пассивные кабели прямого подключения (DAC) и активные кабели (AEC) можно использовать, когда коммутаторы находятся в одной стойке, но в конструкции, оптимизированной для трасс, коммутаторы не обязательно находятся в одной стойке, поэтому необходимо использовать оптику.
Кроме того, расстояние от листового коммутатора до каркасного коммутатора может превышать 50 метров, поэтому необходимо использовать одномодовые оптические трансиверы.
Благодаря конструкции, не оптимизированной для рельсовых соединений, вы можете заменить 98 304 оптоволоконных трансивера, соединяющих графический процессор и конечные коммутаторы, недорогими медными кабелями прямого подключения, в результате чего содержание меди в вашем канале графического процессора составит 25–33%.
Как вы можете видеть на схеме стойки ниже, подключение каждого графического процессора к коммутатору на плате больше не подключается сначала к кабельному лотку, а затем сбоку через 9 стоек к выделенному оптимизированному для направляющих коммутатору на плате, а вместо этого размещается. встроенный переключатель в середине стойки, предоставляющий каждому графическому процессору доступ к медному кабелю ЦАП.
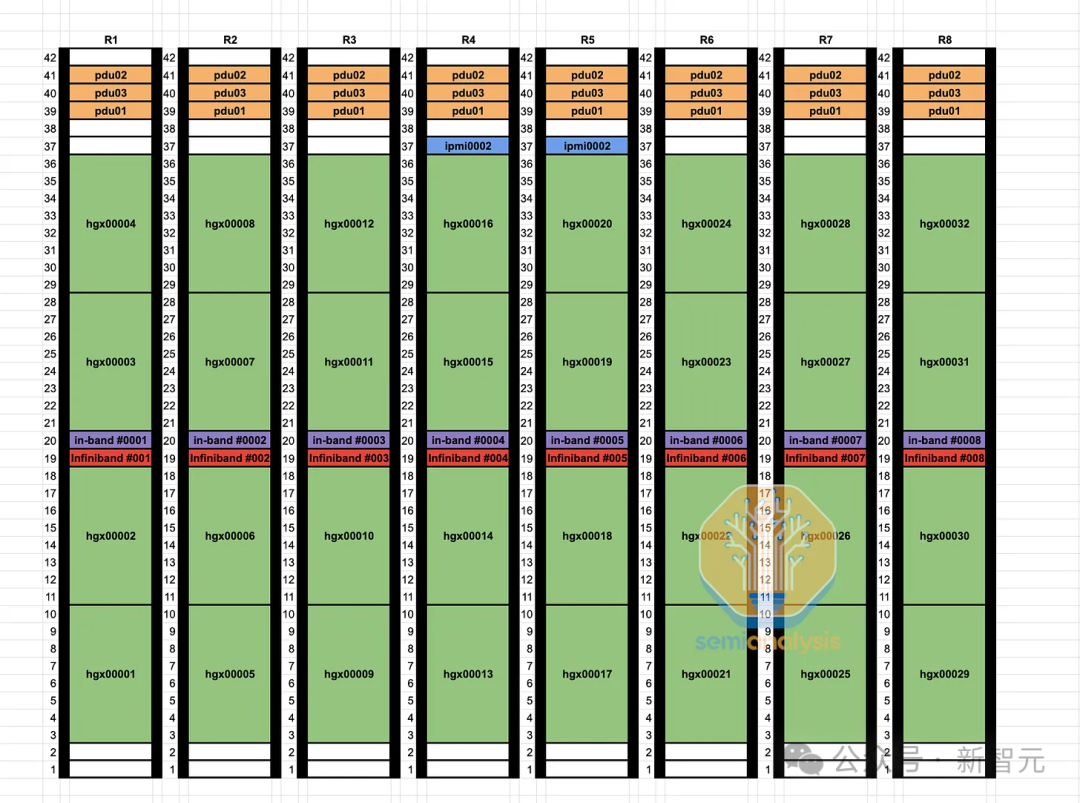
По сравнению с оптическими кабелями медные кабели ЦАП меньше охлаждаются, потребляют меньше энергии, стоят дешевле и более надежны, поэтому такая конструкция уменьшает периодические сбои и сбои сетевых соединений, что является проблемой для всех пользователей. Основные проблемы, с которыми сталкиваются высокоскоростные соединения. оптические устройства.
При использовании медного кабеля ЦАП магистральный коммутатор Quantum-2IB потребляет 747 Вт. При использовании многомодовых оптоволоконных трансиверов потребляемая мощность увеличивается до 1500 Вт.
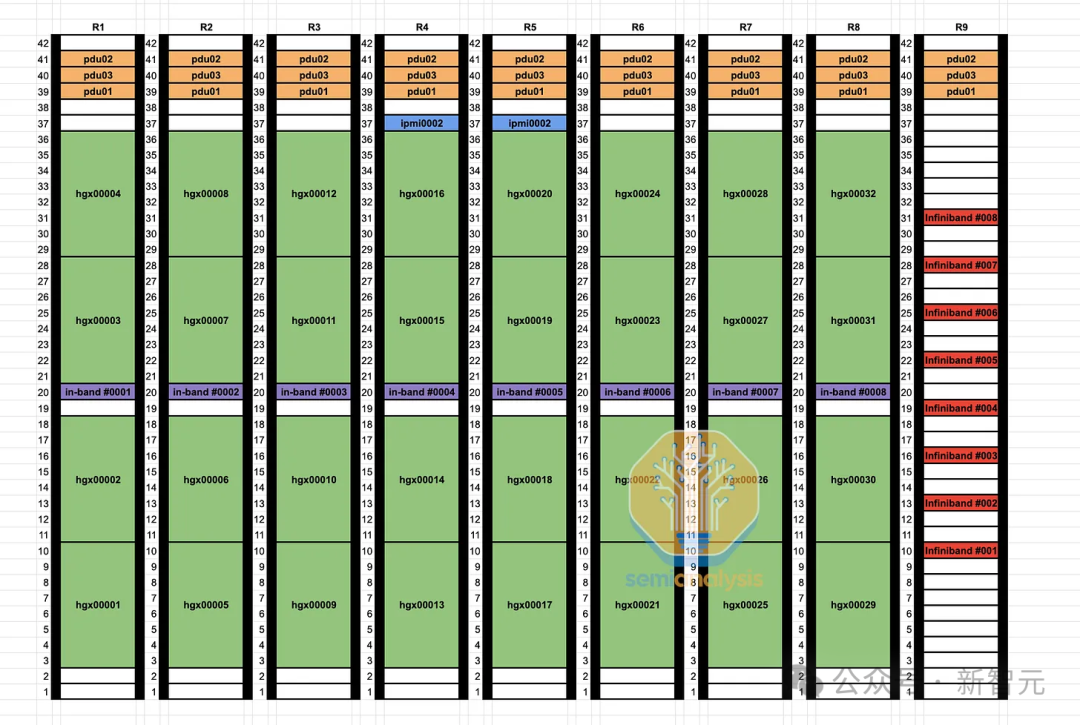
Кроме того, первоначальная прокладка кабелей в оптимизированной конструкции потребовала много времени для технических специалистов центра обработки данных, поскольку два конца каждого канала находились на расстоянии до 50 метров друг от друга и не находились в одной стойке.
В конструкции средней стойки конечные коммутаторы располагаются в той же стойке, что и все графические процессоры, подключенные к конечным коммутаторам. Еще до завершения проектирования связи между вычислительным узлом и конечным коммутатором можно протестировать на фабрике интеграции, поскольку все каналы являются таковыми. на той же стойке на стойке.
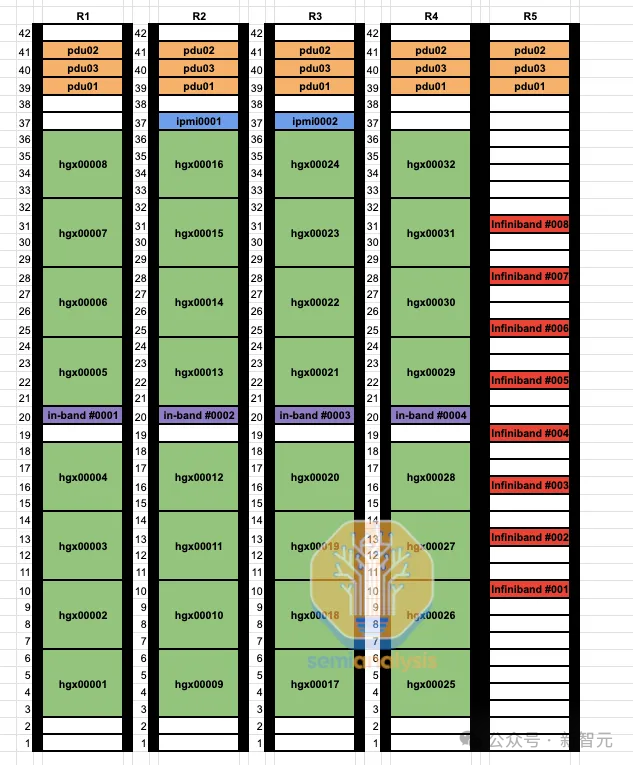
Надежность и восстановление
Поскольку обучение текущей модели выполняется одновременно, надежность стала одной из наиболее важных эксплуатационных проблем для гигантских кластеров. Наиболее распространенные проблемы с надежностью включают ошибки графического процессора HBM ECC, зависание драйвера графического процессора, сбой оптоволоконного приемопередатчика, перегрев сетевой карты и т. д.
Чтобы обеспечить низкое среднее время восстановления, центры обработки данных должны держать узлы горячего резерва и компоненты холодного резерва на месте. При возникновении сбоя лучший способ — не прекращать обучение напрямую, а заменить его уже включенным резервным узлом для продолжения обучения.
Фактически, большинство сбоев серверов можно устранить путем перезапуска, но иногда техническим специалистам приходится диагностировать и заменять оборудование на месте.
В лучшем случае специалистам центра обработки данных потребуется всего несколько часов для ремонта поврежденного сервера с графическим процессором, но во многих случаях для возврата поврежденного узла в эксплуатацию могут потребоваться дни.
При обучении модели контрольные точки необходимо часто сохранять в памяти ЦП или SSD-накопителе NAND, чтобы предотвратить такие ошибки, как HBM ECC. При возникновении ошибки веса модели и оптимизатора необходимо перезагрузить, прежде чем обучение можно будет продолжить.
Методы отказоустойчивого обучения (такие как Oobleck) можно использовать для предоставления управляемых приложениями методов обработки сбоев графического процессора и сети на уровне пользователя.
К сожалению, частая проверка контрольных точек резервного копирования и методы отказоустойчивого обучения могут нанести вред общему MFU системы, поскольку кластер необходимо постоянно приостанавливать, чтобы сохранить текущие веса в постоянной памяти или памяти ЦП.
Кроме того, контрольные точки обычно сохраняются только каждые 100 итераций, а это означает, что вы теряете до 99 шагов полезной работы при каждой перезагрузке. В кластере из 100 000 карт, если каждая итерация занимает 2 секунды, при сбое 99-й итерации будет потеряно максимум 229 графо-дней работы.
Другой метод аварийного переключения — заставить резервный узел выполнять репликацию RDMA с других графических процессоров через внутреннюю структуру. Внутренние графические процессоры имеют скорость около 400 Гбит/с, а каждый графический процессор имеет 80 ГБ памяти HBM, поэтому копирование весов занимает около 1,6 секунды.
При таком подходе вы теряете не более 1 шага (поскольку больше HBM графических процессоров будут иметь актуальные копии весов), поэтому только 2,3 дня вычислений на графическом процессоре плюс 1,85 на копирование весов с помощью RDMA в память из других HBM графических процессоров. Дни ГПУ.
Большинство ведущих лабораторий искусственного интеллекта переняли этот метод, но многие небольшие компании по-прежнему настаивают на использовании тяжелого, медленного и неэффективного метода обработки всех сбоев путем перезапуска с контрольной точки. Восстановление после сбоя посредством реконструкции памяти может улучшить MFU больших обучающих прогонов на несколько процентных пунктов.
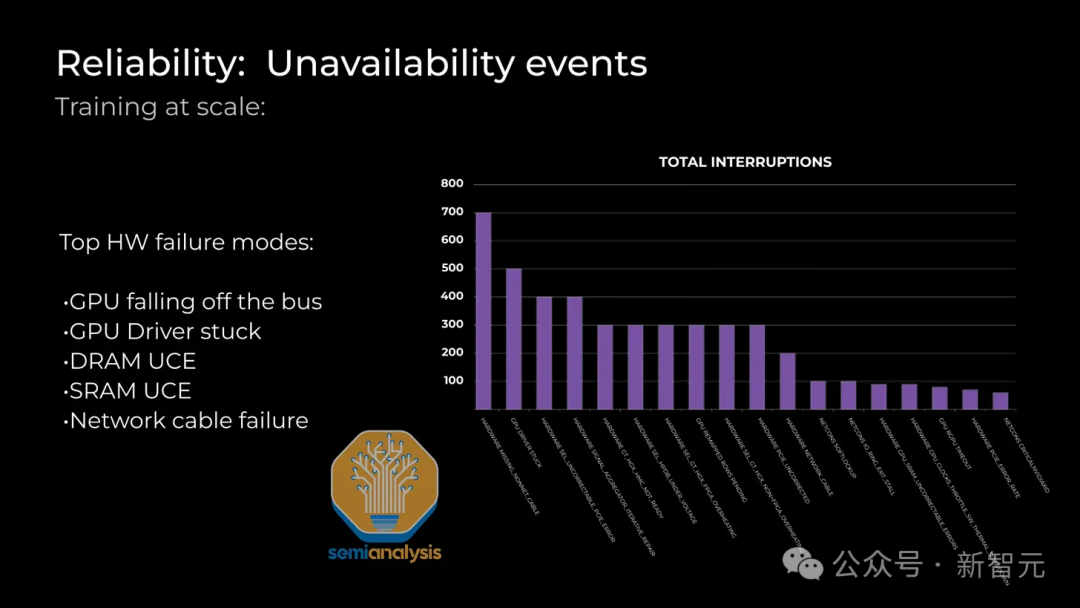
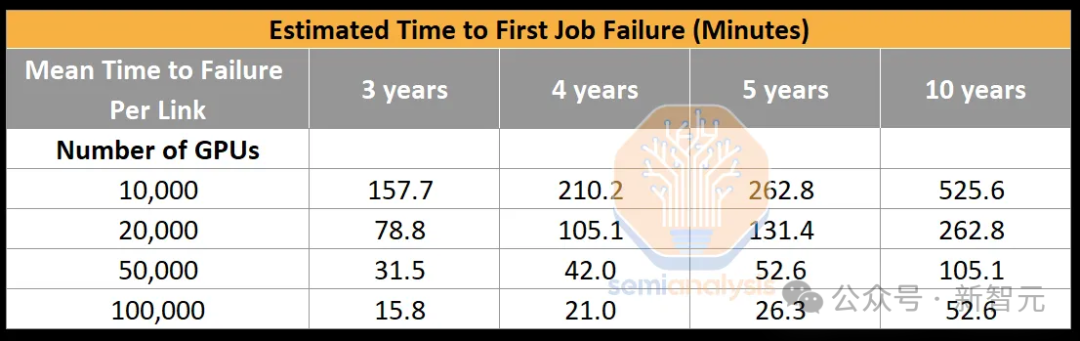
Что касается сетевых сбоев, одной из наиболее распространенных проблем является сбой канала Infiniband/RoCE. Из-за большого количества трансиверов, даже если средняя частота отказов каждой сетевой карты до нижнего звена коммутатора составляет 5 лет, первый сбой в работе нового функционирующего кластера займет всего 26,28 минут.
Если восстановление после сбоя не выполняется путем реконструкции памяти, в кластере графических процессоров на 100 000 карт время, затраченное на перезапуск из-за отказа оптоволокна, будет больше, чем фактический расчет модели.
Поскольку каждый графический процессор напрямую подключен к сетевой карте ConnectX-7 (через коммутатор PCIe), отказоустойчивость на уровне сетевой архитектуры отсутствует, поэтому сбои приходится обрабатывать в коде обучения пользователей, что усложняет базу кода.
Это одна из основных проблем текущей сетевой структуры графических процессоров NVIDIA и AMD. Даже если одна сетевая карта выйдет из строя, графический процессор не сможет взаимодействовать с другими графическими процессорами.
Поскольку модель большого языка (LLM) использует тензорный внутри узла параллелизм,Если сетевая карта, трансивер или графический процессор вышли из строя,Весь сервер выйдет из строя.
В настоящее время ведется большая работа по обеспечению реконфигурируемости сети и снижению уязвимости узлов. Эта работа имеет решающее значение, поскольку текущая ситуация означает, что весь GB200 NVL72 может выйти из строя из-за отказа всего лишь одного графического процессора или оптики.
Очевидно, выход из строя стойки с 72 графическими процессорами стоимостью в миллионы долларов является более катастрофическим, чем выход из строя сервера с 8 графическими процессорами стоимостью сотни тысяч долларов.
NVIDIA приняла к сведению эту серьезную проблему и добавила специальный механизм RAS (надежность, доступность и удобство обслуживания).
Среди них механизм RAS прогнозирует возможные сбои чипов и предупреждает технических специалистов центров обработки данных, анализируя данные на уровне чипа, такие как температура, количество восстановленных повторных попыток ECC, тактовая частота, напряжение и другие показатели.
Это позволит техническим специалистам выполнять профилактическое обслуживание, например, использовать конфигурации с более высокой скоростью вращения вентиляторов для поддержания надежности, а также выводить серверы из очереди на эксплуатацию для дальнейшего физического осмотра во время будущих периодов обслуживания.
Кроме того, перед началом задачи обучения механизм RAS каждого чипа выполняет комплексные самотестирования, такие как выполнение матричного умножения с известными результатами для обнаружения скрытого повреждения данных (SDC).
оптимизация затрат
Cedar-7
Некоторые клиенты, такие как Microsoft и OpenAI, используют сетевые модули Cedar Fever-7 вместо восьми сетевых карт ConnectX-7 в формате PCIe.
Основное преимущество использования модуля Cedar Fever заключается в том, что для него требуется всего 4 слота OSFP вместо 8, и он позволяет использовать двухпортовые трансиверы 2x400G на стороне вычислительного узла.
Это уменьшает количество трансиверов, подключенных к листовому коммутатору на каждом узле H100, с 8 до 4, общее количество трансиверов, подключающих графический процессор к листовому коммутатору на стороне вычислительного узла, сокращается с 98304 до 49152.

Это также помогает продлить время до первого сбоя задания, поскольку количество связей между графическим процессором и конечным коммутатором сокращается вдвое.
Расчетное среднее время до отказа для двухпортового канала 2x400G составляет 4 года (по сравнению с 5 годами для однопортового канала 400G), что увеличит расчетное время до первого сбоя в работе с 26,28 минут до 42,05 минут.

Spectrum-X
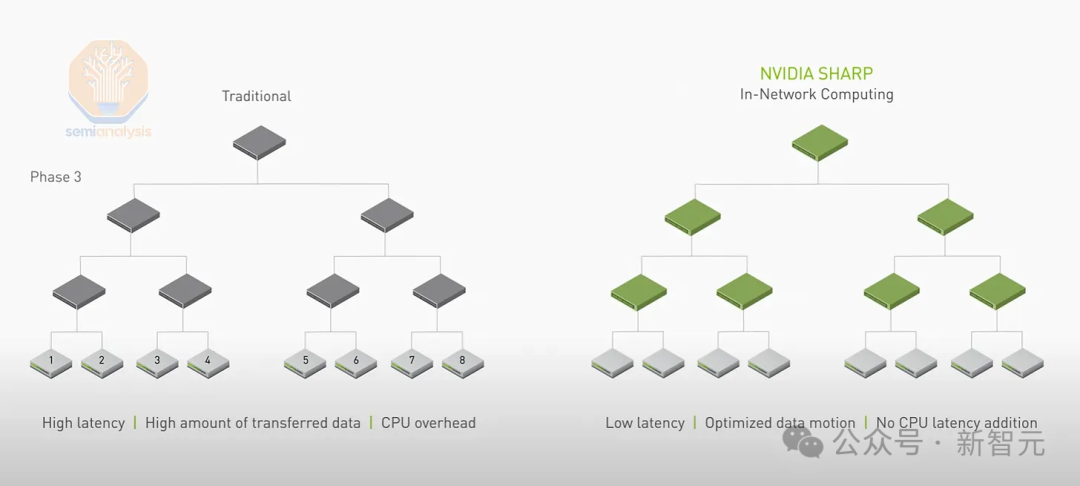
Преимущество InfiniBand заключается в том, что Ethernet не поддерживает сокращение SHARP внутри сети.
SHARP может сократить количество операций отправки и записи, требуемых каждым графическим процессором, в 2 раза, поэтому теоретическая пропускная способность сети также увеличивается в 2 раза.
Но коммутаторы InfiniBand NDR Quantum-2 имеют только 64 порта 400G, в то время как каждый коммутатор Spectrum-X Ethernet SN5600 имеет 128 портов 400G, а ASIC коммутатора Tomahawk 5 от Broadcom также поддерживает 128 портов 400G.
Из-за низкой пропускной способности портов коммутаторов Quantum-2 количество полностью связанных друг с другом графических процессоров в кластере из 100 000 узлов может достигать максимум 65 536 H100.
Впрочем, коммутатор InfiniBand следующего поколения, Quantum-X800, решит эту проблему со 144 портами 800G, но, как видно из номера «144», он предназначен для систем NVL72 и NVL36 и вряд ли будет доступен на B200 или B100 Широко используется в кластерах.
Основное преимущество Spectrum-X заключается в том, что он имеет поддержку первого уровня со стороны библиотек NVIDIA, таких как NCCL, что позволит вам оказаться в первой очереди клиентов их новой линейки продуктов.
Для сравнения, если вы используете чип Tomahawk 5, потребуется много внутренних инженерных усилий для оптимизации сети для достижения максимальной пропускной способности.
Однако, если вы используете Spectrum-X, вам придется доплатить за приобретение трансиверов из линейки продуктов Nvidia LinkX, поскольку другие трансиверы могут работать неправильно или не пройти проверку Nvidia.
Кроме того, Nvidia использовала Bluefield-3 вместо ConnectX-7 в качестве временного решения в первом поколении 400G Spectrum-X. (Ожидается, что ConnectX-8 будет отлично работать с 800G Spectrum-X)
В гипермасштабных центрах обработки данных разница в цене между Bluefield-3 и ConnectX-7 составляет около 300 долларов США, но первый потребляет на 50 Вт больше энергии. Таким образом, каждому узлу требуется дополнительно 400 Вт мощности, что снижает «интеллект на пикоджоуль» всего обучающего сервера.
Теперь для размещения Spectrum-X в центре обработки данных требуется дополнительно 5 МВт мощности для развертывания 100 000 графических процессоров, чего нет у Broadcom Tomahawk 5, использующего ту же сетевую архитектуру.
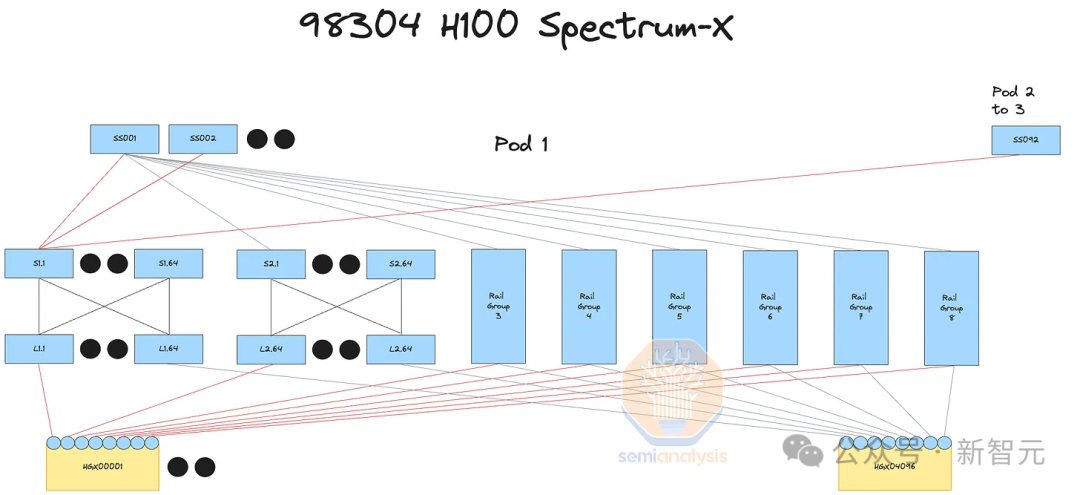
Tomahawk 5
Чтобы избежать высоких затрат Nvidia, многие клиенты предпочитают использовать коммутаторы на базе Broadcom Tomahawk 5.
Каждый коммутатор на базе Tomahawk 5 имеет те же 128 портов 400G, что и коммутатор Spectrum-X SN5600, и компании с хорошими сетевыми инженерами могут добиться аналогичной производительности. Кроме того, вы можете купить стандартные трансиверы и медные кабели у любого поставщика и смешать их.
Большинство клиентов работают напрямую с ODM-компаниями, такими как Celestica для своих коммутаторов, а также с Innolight и Eoptolink для своих трансиверов.
Судя по стоимости коммутаторов и универсальных трансиверов, Tomahawk 5 намного дешевле, чем Nvidia InfiniBand, и экономичнее, чем Nvidia Spectrum-X.
К сожалению, вам понадобится достаточно инженерного мастерства, чтобы исправить и оптимизировать коммуникационный кластер NCCL для Томагавка 5. В конце концов, хотя последний работает «из коробки», он оптимизирован только для Nvidia Spectrum-X и Nvidia InfiniBand.
Хорошая новость заключается в том, что если у вас есть 4 миллиарда долларов на 100 000 кластеров, у вас также должно быть достаточно инженерных возможностей для исправления NCCL и его оптимизации.
Конечно, разработка программного обеспечения — дело сложное, но Semianalysis считает, что каждый гипермасштабный центр обработки данных проведет такую оптимизацию и откажется от InfiniBand.

спецификация материалов
Общие капитальные затраты на 100 000 кластеров H100 составляют примерно 4 миллиарда долларов, но точная сумма будет варьироваться в зависимости от типа выбранной сети.
Конкретно его можно разделить на четыре типа:
1. 4-уровневая сеть InfiniBand, включающая 32 768 кластеров графических процессоров, оптимизация дорожек, коэффициент конвергенции 7:1.
2. Трехуровневая сеть Spectrum X, включающая 32 768 кластеров графических процессоров, оптимизация дорожек, коэффициент сходимости 7:1.
3. 3-слойная сеть InfiniBand, содержащая 24 576 кластеров GPU, неорбитальная оптимизация, используется для межкластерных соединений во внешних сетях.
4. Трехуровневая сеть Broadcom Tomahawk 5 Ethernet с 32 768 кластерами графических процессоров, оптимизация орбиты, коэффициент сходимости 7:1.
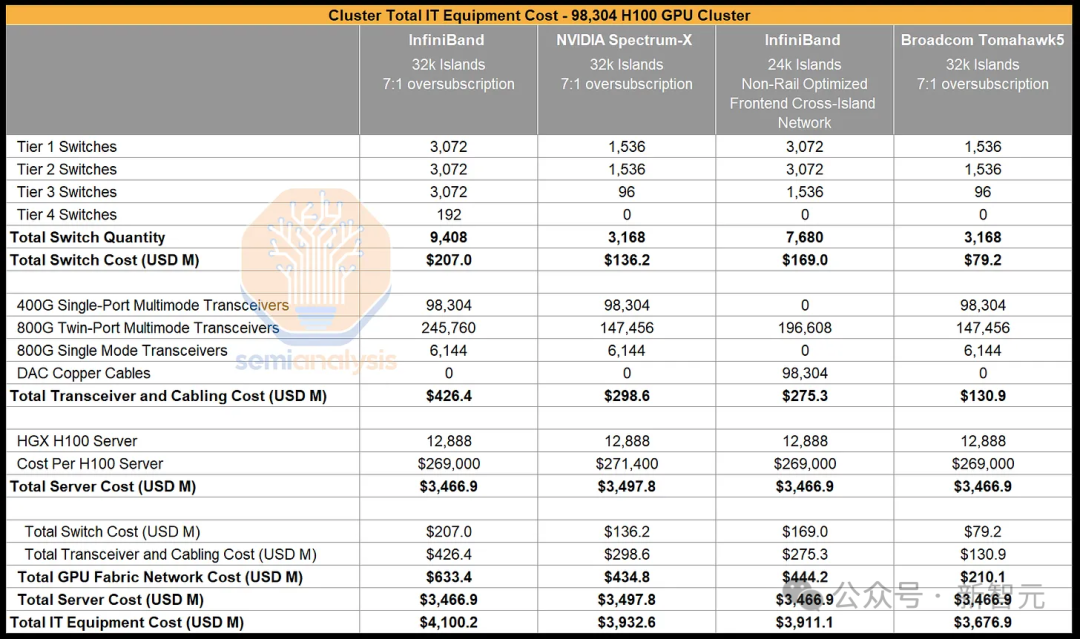
Видно, что вариант 1 в 1,3–1,6 раза дороже, чем другие варианты; вариант 2, хотя и обеспечивает более крупные кластеры, более высокую пропускную способность между кластерами и аналогичные затраты, требует большей мощности, а вариант 3 серьезно снизит гибкость параллельного подхода; решения.
Таким образом, кластер 32k на базе Broadcom Tomahawk 5 с коэффициентом конвергенции 7:1 является наиболее экономически эффективным вариантом, поэтому многие компании предпочитают строить подобные сети.
план этажа
Наконец, при проектировании кластера также необходимо оптимизировать расположение стоек.
Как видно на рисунке, некоторые ряды конечных коммутаторов расположены не в одном ряду. На самом деле это сделано для оптимизации использования 50 метров многомодового волокна.
Потому что, если вы поместите многомодовые трансиверы в конце ряда, переключатели в середине окажутся вне зоны действия.

План кластера 32 тыс. с использованием оптимизированного для орбиты Spectrum-X/Tomahawk 5
В этом кластере разработки Microsoft каждая стойка поддерживает плотность мощности до 40 к Вт, в каждой стойке размещается четыре узла H100.

На данный момент построено 3 из 4 зданий этого кластера на 100 000 узлов.
Для подключения серверов H100 к оконечным коммутаторам используется многомодовое оптоволокно AOC, обозначенное синим кабелем.

В дальнейшем доходы Broadcom от сети будут продолжать расти, поскольку они доминируют почти во всех гипермасштабных кластерах.
В то же время гигант продолжит расти в сфере сетевых технологий, поскольку множество новых облачных сервисов и предприятия склонны выбирать эталонные разработки Nvidia.
Ссылки:
https://www.semianalysis.com/p/100000-h100-clusters-power-network



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
