ICLR 2024 | TIME-LLM: Перекодирование данных временных рядов в более естественное текстовое представление
Прогнозирование временных рядов имеет большое значение во многих реальных динамических системах и широко изучается. В отличие от обработки естественного языка (NLP) и компьютерного зрения (CV), где одна большая модель может обрабатывать несколько задач, модели прогнозирования временных рядов часто необходимо специально разрабатывать для удовлетворения потребностей различных задач и приложений. Хотя предварительно обученные базовые модели добились впечатляющего прогресса в области НЛП и CV, их развитие в области временных рядов по-прежнему ограничено разреженностью данных. Недавние исследования показали, что большие языковые модели (LLM) обладают надежными возможностями распознавания образов и рассуждений при обработке сложных последовательностей токенов. Однако вопрос о том, как эффективно согласовать данные временных рядов и естественный язык и использовать эти возможности, остается проблемой.
В этой статье представлена работа с использованием модели большого языка (LLM) для прогнозирования временных рядов. В документе принята независимая от канала стратегия, которая разлагает прогнозы с несколькими переменными на несколько независимых прогнозов с одной переменной.

Адрес статьи: https://arxiv.org/abs/2310.01728.
Исходный код статьи: https://anonymous.4open.science/r/Time-LLM.
Обзор бумаги
В этой работе авторы предлагают TIME-LLM, структуру перепрограммирования, которая переназначает LLM для общего прогнозирования временных рядов, сохраняя при этом базовую языковую модель. Авторы сначала перепрограммируют входной временной ряд, используя текстовый прототип, а затем вводят его в замороженный LLM, чтобы согласовать два режима. Чтобы улучшить способность LLM к рассуждению о данных временных рядов, автор предложил метод Prompt-as-Prefix (PaP) для обогащения входных временных рядов путем добавления дополнительного контекста к входным временным рядам и предоставления инструкций по задачам на естественном языке. Наконец, для получения результатов прогнозирования прогнозируются участки временных рядов, преобразованные с помощью LLM.
Основные результаты этой работы можно резюмировать следующим образом:
• Внедряет новую концепцию перепрограммирования больших языковых моделей для прогнозирования временных рядов без изменения предварительно обученной базовой модели. Исходя из этого, авторы показывают, что прогнозирование можно рассматривать как еще одну «лингвистическую» задачу, которую можно эффективно решить с помощью готовых LLM.
• Предложил новую структуру TIME-LLM, которая включает в себя перепрограммирование входных временных рядов в более естественное представление текстового прототипа и дополнение входного контекста декларативными подсказками, такими как экспертные знания предметной области и описания задач для руководства при рассуждениях LLM. Этот метод указывает на превосходную производительность мультимодальных базовых моделей как для языка, так и для временных рядов.
• TIME-LLM стабильно превосходит современные решения при решении основных задач прогнозирования, особенно в сценариях с малым числом и нулевым количеством попыток. Кроме того, можно достичь более высокой производительности при сохранении превосходной эффективности перепрограммирования модели. Значительно раскройте неиспользованный потенциал LLM для временных рядов и других последовательных данных.
модельная основа
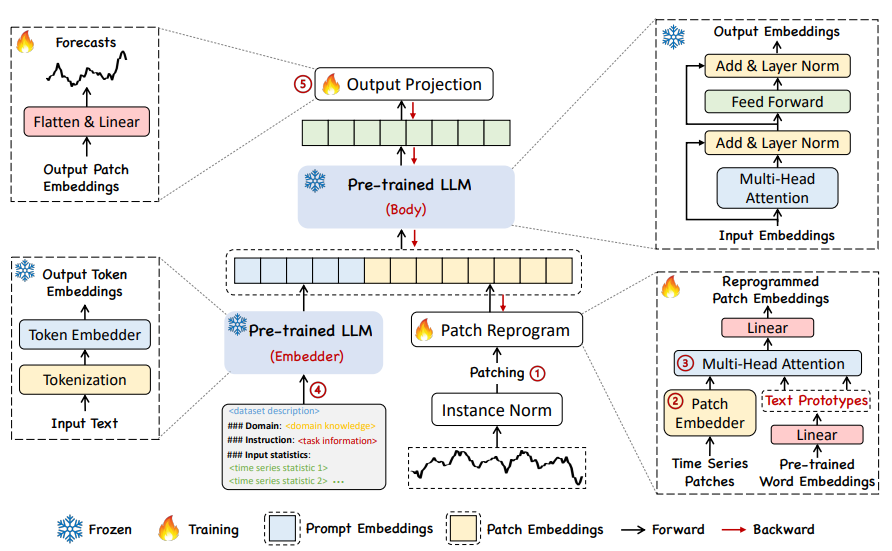
01
Input Embedding
Как показано ①и② на рисунке выше, модельная основа.,Временной ряд сначала проходит операцию нормализации RevIN.,Затем разделите патч на вложения,Получите форму как
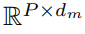
Входные характеристики синхронизации
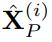
。
02
Patch Reprogramming
Из-за различий в способах выражения временные ряды и текст относятся к разным модальностям. Временные ряды нельзя ни редактировать напрямую, ни описывать без потерь на естественном языке, что представляет собой серьезную проблему для прямого руководства LLM для понимания временных рядов без необходимости ресурсоемкой точной настройки. Следовательно, необходимо согласовать временные функции ввода с текстовой областью естественного языка.
Распространенным методом согласования различных модальностей является перекрестное внимание. Вам нужно только сделать перекрестное внимание для функций внедрения и временного ввода всех слов (где функция временного ввода — это запрос, а внедрение всех слов — это ключ и значение). ). Однако словарный запас очень велик, и, конечно, невозможно напрямую сопоставить временные характеристики со всеми словами, и не все слова имеют семантические отношения, согласованные с временными рядами.
Для решения вышеизложенных задач в статье выполняется линейное комбинирование для получения текстовых прототипов.
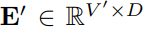
, количество слов, содержащихся в текстовых прототипах, намного меньше, чем в исходном словаре, и эту комбинацию можно использовать для представления изменяющихся характеристик данных временных рядов, таких как «короткий рост или медленное снижение». Далее в статье используется механизм самообслуживания с несколькими головками для адаптивного получения текстового описания, соответствующего патчу, следующим образом:
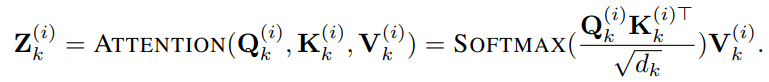
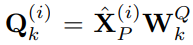
,
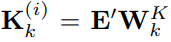
,
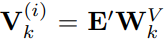
Выходные данные нескольких головок объединяются и получаются через линейный слой.
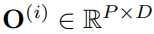
, как представление данных временного ряда (обратите внимание, что это представление одноканальных данных). Благодаря вышеупомянутому механизму внимания представления слов агрегируются вместо внедрения исходной последовательности. Это необходимо для лучшей адаптации к LLM. В конце концов, LLM обучается на данных корпуса, а не на данных временных рядов.
03
Prompt-as-Prefix
Prompt-as-Prefix (PaP) — это простой, но эффективный метод активации LLM для конкретной задачи. Однако перевод временных рядов непосредственно на естественный язык создает значительные проблемы, которые препятствуют как созданию наборов данных, которые следуют инструкциям, так и эффективному использованию оперативных сигналов без ущерба для производительности.
Недавние достижения показали, что другие шаблоны данных, такие как изображения, могут быть легко интегрированы в префикс сигналов, что позволяет эффективно делать выводы на основе этих входных данных. Вдохновленные этими открытиями, авторы, чтобы сделать свой метод непосредственно применимым к реальным временным рядам, ставят альтернативный вопрос: могут ли подсказки служить операцией предварительной обработки для обогащения входного контекста и управления преобразованием перепрограммированных фрагментов временных рядов? Эта концепция называется Prompt-as-Prefix (PaP), и, кроме того, авторы отметили, что она значительно улучшает адаптируемость LLM к последующим задачам, дополняя при этом перепрограммирование исправлений. С точки зрения непрофессионала, это означает подачу некоторой предварительной информации из набора данных временных рядов в виде префиксной подсказки в форме естественного языка и объединение выровненных функций временных рядов с LLM. Может ли это улучшить эффект прогнозирования?
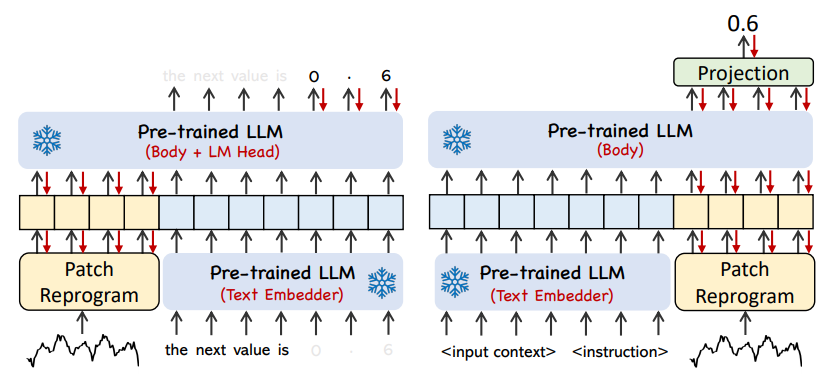
На рисунке выше показаны два метода подсказки. В Patch-as-Prefix языковой модели предлагается предсказать последующие значения во временном ряду, выраженные на естественном языке. Этот подход сталкивается с некоторыми ограничениями: (1) языковые модели часто демонстрируют низкую чувствительность при обработке чисел высокой точности без помощи внешних инструментов, что создает серьезные проблемы для точной обработки задач долгосрочного прогнозирования (2) сложная настраиваемая постобработка; требуется для разных языковых моделей, поскольку они предварительно обучены на разных корпусах и могут использовать разные типы сегментации слов при генерации чисел высокой точности. Это приводит к тому, что прогнозы представляются в различных форматах естественного языка, например.
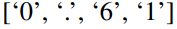
и
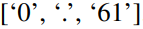
, что представляет собой 0,61 в десятичном формате.
С другой стороны, Prompt-as-Prefix ловко обходит эти ограничения. На практике авторы определили три ключевых компонента для создания эффективных подсказок: (1) контекст набора данных; (2) инструкции по задачам, позволяющие LLM адаптироваться к различным последующим задачам; (3) статистические описания, такие как тенденции, задержки и т. д. позволяя LLM лучше понимать характеристики данных временных рядов. На изображении ниже показан пример подсказки.

Результаты эксперимента
TIME-LLM в нескольких тестах и настройках,Особенно в сценариях с малым количеством выборок и с нулевой выборкой.,Все они продолжают с большим отрывом превосходить самые передовые методы прогнозирования.
В таблице 1 ниже показано, что TIME-LLM в большинстве случаев превосходит все базовые показатели и имеет значительные преимущества по сравнению с большинством базовых показателей.
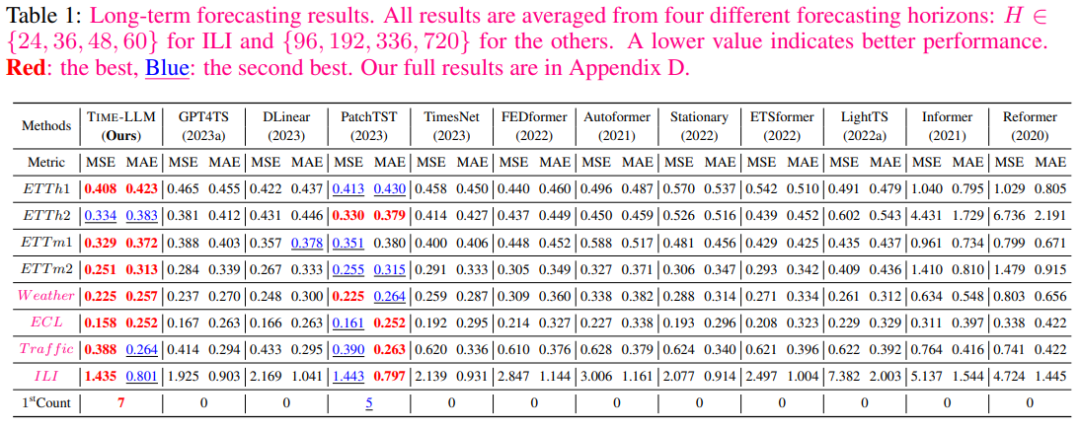
В области 10% обучения за несколько кадров,По сравнению с GPT4TS,Авторский метод обеспечивает снижение MSE на 5%.,Без каких-либо доработок LLM. По сравнению с последними моделями SOTA, такими как PatchTST, DLinear иTimesNet.,Средние улучшения авторов превысили 8%, 12% и 33%.
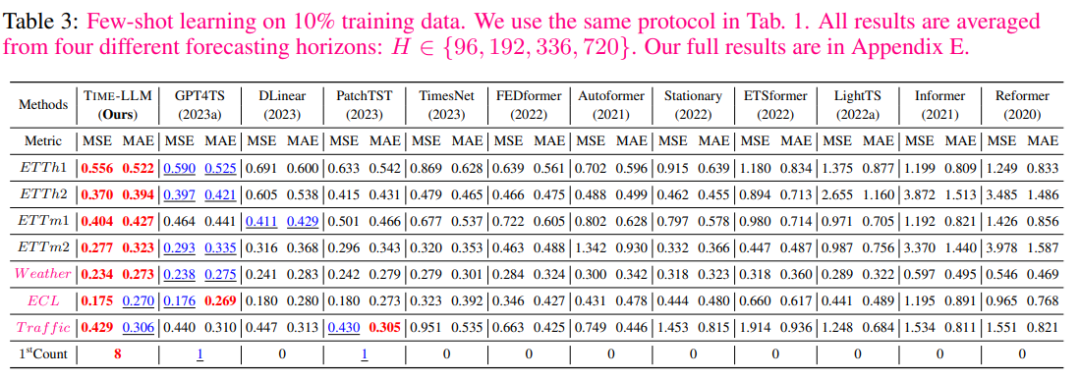
В сценарии 5% обучения с несколькими выстрелами,Аналогичную тенденцию можно наблюдать,По сравнению с GPT4TS,Среднее улучшение авторов составило более 5%. По сравнению с PatchTST, DLinearиTimesNet,TIME-LLM демонстрирует поразительное среднее улучшение — более 20%.
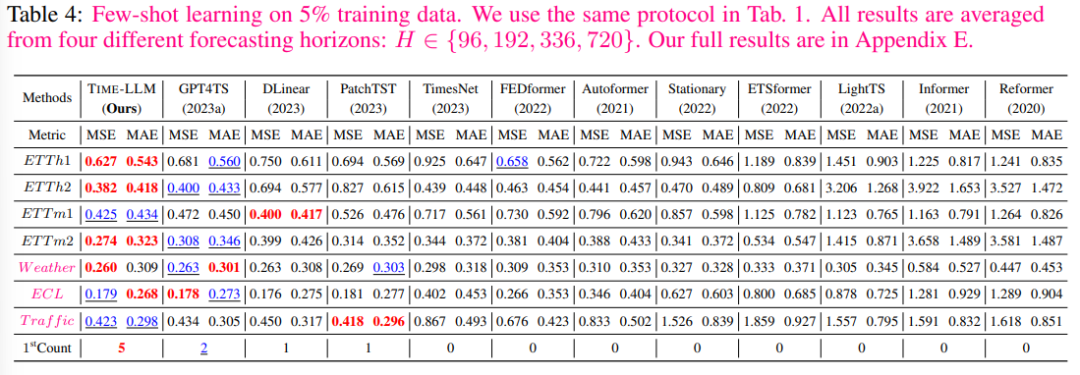
Заинтересованные друзья могут просмотреть исходный текст статьи, чтобы узнать больше об экспериментальных данных и результатах.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
