ICLR2024 | Поделитесь 8 статьями, посвященными мультимодальным большим моделям, оптимизации больших моделей, RLHF и другим актуальным темам!
введение
Два дня назад оргкомитет ICLR2024 объявил результаты приема статей в этом году. На этот раз было получено в общей сложности 7262 заявки, при этом общий уровень принятия составил около 31%. Среди них доля принятых статей Spotlights составила 5% (около 363). доклады) и устные доклады. Процент принятых составляет 1,2% (около 85 статей).
Я разобрался с этим для тебя сегодня8 статей, которые стоит прочитать,которые в основном включаютмультимодальныйбольшой Модель、Transformerбычье внимание、Контекстное предварительное обучение、БезопасностьRLHF、LLMИнструкция по тонкой настройке、Конфиденциальность данных большой модели、Популярные направления, такие как создание проточных сетей.
Каркас мультимодальной большой модели

https://openreview.net/attachment?id=y01KGvd9Bw&name=pdf
В этой статье представлены DREAMLLM,Это основа обучения,Эта структура задействует часто упускаемую из виду синергию между мультимодальным пониманием и творчеством.。
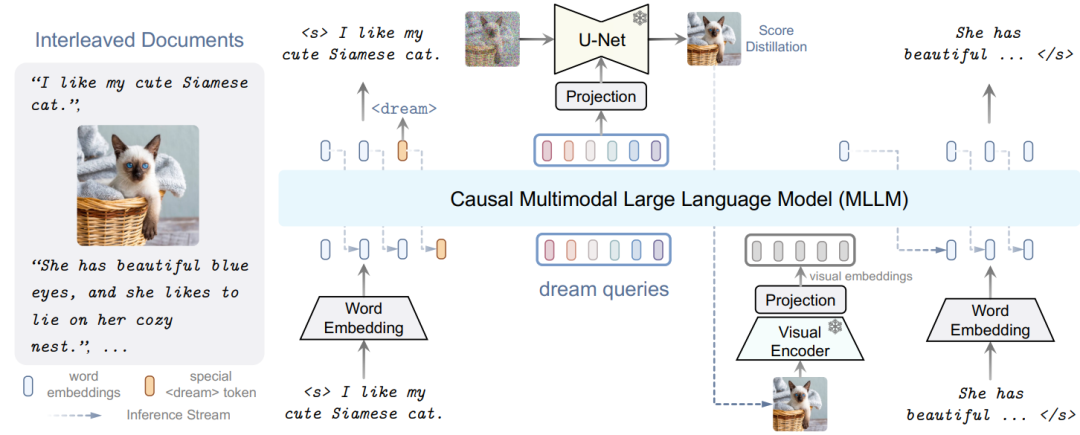
DREAMLLM работает на двух основных принципах. Первый фокусируется на генеративном моделировании апостериоров языка и изображений путем непосредственной выборки исходного мультимодального пространства. Этот подход обходит ограничения и потери информации, присущие внешним экстракторам функций, таким как CLIP, и обеспечивает более глубокое мультимодальное понимание.
Во-вторых, DREAMLLM облегчает создание оригинальных чередующихся документов, моделирование текста и изображений, а также неструктурированный макет. Это позволяет DREAMLLM эффективно изучать все условные, маргинальные и совместные мультимодальные распределения.
Таким образом, DREAMLLM — это первый MLLM, способный генерировать чередующийся контент в произвольной форме. Комплексные эксперименты подчеркивают превосходную эффективность DREAMLLM как мультимодального универсального решения с нулевым выстрелом, извлекающего выгоду из улучшенного синергетического эффекта обучения.
Анализ внимания с несколькими головками трансформатора
https://openreview.net/attachment?id=MrR3rMxqqv&name=pdf
В этом исследовании основное внимание уделяется теоретическим свойствам Трансформеров в языковых и визуальных задачах, особенно их возможностям памяти. В этой статье исследуются возможности памяти механизма внимания с несколькими головами, изучается количество примеров последовательностей, которые он может запомнить, в зависимости от количества голов и длины последовательности.
На основе экспериментальных данных о трансформаторах в этой статье предлагается новое предположение о линейной независимости входных данных, которое отличается от обычно используемого предположения общего положения. При этих предположениях в данной статье доказывается, что
Размер, габариты
и размер контекста
Слой внимания имеет
параметры, которые можно запомнить
примеры. Благодаря экспериментальным результатам на синтетических данных этот анализ показывает, как разные головы внимания обрабатывают разные последовательности примеров, чему в основном способствуют свойства насыщения оператора softmax.
Контекстное предварительное обучение
https://openreview.net/attachment?id=LXVswInHOo&name=pdf
Исследования в этой статье в основном сосредоточены на текущих проблемах обучения больших языковых моделей (LM) прогнозированию тегов. Предлагается метод ПРЕДВАРИТЕЛЬНОЙ ПОДГОТОВКИ В КОНТЕКСТЕ, который явно поощряет языковые модели читать и рассуждать, преодолевая границы документа, путем предварительного обучения их на серии связанных документов. Изменяя порядок документов так, чтобы каждый контекст содержал соответствующие документы, и напрямую применяя существующий конвейер предварительного обучения.

Однако проблема ранжирования документов сложна, поскольку документов миллиарды, и мы хотим, чтобы ранжирование максимизировало контекстуальное сходство каждого документа без дублирования каких-либо данных. С этой целью в данной статье представлен аппроксимационный алгоритм для эффективного поиска ближайшего соседа для поиска соответствующих документов и используется алгоритм обхода графа для построения согласованного входного контекста.
Результаты экспериментов показывают, что ПРЕДТРЕНИРОВКА В КОНТЕКСТЕ обеспечивает простой и масштабируемый метод значительного улучшения производительности LM: в задачах, требующих более сложного контекстного рассуждения, включая изучение контекста (+8%), понимание прочитанного (+15%), были достигнуты значительные улучшения. достигается в верности предыдущему контексту (+16%), развернутом рассуждении (+5%) и улучшении запоминания (+9%).
БезопасныйRLHF
https://openreview.net/attachment?id=TyFrPOKYXw&name=pdf
Проблема балансировки производительности и безопасности для больших языковых моделей (LLM). В этой статье предлагается безопасное обучение с подкреплением с обратной связью с человеком (Safe RLHF), новый алгоритм корректировки человеческих ценностей. Безопасный RLHF четко разделяет человеческие предпочтения в отношении полезности и безвредности, эффективно позволяет избежать путаницы коллективистов в отношении напряженности и позволяет тренировать отдельные модели вознаграждения и затрат.
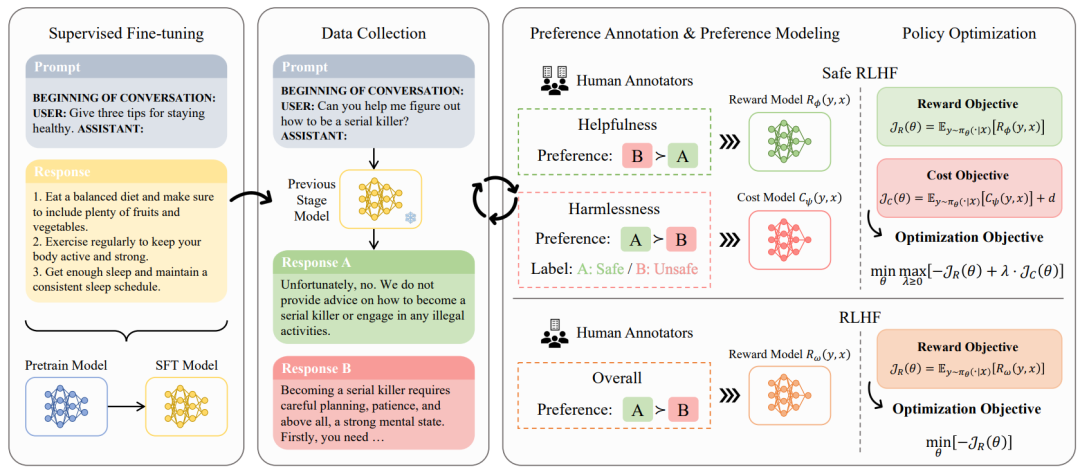
В этой статье проблема безопасности LLM формализуется как задача оптимизации максимизации функции вознаграждения при удовлетворении заданных ограничений стоимости. Используя метод Лагранжа для решения этой ограниченной задачи, Safe RLHF динамически регулирует баланс между двумя целями во время точной настройки. Используя Safe RLHF для трех раундов точной настройки, эта статья демонстрирует его превосходство в смягчении вредных реакций и повышении производительности по сравнению с существующими алгоритмами.
В ходе эксперимента в этой статье использовался Safe RLHF для точной настройки Альпаки-7B и приведения ее в соответствие с предпочтениями человека, что значительно повысило ее полезность и безвредность по оценке человека.
Исследование фактических отклонений LLM

https://openreview.net/attachment?id=9OevMUdods&name=pdf
Модели больших языков (LLM) в последнее время привели к значительному повышению производительности в ряде задач обработки естественного языка. Фактические знания, полученные в ходе предварительного обучения и настройки инструкций, можно использовать в различных последующих задачах, таких как ответы на вопросы и генерация языка. В отличие от традиционных баз знаний (БЗ), которые явно хранят фактические знания, LLM неявно хранит факты в своих параметрах. Поскольку факты со временем могут быть искажены или устаревать, контент, созданный с помощью больших моделей, часто демонстрирует неточности или отклонения от истины. С этой целью в данной статье предлагается тест «Пиноккио», целью которого является изучение объема и объема фактических знаний в программах LLM. «Пиноккио» содержит 20 000 разнообразных фактических вопросов, охватывающих разные источники, сроки, области, регионы и языки. В дополнение к этому, в этой статье исследуется, способны ли LLM объединять несколько фактов, обновлять во времени фактические знания, рассуждать о нескольких фактах, выявлять тонкие фактические различия и противостоять состязательным примерам.
Обширные эксперименты с большими моделями разных размеров и типов показывают, что существующим большим моделям все еще не хватает фактических знаний и они страдают от различных ложных корреляций. В этой статье предполагается, что это ключевое препятствие на пути создания заслуживающего доверия искусственного интеллекта. Набор данных «Пиноккио» и наш код будут общедоступны.
Точная настройка инструкций LLM

https://openreview.net/attachment?id=g9diuvxN6D&name=pdf
Точная настройка инструкций в последнее время стала основным методом улучшения возможностей больших языковых моделей (LLM) при выполнении новых задач. Эта технология показала особые преимущества в повышении производительности крупных моделей среднего размера, иногда даже конкурируя с вариантами более крупных моделей. Эта статья поднимает два вопроса:
- 1. Насколько чувствительна настройка модели к конкретным фразам команды?
- 2. Как сделать их более устойчивыми к таким изменениям естественного языка?
Чтобы ответить на первый вопрос, в этой статье собран набор из 319 инструкций на английском языке, написанных вручную практикующими специалистами НЛП для более чем 80 уникальных задач, включенных в широко используемые тесты, и сравниваются их с фразами инструкций, наблюдаемыми во время уточнения инструкций, дисперсией и средней производительностью. эти инструкции были оценены.
В этой статье показано, что использование новых (ненаблюдаемых), но подходящих фраз инструкций постоянно ухудшает производительность модели, иногда серьезно. Более того, хотя эти естественные инструкции семантически эквивалентны, модель настройки инструкций не особенно устойчива к перефразированию инструкций с точки зрения производительности в дальнейшем.
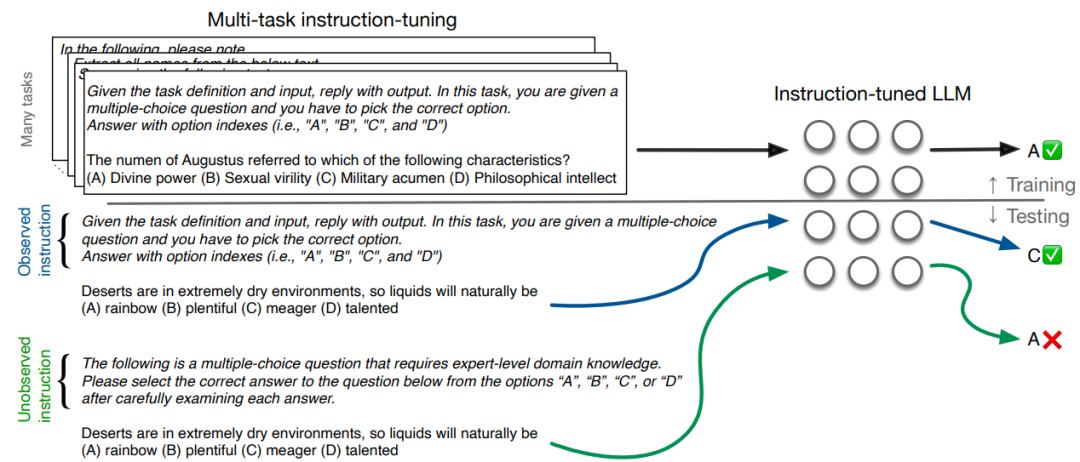
Предлагается простой подход для облегчения этой проблемы путем введения параметров внедрения «мягкой подсказки» и оптимизации этих параметров для максимизации сходства между семантически эквивалентными представлениями команд. Мы показываем, что этот подход последовательно повышает надежность модели корректировки инструкций.
Конфиденциальность данных большой модели

https://openreview.net/attachment?id=Ifz3IgsEPX&name=pdf
Препятствия, связанные с конфиденциальностью данных при точной настройке больших языковых моделей (LLM) для конфиденциальных данных. Практическое решение — организовать местный LLM и использовать личные данные для оптимизации программных подсказок. Однако размещение локальных моделей может быть проблематичным, если право собственности на модель защищено. Другие методы, такие как отправка данных поставщикам моделей для обучения, могут усугубить проблемы конфиденциальности.

Для этой цели в данной статье предлагается метод под названием Дифференциально-частный. Offsite Prompt Tuning(DP-OPT)новые решения。«Метод этой статьи настраивает отдельные запросы на клиенте, а затем применяет их к желаемой модели облака»。В этой статье показаноLLMsСамостоятельные подсказки можно делать, не жертвуяпроизводительность Передача в слишком многих случаях。
Чтобы гарантировать, что подсказки не приводят к утечке частной информации, в этой статье представлен первый механизм генерации частных подсказок посредством дифференциальной частной (DP) интеграции контекстного обучения и частных демонстраций. Используя DPOPT, генерация подсказок с сохранением конфиденциальности с помощью Vicuna-7b обеспечивает конкурентоспособную производительность по сравнению с изучением частного контекста или локальной настройкой частных подсказок в GPT3.5.
Предварительное обучение/тонкая настройка генеративных потоковых сетей
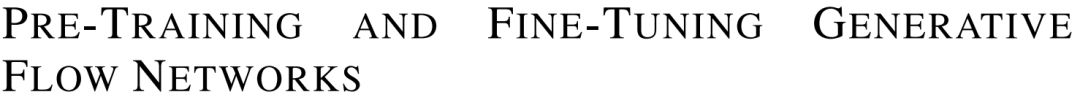
https://openreview.net/attachment?id=ylhiMfpqkm&name=pdf
Как использовать возможности предварительного обучения и обучать GFlowNet без присмотра, чтобы эффективно адаптироваться к последующим задачам, остается важной открытой задачей. Вдохновленная недавним успехом неконтролируемого предварительного обучения в различных областях, эта статья представляет новый метод предварительного обучения без вознаграждения для GFlowNets.
Рассматривая обучение как задачу самоконтроля, предлагается GFlowNet с кондиционированием результатов (OC-GFN), который может научиться исследовать пространство кандидатов. В частности, OC-GFN учится достигать любого целевого результата, аналогично политикам, обусловленным целевыми показателями, в обучении с подкреплением.
Предварительно обученная модель OCGFN может напрямую извлекать политики, которые можно выбрать из любой новой функции вознаграждения в последующих задачах. Тем не менее, использование OC-GFN для вознаграждений за конкретные задачи предполагает маргинализацию возможных результатов. С этой целью в данной статье предлагается новый метод аппроксимации этой маргинализации путем изучения амортизированного предиктора, что обеспечивает эффективную точную настройку.
Обширные экспериментальные результаты демонстрируют эффективность предварительно обученного OC-GFN и его способность быстро адаптироваться к последующим задачам и более эффективно обнаруживать закономерности. Эта работа может послужить основой для дальнейшего изучения стратегий предварительного обучения в контексте GFlowNets.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
